គំរូភាសាធំ (LLMs) ជាទូទៅត្រូវបានបណ្តុះបណ្តាលលើសំណុំទិន្នន័យដែលមានជាសាធារណៈធំៗ ដែលមានលក្ខណៈមិនច្បាស់លាស់នៃដែន។ ឧទាហរណ៍, ឡាម៉ារបស់មេតា ម៉ូដែលត្រូវបានបណ្តុះបណ្តាលលើសំណុំទិន្នន័យដូចជា CommonCrawl, C4, វិគីភីឌា, និង ArXiv. សំណុំទិន្នន័យទាំងនេះគ្របដណ្តប់លើប្រធានបទ និងដែនយ៉ាងទូលំទូលាយ។ ទោះបីជាគំរូលទ្ធផលផ្តល់លទ្ធផលល្អអស្ចារ្យសម្រាប់កិច្ចការទូទៅ ដូចជាការបង្កើតអត្ថបទ និងការទទួលស្គាល់អង្គភាពក៏ដោយ វាមានភស្តុតាងដែលថាគំរូដែលបានបណ្តុះបណ្តាលជាមួយសំណុំទិន្នន័យជាក់លាក់នៃដែនអាចធ្វើឱ្យប្រសើរឡើងបន្ថែមទៀតនូវការអនុវត្ត LLM ។ ឧទាហរណ៍ ទិន្នន័យបណ្តុះបណ្តាលដែលប្រើសម្រាប់ BloombergGPT គឺ 51% ឯកសារជាក់លាក់នៃដែន រួមទាំងព័ត៌មានហិរញ្ញវត្ថុ ឯកសារ និងសម្ភារៈហិរញ្ញវត្ថុផ្សេងទៀត។ លទ្ធផល LLM មានប្រសិទ្ធភាពជាង LLMs ដែលបានទទួលការបណ្តុះបណ្តាលលើសំណុំទិន្នន័យដែលមិនមែនជាដែនជាក់លាក់ នៅពេលសាកល្បងលើកិច្ចការជាក់លាក់ផ្នែកហិរញ្ញវត្ថុ។ អ្នកនិពន្ធនៃ BloombergGPT បានសន្និដ្ឋានថាគំរូរបស់ពួកគេដំណើរការជាងម៉ូដែលផ្សេងទៀតទាំងអស់ដែលបានសាកល្បងសម្រាប់កិច្ចការហិរញ្ញវត្ថុចំនួនបួនក្នុងចំណោមប្រាំ។ គំរូនេះបានផ្តល់នូវការអនុវត្តកាន់តែប្រសើរឡើងនៅពេលដែលបានសាកល្បងសម្រាប់កិច្ចការហិរញ្ញវត្ថុផ្ទៃក្នុងរបស់ Bloomberg ដោយរឹមធំទូលាយ—រហូតដល់ 60 ពិន្ទុប្រសើរជាង (ក្នុងចំណោម 100)។ ទោះបីជាអ្នកអាចស្វែងយល់បន្ថែមអំពីលទ្ធផលវាយតម្លៃដ៏ទូលំទូលាយនៅក្នុង ក្រដាសគំរូខាងក្រោមដែលចាប់យកពី BloombergGPT ក្រដាសអាចផ្តល់ឱ្យអ្នកនូវទិដ្ឋភាពនៃអត្ថប្រយោជន៍នៃការបណ្តុះបណ្តាល LLMs ដោយប្រើទិន្នន័យជាក់លាក់នៃដែនហិរញ្ញវត្ថុ។ ដូចដែលបានបង្ហាញក្នុងឧទាហរណ៍ គំរូ BloombergGPT បានផ្តល់ចម្លើយត្រឹមត្រូវ ខណៈពេលដែលម៉ូដែលដែលមិនមែនជាដែនជាក់លាក់ផ្សេងទៀតមានបញ្ហា៖
ប្រកាសនេះផ្តល់នូវការណែនាំអំពីការបណ្តុះបណ្តាល LLMs ជាពិសេសសម្រាប់ដែនហិរញ្ញវត្ថុ។ យើងគ្របដណ្តប់លើផ្នែកសំខាន់ៗដូចខាងក្រោមៈ
- ការប្រមូលទិន្នន័យ និងការរៀបចំ - ការណែនាំអំពីប្រភព និងការរៀបចំទិន្នន័យហិរញ្ញវត្ថុដែលពាក់ព័ន្ធសម្រាប់ការបណ្តុះបណ្តាលគំរូប្រកបដោយប្រសិទ្ធភាព
- ការហ្វឹកហាត់មុនជាបន្ត ធៀបនឹងការកែតម្រូវ - ពេលណាត្រូវប្រើបច្ចេកទេសនីមួយៗដើម្បីបង្កើនប្រសិទ្ធភាពប្រតិបត្តិការ LLM របស់អ្នក។
- ការបណ្តុះបណ្តាលបន្តប្រកបដោយប្រសិទ្ធភាព - យុទ្ធសាស្រ្តដើម្បីសម្រួលដំណើរការបណ្តុះបណ្តាលមុនបន្ត សន្សំពេលវេលា និងធនធាន
ប្រកាសនេះនាំមកនូវអ្នកជំនាញនៃក្រុមស្រាវជ្រាវវិទ្យាសាស្រ្តដែលបានអនុវត្តនៅក្នុង Amazon Finance Technology និងក្រុមឯកទេស AWS Worldwide សម្រាប់ឧស្សាហកម្មហិរញ្ញវត្ថុសកល។ ខ្លឹមសារខ្លះគឺផ្អែកលើក្រដាស ការបណ្តុះបណ្តាលជាបន្តប្រកបដោយប្រសិទ្ធភាពសម្រាប់ការកសាងគំរូភាសាធំៗជាក់លាក់នៃដែន.
ការប្រមូល និងរៀបចំទិន្នន័យហិរញ្ញវត្ថុ
Domain តម្រូវការបណ្តុះបណ្តាលមុនបន្តបន្ទាប់ ជាសំណុំទិន្នន័យជាក់លាក់នៃដែនខ្នាតធំ គុណភាពខ្ពស់ និងគុណភាពខ្ពស់។ ខាងក្រោមនេះជាជំហានចម្បងសម្រាប់ការរៀបចំសំណុំទិន្នន័យដែន៖
- កំណត់ប្រភពទិន្នន័យ - ប្រភពទិន្នន័យសក្តានុពលសម្រាប់ domain corpus រួមមាន គេហទំព័របើកចំហ វិគីភីឌា សៀវភៅ ប្រព័ន្ធផ្សព្វផ្សាយសង្គម និងឯកសារខាងក្នុង។
- តម្រងទិន្នន័យដែន - ដោយសារតែគោលដៅចុងក្រោយគឺដើម្បីរៀបចំ domain corpus អ្នកប្រហែលជាត្រូវអនុវត្តជំហានបន្ថែមដើម្បីច្រោះយកគំរូដែលមិនពាក់ព័ន្ធទៅនឹងដែនគោលដៅ។ នេះកាត់បន្ថយ corpus ដែលគ្មានប្រយោជន៍សម្រាប់ការបន្តការបណ្តុះបណ្តាលមុន និងកាត់បន្ថយការចំណាយលើការបណ្តុះបណ្តាល។
- កំពុងដំណើរការ - អ្នកអាចពិចារណានូវជំហាននៃដំណើរការមុនជាបន្តបន្ទាប់ ដើម្បីបង្កើនគុណភាពទិន្នន័យ និងប្រសិទ្ធភាពនៃការបណ្តុះបណ្តាល។ ជាឧទាហរណ៍ ប្រភពទិន្នន័យមួយចំនួនអាចមានលេខសំងាត់ដែលមានសំលេងរំខាន។ ការដកស្ទួនត្រូវបានចាត់ទុកថាជាជំហានដ៏មានប្រយោជន៍មួយ ដើម្បីបង្កើនគុណភាពទិន្នន័យ និងកាត់បន្ថយការចំណាយលើការបណ្តុះបណ្តាល។
ដើម្បីបង្កើត LLMs ហិរញ្ញវត្ថុ អ្នកអាចប្រើប្រភពទិន្នន័យសំខាន់ពីរ៖ News CommonCrawl និងឯកសារ SEC ។ ឯកសារ SEC គឺជារបាយការណ៍ហិរញ្ញវត្ថុ ឬឯកសារផ្លូវការផ្សេងទៀតដែលដាក់ជូនគណៈកម្មការមូលបត្រអាមេរិក (SEC)។ ក្រុមហ៊ុនដែលចុះបញ្ជីជាសាធារណៈតម្រូវឱ្យដាក់ឯកសារផ្សេងៗជាប្រចាំ។ នេះបង្កើតឯកសារមួយចំនួនធំក្នុងរយៈពេលជាច្រើនឆ្នាំ។ News CommonCrawl គឺជាសំណុំទិន្នន័យដែលចេញផ្សាយដោយ CommonCrawl ក្នុងឆ្នាំ 2016។ វាមានអត្ថបទព័ត៌មានពីគេហទំព័រព័ត៌មានជុំវិញពិភពលោក។
News CommonCrawl មាននៅលើ សេវាកម្មផ្ទុកសាមញ្ញរបស់ក្រុមហ៊ុន Amazon (Amazon S3) នៅក្នុង commoncrawl ដាក់ធុងនៅ crawl-data/CC-NEWS/. អ្នកអាចទទួលបានបញ្ជីឯកសារដោយប្រើ ចំណុចប្រទាក់បន្ទាត់ពាក្យបញ្ជា AWS (AWS CLI) និងពាក្យបញ្ជាខាងក្រោម៖
In ការបណ្តុះបណ្តាលជាបន្តប្រកបដោយប្រសិទ្ធភាពសម្រាប់ការកសាងគំរូភាសាធំៗជាក់លាក់នៃដែនអ្នកនិពន្ធប្រើ URL និងវិធីសាស្រ្តផ្អែកលើពាក្យគន្លឹះដើម្បីត្រងអត្ថបទព័ត៌មានហិរញ្ញវត្ថុពីព័ត៌មានទូទៅ។ ជាពិសេស អ្នកនិពន្ធរក្សាបញ្ជីនៃព្រឹត្តិបត្រព័ត៌មានហិរញ្ញវត្ថុសំខាន់ៗ និងសំណុំនៃពាក្យគន្លឹះទាក់ទងនឹងព័ត៌មានហិរញ្ញវត្ថុ។ យើងកំណត់អត្តសញ្ញាណអត្ថបទជាព័ត៌មានហិរញ្ញវត្ថុ ប្រសិនបើវាមកពីបណ្តាញព័ត៌មានហិរញ្ញវត្ថុ ឬពាក្យគន្លឹះណាមួយដែលបង្ហាញនៅក្នុង URL ។ វិធីសាស្រ្តដ៏សាមញ្ញ ប៉ុន្តែមានប្រសិទ្ធភាពនេះ អាចឱ្យអ្នកកំណត់អត្តសញ្ញាណព័ត៌មានហិរញ្ញវត្ថុពីមិនត្រឹមតែបណ្តាញព័ត៌មានហិរញ្ញវត្ថុប៉ុណ្ណោះទេ ប៉ុន្តែថែមទាំងផ្នែកហិរញ្ញវត្ថុនៃបណ្តាញព័ត៌មានទូទៅផងដែរ។
ឯកសារ SEC អាចរកបានតាមអ៊ីនធឺណិតតាមរយៈមូលដ្ឋានទិន្នន័យ EDGAR (Electronic Data Gathering, Analysis, and Retrieval) របស់ SEC ដែលផ្តល់ការចូលប្រើទិន្នន័យបើកចំហ។ អ្នកអាចកោសឯកសារពី EDGAR ដោយផ្ទាល់ ឬប្រើ APIs នៅក្នុង ក្រុមហ៊ុន Amazon SageMaker ជាមួយនឹងបន្ទាត់មួយចំនួននៃកូដ សម្រាប់រយៈពេលណាមួយ និងសម្រាប់ចំនួនដ៏ច្រើននៃសញ្ញាធីក (ឧទាហរណ៍ SEC បានកំណត់អត្តសញ្ញាណ)។ ដើម្បីស្វែងយល់បន្ថែម សូមមើល ការទាញយកឯកសារ SEC.
តារាងខាងក្រោមសង្ខេបព័ត៌មានលម្អិតសំខាន់ៗនៃប្រភពទិន្នន័យទាំងពីរ។
| . | ព័ត៌មាន CommonCrawl | SEC ការដាក់ពាក្យ |
| គ្របដណ្តប់ | 2016-2022 | 1993-2022 |
| ទំហំ | 25.8 ពាន់លានពាក្យ | 5.1 ពាន់លានពាក្យ |
អ្នកនិពន្ធឆ្លងកាត់ជំហានដំណើរការបន្ថែមមួយចំនួន មុនពេលទិន្នន័យត្រូវបានបញ្ចូលទៅក្នុងក្បួនដោះស្រាយការបណ្តុះបណ្តាល។ ជាដំបូង យើងសង្កេតឃើញថាឯកសារ SEC មានអត្ថបទមិនច្បាស់ដោយសារតែការដកចេញតារាង និងតួលេខ ដូច្នេះអ្នកនិពន្ធដកចេញប្រយោគខ្លីៗដែលត្រូវបានចាត់ទុកថាជាតារាង ឬស្លាកលេខ។ ទីពីរ យើងអនុវត្តក្បួនដោះស្រាយការបំប្លែងការបំប្លែងអត្ថបទនិងឯកសារថ្មី។ សម្រាប់ឯកសារ SEC យើងស្ទួននៅកម្រិតផ្នែកជំនួសឱ្យកម្រិតឯកសារ។ ជាចុងក្រោយ យើងបង្រួបបង្រួមឯកសារទៅជាខ្សែវែង ធ្វើសញ្ញាសម្ងាត់វា និងបំបែកនិមិត្តសញ្ញាទៅជាបំណែកនៃប្រវែងបញ្ចូលអតិបរមាដែលគាំទ្រដោយគំរូដែលត្រូវបណ្តុះបណ្តាល។ នេះធ្វើអោយប្រសើរឡើងនូវដំណើរការនៃវគ្គបណ្តុះបណ្តាលមុនបន្ត និងកាត់បន្ថយការចំណាយលើការបណ្តុះបណ្តាល។
ការហ្វឹកហាត់មុនជាបន្ត ធៀបនឹងការកែតម្រូវ
LLMs ដែលអាចប្រើបានភាគច្រើនគឺជាគោលបំណងទូទៅ និងខ្វះសមត្ថភាពជាក់លាក់នៃដែន។ Domain LLMs បានបង្ហាញពីដំណើរការគួរឱ្យកត់សម្គាល់នៅក្នុងផ្នែកវេជ្ជសាស្រ្ត ហិរញ្ញវត្ថុ ឬផ្នែកវិទ្យាសាស្ត្រ។ សម្រាប់ LLM ដើម្បីទទួលបានចំនេះដឹងជាក់លាក់នៃដែន មានវិធីបួនយ៉ាង៖ ការបណ្តុះបណ្តាលពីដំបូង ការបណ្តុះបណ្តាលមុនបន្ត ការកែសម្រួលការណែនាំលើភារកិច្ចដែន និងការទាញយកជំនាន់បន្ថែម (RAG) ។
នៅក្នុងគំរូប្រពៃណី ការលៃតម្រូវការផាកពិន័យជាធម្មតាត្រូវបានប្រើដើម្បីបង្កើតគំរូភារកិច្ចជាក់លាក់សម្រាប់ដែន។ នេះមានន័យថារក្សាបាននូវគំរូជាច្រើនសម្រាប់កិច្ចការជាច្រើនដូចជា ការទាញយកអង្គភាព ការដាក់ចំណាត់ថ្នាក់ដោយចេតនា ការវិភាគមនោសញ្ចេតនា ឬការឆ្លើយសំណួរ។ ជាមួយនឹងការមកដល់នៃ LLMs តម្រូវការដើម្បីរក្សាគំរូដាច់ដោយឡែកបានក្លាយទៅជាលែងប្រើហើយដោយប្រើបច្ចេកទេសដូចជាការរៀនក្នុងបរិបទ ឬការជម្រុញ។ វារក្សាទុកកិច្ចខិតខំប្រឹងប្រែងដែលត្រូវការដើម្បីរក្សាគំរូគំរូសម្រាប់កិច្ចការដែលពាក់ព័ន្ធ ប៉ុន្តែខុសគ្នា។
ដោយវិចារណញាណ អ្នកអាចបណ្តុះបណ្តាល LLMs ពីដំបូងជាមួយនឹងទិន្នន័យជាក់លាក់នៃដែន។ ទោះបីជាការងារភាគច្រើនដើម្បីបង្កើត domain LLMs បានផ្តោតលើការបណ្តុះបណ្តាលតាំងពីដំបូងក៏ដោយ វាពិតជាមានតម្លៃថ្លៃណាស់។ ឧទាហរណ៍តម្លៃម៉ូដែល GPT-4 ជាង $ 100 លាន ដើម្បីហ្វឹកហាត់។ ម៉ូដែលទាំងនេះត្រូវបានបណ្តុះបណ្តាលលើការរួមបញ្ចូលគ្នានៃទិន្នន័យដែនបើកចំហ និងទិន្នន័យដែន។ ការបណ្តុះបណ្តាលជាមុនជាបន្តបន្ទាប់អាចជួយឱ្យម៉ូដែលទទួលបានចំណេះដឹងជាក់លាក់នៃដែនដោយមិនចាំបាច់ចំណាយលើការបណ្តុះបណ្តាលជាមុនពីដំបូងឡើយ ពីព្រោះអ្នកបណ្តុះបណ្តាលជាមុននូវដែនបើកចំហ LLM ដែលមានស្រាប់លើតែទិន្នន័យដែនប៉ុណ្ណោះ។
ជាមួយនឹងការកែតម្រូវការណែនាំលើកិច្ចការមួយ អ្នកមិនអាចធ្វើឱ្យគំរូទទួលបានចំណេះដឹងអំពីដែនបានទេ ពីព្រោះ LLM ទទួលបានតែព័ត៌មានដែនដែលមាននៅក្នុងសំណុំទិន្នន័យកែតម្រូវការណែនាំប៉ុណ្ណោះ។ លុះត្រាតែសំណុំទិន្នន័យធំណាស់សម្រាប់ការកែសម្រួលការណែនាំត្រូវបានប្រើ វាមិនគ្រប់គ្រាន់ទេក្នុងការទទួលបានចំណេះដឹងអំពីដែន។ ការស្វែងរកសំណុំទិន្នន័យការណែនាំដែលមានគុណភាពខ្ពស់ជាធម្មតាគឺជាបញ្ហាប្រឈម ហើយជាហេតុផលក្នុងការប្រើ LLMs ជាដំបូង។ ដូចគ្នានេះផងដែរ ការកែតម្រូវការណែនាំលើកិច្ចការមួយអាចប៉ះពាល់ដល់ការអនុវត្តលើកិច្ចការផ្សេងទៀត (ដូចដែលបានឃើញនៅក្នុង ក្រដាសនេះ) ទោះជាយ៉ាងណាក៏ដោយ ការកែសម្រួលការណែនាំគឺមានប្រសិទ្ធភាពជាងជម្រើសណាមួយមុនការបណ្តុះបណ្តាល។
តួរលេខខាងក្រោមប្រៀបធៀបការកែតម្រូវជាក់លាក់នៃកិច្ចការប្រពៃណី។ ធៀបនឹងគំរូសិក្សាក្នុងបរិបទជាមួយ LLMs។
 RAG គឺជាមធ្យោបាយដ៏មានប្រសិទ្ធភាពបំផុតក្នុងការដឹកនាំ LLM ដើម្បីបង្កើតការឆ្លើយតបដែលមានមូលដ្ឋាននៅក្នុងដែន។ ទោះបីជាវាអាចណែនាំគំរូដើម្បីបង្កើតការឆ្លើយតបដោយផ្តល់នូវការពិតពីដែនជាព័ត៌មានជំនួយក៏ដោយ វាមិនទទួលបានភាសាជាក់លាក់នៃដែនទេ ដោយសារ LLM នៅតែពឹងផ្អែកលើរចនាប័ទ្មភាសាមិនមែនដែនដើម្បីបង្កើតការឆ្លើយតប។
RAG គឺជាមធ្យោបាយដ៏មានប្រសិទ្ធភាពបំផុតក្នុងការដឹកនាំ LLM ដើម្បីបង្កើតការឆ្លើយតបដែលមានមូលដ្ឋាននៅក្នុងដែន។ ទោះបីជាវាអាចណែនាំគំរូដើម្បីបង្កើតការឆ្លើយតបដោយផ្តល់នូវការពិតពីដែនជាព័ត៌មានជំនួយក៏ដោយ វាមិនទទួលបានភាសាជាក់លាក់នៃដែនទេ ដោយសារ LLM នៅតែពឹងផ្អែកលើរចនាប័ទ្មភាសាមិនមែនដែនដើម្បីបង្កើតការឆ្លើយតប។
ការបណ្ដុះបណ្ដាលមុនជាបន្តគឺជាមូលដ្ឋានកណ្តាលរវាងការបណ្តុះបណ្តាលមុន និងការណែនាំអំពីការកែតម្រូវក្នុងលក្ខខណ្ឌនៃការចំណាយ ខណៈពេលដែលជាជម្រើសដ៏រឹងមាំក្នុងការទទួលបានចំណេះដឹង និងរចនាប័ទ្មជាក់លាក់នៃដែន។ វាអាចផ្តល់នូវគំរូទូទៅដែលការកែសម្រួលការណែនាំបន្ថែមលើទិន្នន័យការណែនាំមានកំណត់អាចត្រូវបានអនុវត្ត។ ការបណ្ដុះបណ្ដាលជាមុនជាបន្តបន្ទាប់អាចជាយុទ្ធសាស្រ្តដ៏មានប្រសិទ្ធភាពមួយសម្រាប់ដែនឯកទេស ដែលសំណុំនៃកិច្ចការខាងក្រោមមានទំហំធំ ឬមិនស្គាល់ ហើយទិន្នន័យការកែសម្រួលការណែនាំដែលមានស្លាកត្រូវបានកំណត់។ នៅក្នុងសេណារីយ៉ូផ្សេងទៀត ការកែតម្រូវការណែនាំ ឬ RAG ប្រហែលជាសមរម្យជាង។
ដើម្បីស្វែងយល់បន្ថែមអំពីការកែតម្រូវ RAG និងការបណ្តុះបណ្តាលគំរូ សូមយោងទៅ កែសំរួលគំរូគ្រឹះ, ទាញយកជំនាន់ដែលបានបង្កើន (RAG)និង បណ្តុះបណ្តាលគំរូជាមួយ Amazon SageMakerរៀងៗខ្លួន។ សម្រាប់ការប្រកាសនេះ យើងផ្តោតលើការបណ្តុះបណ្តាលបន្តប្រកបដោយប្រសិទ្ធភាព។
វិធីសាស្រ្តនៃការបណ្តុះបណ្តាលមុនបន្តប្រកបដោយប្រសិទ្ធភាព
ការបណ្តុះបណ្តាលមុនវគ្គបន្តមានវិធីសាស្រ្តដូចខាងក្រោមៈ
- Domain-Adaptive Continual Pre-training (DACP) - នៅក្នុងក្រដាស ការបណ្តុះបណ្តាលជាបន្តប្រកបដោយប្រសិទ្ធភាពសម្រាប់ការកសាងគំរូភាសាធំៗជាក់លាក់នៃដែនអ្នកនិពន្ធបន្តបង្វឹកសំណុំគំរូភាសា Pythia ជាមុននៅលើផ្នែកហិរញ្ញវត្ថុ ដើម្បីសម្របវាទៅនឹងដែនហិរញ្ញវត្ថុ។ គោលបំណងគឺដើម្បីបង្កើត LLMs ហិរញ្ញវត្ថុដោយផ្តល់ទិន្នន័យពីដែនហិរញ្ញវត្ថុទាំងមូលទៅជាគំរូប្រភពបើកចំហ។ ដោយសារតែអង្គភាពបណ្តុះបណ្តាលមានសំណុំទិន្នន័យដែលបានរៀបចំទាំងអស់នៅក្នុងដែន គំរូលទ្ធផលគួរតែទទួលបានចំណេះដឹងជាក់លាក់ផ្នែកហិរញ្ញវត្ថុ ដោយហេតុនេះក្លាយជាគំរូដែលអាចប្រើប្រាស់បានសម្រាប់កិច្ចការហិរញ្ញវត្ថុផ្សេងៗ។ លទ្ធផលនេះនៅក្នុងម៉ូដែល FinPythia ។
- កិច្ចការ-ការបណ្តុះបណ្តាលបន្តបន្ទាប់បន្សំ (TACP) - អ្នកនិពន្ធបណ្តុះបណ្តាលគំរូបន្ថែមលើទិន្នន័យកិច្ចការដែលមានស្លាក និងមិនមានស្លាក ដើម្បីសម្រួលពួកគេសម្រាប់កិច្ចការជាក់លាក់។ ក្នុងកាលៈទេសៈខ្លះ អ្នកអភិវឌ្ឍន៍អាចចូលចិត្តម៉ូដែលដែលផ្តល់នូវដំណើរការប្រសើរជាងមុនលើក្រុមនៃកិច្ចការក្នុងដែន ជាជាងគំរូដែនទូទៅ។ TACP ត្រូវបានរចនាឡើងជាការបណ្តុះបណ្តាលជាបន្តបន្ទាប់ក្នុងគោលបំណងលើកកម្ពស់ការអនុវត្តលើកិច្ចការដែលបានកំណត់គោលដៅ ដោយមិនចាំបាច់មានទិន្នន័យដែលមានស្លាក។ ជាពិសេស អ្នកនិពន្ធបន្តបង្វឹកគំរូប្រភពបើកចំហជាមុននៅលើនិមិត្តសញ្ញាកិច្ចការ (ដោយគ្មានស្លាក)។ ការកំណត់ចម្បងនៃ TACP គឺនៅក្នុងការសាងសង់ LLMs ជាក់លាក់នៃភារកិច្ចជំនួសឱ្យ LLMs គ្រឹះ ដោយសារការប្រើប្រាស់ទិន្នន័យកិច្ចការដែលមិនមានស្លាកសម្រាប់ការបណ្តុះបណ្តាល។ ទោះបីជា DACP ប្រើអង្គធាតុធំជាងក៏ដោយ ក៏វាមានតម្លៃថ្លៃគួរសម។ ដើម្បីធ្វើឱ្យមានតុល្យភាពរវាងដែនកំណត់ទាំងនេះ អ្នកនិពន្ធស្នើវិធីសាស្រ្តពីរដែលមានគោលបំណងបង្កើត LLMs មូលដ្ឋានជាក់លាក់នៃដែន ខណៈពេលដែលរក្សាបាននូវការអនុវត្តល្អប្រសើរលើកិច្ចការគោលដៅ៖
- កិច្ចការដែលមានប្រសិទ្ធភាព DACP (ETS-DACP) - អ្នកនិពន្ធស្នើឱ្យជ្រើសរើសសំណុំរងនៃសារពាង្គកាយហិរញ្ញវត្ថុដែលមានលក្ខណៈស្រដៀងនឹងទិន្នន័យកិច្ចការដោយប្រើប្រាស់ភាពស្រដៀងគ្នានៃការបង្កប់។ សំណុំរងនេះត្រូវបានប្រើសម្រាប់ការបណ្តុះបណ្តាលមុនបន្ត ដើម្បីធ្វើឱ្យវាកាន់តែមានប្រសិទ្ធភាព។ ជាពិសេស អ្នកនិពន្ធបន្តបណ្តុះបណ្តាលជាមុននូវប្រភពបើកចំហ LLM លើសាកសពតូចមួយដែលស្រង់ចេញពីផ្នែកហិរញ្ញវត្ថុដែលនៅជិតនឹងកិច្ចការគោលដៅក្នុងការចែកចាយ។ នេះអាចជួយកែលម្អការអនុវត្តការងារ ពីព្រោះយើងយកគំរូនេះទៅចែកចាយនិមិត្តសញ្ញាកិច្ចការ បើទោះបីជាទិន្នន័យដែលមានស្លាកមិនត្រូវបានទាមទារក៏ដោយ។
- DACP Task-Agnostic ប្រកបដោយប្រសិទ្ធភាព (ETA-DACP) - អ្នកនិពន្ធស្នើឱ្យប្រើរង្វាស់ដូចជាភាពច្របូកច្របល់ និងប្រភេទសញ្ញាសម្ងាត់ដែលមិនត្រូវការទិន្នន័យកិច្ចការដើម្បីជ្រើសរើសគំរូពីស្ថាប័នហិរញ្ញវត្ថុសម្រាប់ការបណ្តុះបណ្តាលមុនបន្តប្រកបដោយប្រសិទ្ធភាព។ វិធីសាស្រ្តនេះត្រូវបានរចនាឡើងដើម្បីដោះស្រាយជាមួយសេណារីយ៉ូដែលទិន្នន័យកិច្ចការមិនអាចប្រើបាន ឬគំរូដែនដែលអាចប្រើប្រាស់បានច្រើនសម្រាប់ដែនទូលំទូលាយត្រូវបានគេពេញចិត្ត។ អ្នកនិពន្ធអនុម័តវិមាត្រពីរដើម្បីជ្រើសរើសគំរូទិន្នន័យដែលមានសារៈសំខាន់សម្រាប់ការទទួលបានព័ត៌មានដែនពីសំណុំរងនៃទិន្នន័យដែនមុនការបណ្តុះបណ្តាល៖ ភាពថ្មីថ្មោង និងភាពសម្បូរបែប។ ភាពថ្មីថ្មោងដែលវាស់វែងដោយភាពងឿងឆ្ងល់ដែលបានកត់ត្រាដោយគំរូគោលដៅ សំដៅលើព័ត៌មានដែល LLM មិនបានមើលឃើញពីមុន។ ទិន្នន័យដែលមានភាពថ្មីថ្មោងខ្ពស់បង្ហាញពីចំណេះដឹងប្រលោមលោកសម្រាប់ LLM ហើយទិន្នន័យបែបនេះត្រូវបានគេចាត់ទុកថាពិបាករៀនជាង។ នេះធ្វើបច្ចុប្បន្នភាព LLMs ទូទៅជាមួយនឹងចំនេះដឹងដែនដែលពឹងផ្អែកខ្លាំងក្នុងអំឡុងពេលការបណ្តុះបណ្តាលមុនបន្ត។ ម្យ៉ាងវិញទៀត ភាពចម្រុះ ចាប់យកភាពចម្រុះនៃការចែកចាយនៃប្រភេទសញ្ញាសម្ងាត់នៅក្នុង domain corpus ដែលត្រូវបានចងក្រងជាឯកសារដែលមានសារៈប្រយោជន៍ក្នុងការស្រាវជ្រាវនៃការរៀនកម្មវិធីសិក្សាលើគំរូភាសា។
តួលេខខាងក្រោមប្រៀបធៀបឧទាហរណ៍នៃ ETS-DACP (ឆ្វេង) ទល់នឹង ETA-DACP (ស្តាំ)។

យើងទទួលយកគ្រោងការណ៍គំរូចំនួនពីរ ដើម្បីជ្រើសរើសយ៉ាងសកម្មនូវចំណុចទិន្នន័យពីផ្នែកហិរញ្ញវត្ថុដែលបានរៀបចំ៖ គំរូរឹង និងគំរូទន់។ អតីតត្រូវបានធ្វើឡើងដោយការចាត់ថ្នាក់ផ្នែកហិរញ្ញវត្ថុជាលើកដំបូងដោយមាត្រដ្ឋានដែលត្រូវគ្នានិងបន្ទាប់មកជ្រើសរើសគំរូកំពូល-k ដែល k ត្រូវបានកំណត់ទុកជាមុនតាមថវិកាបណ្តុះបណ្តាល។ សម្រាប់ចុងក្រោយ អ្នកនិពន្ធកំណត់ទម្ងន់គំរូសម្រាប់ចំណុចទិន្នន័យនីមួយៗដោយយោងតាមតម្លៃម៉ែត្រ ហើយបន្ទាប់មកយកគំរូពិន្ទុទិន្នន័យ k ដោយចៃដន្យ ដើម្បីបំពេញថវិកាបណ្តុះបណ្តាល។
លទ្ធផលនិងការវិភាគ
អ្នកនិពន្ធវាយតម្លៃលទ្ធផលនៃ LLMs ហិរញ្ញវត្ថុលើអារេនៃកិច្ចការហិរញ្ញវត្ថុ ដើម្បីស៊ើបអង្កេតប្រសិទ្ធភាពនៃការបណ្តុះបណ្តាលមុនបន្ត៖
- ធនាគារឃ្លាហិរញ្ញវត្ថុ - កិច្ចការចាត់ថ្នាក់អារម្មណ៍លើព័ត៌មានហិរញ្ញវត្ថុ។
- FiQA SA - កិច្ចការចាត់ថ្នាក់អារម្មណ៍ផ្អែកលើទិដ្ឋភាពដោយផ្អែកលើព័ត៌មានហិរញ្ញវត្ថុ និងចំណងជើង។
- ចំណងជើង - កិច្ចការចាត់ថ្នាក់ប្រព័ន្ធគោលពីរ ថាតើចំណងជើងនៅលើអង្គភាពហិរញ្ញវត្ថុមានព័ត៌មានជាក់លាក់ដែរឬទេ។
- ណេស។ - កិច្ចការទាញយកអង្គភាពដែលមានឈ្មោះហិរញ្ញវត្ថុដោយផ្អែកលើផ្នែកវាយតម្លៃហានិភ័យឥណទាននៃរបាយការណ៍ SEC ។ ពាក្យនៅក្នុងកិច្ចការនេះត្រូវបានកត់សំគាល់ដោយ PER, LOC, ORG និង MISC ។
ដោយសារតែ LLMs ហិរញ្ញវត្ថុត្រូវបានណែនាំយ៉ាងល្អិតល្អន់ អ្នកនិពន្ធវាយតម្លៃគំរូក្នុងការកំណត់ចំនួន 5 សម្រាប់កិច្ចការនីមួយៗសម្រាប់ជាប្រយោជន៍នៃភាពរឹងមាំ។ ជាមធ្យម FinPythia 6.9B ដំណើរការលើសពី Pythia 6.9B ដោយ 10% លើកិច្ចការចំនួន 1 ដែលបង្ហាញពីប្រសិទ្ធភាពនៃការបណ្តុះបណ្តាលមុនបន្តជាក់លាក់នៃដែន។ សម្រាប់ម៉ូដែល 2B ការកែលម្អគឺមិនសូវស៊ីជម្រៅ ប៉ុន្តែការអនុវត្តនៅតែប្រសើរឡើងជាមធ្យម XNUMX%។
តួលេខខាងក្រោមបង្ហាញពីភាពខុសគ្នានៃការអនុវត្តមុន និងក្រោយ DACP លើម៉ូដែលទាំងពីរ។

តួលេខខាងក្រោមបង្ហាញពីឧទាហរណ៍គុណភាពពីរដែលបង្កើតឡើងដោយ Pythia 6.9B និង FinPythia 6.9B ។ សម្រាប់សំណួរទាក់ទងនឹងហិរញ្ញវត្ថុចំនួនពីរទាក់ទងនឹងអ្នកគ្រប់គ្រងអ្នកវិនិយោគ និងពាក្យហិរញ្ញវត្ថុ Pythia 6.9B មិនយល់ពីពាក្យនេះ ឬស្គាល់ឈ្មោះនោះទេ ចំណែកឯ FinPythia 6.9B បង្កើតចម្លើយលម្អិតយ៉ាងត្រឹមត្រូវ។ គំរូគុណភាពបង្ហាញឱ្យឃើញថា ការបណ្ដុះបណ្ដាលជាមុនជាបន្តបន្ទាប់អាចឱ្យ LLMs ទទួលបានចំណេះដឹងអំពីដែនកំឡុងពេលដំណើរការ។

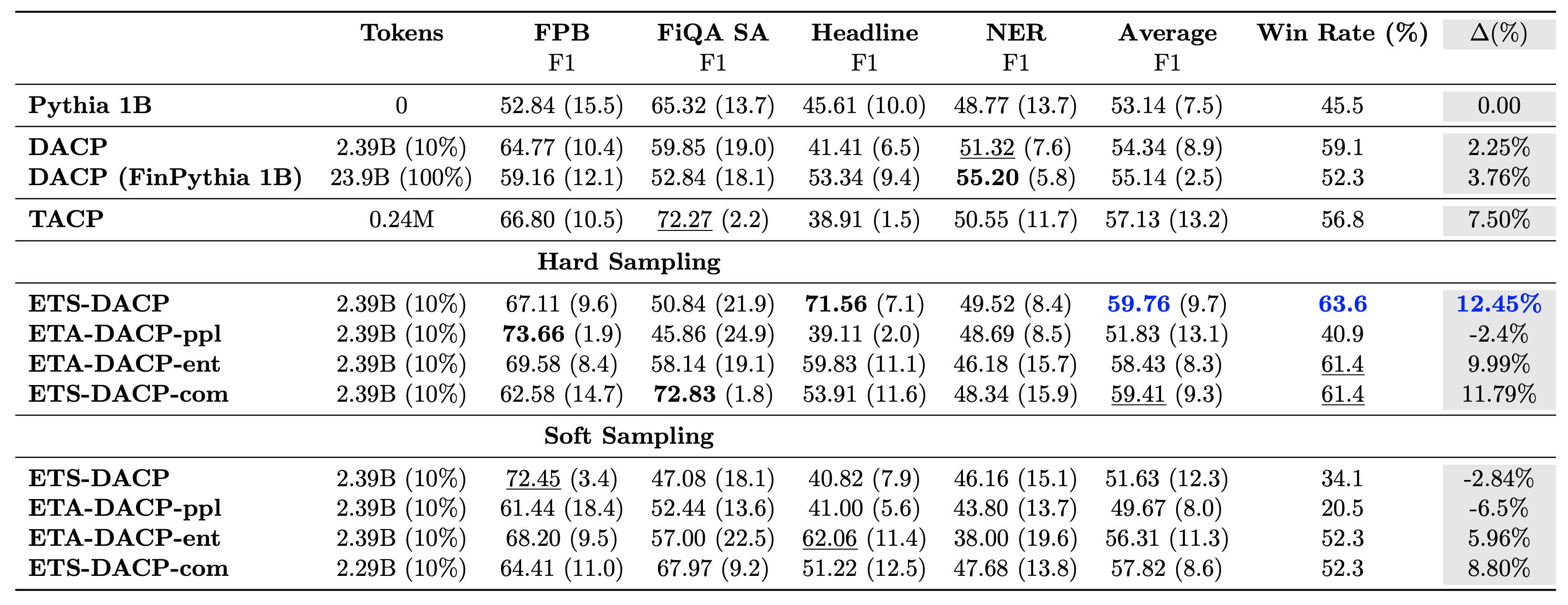
តារាងខាងក្រោមប្រៀបធៀបវិធីសាស្រ្តបន្តការបណ្តុះបណ្តាលប្រកបដោយប្រសិទ្ធភាពផ្សេងៗ។ ETA-DACP-ppl គឺ ETA-DACP ផ្អែកលើភាពច្របូកច្របល់ (ភាពថ្មីថ្មោង) ហើយ ETA-DACP-ent គឺផ្អែកលើ entropy (ភាពចម្រុះ) ។ ETS-DACP-com គឺស្រដៀងនឹង DACP ជាមួយនឹងការជ្រើសរើសទិន្នន័យដោយជាមធ្យមម៉ែត្រទាំងបី។ ខាងក្រោមនេះគឺជាការទាញយកមួយចំនួនពីលទ្ធផល៖
- វិធីសាស្ត្រជ្រើសរើសទិន្នន័យមានប្រសិទ្ធភាព - ពួកគេលើសពីការបណ្តុះបណ្តាលបន្តបន្ទាប់ស្តង់ដារជាមួយនឹងទិន្នន័យបណ្តុះបណ្តាលត្រឹមតែ 10% ប៉ុណ្ណោះ។ ការបណ្តុះបណ្តាលជាបន្តបន្ទាប់ប្រកបដោយប្រសិទ្ធភាព រួមមាន Task-Similar DACP (ETS-DACP), Task-Agnostic DACP ផ្អែកលើ entropy (ESA-DACP-ent) និង Task-Similar DACP ដោយផ្អែកលើរង្វាស់ទាំងបី (ETS-DACP-com) លើសពីស្តង់ដារ DACP ជាមធ្យមបើទោះបីជាការពិតដែលថាពួកគេត្រូវបានបណ្តុះបណ្តាលតែ 10% នៃផ្នែកហិរញ្ញវត្ថុ។
- ការជ្រើសរើសទិន្នន័យ Task-aware ដំណើរការល្អបំផុតស្របតាមការស្រាវជ្រាវគំរូភាសាតូចៗ - ETS-DACP កត់ត្រាដំណើរការជាមធ្យមល្អបំផុតក្នុងចំណោមវិធីសាស្រ្តទាំងអស់ ហើយផ្អែកលើរង្វាស់ទាំងបី កត់ត្រានូវការអនុវត្តការងារល្អបំផុតទីពីរ។ នេះបង្ហាញថាការប្រើប្រាស់ទិន្នន័យកិច្ចការដែលមិនបានដាក់ស្លាកនៅតែជាវិធីសាស្រ្តដ៏មានប្រសិទ្ធភាពក្នុងការជំរុញការអនុវត្តការងារក្នុងករណី LLMs ។
- ការជ្រើសរើសទិន្នន័យដែលមិនជឿលើកិច្ចការគឺជិតទីពីរ - ESA-DACP-ent ធ្វើតាមការអនុវត្តវិធីសាស្រ្តជ្រើសរើសទិន្នន័យដែលដឹងអំពីភារកិច្ច ដោយបញ្ជាក់ថាយើងនៅតែអាចជំរុញការអនុវត្តការងារដោយជ្រើសរើសយ៉ាងសកម្មនូវគំរូដែលមានគុណភាពខ្ពស់ដែលមិនជាប់ទាក់ទងនឹងកិច្ចការជាក់លាក់។ នេះត្រួសត្រាយផ្លូវក្នុងការសាងសង់ LLMs ហិរញ្ញវត្ថុសម្រាប់ដែនទាំងមូល ខណៈពេលដែលសម្រេចបាននូវការអនុវត្តការងារដ៏ប្រសើរ។
សំណួរសំខាន់មួយទាក់ទងនឹងការបន្តបណ្តុះបណ្តាលមុនគឺថាតើវាជះឥទ្ធិពលអវិជ្ជមានដល់ការអនុវត្តលើកិច្ចការដែលមិនមែនជាដែនដែរឬទេ។ អ្នកនិពន្ធក៏បានវាយតម្លៃគំរូដែលបានបណ្តុះបណ្តាលជាបន្តបន្ទាប់លើកិច្ចការទូទៅចំនួនបួនដែលប្រើយ៉ាងទូលំទូលាយ៖ ARC, MMLU, TruthQA និង HellaSwag ដែលវាស់វែងសមត្ថភាពនៃការឆ្លើយសំណួរ ហេតុផល និងការបញ្ចប់។ អ្នកនិពន្ធយល់ឃើញថា ការបណ្តុះបណ្តាលជាបន្តបន្ទាប់មិនប៉ះពាល់យ៉ាងធ្ងន់ធ្ងរដល់ការអនុវត្តដែលមិនមែនដែន។ សម្រាប់ព័ត៌មានលម្អិត សូមមើល ការបណ្តុះបណ្តាលជាបន្តប្រកបដោយប្រសិទ្ធភាពសម្រាប់ការកសាងគំរូភាសាធំៗជាក់លាក់នៃដែន.
សន្និដ្ឋាន
ការបង្ហោះនេះបានផ្តល់នូវការយល់ដឹងអំពីការប្រមូលទិន្នន័យ និងយុទ្ធសាស្រ្តបណ្តុះបណ្តាលមុនបន្តសម្រាប់ការបណ្តុះបណ្តាល LLMs សម្រាប់ដែនហិរញ្ញវត្ថុ។ អ្នកអាចចាប់ផ្តើមបណ្តុះបណ្តាល LLMs ផ្ទាល់ខ្លួនរបស់អ្នកសម្រាប់កិច្ចការហិរញ្ញវត្ថុដោយប្រើ ការបណ្តុះបណ្តាល Amazon SageMaker or ក្រុមហ៊ុន Amazon Bedrock នាពេលបច្ចុប្បន្ននេះ។
អំពីនិពន្ធនេះ
 យ៉ុង ស៊ី គឺជាអ្នកវិទ្យាសាស្ត្រអនុវត្តនៅក្នុង Amazon FinTech ។ គាត់ផ្តោតលើការបង្កើតគំរូភាសាធំៗ និងកម្មវិធី AI ជំនាន់ថ្មីសម្រាប់ហិរញ្ញវត្ថុ។
យ៉ុង ស៊ី គឺជាអ្នកវិទ្យាសាស្ត្រអនុវត្តនៅក្នុង Amazon FinTech ។ គាត់ផ្តោតលើការបង្កើតគំរូភាសាធំៗ និងកម្មវិធី AI ជំនាន់ថ្មីសម្រាប់ហិរញ្ញវត្ថុ។
 Karan Aggarwal គឺជាអ្នកវិទ្យាសាស្ត្រអនុវត្តជាន់ខ្ពស់ជាមួយ Amazon FinTech ដោយផ្តោតលើ Generative AI សម្រាប់ករណីប្រើប្រាស់ហិរញ្ញវត្ថុ។ Karan មានបទពិសោធន៍យ៉ាងទូលំទូលាយក្នុងការវិភាគស៊េរីពេលវេលា និង NLP ដោយមានការចាប់អារម្មណ៍ជាពិសេសក្នុងការរៀនពីទិន្នន័យដែលមានស្លាកមានកំណត់
Karan Aggarwal គឺជាអ្នកវិទ្យាសាស្ត្រអនុវត្តជាន់ខ្ពស់ជាមួយ Amazon FinTech ដោយផ្តោតលើ Generative AI សម្រាប់ករណីប្រើប្រាស់ហិរញ្ញវត្ថុ។ Karan មានបទពិសោធន៍យ៉ាងទូលំទូលាយក្នុងការវិភាគស៊េរីពេលវេលា និង NLP ដោយមានការចាប់អារម្មណ៍ជាពិសេសក្នុងការរៀនពីទិន្នន័យដែលមានស្លាកមានកំណត់
 អៃហ្សាស អាម៉ាដ គឺជាអ្នកគ្រប់គ្រងផ្នែកវិទ្យាសាស្ត្រអនុវត្តនៅ Amazon ជាកន្លែងដែលគាត់ដឹកនាំក្រុមអ្នកវិទ្យាសាស្ត្របង្កើតកម្មវិធីផ្សេងៗនៃ Machine Learning និង Generative AI ក្នុងផ្នែកហិរញ្ញវត្ថុ។ ចំណាប់អារម្មណ៍ស្រាវជ្រាវរបស់គាត់គឺនៅក្នុង NLP, Generative AI, និង LLM Agents ។ គាត់បានទទួលបណ្ឌិតផ្នែកវិស្វកម្មអគ្គិសនីពីសាកលវិទ្យាល័យ Texas A&M ។
អៃហ្សាស អាម៉ាដ គឺជាអ្នកគ្រប់គ្រងផ្នែកវិទ្យាសាស្ត្រអនុវត្តនៅ Amazon ជាកន្លែងដែលគាត់ដឹកនាំក្រុមអ្នកវិទ្យាសាស្ត្របង្កើតកម្មវិធីផ្សេងៗនៃ Machine Learning និង Generative AI ក្នុងផ្នែកហិរញ្ញវត្ថុ។ ចំណាប់អារម្មណ៍ស្រាវជ្រាវរបស់គាត់គឺនៅក្នុង NLP, Generative AI, និង LLM Agents ។ គាត់បានទទួលបណ្ឌិតផ្នែកវិស្វកម្មអគ្គិសនីពីសាកលវិទ្យាល័យ Texas A&M ។
 ឈីងវៃលី គឺជាអ្នកជំនាញផ្នែករៀនម៉ាស៊ីននៅ Amazon Web Services ។ គាត់បានទទួលបណ្ឌិតរបស់គាត់ នៅក្នុងប្រតិបត្តិការស្រាវជ្រាវ បន្ទាប់ពីគាត់បានបំបែកគណនីជំនួយស្រាវជ្រាវរបស់ទីប្រឹក្សារបស់គាត់ ហើយមិនបានប្រគល់រង្វាន់ណូបែលដែលគាត់បានសន្យា។ បច្ចុប្បន្នគាត់ជួយអតិថិជនក្នុងសេវាកម្មហិរញ្ញវត្ថុបង្កើតដំណោះស្រាយការរៀនម៉ាស៊ីននៅលើ AWS ។
ឈីងវៃលី គឺជាអ្នកជំនាញផ្នែករៀនម៉ាស៊ីននៅ Amazon Web Services ។ គាត់បានទទួលបណ្ឌិតរបស់គាត់ នៅក្នុងប្រតិបត្តិការស្រាវជ្រាវ បន្ទាប់ពីគាត់បានបំបែកគណនីជំនួយស្រាវជ្រាវរបស់ទីប្រឹក្សារបស់គាត់ ហើយមិនបានប្រគល់រង្វាន់ណូបែលដែលគាត់បានសន្យា។ បច្ចុប្បន្នគាត់ជួយអតិថិជនក្នុងសេវាកម្មហិរញ្ញវត្ថុបង្កើតដំណោះស្រាយការរៀនម៉ាស៊ីននៅលើ AWS ។
 Raghvender Arni ដឹកនាំក្រុមបង្កើនល្បឿនអតិថិជន (CAT) នៅក្នុង AWS Industries ។ CAT គឺជាក្រុមឆ្លងកាត់មុខងារជាសកលនៃអតិថិជនដែលប្រឈមមុខនឹងស្ថាបត្យករពពក វិស្វករកម្មវិធី អ្នកវិទ្យាសាស្ត្រទិន្នន័យ និងអ្នកជំនាញ AI/ML និងអ្នករចនាដែលជំរុញការច្នៃប្រឌិតតាមរយៈការបង្កើតគំរូកម្រិតខ្ពស់ និងជំរុញឱ្យដំណើរការប្រតិបត្តិការលើពពកល្អឥតខ្ចោះតាមរយៈជំនាញបច្ចេកទេសឯកទេស។
Raghvender Arni ដឹកនាំក្រុមបង្កើនល្បឿនអតិថិជន (CAT) នៅក្នុង AWS Industries ។ CAT គឺជាក្រុមឆ្លងកាត់មុខងារជាសកលនៃអតិថិជនដែលប្រឈមមុខនឹងស្ថាបត្យករពពក វិស្វករកម្មវិធី អ្នកវិទ្យាសាស្ត្រទិន្នន័យ និងអ្នកជំនាញ AI/ML និងអ្នករចនាដែលជំរុញការច្នៃប្រឌិតតាមរយៈការបង្កើតគំរូកម្រិតខ្ពស់ និងជំរុញឱ្យដំណើរការប្រតិបត្តិការលើពពកល្អឥតខ្ចោះតាមរយៈជំនាញបច្ចេកទេសឯកទេស។
- SEO ដែលដំណើរការដោយមាតិកា និងការចែកចាយ PR ។ ទទួលបានការពង្រីកថ្ងៃនេះ។
- PlatoData.Network Vertical Generative Ai. ផ្តល់អំណាចដល់ខ្លួនអ្នក។ ចូលប្រើទីនេះ។
- PlatoAiStream Web3 Intelligence ។ ចំណេះដឹងត្រូវបានពង្រីក។ ចូលប្រើទីនេះ។
- ផ្លាតូអេសជី។ កាបូន CleanTech, ថាមពល, បរិស្ថាន, ពន្លឺព្រះអាទិត្យ ការគ្រប់គ្រងកាកសំណល់។ ចូលប្រើទីនេះ។
- ផ្លាតូសុខភាព។ ជីវបច្ចេកវិទ្យា និង ភាពវៃឆ្លាត សាកល្បងគ្លីនិក។ ចូលប្រើទីនេះ។
- ប្រភព: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

