개요
감사 데이터의 세계는 복잡할 수 있으며 극복해야 할 과제가 많습니다. 가장 큰 과제 중 하나는 데이터 세트를 처리하는 동안 범주 속성을 처리하는 것입니다. 이 기사에서는 데이터 감사, 이상 감지 및 범주 속성 인코딩이 모델에 미치는 영향의 세계를 탐구합니다.
감사 데이터에 대한 이상 탐지와 관련된 주요 문제 중 하나는 범주 속성을 처리하는 것입니다. 모델이 텍스트 입력을 해석할 수 없기 때문에 범주형 특성 인코딩은 필수입니다. 일반적으로 이것은 Label 인코딩 또는 One Hot 인코딩을 사용하여 수행됩니다. 그러나 대규모 데이터 세트에서 One-hot 인코딩은 차원의 저주로 인해 모델 성능이 저하될 수 있습니다.
학습 목표
-
감사 데이터의 개념과 과제를 이해하려면
- 심층 비감독 이상 탐지의 다양한 방법을 평가합니다.
- 감사 데이터에서 이상 탐지에 사용되는 모델에 대한 인코딩 범주 속성의 영향을 이해합니다.
이 기사는 데이터 과학 Blogathon.
차례
- 아우아타란?
- 이상 탐지 란 무엇입니까?
- 데이터를 감사하는 동안 직면하는 주요 문제
- 이상 감지를 위한 데이터 세트 감사
- 범주 속성의 인코딩
- 범주 인코딩
- 감독되지 않은 이상 탐지 모델
- 인코딩 범주 속성이 모델에 어떤 영향을 줍니까?
8.1 자동차 보험 데이터 세트의 t-SNE 표현
8.2 차량 보험 데이터 세트의 t-SNE 표현
8.3 Vehicle Claims 데이터 세트의 t-SNE 표현 - 결론
데이터를 감사하고 있습니까?
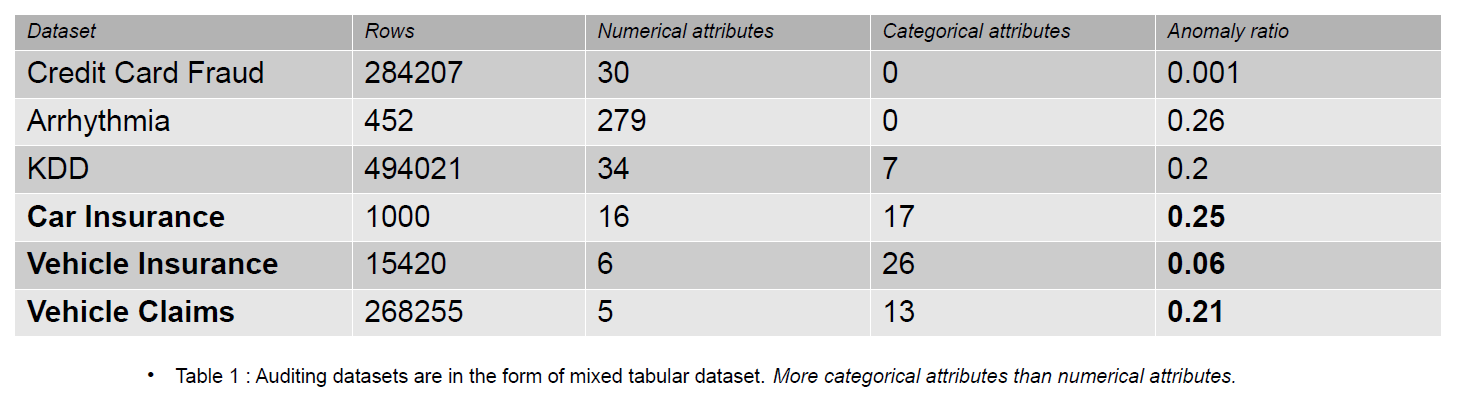
감사 데이터에는 정보 시스템에 대한 저널, 보험 청구 및 침입 데이터가 포함될 수 있습니다. 이 기사에서 제공된 예는 차량의 보험 청구입니다. 보험 청구는 KDD와 같은 이상 감지 데이터 세트와 더 많은 범주 기능으로 구별할 수 있습니다.
범주형 기능은 정수 또는 문자 유형일 수 있는 데이터의 디스크입니다. 수치적 특성은 항상 실제 값을 갖는 데이터의 연속적인 속성입니다. 신용 카드 사기 데이터와 같은 이상 탐지 커뮤니티에서 숫자 기능이 있는 데이터 세트가 인기가 있습니다. 공개적으로 사용 가능한 대부분의 데이터 세트에는 보험 청구 데이터보다 범주 기능이 적습니다. 범주형 기능은 보험 청구 데이터 세트의 숫자 기능보다 더 많습니다.
보험 청구에는 모델, 브랜드, 소득, 비용, 문제, 색상 등과 같은 기능이 포함됩니다. 범주 기능의 수는 신용 카드 및 KDD 데이터 세트보다 감사 데이터에서 더 많습니다. 이러한 데이터 세트는 감독되지 않은 이상 탐지 방법의 벤치마크입니다. 아래 표에서 볼 수 있듯이 보험 청구 데이터 세트에는 사기성 데이터의 동작을 이해하는 데 중요한 더 많은 범주 기능이 있습니다.
범주형 인코딩의 영향을 평가하는 데 사용되는 감사 데이터 세트는 자동차 보험, 차량 보험 및 차량 청구입니다.
이상 탐지 란 무엇입니까?
이상은 특정 거리(임계값)만큼 데이터 세트의 정상 데이터에서 멀리 떨어진 관찰입니다. 감사 데이터 측면에서 우리는 사기성 데이터라는 용어를 선호합니다. 이상 탐지는 기계 학습 또는 딥 러닝 모델을 사용하여 정상적인 데이터와 사기성 데이터를 구분합니다. 다른 방법 밀도 추정, 재구성 오류 및 분류 방법과 같은 이상 탐지에 사용할 수 있습니다.
- 밀도 추정 – 이러한 방법은 정규 데이터 분포를 추정하고 학습된 분포에서 샘플링되지 않은 비정상 데이터를 분류합니다.
- 재구성 오류 – 재구성 오류 기반 방법은 정상 데이터가 비정상 데이터보다 적은 손실로 재구성될 수 있다는 원리에 기반합니다. 재구성 손실이 높을수록 데이터가 이상일 가능성이 높아집니다.
- 분류 방법 - 다음과 같은 분류 방법 랜덤 포레스트, Isolation Forest, One Class – Support Vector Machines 및 Local Outlier Factors를 이상 감지에 사용할 수 있습니다. 이상 감지의 분류에는 클래스 중 하나를 이상으로 식별하는 작업이 포함됩니다. 그래도 클래스는 다중 클래스 시나리오에서 두 그룹(0과 1)으로 나뉘며 데이터가 적은 클래스가 비정상 클래스입니다.
위 방법의 출력은 이상 점수 또는 재구성 오류입니다. 그런 다음 비정상적인 데이터를 분류하는 임계값을 결정해야 합니다.
데이터를 감사하는 동안 직면하는 주요 문제
- 범주 속성 처리: 모델이 텍스트 입력을 해석할 수 없기 때문에 범주형 특성 인코딩은 필수입니다. 따라서 값은 Label 인코딩 또는 One Hot 인코딩으로 인코딩됩니다. 그러나 대규모 데이터 세트에서 One hot encoding은 속성 수를 늘려 데이터를 고차원 공간으로 변환합니다. 모델은 다음으로 인해 성능이 좋지 않습니다. 차원의 저주.
- 분류 임계값 선택: 데이터에 레이블이 지정되지 않은 경우 데이터 세트에 존재하는 이상 항목의 수를 모르기 때문에 모델의 성능을 평가하기 어렵습니다. 데이터 세트에 대한 사전 지식이 있으면 임계값을 더 쉽게 결정할 수 있습니다. 데이터에 비정상적인 샘플 5개 중 10개가 있다고 가정해 보겠습니다. 따라서 50 백분위수 점수에서 임계값을 선택할 수 있습니다.
- 공개 데이터세트: 대부분의 감사 데이터 세트는 회사에 속하고 민감한 개인 정보를 포함하기 때문에 기밀입니다. 기밀성 문제를 완화하는 한 가지 가능한 방법은 합성 데이터 세트(Vehicle Claims)를 사용하여 훈련하는 것입니다.
이상 감지를 위한 데이터 세트 감사
차량에 대한 보험 청구에는 모델, 브랜드, 가격, 연도 및 연료 유형과 같은 차량 속성에 대한 정보가 포함됩니다. 여기에는 운전자, 생년월일, 성별 및 직업에 대한 정보가 포함됩니다. 또한 청구에는 총 수리 비용에 대한 정보가 포함될 수 있습니다. 이 기사에서 사용된 데이터 세트는 모두 단일 도메인에서 가져온 것이지만 속성 수와 인스턴스 수가 다릅니다.
-
Vehicle Claims 데이터 세트는 250,000개 이상의 행을 포함하는 크기가 크며 범주 속성의 카디널리티는 1171입니다. 크기가 크기 때문에 이 데이터 세트는 차원의 저주에 시달립니다.
- 차량 보험 데이터 세트는 15,420개의 행과 151개의 고유 범주 값이 있는 중간 크기입니다. 이것은 차원의 저주로 고통받는 경향이 적습니다.
- 자동차 보험 데이터 세트는 레이블과 25%의 변칙 샘플이 포함된 소규모이며 비슷한 수의 숫자 및 범주 기능을 포함합니다. 169개의 고유한 범주로 인해 차원의 저주를 받지 않습니다.
범주 속성의 인코딩
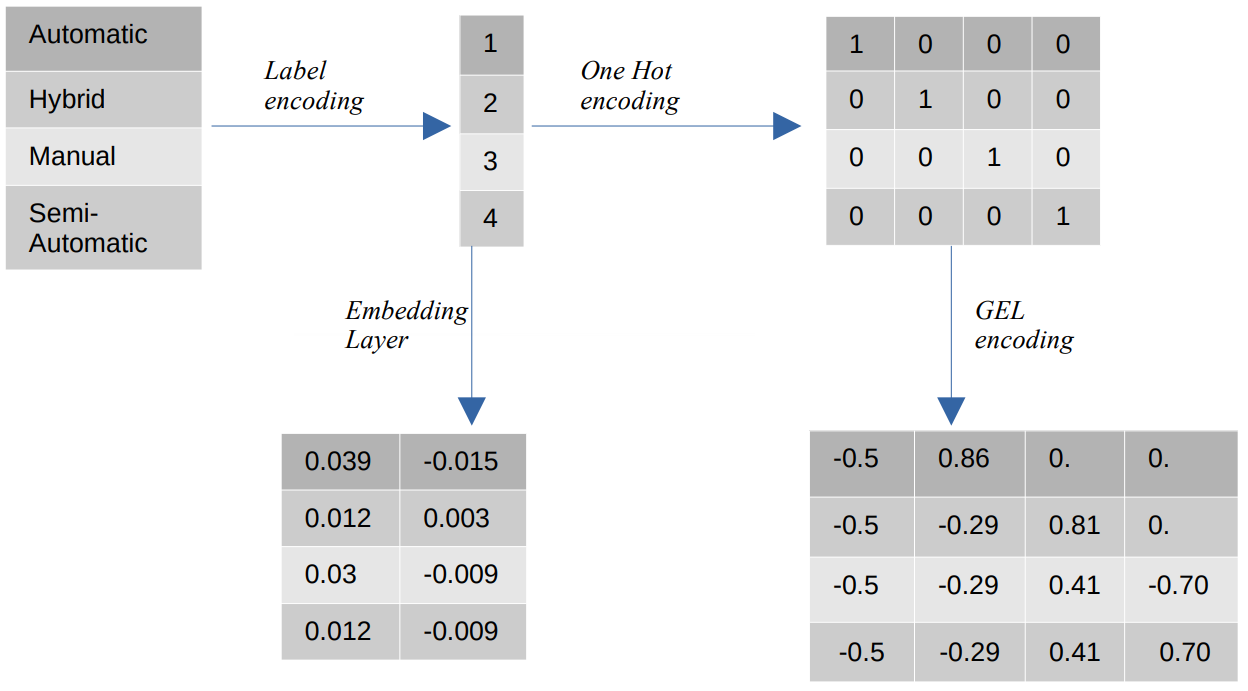
범주 값의 다른 인코딩
- 라벨 인코딩 – 레이블 인코딩에서 범주 값은 1과 범주 수 사이의 숫자 정수 값으로 대체됩니다. 레이블 인코딩은 서수 값에 대해 의도된 방식으로 범주를 나타냅니다. 여전히 기능이 명목상일 때 범주 값이 특정 순서를 따르지 않기 때문에 표현이 올바르지 않습니다.
예를 들어 기능에 자동, 하이브리드, 수동 및 반자동과 같은 범주가 있는 경우 레이블 인코딩은 이러한 값을 {1: 자동, 2: 하이브리드, 3: 수동, 4: 반자동}으로 변환합니다. 이 표현은 범주 값에 대한 정보를 제공하지 않지만 {0: 낮음, 1: 중간, 2: 높음}과 같은 표현은 특성 변수 낮음에 더 낮은 숫자 값이 할당되기 때문에 명확한 표현을 제공합니다. 따라서 레이블 인코딩은 서수 값에 대해 더 좋지만 명목 값에 대해서는 불리합니다. - 하나의 핫 인코딩 – 하나의 핫 인코딩은 각 범주 값을 이진 값으로 구성된 데이터 세트의 고유한 기능으로 변환하는 명목 인코딩 값의 문제를 해결하는 데 사용됩니다. 예를 들어 {1, 2, 3, 4}로 인코딩된 1,0,0,0개의 다른 카테고리의 경우 One Hot 인코딩은 {Automatic: [0,1,0,0], Hybrid: [0,0,1,0]과 같은 새로운 기능을 생성합니다. ,0,0,0,1], 수동: [XNUMX], 반자동: [XNUMX]}.
그런 다음 데이터 세트의 차원은 데이터 세트에 있는 범주의 수에 직접적으로 의존합니다. 결과적으로 One Hot 인코딩은 이 인코딩 방법의 단점인 차원의 저주로 이어질 수 있습니다. - GEL 인코딩 – GEL 인코딩은 감독 및 비지도 학습 방법에 사용할 수 있는 임베딩 기술입니다. One Hot 인코딩의 원칙을 기반으로 하며 One Hot 인코딩을 사용하여 인코딩된 범주 기능의 차원을 줄이는 데 사용할 수 있습니다.
- 임베딩 레이어 - 단어 임베딩은 유사한 단어가 유사한 인코딩을 갖는 간결하고 조밀한 표현을 사용하는 방법을 제공합니다. 임베딩은 훈련 가능한 매개변수인 부동 소수점 값의 조밀한 벡터입니다. 단어 임베딩은 8차원(소규모 데이터세트의 경우)에서 1024차원(대규모 데이터세트의 경우)까지 다양합니다.
더 높은 차원의 임베딩은 단어 사이의 더 자세한 관계를 캡처할 수 있지만 학습하려면 더 많은 데이터가 필요합니다. 임베딩 레이어는 행렬에 있는 각 단어를 특정 크기의 벡터로 변환하는 조회 테이블입니다.
감독되지 않은 이상 탐지 모델
현실 세계에서는 대부분의 경우 데이터에 레이블이 지정되지 않으며 데이터에 레이블을 지정하는 데 비용과 시간이 많이 듭니다. 따라서 평가를 위해 감독되지 않은 모델을 사용할 것입니다.
- SOM - SOM(Self-Organizing Map)은 역전파 학습을 사용하는 대신 뉴런의 가중치가 경쟁적으로 업데이트되는 경쟁 학습 방법입니다. SOM은 각각 입력 벡터와 동일한 크기의 가중치 벡터가 있는 뉴런 맵으로 구성됩니다. 가중치 벡터는 훈련이 시작되기 전에 임의의 가중치로 초기화됩니다. 훈련 중에 각 입력은 거리 메트릭(예: 유클리드 거리)을 기반으로 맵의 뉴런과 비교되고 입력 벡터까지의 거리가 최소인 뉴런인 BMU(Best Matching Unit)에 매핑됩니다.
BMU의 가중치는 입력 벡터의 가중치로 업데이트되고 이웃 뉴런은 이웃 반경(시그마)을 기준으로 업데이트됩니다. 뉴런은 최상의 일치 단위가 되기 위해 서로 경쟁하기 때문에 이 프로세스를 경쟁 학습이라고 합니다. 결국 정상 샘플의 뉴런은 비정상적인 샘플보다 더 가깝습니다. 이상 점수는 입력 샘플과 최적 일치 단위의 가중치 간의 차이인 양자화 오류로 정의됩니다. 양자화 오류가 높을수록 샘플이 이상일 확률이 높다는 것을 나타냅니다. - DAGMM - DAGMM(Deep Autoencoding Gaussian Mixture Model)은 확률이 낮은 영역에 이상이 있다고 가정하는 밀도 추정 방법입니다. 네트워크는 오토인코더를 사용하여 데이터를 더 낮은 차원으로 투영하는 데 사용되는 압축 네트워크와 가우시안 혼합 모델의 매개변수를 추정하는 데 사용되는 추정 네트워크의 두 부분으로 나뉩니다. DAGMM은 k개 수의 가우스 혼합을 추정합니다. 여기서 k는 1에서 N(데이터 포인트 수) 사이의 임의의 수일 수 있으며 일반 포인트가 고밀도 영역에 있다고 가정합니다. 가우시안 혼합은 비정상 샘플보다 정상 점에서 더 높습니다. 이상 점수는 샘플의 예상 에너지로 정의됩니다.
- RSRAE - 감독되지 않은 이상 탐지를 위한 강력한 표면 복구 계층은 먼저 오토인코더를 사용하여 데이터를 더 낮은 차원으로 투영하는 재구성 오류 방법입니다. 그런 다음 잠재 표현은 이상치에 강한 선형 부분 공간에 직교 투영됩니다. 그런 다음 디코더는 선형 부분 공간의 출력을 재구성합니다. 이 방법에서 재구성 오류가 높을수록 샘플이 이상일 확률이 높아집니다.
- SOM-DAGMM- SOM(Self-Organizing Map) – DAGMM(Deep Autoencoding Gaussian Mixture Model)도 밀도 추정 모델입니다. DAGMM과 마찬가지로 정상 데이터 포인트의 확률 분포도 추정하고 학습된 분포에서 샘플링될 확률이 낮은 데이터 포인트를 이상으로 분류합니다. SOM-DAGMM과 DAGMM의 주요 차이점은 SOM-DAGMM에는 입력 샘플에 대한 SOM의 정규화된 좌표가 포함되어 DAGMM의 경우 누락된 토폴로지 정보를 추정 네트워크에 제공한다는 것입니다. 이상 점수는 샘플의 예상 에너지로 정의되고 낮은 에너지는 샘플이 이상일 확률이 높다는 점에서 DAGMM과도 유사합니다.
다음으로 범주형 속성을 처리하는 문제를 다룰 것입니다.
인코딩 범주 속성이 모델에 어떤 영향을 줍니까?
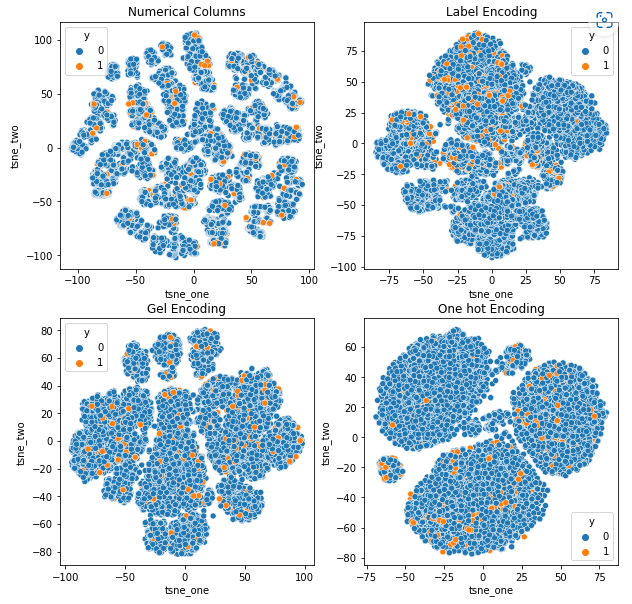
다양한 인코딩이 데이터세트에 미치는 영향을 이해하기 위해 t-SNE를 사용하여 다양한 인코딩에 대한 데이터의 저차원 표현을 시각화합니다. t-SNE는 고차원 데이터를 저차원 공간에 투영하여 시각화하기 쉽게 만듭니다. t-SNE 시각화와 동일한 데이터 세트의 서로 다른 인코딩의 수치 결과를 비교함으로써 데이터 세트에 대한 인코딩의 영향에 대한 결과 표현 및 이해에서 차이가 관찰됩니다.
자동차 보험 데이터 세트의 t-SNE 표현
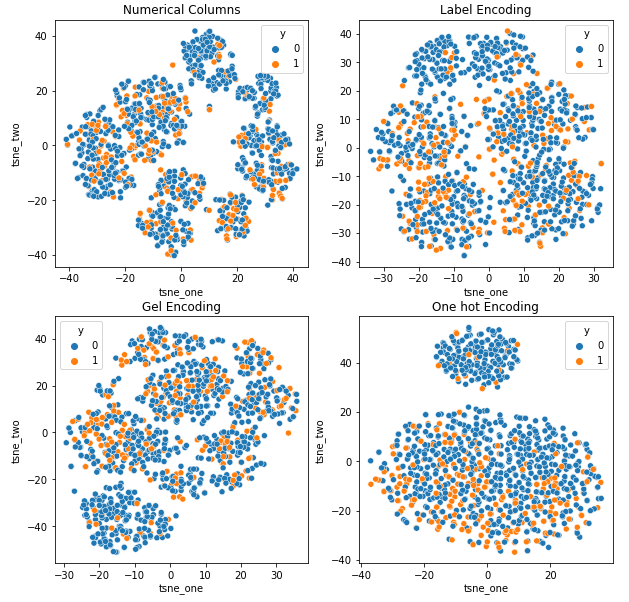
차량 보험 데이터 세트의 t-SNE 표현
-
자동차 보험 데이터 세트보다 행 수가 많기 때문에 데이터가 서로 더 가깝습니다. One Hot 인코딩에서 차원이 증가함에 따라 분리하기 어려워집니다.
-
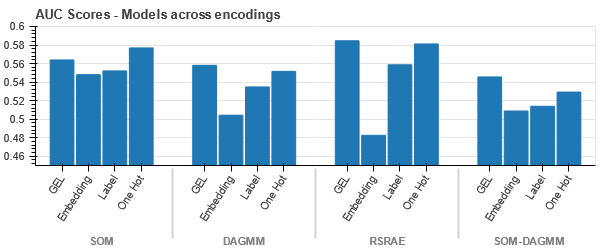
GEL 인코딩은 DAGMM을 제외한 모든 경우에 One Hot 인코딩보다 낫습니다.
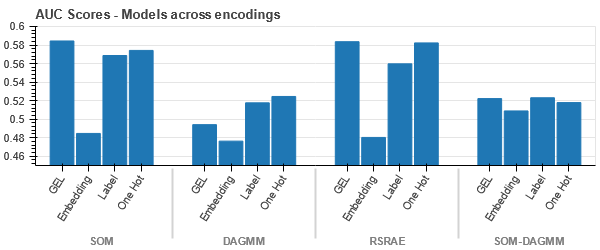
차량 클레임 데이터 세트의 t-SNE 표현
-
데이터는 모든 경우에 긴밀하게 연결되어 있어 차원이 높아져 분리하기가 어렵습니다. 이는 차원 증가로 인해 모델 성능이 저하되는 이유 중 하나입니다.
- SOM은 이 데이터 세트에 대한 다른 모든 모델보다 성능이 뛰어납니다. 그래도 임베딩 레이어는 대부분의 경우에 더 적합하므로 인코딩의 대안이 됩니다. 범주형 속성 이상 감지를 위해.
결론
이 문서에서는 감사 데이터, 이상 탐지 및 범주 인코딩에 대한 간략한 개요를 제공합니다. 감사 데이터에서 범주 속성을 처리하는 것이 어렵다는 점을 이해하는 것이 중요합니다. 속성 인코딩이 모델에 미치는 영향을 이해함으로써 데이터 세트에서 이상 감지 정확도를 향상시킬 수 있습니다. 이 기사의 주요 내용은 다음과 같습니다.
- 데이터 크기가 증가함에 따라 One Hot 인코딩이 적합하지 않기 때문에 GEL 인코딩 및 Embedding 레이어와 같은 범주 속성에 대한 대체 인코딩 방법을 사용하는 것이 중요합니다.
- 하나의 모델이 모든 데이터 세트에 대해 작동하지 않습니다. 표 형식 데이터 세트의 경우 도메인 지식이 매우 중요합니다.
- 인코딩 방법의 선택은 모델 선택에 따라 다릅니다.
모델 평가를 위한 코드는 다음에서 사용할 수 있습니다. GitHub의.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/

