ស្ទូឌីយោ Amazon SageMaker ផ្តល់នូវដំណោះស្រាយដែលត្រូវបានគ្រប់គ្រងយ៉ាងពេញលេញសម្រាប់អ្នកវិទ្យាសាស្ត្រទិន្នន័យ ដើម្បីបង្កើតអន្តរកម្ម បណ្តុះបណ្តាល និងដាក់ឱ្យប្រើប្រាស់នូវគំរូនៃការរៀនម៉ាស៊ីន (ML)។ នៅក្នុងដំណើរការនៃការធ្វើការលើកិច្ចការ ML របស់ពួកគេ អ្នកវិទ្យាសាស្ត្រទិន្នន័យជាធម្មតាចាប់ផ្តើមដំណើរការការងាររបស់ពួកគេដោយស្វែងរកប្រភពទិន្នន័យដែលពាក់ព័ន្ធ និងភ្ជាប់ទៅពួកគេ។ បន្ទាប់មកពួកគេប្រើ SQL ដើម្បីរុករក វិភាគ មើលឃើញ និងរួមបញ្ចូលទិន្នន័យពីប្រភពផ្សេងៗ មុនពេលប្រើវានៅក្នុងការបណ្តុះបណ្តាល ML និងការសន្និដ្ឋានរបស់ពួកគេ។ ពីមុន អ្នកវិទ្យាសាស្ត្រទិន្នន័យជារឿយៗបានរកឃើញថាខ្លួនកំពុងលេងឧបករណ៍ជាច្រើនដើម្បីគាំទ្រ SQL នៅក្នុងដំណើរការការងាររបស់ពួកគេ ដែលរារាំងដល់ផលិតភាព។
យើងមានសេចក្តីរំភើបក្នុងការប្រកាសថា សៀវភៅកត់ត្រា JupyterLab នៅក្នុង SageMaker Studio ឥឡូវនេះបានភ្ជាប់មកជាមួយការគាំទ្រដែលភ្ជាប់មកជាមួយសម្រាប់ SQL ។ អ្នកវិទ្យាសាស្ត្រទិន្នន័យឥឡូវនេះអាច៖
- ភ្ជាប់ទៅសេវាកម្មទិន្នន័យពេញនិយម រួមទាំង អាម៉ាហ្សូនអាថេណា, ក្រុមហ៊ុន Amazon Redshift, Amazon DataZoneនិង Snowflake ដោយផ្ទាល់នៅក្នុងសៀវភៅកត់ត្រា
- រុករក និងស្វែងរកមូលដ្ឋានទិន្នន័យ គ្រោងការណ៍ តារាង និងទិដ្ឋភាព និងមើលទិន្នន័យជាមុននៅក្នុងចំណុចប្រទាក់សៀវភៅកត់ត្រា
- លាយកូដ SQL និង Python នៅក្នុងសៀវភៅកត់ត្រាតែមួយសម្រាប់ការរុករក និងបំប្លែងទិន្នន័យប្រកបដោយប្រសិទ្ធភាពសម្រាប់ប្រើប្រាស់ក្នុងគម្រោង ML
- ប្រើមុខងារផលិតភាពរបស់អ្នកអភិវឌ្ឍន៍ ដូចជាការបំពេញពាក្យបញ្ជា SQL ជំនួយក្នុងទម្រង់កូដ និងការរំលេចវាក្យសម្ព័ន្ធ ដើម្បីជួយពន្លឿនការអភិវឌ្ឍន៍កូដ និងបង្កើនផលិតភាពរបស់អ្នកអភិវឌ្ឍន៍ទាំងមូល។
លើសពីនេះ អ្នកគ្រប់គ្រងអាចគ្រប់គ្រងការភ្ជាប់ទៅសេវាកម្មទិន្នន័យទាំងនេះដោយសុវត្ថិភាព ដោយអនុញ្ញាតឱ្យអ្នកវិទ្យាសាស្ត្រទិន្នន័យចូលប្រើទិន្នន័យដែលមានការអនុញ្ញាតដោយមិនចាំបាច់គ្រប់គ្រងព័ត៌មានសម្ងាត់ដោយដៃ។
នៅក្នុងការប្រកាសនេះ យើងណែនាំអ្នកតាមរយៈការដំឡើងមុខងារនេះនៅក្នុង SageMaker Studio ហើយណែនាំអ្នកតាមរយៈសមត្ថភាពផ្សេងៗនៃមុខងារនេះ។ បន្ទាប់មក យើងបង្ហាញពីរបៀបដែលអ្នកអាចបង្កើនបទពិសោធន៍ SQL ក្នុងសៀវភៅកត់ត្រាដោយប្រើសមត្ថភាព Text-to-SQL ដែលផ្តល់ដោយគំរូភាសាធំៗកម្រិតខ្ពស់ (LLMs) ដើម្បីសរសេរសំណួរ SQL ស្មុគស្មាញដោយប្រើអត្ថបទភាសាធម្មជាតិជាការបញ្ចូល។ ជាចុងក្រោយ ដើម្បីបើកឱ្យអ្នកប្រើប្រាស់កាន់តែទូលំទូលាយដើម្បីបង្កើតសំណួរ SQL ពីការបញ្ចូលភាសាធម្មជាតិនៅក្នុងសៀវភៅកត់ត្រារបស់ពួកគេ យើងបង្ហាញអ្នកពីរបៀបដាក់ពង្រាយគំរូ Text-to-SQL ទាំងនេះដោយប្រើ ក្រុមហ៊ុន Amazon SageMaker ចំណុចបញ្ចប់។
ទិដ្ឋភាពទូទៅនៃដំណោះស្រាយ
ជាមួយនឹងការរួមបញ្ចូល SQL របស់កុំព្យូទ័រយួរដៃ SageMaker Studio JupyterLab ឥឡូវនេះអ្នកអាចភ្ជាប់ទៅប្រភពទិន្នន័យដ៏ពេញនិយមដូចជា Snowflake, Athena, Amazon Redshift និង Amazon DataZone ។ មុខងារថ្មីនេះ អាចឱ្យអ្នកអនុវត្តមុខងារផ្សេងៗបាន។
ឧទាហរណ៍ អ្នកអាចស្វែងរកប្រភពទិន្នន័យដូចជា មូលដ្ឋានទិន្នន័យ តារាង និងគ្រោងការណ៍ដោយផ្ទាល់ពីប្រព័ន្ធអេកូ JupyterLab របស់អ្នក។ ប្រសិនបើបរិស្ថានសៀវភៅកត់ត្រារបស់អ្នកកំពុងដំណើរការលើ SageMaker Distribution 1.6 ឬខ្ពស់ជាងនេះ រកមើលធាតុក្រាហ្វិកថ្មីនៅផ្នែកខាងឆ្វេងនៃចំណុចប្រទាក់ JupyterLab របស់អ្នក។ ការបន្ថែមនេះជួយបង្កើនលទ្ធភាពប្រើប្រាស់ទិន្នន័យ និងការគ្រប់គ្រងនៅក្នុងបរិយាកាសអភិវឌ្ឍន៍របស់អ្នក។
ប្រសិនបើអ្នកមិនស្ថិតនៅលើការចែកចាយ SageMaker ដែលបានស្នើ (1.5 ឬទាបជាងនេះ) ឬនៅក្នុងបរិយាកាសផ្ទាល់ខ្លួនទេ សូមមើលឧបសម្ព័ន្ធសម្រាប់ព័ត៌មានបន្ថែម។
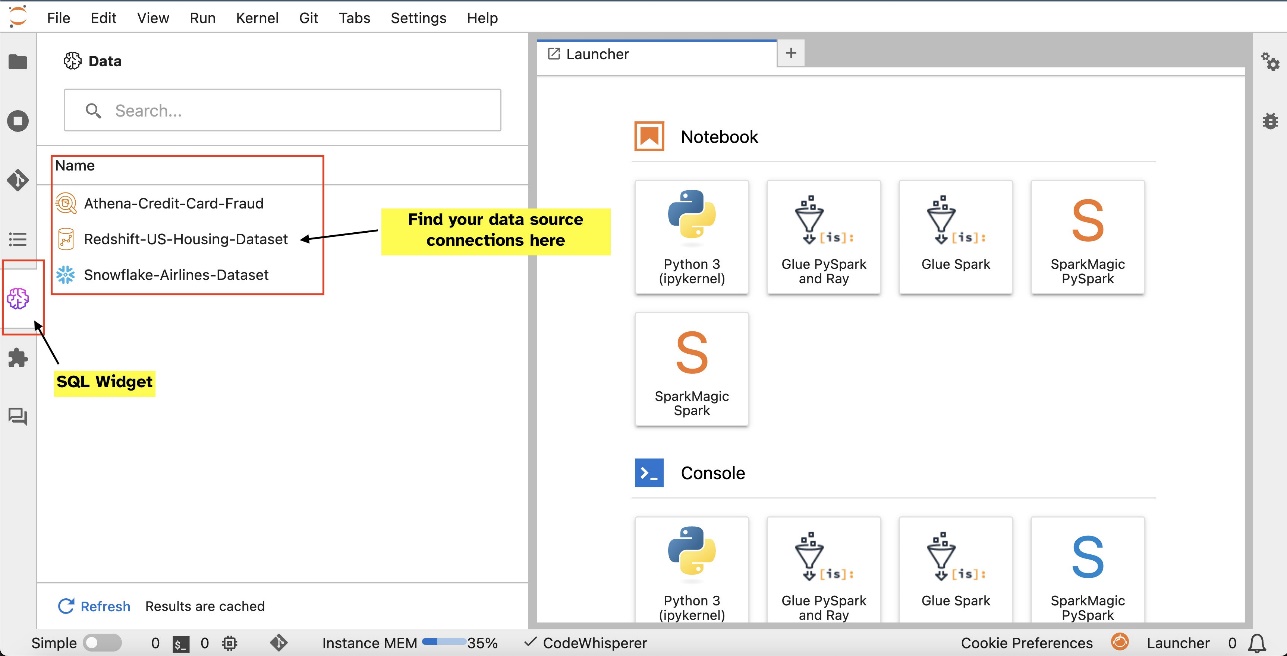
បន្ទាប់ពីអ្នកបានរៀបចំការតភ្ជាប់ (បង្ហាញក្នុងផ្នែកបន្ទាប់) អ្នកអាចរាយបញ្ជីការតភ្ជាប់ទិន្នន័យ រកមើលមូលដ្ឋានទិន្នន័យ និងតារាង និងពិនិត្យមើលគ្រោងការណ៍។
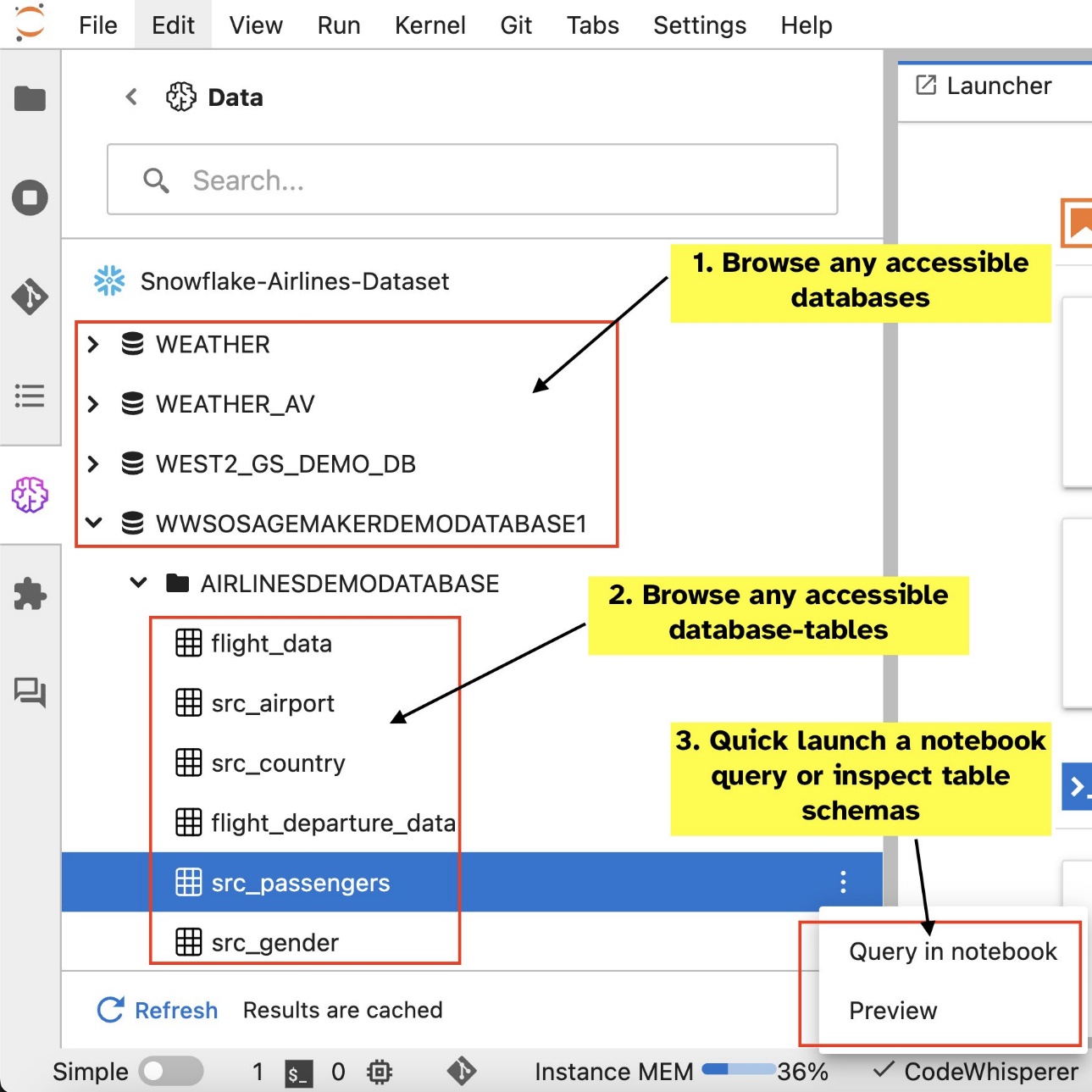
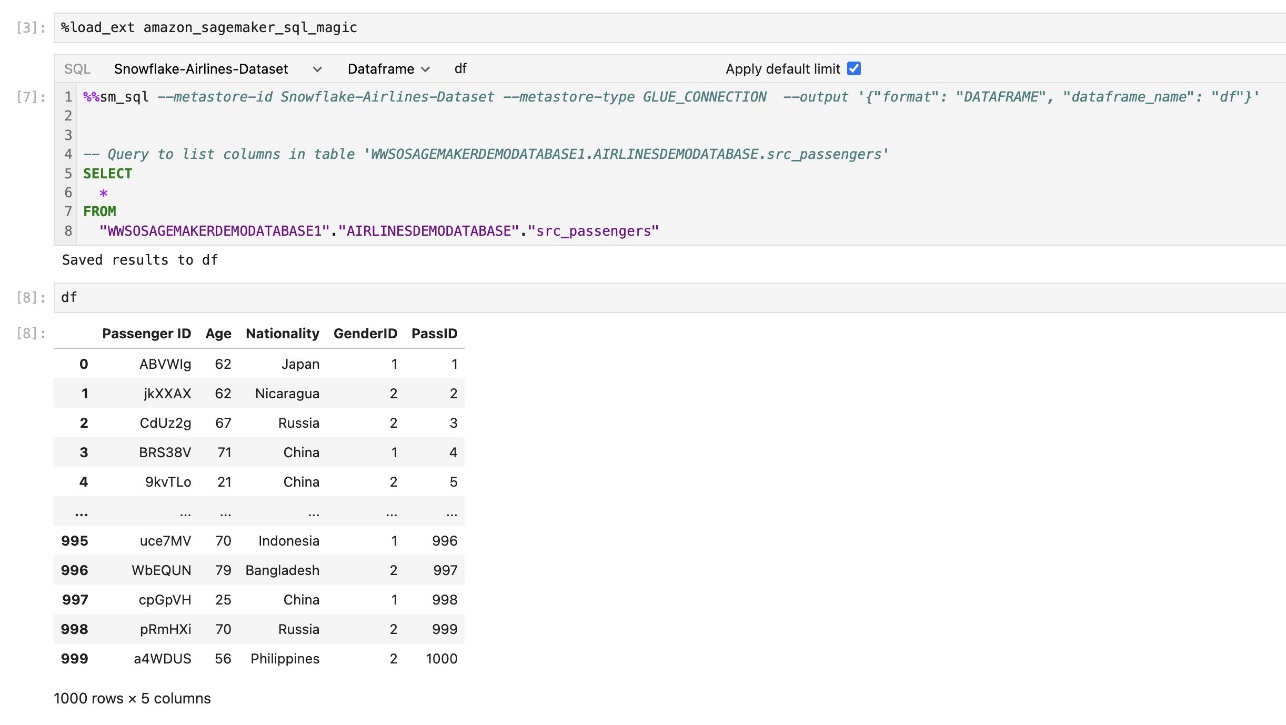
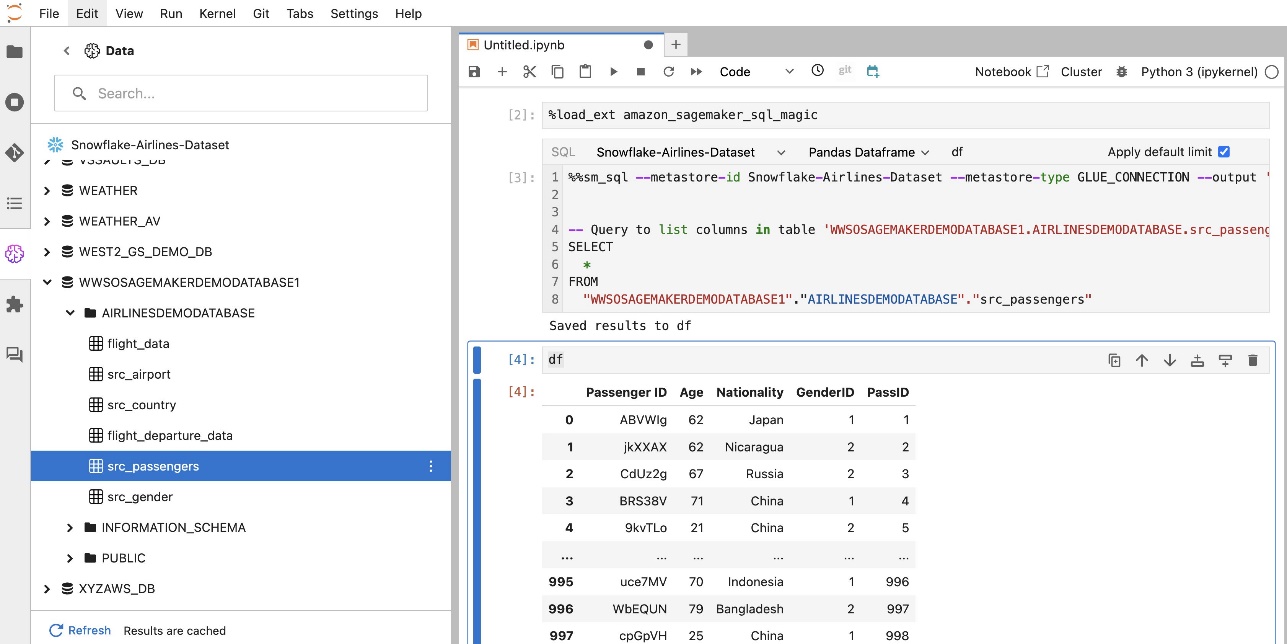
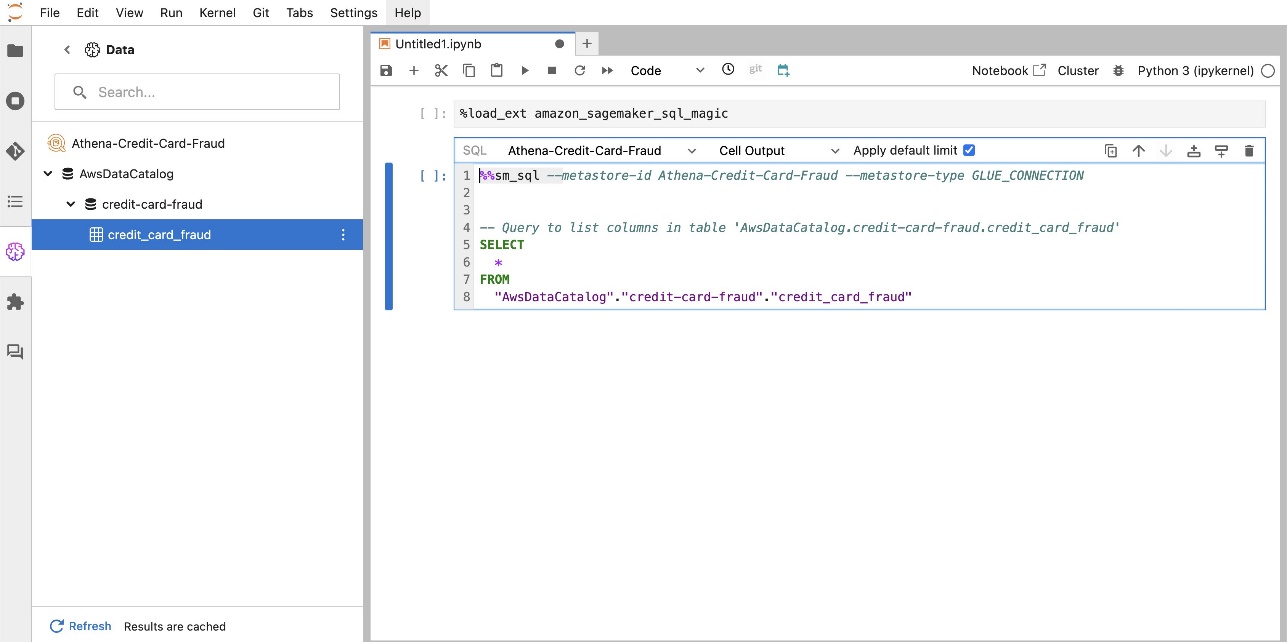
ផ្នែកបន្ថែម SQL ដែលភ្ជាប់មកជាមួយ SageMaker Studio JupyterLab ក៏អនុញ្ញាតឱ្យអ្នកដំណើរការសំណួរ SQL ដោយផ្ទាល់ពីសៀវភៅកត់ត្រាផងដែរ។ សៀវភៅកត់ត្រា Jupyter អាចបែងចែករវាងកូដ SQL និង Python ដោយប្រើ %%sm_sql ពាក្យបញ្ជាវេទមន្ត ដែលត្រូវតែដាក់នៅផ្នែកខាងលើនៃក្រឡាណាមួយដែលមានកូដ SQL ។ ពាក្យបញ្ជានេះផ្តល់សញ្ញាដល់ JupyterLab ថាការណែនាំខាងក្រោមគឺជាពាក្យបញ្ជា SQL ជាជាងកូដ Python ។ លទ្ធផលនៃសំណួរអាចត្រូវបានបង្ហាញដោយផ្ទាល់នៅក្នុងសៀវភៅកត់ត្រា ដែលជួយសម្រួលដល់ការរួមបញ្ចូលលំហូរការងារ SQL និង Python នៅក្នុងការវិភាគទិន្នន័យរបស់អ្នក។
លទ្ធផលនៃសំណួរអាចត្រូវបានបង្ហាញជាតារាង HTML ដូចបង្ហាញក្នុងរូបថតអេក្រង់ខាងក្រោម។

ពួកគេក៏អាចសរសេរទៅ ក ផេនដា DataFrame.
តម្រូវការជាមុន
សូមប្រាកដថាអ្នកបានបំពេញតម្រូវការជាមុនខាងក្រោម ដើម្បីប្រើបទពិសោធន៍ SQL notebook SageMaker Studio៖
- ស្ទូឌីយោ SageMaker V2 - ត្រូវប្រាកដថាអ្នកកំពុងដំណើរការកំណែចុងក្រោយបំផុតរបស់អ្នក។ ដែន SageMaker Studio និងទម្រង់អ្នកប្រើប្រាស់. ប្រសិនបើអ្នកកំពុងប្រើ SageMaker Studio Classic សូមយោងទៅ ការផ្លាស់ប្តូរពី Amazon SageMaker Studio Classic.
- តួនាទី IAM - SageMaker ទាមទារ អត្តសញ្ញាណ AWS និងការគ្រប់គ្រងការចូលប្រើ តួនាទី (IAM) ដែលត្រូវកំណត់ទៅដែន SageMaker Studio ឬទម្រង់អ្នកប្រើប្រាស់ ដើម្បីគ្រប់គ្រងការអនុញ្ញាតប្រកបដោយប្រសិទ្ធភាព។ ការធ្វើបច្ចុប្បន្នភាពតួនាទីប្រតិបត្តិអាចត្រូវបានទាមទារ ដើម្បីនាំយកការរុករកទិន្នន័យ និងមុខងារដំណើរការ SQL ។ គោលការណ៍ឧទាហរណ៍ខាងក្រោមអនុញ្ញាតឱ្យអ្នកប្រើប្រាស់ផ្តល់សិទ្ធិ រាយបញ្ជី និងដំណើរការ កាវអេវ, អាធីណា, សេវាកម្មផ្ទុកសាមញ្ញរបស់ក្រុមហ៊ុន Amazon (Amazon S3), អ្នកគ្រប់គ្រងអាថ៌កំបាំងអេ។ អេស។ អេនិងធនធាន Amazon Redshift៖
- JupyterLab Space - អ្នកត្រូវការចូលទៅកាន់ SageMaker Studio និង JupyterLab Space ដែលបានធ្វើបច្ចុប្បន្នភាពជាមួយ ការចែកចាយ SageMaker កំណែរូបភាព v1.6 ឬក្រោយ។ ប្រសិនបើអ្នកកំពុងប្រើរូបភាពផ្ទាល់ខ្លួនសម្រាប់ JupyterLab Spaces ឬកំណែចាស់នៃ SageMaker Distribution (v1.5 ឬទាបជាង) សូមមើលឧបសម្ព័ន្ធសម្រាប់ការណែនាំក្នុងការដំឡើងកញ្ចប់ និងម៉ូឌុលចាំបាច់ ដើម្បីបើកមុខងារនេះនៅក្នុងបរិស្ថានរបស់អ្នក។ ដើម្បីស្វែងយល់បន្ថែមអំពី SageMaker Studio JupyterLab Spaces សូមមើល បង្កើនផលិតភាពនៅលើ Amazon SageMaker Studio៖ ការណែនាំ JupyterLab Spaces និងឧបករណ៍ AI បង្កើត.
- ឯកសារបញ្ជាក់ការចូលប្រើប្រភពទិន្នន័យ - លក្ខណៈពិសេសសៀវភៅកត់ត្រា SageMaker Studio នេះទាមទារឈ្មោះអ្នកប្រើប្រាស់ និងពាក្យសម្ងាត់ចូលប្រើប្រភពទិន្នន័យដូចជា Snowflake និង Amazon Redshift ។ បង្កើតឈ្មោះអ្នកប្រើនិងការចូលប្រើប្រាស់ដោយផ្អែកលើពាក្យសម្ងាត់ទៅប្រភពទិន្នន័យទាំងនេះប្រសិនបើអ្នកមិនទាន់មាន។ ការចូលទៅកាន់ Snowflake ដែលមានមូលដ្ឋានលើ OAuth មិនមែនជាមុខងារដែលគាំទ្រដូចការសរសេរនេះទេ។
- ផ្ទុក SQL វេទមន្ត - មុនពេលអ្នកដំណើរការសំណួរ SQL ពីក្រឡាសៀវភៅកត់ត្រា Jupyter វាចាំបាច់ក្នុងការផ្ទុកផ្នែកបន្ថែម SQL magics ។ ប្រើពាក្យបញ្ជា
%load_ext amazon_sagemaker_sql_magicដើម្បីបើកមុខងារនេះ។ លើសពីនេះទៀតអ្នកអាចដំណើរការ%sm_sql?ពាក្យបញ្ជាដើម្បីមើលបញ្ជីទូលំទូលាយនៃជម្រើសដែលបានគាំទ្រសម្រាប់ការសួរពីក្រឡា SQL ។ ជម្រើសទាំងនេះរួមមានការកំណត់ដែនកំណត់សំណួរលំនាំដើមនៃ 1,000 ដំណើរការការស្រង់ចេញពេញលេញ និងបញ្ចូលប៉ារ៉ាម៉ែត្រសំណួរ ក្នុងចំណោមផ្សេងទៀត។ ការរៀបចំនេះអនុញ្ញាតឱ្យមានការគ្រប់គ្រងទិន្នន័យ SQL ដែលអាចបត់បែនបាន និងមានប្រសិទ្ធភាពដោយផ្ទាល់នៅក្នុងបរិស្ថានសៀវភៅកត់ត្រារបស់អ្នក។
បង្កើតការតភ្ជាប់មូលដ្ឋានទិន្នន័យ
សមត្ថភាពរុករក និងប្រតិបត្តិ SQL ដែលមានស្រាប់របស់ SageMaker Studio ត្រូវបានពង្រឹងដោយការតភ្ជាប់ AWS Glue ។ ការភ្ជាប់ AWS Glue គឺជាវត្ថុកាតាឡុកទិន្នន័យ AWS Glue ដែលរក្សាទុកទិន្នន័យសំខាន់ៗដូចជា លិខិតសម្គាល់ការចូល ខ្សែអក្សរ URI និងព័ត៌មានក្លោដឯកជននិម្មិត (VPC) សម្រាប់កន្លែងផ្ទុកទិន្នន័យជាក់លាក់។ ការតភ្ជាប់ទាំងនេះត្រូវបានប្រើប្រាស់ដោយ AWS Glue crawlers, jobs, and development endpoints ដើម្បីចូលទៅកាន់កន្លែងផ្ទុកទិន្នន័យប្រភេទផ្សេងៗ។ អ្នកអាចប្រើការតភ្ជាប់ទាំងនេះសម្រាប់ទាំងទិន្នន័យប្រភព និងគោលដៅ ហើយថែមទាំងប្រើការតភ្ជាប់ដូចគ្នាឡើងវិញតាមរយៈ crawlers ច្រើន ឬការងារស្រង់ចេញ បំលែង និងផ្ទុក (ETL)។
ដើម្បីរុករកប្រភពទិន្នន័យ SQL នៅក្នុងបន្ទះខាងឆ្វេងនៃ SageMaker Studio ដំបូងអ្នកត្រូវបង្កើតវត្ថុភ្ជាប់ AWS Glue ។ ការតភ្ជាប់ទាំងនេះជួយសម្រួលដល់ការចូលទៅកាន់ប្រភពទិន្នន័យផ្សេងៗគ្នា និងអនុញ្ញាតឱ្យអ្នកស្វែងរកធាតុទិន្នន័យជាគ្រោងការណ៍របស់ពួកគេ។
នៅក្នុងផ្នែកខាងក្រោម យើងដើរឆ្លងកាត់ដំណើរការនៃការបង្កើតឧបករណ៍ភ្ជាប់ AWS Glue ជាក់លាក់ SQL ។ វានឹងអនុញ្ញាតឱ្យអ្នកចូលប្រើប្រាស់ មើល និងរុករកសំណុំទិន្នន័យនៅទូទាំងកន្លែងផ្ទុកទិន្នន័យផ្សេងៗ។ សម្រាប់ព័ត៌មានលម្អិតបន្ថែមអំពីការតភ្ជាប់ AWS Glue សូមមើល កំពុងភ្ជាប់ទៅទិន្នន័យ.
បង្កើតការភ្ជាប់ AWS Glue
មធ្យោបាយតែមួយគត់ដើម្បីនាំយកប្រភពទិន្នន័យទៅក្នុង SageMaker Studio គឺជាមួយនឹងការតភ្ជាប់ AWS Glue ។ អ្នកត្រូវបង្កើតការតភ្ជាប់ AWS Glue ជាមួយនឹងប្រភេទការតភ្ជាប់ជាក់លាក់។ តាមការសរសេរនេះ យន្តការតែមួយគត់នៃការបង្កើតការភ្ជាប់ទាំងនេះគឺការប្រើប្រាស់ ចំណុចប្រទាក់បន្ទាត់ពាក្យបញ្ជា AWS (អេ។ អេស។ ស៊ី។ អាយ។ អេស) ។
និយមន័យនៃការតភ្ជាប់ឯកសារ JSON
នៅពេលភ្ជាប់ទៅប្រភពទិន្នន័យផ្សេងៗគ្នានៅក្នុង AWS Glue ដំបូងអ្នកត្រូវតែបង្កើតឯកសារ JSON ដែលកំណត់លក្ខណសម្បត្តិនៃការតភ្ជាប់ ដែលហៅថា ឯកសារនិយមន័យនៃការតភ្ជាប់. ឯកសារនេះមានសារៈសំខាន់សម្រាប់ការបង្កើតការតភ្ជាប់ AWS Glue ហើយគួរតែលម្អិតអំពីការកំណត់រចនាសម្ព័ន្ធចាំបាច់ទាំងអស់សម្រាប់ការចូលប្រើប្រភពទិន្នន័យ។ សម្រាប់ការអនុវត្តល្អបំផុតផ្នែកសុវត្ថិភាព វាត្រូវបានណែនាំឱ្យប្រើកម្មវិធីគ្រប់គ្រងសម្ងាត់ ដើម្បីរក្សាទុកព័ត៌មានរសើបដូចជាពាក្យសម្ងាត់។ ទន្ទឹមនឹងនេះ លក្ខណៈសម្បត្តិនៃការតភ្ជាប់ផ្សេងទៀតអាចត្រូវបានគ្រប់គ្រងដោយផ្ទាល់តាមរយៈការតភ្ជាប់ AWS Glue ។ វិធីសាស្រ្តនេះធ្វើឱ្យប្រាកដថាព័ត៌មានសម្ងាត់រសើបត្រូវបានការពារ ខណៈពេលដែលនៅតែធ្វើឱ្យការកំណត់រចនាសម្ព័ន្ធការតភ្ជាប់អាចចូលប្រើបាន និងអាចគ្រប់គ្រងបាន។
ខាងក្រោមនេះគឺជាឧទាហរណ៍នៃនិយមន័យនៃការតភ្ជាប់ JSON៖
នៅពេលដំឡើងការភ្ជាប់ AWS Glue សម្រាប់ប្រភពទិន្នន័យរបស់អ្នក មានគោលការណ៍ណែនាំសំខាន់ៗមួយចំនួនដែលត្រូវអនុវត្តតាម ដើម្បីផ្តល់ទាំងមុខងារ និងសុវត្ថិភាព៖
- ការពង្រឹងលក្ខណៈសម្បត្តិ - នៅខាងក្នុង
PythonPropertiesគន្លឹះ ត្រូវប្រាកដថាលក្ខណៈសម្បត្តិទាំងអស់គឺ គូតម្លៃគន្លឹះដែលបានកំណត់. វាមានសារៈសំខាន់ណាស់ក្នុងការគេចចេញពីការដកស្រង់ពីរដងឱ្យបានត្រឹមត្រូវដោយប្រើតួអក្សរ backslash () ក្នុងករណីចាំបាច់។ វាជួយរក្សាទម្រង់ត្រឹមត្រូវ និងជៀសវាងកំហុសវាក្យសម្ព័ន្ធនៅក្នុង JSON របស់អ្នក។ - គ្រប់គ្រងព័ត៌មានរសើប - ទោះបីជាវាអាចធ្វើទៅបានដើម្បីរួមបញ្ចូលលក្ខណៈសម្បត្តិនៃការតភ្ជាប់ទាំងអស់នៅក្នុង
PythonPropertiesវាត្រូវបានណែនាំមិនឱ្យរួមបញ្ចូលព័ត៌មានលម្អិតរសើបដូចជាពាក្យសម្ងាត់ដោយផ្ទាល់នៅក្នុងលក្ខណៈសម្បត្តិទាំងនេះ។ ជំនួសមកវិញ ប្រើកម្មវិធីគ្រប់គ្រងសម្ងាត់សម្រាប់គ្រប់គ្រងព័ត៌មានរសើប។ វិធីសាស្រ្តនេះធានាសុវត្ថិភាពទិន្នន័យរសើបរបស់អ្នកដោយរក្សាទុកវានៅក្នុងបរិយាកាសដែលបានគ្រប់គ្រង និងអ៊ិនគ្រីប ឆ្ងាយពីឯកសារកំណត់រចនាសម្ព័ន្ធសំខាន់ៗ។
បង្កើតការភ្ជាប់ AWS Glue ដោយប្រើ AWS CLI
បន្ទាប់ពីអ្នកបញ្ចូលវាលចាំបាច់ទាំងអស់នៅក្នុងឯកសារ JSON និយមន័យនៃការតភ្ជាប់របស់អ្នក អ្នកត្រៀមខ្លួនជាស្រេចដើម្បីបង្កើតការតភ្ជាប់ AWS Glue សម្រាប់ប្រភពទិន្នន័យរបស់អ្នកដោយប្រើ AWS CLI និងពាក្យបញ្ជាខាងក្រោម៖
ពាក្យបញ្ជានេះផ្តួចផ្តើមការភ្ជាប់ AWS Glue ថ្មីដោយផ្អែកលើលក្ខណៈជាក់លាក់ដែលបានរៀបរាប់នៅក្នុងឯកសារ JSON របស់អ្នក។ ខាងក្រោមនេះគឺជាការបំបែកយ៉ាងឆាប់រហ័សនៃសមាសភាគពាក្យបញ្ជា៖
- - តំបន់ - វាបញ្ជាក់តំបន់ AWS ដែលការតភ្ជាប់ AWS Glue របស់អ្នកនឹងត្រូវបានបង្កើត។ វាមានសារៈសំខាន់ណាស់ក្នុងការជ្រើសរើសតំបន់ដែលប្រភពទិន្នន័យរបស់អ្នក និងសេវាកម្មផ្សេងទៀតមានទីតាំងនៅ ដើម្បីកាត់បន្ថយភាពយឺតយ៉ាវ និងអនុលោមតាមតម្រូវការស្នាក់នៅទិន្នន័យ។
- -cli-input-json file:///path/to/file/connection/definition/file.json - ប៉ារ៉ាម៉ែត្រនេះដឹកនាំ AWS CLI ដើម្បីអានការកំណត់រចនាសម្ព័ន្ធបញ្ចូលពីឯកសារមូលដ្ឋានដែលមាននិយមន័យការតភ្ជាប់របស់អ្នកជាទម្រង់ JSON ។
អ្នកគួរតែអាចបង្កើតការភ្ជាប់ AWS Glue ជាមួយនឹងពាក្យបញ្ជា AWS CLI មុនពីស្ថានីយ Studio JupyterLab របស់អ្នក។ នៅលើ ឯកសារ ម៉ឺនុយជ្រើសរើស ជាថ្មី និង ស្ថានីយ.

ប្រសិនបើការ create-connection ពាក្យបញ្ជាដំណើរការដោយជោគជ័យ អ្នកគួរតែឃើញប្រភពទិន្នន័យរបស់អ្នកបានរាយក្នុងផ្ទាំងកម្មវិធីរុករក SQL ។ ប្រសិនបើអ្នកមិនឃើញប្រភពទិន្នន័យរបស់អ្នកក្នុងបញ្ជីទេ សូមជ្រើសរើស ធ្វើឱ្យស្រស់ ដើម្បីធ្វើបច្ចុប្បន្នភាពឃ្លាំងសម្ងាត់។

បង្កើតការតភ្ជាប់ Snowflake
នៅក្នុងផ្នែកនេះ យើងផ្តោតលើការរួមបញ្ចូលប្រភពទិន្នន័យ Snowflake ជាមួយ SageMaker Studio។ ការបង្កើតគណនី Snowflake មូលដ្ឋានទិន្នន័យ និងឃ្លាំងស្ថិតនៅក្រៅវិសាលភាពនៃប្រកាសនេះ។ ដើម្បីចាប់ផ្តើមជាមួយ Snowflake សូមមើល ការណែនាំអ្នកប្រើប្រាស់ Snowflake. នៅក្នុងការប្រកាសនេះ យើងផ្តោតលើការបង្កើតឯកសារ JSON និយមន័យ Snowflake និងបង្កើតការតភ្ជាប់ប្រភពទិន្នន័យ Snowflake ដោយប្រើ AWS Glue ។
បង្កើតអាថ៌កំបាំងអ្នកគ្រប់គ្រងសម្ងាត់
អ្នកអាចភ្ជាប់ទៅគណនី Snowflake របស់អ្នកដោយប្រើលេខសម្គាល់អ្នកប្រើប្រាស់ និងពាក្យសម្ងាត់ ឬប្រើសោឯកជន។ ដើម្បីភ្ជាប់ជាមួយលេខសម្គាល់អ្នកប្រើប្រាស់ និងពាក្យសម្ងាត់ អ្នកត្រូវរក្សាទុកព័ត៌មានសម្ងាត់របស់អ្នកដោយសុវត្ថិភាពនៅក្នុងកម្មវិធីគ្រប់គ្រងសម្ងាត់។ ដូចដែលបានរៀបរាប់ពីមុនមក ទោះបីជាវាអាចបង្កប់ព័ត៌មាននេះនៅក្រោម PythonProperties ក៏ដោយ វាមិនត្រូវបានណែនាំឱ្យរក្សាទុកព័ត៌មានរសើបជាទម្រង់អត្ថបទធម្មតានោះទេ។ ត្រូវប្រាកដថា ទិន្នន័យរសើបត្រូវបានគ្រប់គ្រងដោយសុវត្ថិភាព ដើម្បីជៀសវាងហានិភ័យសុវត្ថិភាពដែលអាចកើតមាន។
ដើម្បីរក្សាទុកព័ត៌មាននៅក្នុងកម្មវិធីគ្រប់គ្រងសម្ងាត់ សូមបំពេញជំហានខាងក្រោម៖
- នៅលើកុងសូលកម្មវិធីគ្រប់គ្រងអាថ៌កំបាំង សូមជ្រើសរើស រក្សាទុកអាថ៌កំបាំងថ្មី។.
- សម្រាប់ ប្រភេទសម្ងាត់ជ្រើស ប្រភេទផ្សេងទៀតនៃការសម្ងាត់.
- សម្រាប់គូតម្លៃគន្លឹះ សូមជ្រើសរើស អត្ថបទធម្មតា ហើយបញ្ចូលដូចខាងក្រោម៖
- បញ្ចូលឈ្មោះសម្រាប់អាថ៌កំបាំងរបស់អ្នក ដូចជា
sm-sql-snowflake-secret. - ទុកការកំណត់ផ្សេងទៀតជាលំនាំដើម ឬប្ដូរតាមបំណងប្រសិនបើចាំបាច់។
- បង្កើតអាថ៌កំបាំង។
បង្កើតការភ្ជាប់ AWS Glue សម្រាប់ Snowflake
ដូចដែលបានពិភាក្សាពីមុន ការតភ្ជាប់ AWS Glue គឺចាំបាច់សម្រាប់ការចូលប្រើការតភ្ជាប់ណាមួយពី SageMaker Studio។ អ្នកអាចរកឃើញបញ្ជីនៃ លក្ខណៈសម្បត្តិការតភ្ជាប់ដែលបានគាំទ្រទាំងអស់សម្រាប់ Snowflake. ខាងក្រោមនេះគឺជានិយមន័យនៃការតភ្ជាប់គំរូ JSON សម្រាប់ Snowflake ។ ជំនួសតម្លៃកន្លែងដាក់ជាមួយនឹងតម្លៃសមស្រប មុនពេលរក្សាទុកវាទៅក្នុងថាស៖
ដើម្បីបង្កើតវត្ថុភ្ជាប់ AWS Glue សម្រាប់ប្រភពទិន្នន័យ Snowflake សូមប្រើពាក្យបញ្ជាខាងក្រោម៖
ពាក្យបញ្ជានេះបង្កើតការភ្ជាប់ប្រភពទិន្នន័យ Snowflake ថ្មីនៅក្នុងផ្ទាំងកម្មវិធីរុករកតាមអ៊ីនធឺណិត SQL របស់អ្នកដែលអាចរុករកបាន ហើយអ្នកអាចដំណើរការសំណួរ SQL ប្រឆាំងនឹងវាពីកោសិកាសៀវភៅ JupyterLab របស់អ្នក។
បង្កើតការភ្ជាប់ Amazon Redshift
Amazon Redshift គឺជាសេវាកម្មឃ្លាំងទិន្នន័យទំហំ petabyte ដែលត្រូវបានគ្រប់គ្រងយ៉ាងពេញលេញ ដែលជួយសម្រួល និងកាត់បន្ថយការចំណាយលើការវិភាគទិន្នន័យរបស់អ្នកទាំងអស់ដោយប្រើ SQL ស្តង់ដារ។ នីតិវិធីសម្រាប់ការបង្កើតការតភ្ជាប់ Amazon Redshift ឆ្លុះបញ្ចាំងយ៉ាងជិតស្និទ្ធថាសម្រាប់ការតភ្ជាប់ Snowflake ។
បង្កើតអាថ៌កំបាំងអ្នកគ្រប់គ្រងសម្ងាត់
ស្រដៀងគ្នាទៅនឹងការដំឡើង Snowflake ដើម្បីភ្ជាប់ទៅ Amazon Redshift ដោយប្រើលេខសម្គាល់អ្នកប្រើប្រាស់ និងពាក្យសម្ងាត់ អ្នកត្រូវរក្សាទុកព័ត៌មានសម្ងាត់ដោយសុវត្ថិភាពនៅក្នុងកម្មវិធីគ្រប់គ្រងសម្ងាត់។ បំពេញជំហានខាងក្រោម៖
- នៅលើកុងសូលកម្មវិធីគ្រប់គ្រងអាថ៌កំបាំង សូមជ្រើសរើស រក្សាទុកអាថ៌កំបាំងថ្មី។.
- សម្រាប់ ប្រភេទសម្ងាត់ជ្រើស លិខិតសម្គាល់សម្រាប់ក្រុម Amazon Redshift.
- បញ្ចូលព័ត៌មានសម្ងាត់ដែលប្រើដើម្បីចូលដើម្បីចូលប្រើ Amazon Redshift ជាប្រភពទិន្នន័យ។
- ជ្រើសរើសក្រុម Redshift ដែលទាក់ទងនឹងអាថ៌កំបាំង។
- បញ្ចូលឈ្មោះសម្រាប់អាថ៌កំបាំង ដូចជា
sm-sql-redshift-secret. - ទុកការកំណត់ផ្សេងទៀតជាលំនាំដើម ឬប្ដូរតាមបំណងប្រសិនបើចាំបាច់។
- បង្កើតអាថ៌កំបាំង។
ដោយធ្វើតាមជំហានទាំងនេះ អ្នកត្រូវប្រាកដថាព័ត៌មានអត្តសញ្ញាណនៃការតភ្ជាប់របស់អ្នកត្រូវបានគ្រប់គ្រងដោយសុវត្ថិភាព ដោយប្រើមុខងារសុវត្ថិភាពដ៏រឹងមាំរបស់ AWS ដើម្បីគ្រប់គ្រងទិន្នន័យរសើបប្រកបដោយប្រសិទ្ធភាព។
បង្កើតការភ្ជាប់ AWS Glue សម្រាប់ Amazon Redshift
ដើម្បីរៀបចំការតភ្ជាប់ជាមួយ Amazon Redshift ដោយប្រើនិយមន័យ JSON សូមបំពេញក្នុងវាលចាំបាច់ ហើយរក្សាទុកការកំណត់រចនាសម្ព័ន្ធ JSON ខាងក្រោមទៅក្នុងថាស៖
ដើម្បីបង្កើតវត្ថុភ្ជាប់ AWS Glue សម្រាប់ប្រភពទិន្នន័យ Redshift សូមប្រើពាក្យបញ្ជា AWS CLI ខាងក្រោម៖
ពាក្យបញ្ជានេះបង្កើតការតភ្ជាប់នៅក្នុង AWS Glue ដែលភ្ជាប់ទៅប្រភពទិន្នន័យ Redshift របស់អ្នក។ ប្រសិនបើពាក្យបញ្ជាដំណើរការដោយជោគជ័យ អ្នកនឹងអាចឃើញប្រភពទិន្នន័យ Redshift របស់អ្នកនៅក្នុងសៀវភៅកត់ត្រា SageMaker Studio JupyterLab រួចរាល់សម្រាប់ការដំណើរការសំណួរ SQL និងធ្វើការវិភាគទិន្នន័យ។

បង្កើតការតភ្ជាប់ Athena
Athena គឺជាសេវាកម្មសំណួរ SQL ដែលត្រូវបានគ្រប់គ្រងយ៉ាងពេញលេញពី AWS ដែលអនុញ្ញាតឱ្យមានការវិភាគទិន្នន័យដែលបានរក្សាទុកនៅក្នុង Amazon S3 ដោយប្រើ SQL ស្តង់ដារ។ ដើម្បីដំឡើងការភ្ជាប់ Athena ជាប្រភពទិន្នន័យនៅក្នុងកម្មវិធីរុករកតាមអ៊ីនធឺណិត SQL របស់ JupyterLab អ្នកត្រូវបង្កើតនិយមន័យនៃការតភ្ជាប់គំរូ Athena JSON ។ រចនាសម្ព័ន្ធ JSON ខាងក្រោមកំណត់រចនាសម្ព័ន្ធព័ត៌មានលម្អិតចាំបាច់ដើម្បីភ្ជាប់ទៅ Athena ដោយបញ្ជាក់កាតាឡុកទិន្នន័យ ថតដំណាក់កាល S3 និងតំបន់៖
ដើម្បីបង្កើតវត្ថុភ្ជាប់ AWS Glue សម្រាប់ប្រភពទិន្នន័យ Athena សូមប្រើពាក្យបញ្ជា AWS CLI ខាងក្រោម៖
ប្រសិនបើពាក្យបញ្ជាជោគជ័យ អ្នកនឹងអាចចូលប្រើកាតាឡុកទិន្នន័យ Athena និងតារាងដោយផ្ទាល់ពីកម្មវិធីរុករកតាមអ៊ីនធឺណិត SQL នៅក្នុងសៀវភៅកត់ត្រា SageMaker Studio JupyterLab របស់អ្នក។
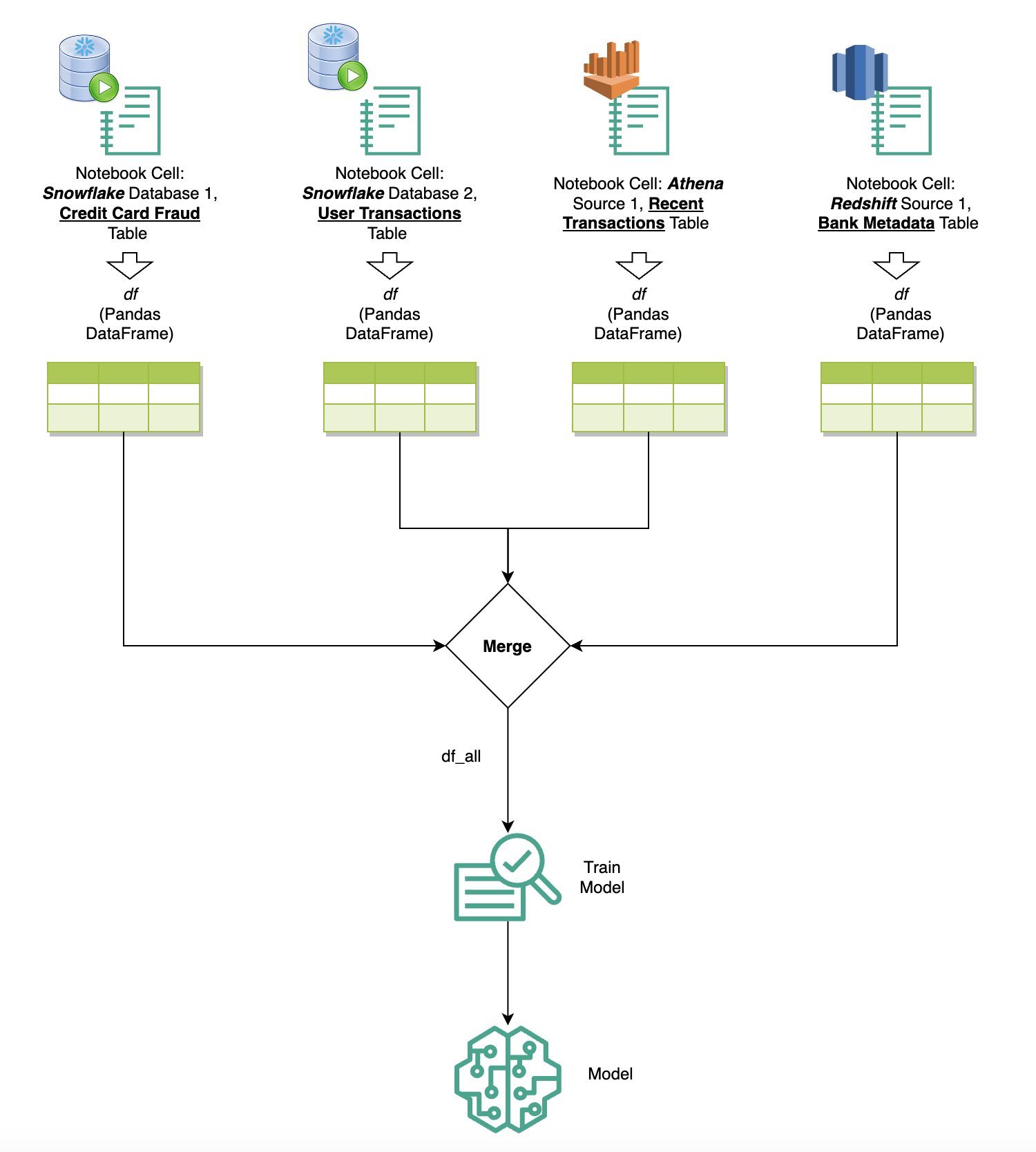
សំណួរទិន្នន័យពីប្រភពជាច្រើន។
ប្រសិនបើអ្នកមានប្រភពទិន្នន័យជាច្រើនដែលរួមបញ្ចូលទៅក្នុង SageMaker Studio តាមរយៈកម្មវិធីរុករកតាមអ៊ីនធឺណិត SQL ដែលភ្ជាប់មកជាមួយ និងមុខងារ SQL របស់ notebook អ្នកអាចដំណើរការសំណួរបានយ៉ាងឆាប់រហ័ស និងផ្លាស់ប្តូររវាងកម្មវិធីខាងក្រោយប្រភពទិន្នន័យក្នុងក្រឡាជាបន្តបន្ទាប់នៅក្នុងសៀវភៅកត់ត្រា។ សមត្ថភាពនេះអនុញ្ញាតឱ្យមានការផ្លាស់ប្តូរដោយគ្មានថ្នេររវាងមូលដ្ឋានទិន្នន័យ ឬប្រភពទិន្នន័យផ្សេងៗក្នុងអំឡុងពេលដំណើរការការងារវិភាគរបស់អ្នក។
អ្នកអាចដំណើរការសំណួរប្រឆាំងនឹងការប្រមូលផ្តុំចម្រុះនៃប្រភពទិន្នន័យខាងក្រោយ ហើយនាំលទ្ធផលដោយផ្ទាល់ទៅក្នុងលំហ Python សម្រាប់ការវិភាគបន្ថែម ឬមើលឃើញ។ នេះត្រូវបានសម្របសម្រួលដោយ គ %%sm_sql ពាក្យបញ្ជាវេទមន្តមាននៅក្នុងសៀវភៅកត់ត្រា SageMaker Studio ។ ដើម្បីបញ្ចេញលទ្ធផលនៃសំណួរ SQL របស់អ្នកទៅក្នុងផេនដា DataFrame មានជម្រើសពីរ៖
- ពីរបារឧបករណ៍ក្រឡាសៀវភៅកត់ត្រារបស់អ្នក សូមជ្រើសរើសប្រភេទលទ្ធផល DataFrame ហើយដាក់ឈ្មោះអថេរ DataFrame របស់អ្នក។
- បន្ថែមប៉ារ៉ាម៉ែត្រខាងក្រោមទៅរបស់អ្នក។
%%sm_sqlពាក្យបញ្ជា:
ដ្យាក្រាមខាងក្រោមបង្ហាញពីដំណើរការការងារនេះ និងបង្ហាញពីរបៀបដែលអ្នកអាចដំណើរការសំណួរដោយមិនពិបាកឆ្លងកាត់ប្រភពផ្សេងៗនៅក្នុងកោសិកាសៀវភៅកត់ត្រាជាបន្តបន្ទាប់ ក៏ដូចជាបណ្តុះបណ្តាលគំរូ SageMaker ដោយប្រើការងារបណ្តុះបណ្តាល ឬដោយផ្ទាល់នៅក្នុងសៀវភៅកត់ត្រាដោយប្រើកុំព្យូទ័រមូលដ្ឋាន។ លើសពីនេះទៀត ដ្យាក្រាមបង្ហាញពីរបៀបដែលការរួមបញ្ចូល SQL ដែលភ្ជាប់មកជាមួយនៃ SageMaker Studio សម្រួលដល់ដំណើរការនៃការស្រង់ចេញ និងការស្ថាបនាដោយផ្ទាល់នៅក្នុងបរិយាកាសដែលធ្លាប់ស្គាល់នៃកោសិកាសៀវភៅ JupyterLab ។
អត្ថបទទៅ SQL៖ ការប្រើភាសាធម្មជាតិដើម្បីបង្កើនការសរសេរសំណួរ
SQL គឺជាភាសាស្មុគស្មាញដែលទាមទារការយល់ដឹងអំពីមូលដ្ឋានទិន្នន័យ តារាង វាក្យសម្ព័ន្ធ និងទិន្នន័យមេតា។ សព្វថ្ងៃនេះ បញ្ញាសិប្បនិមិត្ត (AI) អាចឱ្យអ្នកសរសេរសំណួរ SQL ដ៏ស្មុគស្មាញ ដោយមិនចាំបាច់ត្រូវការបទពិសោធន៍ SQL ស៊ីជម្រៅ។ ការរីកចម្រើននៃ LLMs បានជះឥទ្ធិពលយ៉ាងខ្លាំងដល់ការបង្កើត SQL ដែលមានមូលដ្ឋានលើដំណើរការភាសាធម្មជាតិ (NLP) ដែលអនុញ្ញាតឱ្យបង្កើតសំណួរ SQL ច្បាស់លាស់ពីការពិពណ៌នាភាសាធម្មជាតិ ដែលជាបច្ចេកទេសមួយហៅថា Text-to-SQL ។ ទោះយ៉ាងណាក៏ដោយ វាចាំបាច់ក្នុងការទទួលស្គាល់ភាពខុសគ្នារវាងភាសាមនុស្ស និង SQL ។ ពេលខ្លះភាសារបស់មនុស្សអាចមានភាពមិនច្បាស់លាស់ ឬមិនច្បាស់លាស់ ចំណែកឯ SQL មានរចនាសម្ព័ន្ធច្បាស់លាស់ និងមិនច្បាស់លាស់។ ការភ្ជាប់គម្លាតនេះ និងការបំប្លែងភាសាធម្មជាតិយ៉ាងត្រឹមត្រូវទៅជាសំណួរ SQL អាចបង្ហាញពីបញ្ហាប្រឈមដ៏ខ្លាំងមួយ។ នៅពេលផ្តល់ការជម្រុញសមស្រប LLMs អាចជួយភ្ជាប់គម្លាតនេះដោយការយល់ដឹងពីចេតនានៅពីក្រោយភាសាមនុស្ស និងបង្កើតសំណួរ SQL ត្រឹមត្រូវតាមនោះ។
ជាមួយនឹងការចេញផ្សាយនៃមុខងារសំណួរ SQL នៅក្នុងសៀវភៅកត់ត្រា SageMaker Studio SageMaker Studio ធ្វើឱ្យវាមានភាពត្រង់ក្នុងការត្រួតពិនិត្យមូលដ្ឋានទិន្នន័យ និងគ្រោងការណ៍ និងអ្នកនិពន្ធ ដំណើរការ និងបំបាត់កំហុសសំណួរ SQL ដោយមិនចាំបាច់ចាកចេញពី Jupyter notebook IDE ឡើយ។ ផ្នែកនេះស្វែងយល់ពីរបៀបដែលសមត្ថភាព Text-to-SQL របស់ LLMs កម្រិតខ្ពស់អាចជួយសម្រួលដល់ការបង្កើតសំណួរ SQL ដោយប្រើភាសាធម្មជាតិនៅក្នុងសៀវភៅ Jupyter ។ យើងប្រើប្រាស់គំរូ Text-to-SQL ដ៏ទំនើប defog/sqlcoder-7b-2 ដោយភ្ជាប់ជាមួយ Jupyter AI ដែលជាជំនួយការ AI ជំនាន់ថ្មីដែលត្រូវបានរចនាឡើងជាពិសេសសម្រាប់សៀវភៅកត់ត្រា Jupyter ដើម្បីបង្កើតសំណួរ SQL ដ៏ស្មុគស្មាញពីភាសាធម្មជាតិ។ ដោយប្រើគំរូកម្រិតខ្ពស់នេះ យើងអាចបង្កើតសំណួរ SQL ដ៏ស្មុគស្មាញដោយប្រើប្រាស់ភាសាធម្មជាតិដោយមិនចាំបាច់ប្រឹងប្រែង និងមានប្រសិទ្ធភាព ដោយហេតុនេះបង្កើនបទពិសោធន៍ SQL របស់យើងនៅក្នុងសៀវភៅកត់ត្រា។
ការបង្កើតគំរូសៀវភៅកត់ត្រាដោយប្រើ Hugging Face Hub
ដើម្បីចាប់ផ្តើមបង្កើតគំរូ អ្នកត្រូវការដូចខាងក្រោម៖
- លេខកូដ GitHub - កូដដែលបង្ហាញក្នុងផ្នែកនេះមាននៅខាងក្រោម GitHub repo និងដោយយោងទៅលើ សៀវភៅកត់ត្រាឧទាហរណ៍.
- JupyterLab Space - ការចូលទៅកាន់ SageMaker Studio JupyterLab Space ដែលគាំទ្រដោយ GPU-based instance គឺចាំបាច់។ សម្រាប់
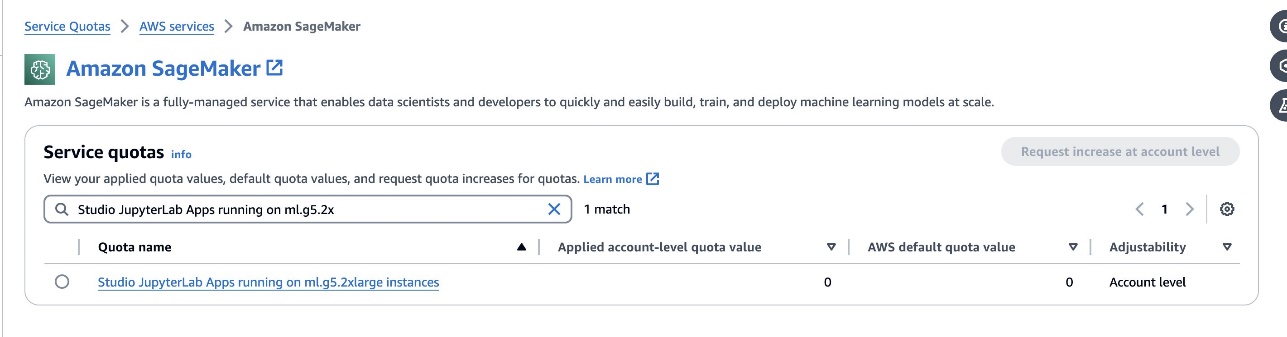
defog/sqlcoder-7b-2គំរូ គំរូប៉ារ៉ាម៉ែត្រ 7B ដោយប្រើឧទាហរណ៍ ml.g5.2xlarge ត្រូវបានណែនាំ។ ជម្មើសជំនួសដូចជាdefog/sqlcoder-70b-alpha ឬdefog/sqlcoder-34b-alphaក៏អាចប្រើបានសម្រាប់ការបំប្លែងភាសាធម្មជាតិទៅជា SQL ដែរ ប៉ុន្តែប្រភេទឧទាហរណ៍ធំជាងអាចត្រូវបានទាមទារសម្រាប់ការធ្វើគំរូ។ ត្រូវប្រាកដថាអ្នកមានកូតាដើម្បីបើកដំណើរការវត្ថុដែលគាំទ្រដោយ GPU ដោយរុករកទៅកុងសូល Quotas សេវាកម្ម ស្វែងរក SageMaker និងស្វែងរកStudio JupyterLab Apps running on <instance type>.
បើកដំណើរការ JupyterLab Space ដែលគាំទ្រ GPU ថ្មីពី SageMaker Studio របស់អ្នក។ វាត្រូវបានណែនាំឱ្យបង្កើត JupyterLab Space ថ្មីដែលមានយ៉ាងហោចណាស់ 75 GB ហាងប្លុកអេលហ្សូលអេល ការផ្ទុក (Amazon EBS) សម្រាប់គំរូប៉ារ៉ាម៉ែត្រ 7B ។

- កន្លែងឱបមុខ - ប្រសិនបើដែន SageMaker Studio របស់អ្នកមានសិទ្ធិទាញយកម៉ូដែលពី កន្លែងឱបមុខអ្នកអាចប្រើ
AutoModelForCausalLMថ្នាក់ពី អោបមុខ/ប្រដាប់បំលែង ដើម្បីទាញយកម៉ូដែលដោយស្វ័យប្រវត្តិ ហើយខ្ទាស់ពួកវាទៅ GPUs មូលដ្ឋានរបស់អ្នក។ ទម្ងន់គំរូនឹងត្រូវបានរក្សាទុកនៅក្នុងឃ្លាំងសម្ងាត់ម៉ាស៊ីនមូលដ្ឋានរបស់អ្នក។ សូមមើលកូដខាងក្រោម៖
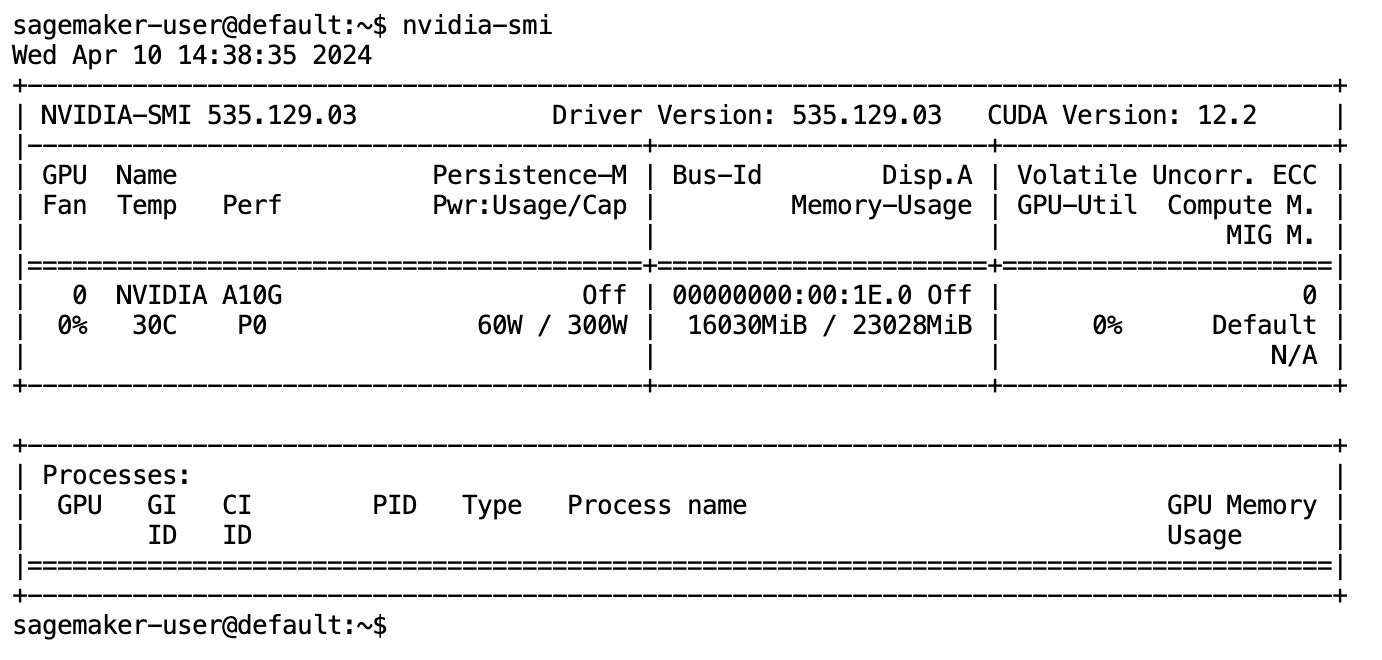
បន្ទាប់ពីម៉ូដែលត្រូវបានទាញយក និងផ្ទុកពេញទៅក្នុងអង្គចងចាំ អ្នកគួរតែសង្កេតមើលការកើនឡើងនៃការប្រើប្រាស់ GPU នៅលើម៉ាស៊ីនមូលដ្ឋានរបស់អ្នក។ នេះបង្ហាញថាគំរូកំពុងប្រើប្រាស់ធនធាន GPU យ៉ាងសកម្មសម្រាប់កិច្ចការកុំព្យូទ័រ។ អ្នកអាចផ្ទៀងផ្ទាត់វានៅក្នុងចន្លោះ JupyterLab ផ្ទាល់ខ្លួនរបស់អ្នកដោយដំណើរការ nvidia-smi (សម្រាប់ការបង្ហាញតែម្តង) ឬ nvidia-smi —loop=1 (ដើម្បីធ្វើឡើងវិញរាល់វិនាទី) ពីស្ថានីយ JupyterLab របស់អ្នក។
គំរូអត្ថបទទៅ SQL ពូកែក្នុងការស្វែងយល់ពីចេតនា និងបរិបទនៃសំណើរបស់អ្នកប្រើ ទោះបីជាភាសាដែលបានប្រើមានការសន្ទនា ឬមិនច្បាស់លាស់ក៏ដោយ។ ដំណើរការនេះពាក់ព័ន្ធនឹងការបកប្រែការបញ្ចូលភាសាធម្មជាតិទៅក្នុងធាតុគ្រោងការណ៍មូលដ្ឋានទិន្នន័យត្រឹមត្រូវ ដូចជាឈ្មោះតារាង ឈ្មោះជួរឈរ និងលក្ខខណ្ឌ។ ទោះជាយ៉ាងណាក៏ដោយ គំរូ Text-to-SQL ក្រៅធ្នើនឹងមិនដឹងពីរចនាសម្ព័ន្ធនៃឃ្លាំងទិន្នន័យរបស់អ្នក គ្រោងការណ៍មូលដ្ឋានទិន្នន័យជាក់លាក់ ឬអាចបកស្រាយបានត្រឹមត្រូវអំពីខ្លឹមសារនៃតារាងដោយផ្អែកលើឈ្មោះជួរឈរតែប៉ុណ្ណោះ។ ដើម្បីប្រើគំរូទាំងនេះប្រកបដោយប្រសិទ្ធភាពដើម្បីបង្កើតសំណួរ SQL ជាក់ស្តែង និងមានប្រសិទ្ធភាពពីភាសាធម្មជាតិ វាចាំបាច់ក្នុងការសម្របគំរូបង្កើតអត្ថបទ SQL ទៅនឹងគ្រោងការណ៍មូលដ្ឋានទិន្នន័យឃ្លាំងជាក់លាក់របស់អ្នក។ ការសម្របសម្រួលនេះត្រូវបានសម្របសម្រួលតាមរយៈការប្រើប្រាស់ LLM ជម្រុញ. ខាងក្រោមនេះគឺជាគំរូប្រអប់បញ្ចូលដែលបានណែនាំសម្រាប់គំរូ defog/sqlcoder-7b-2 Text-to-SQL ដែលបែងចែកជាបួនផ្នែក៖
- កិច្ចការ។ - ផ្នែកនេះគួរតែបញ្ជាក់កិច្ចការកម្រិតខ្ពស់ដែលត្រូវសម្រេចដោយគំរូ។ វាគួរតែរួមបញ្ចូលប្រភេទនៃផ្នែកខាងក្រោយនៃមូលដ្ឋានទិន្នន័យ (ដូចជា Amazon RDS, PostgreSQL ឬ Amazon Redshift) ដើម្បីធ្វើឱ្យគំរូដឹងពីភាពខុសគ្នានៃវាក្យសម្ព័ន្ធដែលអាចប៉ះពាល់ដល់ការបង្កើតសំណួរ SQL ចុងក្រោយ។
- សេចក្តីណែនាំ - ផ្នែកនេះគួរតែកំណត់ព្រំដែនភារកិច្ច និងការយល់ដឹងអំពីដែនសម្រាប់គំរូ ហើយអាចរួមបញ្ចូលឧទាហរណ៍មួយចំនួន ដើម្បីណែនាំគំរូក្នុងការបង្កើតសំណួរ SQL ដែលបានកែសម្រួលយ៉ាងល្អិតល្អន់។
- គ្រោងការណ៍មូលដ្ឋានទិន្នន័យ - ផ្នែកនេះគួរតែលម្អិតអំពីគ្រោងការណ៍មូលដ្ឋានទិន្នន័យឃ្លាំងរបស់អ្នក ដោយរៀបរាប់ពីទំនាក់ទំនងរវាងតារាង និងជួរឈរ ដើម្បីជួយដល់គំរូក្នុងការយល់ដឹងអំពីរចនាសម្ព័ន្ធមូលដ្ឋានទិន្នន័យ។
- ចម្លើយ - ផ្នែកនេះត្រូវបានបម្រុងទុកសម្រាប់គំរូដើម្បីបញ្ចេញការឆ្លើយតបសំណួរ SQL ទៅនឹងការបញ្ចូលភាសាធម្មជាតិ។
ឧទាហរណ៍នៃគ្រោងការណ៍មូលដ្ឋានទិន្នន័យ និងប្រអប់បញ្ចូលដែលប្រើក្នុងផ្នែកនេះមាននៅក្នុង ជីធីហបស្តុប.
វិស្វកម្មរហ័សមិនមែនគ្រាន់តែអំពីការបង្កើតសំណួរ ឬសេចក្តីថ្លែងការណ៍ប៉ុណ្ណោះទេ។ វាជាសិល្បៈ និងវិទ្យាសាស្ត្រដែលប៉ះពាល់យ៉ាងខ្លាំងដល់គុណភាពនៃអន្តរកម្មជាមួយគំរូ AI។ វិធីដែលអ្នកបង្កើតការជម្រុញអាចមានឥទ្ធិពលយ៉ាងខ្លាំងទៅលើធម្មជាតិ និងអត្ថប្រយោជន៍នៃការឆ្លើយតបរបស់ AI ។ ជំនាញនេះគឺមានសារៈសំខាន់ក្នុងការបង្កើនសក្តានុពលនៃអន្តរកម្ម AI ជាពិសេសនៅក្នុងកិច្ចការស្មុគស្មាញដែលទាមទារការយល់ដឹងពិសេស និងការឆ្លើយតបលម្អិត។
វាមានសារៈសំខាន់ណាស់ក្នុងការមានជម្រើសក្នុងការសាងសង់ និងសាកល្បងការឆ្លើយតបរបស់គំរូយ៉ាងឆាប់រហ័សសម្រាប់ប្រអប់បញ្ចូលដែលបានផ្តល់ឱ្យ និងបង្កើនប្រសិទ្ធភាពប្រអប់បញ្ចូលដោយផ្អែកលើការឆ្លើយតប។ សៀវភៅកត់ត្រា JupyterLab ផ្តល់នូវសមត្ថភាពក្នុងការទទួលបានមតិកែលម្អគំរូភ្លាមៗពីម៉ូដែលដែលកំពុងដំណើរការលើកុំព្យូទ័រក្នុងស្រុក និងបង្កើនប្រសិទ្ធភាពភ្លាមៗ និងសម្រួលការឆ្លើយតបរបស់ម៉ូដែលមួយបន្ថែមទៀត ឬផ្លាស់ប្តូរគំរូទាំងស្រុង។ នៅក្នុងការប្រកាសនេះ យើងប្រើប្រាស់ Notebook SageMaker Studio JupyterLab គាំទ្រដោយ NVIDIA A5.2G 10 GB GPU របស់ ml.g24xlarge ដើម្បីដំណើរការការសន្និដ្ឋានគំរូ Text-to-SQL នៅលើសៀវភៅកត់ត្រា ហើយធ្វើអន្តរកម្មបង្កើតប្រអប់បញ្ចូលគំរូរបស់យើងរហូតដល់ការឆ្លើយតបរបស់ម៉ូដែលត្រូវបានលៃតម្រូវគ្រប់គ្រាន់ដើម្បីផ្តល់ ការឆ្លើយតបដែលអាចប្រតិបត្តិដោយផ្ទាល់នៅក្នុងកោសិកា SQL របស់ JupyterLab ។ ដើម្បីដំណើរការការសន្និដ្ឋានអំពីគំរូ និងដំណើរការការឆ្លើយតបគំរូក្នុងពេលដំណាលគ្នា យើងប្រើការរួមបញ្ចូលគ្នានៃ model.generate និង TextIteratorStreamer ដូចដែលបានកំណត់ក្នុងកូដខាងក្រោម៖
លទ្ធផលរបស់ម៉ូដែលអាចត្រូវបានតុបតែងជាមួយ SageMaker SQL magic %%sm_sql ...ដែលអនុញ្ញាតឱ្យសៀវភៅកត់ត្រា JupyterLab កំណត់អត្តសញ្ញាណក្រឡាជាក្រឡា SQL ។
ធ្វើជាម្ចាស់ផ្ទះគំរូ Text-to-SQL ជាចំណុចបញ្ចប់ SageMaker
នៅចុងបញ្ចប់នៃដំណាក់កាលគំរូគំរូ យើងបានជ្រើសរើស Text-to-SQL LLM ដែលយើងពេញចិត្ត ដែលជាទម្រង់ប្រអប់បញ្ចូលដ៏មានប្រសិទ្ធភាព និងប្រភេទឧទាហរណ៍សមរម្យសម្រាប់ការបង្ហោះគំរូ (ទាំង single-GPU ឬ multi-GPU)។ SageMaker សម្របសម្រួលការបង្ហោះដែលអាចធ្វើមាត្រដ្ឋានបាននៃគំរូផ្ទាល់ខ្លួនតាមរយៈការប្រើប្រាស់ SageMaker endpoints ។ ចំណុចបញ្ចប់ទាំងនេះអាចត្រូវបានកំណត់តាមលក្ខណៈវិនិច្ឆ័យជាក់លាក់ ដែលអនុញ្ញាតឱ្យមានការដាក់ពង្រាយ LLMs ជាចំណុចបញ្ចប់។ សមត្ថភាពនេះអនុញ្ញាតឱ្យអ្នកធ្វើមាត្រដ្ឋានដំណោះស្រាយទៅកាន់ទស្សនិកជនកាន់តែទូលំទូលាយ ដែលអនុញ្ញាតឱ្យអ្នកប្រើប្រាស់បង្កើតសំណួរ SQL ពីការបញ្ចូលភាសាធម្មជាតិដោយប្រើ LLMs ផ្ទាល់ខ្លួន។ ដ្យាក្រាមខាងក្រោមបង្ហាញពីស្ថាបត្យកម្មនេះ។

ដើម្បីធ្វើជាម្ចាស់ផ្ទះ LLM របស់អ្នកជាចំណុចបញ្ចប់ SageMaker អ្នកបង្កើតវត្ថុបុរាណជាច្រើន។
វត្ថុបុរាណដំបូងគឺទម្ងន់គំរូ។ SageMaker Deep Java Library (DJL) កំពុងបម្រើ កុងតឺន័រអនុញ្ញាតឱ្យអ្នករៀបចំការកំណត់តាមរយៈមេតា serving.properties ឯកសារដែលអាចឱ្យអ្នកដឹកនាំពីរបៀបដែលម៉ូដែលមានប្រភព—ដោយផ្ទាល់ពី Hugging Face Hub ឬដោយការទាញយកវត្ថុបុរាណគំរូពី Amazon S3 ។ ប្រសិនបើអ្នកបញ្ជាក់ model_id=defog/sqlcoder-7b-2DJL Serving នឹងព្យាយាមទាញយកម៉ូដែលនេះដោយផ្ទាល់ពី Hugging Face Hub។ ទោះជាយ៉ាងណាក៏ដោយ អ្នកអាចនឹងទទួលរងការគិតថ្លៃចូល/ការបញ្ចូលបណ្តាញ រាល់ពេលដែលចំនុចបញ្ចប់ត្រូវបានដាក់ពង្រាយ ឬធ្វើមាត្រដ្ឋានយឺត។ ដើម្បីជៀសវាងការគិតថ្លៃទាំងនេះ និងអាចបង្កើនល្បឿនទាញយកវត្ថុបុរាណគំរូ វាត្រូវបានណែនាំឱ្យរំលងការប្រើប្រាស់ model_id in serving.properties និងរក្សាទុកទម្ងន់គំរូជាវត្ថុបុរាណ S3 ហើយបញ្ជាក់ពួកវាជាមួយ s3url=s3://path/to/model/bin.
ការរក្សាទុកគំរូមួយ (ជាមួយនឹងសញ្ញាសម្គាល់របស់វា) ទៅក្នុងថាស ហើយបង្ហោះវាទៅ Amazon S3 អាចត្រូវបានសម្រេចដោយគ្រាន់តែបន្ទាត់មួយចំនួននៃកូដ៖
អ្នកក៏ប្រើឯកសារប្រអប់បញ្ចូលមូលដ្ឋានទិន្នន័យផងដែរ។ នៅក្នុងការរៀបចំនេះ ប្រអប់បញ្ចូលទិន្នន័យត្រូវបានផ្សំឡើងដោយ Task, Instructions, Database Schemaនិង Answer sections. សម្រាប់ស្ថាបត្យកម្មបច្ចុប្បន្ន យើងបែងចែកឯកសារប្រអប់បញ្ចូលដាច់ដោយឡែកសម្រាប់គ្រោងការណ៍មូលដ្ឋានទិន្នន័យនីមួយៗ។ ទោះយ៉ាងណាក៏ដោយ មានភាពបត់បែនក្នុងការពង្រីកការដំឡើងនេះ ដើម្បីរួមបញ្ចូលមូលដ្ឋានទិន្នន័យជាច្រើនក្នុងមួយឯកសារភ្លាមៗ ដែលអនុញ្ញាតឱ្យម៉ូដែលដំណើរការសមាសធាតុផ្សំឆ្លងកាត់មូលដ្ឋានទិន្នន័យនៅលើម៉ាស៊ីនមេតែមួយ។ ក្នុងដំណាក់កាលបង្កើតគំរូរបស់យើង យើងរក្សាទុកប្រអប់បញ្ចូលទិន្នន័យជាឯកសារអត្ថបទដែលមានឈ្មោះ <Database-Glue-Connection-Name>.prompt, ដែលជាកន្លែងដែល Database-Glue-Connection-Name ទាក់ទងទៅនឹងឈ្មោះការតភ្ជាប់ដែលអាចមើលឃើញនៅក្នុងបរិស្ថាន JupyterLab របស់អ្នក។ ជាឧទាហរណ៍ ការបង្ហោះនេះសំដៅទៅលើការភ្ជាប់ Snowflake ដែលមានឈ្មោះថា Airlines_Datasetដូច្នេះ ឯកសារប្រអប់បញ្ចូលមូលដ្ឋានទិន្នន័យត្រូវបានដាក់ឈ្មោះ Airlines_Dataset.prompt. បន្ទាប់មកឯកសារនេះត្រូវបានរក្សាទុកនៅលើ Amazon S3 ហើយត្រូវបានអាន និងរក្សាទុកជាបន្តបន្ទាប់ដោយគំរូរបស់យើងដែលបម្រើតក្កវិជ្ជា។
ជាងនេះទៅទៀត ស្ថាបត្យកម្មនេះអនុញ្ញាតឱ្យអ្នកប្រើប្រាស់ដែលមានការអនុញ្ញាតណាមួយនៃចំណុចបញ្ចប់នេះដើម្បីកំណត់ រក្សាទុក និងបង្កើតភាសាធម្មជាតិចំពោះសំណួរ SQL ដោយមិនចាំបាច់មានការប្រើប្រាស់ឡើងវិញច្រើននៃគំរូនោះទេ។ យើងប្រើដូចខាងក្រោម ឧទាហរណ៍នៃប្រអប់បញ្ចូលទិន្នន័យ ដើម្បីបង្ហាញពីមុខងារ Text-to-SQL ។
បន្ទាប់មក អ្នកបង្កើតតក្កវិជ្ជាសេវាកម្មគំរូផ្ទាល់ខ្លួន។ នៅក្នុងផ្នែកនេះ អ្នកគូសបញ្ជាក់អំពីតក្កវិជ្ជាសន្និដ្ឋានផ្ទាល់ខ្លួនដែលមានឈ្មោះ model.py. ស្គ្រីបនេះត្រូវបានរចនាឡើងដើម្បីបង្កើនប្រសិទ្ធភាពប្រតិបត្តិការ និងការរួមបញ្ចូលនៃសេវាកម្ម Text-to-SQL របស់យើង៖
- កំណត់តក្កវិជ្ជាឃ្លាំងផ្ទុកឯកសារប្រអប់បញ្ចូលទិន្នន័យ - ដើម្បីកាត់បន្ថយភាពយឺតយ៉ាវ យើងអនុវត្តតក្កវិជ្ជាផ្ទាល់ខ្លួនសម្រាប់ការទាញយក និងរក្សាទុកឯកសារប្រអប់បញ្ចូលក្នុងឃ្លាំងសម្ងាត់។ យន្តការនេះធ្វើឱ្យប្រាកដថាការជម្រុញអាចរកបានយ៉ាងងាយស្រួល ដោយកាត់បន្ថយការចំណាយលើសដែលទាក់ទងនឹងការទាញយកញឹកញាប់។
- កំណត់តក្កវិជ្ជាការសន្និដ្ឋានគំរូផ្ទាល់ខ្លួន - ដើម្បីបង្កើនល្បឿននៃការសន្និដ្ឋាន គំរូអត្ថបទទៅ SQL របស់យើងត្រូវបានផ្ទុកក្នុងទម្រង់ភាពជាក់លាក់ float16 ហើយបន្ទាប់មកបម្លែងទៅជាគំរូ DeepSpeed ។ ជំហាននេះអនុញ្ញាតឱ្យការគណនាកាន់តែមានប្រសិទ្ធភាព។ លើសពីនេះ នៅក្នុងតក្កវិជ្ជានេះ អ្នកបញ្ជាក់ប៉ារ៉ាម៉ែត្រណាដែលអ្នកប្រើប្រាស់អាចកែតម្រូវបានក្នុងអំឡុងពេលហៅការសន្និដ្ឋាន ដើម្បីកែសម្រួលមុខងារតាមតម្រូវការរបស់ពួកគេ។
- កំណត់តក្កវិជ្ជាបញ្ចូល និងលទ្ធផលផ្ទាល់ខ្លួន - ការបង្កើតទម្រង់បញ្ចូល/ទិន្នផលច្បាស់លាស់ និងតាមតម្រូវការគឺចាំបាច់សម្រាប់ការរួមបញ្ចូលយ៉ាងរលូនជាមួយកម្មវិធីខាងក្រោម។ កម្មវិធីមួយបែបនេះគឺ JupyterAI ដែលយើងពិភាក្សានៅក្នុងផ្នែកបន្តបន្ទាប់។
លើសពីនេះទៀត យើងរួមបញ្ចូល ក serving.properties ឯកសារដែលដើរតួជាឯកសារកំណត់រចនាសម្ព័ន្ធសកលសម្រាប់ម៉ូដែលដែលបានបង្ហោះដោយប្រើការបម្រើ DJL ។ សម្រាប់ព័ត៌មានបន្ថែម សូមមើល ការកំណត់ និងការកំណត់.
ចុងក្រោយ អ្នកក៏អាចរួមបញ្ចូល a requirements.txt ឯកសារដើម្បីកំណត់ម៉ូឌុលបន្ថែមដែលត្រូវការសម្រាប់ការសន្និដ្ឋាន និងវេចខ្ចប់អ្វីគ្រប់យ៉ាងទៅក្នុង tarball សម្រាប់ដាក់ពង្រាយ។
សូមមើលលេខកូដខាងក្រោម៖
រួមបញ្ចូលចំណុចបញ្ចប់របស់អ្នកជាមួយ SageMaker Studio Jupyter AI ជំនួយការ
Jupyter AI គឺជាឧបករណ៍ប្រភពបើកចំហដែលនាំមកនូវ AI ជំនាន់ថ្មីទៅកាន់សៀវភៅកត់ត្រា Jupyter ដោយផ្តល់ជូននូវវេទិកាដ៏រឹងមាំ និងងាយស្រួលប្រើសម្រាប់ស្វែងរកគំរូ AI ជំនាន់។ វាបង្កើនផលិតភាពនៅក្នុងសៀវភៅកត់ត្រា JupyterLab និង Jupyter ដោយផ្តល់នូវលក្ខណៈពិសេសដូចជា %% ai magic សម្រាប់បង្កើតសួនកុមារ AI ខាងក្នុងសៀវភៅកត់ត្រា UI ជជែកដើមនៅក្នុង JupyterLab សម្រាប់អន្តរកម្មជាមួយ AI ជាជំនួយការសន្ទនា និងការគាំទ្រសម្រាប់អារេដ៏ធំទូលាយនៃ LLMs ពី អ្នកផ្តល់សេវាចូលចិត្ត អាម៉ាហ្សូន Titan, AI21, Anthropic, Cohere, និង Hugging Face ឬសេវាកម្មគ្រប់គ្រងដូចជា ក្រុមហ៊ុន Amazon Bedrock និង SageMaker ចំណុចបញ្ចប់។ សម្រាប់ការប្រកាសនេះ យើងប្រើប្រាស់ការរួមបញ្ចូលក្រៅប្រអប់របស់ Jupyter AI ជាមួយនឹងចំណុចបញ្ចប់ SageMaker ដើម្បីនាំយកសមត្ថភាព Text-to-SQL ទៅក្នុងសៀវភៅកត់ត្រា JupyterLab ។ ឧបករណ៍ Jupyter AI ត្រូវបានដំឡើងជាមុននៅក្នុង SageMaker Studio JupyterLab Spaces ទាំងអស់ដែលគាំទ្រដោយ រូបថតរបស់ SageMaker Distribution; អ្នកប្រើប្រាស់ចុងក្រោយមិនតម្រូវឱ្យធ្វើការកំណត់បន្ថែមណាមួយដើម្បីចាប់ផ្តើមប្រើប្រាស់ផ្នែកបន្ថែម Jupyter AI ដើម្បីរួមបញ្ចូលជាមួយ SageMaker ចំណុចបញ្ចប់ដែលបានបង្ហោះ។ នៅក្នុងផ្នែកនេះ យើងពិភាក្សាអំពីវិធីពីរយ៉ាងក្នុងការប្រើឧបករណ៍ Jupyter AI រួមបញ្ចូលគ្នា។
Jupyter AI នៅខាងក្នុងសៀវភៅកត់ត្រាដោយប្រើវេទមន្ត
Jupyter AI %%ai ពាក្យបញ្ជាវេទមន្តអនុញ្ញាតឱ្យអ្នកបំប្លែងសៀវភៅកត់ត្រា SageMaker Studio JupyterLab របស់អ្នកទៅជាបរិស្ថាន AI ដែលអាចផលិតឡើងវិញបាន។ ដើម្បីចាប់ផ្តើមប្រើវេទមន្ត AI សូមប្រាកដថាអ្នកបានផ្ទុកផ្នែកបន្ថែម jupyter_ai_magics ដើម្បីប្រើ %%ai វេទមន្ត និងលើសពីនេះទៀតផ្ទុក amazon_sagemaker_sql_magic ដើម្បីប្រើ %%sm_sql វេទមន្ត៖
ដើម្បីដំណើរការការហៅទៅកាន់ចំណុចបញ្ចប់ SageMaker របស់អ្នកពីសៀវភៅកត់ត្រារបស់អ្នកដោយប្រើ %%ai ពាក្យបញ្ជាវេទមន្ត ផ្តល់នូវប៉ារ៉ាម៉ែត្រខាងក្រោម និងរៀបចំរចនាសម្ព័ន្ធពាក្យបញ្ជាដូចខាងក្រោមៈ
- - ឈ្មោះតំបន់ - បញ្ជាក់តំបន់ដែលចំណុចបញ្ចប់របស់អ្នកត្រូវបានដាក់ពង្រាយ។ នេះធ្វើឱ្យប្រាកដថាសំណើត្រូវបានបញ្ជូនទៅកាន់ទីតាំងភូមិសាស្ត្រត្រឹមត្រូវ។
- - គ្រោងការណ៍សំណើ - រួមបញ្ចូលគ្រោងការណ៍នៃទិន្នន័យបញ្ចូល។ គ្រោងការណ៍នេះរៀបរាប់អំពីទម្រង់ដែលរំពឹងទុក និងប្រភេទនៃទិន្នន័យបញ្ចូលដែលគំរូរបស់អ្នកត្រូវការដើម្បីដំណើរការសំណើ។
- - ផ្លូវឆ្លើយតប - កំណត់ផ្លូវនៅក្នុងវត្ថុឆ្លើយតបដែលលទ្ធផលនៃគំរូរបស់អ្នកស្ថិតនៅ។ ផ្លូវនេះត្រូវបានប្រើដើម្បីទាញយកទិន្នន័យដែលពាក់ព័ន្ធពីការឆ្លើយតបដែលត្រឡប់ដោយគំរូរបស់អ្នក។
- -f (ស្រេចចិត្ត) - នេះគឺជា ទ្រង់ទ្រាយលទ្ធផល ទង់ដែលបង្ហាញពីប្រភេទនៃទិន្នផលដែលត្រឡប់ដោយគំរូ។ នៅក្នុងបរិបទនៃសៀវភៅកត់ត្រា Jupyter ប្រសិនបើលទ្ធផលគឺជាកូដ ទង់នេះគួរតែត្រូវបានកំណត់ស្របតាមទ្រង់ទ្រាយលទ្ធផលជាកូដដែលអាចប្រតិបត្តិបាននៅផ្នែកខាងលើនៃក្រឡាសៀវភៅ Jupyter អមដោយផ្ទៃបញ្ចូលអត្ថបទឥតគិតថ្លៃសម្រាប់អន្តរកម្មអ្នកប្រើប្រាស់។
ឧទាហរណ៍ ពាក្យបញ្ជានៅក្នុងក្រឡាសៀវភៅ Jupyter អាចមើលទៅដូចកូដខាងក្រោម៖
បង្អួចជជែកកំសាន្ត Jupyter AI
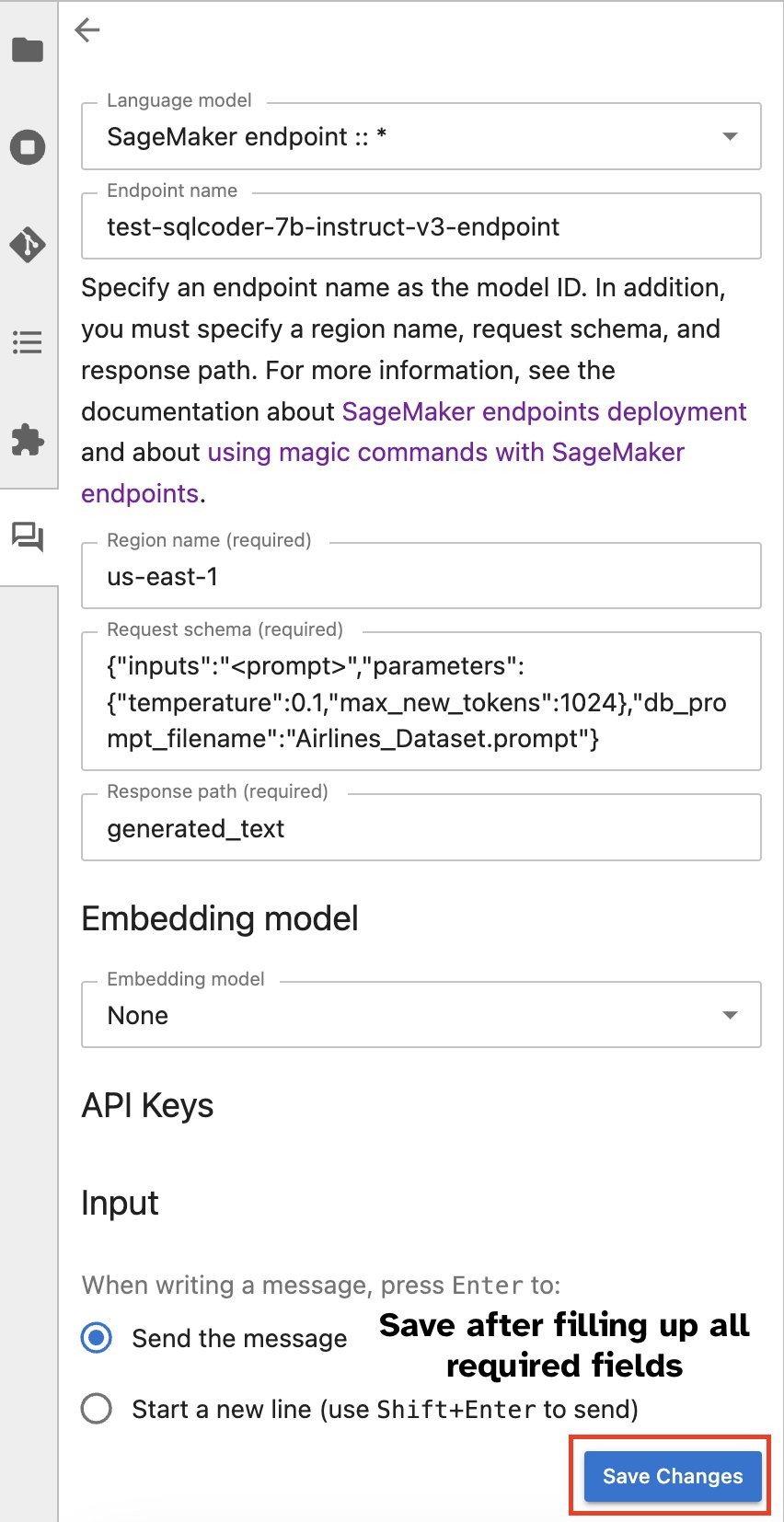
ជាជម្រើស អ្នកអាចធ្វើអន្តរកម្មជាមួយ SageMaker endpoints តាមរយៈចំណុចប្រទាក់អ្នកប្រើដែលភ្ជាប់មកជាមួយ ធ្វើឱ្យដំណើរការនៃការបង្កើតសំណួរ ឬការចូលរួមក្នុងការសន្ទនាកាន់តែងាយស្រួល។ មុនពេលចាប់ផ្តើមជជែកជាមួយចំណុចបញ្ចប់ SageMaker របស់អ្នក កំណត់រចនាសម្ព័ន្ធការកំណត់ដែលពាក់ព័ន្ធនៅក្នុង Jupyter AI សម្រាប់ចំណុចបញ្ចប់ SageMaker ដូចដែលបានបង្ហាញនៅក្នុងរូបថតអេក្រង់ខាងក្រោម។
 |
 |
សន្និដ្ឋាន
ឥឡូវនេះ ស្ទូឌីយោ SageMaker សម្រួល និងសម្រួលលំហូរការងាររបស់អ្នកវិទ្យាសាស្ត្រទិន្នន័យ ដោយបញ្ចូលការគាំទ្រ SQL ទៅក្នុងសៀវភៅកត់ត្រា JupyterLab ។ នេះអនុញ្ញាតឱ្យអ្នកវិទ្យាសាស្ត្រទិន្នន័យផ្តោតលើភារកិច្ចរបស់ពួកគេដោយមិនចាំបាច់គ្រប់គ្រងឧបករណ៍ច្រើន។ លើសពីនេះ ការរួមបញ្ចូល SQL ថ្មីដែលភ្ជាប់មកជាមួយនៅក្នុង SageMaker Studio អនុញ្ញាតឱ្យបុគ្គលទិន្នន័យបង្កើតសំណួរ SQL ដោយមិនចាំបាច់ប្រឹងប្រែងដោយប្រើអត្ថបទភាសាធម្មជាតិជាការបញ្ចូល ដោយហេតុនេះបង្កើនល្បឿនការងាររបស់ពួកគេ។
យើងលើកទឹកចិត្តឱ្យអ្នករុករកលក្ខណៈពិសេសទាំងនេះនៅក្នុង SageMaker Studio ។ សម្រាប់ព័ត៌មានបន្ថែម សូមមើល រៀបចំទិន្នន័យជាមួយ SQL នៅក្នុង Studio.
ឧបសម្ព័ន្ធ
បើកដំណើរការកម្មវិធីរុករក SQL និងក្រឡា SQL សៀវភៅកត់ត្រាក្នុងបរិយាកាសផ្ទាល់ខ្លួន
ប្រសិនបើអ្នកមិនប្រើរូបភាពចែកចាយ SageMaker ឬប្រើរូបភាពចែកចាយ 1.5 ឬទាបជាងនេះទេ សូមដំណើរការពាក្យបញ្ជាខាងក្រោមដើម្បីបើកមុខងាររុករក SQL នៅក្នុងបរិស្ថាន JupyterLab របស់អ្នក៖
ផ្លាស់ប្តូរទីតាំងធាតុក្រាហ្វិកកម្មវិធីរុករក SQL
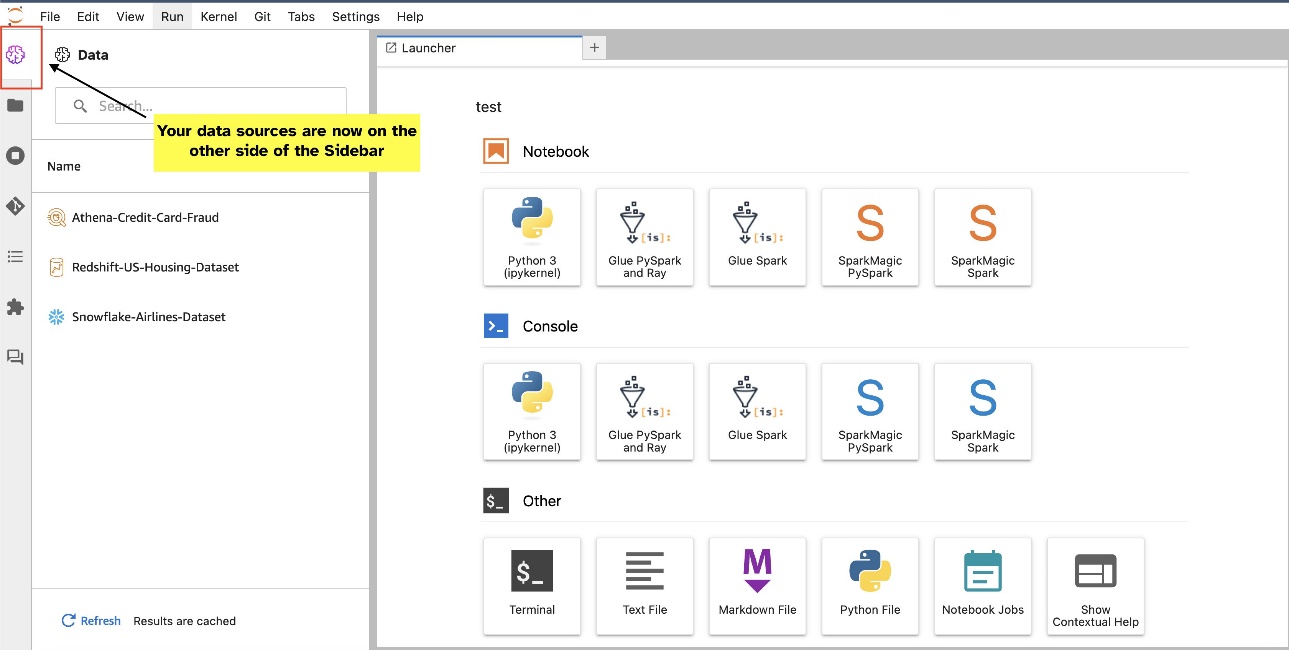
ធាតុក្រាហ្វិក JupyterLab អនុញ្ញាតឱ្យមានការផ្លាស់ប្តូរទីតាំង។ អាស្រ័យលើចំណូលចិត្តរបស់អ្នក អ្នកអាចផ្លាស់ទីធាតុក្រាហ្វិកទៅផ្នែកម្ខាងនៃផ្ទាំងធាតុក្រាហ្វិក JupyterLab ។ ប្រសិនបើអ្នកចូលចិត្ត អ្នកអាចផ្លាស់ទីទិសដៅនៃធាតុក្រាហ្វិក SQL ទៅផ្នែកផ្ទុយ (ពីស្តាំទៅឆ្វេង) នៃរបារចំហៀងដោយចុចកណ្ដុរស្ដាំលើរូបតំណាងធាតុក្រាហ្វិក ហើយជ្រើសរើស ប្តូររបារចំហៀង.
 |
 |
អំពីអ្នកនិពន្ធ
 Pranav Murthy គឺជាស្ថាបត្យករឯកទេសដំណោះស្រាយ AI/ML នៅ AWS។ គាត់ផ្តោតលើការជួយអតិថិជនបង្កើត បណ្តុះបណ្តាល ប្រើប្រាស់ និងផ្ទេរបន្ទុកការងាររបស់ម៉ាស៊ីន (ML) ទៅកាន់ SageMaker ។ ពីមុនគាត់បានធ្វើការនៅក្នុងឧស្សាហកម្ម semiconductor ដែលកំពុងអភិវឌ្ឍចក្ខុវិស័យកុំព្យូទ័រធំ (CV) និងគំរូដំណើរការភាសាធម្មជាតិ (NLP) ដើម្បីកែលម្អដំណើរការ semiconductor ដោយប្រើបច្ចេកទេស ML ទំនើប។ ពេលទំនេរ គាត់ចូលចិត្តលេងអុក និងធ្វើដំណើរកម្សាន្ត។ អ្នកអាចស្វែងរក Pranav នៅលើ LinkedIn.
Pranav Murthy គឺជាស្ថាបត្យករឯកទេសដំណោះស្រាយ AI/ML នៅ AWS។ គាត់ផ្តោតលើការជួយអតិថិជនបង្កើត បណ្តុះបណ្តាល ប្រើប្រាស់ និងផ្ទេរបន្ទុកការងាររបស់ម៉ាស៊ីន (ML) ទៅកាន់ SageMaker ។ ពីមុនគាត់បានធ្វើការនៅក្នុងឧស្សាហកម្ម semiconductor ដែលកំពុងអភិវឌ្ឍចក្ខុវិស័យកុំព្យូទ័រធំ (CV) និងគំរូដំណើរការភាសាធម្មជាតិ (NLP) ដើម្បីកែលម្អដំណើរការ semiconductor ដោយប្រើបច្ចេកទេស ML ទំនើប។ ពេលទំនេរ គាត់ចូលចិត្តលេងអុក និងធ្វើដំណើរកម្សាន្ត។ អ្នកអាចស្វែងរក Pranav នៅលើ LinkedIn.
 វ៉ារុនសា គឺជាវិស្វករផ្នែកទន់ដែលធ្វើការនៅ Amazon SageMaker Studio នៅ Amazon Web Services ។ គាត់ផ្តោតលើការកសាងដំណោះស្រាយ ML អន្តរកម្មដែលសម្រួលដំណើរការទិន្នន័យ និងដំណើររៀបចំទិន្នន័យ។ ពេលទំនេរ វ៉ារុន ចូលចិត្តសកម្មភាពក្រៅផ្ទះ រួមទាំងការឡើងភ្នំ និងជិះស្គី ហើយតែងតែស្វែងរកកន្លែងថ្មីៗ និងគួរឱ្យរំភើប។
វ៉ារុនសា គឺជាវិស្វករផ្នែកទន់ដែលធ្វើការនៅ Amazon SageMaker Studio នៅ Amazon Web Services ។ គាត់ផ្តោតលើការកសាងដំណោះស្រាយ ML អន្តរកម្មដែលសម្រួលដំណើរការទិន្នន័យ និងដំណើររៀបចំទិន្នន័យ។ ពេលទំនេរ វ៉ារុន ចូលចិត្តសកម្មភាពក្រៅផ្ទះ រួមទាំងការឡើងភ្នំ និងជិះស្គី ហើយតែងតែស្វែងរកកន្លែងថ្មីៗ និងគួរឱ្យរំភើប។
 Sumedha Swamy គឺជាអ្នកគ្រប់គ្រងផលិតផលចម្បងនៅ Amazon Web Services ជាកន្លែងដែលគាត់ដឹកនាំក្រុម SageMaker Studio ក្នុងបេសកកម្មរបស់ខ្លួនក្នុងការអភិវឌ្ឍន៍ IDE នៃជម្រើសសម្រាប់វិទ្យាសាស្ត្រទិន្នន័យ និងការរៀនម៉ាស៊ីន។ គាត់បានឧទ្ទិសដល់ 15 ឆ្នាំកន្លងមកក្នុងការបង្កើតផលិតផលប្រើប្រាស់ និងសហគ្រាសដែលមានមូលដ្ឋានលើ Machine Learning ។
Sumedha Swamy គឺជាអ្នកគ្រប់គ្រងផលិតផលចម្បងនៅ Amazon Web Services ជាកន្លែងដែលគាត់ដឹកនាំក្រុម SageMaker Studio ក្នុងបេសកកម្មរបស់ខ្លួនក្នុងការអភិវឌ្ឍន៍ IDE នៃជម្រើសសម្រាប់វិទ្យាសាស្ត្រទិន្នន័យ និងការរៀនម៉ាស៊ីន។ គាត់បានឧទ្ទិសដល់ 15 ឆ្នាំកន្លងមកក្នុងការបង្កើតផលិតផលប្រើប្រាស់ និងសហគ្រាសដែលមានមូលដ្ឋានលើ Machine Learning ។
 Bosco Albuquerque គឺជា Sr. Partner Solutions Architect នៅ AWS ហើយមានបទពិសោធន៍ជាង 20 ឆ្នាំដែលធ្វើការជាមួយមូលដ្ឋានទិន្នន័យ និងផលិតផលវិភាគពីអ្នកលក់មូលដ្ឋានទិន្នន័យសហគ្រាស និងអ្នកផ្តល់សេវាពពក។ គាត់បានជួយក្រុមហ៊ុនបច្ចេកវិទ្យាក្នុងការរចនា និងអនុវត្តដំណោះស្រាយនិងផលិតផលវិភាគទិន្នន័យ។
Bosco Albuquerque គឺជា Sr. Partner Solutions Architect នៅ AWS ហើយមានបទពិសោធន៍ជាង 20 ឆ្នាំដែលធ្វើការជាមួយមូលដ្ឋានទិន្នន័យ និងផលិតផលវិភាគពីអ្នកលក់មូលដ្ឋានទិន្នន័យសហគ្រាស និងអ្នកផ្តល់សេវាពពក។ គាត់បានជួយក្រុមហ៊ុនបច្ចេកវិទ្យាក្នុងការរចនា និងអនុវត្តដំណោះស្រាយនិងផលិតផលវិភាគទិន្នន័យ។
- SEO ដែលដំណើរការដោយមាតិកា និងការចែកចាយ PR ។ ទទួលបានការពង្រីកថ្ងៃនេះ។
- PlatoData.Network Vertical Generative Ai. ផ្តល់អំណាចដល់ខ្លួនអ្នក។ ចូលប្រើទីនេះ។
- PlatoAiStream Web3 Intelligence ។ ចំណេះដឹងត្រូវបានពង្រីក។ ចូលប្រើទីនេះ។
- ផ្លាតូអេសជី។ កាបូន CleanTech, ថាមពល, បរិស្ថាន, ពន្លឺព្រះអាទិត្យ ការគ្រប់គ្រងកាកសំណល់។ ចូលប្រើទីនេះ។
- ផ្លាតូសុខភាព។ ជីវបច្ចេកវិទ្យា និង ភាពវៃឆ្លាត សាកល្បងគ្លីនិក។ ចូលប្រើទីនេះ។
- ប្រភព: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

