堅牢で再利用可能な機械学習 (ML) パイプラインの作成は、複雑で時間のかかるプロセスになる可能性があります。 開発者は通常、処理スクリプトとトレーニング スクリプトをローカルでテストしますが、パイプライン自体は通常、クラウドでテストされます。 実験中に完全なパイプラインを作成して実行すると、開発ライフサイクルに不要なオーバーヘッドとコストが追加されます。 この投稿では、使用方法について詳しく説明します Amazon SageMaker パイプラインのローカルモード ML パイプラインをローカルで実行して、コストを削減しながらパイプラインの開発と実行時間を短縮します。 パイプラインがローカルで完全にテストされた後、次のコマンドで簡単に再実行できます アマゾンセージメーカー わずか数行のコード変更でリソースを管理できます。
ML ライフサイクルの概要
ML の新しいイノベーションとアプリケーションの主な原動力の XNUMX つは、データの可用性と量、および安価なコンピューティング オプションです。 いくつかのドメインで、ML は従来のビッグデータや分析手法では解決できなかった問題を解決できることが証明されており、データ サイエンスと ML の実践者に対する需要は着実に増加しています。 非常に高いレベルから見ると、ML ライフサイクルはさまざまな部分で構成されていますが、ML モデルの構築は通常、次の一般的な手順で構成されています。
- データのクレンジングと準備 (特徴量エンジニアリング)
- モデルのトレーニングとチューニング
- モデル評価
- モデルのデプロイ (またはバッチ変換)
データ準備ステップでは、データがロードされ、マッサージされ、ML モデルが期待するタイプの入力または特徴に変換されます。 データを変換するためのスクリプトの作成は、通常、反復プロセスであり、開発をスピードアップするために高速なフィードバック ループが重要です。 通常、機能エンジニアリング スクリプトをテストするときに完全なデータセットを使用する必要はありません。 ローカルモード機能 SageMaker 処理の。 これにより、小さなデータセットを使用して、ローカルで実行し、コードを繰り返し更新できます。 最終的なコードの準備が整うと、リモート処理ジョブに送信されます。リモート処理ジョブは完全なデータセットを使用し、SageMaker マネージド インスタンスで実行されます。
開発プロセスは、モデルのトレーニングとモデルの評価の両方のステップのデータ準備ステップに似ています。 データサイエンティストは、 ローカルモード機能 ML 最適化インスタンスの SageMaker マネージド クラスター内のすべてのデータを使用する前に、小規模なデータセットをローカルですばやく反復するための SageMaker トレーニングの。 これにより、開発プロセスがスピードアップし、実験中に SageMaker によって管理される ML インスタンスを実行するコストがなくなります。
組織の ML の成熟度が高まるにつれて、次を使用できます。 AmazonSageMakerパイプライン これらのステップをつなぎ合わせる ML パイプラインを作成し、ML モデルを処理、トレーニング、評価するより複雑な ML ワークフローを作成します。 SageMaker Pipelines は、データの読み込み、データ変換、モデルのトレーニングとチューニング、モデルのデプロイなど、ML ワークフローのさまざまなステップを自動化するためのフルマネージド サービスです。 最近まで、スクリプトをローカルで開発してテストすることはできましたが、クラウドで ML パイプラインをテストする必要がありました。 これにより、ML パイプラインのフローとフォームの反復は、時間とコストのかかるプロセスになりました。 現在、SageMaker Pipelines のローカルモード機能が追加されているため、処理スクリプトとトレーニング スクリプトをテストおよび反復する方法と同様に、ML パイプラインを反復およびテストできます。 データの小さなサブセットを使用してパイプラインの構文と機能を検証し、ローカル マシンでパイプラインを実行してテストできます。
SageMakerパイプライン
SageMaker Pipelines は、単純または複雑な ML ワークフローを実行するための完全に自動化された方法を提供します。 SageMaker Pipelines を使用すると、使いやすい Python SDK を使用して ML ワークフローを作成し、次を使用してワークフローを視覚化および管理できます。 Amazon SageMakerスタジオ. SageMaker Pipelines で作成したワークフローステップを保存して再利用することで、データサイエンスチームはより効率的になり、より迅速にスケーリングできます。 また、インフラストラクチャとリポジトリの作成を自動化する事前構築済みのテンプレートを使用して、ML 環境内でモデルを構築、テスト、登録、デプロイすることもできます。 これらのテンプレートは組織で自動的に使用可能になり、次を使用してプロビジョニングされます。 AWSサービスカタログ 製品。
SageMaker Pipelines は、開発環境と本番環境の間のパリティの維持、バージョン管理、オンデマンド テスト、エンドツーエンドの自動化など、継続的インテグレーションと継続的デプロイ (CI/CD) プラクティスを ML にもたらします。組織。 DevOps の実践者は、CI/CD 手法を使用する主な利点のいくつかには、再利用可能なコンポーネントによる生産性の向上と、自動テストによる品質の向上が含まれることを知っています。これにより、ビジネス目標の ROI が短縮されます。 これらの利点は、SageMaker Pipelines を使用して ML モデルのトレーニング、テスト、デプロイを自動化することにより、MLOps 実践者が利用できるようになりました。 ローカル モードを使用すると、パイプラインで使用するスクリプトを開発する際に、はるかに迅速に反復できるようになりました。 ローカル パイプライン インスタンスは Studio IDE 内で表示または実行できないことに注意してください。 ただし、ローカル パイプラインの追加の表示オプションはまもなく利用可能になります。
SageMaker SDK は汎用目的を提供します ローカル モードの構成 これにより、開発者は、サポートされているプロセッサと推定器をローカル環境で実行およびテストできます。 ローカル モードのトレーニングは、AWS がサポートする複数のフレームワーク イメージ (TensorFlow、MXNet、Chainer、PyTorch、および Scikit-Learn) と、自分で提供するイメージで使用できます。
オーケストレーションされたワークフロー ステップの有向非巡回グラフ (DAG) を構築する SageMaker Pipelines は、ML ライフサイクルの一部である多くのアクティビティをサポートします。 ローカル モードでは、次の手順がサポートされています。
- ジョブステップの処理 – 機能エンジニアリング、データ検証、モデル評価、モデル解釈などのデータ処理ワークロードを実行するための、SageMaker での簡素化されたマネージド エクスペリエンス
- トレーニング ジョブ ステップ – トレーニング データセットからの例を提示することでモデルに予測を教える反復プロセス
- ハイパーパラメータ調整ジョブ – 最も正確なモデルを生成するハイパーパラメータを自動的に評価および選択する方法
- 条件付き実行ステップ – パイプラインで分岐の条件付き実行を提供するステップ
- モデルステップ – このステップでは、CreateModel 引数を使用して、変換ステップまたは後でエンドポイントとしてデプロイするためのモデルを作成できます。
- ジョブ ステップの変換 – 大規模なデータセットから予測を生成し、永続的なエンドポイントが必要ない場合に推論を実行するバッチ変換ジョブ
- 失敗の手順 – パイプラインの実行を停止し、実行を失敗としてマークするステップ
ソリューションの概要
私たちのソリューションは、ローカルモードで SageMaker パイプラインを作成して実行するための重要なステップを示しています。つまり、ローカルの CPU、RAM、およびディスクリソースを使用して、ワークフローステップをロードして実行します。 ローカル環境は、VSCode や PyCharm などの一般的な IDE を使用してラップトップで実行することも、従来のノートブック インスタンスを使用して SageMaker でホストすることもできます。
ローカル モードを使用すると、データ サイエンティストは、処理、トレーニング、および評価ジョブを含むステップをつなぎ合わせて、ワークフロー全体をローカルで実行できます。 ローカルでのテストが完了したら、SageMaker 管理環境でパイプラインを再実行できます。 LocalPipelineSession オブジェクト PipelineSession、ML ライフサイクルに一貫性をもたらします。
このノートブック サンプルでは、公開されている標準のデータセット、 UCI Machine Learning アワビ データセット. 目標は、ML モデルをトレーニングして、物理的な測定値からアワビの巻貝の年齢を判断することです。 本質的に、これは回帰の問題です。
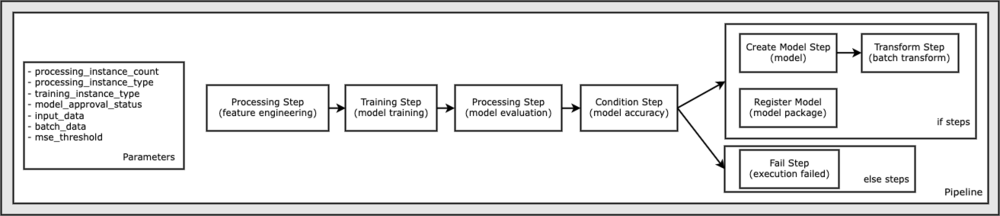
このノートブック サンプルを実行するために必要なすべてのコードは、GitHub の amazon-sagemaker-examples リポジトリ。 このノートブック サンプルでは、パイプライン ワークフローの各ステップが個別に作成されてから、相互に接続されてパイプラインが作成されます。 次のステップを作成します。
- 処理ステップ (特徴量エンジニアリング)
- トレーニング ステップ (モデル トレーニング)
- 加工工程(モデル評価)
- 条件ステップ (モデル精度)
- モデル作成ステップ (モデル)
- 変換ステップ (バッチ変換)
- モデル登録ステップ(モデルパッケージ)
- 失敗ステップ (実行失敗)
次の図は、パイプラインを示しています。
前提条件
この投稿を進めるには、次のものが必要です。
これらの前提条件が整ったら、次のセクションで説明するように、サンプル ノートブックを実行できます。
パイプラインを構築する
このノートブックのサンプルでは、 SageMaker スクリプトモード つまり、実際の Python コード (スクリプト) を提供してアクティビティを実行し、このコードへの参照を渡します。 スクリプトモードは、XGBoost や Scikit-Learn などの SageMaker の事前構築済みコンテナを引き続き利用しながら、コードをカスタマイズできるようにすることで、SageMaker 処理内の動作を制御するための優れた柔軟性を提供します。 カスタム コードは、magic コマンドで始まるセルを使用して Python スクリプト ファイルに書き込まれます。 %%writefile、次のように:
%%writefile code/evaluation.py
ローカル モードの主なイネーブラーは、 LocalPipelineSession Python SDK からインスタンス化されたオブジェクト。 次のコード セグメントは、ローカル モードで SageMaker パイプラインを作成する方法を示しています。 多くのローカル パイプライン ステップに対してローカル データ パスを設定できますが、Amazon S3 は、変換によるデータ出力を保存するデフォルトの場所です。 新しい LocalPipelineSession object は、この投稿で説明されている SageMaker ワークフロー API 呼び出しの多くで Python SDK に渡されます。 を使用できることに注意してください。 local_pipeline_session 変数を使用して、S3 デフォルト バケットと現在のリージョン名への参照を取得します。
個々のパイプライン ステップを作成する前に、パイプラインで使用されるいくつかのパラメーターを設定します。 これらのパラメーターの一部は文字列リテラルですが、SDK によって提供される特別な列挙型として作成されるものもあります。 列挙された型付けにより、パイプラインに有効な設定が提供されることが保証されます。 ConditionLessThanOrEqualTo さらに下へ:
mse_threshold = ParameterFloat(name="MseThreshold", default_value=7.0)
ここで特徴量エンジニアリングを実行するために使用されるデータ処理ステップを作成するには、 SKLearnProcessor データセットをロードして変換します。 私たちは local_pipeline_session ローカル モードで実行するワークフロー ステップを指示するクラス コンストラクターへの変数:
次に、最初の実際のパイプライン ステップを作成します。 ProcessingStep SageMaker SDK からインポートされたオブジェクト。 プロセッサの引数は、への呼び出しから返されます。 SKLearnProcessor run() メソッド。 このワークフロー ステップは、ノートブックの最後にある他のステップと組み合わされて、パイプライン内の操作の順序を示します。
次に、最初に SageMaker SDK を使用して標準推定器をインスタンス化することにより、トレーニング ステップを確立するためのコードを提供します。 私たちは同じことを渡します local_pipeline_session xgb_train という名前の推定器への変数を sagemaker_session 口論。 XGBoost モデルをトレーニングしたいので、フレームワークといくつかのバージョン パラメーターを含む次のパラメーターを指定して、有効な画像 URI を生成する必要があります。
必要に応じて、追加の推定メソッドを呼び出すことができます。たとえば、 set_hyperparameters()、トレーニング ジョブのハイパーパラメータ設定を提供します。 推定器が構成されたので、実際のトレーニング ステップを作成する準備が整いました。 もう一度、インポートします TrainingStep SageMaker SDK ライブラリのクラス:
次に、モデル評価を実行する別の処理ステップを構築します。 これは、 ScriptProcessor インスタンスと local_pipeline_session パラメータとしてのオブジェクト:
トレーニング済みモデルのデプロイを有効にするには、 SageMaker リアルタイムエンドポイント またはバッチ変換するには、作成する必要があります Model モデル アーティファクト、適切な画像 URI、およびオプションでカスタム推論コードを渡すことでオブジェクトを作成します。 次に、これを渡します Model 反対する ModelStep、ローカル パイプラインに追加されます。 次のコードを参照してください。
次に、一連の特徴ベクトルを送信して推論を実行するバッチ変換ステップを作成します。 まず、 Transformer オブジェクトを渡して local_pipeline_session パラメータを指定します。 次に、 TransformStep、必要な引数を渡し、これをパイプライン定義に追加します。
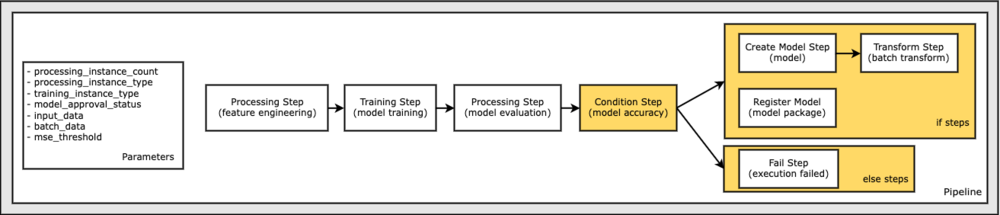
最後に、分岐条件をワークフローに追加して、モデル評価の結果が基準を満たす場合にのみバッチ変換を実行するようにします。 を追加することで、この条件を示すことができます ConditionStep のような特定の条件タイプで ConditionLessThanOrEqualTo. 次に、XNUMX つのブランチのステップを列挙し、基本的にパイプラインの if/else または true/false ブランチを定義します。 で提供される if_steps ConditionStep (ステップ作成_モデル, ステップ変換) 条件が評価されるたびに実行されます True.
次の図は、この条件分岐と関連する if/else ステップを示しています。 条件ステップで比較されたモデル評価ステップの結果に基づいて、XNUMX つの分岐のみが実行されます。
すべてのステップを定義し、基礎となるクラス インスタンスを作成したので、それらをパイプラインに結合できます。 いくつかのパラメーターを提供し、必要な順序でステップをリストするだけで操作の順序を決定的に定義します。 注意してください TransformStep 条件付きステップのターゲットであり、へのステップ引数として提供されたため、ここには表示されません ConditionalStep 早く
パイプラインを実行するには、次の XNUMX つのメソッドを呼び出す必要があります。 pipeline.upsert()、パイプラインを基礎となるサービスにアップロードし、 pipeline.start()、パイプラインの実行を開始します。 他のさまざまな方法を使用して、実行ステータスを調べたり、パイプライン ステップを一覧表示したりできます。 ローカル モードのパイプライン セッションを使用したため、これらの手順はすべてプロセッサ上でローカルに実行されます。 start メソッドの下のセル出力は、パイプラインからの出力を示しています。
セル出力の下部に次のようなメッセージが表示されます。
Pipeline execution d8c3e172-089e-4e7a-ad6d-6d76caf987b7 SUCCEEDED
管理対象リソースに戻す
パイプラインがエラーなしで実行されることを確認し、パイプラインのフローと形式に満足したら、パイプラインを再作成できますが、SageMaker マネージド リソースを使用して再実行します。 必要な唯一の変更は、 PipelineSession オブジェクトの代わりに LocalPipelineSession:
sagemaker.workflow.pipeline_context インポート LocalPipelineSessionfrom sagemaker.workflow.pipeline_context import PipelineSession
local_pipeline_session = LocalPipelineSession()pipeline_session = PipelineSession()
これにより、SageMaker 管理リソースでこのセッションオブジェクトを参照して各ステップを実行するようにサービスに通知します。 小さな変更を考慮して、次のコード セルで必要なコード変更のみを示しますが、同じ変更を各セルに実装する必要があります。 local_pipeline_session 物体。 ただし、変更はすべてのセルで同じです。 local_pipeline_session を持つオブジェクト pipeline_session オブジェクト。
ローカル セッション オブジェクトがどこでも置き換えられた後、パイプラインを再作成し、SageMaker マネージド リソースで実行します。
クリーンアップ
Studio 環境を整頓したい場合は、次の方法を使用して SageMaker パイプラインとモデルを削除できます。 完全なコードはサンプルにあります ノート.
まとめ
最近まで、SageMaker Processing と SageMaker Training のローカル モード機能を使用して、SageMaker 管理リソースを使用してすべてのデータに対して実行する前に、処理スクリプトとトレーニング スクリプトをローカルで反復することができました。 SageMaker Pipelines の新しいローカルモード機能により、ML 実践者は、ML パイプラインで反復するときに同じ方法を適用して、さまざまな ML ワークフローをつなぎ合わせることができるようになりました。 パイプラインの本番環境の準備が整ったら、SageMaker が管理するリソースでパイプラインを実行するには、コードを数行変更するだけです。 これにより、開発中のパイプラインの実行時間が短縮され、SageMaker が管理するリソースのコストを削減しながら、より迅速な開発サイクルでより迅速なパイプライン開発につながります。
AmazonSageMakerパイプライン or SageMaker パイプラインを使用してローカルでジョブを実行する.
著者について
 ポール・ハーギス AWS、Amazon、Hortonworks など、いくつかの企業で機械学習に注力してきました。 彼はテクノロジー ソリューションを構築し、それを最大限に活用する方法を人々に教えることを楽しんでいます。 AWS での職務に就く前は、Amazon Exports and Expansions の主任アーキテクトとして、amazon.com が海外の買い物客のエクスペリエンスを改善するのを支援していました。 Paul は、顧客が機械学習イニシアチブを拡大して現実の問題を解決できるよう支援することを好みます。
ポール・ハーギス AWS、Amazon、Hortonworks など、いくつかの企業で機械学習に注力してきました。 彼はテクノロジー ソリューションを構築し、それを最大限に活用する方法を人々に教えることを楽しんでいます。 AWS での職務に就く前は、Amazon Exports and Expansions の主任アーキテクトとして、amazon.com が海外の買い物客のエクスペリエンスを改善するのを支援していました。 Paul は、顧客が機械学習イニシアチブを拡大して現実の問題を解決できるよう支援することを好みます。
 ニクラスパーム はスウェーデンのストックホルムにあるAWSのソリューションアーキテクトであり、北欧全域の顧客がクラウドで成功するのを支援しています。 彼は、IoTや機械学習とともにサーバーレステクノロジーに特に情熱を注いでいます。 仕事以外では、ニクラスは熱心なクロスカントリースキーヤーとスノーボーダーであり、マスターエッグボイラーでもあります。
ニクラスパーム はスウェーデンのストックホルムにあるAWSのソリューションアーキテクトであり、北欧全域の顧客がクラウドで成功するのを支援しています。 彼は、IoTや機械学習とともにサーバーレステクノロジーに特に情熱を注いでいます。 仕事以外では、ニクラスは熱心なクロスカントリースキーヤーとスノーボーダーであり、マスターエッグボイラーでもあります。
 キリット・サダカ SageMaker Service SA チームで働く ML ソリューション アーキテクトです。 AWS に参加する前は、初期段階の AI スタートアップで働いた後、AI 研究、MLOps、および技術的リーダーシップのさまざまな役割でコンサルティングを行っていました。
キリット・サダカ SageMaker Service SA チームで働く ML ソリューション アーキテクトです。 AWS に参加する前は、初期段階の AI スタートアップで働いた後、AI 研究、MLOps、および技術的リーダーシップのさまざまな役割でコンサルティングを行っていました。

