សម្រាប់ការបង្កើតកម្មវិធី AI ជំនាន់ណាមួយ ការពង្រឹងគំរូភាសាធំ (LLMs) ជាមួយនឹងទិន្នន័យថ្មីគឺជាការចាំបាច់។ នេះគឺជាកន្លែងដែលបច្ចេកទេស Retrieval Augmented Generation (RAG) ចូលមក។ RAG គឺជាស្ថាបត្យកម្ម machine learning (ML) ដែលប្រើឯកសារខាងក្រៅ (ដូចជា Wikipedia) ដើម្បីបង្កើនចំនេះដឹងរបស់វា និងសម្រេចបាននូវលទ្ធផលចុងក្រោយបង្អស់លើការងារដែលពឹងផ្អែកលើចំណេះដឹង។ . សម្រាប់ការបញ្ចូលប្រភពទិន្នន័យខាងក្រៅទាំងនេះ មូលដ្ឋានទិន្នន័យវ៉ិចទ័របានវិវត្ត ដែលអាចរក្សាទុកការបង្កប់វ៉ិចទ័រនៃប្រភពទិន្នន័យ និងអនុញ្ញាតឱ្យស្វែងរកភាពស្រដៀងគ្នា។
នៅក្នុងការបង្ហោះនេះ យើងបង្ហាញពីរបៀបបង្កើត RAG extract, transform, and load (ETL) pipeline ingestion pipeline ដើម្បីបញ្ចូលទិន្នន័យយ៉ាងច្រើនទៅក្នុង សេវាកម្ម Amazon OpenSearch ចង្កោមនិងប្រើប្រាស់ សេវាកម្មមូលដ្ឋានទិន្នន័យទំនាក់ទំនង Amazon (Amazon RDS) សម្រាប់ PostgreSQL ជាមួយផ្នែកបន្ថែម pgvector ជាកន្លែងផ្ទុកទិន្នន័យវ៉ិចទ័រ។ សេវាកម្មនីមួយៗអនុវត្ត k-nearest neighbor (k-NN) ឬប្រហាក់ប្រហែលជិតបំផុតជិតបំផុត (ANN) algorithms និងម៉ែត្រចម្ងាយដើម្បីគណនាភាពស្រដៀងគ្នា។ យើងណែនាំការរួមបញ្ចូល រ៉េ ចូលទៅក្នុងយន្តការទាញយកឯកសារបរិបទ RAG ។ រ៉េគឺជាប្រភពបើកចំហ Python គោលបំណងទូទៅ បណ្ណាល័យកុំព្យូទ័រដែលបានចែកចាយ។ វាអនុញ្ញាតឱ្យដំណើរការទិន្នន័យចែកចាយដើម្បីបង្កើត និងរក្សាទុកការបង្កប់សម្រាប់ទិន្នន័យមួយចំនួនធំ ស្របគ្នានឹង GPUs ជាច្រើន។ យើងប្រើចង្កោម Ray ជាមួយ GPUs ទាំងនេះដើម្បីដំណើរការការបញ្ចូល និងសំណួរស្របគ្នាសម្រាប់សេវាកម្មនីមួយៗ។
នៅក្នុងការពិសោធន៍នេះ យើងព្យាយាមវិភាគទិដ្ឋភាពខាងក្រោមសម្រាប់សេវាកម្ម OpenSearch និងផ្នែកបន្ថែម pgvector នៅលើ Amazon RDS៖
- ក្នុងនាមជាហាងវ៉ិចទ័រ សមត្ថភាពក្នុងការធ្វើមាត្រដ្ឋាន និងដោះស្រាយសំណុំទិន្នន័យដ៏ធំមួយដែលមានកំណត់ត្រារាប់សិបលានសម្រាប់ RAG
- ការស្ទះដែលអាចកើតមាននៅក្នុងបំពង់បង្ហូរចូលសម្រាប់ RAG
- របៀបដើម្បីសម្រេចបាននូវការអនុវត្តដ៏ល្អប្រសើរនៅក្នុងការបញ្ចូល និងពេលវេលាទាញយកសំណួរសម្រាប់ OpenSearch Service និង Amazon RDS
ដើម្បីស្វែងយល់បន្ថែមអំពីឃ្លាំងទិន្នន័យវ៉ិចទ័រ និងតួនាទីរបស់ពួកគេក្នុងការបង្កើតកម្មវិធី AI ជំនាន់នោះ សូមយោងទៅ តួនាទីនៃឃ្លាំងទិន្នន័យវ៉ិចទ័រនៅក្នុងកម្មវិធី AI ជំនាន់.
ទិដ្ឋភាពទូទៅនៃសេវាកម្ម OpenSearch
សេវាកម្ម OpenSearch គឺជាសេវាកម្មគ្រប់គ្រងសម្រាប់ការវិភាគ ការស្វែងរក និងការធ្វើលិបិក្រមនៃទិន្នន័យអាជីវកម្ម និងប្រតិបត្តិការប្រកបដោយសុវត្ថិភាព។ សេវាកម្ម OpenSearch គាំទ្រទិន្នន័យទំហំ petabyte ជាមួយនឹងសមត្ថភាពក្នុងការបង្កើតលិបិក្រមជាច្រើននៅលើទិន្នន័យអត្ថបទ និងវ៉ិចទ័រ។ ជាមួយនឹងការកំណត់រចនាសម្ព័ន្ធដែលបានធ្វើឱ្យប្រសើរឡើង វាមានគោលបំណងសម្រាប់ការប្រមូលឡើងវិញខ្ពស់សម្រាប់សំណួរ។ សេវាកម្ម OpenSearch គាំទ្រ ANN ក៏ដូចជាការស្វែងរក k-NN ពិតប្រាកដ។ សេវាកម្ម OpenSearch គាំទ្រជម្រើសនៃក្បួនដោះស្រាយពី NMSLIB, FAISSនិង លូសិន បណ្ណាល័យដើម្បីផ្តល់ថាមពលដល់ការស្វែងរក k-NN ។ យើងបានបង្កើតសន្ទស្សន៍ ANN សម្រាប់ OpenSearch ជាមួយនឹងក្បួនដោះស្រាយ Hierarchical Navigable Small World (HNSW) ព្រោះវាត្រូវបានចាត់ទុកថាជាវិធីសាស្ត្រស្វែងរកប្រសើរជាងមុនសម្រាប់សំណុំទិន្នន័យធំ។ សម្រាប់ព័ត៌មានបន្ថែមអំពីជម្រើសនៃក្បួនដោះស្រាយលិបិក្រម សូមមើល ជ្រើសរើសក្បួនដោះស្រាយ k-NN សម្រាប់ករណីប្រើប្រាស់ខ្នាតធំរបស់អ្នកជាមួយ OpenSearch.
ទិដ្ឋភាពទូទៅនៃ Amazon RDS សម្រាប់ PostgreSQL ជាមួយ pgvector
ផ្នែកបន្ថែម pgvector បន្ថែមការស្វែងរកវ៉ិចទ័រប្រភពបើកចំហទៅ PostgreSQL ។ តាមរយៈការប្រើប្រាស់ផ្នែកបន្ថែម pgvector PostgreSQL អាចធ្វើការស្វែងរកស្រដៀងគ្នាលើការបង្កប់វ៉ិចទ័រ ដោយផ្តល់ឱ្យអាជីវកម្មនូវដំណោះស្រាយរហ័ស និងស្ទាត់ជំនាញ។ pgvector ផ្តល់នូវការស្វែងរកភាពស្រដៀងគ្នានៃវ៉ិចទ័រពីរប្រភេទ៖ អ្នកជិតខាងពិតប្រាកដដែលនៅជិតបំផុតដែលលទ្ធផលជាមួយនឹងការប្រមូលមកវិញ 100% និងអ្នកជិតខាងដែលនៅជិតបំផុត (ANN) ដែលផ្តល់នូវប្រសិទ្ធភាពប្រសើរជាងការស្វែងរកពិតប្រាកដជាមួយនឹងការដោះដូរលើការហៅមកវិញ។ សម្រាប់ការស្វែងរកនៅលើលិបិក្រម អ្នកអាចជ្រើសរើសចំនួនមជ្ឈមណ្ឌលដែលត្រូវប្រើក្នុងការស្វែងរក ដោយមានមជ្ឈមណ្ឌលជាច្រើនទៀតផ្តល់នូវការរំលឹកឡើងវិញបានប្រសើរជាងមុនជាមួយនឹងការដោះដូរនៃការអនុវត្ត។
ទិដ្ឋភាពទូទៅនៃដំណោះស្រាយ
ដ្យាក្រាមខាងក្រោមបង្ហាញពីស្ថាបត្យកម្មដំណោះស្រាយ។

សូមក្រឡេកមើលសមាសធាតុសំខាន់ៗដោយលំអិត។
សំណុំទិន្នន័យ
យើងប្រើទិន្នន័យ OSCAR ជាអង្គភាពរបស់យើង និងសំណុំទិន្នន័យ SQUAD ដើម្បីផ្តល់សំណួរគំរូ។ សំណុំទិន្នន័យទាំងនេះដំបូងត្រូវបានបំប្លែងទៅជាឯកសារ Parquet ។ បន្ទាប់មកយើងប្រើ Ray cluster ដើម្បីបំប្លែងទិន្នន័យ Parquet ទៅជាការបង្កប់។ ការបង្កប់ដែលបានបង្កើតត្រូវបានបញ្ចូលទៅក្នុងសេវាកម្ម OpenSearch និង Amazon RDS ជាមួយ pgvector ។
OSCAR (Open Super-large Crawled Aggregated Corpus) គឺជាសាកសពពហុភាសាដ៏ធំមួយដែលទទួលបានដោយការចាត់ថ្នាក់ភាសា និងការត្រងនៃ ក្អែកធម្មតា សាកសពដោយប្រើ មិនស្មោះត្រង់ ស្ថាបត្យកម្ម។ ទិន្នន័យត្រូវបានចែកចាយតាមភាសាទាំងទម្រង់ដើម និងទម្រង់ចម្លង។ សំណុំទិន្នន័យ Oscar Corpus គឺប្រហែល 609 លានកំណត់ត្រា ហើយយកប្រហែល 4.5 TB ជាឯកសារ JSONL ឆៅ។ បន្ទាប់មកឯកសារ JSONL ត្រូវបានបំប្លែងទៅជាទម្រង់ Parquet ដែលកាត់បន្ថយទំហំសរុបមកត្រឹម 1.8 TB។ យើងបានធ្វើមាត្រដ្ឋានសំណុំទិន្នន័យចុះមកត្រឹម 25 លានកំណត់ត្រា ដើម្បីសន្សំពេលពេលបញ្ចូល។
SQuAD (សំណុំទិន្នន័យចម្លើយសំណួរស្ទែនហ្វដ) គឺជាសំណុំទិន្នន័យនៃការអានដែលយល់ច្បាស់ដែលមានសំណួរដែលដាក់ដោយបុគ្គលិកហ្វូងមនុស្សនៅលើសំណុំនៃអត្ថបទវិគីភីឌា ដែលចម្លើយចំពោះរាល់សំណួរគឺជាផ្នែកនៃអត្ថបទ ឬ spanពីវគ្គនៃការអានដែលត្រូវគ្នា ឬសំណួរប្រហែលជាមិនអាចឆ្លើយបាន។ យើងប្រើ ក្រុម, មានអាជ្ញាប័ណ្ណជា CC-BY-SA 4.0 ដើម្បីផ្តល់សំណួរគំរូ។ វាមានសំណួរប្រហែល 100,000 ជាមួយនឹងសំណួរដែលមិនអាចឆ្លើយបានជាង 50,000 ដែលសរសេរដោយបុគ្គលិកហ្វូងមនុស្សដើម្បីឱ្យមើលទៅស្រដៀងទៅនឹងសំណួរដែលអាចឆ្លើយបាន។
ចង្កោមកាំរស្មីសម្រាប់ការបញ្ចូល និងបង្កើតការបង្កប់វ៉ិចទ័រ
នៅក្នុងការធ្វើតេស្តរបស់យើង យើងបានរកឃើញថា GPUs ធ្វើឱ្យមានផលប៉ះពាល់ដ៏ធំបំផុតដល់ដំណើរការនៅពេលបង្កើតការបង្កប់។ ដូច្នេះហើយ យើងបានសម្រេចចិត្តប្រើ Ray cluster ដើម្បីបំប្លែងអត្ថបទដើមរបស់យើង និងបង្កើតការបង្កប់។ រ៉េ គឺជាក្របខ័ណ្ឌគណនាបង្រួបបង្រួមប្រភពបើកចំហដែលអាចឱ្យវិស្វករ ML និងអ្នកអភិវឌ្ឍន៍ Python ធ្វើមាត្រដ្ឋានកម្មវិធី Python និងបង្កើនល្បឿនការងារ ML ។ ចង្កោមរបស់យើងមាន 5 g4dn.12xlarge ក្រុមហ៊ុនអេលហ្សិកអេលហ្វីលីពក្លោត (Amazon EC2) ឧទាហរណ៍។ វត្ថុនីមួយៗត្រូវបានកំណត់រចនាសម្ព័ន្ធជាមួយ GPU NVIDIA T4 Tensor Core ចំនួន 4, 48 vCPU និង 192 GiB នៃអង្គចងចាំ។ សម្រាប់កំណត់ត្រាអត្ថបទរបស់យើង យើងបានបញ្ចប់ការបំបែកនីមួយៗជា 1,000 បំណែកជាមួយនឹងការត្រួតគ្នា 100 កំណាត់។ នេះបំបែកបានប្រហែល 200 ក្នុងមួយកំណត់ត្រា។ សម្រាប់គំរូដែលប្រើដើម្បីបង្កើតការបង្កប់ យើងបានដោះស្រាយ ទាំងអស់-mpnet-base-v2 ដើម្បីបង្កើតទំហំវ៉ិចទ័រ 768 វិមាត្រ។
ការរៀបចំហេដ្ឋារចនាសម្ព័ន្ធ
យើងបានប្រើប្រភេទវត្ថុ RDS ខាងក្រោម និងការកំណត់រចនាសម្ព័ន្ធចង្កោមសេវាកម្ម OpenSearch ដើម្បីរៀបចំហេដ្ឋារចនាសម្ព័ន្ធរបស់យើង។
ខាងក្រោមនេះជាលក្ខណៈសម្បត្តិប្រភេទវត្ថុ RDS របស់យើង៖
- ប្រភេទឧទាហរណ៍៖ db.r7g.12xlarge
- ទំហំផ្ទុកដែលបានបែងចែក៖ 20 TB
- Multi-AZ៖ ពិត
- ឧបករណ៍ផ្ទុកដែលបានអ៊ិនគ្រីប៖ ពិត
- បើកដំណើរការការយល់ដឹងអំពីការអនុវត្ត៖ ពិត
- ការរក្សាការយល់ដឹងអំពីការអនុវត្ត៖ ៧ ថ្ងៃ។
- ប្រភេទផ្ទុក៖ gp3
- IOPS ផ្តល់ជូន៖ 64,000
- ប្រភេទសន្ទស្សន៍៖ IVF
- ចំនួននៃបញ្ជី: 5,000
- មុខងារចម្ងាយ៖ L2
ខាងក្រោមនេះគឺជាលក្ខណៈសម្បត្តិក្រុមសេវាកម្ម OpenSearch របស់យើង៖
- កំណែ: 2.5
- ថ្នាំងទិន្នន័យ៖ ១០
- ប្រភេទឧទាហរណ៍ថ្នាំងទិន្នន័យ៖ r6g.4xlarge
- ថ្នាំងបឋម៖ ៣
- ប្រភេទថ្នាំងបឋម៖ r6g.xlarge
- សន្ទស្សន៍៖ ម៉ាស៊ីន HNSW៖
nmslib - ចន្លោះពេលធ្វើឱ្យស្រស់៖ 30 វិនាទី
ef_construction: 256- m: ១៦
- មុខងារចម្ងាយ៖ L2
យើងបានប្រើការកំណត់រចនាសម្ព័ន្ធធំៗសម្រាប់ទាំងក្រុម OpenSearch Service និង RDS instances ដើម្បីជៀសវាងការជាប់គាំងនៃការអនុវត្ត។
យើងដាក់ដំណោះស្រាយដោយប្រើអេ ឧបករណ៍អភិវឌ្ឍន៍ពពកអេសអេស (AWS CDK) ជង់ដូចដែលបានរៀបរាប់នៅក្នុងផ្នែកខាងក្រោម។
ប្រើជង់ AWS CDK
ជង់ AWS CDK អនុញ្ញាតឱ្យយើងជ្រើសរើសសេវាកម្ម OpenSearch ឬ Amazon RDS សម្រាប់ការបញ្ចូលទិន្នន័យ។
តម្រូវការជាមុន
មុនពេលបន្តការដំឡើង នៅក្រោម cdk, bin, src.tc ផ្លាស់ប្តូរតម្លៃ Boolean សម្រាប់ Amazon RDS និង OpenSearch Service ទៅជាពិត ឬមិនពិត អាស្រ័យលើចំណូលចិត្តរបស់អ្នក។
អ្នកក៏ត្រូវការសេវាភ្ជាប់ផងដែរ។ អត្តសញ្ញាណ AWS និងការគ្រប់គ្រងការចូលប្រើ តួនាទី (IAM) សម្រាប់ដែនសេវាកម្ម OpenSearch ។ សម្រាប់ព័ត៌មានលម្អិត សូមមើល Amazon OpenSearch Service បង្កើតបណ្ណាល័យ. អ្នកក៏អាចដំណើរការពាក្យបញ្ជាខាងក្រោមដើម្បីបង្កើតតួនាទី៖
ជង់ AWS CDK នេះនឹងដាក់ពង្រាយហេដ្ឋារចនាសម្ព័ន្ធដូចខាងក្រោម៖
- VPC
- ម៉ាស៊ីនលោត (នៅខាងក្នុង VPC)
- ចង្កោមសេវាកម្ម OpenSearch (ប្រសិនបើប្រើសេវាកម្ម OpenSearch សម្រាប់ការបញ្ចូល)
- ឧទាហរណ៍ RDS (ប្រសិនបើប្រើ Amazon RDS សម្រាប់ការបញ្ចូល)
- An អ្នកគ្រប់គ្រងប្រព័ន្ធអេ។ អេស។ អេ ឯកសារសម្រាប់ដាក់ពង្រាយក្រុម Ray
- An សេវាកម្មផ្ទុកសាមញ្ញរបស់ក្រុមហ៊ុន Amazon (Amazon S3) ដាក់ធុង
- An កាវអេវ ការងារសម្រាប់បំប្លែងសំណុំទិន្នន័យ OSCAR JSONL ទៅជាឯកសារ Parquet
- ក្រុមហ៊ុន Amazon CloudWatch ផ្ទាំងគ្រប់គ្រង
ទាញយកសំណុំទិន្នន័យ
ដំណើរការពាក្យបញ្ជាខាងក្រោមពីម៉ាស៊ីនលោត៖
មុនពេលក្លូន git repo ត្រូវប្រាកដថាអ្នកមានទម្រង់ Hugging Face និងការចូលប្រើទិន្នន័យ OSCAR ។ អ្នកត្រូវប្រើឈ្មោះអ្នកប្រើ និងពាក្យសម្ងាត់សម្រាប់ក្លូនទិន្នន័យ OSCAR៖
បំលែងឯកសារ JSONL ទៅជា Parquet
ជង់ AWS CDK បានបង្កើតការងារ AWS Glue ETL oscar-jsonl-parquet ដើម្បីបំប្លែងទិន្នន័យ OSCAR ពី JSONL ទៅជាទម្រង់ Parquet។
បន្ទាប់ពីអ្នកដំណើរការឯកសារ oscar-jsonl-parquet ការងារ ឯកសារក្នុងទម្រង់ Parquet គួរតែមាននៅក្រោមថត parquet នៅក្នុងធុង S3 ។
ទាញយកសំណួរ
ពីម៉ាស៊ីនលោតរបស់អ្នក ទាញយកទិន្នន័យសំណួរ ហើយបង្ហោះវាទៅក្នុងធុង S3 របស់អ្នក៖
រៀបចំក្រុម Ray
ជាផ្នែកមួយនៃការដាក់ពង្រាយជង់ AWS CDK យើងបានបង្កើតឯកសារគ្រប់គ្រងប្រព័ន្ធហៅថា CreateRayCluster.
ដើម្បីដំណើរការឯកសារ សូមបំពេញជំហានខាងក្រោម៖
- នៅលើកុងសូល កម្មវិធីគ្រប់គ្រងប្រព័ន្ធ នៅក្រោម ឯកសារ នៅក្នុងផ្ទាំងរុករក សូមជ្រើសរើស កាន់កាប់ដោយខ្ញុំ.
- បើក
CreateRayClusterឯកសារ។ - ជ្រើស រត់.
ទំព័រពាក្យបញ្ជារត់នឹងមានតម្លៃលំនាំដើមដែលត្រូវបានបញ្ចូលសម្រាប់ចង្កោម។
ការកំណត់រចនាសម្ព័ន្ធលំនាំដើមស្នើសុំ 5 g4dn.12xlarge ។ ត្រូវប្រាកដថាគណនីរបស់អ្នកមានដែនកំណត់ដើម្បីគាំទ្រវា។ ដែនកំណត់សេវាកម្មដែលពាក់ព័ន្ធគឺកំពុងដំណើរការតាមតម្រូវការ G និង VT ។ លំនាំដើមសម្រាប់នេះគឺ 64 ប៉ុន្តែការកំណត់រចនាសម្ព័ន្ធនេះទាមទារ 240 ស៊ីភីយូ។
- បន្ទាប់ពីអ្នកពិនិត្យមើលការកំណត់រចនាសម្ព័ន្ធចង្កោម សូមជ្រើសរើសម៉ាស៊ីនលោតជាគោលដៅសម្រាប់ពាក្យបញ្ជារត់។
ពាក្យបញ្ជានេះនឹងអនុវត្តជំហានដូចខាងក្រោមៈ
- ចម្លងឯកសារក្រុម Ray
- រៀបចំក្រុម Ray
- ដំឡើងសន្ទស្សន៍សេវាកម្ម OpenSearch
- រៀបចំតារាង RDS
អ្នកអាចត្រួតពិនិត្យលទ្ធផលនៃពាក្យបញ្ជានៅលើកុងសូលកម្មវិធីគ្រប់គ្រងប្រព័ន្ធ។ ដំណើរការនេះនឹងចំណាយពេល 10-15 នាទីសម្រាប់ការចាប់ផ្តើមដំបូង។
ដំណើរការការបញ្ចូល
ពីម៉ាស៊ីនលោត សូមភ្ជាប់ទៅក្រុម Ray៖
ជាលើកដំបូងដែលភ្ជាប់ទៅម៉ាស៊ីនសូមដំឡើងតម្រូវការ។ ឯកសារទាំងនេះគួរតែមានវត្តមាននៅលើថ្នាំងក្បាលរួចហើយ។
សម្រាប់វិធីសាស្រ្តណាមួយនៃការបញ្ចូល ប្រសិនបើអ្នកទទួលបានកំហុសដូចខាងក្រោម វាទាក់ទងនឹងលិខិតសម្គាល់ដែលផុតកំណត់។ ដំណោះស្រាយបច្ចុប្បន្ន (តាមការសរសេរនេះ) គឺត្រូវដាក់ឯកសារបញ្ជាក់អត្តសញ្ញាណនៅក្នុងថ្នាំងក្បាល Ray ។ ដើម្បីជៀសវាងហានិភ័យសុវត្ថិភាព កុំប្រើអ្នកប្រើប្រាស់ IAM សម្រាប់ការផ្ទៀងផ្ទាត់នៅពេលបង្កើតកម្មវិធីដែលបង្កើតដោយគោលបំណង ឬធ្វើការជាមួយទិន្នន័យពិត។ ជំនួសមកវិញ សូមប្រើសហព័ន្ធជាមួយអ្នកផ្តល់អត្តសញ្ញាណដូចជា AWS IAM Identity Center (អ្នកបន្តទៅ AWS Single Sign-On).
ជាធម្មតា អត្តសញ្ញាណប័ណ្ណត្រូវបានរក្សាទុកក្នុងឯកសារ ~/.aws/credentials នៅលើប្រព័ន្ធ Linux និង macOS និង %USERPROFILE%.awscredentials នៅលើ Windows ប៉ុន្តែទាំងនេះគឺជាព័ត៌មានបញ្ជាក់រយៈពេលខ្លីជាមួយនឹងនិមិត្តសញ្ញាសម័យ។ អ្នកក៏មិនអាចបដិសេធឯកសារអត្តសញ្ញាណលំនាំដើមបានដែរ ដូច្នេះហើយអ្នកត្រូវបង្កើតព័ត៌មានសម្ងាត់រយៈពេលវែងដោយគ្មានសញ្ញាសម្ងាត់សម័យដោយប្រើអ្នកប្រើ IAM ថ្មី។
ដើម្បីបង្កើតព័ត៌មានសម្ងាត់រយៈពេលវែង អ្នកត្រូវបង្កើតសោចូលប្រើ AWS និងសោចូលសម្ងាត់ AWS ។ អ្នកអាចធ្វើវាបានពីកុងសូល IAM ។ សម្រាប់ការណែនាំ សូមមើល ផ្ទៀងផ្ទាត់ជាមួយព័ត៌មានអត្តសញ្ញាណអ្នកប្រើប្រាស់ IAM.
បន្ទាប់ពីអ្នកបង្កើតសោ សូមភ្ជាប់ទៅម៉ាស៊ីនលោតដោយប្រើ កម្មវិធីគ្រប់គ្រងសម័យសមត្ថភាពរបស់ Systems Manager ហើយដំណើរការពាក្យបញ្ជាខាងក្រោម៖
ឥឡូវនេះអ្នកអាចដំណើរការជំហាននៃការបញ្ចូលឡើងវិញ។
បញ្ចូលទិន្នន័យទៅក្នុងសេវាកម្ម OpenSearch
ប្រសិនបើអ្នកកំពុងប្រើសេវាកម្ម OpenSearch សូមដំណើរការស្គ្រីបខាងក្រោមដើម្បីបញ្ចូលឯកសារ៖
នៅពេលវាបញ្ចប់ សូមដំណើរការស្គ្រីបដែលដំណើរការសំណួរក្លែងធ្វើ៖
បញ្ចូលទិន្នន័យទៅក្នុង Amazon RDS
ប្រសិនបើអ្នកកំពុងប្រើ Amazon RDS សូមដំណើរការស្គ្រីបខាងក្រោមដើម្បីបញ្ចូលឯកសារ៖
នៅពេលវាបញ្ចប់ ត្រូវប្រាកដថាដំណើរការម៉ាស៊ីនបូមធូលីពេញលេញនៅលើឧទាហរណ៍ RDS ។
បន្ទាប់មកដំណើរការស្គ្រីបខាងក្រោមដើម្បីដំណើរការសំណួរក្លែងធ្វើ៖
ដំឡើងផ្ទាំងគ្រប់គ្រងរ៉េ
មុននឹងអ្នករៀបចំ Ray dashboard អ្នកគួរតែដំឡើង ចំណុចប្រទាក់បន្ទាត់ពាក្យបញ្ជា AWS (AWS CLI) នៅលើម៉ាស៊ីនមូលដ្ឋានរបស់អ្នក។ សម្រាប់ការណែនាំ សូមមើល ដំឡើង ឬធ្វើបច្ចុប្បន្នភាពកំណែចុងក្រោយបំផុតនៃ AWS CLI.
បំពេញជំហានខាងក្រោមដើម្បីដំឡើងផ្ទាំងគ្រប់គ្រង៖
- ដំឡើង កម្មវិធីជំនួយកម្មវិធីគ្រប់គ្រងសម័យ សម្រាប់ AWS CLI ។
- នៅក្នុងគណនី Isengard ចម្លងព័ត៌មានសម្ងាត់បណ្តោះអាសន្នសម្រាប់ bash/zsh ហើយដំណើរការនៅក្នុងស្ថានីយក្នុងតំបន់របស់អ្នក។
- បង្កើតឯកសារ session.sh នៅក្នុងម៉ាស៊ីនរបស់អ្នក ហើយចម្លងខ្លឹមសារខាងក្រោមទៅឯកសារ៖
- ផ្លាស់ប្តូរថតឯកសារទៅកន្លែងដែលឯកសារ session.sh នេះត្រូវបានរក្សាទុក។
- រត់ពាក្យបញ្ជា
Chmod +xដើម្បីផ្តល់សិទ្ធិប្រតិបត្តិដល់ឯកសារ។ - រត់ពាក្យបញ្ជាដូចខាងក្រោម:
ឧទាហរណ៍:
អ្នកនឹងឃើញសារមួយដូចខាងក្រោម៖
បើកផ្ទាំងថ្មីនៅក្នុងកម្មវិធីរុករករបស់អ្នក ហើយបញ្ចូល localhost:8265។
អ្នកនឹងឃើញផ្ទាំងគ្រប់គ្រង Ray និងស្ថិតិនៃការងារ និងចង្កោមដែលកំពុងដំណើរការ។ អ្នកអាចតាមដានម៉ែត្រពីទីនេះ។
ឧទាហរណ៍ អ្នកអាចប្រើផ្ទាំងគ្រប់គ្រង Ray ដើម្បីសង្កេតមើលការផ្ទុកនៅលើចង្កោម។ ដូចដែលបានបង្ហាញនៅក្នុងរូបថតអេក្រង់ខាងក្រោម កំឡុងពេលបញ្ចូល GPUs កំពុងដំណើរការជិតដល់ 100% នៃការប្រើប្រាស់។
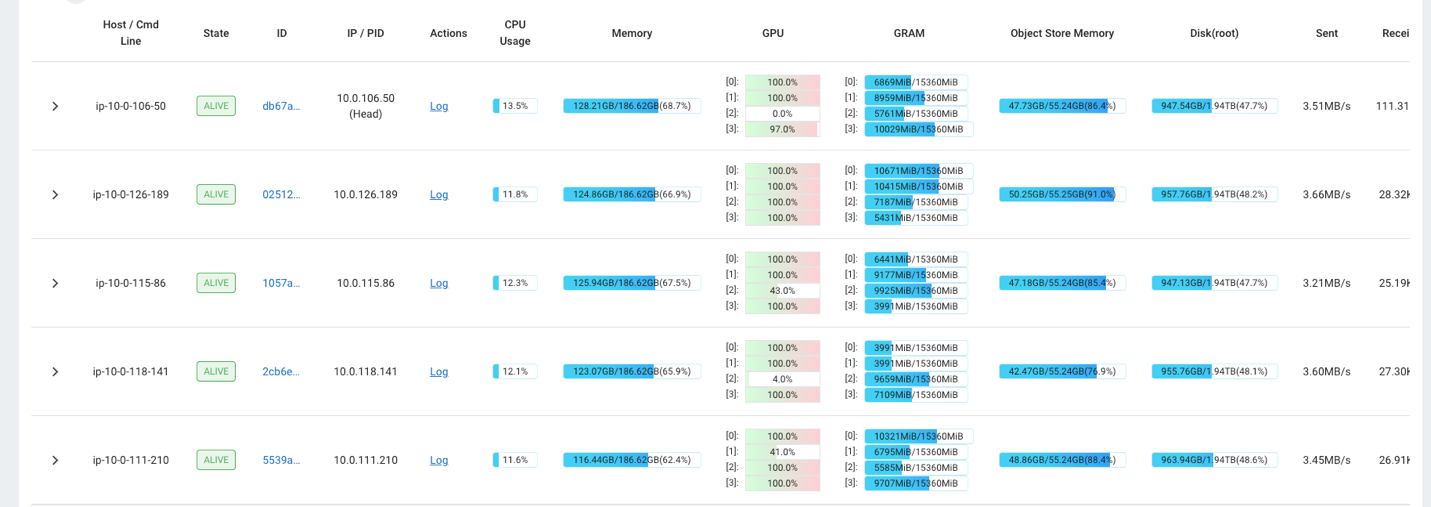
អ្នកអាចប្រើ RAG_Benchmarks ផ្ទាំងគ្រប់គ្រង CloudWatch ដើម្បីមើលអត្រាបញ្ចូល និងពេលវេលាឆ្លើយតបសំណួរ។
ការពង្រីកនៃដំណោះស្រាយ
អ្នកអាចពង្រីកដំណោះស្រាយនេះដើម្បីដោតនៅក្នុង AWS ឬហាងវ៉ិចទ័រភាគីទីបីផ្សេងទៀត។ សម្រាប់រាល់ហាងវ៉ិចទ័រថ្មី អ្នកនឹងត្រូវបង្កើតស្គ្រីបសម្រាប់កំណត់រចនាសម្ព័ន្ធឃ្លាំងទិន្នន័យ ក៏ដូចជាការបញ្ចូលទិន្នន័យផងដែរ។ បំពង់ដែលនៅសល់អាចប្រើឡើងវិញតាមតម្រូវការ។
សន្និដ្ឋាន
នៅក្នុងការបង្ហោះនេះ យើងបានចែករំលែកនូវបំពង់ ETL ដែលអ្នកអាចប្រើដើម្បីដាក់ទិន្នន័យ Vectorized RAG នៅក្នុងសេវាកម្ម OpenSearch ក៏ដូចជា Amazon RDS ជាមួយនឹងផ្នែកបន្ថែម pgvector ជាវ៉ិចទ័រ datastores ។ ដំណោះស្រាយបានប្រើចង្កោម Ray ដើម្បីផ្តល់នូវភាពស្របគ្នាចាំបាច់ក្នុងការបញ្ចូលអង្គធាតុទិន្នន័យធំ។ អ្នកអាចប្រើវិធីសាស្រ្តនេះដើម្បីរួមបញ្ចូលមូលដ្ឋានទិន្នន័យវ៉ិចទ័រណាមួយនៃជម្រើសរបស់អ្នកដើម្បីបង្កើតបំពង់ RAG ។
អំពីនិពន្ធនេះ
 Randy DeFauw គឺជាស្ថាបត្យករដំណោះស្រាយចម្បងជាន់ខ្ពស់នៅ AWS ។ គាត់ទទួលបាន MSEE ពីសាកលវិទ្យាល័យ Michigan ជាកន្លែងដែលគាត់បានធ្វើការលើចក្ខុវិស័យកុំព្យូទ័រសម្រាប់យានយន្តស្វយ័ត។ គាត់ក៏ទទួលបាន MBA ពីសាកលវិទ្យាល័យ Colorado State ផងដែរ។ Randy បានកាន់មុខតំណែងជាច្រើននៅក្នុងផ្នែកបច្ចេកវិទ្យា ចាប់ពីវិស្វកម្មផ្នែកទន់ រហូតដល់ការគ្រប់គ្រងផលិតផល។ គាត់បានចូលទៅក្នុងទំហំទិន្នន័យធំក្នុងឆ្នាំ 2013 ហើយបន្តរុករកតំបន់នោះ។ គាត់កំពុងធ្វើការយ៉ាងសកម្មលើគម្រោងនៅក្នុង ML space ហើយបានបង្ហាញនៅក្នុងសន្និសីទជាច្រើន រួមទាំង Strata និង GlueCon ។
Randy DeFauw គឺជាស្ថាបត្យករដំណោះស្រាយចម្បងជាន់ខ្ពស់នៅ AWS ។ គាត់ទទួលបាន MSEE ពីសាកលវិទ្យាល័យ Michigan ជាកន្លែងដែលគាត់បានធ្វើការលើចក្ខុវិស័យកុំព្យូទ័រសម្រាប់យានយន្តស្វយ័ត។ គាត់ក៏ទទួលបាន MBA ពីសាកលវិទ្យាល័យ Colorado State ផងដែរ។ Randy បានកាន់មុខតំណែងជាច្រើននៅក្នុងផ្នែកបច្ចេកវិទ្យា ចាប់ពីវិស្វកម្មផ្នែកទន់ រហូតដល់ការគ្រប់គ្រងផលិតផល។ គាត់បានចូលទៅក្នុងទំហំទិន្នន័យធំក្នុងឆ្នាំ 2013 ហើយបន្តរុករកតំបន់នោះ។ គាត់កំពុងធ្វើការយ៉ាងសកម្មលើគម្រោងនៅក្នុង ML space ហើយបានបង្ហាញនៅក្នុងសន្និសីទជាច្រើន រួមទាំង Strata និង GlueCon ។
 ដាវីឌ គ្រីស្ទាន គឺជាស្ថាបត្យករដំណោះស្រាយចម្បងដែលមានមូលដ្ឋាននៅរដ្ឋកាលីហ្វ័រញ៉ាខាងត្បូង។ គាត់មានបរិញ្ញាបត្រផ្នែកសន្តិសុខព័ត៌មាន និងចំណង់ចំណូលចិត្តសម្រាប់ស្វ័យប្រវត្តិកម្ម។ ផ្នែកផ្តោតសំខាន់របស់គាត់គឺវប្បធម៌ និងការផ្លាស់ប្តូរ DevOps ហេដ្ឋារចនាសម្ព័ន្ធជាកូដ និងភាពធន់។ មុនពេលចូលរួមជាមួយ AWS គាត់បានកាន់តួនាទីផ្នែកសន្តិសុខ DevOps និងវិស្វកម្មប្រព័ន្ធ គ្រប់គ្រងបរិស្ថានពពកឯកជន និងសាធារណៈខ្នាតធំ។
ដាវីឌ គ្រីស្ទាន គឺជាស្ថាបត្យករដំណោះស្រាយចម្បងដែលមានមូលដ្ឋាននៅរដ្ឋកាលីហ្វ័រញ៉ាខាងត្បូង។ គាត់មានបរិញ្ញាបត្រផ្នែកសន្តិសុខព័ត៌មាន និងចំណង់ចំណូលចិត្តសម្រាប់ស្វ័យប្រវត្តិកម្ម។ ផ្នែកផ្តោតសំខាន់របស់គាត់គឺវប្បធម៌ និងការផ្លាស់ប្តូរ DevOps ហេដ្ឋារចនាសម្ព័ន្ធជាកូដ និងភាពធន់។ មុនពេលចូលរួមជាមួយ AWS គាត់បានកាន់តួនាទីផ្នែកសន្តិសុខ DevOps និងវិស្វកម្មប្រព័ន្ធ គ្រប់គ្រងបរិស្ថានពពកឯកជន និងសាធារណៈខ្នាតធំ។
 Prachi Kulkarni គឺជាស្ថាបត្យករដំណោះស្រាយជាន់ខ្ពស់នៅ AWS ។ ជំនាញរបស់នាងគឺការរៀនម៉ាស៊ីន ហើយនាងកំពុងធ្វើការយ៉ាងសកម្មលើការរចនាដំណោះស្រាយដោយប្រើ AWS ML ទិន្នន័យធំ និងការផ្តល់ជូនវិភាគផ្សេងៗ។ Prachi មានបទពិសោធន៍ក្នុងវិស័យជាច្រើន រួមទាំងការថែទាំសុខភាព អត្ថប្រយោជន៍ ការលក់រាយ និងការអប់រំ ហើយបានធ្វើការក្នុងមុខតំណែងជាច្រើនក្នុងផ្នែកវិស្វកម្មផលិតផល និងស្ថាបត្យកម្ម ការគ្រប់គ្រង និងភាពជោគជ័យរបស់អតិថិជន។
Prachi Kulkarni គឺជាស្ថាបត្យករដំណោះស្រាយជាន់ខ្ពស់នៅ AWS ។ ជំនាញរបស់នាងគឺការរៀនម៉ាស៊ីន ហើយនាងកំពុងធ្វើការយ៉ាងសកម្មលើការរចនាដំណោះស្រាយដោយប្រើ AWS ML ទិន្នន័យធំ និងការផ្តល់ជូនវិភាគផ្សេងៗ។ Prachi មានបទពិសោធន៍ក្នុងវិស័យជាច្រើន រួមទាំងការថែទាំសុខភាព អត្ថប្រយោជន៍ ការលក់រាយ និងការអប់រំ ហើយបានធ្វើការក្នុងមុខតំណែងជាច្រើនក្នុងផ្នែកវិស្វកម្មផលិតផល និងស្ថាបត្យកម្ម ការគ្រប់គ្រង និងភាពជោគជ័យរបស់អតិថិជន។
 រីឆា ហ្គូតា គឺជាដំណោះស្រាយស្ថាបត្យករនៅ AWS ។ នាងមានចំណង់ចំណូលចិត្តលើការបង្កើតដំណោះស្រាយពីចុងដល់ចប់សម្រាប់អតិថិជន។ ឯកទេសរបស់នាងគឺការរៀនម៉ាស៊ីន និងរបៀបដែលវាអាចត្រូវបានប្រើដើម្បីបង្កើតដំណោះស្រាយថ្មីដែលនាំទៅរកភាពល្អឥតខ្ចោះនៃប្រតិបត្តិការ និងជំរុញប្រាក់ចំណូលអាជីវកម្ម។ មុនពេលចូលរួមជាមួយ AWS នាងបានធ្វើការក្នុងសមត្ថភាពរបស់ Software Engineer និង Solutions Architect ដែលបង្កើតដំណោះស្រាយសម្រាប់ប្រតិបត្តិករទូរគមនាគមន៍ធំៗ។ ក្រៅពីការងារ នាងចូលចិត្តស្វែងរកកន្លែងថ្មី និងចូលចិត្តសកម្មភាពផ្សងព្រេង។
រីឆា ហ្គូតា គឺជាដំណោះស្រាយស្ថាបត្យករនៅ AWS ។ នាងមានចំណង់ចំណូលចិត្តលើការបង្កើតដំណោះស្រាយពីចុងដល់ចប់សម្រាប់អតិថិជន។ ឯកទេសរបស់នាងគឺការរៀនម៉ាស៊ីន និងរបៀបដែលវាអាចត្រូវបានប្រើដើម្បីបង្កើតដំណោះស្រាយថ្មីដែលនាំទៅរកភាពល្អឥតខ្ចោះនៃប្រតិបត្តិការ និងជំរុញប្រាក់ចំណូលអាជីវកម្ម។ មុនពេលចូលរួមជាមួយ AWS នាងបានធ្វើការក្នុងសមត្ថភាពរបស់ Software Engineer និង Solutions Architect ដែលបង្កើតដំណោះស្រាយសម្រាប់ប្រតិបត្តិករទូរគមនាគមន៍ធំៗ។ ក្រៅពីការងារ នាងចូលចិត្តស្វែងរកកន្លែងថ្មី និងចូលចិត្តសកម្មភាពផ្សងព្រេង។
- SEO ដែលដំណើរការដោយមាតិកា និងការចែកចាយ PR ។ ទទួលបានការពង្រីកថ្ងៃនេះ។
- PlatoData.Network Vertical Generative Ai. ផ្តល់អំណាចដល់ខ្លួនអ្នក។ ចូលប្រើទីនេះ។
- PlatoAiStream Web3 Intelligence ។ ចំណេះដឹងត្រូវបានពង្រីក។ ចូលប្រើទីនេះ។
- ផ្លាតូអេសជី។ កាបូន CleanTech, ថាមពល, បរិស្ថាន, ពន្លឺព្រះអាទិត្យ ការគ្រប់គ្រងកាកសំណល់។ ចូលប្រើទីនេះ។
- ផ្លាតូសុខភាព។ ជីវបច្ចេកវិទ្យា និង ភាពវៃឆ្លាត សាកល្បងគ្លីនិក។ ចូលប្រើទីនេះ។
- ប្រភព: https://aws.amazon.com/blogs/big-data/build-a-rag-data-ingestion-pipeline-for-large-scale-ml-workloads/

