機械学習 (ML) は、近年、さまざまな業界でビジネスを改善してきました。 プライムビデオ アカウント、ドキュメントの要約と効率的な検索 アレクサの音声アシスタント。 ただし、この技術をビジネスにどのように組み込むかという問題は残ります。 従来のルールベースの方法とは異なり、ML はデータからパターンを自動的に推測して、目的のタスクを実行します。 これにより、自動化のためにルールをキュレートする必要がなくなりますが、ML モデルは、トレーニング対象のデータと同じくらい優れたものにしかならないことも意味します。 ただし、データの作成はしばしば困難な作業です。 で Amazon 機械学習ソリューション ラボ、私たちはこの問題に繰り返し遭遇しており、お客様のためにこの旅を楽にしたいと考えています. このプロセスをオフロードしたい場合は、次を使用できます Amazon SageMaker グラウンド トゥルース プラス.
この投稿の終わりまでに、次のことを達成できるようになります。
- データ取得パイプラインの設定に関連するビジネス プロセスを理解する
- データのラベル付けパイプラインをサポートおよび促進するための AWS クラウド サービスを特定する
- カスタム ユース ケースのデータ取得およびラベル付けタスクを実行する
- ビジネスと技術のベスト プラクティスに従って高品質のデータを作成する
この投稿全体を通して、データ作成プロセスに焦点を当て、AWS のサービスを利用してインフラストラクチャとプロセス コンポーネントを処理します。 つまり、使用します Amazon SageMakerグラウンドトゥルース ラベル付けインフラストラクチャ パイプラインとユーザー インターフェイスを処理します。 このサービスは、ポイント アンド ゴー アプローチを使用してデータを収集します。 Amazon シンプル ストレージ サービス (Amazon S3) を作成し、ラベル付けワークフローをセットアップします。 ラベル付けについては、プライベート チームを使用してデータ ラベルを取得する柔軟性が組み込まれています。 Amazon Mechanical Turk 力、またはあなたの好みのラベリングベンダーから AWS Marketplace. 最後に、使用できます AWSラムダ & Amazon SageMakerノートブック データの処理、視覚化、または品質管理 (ラベリング前またはラベリング後のいずれか)。
すべてのピースが配置されたので、プロセスを開始しましょう。
データ作成の流れ
一般的な直感に反して、データ作成の最初のステップはデータ収集ではありません。 ユーザーから逆算して問題を明確にすることが重要です。 たとえば、ユーザーは最終成果物で何を気にしますか? 専門家は、ユースケースに関連するシグナルがデータのどこにあると考えていますか? ユースケース環境に関するどのような情報をモデル化に提供できますか? これらの質問に対する答えがわからなくても、心配しないでください。 ニュアンスを理解するために、ユーザーや現場の専門家と話す時間をとってください。 この最初の理解は、あなたを正しい方向に導き、成功へと導きます。
この投稿では、ユーザー要件仕様のこの初期プロセスについて説明したことを前提としています。 次の XNUMX つのセクションでは、品質データを作成するための後続のプロセス (計画、ソース データの作成、およびデータの注釈) について説明します。 ラベル付きデータを効率的に作成するには、データ作成と注釈のステップでループをパイロットすることが不可欠です。 これには、必要に応じて、データの作成、注釈、品質保証、およびパイプラインの更新を繰り返すことが含まれます。
次の図は、一般的なデータ作成パイプラインで必要な手順の概要を示しています。 ユース ケースからさかのぼって、必要なデータを特定し (要件の仕様)、データを取得するプロセスを構築し (計画)、実際のデータ取得プロセスを実装し (データの収集と注釈)、結果を評価します。 破線で強調表示されたパイロット実行により、高品質のデータ取得パイプラインが開発されるまでプロセスを繰り返すことができます。
一般的なデータ作成パイプラインで必要な手順の概要。
計画
標準的なデータ作成プロセスは、効率が悪いと時間がかかり、貴重な人的資源を浪費する可能性があります。 なぜ時間がかかるのでしょうか? この質問に答えるには、データ作成プロセスの範囲を理解する必要があります。 お客様を支援するために、考慮すべき重要なコンポーネントと利害関係者の概要チェックリストと説明を収集しました。 これらの質問に答えるのは、最初は難しいかもしれません。 ユースケースによっては、これらの一部のみが適用される場合があります。
- 必要な承認のための法的連絡先を特定する – アプリケーションにデータを使用するには、会社のポリシーとユース ケースに準拠していることを確認するために、ライセンスまたはベンダー契約のレビューが必要になる場合があります。 プロセスのデータ取得と注釈のステップ全体で、法的なサポートを特定することが重要です。
- データ処理のセキュリティ担当者を特定する –購入したデータが漏洩すると、重大な罰金や会社への影響が生じる可能性があります。 安全な実践を確保するために、データの取得と注釈の手順全体でセキュリティ サポートを特定することが重要です。
- ユース ケースの要件を詳述し、ソース データと注釈のガイドラインを定義する – 高度な特異性が求められるため、データの作成と注釈付けは困難です。 リソースの浪費を避けるために、データ ジェネレーターやアノテーターを含む利害関係者は完全に一致している必要があります。 この目的のために、アノテーション タスクのあらゆる側面 (正確な手順、特殊なケース、ウォークスルーの例など) を指定するガイドライン ドキュメントを使用するのが一般的です。
- ソースデータを収集するための期待に合わせる – 次の点を考慮してください。
- 潜在的なデータ ソースに関する調査を実施する – たとえば、公開データセット、他の内部チームからの既存のデータセット、自己収集したデータ、またはベンダーから購入したデータ。
- 品質評価の実施 – 最終的なユース ケースに関連する分析パイプラインを作成します。
- データ注釈を作成するための期待に合わせる – 次の点を考慮してください。
- 技術関係者を特定する – これは通常、Ground Truth に関する技術文書を使用して注釈パイプラインを実装できる、社内の個人またはチームです。 これらの利害関係者は、アノテーション付きデータの品質評価も担当して、ダウンストリーム ML アプリケーションのニーズを満たしていることを確認します。
- データ注釈者を特定する – これらの個人は、所定の指示を使用して、Ground Truth 内のソース データにラベルを追加します。 ユースケースとアノテーションのガイドラインによっては、ドメインの知識が必要になる場合があります。 社内の従業員を使用することも、料金を支払うこともできます。 外部ベンダーが管理する要員.
- データ作成プロセスの監視を確実にする – 以上の点からわかるように、データ作成は多くの専門的な利害関係者が関与する詳細なプロセスです。 したがって、目的の結果に向けてエンドツーエンドで監視することが重要です。 専任の担当者またはチームがプロセスを監督することで、まとまりのある効率的なデータ作成プロセスを確保することができます。
選択するルートに応じて、次のことも考慮する必要があります。
- ソース データセットを作成する – これは、既存のデータが当面のタスクに適していない場合、または法的な制約により使用できない場合を指します。 内部チームまたは外部ベンダー (次のポイント) を使用する必要があります。 これは、高度に専門化されたドメインや公開研究が少ない分野によく見られます。 たとえば、医師のよくある質問、衣服の配置、スポーツの専門家などです。 それは内部または外部の場合があります。
- ベンダーを調査し、オンボーディング プロセスを実施する – 外部ベンダーを使用する場合は、両方のエンティティ間で契約およびオンボーディング プロセスを設定する必要があります。
このセクションでは、考慮する必要があるコンポーネントと利害関係者を確認しました。 しかし、実際のプロセスはどのように見えるのでしょうか? 次の図では、データの作成と注釈のプロセス ワークフローの概要を示します。 反復アプローチでは、パイロットと呼ばれるデータの小さなバッチを使用して、ターンアラウンド タイムを短縮し、早期にエラーを検出し、低品質のデータの作成でリソースを浪費しないようにします。 これらのパイロット ラウンドについては、この投稿の後半で説明します。 また、データの作成、注釈、および品質管理に関するいくつかのベスト プラクティスについても説明します。
次の図は、データ作成パイプラインの反復開発を示しています。 垂直方向には、データ ソース ブロック (緑) と注釈ブロック (青) があります。 両方のブロックに独立したパイロット ラウンドがあります (データ作成/注釈、QAQC、および更新)。 ますます高品質のソース データが作成され、ますます高品質の注釈を作成するために使用できます。
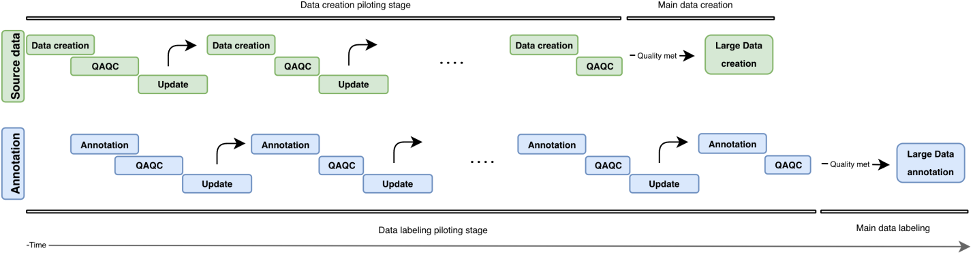
データ作成パイプラインにおける反復開発の概要。
ソースデータの作成
入力作成プロセスは、タスクの種類に応じて、関心のあるアイテムをステージングすることを中心に展開します。 これらは、画像 (新聞のスキャン)、ビデオ (交通状況)、3D 点群 (医療スキャン)、または単なるテキスト (字幕トラック、書き起こし) などです。 一般に、タスク関連のアイテムをステージングするときは、次のことを確認してください。
- 最終的な AI / ML システムの実際のユースケースを反映する – トレーニング データの画像またはビデオを収集するためのセットアップは、実際のアプリケーションでの入力データのセットアップとほぼ一致する必要があります。 これは、一貫した配置面、光源、またはカメラ アングルを持つことを意味します。
- ばらつきの原因を考慮して最小限に抑える – 次の点を考慮してください。
- データ収集基準を維持するためのベスト プラクティスを開発する – ユース ケースの粒度によっては、データ ポイント間の一貫性を保証するために要件を指定する必要がある場合があります。 たとえば、単一のカメラ ポイントから画像またはビデオ データを収集している場合、関心のあるオブジェクトの一貫した配置を確認するか、データ キャプチャ ラウンドの前にカメラの品質チェックを要求する必要がある場合があります。 これにより、カメラの傾きやブレなどの問題を回避し、アウト オブ フレームやぼやけた画像を削除したり、画像フレームを対象領域の中心に手動で配置する必要があるなど、ダウンストリームのオーバーヘッドを最小限に抑えることができます。
- ばらつきの原因となるテスト時間の先取り – テスト時にこれまでに述べた属性のいずれかに変動性が予想される場合は、トレーニング データの作成中にそれらの変動性ソースを取得できることを確認してください。 たとえば、ML アプリケーションが複数の異なる照明設定で動作することが予想される場合は、さまざまな照明設定でトレーニング画像とビデオを作成することを目指す必要があります。 ユースケースによっては、カメラの位置の変動もラベルの品質に影響を与える可能性があります。
- 利用可能な場合は、以前のドメイン知識を組み込む – 次の点を考慮してください。
- エラーの原因に関するインプット – ドメインの専門家は、長年の経験に基づいて、エラーの原因について洞察を提供できます。 前の XNUMX つのポイントのベスト プラクティスに関するフィードバックを提供できます。 データ収集時または使用時のばらつきの原因として考えられるものは何ですか?
- ドメイン固有のデータ収集のベスト プラクティス – 技術関係者は、収集された画像やビデオに焦点を当てるべき技術的側面についてすでに良い考えを持っているかもしれませんが、ドメインの専門家は、これらのニーズが満たされるようにデータをステージングまたは収集する最善の方法についてフィードバックを提供できます。
作成したデータの品質管理と品質保証
データ収集パイプラインをセットアップしたので、先に進んでできるだけ多くのデータを収集したくなるかもしれません。 ちょっと待って! 最初に、セットアップによって収集されたデータが実際のユースケースに適しているかどうかを確認する必要があります。 いくつかの初期サンプルを使用し、そのサンプル データの分析から得た洞察を通じてセットアップを繰り返し改善することができます。 パイロット プロセス中は、技術、ビジネス、および注釈の関係者と緊密に連携してください。 これにより、最小限のオーバーヘッドで ML 対応のラベル付きデータを生成しながら、結果として得られるパイプラインがビジネス ニーズを満たしていることが保証されます。
注釈
入力の注釈は、データに魔法のタッチを追加する場所、つまりラベルです! タスクの種類とデータ作成プロセスによっては、手動のアノテーターが必要になる場合もあれば、既製の自動化された方法を使用する場合もあります。 データ注釈パイプライン自体は、技術的に困難なタスクになる可能性があります。 Ground Truth は、技術関係者のこのジャーニーを容易にします。 一般的なデータ ソースのラベル付けワークフローの組み込みレパートリー. いくつかの追加手順により、ビルドも可能になります カスタムラベリングワークフロー 事前設定されたオプションを超えています。
適切な注釈ワークフローを開発する際には、次の質問を自問してください。
- データに手動の注釈プロセスが必要ですか? 場合によっては、目前のタスクには自動ラベル付けサービスで十分な場合があります。 ドキュメントと利用可能なツールを確認すると、ユース ケースに手動の注釈が必要かどうかを判断するのに役立ちます (詳細については、を参照してください)。 データのラベル付けとは)。 データ作成プロセスでは、データ注釈の粒度に関するさまざまなレベルの制御が可能になります。 このプロセスによっては、手動での注釈の必要性を回避できる場合もあります。 詳細については、次を参照してください。 Amazon SageMaker Ground Truthを使用してカスタムQ&Aデータセットを構築し、Hugging Face Q&ANLUモデルをトレーニングします.
- 私のグラウンドトゥルースを形成するものは何ですか? ほとんどの場合、グラウンド トゥルースは注釈プロセスから得られます。これが重要なポイントです。 また、ユーザーがグラウンド トゥルース ラベルにアクセスできる場合もあります。 これにより、品質保証プロセスを大幅にスピードアップしたり、複数の手動注釈に必要なオーバーヘッドを削減したりできます。
- グラウンド トゥルース状態からの逸脱量の上限は? エンド ユーザーと協力して、これらのラベルに関する典型的なエラー、そのようなエラーの原因、および望ましいエラーの削減を理解してください。 これは、ラベル付けタスクのどの側面が最も困難であるか、または注釈エラーが発生する可能性があるかを特定するのに役立ちます。
- これらのアイテムにラベルを付けるためにユーザーまたは現場の実務家が使用する既存のルールはありますか? これらのガイドラインを使用して改良し、手動アノテーター向けの一連の指示を作成してください。
入力注釈プロセスのパイロット
入力注釈プロセスを試験運用するときは、次の点を考慮してください。
- アノテーターおよびフィールド・プラクティショナーと一緒に指示を確認してください – 指示は簡潔かつ具体的でなければなりません。 ユーザーからのフィードバックを求めます (指示は正確ですか? 現場の専門家以外にも理解できるようにするために、指示を修正できますか?) および注釈者 (すべてが理解できるか? タスクは明確ですか?)。 可能であれば、ラベル付けされたデータの良い例と悪い例を追加して、アノテーターが期待されるものと一般的なラベル付けエラーがどのように見えるかを識別できるようにします。
- 注釈用のデータを収集する – 顧客と一緒にデータをレビューして、予想される基準を満たしていることを確認し、手動の注釈から予想される結果に合わせます。
- テスト実行として手動アノテーターのプールに例を提供する – この一連の例におけるアノテーター間の典型的な違いは? 特定の画像内の各アノテーションの分散を調べて、アノテーター間の一貫性の傾向を特定します。 次に、画像またはビデオ フレーム全体の差異を比較して、どのラベルを配置するのが難しいかを特定します。
注釈の品質管理
アノテーションの品質管理には、アノテーター間の一貫性の評価と、アノテーション自体の品質の評価という XNUMX つの主要なコンポーネントがあります。
複数のアノテーターを同じタスクに割り当て (たとえば、XNUMX 人のアノテーターが同じ画像のキー ポイントにラベルを付ける)、アノテーター間のこれらのラベルの標準偏差とともに平均値を測定できます。 そうすることで、外れ値の注釈 (誤ったラベルが使用されている、または平均的な注釈からかけ離れたラベル) を特定するのに役立ちます。これにより、指示を改善したり、特定の注釈者にさらなるトレーニングを提供したりするなど、実行可能な結果を導き出すことができます。
アノテーション自体の品質を評価することは、アノテーターの多様性と、(利用可能な場合) ドメインの専門家またはグラウンド トゥルース情報の入手可能性に関連しています。 アノテーター間の平均分散が一貫して高い特定のラベル (すべての画像にわたって) はありますか? ラベルがどこにあるべきか、またはどのように見えるべきかについて、あなたの期待からかけ離れているラベルはありますか?
私たちの経験に基づくと、データ注釈の典型的な品質管理ループは次のようになります。
- テスト実行の結果に基づいて、手順またはイメージ ステージングを反復します。 – オブジェクトが遮られていないか、またはイメージ ステージングがアノテーターまたはユーザーの期待に一致していませんか? 説明が誤解を招くものでしたか、それとも見本画像のラベルや一般的なエラーを見逃していましたか? アノテーター向けの指示を改善できますか?
- テスト実行の問題に対処したことに満足している場合は、注釈のバッチを実行します – バッチからの結果をテストするには、アノテーター間および画像ラベル間の変動性を評価する同じ品質評価アプローチに従います。
まとめ
この投稿は、ビジネス関係者が AI/ML アプリケーションのデータ作成の複雑さを理解するためのガイドとして役立ちます。 説明されているプロセスは、技術者が人員やコストなどのビジネス上の制約を最適化しながら高品質のデータを生成するためのガイドとしても役立ちます。 適切に行わないと、データの作成とラベル付けのパイプラインに 4 ~ 6 か月かかることがあります。
この投稿で概説したガイドラインと提案を使用すると、障害を回避し、完了までの時間を短縮し、高品質のデータを作成する過程でのコストを最小限に抑えることができます。
著者について
 ジャスリーン・グレワル アマゾン ウェブ サービスの応用科学者であり、AWS のお客様と協力して機械学習を使用して現実世界の問題を解決し、特に精密医療とゲノミクスに重点を置いています。 彼女は、バイオインフォマティクス、腫瘍学、および臨床ゲノミクスに強いバックグラウンドを持っています。 彼女は AI/ML とクラウド サービスを使用して患者ケアを改善することに情熱を注いでいます。
ジャスリーン・グレワル アマゾン ウェブ サービスの応用科学者であり、AWS のお客様と協力して機械学習を使用して現実世界の問題を解決し、特に精密医療とゲノミクスに重点を置いています。 彼女は、バイオインフォマティクス、腫瘍学、および臨床ゲノミクスに強いバックグラウンドを持っています。 彼女は AI/ML とクラウド サービスを使用して患者ケアを改善することに情熱を注いでいます。
 ボリス・アロンチック はAmazonAIMachine Learning Solutions Labのマネージャーであり、MLの科学者とエンジニアのチームを率いて、AWSの顧客がAI/MLソリューションを活用してビジネス目標を実現できるよう支援しています。
ボリス・アロンチック はAmazonAIMachine Learning Solutions Labのマネージャーであり、MLの科学者とエンジニアのチームを率いて、AWSの顧客がAI/MLソリューションを活用してビジネス目標を実現できるよう支援しています。
 ミゲルロメロカルボ の応用科学者です Amazon MLソリューションラボ そこで彼は、AWS の社内チームや戦略的顧客と提携して、ML とクラウドの採用を通じてビジネスを加速させています。
ミゲルロメロカルボ の応用科学者です Amazon MLソリューションラボ そこで彼は、AWS の社内チームや戦略的顧客と提携して、ML とクラウドの採用を通じてビジネスを加速させています。
 リン・リーチョン アマゾン ウェブ サービスの Amazon ML Solutions Lab チームのシニア サイエンティスト兼マネージャーです。 彼女は戦略的な AWS のお客様と協力して、人工知能と機械学習を調査および適用して、新しい洞察を発見し、複雑な問題を解決しています。
リン・リーチョン アマゾン ウェブ サービスの Amazon ML Solutions Lab チームのシニア サイエンティスト兼マネージャーです。 彼女は戦略的な AWS のお客様と協力して、人工知能と機械学習を調査および適用して、新しい洞察を発見し、複雑な問題を解決しています。

