នៅក្នុងការបង្ហោះនេះ យើងបង្ហាញពីរបៀបក្នុងការកែសម្រួលគំរូភាសាប្រូតេអ៊ីនទាន់សម័យ (pLM) ប្រកបដោយប្រសិទ្ធភាព ដើម្បីទស្សន៍ទាយការធ្វើមូលដ្ឋានីយកម្មកោសិការងប្រូតេអ៊ីនដោយប្រើ ក្រុមហ៊ុន Amazon SageMaker.
ប្រូតេអ៊ីនគឺជាម៉ាស៊ីនម៉ូលេគុលរបស់រាងកាយដែលទទួលខុសត្រូវគ្រប់យ៉ាងពីការធ្វើចលនាសាច់ដុំដើម្បីឆ្លើយតបនឹងការឆ្លងមេរោគ។ ថ្វីបើមានប្រភេទនេះក៏ដោយ ប្រូតេអ៊ីនទាំងអស់ត្រូវបានបង្កើតឡើងពីខ្សែសង្វាក់នៃម៉ូលេគុលដែលហៅថាអាស៊ីតអាមីណូ។ ហ្សែនរបស់មនុស្សបានអ៊ិនកូដអាស៊ីតអាមីណូស្តង់ដារចំនួន 20 ដែលនីមួយៗមានរចនាសម្ព័ន្ធគីមីខុសគ្នាបន្តិចបន្តួច។ ទាំងនេះអាចត្រូវបានតំណាងដោយអក្សរនៃអក្ខរក្រមដែលបន្ទាប់មកអនុញ្ញាតឱ្យយើងវិភាគនិងរុករកប្រូតេអ៊ីនជាខ្សែអក្សរ។ ចំនួនដ៏ច្រើនដែលអាចធ្វើទៅបាននៃលំដាប់ប្រូតេអ៊ីន និងរចនាសម្ព័ន្ធគឺជាអ្វីដែលផ្តល់ឱ្យប្រូតេអ៊ីននូវការប្រើប្រាស់ដ៏ធំទូលាយរបស់ពួកគេ។
ប្រូតេអ៊ីនក៏ដើរតួយ៉ាងសំខាន់ក្នុងការអភិវឌ្ឍន៍ថ្នាំ ដែលជាគោលដៅសក្តានុពល ប៉ុន្តែក៏ជាការព្យាបាលផងដែរ។ ដូចដែលបានបង្ហាញក្នុងតារាងខាងក្រោម ថ្នាំដែលលក់ដាច់បំផុតក្នុងឆ្នាំ 2022 គឺជាប្រូតេអ៊ីន (ជាពិសេសអង្គបដិប្រាណ) ឬម៉ូលេគុលផ្សេងទៀតដូចជា mRNA ដែលត្រូវបានបកប្រែទៅជាប្រូតេអ៊ីននៅក្នុងខ្លួន។ ដោយសារតែនេះ អ្នកស្រាវជ្រាវវិទ្យាសាស្ត្រជីវិតជាច្រើនត្រូវឆ្លើយសំណួរអំពីប្រូតេអ៊ីនលឿនជាង តម្លៃថោក និងត្រឹមត្រូវជាង។
| ឈ្មោះ | ក្រុមហ៊ុនផលិត | ការលក់សកលឆ្នាំ 2022 (រាប់ពាន់លានដុល្លារអាមេរិក) | សូចនាករ |
| ខុមនីណាទី | Pfizer / BioNTech | $40.8 | កូវីដ 19 |
| ស្ពៃក្តោប | Moderna | $21.8 | កូវីដ 19 |
| Humira | AbbVie | $21.6 | ជំងឺរលាកសន្លាក់ ជំងឺ Crohn និងអ្នកដទៃ |
| Keytruda | Merck | $21.0 | មហារីកផ្សេងៗ |
ប្រភពទិន្នន័យ៖ Urquhart, L. ក្រុមហ៊ុន និងថ្នាំកំពូលៗដោយការលក់នៅឆ្នាំ 2022. Nature Reviews Drug Discovery 22, 260–260 (2023)។
ដោយសារតែយើងអាចតំណាងឱ្យប្រូតេអ៊ីនជាលំដាប់នៃតួអក្សរ យើងអាចវិភាគពួកវាដោយប្រើបច្ចេកទេសដែលត្រូវបានបង្កើតឡើងដំបូងសម្រាប់ភាសាសរសេរ។ នេះរាប់បញ្ចូលទាំងគំរូភាសាធំ (LLMs) ដែលបានបណ្តុះបណ្តាលជាមុនលើសំណុំទិន្នន័យដ៏ធំ ដែលបន្ទាប់មកអាចត្រូវបានកែសម្រួលសម្រាប់កិច្ចការជាក់លាក់ ដូចជាការសង្ខេបអត្ថបទ ឬ chatbots ជាដើម។ ដូចគ្នានេះដែរ pLMs ត្រូវបានបណ្តុះបណ្តាលជាមុនលើមូលដ្ឋានទិន្នន័យលំដាប់ប្រូតេអ៊ីនធំ ដោយប្រើការរៀនដែលមិនមានស្លាក និងគ្រប់គ្រងដោយខ្លួនឯង។ យើងអាចសម្របពួកវាដើម្បីទស្សន៍ទាយអ្វីៗដូចជារចនាសម្ព័ន្ធ 3D នៃប្រូតេអ៊ីន ឬរបៀបដែលវាអាចមានអន្តរកម្មជាមួយម៉ូលេគុលផ្សេងទៀត។ អ្នកស្រាវជ្រាវថែមទាំងបានប្រើ pLMs ដើម្បីរចនាប្រូតេអ៊ីនថ្មីពីដំបូង។ ឧបករណ៍ទាំងនេះមិនជំនួសជំនាញវិទ្យាសាស្ត្ររបស់មនុស្សទេ ប៉ុន្តែពួកគេមានសក្តានុពលក្នុងការបង្កើនល្បឿននៃការអភិវឌ្ឍន៍មុនគ្លីនិក និងការរចនាសាកល្បង។
បញ្ហាប្រឈមមួយជាមួយម៉ូដែលទាំងនេះគឺទំហំរបស់វា។ ទាំង LLMs និង pLMs បានកើនឡើងតាមលំដាប់លំដោយក្នុងប៉ុន្មានឆ្នាំចុងក្រោយនេះ ដូចដែលបានបង្ហាញក្នុងរូបខាងក្រោម។ នេះមានន័យថា វាអាចចំណាយពេលយូរដើម្បីបង្ហាត់ពួកគេឱ្យមានភាពត្រឹមត្រូវគ្រប់គ្រាន់។ វាក៏មានន័យថាអ្នកត្រូវប្រើផ្នែករឹង ជាពិសេស GPUs ដែលមានអង្គចងចាំច្រើនដើម្បីរក្សាទុកប៉ារ៉ាម៉ែត្រគំរូ។
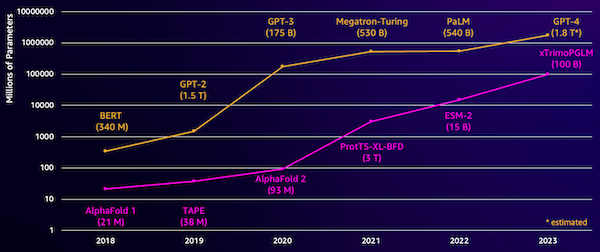
រយៈពេលបណ្តុះបណ្តាលដ៏វែង បូករួមទាំងករណីធំ ស្មើនឹងការចំណាយខ្ពស់ ដែលអាចធ្វើឲ្យការងារនេះហួសពីលទ្ធភាពសម្រាប់អ្នកស្រាវជ្រាវជាច្រើន។ ជាឧទាហរណ៍នៅឆ្នាំ 2023 ក ក្រុមស្រាវជ្រាវ បានពិពណ៌នាអំពីការបណ្តុះបណ្តាល 100 billion-parameter pLM នៅលើ 768 A100 GPUs រយៈពេល 164 ថ្ងៃ! ជាសំណាងល្អ ក្នុងករណីជាច្រើន យើងអាចសន្សំសំចៃពេលវេលា និងធនធានដោយការសម្រប pLM ដែលមានស្រាប់ទៅនឹងកិច្ចការជាក់លាក់របស់យើង។ បច្ចេកទេសនេះត្រូវបានគេហៅថា កែសំរួលហើយក៏អនុញ្ញាតឱ្យយើងខ្ចីឧបករណ៍កម្រិតខ្ពស់ពីប្រភេទនៃគំរូភាសាផ្សេងទៀតផងដែរ។
ទិដ្ឋភាពទូទៅនៃដំណោះស្រាយ
បញ្ហាជាក់លាក់ដែលយើងដោះស្រាយនៅក្នុងការប្រកាសនេះគឺ ការធ្វើមូលដ្ឋានីយកម្មកោសិការង៖ តាមលំដាប់ប្រូតេអ៊ីន តើយើងអាចបង្កើតគំរូដែលអាចទស្សន៍ទាយបានថា តើវារស់នៅខាងក្រៅ (ភ្នាសកោសិកា) ឬនៅខាងក្នុងកោសិកាដែរឬទេ? នេះគឺជាព័ត៌មានដ៏សំខាន់ដែលអាចជួយយើងឱ្យយល់អំពីមុខងារ និងថាតើវានឹងធ្វើឱ្យគោលដៅគ្រឿងញៀនល្អដែរឬទេ។
យើងចាប់ផ្តើមដោយការទាញយកសំណុំទិន្នន័យសាធារណៈដោយប្រើ ស្ទូឌីយោ Amazon SageMaker. បន្ទាប់មកយើងប្រើ SageMaker ដើម្បីកែសម្រួលគំរូភាសាប្រូតេអ៊ីន ESM-2 ដោយប្រើវិធីសាស្ត្របណ្តុះបណ្តាលប្រកបដោយប្រសិទ្ធភាព។ ជាចុងក្រោយ យើងដាក់ពង្រាយគំរូនេះជាចំណុចបញ្ចប់ការសន្និដ្ឋានតាមពេលវេលាជាក់ស្តែង ហើយប្រើវាដើម្បីសាកល្បងប្រូតេអ៊ីនដែលគេស្គាល់មួយចំនួន។ ដ្យាក្រាមខាងក្រោមបង្ហាញពីដំណើរការការងារនេះ។

នៅក្នុងផ្នែកខាងក្រោម យើងឆ្លងកាត់ជំហានដើម្បីរៀបចំទិន្នន័យបណ្តុះបណ្តាលរបស់អ្នក បង្កើតស្គ្រីបបណ្តុះបណ្តាល និងដំណើរការការងារបណ្តុះបណ្តាល SageMaker ។ កូដទាំងអស់ដែលមាននៅក្នុងប្រកាសនេះមាននៅលើ GitHub.
រៀបចំទិន្នន័យបណ្តុះបណ្តាល
យើងប្រើផ្នែកមួយនៃ សំណុំទិន្នន័យ DeepLoc-2ដែលមានផ្ទុកប្រូតេអ៊ីន SwissProt ជាច្រើនពាន់ជាមួយនឹងទីតាំងដែលបានកំណត់ដោយពិសោធន៍។ យើងត្រងសម្រាប់លំដាប់ដែលមានគុណភាពខ្ពស់រវាងអាស៊ីតអាមីណូ 100-512៖
df = pd.read_csv(
"https://services.healthtech.dtu.dk/services/DeepLoc-2.0/data/Swissprot_Train_Validation_dataset.csv"
).drop(["Unnamed: 0", "Partition"], axis=1)
df["Membrane"] = df["Membrane"].astype("int32")
# filter for sequences between 100 and 512 amino acides
df = df[df["Sequence"].apply(lambda x: len(x)).between(100, 512)]
# Remove unnecessary features
df = df[["Sequence", "Kingdom", "Membrane"]]
បន្ទាប់មក យើងកំណត់លំដាប់លំដោយ ហើយបំបែកវាទៅជាឈុតបណ្តុះបណ្តាល និងវាយតម្លៃ៖
dataset = Dataset.from_pandas(df).train_test_split(test_size=0.2, shuffle=True)
tokenizer = AutoTokenizer.from_pretrained("facebook/esm2_t33_650M_UR50D")
def preprocess_data(examples, max_length=512):
text = examples["Sequence"]
encoding = tokenizer(text, truncation=True, max_length=max_length)
encoding["labels"] = examples["Membrane"]
return encoding
encoded_dataset = dataset.map(
preprocess_data,
batched=True,
num_proc=os.cpu_count(),
remove_columns=dataset["train"].column_names,
)
encoded_dataset.set_format("torch")
ជាចុងក្រោយ យើងផ្ទុកទិន្នន័យបណ្តុះបណ្តាល និងវាយតម្លៃដែលបានដំណើរការទៅ សេវាកម្មផ្ទុកសាមញ្ញរបស់ក្រុមហ៊ុន Amazon (Amazon S3)៖
train_s3_uri = S3_PATH + "/data/train"
test_s3_uri = S3_PATH + "/data/test"
encoded_dataset["train"].save_to_disk(train_s3_uri)
encoded_dataset["test"].save_to_disk(test_s3_uri)បង្កើតស្គ្រីបបណ្តុះបណ្តាល
របៀបស្គ្រីប SageMaker អនុញ្ញាតឱ្យអ្នកដំណើរការកូដបណ្តុះបណ្តាលផ្ទាល់ខ្លួនរបស់អ្នកនៅក្នុងឧបករណ៍ផ្ទុកក្របខ័ណ្ឌក្របខ័ណ្ឌការរៀនម៉ាស៊ីនដែលបានធ្វើឱ្យប្រសើរឡើង (ML) ដែលគ្រប់គ្រងដោយ AWS ។ សម្រាប់ឧទាហរណ៍នេះ យើងសម្របតាម ស្គ្រីបដែលមានស្រាប់សម្រាប់ការចាត់ថ្នាក់អត្ថបទ ពី Hugging Face។ នេះអនុញ្ញាតឱ្យយើងសាកល្បងវិធីសាស្រ្តជាច្រើនសម្រាប់ការកែលម្អប្រសិទ្ធភាពនៃការងារបណ្តុះបណ្តាលរបស់យើង។
វិធីសាស្រ្តទី 1: ថ្នាក់បណ្តុះបណ្តាលទម្ងន់
ដូចសំណុំទិន្នន័យជីវសាស្រ្តជាច្រើន ទិន្នន័យ DeepLoc ត្រូវបានចែកចាយមិនស្មើគ្នា មានន័យថាមិនមានចំនួនភ្នាស និងប្រូតេអ៊ីនដែលមិនមែនជាភ្នាសស្មើគ្នាទេ។ យើងអាចយកគំរូទិន្នន័យរបស់យើងឡើងវិញ ហើយបោះបង់កំណត់ត្រាពីថ្នាក់ភាគច្រើន។ ទោះជាយ៉ាងណាក៏ដោយ វានឹងកាត់បន្ថយទិន្នន័យបណ្តុះបណ្តាលសរុប និងអាចប៉ះពាល់ដល់ភាពត្រឹមត្រូវរបស់យើង។ ផ្ទុយទៅវិញ យើងគណនាទម្ងន់ថ្នាក់កំឡុងពេលហ្វឹកហាត់ ហើយប្រើវាដើម្បីកែតម្រូវការបាត់បង់។
នៅក្នុងស្គ្រីបបណ្តុះបណ្តាលរបស់យើង យើងដាក់ថ្នាក់រង Trainer ថ្នាក់ពី transformers ជាមួយនឹង WeightedTrainer ថ្នាក់ដែលយកទម្ងន់ថ្នាក់ទៅក្នុងគណនីនៅពេលគណនាការបាត់បង់ឆ្លង entropy ។ វាជួយការពារការលំអៀងនៅក្នុងគំរូរបស់យើង៖
class WeightedTrainer(Trainer):
def __init__(self, class_weights, *args, **kwargs):
self.class_weights = class_weights
super().__init__(*args, **kwargs)
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
outputs = model(**inputs)
logits = outputs.get("logits")
loss_fct = torch.nn.CrossEntropyLoss(
weight=torch.tensor(self.class_weights, device=model.device)
)
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else lossវិធីសាស្រ្តទី 2: ការប្រមូលផ្តុំជម្រាល
ការប្រមូលផ្តុំជម្រាលគឺជាបច្ចេកទេសបណ្តុះបណ្តាលដែលអនុញ្ញាតឱ្យគំរូដើម្បីក្លែងធ្វើការបណ្តុះបណ្តាលលើទំហំបាច់ធំជាង។ ជាធម្មតា ទំហំបណ្តុំ (ចំនួនគំរូដែលប្រើដើម្បីគណនាជម្រាលក្នុងជំហានបណ្តុះបណ្តាលមួយ) ត្រូវបានកំណត់ដោយសមត្ថភាពអង្គចងចាំ GPU ។ ជាមួយនឹងការប្រមូលផ្តុំជម្រាល គំរូគណនាជម្រាលនៅលើបាច់តូចៗជាមុនសិន។ បន្ទាប់មក ជំនួសឱ្យការអាប់ដេតទម្ងន់គំរូភ្លាមៗ ជម្រាលត្រូវបានប្រមូលផ្តុំលើដុំតូចៗជាច្រើន។ នៅពេលដែលជម្រាលដែលបានប្រមូលផ្តុំស្មើនឹងទំហំបាច់ធំជាងគោលដៅ ជំហានបង្កើនប្រសិទ្ធភាពត្រូវបានអនុវត្តដើម្បីធ្វើបច្ចុប្បន្នភាពគំរូ។ នេះអនុញ្ញាតឱ្យម៉ូដែលហ្វឹកហាត់ជាមួយនឹងបណ្តុំធំជាងមុនប្រកបដោយប្រសិទ្ធភាពដោយមិនចាំបាច់លើសពីដែនកំណត់អង្គចងចាំ GPU ។
ទោះជាយ៉ាងណាក៏ដោយ ការគណនាបន្ថែមគឺត្រូវការជាចាំបាច់សម្រាប់បណ្តុំតូចជាងការឆ្លងកាត់ទៅមុខ និងថយក្រោយ។ ការបង្កើនទំហំបាច់តាមរយៈការប្រមូលផ្តុំជម្រាលអាចបន្ថយល្បឿននៃការហ្វឹកហាត់ ជាពិសេសប្រសិនបើជំហានប្រមូលផ្តុំច្រើនពេកត្រូវបានប្រើ។ គោលបំណងគឺដើម្បីបង្កើនការប្រើប្រាស់ GPU ប៉ុន្តែជៀសវាងការយឺតយ៉ាវហួសហេតុពីជំហានគណនាជម្រាលបន្ថែមច្រើនពេក។
វិធីសាស្រ្តទី 3: ការត្រួតពិនិត្យជម្រាល
ការត្រួតពិនិត្យជម្រាលគឺជាបច្ចេកទេសដែលកាត់បន្ថយការចងចាំដែលត្រូវការអំឡុងពេលហ្វឹកហាត់ ខណៈពេលដែលរក្សាពេលវេលាគណនាសមហេតុផល។ បណ្តាញសរសៃប្រសាទធំយកអង្គចងចាំច្រើន ដោយសារពួកគេត្រូវរក្សាទុកតម្លៃមធ្យមទាំងអស់ពីការបញ្ជូនបន្ត ដើម្បីគណនាជម្រាលអំឡុងពេលឆ្លងកាត់ថយក្រោយ។ នេះអាចបណ្តាលឱ្យមានបញ្ហាការចងចាំ។ ដំណោះស្រាយមួយគឺមិនត្រូវរក្សាទុកតម្លៃកម្រិតមធ្យមទាំងនេះទេ ប៉ុន្តែបន្ទាប់មកពួកគេត្រូវតែគណនាឡើងវិញក្នុងអំឡុងពេលឆ្លងកាត់ខាងក្រោយ ដែលចំណាយពេលច្រើន។
ការត្រួតពិនិត្យជម្រាលផ្តល់នូវវិធីសាស្រ្តប្រកបដោយតុល្យភាព។ វារក្សាទុកតែតម្លៃមធ្យមមួយចំនួនប៉ុណ្ណោះ ដែលហៅថា ចំណុចត្រួតពិនិត្យនិងគណនាឡើងវិញតាមតម្រូវការ។ ដូច្នេះហើយ វាប្រើប្រាស់អង្គចងចាំតិចជាងការរក្សាទុកអ្វីៗទាំងអស់ ប៉ុន្តែក៏មានការគណនាតិចជាងការគណនាឡើងវិញនូវអ្វីៗទាំងអស់។ តាមរយៈការជ្រើសរើសជាយុទ្ធសាស្ត្រ ថាតើការធ្វើឱ្យសកម្មណាមួយទៅកាន់ចំណុចត្រួតពិនិត្យ ការត្រួតពិនិត្យកម្រិតជម្រាលអាចឱ្យបណ្តាញសរសៃប្រសាទធំៗត្រូវបានបណ្តុះបណ្តាលជាមួយនឹងការប្រើប្រាស់អង្គចងចាំដែលអាចគ្រប់គ្រងបាន និងពេលវេលាគណនា។ បច្ចេកទេសដ៏សំខាន់នេះធ្វើឱ្យវាមានលទ្ធភាពក្នុងការបណ្តុះបណ្តាលម៉ូដែលធំ ៗ ដែលនឹងដំណើរការទៅក្នុងដែនកំណត់នៃការចងចាំ។
នៅក្នុងស្គ្រីបបណ្តុះបណ្តាលរបស់យើង យើងបើកដំណើរការជម្រាល និងការត្រួតពិនិត្យដោយបន្ថែមប៉ារ៉ាម៉ែត្រចាំបាច់ទៅ TrainingArguments កម្មវត្ថុ៖
from transformers import TrainingArguments
training_args = TrainingArguments(
gradient_accumulation_steps=4,
gradient_checkpointing=True
)វិធីសាស្រ្តទី 4: ការសម្របសម្រួលកម្រិតទាបនៃ LLMs
គំរូភាសាធំៗដូចជា ESM-2 អាចមានប៉ារ៉ាម៉ែត្ររាប់ពាន់លាន ដែលមានតម្លៃថ្លៃក្នុងការហ្វឹកហាត់ និងដំណើរការ។ អ្នកស្រាវជ្រាវ បានបង្កើតវិធីសាស្រ្តបណ្តុះបណ្តាលមួយហៅថា Low-Rank Adaptation (LoRA) ដើម្បីធ្វើឱ្យការកែតម្រូវគំរូដ៏ធំទាំងនេះកាន់តែមានប្រសិទ្ធភាព។
គំនិតសំខាន់នៅពីក្រោយ LoRA គឺថានៅពេលធ្វើការកែតម្រូវគំរូសម្រាប់កិច្ចការជាក់លាក់មួយ អ្នកមិនចាំបាច់ធ្វើបច្ចុប្បន្នភាពប៉ារ៉ាម៉ែត្រដើមទាំងអស់នោះទេ។ ផ្ទុយទៅវិញ LoRA បន្ថែមម៉ាទ្រីសតូចជាងថ្មីទៅម៉ូដែលដែលបំប្លែងធាតុចូល និងលទ្ធផល។ មានតែម៉ាទ្រីសតូចៗទាំងនេះប៉ុណ្ណោះដែលត្រូវបានអាប់ដេតកំឡុងពេលធ្វើការកែតម្រូវ ដែលលឿនជាង និងប្រើប្រាស់អង្គចងចាំតិចជាងមុន។ ប៉ារ៉ាម៉ែត្រគំរូដើមនៅជាប់គាំង។
បន្ទាប់ពីការកែសម្រួលជាមួយ LoRA អ្នកអាចបញ្ចូលម៉ាទ្រីសដែលប្រែប្រួលតូចចូលទៅក្នុងគំរូដើមវិញ។ ឬអ្នកអាចទុកពួកវាឱ្យនៅដាច់ពីគ្នា ប្រសិនបើអ្នកចង់កែសម្រួលគំរូឱ្យបានរហ័សសម្រាប់កិច្ចការផ្សេងទៀតដោយមិនបំភ្លេចកិច្ចការមុនៗ។ សរុបមក LoRA អនុញ្ញាតឱ្យ LLMs សម្របខ្លួនប្រកបដោយប្រសិទ្ធភាពចំពោះកិច្ចការថ្មីដោយប្រភាគនៃថ្លៃដើមធម្មតា។
នៅក្នុងស្គ្រីបបណ្តុះបណ្តាលរបស់យើង យើងកំណត់រចនាសម្ព័ន្ធ LoRA ដោយប្រើ PEFT បណ្ណាល័យពី Hugging Face:
from peft import get_peft_model, LoraConfig, TaskType
import torch
from transformers import EsmForSequenceClassification
model = EsmForSequenceClassification.from_pretrained(
“facebook/esm2_t33_650M_UR50D”,
Torch_dtype=torch.bfloat16,
Num_labels=2,
)
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
bias="none",
r=8,
lora_alpha=16,
lora_dropout=0.05,
target_modules=[
"query",
"key",
"value",
"EsmSelfOutput.dense",
"EsmIntermediate.dense",
"EsmOutput.dense",
"EsmContactPredictionHead.regression",
"EsmClassificationHead.dense",
"EsmClassificationHead.out_proj",
]
)
model = get_peft_model(model, peft_config)ដាក់ស្នើការងារបណ្តុះបណ្តាល SageMaker
បន្ទាប់ពីអ្នកបានកំណត់ស្គ្រីបបណ្តុះបណ្តាលរបស់អ្នក អ្នកអាចកំណត់រចនាសម្ព័ន្ធ និងបញ្ជូនការងារបណ្តុះបណ្តាល SageMaker ។ ដំបូងត្រូវបញ្ជាក់ប៉ារ៉ាម៉ែត្រខ្ពស់៖
hyperparameters = {
"model_id": "facebook/esm2_t33_650M_UR50D",
"epochs": 1,
"per_device_train_batch_size": 8,
"gradient_accumulation_steps": 4,
"use_gradient_checkpointing": True,
"lora": True,
}បន្ទាប់មក កំណត់ថាតើម៉ែត្រអ្វីខ្លះដែលត្រូវចាប់យកពីកំណត់ហេតុបណ្តុះបណ្តាល៖
metric_definitions = [
{"Name": "epoch", "Regex": "'epoch': ([0-9.]*)"},
{
"Name": "max_gpu_mem",
"Regex": "Max GPU memory use during training: ([0-9.e-]*) MB",
},
{"Name": "train_loss", "Regex": "'loss': ([0-9.e-]*)"},
{
"Name": "train_samples_per_second",
"Regex": "'train_samples_per_second': ([0-9.e-]*)",
},
{"Name": "eval_loss", "Regex": "'eval_loss': ([0-9.e-]*)"},
{"Name": "eval_accuracy", "Regex": "'eval_accuracy': ([0-9.e-]*)"},
]ជាចុងក្រោយ កំណត់ការប៉ាន់ប្រមាណ Hugging Face ហើយបញ្ជូនវាសម្រាប់ការបណ្តុះបណ្តាលលើប្រភេទឧទាហរណ៍ ml.g5.2xlarge ។ នេះគឺជាប្រភេទវត្ថុតម្លៃដែលមានប្រសិទ្ធភាពដែលមានយ៉ាងទូលំទូលាយនៅក្នុងតំបន់ AWS ជាច្រើន៖
from sagemaker.experiments.run import Run
from sagemaker.huggingface import HuggingFace
from sagemaker.inputs import TrainingInput
hf_estimator = HuggingFace(
base_job_name="esm-2-membrane-ft",
entry_point="lora-train.py",
source_dir="scripts",
instance_type="ml.g5.2xlarge",
instance_count=1,
transformers_version="4.28",
pytorch_version="2.0",
py_version="py310",
output_path=f"{S3_PATH}/output",
role=sagemaker_execution_role,
hyperparameters=hyperparameters,
metric_definitions=metric_definitions,
checkpoint_local_path="/opt/ml/checkpoints",
sagemaker_session=sagemaker_session,
keep_alive_period_in_seconds=3600,
tags=[{"Key": "project", "Value": "esm-fine-tuning"}],
)
with Run(
experiment_name=EXPERIMENT_NAME,
sagemaker_session=sagemaker_session,
) as run:
hf_estimator.fit(
{
"train": TrainingInput(s3_data=train_s3_uri),
"test": TrainingInput(s3_data=test_s3_uri),
}
)តារាងខាងក្រោមប្រៀបធៀបវិធីសាស្រ្តបណ្តុះបណ្តាលផ្សេងៗគ្នាដែលយើងបានពិភាក្សា និងឥទ្ធិពលរបស់វាទៅលើពេលវេលាដំណើរការ ភាពត្រឹមត្រូវ និងតម្រូវការអង្គចងចាំ GPU នៃការងាររបស់យើង។
| ការកំណត់រចនាសម្ព័ន្ធ | ពេលវេលាទូទាត់ប្រាក់ (នាទី) | ភាពត្រឹមត្រូវនៃការវាយតម្លៃ | ការប្រើប្រាស់អង្គចងចាំ GPU អតិបរមា (GB) |
| គំរូមូលដ្ឋាន | 28 | 0.91 | 22.6 |
| មូលដ្ឋាន + GA | 21 | 0.90 | 17.8 |
| មូលដ្ឋាន + GC | 29 | 0.91 | 10.2 |
| មូលដ្ឋាន + LoRA | 23 | 0.90 | 18.6 |
រាល់វិធីសាស្រ្តផលិតគំរូជាមួយនឹងភាពត្រឹមត្រូវនៃការវាយតម្លៃខ្ពស់។ ការប្រើប្រាស់ LoRA និងការធ្វើឱ្យសកម្មជម្រាលបានបន្ថយរយៈពេលដំណើរការ (និងតម្លៃ) ដោយ 18% និង 25% រៀងគ្នា។ ការប្រើការពិនិត្យមើលជម្រាលបានកាត់បន្ថយការប្រើប្រាស់អង្គចងចាំ GPU អតិបរមា 55% ។ អាស្រ័យលើឧបសគ្គរបស់អ្នក (តម្លៃ ពេលវេលា ហាដវែរ) វិធីសាស្រ្តមួយក្នុងចំណោមវិធីសាស្រ្តទាំងនេះអាចមានន័យច្រើនជាងវិធីមួយផ្សេងទៀត។
វិធីសាស្រ្តនីមួយៗអនុវត្តបានល្អដោយខ្លួនឯង ប៉ុន្តែតើមានអ្វីកើតឡើងនៅពេលយើងប្រើវាបញ្ចូលគ្នា? តារាងខាងក្រោមសង្ខេបលទ្ធផល។
| ការកំណត់រចនាសម្ព័ន្ធ | ពេលវេលាទូទាត់ប្រាក់ (នាទី) | ភាពត្រឹមត្រូវនៃការវាយតម្លៃ | ការប្រើប្រាស់អង្គចងចាំ GPU អតិបរមា (GB) |
| វិធីសាស្រ្តទាំងអស់។ | 12 | 0.80 | 3.3 |
ក្នុងករណីនេះយើងឃើញការថយចុះ 12% នៃភាពត្រឹមត្រូវ។ ទោះជាយ៉ាងណាក៏ដោយ យើងបានកាត់បន្ថយរយៈពេលដំណើរការ 57% និងការប្រើប្រាស់អង្គចងចាំ GPU 85%! នេះគឺជាការថយចុះដ៏ធំដែលអនុញ្ញាតឱ្យយើងបណ្តុះបណ្តាលលើជួរដ៏ធំទូលាយនៃប្រភេទឧទាហរណ៍ដែលមានប្រសិទ្ធភាព។
សម្អាត។
ប្រសិនបើអ្នកកំពុងតាមដាននៅក្នុងគណនី AWS ផ្ទាល់ខ្លួនរបស់អ្នក សូមលុបចំណុចបញ្ចប់ការសន្និដ្ឋាន និងទិន្នន័យណាមួយដែលអ្នកបានបង្កើត ដើម្បីជៀសវាងការគិតថ្លៃបន្ថែមទៀត។
predictor.delete_endpoint()
bucket = boto_session.resource("s3").Bucket(S3_BUCKET)
bucket.objects.filter(Prefix=S3_PREFIX).delete()សន្និដ្ឋាន
នៅក្នុងការបង្ហោះនេះ យើងបានបង្ហាញពីវិធីដើម្បីសម្រួលយ៉ាងមានប្រសិទ្ធភាពនូវគំរូភាសាប្រូតេអ៊ីនដូចជា ESM-2 សម្រាប់កិច្ចការដែលពាក់ព័ន្ធផ្នែកវិទ្យាសាស្ត្រ។ សម្រាប់ព័ត៌មានបន្ថែមអំពីការប្រើប្រាស់បណ្ណាល័យ Transformers និង PEFT ដើម្បីបណ្តុះបណ្តាល pLMS សូមពិនិត្យមើលការផ្សាយ សិក្សាជ្រៅជាមួយប្រូតេអ៊ីន និង ESMBind (ESMB)៖ ការកែសម្រួលចំណាត់ថ្នាក់ទាបនៃ ESM-2 សម្រាប់ការទស្សន៍ទាយគេហទំព័រចងប្រូតេអ៊ីន នៅលើប្លក់ Hugging Face។ អ្នកក៏អាចស្វែងរកឧទាហរណ៍បន្ថែមនៃការប្រើប្រាស់ machine learning ដើម្បីទស្សន៍ទាយលក្ខណៈសម្បត្តិប្រូតេអ៊ីននៅក្នុង ការវិភាគប្រូតេអ៊ីនដ៏អស្ចារ្យនៅលើ AWS ឃ្លាំង GitHub ។
អំពីអ្នកនិពន្ធ
 Brian ស្មោះត្រង់ គឺជាស្ថាបត្យករដំណោះស្រាយ AI/ML ជាន់ខ្ពស់នៅក្នុងក្រុម Global Healthcare and Life Sciences នៅ Amazon Web Services។ គាត់មានបទពិសោធន៍ជាង 17 ឆ្នាំនៅក្នុងបច្ចេកវិទ្យាជីវសាស្ត្រ និងការរៀនម៉ាស៊ីន ហើយមានចំណង់ចំណូលចិត្តក្នុងការជួយអតិថិជនក្នុងការដោះស្រាយបញ្ហាប្រឈមផ្នែកហ្សែន និងប្រូតេអូម។ ពេលទំនេរ គាត់ចូលចិត្តធ្វើម្ហូប និងញ៉ាំជាមួយមិត្តភក្តិ និងក្រុមគ្រួសាររបស់គាត់។
Brian ស្មោះត្រង់ គឺជាស្ថាបត្យករដំណោះស្រាយ AI/ML ជាន់ខ្ពស់នៅក្នុងក្រុម Global Healthcare and Life Sciences នៅ Amazon Web Services។ គាត់មានបទពិសោធន៍ជាង 17 ឆ្នាំនៅក្នុងបច្ចេកវិទ្យាជីវសាស្ត្រ និងការរៀនម៉ាស៊ីន ហើយមានចំណង់ចំណូលចិត្តក្នុងការជួយអតិថិជនក្នុងការដោះស្រាយបញ្ហាប្រឈមផ្នែកហ្សែន និងប្រូតេអូម។ ពេលទំនេរ គាត់ចូលចិត្តធ្វើម្ហូប និងញ៉ាំជាមួយមិត្តភក្តិ និងក្រុមគ្រួសាររបស់គាត់។
- SEO ដែលដំណើរការដោយមាតិកា និងការចែកចាយ PR ។ ទទួលបានការពង្រីកថ្ងៃនេះ។
- PlatoData.Network Vertical Generative Ai. ផ្តល់អំណាចដល់ខ្លួនអ្នក។ ចូលប្រើទីនេះ។
- PlatoAiStream Web3 Intelligence ។ ចំណេះដឹងត្រូវបានពង្រីក។ ចូលប្រើទីនេះ។
- ផ្លាតូអេសជី។ កាបូន CleanTech, ថាមពល, បរិស្ថាន, ពន្លឺព្រះអាទិត្យ ការគ្រប់គ្រងកាកសំណល់។ ចូលប្រើទីនេះ។
- ផ្លាតូសុខភាព។ ជីវបច្ចេកវិទ្យា និង ភាពវៃឆ្លាត សាកល្បងគ្លីនិក។ ចូលប្រើទីនេះ។
- ប្រភព: https://aws.amazon.com/blogs/machine-learning/efficiently-fine-tune-the-esm-2-protein-language-model-with-amazon-sagemaker/

