ローン予測問題に関するこの記事へようこそ。 以下は、このトピックの簡単な紹介であり、学習内容を理解するのに役立ちます。
この記事は、を使用して二項分類の問題を解決したい人を対象としています Python 。 この記事の終わりまでに、あなたはそのような問題を解決するために必要なスキルとテクニックを身につけるでしょう。 この記事はあなたのスキルを磨くのに十分な理論と実践の知識をあなたに提供します。
1.問題の概要
2.探索的データ分析(EDA)と前処理
3.モデル構築と特徴工学
これらのセクションは、理論とコーディングの例で補足されています。 さらに、データセットリソースを取得します。
この問題に対して、トレーニング、テスト、サンプル送信のXNUMXつのCSVファイルが提供されています。
ファイル名は、データハックプラットフォームからダウンロードしたトレインとテストファイルの名前に置き換える必要があります。
これらのデータセットで何かを変更しても元のデータセットが失われないように、トレインとテストデータのコピーを作成しましょう。
このセクションでは、トレインとテストのデータセットを見ていきます。 まず、データに存在する機能を確認し、次にそれらのデータ型を確認します。
12個の独立変数と1個のターゲット変数、つまりトレーニングデータセットのLoan_Statusがあります。 テストデータセットの列を見てみましょう。
Loan_Statusを除いて、テストデータセットにはトレーニングデータセットと同様の機能があります。 列車データを使用して構築されたモデルを使用して、Loan_Statusを予測します。 以下に、各変数の説明を示します。
データセットの形を見てみましょう。
トレーニングデータセットには614行と13列、テストデータセットには367行と12列があります。
このセクションでは、単変量解析を行います。 これは、各変数を個別に分析する最も簡単なデータ分析形式です。 カテゴリ機能の場合、頻度テーブルまたは棒グラフを使用して、特定の変数の各カテゴリの数を計算できます。 確率密度関数(PDF)を使用して、数値変数の分布を調べることができます。
まず、ターゲット変数、つまりLoan_Statusを確認します。 これはカテゴリ変数であるため、頻度テーブル、パーセンテージ分布、および棒グラフを見てみましょう。
変数の頻度テーブルは、その変数の各カテゴリの数を示します。
422人中69人(約614%)が承認を得ました。
それでは、各変数を個別に視覚化してみましょう。 さまざまなタイプの変数は、カテゴリー、順序、および数値です。
まず、カテゴリと順序の特徴を視覚化しましょう。
次に、順序変数を視覚化してみましょう。
これまで、カテゴリ変数と順序変数を見てきました。次に、数値変数を視覚化してみましょう。 まず、申請者の収入の分布を見てみましょう。
申請者の収入の分布のほとんどのデータは左側にあると推測できます。つまり、通常は分布していません。 データが通常に分散されている場合はアルゴリズムがより適切に機能するため、後のセクションでそれを正常にしようとします。
LoanAmount変数の分布を見てみましょう。
この変数には多くの外れ値があり、分布はかなり正常です。 異常値は後のセクションで扱います。
ここで、各機能がローンステータスとどの程度相関しているかを知りたいと思います。 したがって、次のセクションでは、二変量解析を見ていきます。
以前に生成したいくつかの仮説を思い出してみましょう。
- 高収入の申請者は、ローン承認の機会が増えるはずです。
- 以前の債務を返済した申請者は、ローン承認の可能性が高くなるはずです。
- ローンの承認は、ローンの金額にも依存する必要があります。 融資額が少なければ、融資承認の可能性は高くなります。
- ローンを返済するために毎月支払われる金額が少ないほど、ローン承認の可能性が高くなります。
二変量解析を使用して、上記の仮説をテストしてみましょう。
単変量解析ですべての変数を個別に調べた後、ターゲット変数に関してそれらを再び探索します。
カテゴリー独立変数とターゲット変数
まず、ターゲット変数とカテゴリカル独立変数の関係を見つけます。 積み上げ棒グラフを見てみましょう。承認されたローンと承認されていないローンの割合がわかります。
Gender=pd.crosstab(train['Gender'],train['Loan_Status']) Gender.div(Gender.sum(1).astype(float), axis=0).plot(kind="bar", figsize) =(4,4))
男性と女性の申請者の割合は、承認されたローンと承認されていないローンの両方でほぼ同じであると推測できます。
次に、残りのカテゴリ変数とターゲット変数を視覚化します。
既婚=pd.crosstab(train['既婚'],train['ローン_ステータス']) 扶養家族=pd.crosstab(train['扶養家族'],train['ローン_ステータス']) Education=pd.crosstab(train['Education'],train['Loan_Status']) Self_Employed=pd.crosstab(train['Self_Employed'],train['Loan_Status']) 既婚.div(既婚.sum(1).astype(float), axis=0).plot(kind="bar", figsize=(4,4)) plt.show() dependents.div(Dependents.sum(1).astype(float), axis=0).plot(kind="bar", stacked=True) plt.show() Education.div(Education.sum(1).astype(float), axis=0).plot(kind="bar", figsize=(4,4)) plt.show() Self_Employed.div(Self_Employed.sum(1).astype(float),axis=0).plot(kind="bar",figsize=(4,4)) plt.show()

- 承認されたローンの方が既婚者の割合が高くなっています。
- 1人または3人以上の扶養家族を持つ申請者の分布は、Loan_Statusの両方のカテゴリで類似しています。
- Self_Employed対Loan_Statusプロットから推測できる重要なものはありません。
次に、残りのカテゴリ独立変数とLoan_Statusの関係を見ていきます。
Credit_History=pd.crosstab(train['Credit_History'],train['Loan_Status']) Property_Area=pd.crosstab(train['Property_Area'],train['Loan_Status']) Credit_History.div(Credit_History.sum(1) .astype(float), axis=0).plot(kind="bar", stacked=True, figsize=(4,4)) plt.show() Property_Area.div(Property_Area.sum(1).astype(float) )、axis=0).plot(kind="bar"、stacked=True) plt.show()

- 信用履歴が1の人は、ローンが承認される可能性が高いようです。
- 準都市部で承認されるローンの割合は、農村部や都市部に比べて高くなっています。
次に、ターゲット変数に関して独立変数の数値を視覚化してみましょう。
数値独立変数とターゲット変数
ローンが承認された人の平均所得とローンが承認されなかった人の平均所得を比較してみます。
train.groupby('Loan_Status')['ApplicantIncome']。mean()。plot.bar()

ここで、y軸は申請者の平均収入を表します。 平均所得に変化は見られません。 そこで、その値に基づいて応募者の収入変数のビンを作成し、各ビンに対応するローンのステータスを分析しましょう。
bins=[0,2500,4000,6000,81000] group=['低','平均','高','非常に高い'] train['Income_bin']=pd.cut(train['ApplicantIncome'],bins,labels=group)
Income_bin=pd.crosstab(train['Income_bin'],train['Loan_Status'])
Income_bin.div(Income_bin.sum(1).astype(float), axis=0).plot(kind="bar", stacked=True)
plt.xlabel('申請者の収入')
P = plt.ylabel('パーセント')

申請者の収入は融資承認の可能性に影響を与えないと推測できます。これは、申請者の収入が高ければ融資承認の可能性も高いという仮説と矛盾します。
同様の方法で、申請者の収入と融資額の変数を分析します。
bins=[0,1000,3000,42000] group=['低','平均','高'] train['Coapplicant_Income_bin']=pd.cut(train['CoapplicantIncome'],bins,labels=group)
Coapplicant_Income_bin=pd.crosstab(train['Coapplicant_Income_bin'],train['Loan_Status'])
Coapplicant_Income_bin.div(Coapplicant_Income_bin.sum(1).astype(float), axis=0).plot(kind="bar", stacked=True)
plt.xlabel('共同応募者の収入')
P = plt.ylabel('パーセント')

これは、共同申請者の収入が少ない場合、ローン承認の可能性が高いことを示しています。 しかし、これは正しく見えません。 この背後にある考えられる理由は、ほとんどの申請者が共同申請者を持っていないため、そのような申請者の共同申請者の収入が0であり、したがってローンの承認がそれに依存していないことである可能性があります。 したがって、申請者と共同申請者の収入を組み合わせて、ローン承認に対する収入の複合効果を視覚化する新しい変数を作成できます。
Applicant IncomeとCo-applicant Incomeを組み合わせて、Loan_Statusに対するTotal Incomeの組み合わせ効果を見てみましょう。
train ['Total_Income'] = train ['ApplicantIncome'] + train ['CoapplicantIncome']
bins=[0,2500,4000,6000,81000] group=['低','平均','高','非常に高い'] train['Total_Income_bin']=pd.cut(train['Total_Income'],bins,labels=group)
Total_Income_bin=pd.crosstab(train['Total_Income_bin'],train['Loan_Status'])
Total_Income_bin.div(Total_Income_bin.sum(1).astype(float), axis=0).plot(kind="bar", stacked=True)
plt.xlabel('合計収入')
P = plt.ylabel('パーセント')

Total_Incomeが低い申請者に対して承認されるローンの割合は、平均、高、および非常に高い所得の申請者と比較して非常に少ないことがわかります。
ローン金額変数を視覚化してみましょう。
ビン=[0,100,200,700] グループ=['低','平均','高'] train['LoanAmount_bin']=pd.cut(train['LoanAmount'],bins,labels=group)
LoanAmount_bin=pd.crosstab(train['LoanAmount_bin'],train['Loan_Status'])
LoanAmount_bin.div(LoanAmount_bin.sum(1).astype(float), axis=0).plot(kind="bar", stacked=True)
plt.xlabel('融資金額')
P = plt.ylabel('パーセント')

融資額が少ないほど融資承認の可能性が高いという仮説を裏付ける高融資額に比べて、低融資額と平均融資額の方が承認融資の割合が高いことがわかります。
train = train.drop(['Income_bin'、'Coapplicant_Income_bin'、'LoanAmount_bin'、'Total_Income_bin'、'Total_Income']、axis = 1)
train['依存関係'].replace('3+', 3,inplace=True)
test['依存関係'].replace('3+', 3,inplace=True)
train['Loan_Status'].replace('N', 0,inplace=True)
train['Loan_Status'].replace('Y', 1,inplace=True)
次に、すべての数値変数間の相関関係を見てみましょう。 ヒートマップを使用して相関関係を視覚化します。 ヒートマップは、色の変化を通じてデータを視覚化します。 色が濃い変数は、それらの相関がより高いことを意味します。
行列 = train.corr() f, ax = plt.subplots(figsize=(9, 6)) sns.heatmap(matrix, vmax=.8, square=True, cmap="BuPu");

最も相関のある変数は(ApplicantIncome – LoanAmount)と(Credit_History – Loan_Status)であることがわかります。 LoanAmountは、CoapplicantIncomeとも相関関係があります。
行方不明の値と外れ値の処理
データ内のすべての変数を調べた後、欠測データと外れ値がモデルのパフォーマンスに悪影響を与える可能性があるため、欠測値を代入して外れ値を処理できます。
欠損値補完
欠落している値の機能ごとの数をリストアップしましょう。
train.isnull()。sum()

Gender、Married、Dependents、Self_Employed、LoanAmount、Loan_Amount_Term、Credit_Historyの各機能には欠損値があります。
すべての機能の欠損値をXNUMXつずつ扱います。
これらの方法を検討して、欠損値を埋めることができます。
- 数値変数の場合:平均または中央値を使用した補完
- カテゴリー変数の場合:モードを使用した代入
Gender、Married、Dependents、Credit_History、Self_Employedの各機能には欠落している値が非常に少ないため、機能のモードを使用してそれらを埋めることができます。
train ['Gender']。fillna(train ['Gender']。mode()[0]、inplace = True)train ['Married']。fillna(train ['Married']。mode()[0]、 inplace = True)train ['Dependents']。fillna(train ['Dependents']。mode()[0]、inplace = True)train ['Self_Employed']。fillna(train ['Self_Employed']。mode() [0]、inplace = True)train ['Credit_History']。fillna(train ['Credit_History']。mode()[0]、inplace = True)
次に、Loan_Amount_Termの欠損値を埋める方法を見つけてみましょう。 ローン金額の用語変数の値のカウントを見てみましょう。
train ['Loan_Amount_Term']。value_counts()

融資額期間変数では、360の値が最も繰り返されていることがわかります。 したがって、この変数のモードを使用して、この変数の欠落している値を置き換えます。
train ['Loan_Amount_Term']。fillna(train ['Loan_Amount_Term']。mode()[0]、inplace = True)
これで、LoanAmount変数が表示されます。 これは数値変数であるため、平均または中央値を使用して欠落値を代入できます。 「ローン金額」には外れ値があることを以前に見たように、中央値を使用してnull値を埋めます。したがって、外れ値の存在によって大きな影響を受けるため、平均は適切なアプローチではありません。
train ['LoanAmount']。fillna(train ['LoanAmount']。median()、inplace = True)
次に、欠落しているすべての値がデータセットに入力されているかどうかを確認しましょう。
train.isnull()。sum()

見てわかるように、すべての欠損値がテストデータセットに入力されています。 同じ方法で、テストデータセットのすべての欠損値も入力してみましょう。
test['Gender'].fillna(train['Gender'].mode()[0], inplace=True) test['Dependents'].fillna(train['Dependents'].mode()[0], inplace=True) test['Self_Employed'].fillna(train['Self_Employed'].mode()[0], inplace=True) test['Credit_History'].fillna(train['Credit_History'].mode() [0], inplace=True) test['Loan_Amount_Term'].fillna(train['Loan_Amount_Term'].mode()[0], inplace=True) test['LoanAmount'].fillna(train['LoanAmount'] .median()、inplace=True)
外れ値の処理
前に一変量分析で見たように、LoanAmountには外れ値が含まれているため、外れ値の存在がデータの分布に影響を与えるのでそれらを扱う必要があります。 外れ値を含むデータセットに何が起こり得るかを調べてみましょう。 サンプルデータセットの場合:
1、1、2、2、2、2、3、3、3、4、4
次のことがわかります:平均、中央値、最頻値、標準偏差
平均= 2.58
中央値= 2.5
ファッション= 2
標準偏差= 1.08
データセットに外れ値を追加すると、次のようになります。
1、1、2、2、2、2、3、3、3、4、4、400
統計の新しい値は次のとおりです。
平均= 35.38
中央値= 2.5
ファッション= 2
標準偏差= 114.74
外れ値があると、平均と標準偏差に大きな影響を及ぼし、分布に影響を与えることがよくあります。 データセットから外れ値を削除するための手順を実行する必要があります。
これらの外れ値のため、ローン金額のデータの大部分は左側にあり、右側のテールは長くなっています。 これは右歪度と呼ばれます。 歪度を取り除くXNUMXつの方法は、対数変換を行うことです。 ログ変換を行うと、小さい値にはあまり影響しませんが、大きい値は減少します。 したがって、正規分布と同様の分布が得られます。
ログ変換の効果を視覚化してみましょう。 テストデータにも同様の変更を同時に行います。
train['LoanAmount_log'] = np.log(train['LoanAmount']) train['LoanAmount_log'].hist(bins=20) test['LoanAmount_log'] = np.log(test['LoanAmount'])

これで、分布は正常に近くなり、極値の影響は大幅に緩和されました。 ロジスティック回帰モデルを作成して、テストデータセットの予測を作成してみましょう。
分類のための評価指標
モデル構築のプロセスは、モデルのパフォーマンスを評価せずに完了することはできません。 モデルからの予測があるとすると、予測が正確であるかどうかをどのように判断できますか? 結果をプロットして実際の値と比較できます。つまり、予測と実際の値の間の距離を計算できます。 この距離が小さいほど、予測は正確になります。 これは分類の問題であるため、次の評価指標のいずれかを使用してモデルを評価できます。
- 精度:-実際の値と予測値の表形式の表現である混同行列を使用して理解しましょう。 混同行列は次のようになります。

- True Positive –実際にtrue(Y)であり、true(Y)として予測したターゲット
- True Negative –実際にはfalse(N)であり、false(N)として予測したターゲット
- 誤検知–実際にはfalse(N)であるが、true(T)として予測したターゲット
- False Negative –実際にはtrue(T)であるが、false(N)として予測したターゲット
これらの値を使用して、モデルの精度を計算できます。 精度は次の式で与えられます。
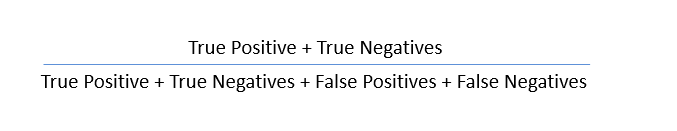
- 精度:-:これは、真の予測で達成された正確さの尺度です。つまり、真とラベル付けされた観測値、実際に真とラベル付けされた観測値の数です。
精度= TP /(TP + FP)
- リコール(感度):- これは、正しく予測された実際の観測値の尺度です。つまり、真のクラスの観測値の数が正しくラベル付けされています。 「感度」とも呼ばれます。
リコール= TP /(TP + FN)
- 特異性:- これは、偽のクラスの観測値が正しくラベル付けされている数の尺度です。
特異性=TN/(TN + FP)
特異性と感度は、ROC曲線を導き出す上で重要な役割を果たします。
- ROC曲線
- 受信者動作特性(ROC)は、真陽性率(感度)と偽陽性率(1-特異度)の間のトレードオフを評価することにより、モデルのパフォーマンスを要約します。
- 精度の指標(A)または一致指数と呼ばれる曲線下面積(AUC)は、ROC曲線の完全なパフォーマンスメトリックです。 曲線の下の面積が大きいほど、モデルの予測力は高くなります。
ROC曲線は次のようになります。

- この曲線の面積は、真陽性と真陰性を正しく分類するモデルの能力を測定します。 モデルで、trueクラスをtrueとして予測し、falseクラスをfalseとして予測する必要があります。
- したがって、真陽性率を1にしたいと言えます。しかし、真陽性率だけでなく、偽陽性率にも関心があります。 たとえば、私たちの問題では、YクラスをYとして予測するだけでなく、NクラスをNとして予測することも必要です。
- 上記の例のクラス2,3,4、5、XNUMX、およびXNUMXで最大になる曲線の面積を増やしたいと思います。
- クラス1の場合、偽陽性率が0.2の場合、真陽性率は約0.6です。 しかし、クラス2の場合、真陽性率は同じ偽陽性率で1です。 したがって、クラス2のAUCは、クラス1のAUCと比較してはるかに大きくなります。したがって、クラス2のモデルの方が優れています。
- クラス2,3,4、5、0、および1のモデルは、クラスXNUMXおよびXNUMXのモデルと比較して、AUCがこれらのクラスの方が高いため、より正確に予測します。
コンテストのページでは、提出データは正確性に基づいて評価されると述べられています。 したがって、評価指標として精度を使用します。
モデル構築:パート1
最初のモデルでターゲット変数を予測させましょう。 バイナリの結果を予測するために使用されるロジスティック回帰から始めます。
- ロジスティック回帰は分類アルゴリズムです。 一連の独立変数を指定して、バイナリの結果(1/0、Yes / No、True / False)を予測するために使用されます。
- ロジスティック回帰は、ロジット関数の推定です。 ロジット関数は、単にイベントを支持するオッズのログです。
- この関数は、必要なステップワイズ関数に非常に似ている確率推定値を使用してS字型の曲線を作成します
Loan_ID変数はローンのステータスに影響を与えないため、削除してみましょう。 トレーニングデータセットに対して行ったのと同じ変更をテストデータセットに対して行います。
train=train.drop('ローンID',axis=1)
test=test.drop('ローンID',axis=1)
Pythonのオープンソースライブラリであるさまざまなモデルを作成するために、「scikit-learn」(sklearn)を使用します。 これは、Pythonでのモデリングに使用できる多くの組み込み関数を含む最も効率的なツールのXNUMXつです。
Sklearnでは、別のデータセットにターゲット変数が必要です。 したがって、トレーニング変数からターゲット変数を削除し、別のデータセットに保存します。
X = train.drop('ローン_ステータス',1)
y = train.Loan_Status
次に、カテゴリ変数のダミー変数を作成します。 ダミー変数は、カテゴリ変数を一連の0と1に変換し、定量化と比較を非常に簡単にします。 最初にダミーのプロセスを理解しましょう:
- 「性別」変数を考えてみましょう。 男性と女性のXNUMXつのクラスがあります。
- ロジスティック回帰は数値のみを入力として受け取るため、男性と女性を数値に変更する必要があります。
- この変数にダミーを適用すると、「Gender」変数がXNUMXつの変数(Gender_MaleとGender_ Female)に変換されます。各クラスにXNUMXつ(男性と女性)です。
- Gender_Maleの値は、性別が女性の場合は0、性別が男性の場合は1になります。
X=pd.get_dummies(X) train=pd.get_dummies(電車) テスト=pd.get_dummies(テスト)
次に、トレーニングデータセットでモデルをトレーニングし、テストデータセットの予測を行います。 しかし、これらの予測を検証できますか? これを行うXNUMXつの方法は、trainデータセットをtrainとvalidationのXNUMXつの部分に分割することです。 このトレーニング部分でモデルをトレーニングし、それを使用して検証部分の予測を行うことができます。 このようにして、検証部分(テストデータセットにはない)の真の予測があるため、予測を検証できます。
sklearnのtrain_test_split関数を使用して、trainデータセットを分割します。 まず、train_test_splitをインポートしましょう。
sklearn.model_selectionからimporttrain_test_splitx_train、x_cv、y_train、y_cv = train_test_split(X、y、test_size = 0.3)
データセットは、トレーニングと検証の部分に分割されています。 sklearnからLogisticRegressionとaccuracy_scoreをインポートし、ロジスティック回帰モデルを適合させましょう。
sklearn.linear_model から LogisticRegression をインポート sklearn.metricsインポートaccuracy_scoreから
モデル = ロジスティック回帰() model.fit(x_train, y_train)

ここで、Cパラメータは正則化強度の逆数を表します。 正則化は、過剰適合を減らすために、パラメーター値の大きさを増やすことに対してペナルティを適用します。 Cの値が小さいほど、正則化が強くなります。 その他のパラメータについては、こちらを参照してください。
検証セットのLoan_Statusを予測し、その精度を計算してみましょう。
pred_cv = model.predict(x_cv)
精度を計算して、予測の精度を計算しましょう。
精度スコア(y_cv、pred_cv)

したがって、予測はほぼ80%正確です。つまり、ローンステータスの80%を正確に特定しました。
テストデータセットの予測を作成してみましょう。
pred_test = model.predict(test)
ソリューションチェッカーで送信する必要のある送信ファイルをインポートしましょう。
submit = pd.read_csv( "Sample_Submission_ZAuTl8O_FK3zQHh.csv")
最終的な送信には、Loan_IDと対応するLoan_Statusのみが必要です。 これらの列に、テストデータセットのLoan_IDと作成した予測、つまりそれぞれpred_testを入力します。
submit['Loan_Status']=pred_test submit['Loan_ID']=test_original['Loan_ID']
YとNの予測が必要であることを思い出してください。1と0をYとNに変換しましょう。
submit['Loan_Status'].replace(0, 'N',inplace=True) submit['Loan_Status'].replace(1, 'Y',inplace=True)
最後に、送信を.csv形式に変換し、送信を行ってリーダーボードの正確性を確認します。
pd.DataFrame(submission、columns = ['Loan_ID'、'Loan_Status'])。to_csv('logistic.csv')
この提出から、リーダーボードで0.7847の精度が得られました。
検証セットを作成する代わりに、相互検証を利用して予測を検証することもできます。 この手法については、次のセクションで学習します。
層化k分割交差検定を使用したロジスティック回帰
目に見えないデータに対するモデルの堅牢性を確認するには、検証を使用できます。 これは、モデルをトレーニングしないデータセットの特定のサンプルを予約する手法です。 その後、完成させる前にこのサンプルでモデルをテストします。 検証の一般的な方法の一部を以下に示します。
- 検証セットのアプローチ
- k分割交差検定
- 相互検証をXNUMXつ残します(LOOCV)
- 層別k分割交差検証
このセクションでは、層化されたk分割交差検定について学習します。 。 それがどのように機能するかを理解しましょう:
- 層別化は、データを再配置して、各折り目が全体を適切に表すようにするプロセスです。
- たとえば、各クラスがデータの50%を構成する二項分類問題では、すべてのフォールドで各クラスがインスタンスの約半分を構成するようにデータを配置するのが最適です。
- バイアスと分散の両方を処理する場合は、一般により良いアプローチです。
- ランダムに選択されたフォールドは、特に巨大なクラスの不均衡がある場合は、マイナークラスを適切に表さない場合があります。
以下は、k=5の場合の階層化されたk-fold検証の視覚化です。

sklearnからStratifiedKFoldをインポートして、モデルを適合させましょう。
sklearn.model_selectionからインポートStratifiedKFold
次に、階層化された5つのフォールドを持つ交差検証ロジスティックモデルを作成し、テストデータセットの予測を作成します。
i=1
kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True)
kf.split(X,y) の train_index,test_index の場合:
print('n{} of kfold {}'.format(i,kf.n_splits))
xtr,xvl = X.iloc[train_index],X.iloc[test_index]
ytr,yvl = y.iloc[train_index],y.iloc[test_index]
モデル = ロジスティック回帰(random_state=1)
model.fit(xtr, ytr)
pred_test = モデル.predict(xvl)
スコア = 精度スコア(yvl,pred_test)
print('accuracy_score',score)
i+=1
pred_test = モデル.predict(テスト)
pred=model.predict_proba(xvl)[:,1]
1/kfold 5 精度スコア 0.7983870967741935 2/kfold 5 精度スコア 0.8306451612903226 3/kfold 5 精度スコア 0.8114754098360656 4/kfold 5 精度スコア 0.7950819672131147 5/kfold 5 精度スコア 0.8278688524590164
このモデルの平均検証精度は0.81です。 roc曲線を視覚化してみましょう。
sklearnインポートメトリクスから
fpr、tpr、_ = metrics.roc_curve(yvl, pred)
auc = metrics.roc_auc_score(yvl, pred)
plt.figure(figsize=(12,8))
plt.plot(fpr,tpr,label="検証, auc="+str(auc))
plt.xlabel('誤検知率')
plt.ylabel('真陽性率') plt.legend(loc=4) plt.show()

AUC値は0.77でした。
submit['Loan_Status']=pred_test submit['Loan_ID']=test_original['Loan_ID']
YとNの予測が必要であることを思い出してください。1と0をYとNに変換しましょう。
submit['Loan_Status'].replace(0, 'N',inplace=True) submit['Loan_Status'].replace(1, 'Y',inplace=True)
送信を.csv形式に変換し、送信してリーダーボードの正確性を確認しましょう。
pd.DataFrame(submission、columns = ['Loan_ID'、'Loan_Status'])。to_csv('Logistic.csv')
この提出から、リーダーボードで0.78472の精度が得られました。 次に、さまざまなアプローチを使用してこの精度を向上させます。
フィーチャ工学
ドメインの知識に基づいて、ターゲット変数に影響を与える可能性のある新機能を考え出すことができます。 次のXNUMXつの新機能を作成します。
- 総収入:-議論されたように
二変量解析では、申請者の収入と共同申請者の収入を組み合わせます。 総収入が高い場合、ローンの可能性
承認も高いかもしれません。 - EMI:-EMIは月額から
ローンを返済するために申請者によって支払われる。 これを作る背後にある考え方
変動するのは、EMIが高い人は難しいと感じるかもしれないということです
ローンを返済します。 ローンの比率をとることでEMIを計算できます
ローン金額期間に対する金額。 - バランス収入:-これ
EMIが支払われた後に残った収入です。 作成の背後にある考え方
この変数は、この値が高い場合、
人はローンを返済するので、ローンのチャンスが増えます
承認。
train ['Total_Income'] = train ['ApplicantIncome'] + train ['CoapplicantIncome'] test ['Total_Income'] = test ['ApplicantIncome'] + test ['CoapplicantIncome']
総所得の分布を見てみましょう。
sns.distplot(train ['Total_Income']);

左にシフトしている、つまり分布が右に歪んでいることがわかります。 それでは、分布を正規分布にするために対数変換を行いましょう。
左にシフトしている、つまり分布が右に歪んでいることがわかります。 それでは、分布を正規分布にするために対数変換を行いましょう。
train['Total_Income_log'] = np.log(train['Total_Income']) sns.distplot(train['Total_Income_log']); test['Total_Income_log'] = np.log(test['Total_Income'])

これで、分布は正常に近くなり、極値の影響は大幅に緩和されました。 では、EMI機能を作成しましょう。
これで、分布は正常に近くなり、極値の影響は大幅に緩和されました。 では、EMI機能を作成しましょう。
train['EMI']=train['LoanAmount']/train['Loan_Amount_Term'] test['EMI']=test['LoanAmount']/test['Loan_Amount_Term']
EMI変数の分布を確認してみましょう。
sns.distplot(train ['EMI']);

ここでバランス収入機能を作成し、その分布を確認しましょう。
train['残高']=train['Total_Income']-(train['EMI']*1000) # 単位を等しくするには 1000 を掛けます test['残高']=test['Total_Income']-(test['EMI']*1000)
sns.distplot(train ['Balance Income']);

これらの新しい機能を作成するために使用した変数を削除してみましょう。 これを行う理由は、これらの古い機能とこれらの新しい機能の間の相関が非常に高くなり、ロジスティック回帰は変数が高度に相関していないことを前提としているためです。 また、データセットからノイズを削除したいので、相関する特徴を削除すると、ノイズの削減にも役立ちます。
train = train.drop(['ApplicantIncome'、'CoapplicantIncome'、'LoanAmount'、'Loan_Amount_Term']、axis = 1)
test = test.drop(['ApplicantIncome'、'CoapplicantIncome'、'LoanAmount'、'Loan_Amount_Term']、axis = 1)
モデル構築:パート2
新しい機能を作成した後、モデル構築プロセスを続行できます。 したがって、デシジョンツリーモデルから始めて、RandomForestやXGBoostなどのより複雑なモデルに移ります。
このセクションでは、次のモデルを作成します。
- 決定木
- ランダムフォレスト
- XGブースト
モデルにフィードするためのデータを準備しましょう。
X = train.drop('ローン_ステータス',1)
y = train.Loan_Status
決定木
決定木は、分類問題で主に使用される教師あり学習アルゴリズムの一種です(事前定義されたターゲット変数があります)。 この手法では、入力変数の最も重要なスプリッター/微分器に基づいて、母集団またはサンプルをXNUMXつ以上の同種のセット(またはサブ母集団)に分割します。
ディシジョンツリーは複数のアルゴリズムを使用して、ノードをXNUMXつ以上のサブノードに分割することを決定します。 サブノードを作成すると、結果のサブノードの均一性が向上します。 つまり、対象変数に対してノードの純度が高くなっていると言えます。
sklearnインポートツリーから
5つのフォールドの交差検証を使用して、決定木モデルを適合させましょう。
i=1
kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True)
kf.split(X,y) の train_index,test_index の場合:
print('n{} of kfold {}'.format(i,kf.n_splits))
xtr,xvl = X.loc[train_index],X.loc[test_index]
ytr,yvl = y[train_index],y[test_index]
モデル = ツリー.DecisionTreeClassifier(random_state=1)
モデル.フィット(xtr, ytr)
pred_test = モデル.predict(xvl)
スコア = 精度スコア(yvl,pred_test)
print('accuracy_score',score)
i+=1
pred_test = モデル.predict(テスト)

このモデルの平均検証精度は0.69です。
submit['Loan_Status']=pred_test # Loan_Status に予測を入力します submit['Loan_ID']=test_original['Loan_ID'] # Loan_ID をテスト Loan_ID で埋める
submit['Loan_Status'].replace(0, 'N',inplace=True) submit['Loan_Status'].replace(1, 'Y',inplace=True)
# 提出ファイルを .csv 形式に変換する
pd.DataFrame(submission, columns=['Loan_ID','Loan_Status']).to_csv('Decision Tree.csv')
決定木モデルの精度よりもはるかに低い0.69の精度が得られました。 それでは、別のモデル、つまりツリーベースのアンサンブルアルゴリズムであるランダムフォレストを構築し、精度を向上させることでモデルを改善してみましょう。
ランダムフォレスト
- RandomForestは、ツリーベースのブートストラップアルゴリズムで、特定の番号はありません。 弱学習器(決定木)を組み合わせて、強力な予測モデルを作成します。
- 個々の学習者ごとに、行のランダムなサンプルとランダムに選択されたいくつかの変数を使用して、決定木モデルを構築します。
- 最終的な予測は、個々の学習者によって行われたすべての予測の関数にすることができます。
- 回帰問題の場合、最終的な予測はすべての予測の平均になります。
sklearn.ensembleからインポートRandomForestClassifier
i=1
kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True)
kf.split(X,y) の train_index,test_index の場合:
print('n{} of kfold {}'.format(i,kf.n_splits))
xtr,xvl = X.loc[train_index],X.loc[test_index]
ytr,yvl = y[train_index],y[test_index]
モデル = RandomForestClassifier(random_state=1, max_ Depth=10)
モデル.フィット(xtr, ytr)
pred_test = モデル.predict(xvl)
スコア = 精度スコア(yvl,pred_test)
print('accuracy_score',score)
i+=1
pred_test = モデル.predict(テスト)

このモデルの平均検証精度は0.766です。
このモデルのハイパーパラメータを調整することにより、精度の向上を試みます。 グリッド検索を使用して、ハイパーパラメータの最適化された値を取得します。 グリッド検索は、パラメーターのグリッドによってパラメーター化された、ハイパーパラメーターのファミリーの最良のものを選択する方法です。
max_depthおよびn_estimatorsパラメーターを調整します。 max_depthはツリーの最大深度を決定し、n_estimatorsはランダムフォレストモデルで使用されるツリーの数を決定します。
sklearn.model_selectionからインポートGridSearchCV
#n_estimatorsには、max_depthの範囲を1〜20の範囲で2の間隔で指定し、1〜200の範囲を20の間隔で指定します
paramgrid = {'max_ Depth': list(range(1, 20, 2)),
'n_estimators': list(range(1, 200, 20))}
grid_search = GridSearchCV(RandomForestClassifier(random_state = 1)、paramgrid)from sklearn.model_selection import train_test_split
# グリッド検索モデルを当てはめる Grid_search.fit(x_train,y_train)
GridSearchCV(cv=なし、error_score='raise'、
estimator=RandomForestClassifier(bootstrap=True, class_weight=None,
criterion='gini'、max_ Depth=なし、max_features='auto'、
max_leaf_nodes=なし、min_impurity_decrease=0.0、
min_impurity_split=なし、min_samples_leaf=1、min_samples_split=2、
min_weight_fraction_leaf=0.0、n_estimators=10、n_jobs=1、oob_score=False、
random_state=1、verbose=0、warm_start=False)、
fit_params=なし、iid=True、n_jobs=1、
param_grid={'max_ Depth': [1, 3, 5, 7, 9, 11, 13, 15, 17, 19],
'n_estimators': [1, 21, 41, 61, 81, 101, 121, 141, 161, 181]},
pre_dispatch='2*n_jobs'、refit=True、return_train_score='warn'、スコアリング=なし、verbose=0)
#最適化された値の推定
Grid_search.best_estimator_

したがって、max_depth変数の最適化された値は3で、n_estimatorの最適化された値は41です。次に、これらの最適化された値を使用してモデルを構築しましょう。
i=1
kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True)
kf.split(X,y) の train_index,test_index の場合:
print('n{} of kfold {}'.format(i,kf.n_splits))
xtr,xvl = X.loc[train_index],X.loc[test_index]
ytr,yvl = y[train_index],y[test_index]
モデル = RandomForestClassifier(random_state=1、max_ Depth=3、n_estimators=41)
モデル.フィット(xtr, ytr)
pred_test = モデル.predict(xvl)
スコア = 精度スコア(yvl,pred_test)
print('accuracy_score',score)
i+=1
pred_test = モデル.predict(テスト)
pred2 = model.predict_proba(テスト[:,1]

submit['Loan_Status']=pred_test # Loan_Status に予測を入力します submit['Loan_ID']=test_original['Loan_ID'] # Loan_ID をテスト Loan_ID で埋める
submit['Loan_Status'].replace(0, 'N',inplace=True) submit['Loan_Status'].replace(1, 'Y',inplace=True)
# 提出ファイルを .csv 形式に変換する
pd.DataFrame(submission, columns=['Loan_ID','Loan_Status']).to_csv('Random Forest.csv')
リーダーボードのランダムフォレストモデルから0.7638の精度が得られました。
ここで、機能の重要性、つまり、この機能で最も重要な機能を見つけてみましょう。 そのために、sklearnのfeature_importances_属性を使用します。
importants=pd.Series(model.feature_importances_,index=X.columns) importants.plot(kind='barh', figsize=(12,8))

Credit_Historyが最も重要な機能であり、次にBalance Income、Total Income、EMIが続くことがわかります。 したがって、特徴工学は、ターゲット変数を予測するのに役立ちました。
XGブースト
XGBoostは高速で効率的なアルゴリズムであり、多くのデータサイエンスコンテストの優勝者によって使用されています。 これはブースティングアルゴリズムであり、ブースティングの詳細については、以下の記事を参照してください。
XGBoostは数値変数でのみ機能し、カテゴリ変数は数値変数に既に置き換えられています。 モデルで使用するパラメーターを見てみましょう。
- n_estimator:モデルのツリー数を指定します。
- max_depth:このパラメーターを使用して、ツリーの最大深度を指定できます。
xgboostからインポートXGBClassifier
i=1
kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True)
kf.split(X,y) の train_index,test_index の場合:
print('n{} of kfold {}'.format(i,kf.n_splits))
xtr,xvl = X.loc[train_index],X.loc[test_index]
ytr,yvl = y[train_index],y[test_index]
モデル = XGBClassifier(n_estimators=50、max_ Depth=4)
モデル.フィット(xtr, ytr)
pred_test = モデル.predict(xvl)
スコア = 精度スコア(yvl,pred_test)
print('accuracy_score',score)
i+=1
pred_test = model.predict(test)pred2 = model.predict_proba(test [:、1]

このモデルの平均検証精度は0.79です。
submit['Loan_Status']=pred_test # Loan_Status に予測を入力します submit['Loan_ID']=test_original['Loan_ID'] # Loan_ID をテスト Loan_ID で埋める
submit['Loan_Status'].replace(0, 'N',inplace=True) submit['Loan_Status'].replace(1, 'Y',inplace=True)
# 提出ファイルを .csv 形式に変換する
pd.DataFrame(submission, columns=['Loan_ID','Loan_Status']).to_csv('XGBoost.csv')
このモデルでは0.73611の精度が得られました。 この記事が、機械学習の競争への取り組み方と、堅牢なモデルを構築するために実行する必要のある手順を理解するのに役立つことを願っています。 したがって、この分析を複製して、問題が発生した場合はお知らせください。
まとめ
モデルの予測を改善するために試すことができることはまだたくさんあります。 変数を作成して追加したり、機能や行のサブセットが異なるさまざまなモデルを試したりします。アイデアの一部を以下に示します。
- グリッド検索を使用してXGBoostモデルをトレーニングし、ハイパーパラメーターを最適化して精度を向上させることができます。
- 応募者を1,2,3、XNUMX、XNUMX人以上の扶養家族と組み合わせて、EDAパートで説明したように新しい機能を作成できます。
- さらにいくつかのパターンを発見するために、独立変数と独立変数の視覚化を行うこともできます。
- また、金利も含まれる可能性のあるより良い式を使用してEMIに到達することもできます。
- We
アンサンブルモデリング(異なるモデルの組み合わせ)を試すこともできます。 に
これらの記事を参照できるアンサンブルテクニックの詳細を読む
重要なポイント
1.本当の問題を理解する
2.探索的データ分析(EDA)と前処理
3.単変量、二変量の概念を理解する
4.データから外れ値ポイントを見つける方法
5.メトリックを使用してモデルを評価する方法
6.特徴工学のいくつかのテクニックも学びます
7.アルゴリズムが少ないモデル構築
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。

