
תמונה מאת המחבר
Mistral AI, אחת מחברות המחקר המובילות בעולם בתחום הבינה המלאכותית, פרסמה לאחרונה את מודל הבסיס עבור Mistral 7B v0.2.
מודל שפת קוד פתוח זה נחשף במהלך אירוע ההאקתון של החברה ב-23 במרץ 2024.
לדגמי Mistral 7B יש 7.3 מיליארד פרמטרים, מה שהופך אותם לחזקים במיוחד. הם מעלים על ה-Llama 2 13B ו-Llama 1 34B כמעט בכל המדדים. הדגם האחרון של V0.2 מציג חלון הקשר של 32k בין שאר ההתקדמות, ומשפר את יכולתו לעבד וליצור טקסט.
בנוסף, הגרסה שהוכרזה לאחרונה היא הדגם הבסיסי של הגרסה המכווננת להוראות, "Mistral-7B-Instruct-V0.2", אשר שוחרר מוקדם יותר בשנה שעברה.
במדריך זה, אני אראה לך כיצד לגשת ולכוונן את מודל השפה הזה ב-Huging Face.
אנו נבצע כוונון עדין של דגם הבסיס של Mistral 7B-v0.2 באמצעות פונקציונליות AutoTrain של Hugging Face.
פנים מחבקות ידועה בדמוקרטיזציה של גישה למודלים של למידת מכונה, המאפשרת למשתמשים יומיומיים לפתח פתרונות AI מתקדמים.
AutoTrain, תכונה של Hugging Face, הופכת את תהליך אימון המודלים לאוטומטי, והופכת אותו לנגיש ויעיל.
זה עוזר למשתמשים לבחור את הפרמטרים ואת טכניקות האימון הטובות ביותר בעת כוונון עדין של מודלים, שזו משימה שאחרת יכולה להיות מרתיעה וגוזלת זמן.
להלן 5 שלבים לכוונון עדין של דגם Mistral-7B שלך:
1. הקמת הסביבה
תחילה עליך ליצור חשבון עם Hugging Face, ולאחר מכן ליצור מאגר דגמים.
כדי להשיג זאת, פשוט בצע את השלבים המפורטים כאן קישור וחזור להדרכה זו.
אנו נאמן את המודל ב- Python. כשזה מגיע לבחירת סביבת מחברת לאימון, אתה יכול להשתמש מחברות Kaggle or גוגל קולאב, שניהם מספקים גישה חופשית למעבדי GPU.
אם תהליך האימון לוקח יותר מדי זמן, אולי כדאי לעבור לפלטפורמת ענן כמו AWS Sagemaker או Azure ML.
לבסוף, בצע את התקנות ה-pip הבאות לפני שתתחיל בקידוד למדריך זה:
!pip install -U autotrain-advanced
!pip install datasets transformers2. הכנת מערך הנתונים שלך
במדריך זה, נשתמש ב- מערך נתונים של אלפקה ב-Huging Face, שנראה כך:
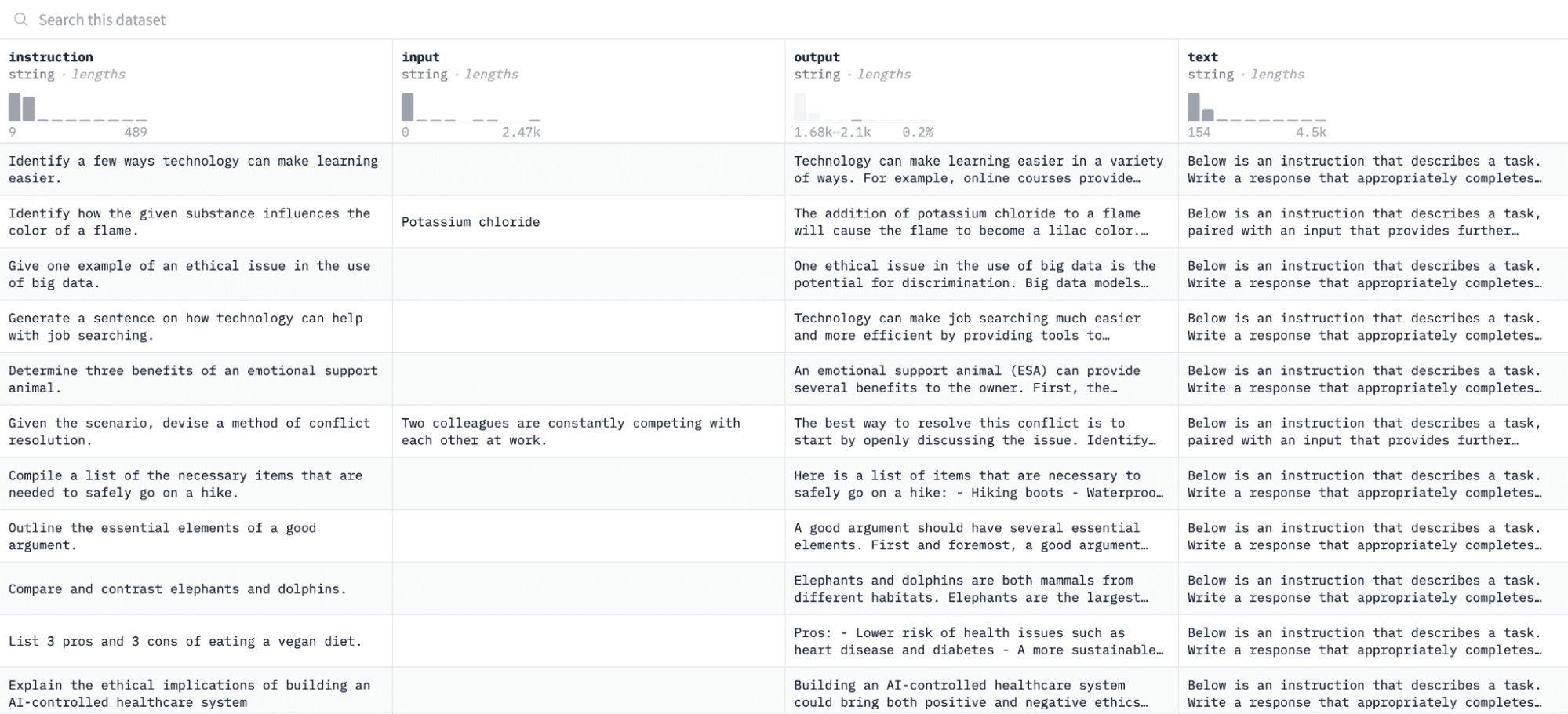
נכוון את המודל לפי צמדי הוראות ותפוקות ונעריך את יכולתו להגיב להוראה שניתנה בתהליך ההערכה.
כדי לגשת ולהכין מערך נתונים זה, הפעל את שורות הקוד הבאות:
import pandas as pd
from datasets import load_dataset
# Load and preprocess dataset
def preprocess_dataset(dataset_name, split_ratio='train[:10%]', input_col='input', output_col='output'):
dataset = load_dataset(dataset_name, split=split_ratio)
df = pd.DataFrame(dataset)
chat_df = df[df[input_col] == ''].reset_index(drop=True)
return chat_df
# Formatting according to AutoTrain requirements
def format_interaction(row):
formatted_text = f"[Begin] {row['instruction']} [End] {row['output']} [Close]"
return formatted_text
# Process and save the dataset
if __name__ == "__main__":
dataset_name = "tatsu-lab/alpaca"
processed_data = preprocess_dataset(dataset_name)
processed_data['formatted_text'] = processed_data.apply(format_interaction, axis=1)
save_path = 'formatted_data/training_dataset'
os.makedirs(save_path, exist_ok=True)
file_path = os.path.join(save_path, 'formatted_train.csv')
processed_data[['formatted_text']].to_csv(file_path, index=False)
print("Dataset formatted and saved.")הפונקציה הראשונה תטען את מערך הנתונים של Alpaca באמצעות ספריית "מערכי הנתונים" ותנקה אותו כדי להבטיח שאיננו כוללים הוראות ריקות. הפונקציה השנייה מבנה את הנתונים שלך בפורמט ש-AutoTrain יכול להבין.
לאחר הפעלת הקוד לעיל, מערך הנתונים ייטען, יעוצב ויישמר בנתיב שצוין. כאשר אתה פותח את מערך הנתונים המעוצב שלך, אתה אמור לראות עמודה אחת שכותרתה "פורמט_טקסט".
3. הגדרת סביבת האימון שלך
כעת, לאחר שהכנת בהצלחה את מערך הנתונים, בוא נמשיך להגדיר את סביבת האימון המודל שלך.
לשם כך, עליך להגדיר את הפרמטרים הבאים:
project_name = 'mistralai'
model_name = 'alpindale/Mistral-7B-v0.2-hf'
push_to_hub = True
hf_token = 'your_token_here'
repo_id = 'your_repo_here.'להלן פירוט של המפרטים לעיל:
- אתה יכול לציין כל שם הפרוייקט. זה המקום שבו כל הפרויקטים וההדרכה שלך יאוחסנו.
- אל האני שם המודל פרמטר הוא הדגם שאתה רוצה לכוונן. במקרה זה, ציינתי נתיב ל- דגם בסיס Mistral-7B v0.2 על חיבוק פנים.
- אל האני hf_token יש להגדיר את המשתנה לאסימון החיבוק שלך, אותו ניתן להשיג על ידי ניווט אל קישור זה.
- repo_id חייב להיות מוגדר למאגר המודלים של Hugging Face שיצרת בשלב הראשון של מדריך זה. לדוגמה, מזהה המאגר שלי הוא NatasshaS/Model2.
4. הגדרת פרמטרים של דגם
לפני כוונון עדין של המודל שלנו, עלינו להגדיר את פרמטרי האימון, השולטים בהיבטים של התנהגות המודל כמו משך האימון והסדרה.
פרמטרים אלה משפיעים על היבטים מרכזיים כמו משך הזמן שהמודל מתאמן, כיצד הוא לומד מהנתונים וכיצד הוא נמנע מהתאמה יתר.
אתה יכול להגדיר את הפרמטרים הבאים עבור הדגם שלך:
use_fp16 = True
use_peft = True
use_int4 = True
learning_rate = 1e-4
num_epochs = 3
batch_size = 4
block_size = 512
warmup_ratio = 0.05
weight_decay = 0.005
lora_r = 8
lora_alpha = 16
lora_dropout = 0.015. הגדרת משתני סביבה
כעת נכין את סביבת האימון שלנו על ידי הגדרת כמה משתני סביבה.
שלב זה מבטיח שתכונת AutoTrain תשתמש בהגדרות הרצויות כדי לכוונן את הדגם, כגון שם הפרויקט והעדפות ההדרכה שלנו:
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)6. ליזום הדרכת מודלים
לבסוף, בואו נתחיל לאמן את המודל באמצעות ה רכבת אוטומטית פקודה. שלב זה כולל ציון תצורות המודל, מערך הנתונים ותצורות ההדרכה שלך, כפי שמוצג להלן:
!autotrain llm
--train
--model "${MODEL_NAME}"
--project-name "${PROJECT_NAME}"
--data-path "formatted_data/training_dataset/"
--text-column "formatted_text"
--lr "${LEARNING_RATE}"
--batch-size "${BATCH_SIZE}"
--epochs "${NUM_EPOCHS}"
--block-size "${BLOCK_SIZE}"
--warmup-ratio "${WARMUP_RATIO}"
--lora-r "${LORA_R}"
--lora-alpha "${LORA_ALPHA}"
--lora-dropout "${LORA_DROPOUT}"
--weight-decay "${WEIGHT_DECAY}"
$( [[ "$USE_FP16" == "True" ]] && echo "--mixed-precision fp16" )
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" )
$( [[ "$USE_INT4" == "True" ]] && echo "--quantization int4" )
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )הקפד לשנות את נתיב נתונים למקום שבו נמצא מערך ההדרכה שלך.
7. הערכת המודל
לאחר שהדגם שלך סיים את ההכשרה, אתה אמור לראות תיקיה מופיעה בספרייה שלך עם כותרת זהה לשם הפרויקט שלך.
במקרה שלי, התיקיה הזו נקראת "מסטראלי," כפי שניתן לראות בתמונה למטה:
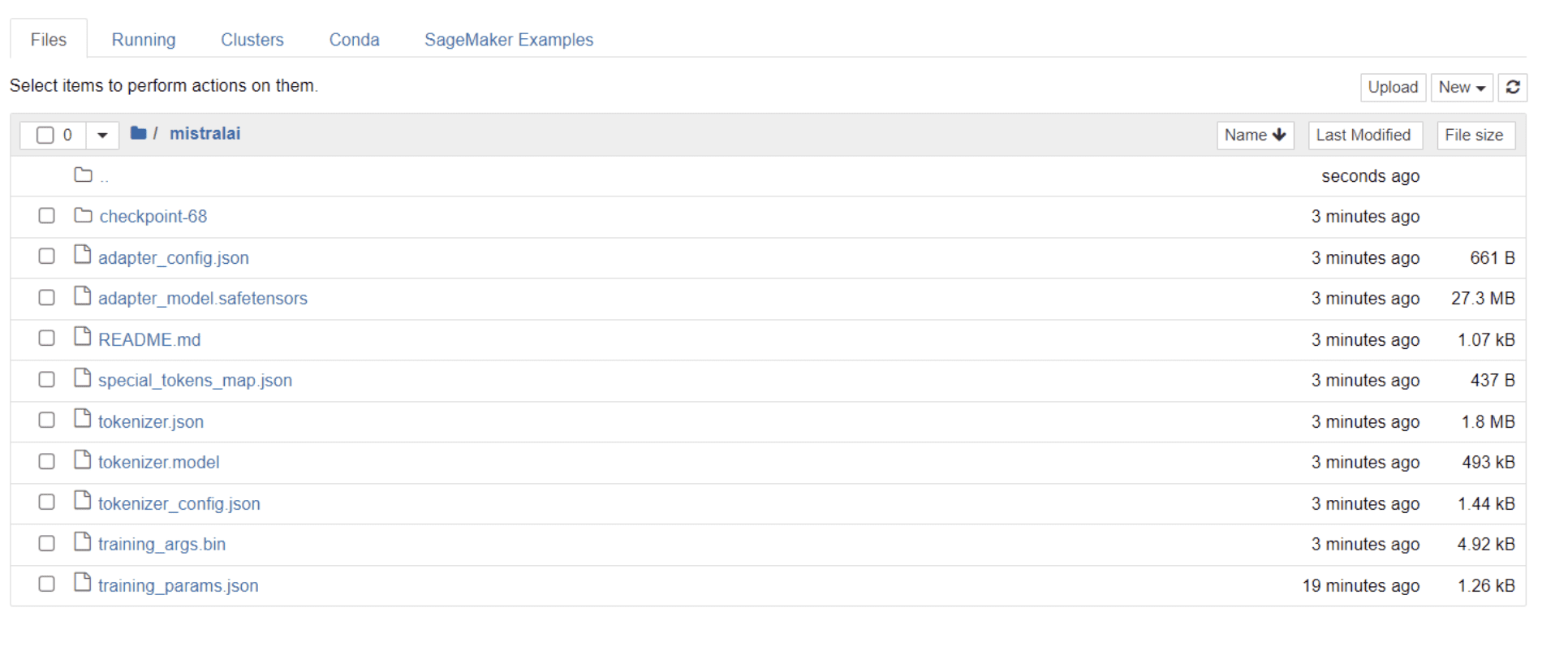
בתוך תיקיה זו, אתה יכול למצוא קבצים שמקיפים את משקלי הדגם, הפרמטרים ההיפר-פרמטרים ופרטי הארכיטקטורה שלך.
כעת נבדוק אם המודל המכוונן הזה מסוגל להגיב במדויק לשאלה במערך הנתונים שלנו. כדי להשיג זאת, תחילה עלינו להפעיל את שורות הקוד הבאות כדי ליצור 5 כניסות ויציאות לדוגמה ממערך הנתונים שלנו:
# Print out 5 sample inputs and outputs from our dataset
for i, example in enumerate(dataset):
if i >= 5:
break
print(f"Instruction: {example['instruction']}")
print(f"Output: {example['output']}n---")אתה אמור לראות תגובה שנראית כך, המציגה 5 נקודות נתונים לדוגמה:
Instruction: Give three tips for staying healthy.
Output: 1.Eat a balanced diet and make sure to include plenty of fruits and vegetables.
2. Exercise regularly to keep your body active and strong.
3. Get enough sleep and maintain a consistent sleep schedule.
---
Instruction: What are the three primary colors?
Output: The three primary colors are red, blue, and yellow.
---
Instruction: Describe the structure of an atom.
Output: An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom.
---
Instruction: How can we reduce air pollution?
Output: There are a number of ways to reduce air pollution, such as shifting to renewable energy sources, encouraging the use of public transportation, prohibiting the burning of fossil fuels, implementing policies to reduce emissions from industrial sources, and implementing vehicle emissions standards. Additionally, individuals can do their part to reduce air pollution by reducing car use, avoiding burning materials such as wood, and changing to energy efficient appliances.
---
Instruction: Describe a time when you had to make a difficult decision.
Output: I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client's expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team's resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client's expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities.אנחנו הולכים להקליד את אחת מההוראות לעיל במודל ולבדוק אם הוא מייצר פלט מדויק. הנה פונקציה לספק הוראה לדגם ולקבל ממנו תגובה:
# Function to provide an instruction
def ask(model, tokenizer, question, max_length=128):
inputs = tokenizer.encode(question, return_tensors='pt')
outputs = model.generate(inputs, max_length=max_length, num_return_sequences=1)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return answerלבסוף, הזן שאלה לפונקציה זו כפי שמוצג להלן:
question = "Describe a time when you had to make a difficult decision."
answer = ask(model, tokenizer, question)
print(answer)המודל שלך אמור ליצור תגובה זהה לפלט המקביל שלו במערך ההדרכה, כפי שמוצג להלן:
Describe a time when you had to make a difficult decision.
What did you do? How did it turn out?
[/INST] I remember a time when I had to make a difficult decision about
my career. I had been working in the same job for several years and had
grown tired of it. I knew that I needed to make a change, but I was unsure of what to do. I weighed my options carefully and eventually decided to take a leap of faith and start my own business. It was a risky move, but it paid off in the end. I am now the owner of a successful business andשים לב שהתשובה עשויה להיראות חלקית או מנותקת בגלל מספר האסימונים שציינו. אל תהסס להתאים את הערך "max_length" כדי לאפשר תגובה מורחבת יותר.
אם הגעתם עד הלום, מזל טוב!
כיוונתם בהצלחה מודל שפה מתקדם, תוך מינוף העוצמה של Mistral 7B v-0.2 לצד היכולות של Hugging Face.
אבל המסע לא מסתיים כאן.
כשלב הבא, אני ממליץ להתנסות עם מערכי נתונים שונים או לכוונן פרמטרים מסוימים של אימון כדי לייעל את ביצועי המודל. כוונון עדין של מודלים בקנה מידה גדול יותר ישפר את השימושיות שלהם, אז נסה להתנסות עם מערכי נתונים גדולים יותר או פורמטים משתנים, כגון קובצי PDF וקבצי טקסט.
ניסיון כזה הופך לבעל ערך רב כאשר עובדים עם נתונים מהעולם האמיתי בארגונים, שלעתים קרובות הוא מבולגן ובלתי מובנה.
נטשה סלבארג ' הוא מדען נתונים אוטודידקט עם תשוקה לכתיבה. נטשה כותבת על כל מה שקשור למדעי הנתונים, מאסטר אמיתי בכל נושאי הנתונים. אתה יכול להתחבר אליה הלאה לינקדין או לבדוק אותה ערוץ YouTube.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://www.kdnuggets.com/mistral-7b-v02-fine-tuning-mistral-new-open-source-llm-with-hugging-face?utm_source=rss&utm_medium=rss&utm_campaign=mistral-7b-v0-2-fine-tuning-mistrals-new-open-source-llm-with-hugging-face

