מבוא
בלב ה מדע נתונים סטטיסטיקת שקרים, שקיימת כבר מאות שנים אך נותרה חיונית ביסודה בעידן הדיגיטלי של היום. למה? כי מושגי סטטיסטיקה בסיסיים הם עמוד השדרה של ניתוח נתונים, מה שמאפשר לנו להבין את כמויות הנתונים העצומות שנוצרות מדי יום. זה כמו לשוחח עם נתונים, שם הסטטיסטיקה עוזרת לנו לשאול את השאלות הנכונות ולהבין את הסיפורים שהנתונים מנסים לספר.
מחיזוי מגמות עתידיות וקבלת החלטות על סמך נתונים ועד לבדיקת השערות ומדידת ביצועים, סטטיסטיקה היא הכלי שמניע את התובנות מאחורי החלטות מונעות נתונים. זהו הגשר בין נתונים גולמיים לתובנות ניתנות לפעולה, מה שהופך אותו לחלק הכרחי ממדעי הנתונים.
במאמר זה, ריכזתי את 15 המושגים הסטטיסטיים הבסיסיים המובילים שכל מתחיל במדעי הנתונים צריך לדעת!

תוכן העניינים
1. דגימה סטטיסטית ואיסוף נתונים
נלמד כמה מושגי סטטיסטיקה בסיסיים, אבל ההבנה מהיכן מגיעים הנתונים שלנו וכיצד אנחנו אוספים אותם חיונית לפני צלילה עמוק לתוך אוקיינוס הנתונים. כאן נכנסות לתמונה אוכלוסיות, מדגמים וטכניקות דגימה שונות.
תארו לעצמכם שאנחנו רוצים לדעת את הגובה הממוצע של אנשים בעיר. זה מעשי למדוד את כולם, אז אנחנו לוקחים קבוצה קטנה יותר (מדגם) המייצגת את האוכלוסייה הגדולה יותר. הטריק טמון באופן שבו אנו בוחרים את המדגם הזה. טכניקות כמו דגימה אקראית, מרובדת או מקבץ מבטיחות שהמדגם שלנו מיוצג היטב, ממזער את ההטיה והופכת את הממצאים שלנו לאמינים יותר.
על ידי הבנת אוכלוסיות ומדגמים, אנו יכולים להרחיב בביטחון את התובנות שלנו מהמדגם לכלל האוכלוסייה, לקבל החלטות מושכלות ללא צורך בסקר את כולם.
2. סוגי נתונים וסולם מדידה
הנתונים מגיעים בטעמים שונים, והכרת סוג הנתונים שאתה מתמודד איתם היא חיונית לבחירת הכלים והטכניקות הסטטיסטיות הנכונות.
נתונים כמותיים ואיכותיים
- מידע כמותי: סוג זה של נתונים עוסק בסך הכל במספרים. זה ניתן למדידה וניתן להשתמש בו לחישובים מתמטיים. נתונים כמותיים אומרים לנו "כמה" או "כמה", כמו מספר המשתמשים המבקרים באתר או הטמפרטורה בעיר. זה פשוט ואובייקטיבי, מספק תמונה ברורה באמצעות ערכים מספריים.
- נתונים איכותיים: לעומת זאת, נתונים איכותיים עוסקים במאפיינים ובתיאורים. זה קשור ל"איזה סוג" או "איזו קטגוריה". תחשוב על זה כעל הנתונים המתארים תכונות או תכונות, כגון צבע של מכונית או ז'אנר של ספר. נתונים אלה הם סובייקטיביים, מבוססים על תצפיות ולא על מדידות.
ארבעה מאזני מדידה
- קנה מידה נומינלי: זוהי צורת המדידה הפשוטה ביותר המשמשת לסיווג נתונים ללא סדר מסוים. דוגמאות כוללות סוגי מאכלים, קבוצות דם או לאום. מדובר על תיוג ללא כל ערך כמותי.
- סולם סידורי: ניתן לסדר או לדרג נתונים כאן, אך המרווחים בין הערכים אינם מוגדרים. חשבו על סקר שביעות רצון עם אפשרויות כמו מרוצה, ניטרלי ולא מרוצה. זה אומר לנו את הסדר אבל לא את המרחק בין הדירוגים.
- סולם מרווחים: מרווחים מסדרים נתונים ומכמתים את ההבדל בין ערכים. עם זאת, אין נקודת אפס בפועל. דוגמה טובה היא הטמפרטורה בצלזיוס; ההבדל בין 10°C ל-20°C זהה לזה שבין 20°C ל-30°C, אבל 0°C לא אומר היעדר טמפרטורה.
- סולם יחס: לסולם האינפורמטיבי ביותר יש את כל המאפיינים של סולם מרווחים בתוספת נקודת אפס משמעותית, המאפשרת השוואה מדויקת של גדלים. דוגמאות כוללות משקל, גובה והכנסה. כאן, אנו יכולים לומר שמשהו גדול פי שניים מהאחר.
3. סטטיסטיקה תיאורית
Imagine סטטיסטיקה תיאורית בתור הדייט הראשון שלך עם הנתונים שלך. מדובר בהכרת היסודות, קווים הרחבים שמתארים את מה שעומד מולך. לסטטיסטיקה תיאורית שני סוגים עיקריים: נטייה מרכזית ומדדי שונות.
מדדים של נטייה מרכזית: אלה הם כמו מרכז הכובד של הנתונים. הם נותנים לנו ערך יחיד אופייני או מייצג של מערך הנתונים שלנו.
מתכוון: הממוצע מחושב על ידי חיבור כל הערכים וחלוקה במספר הערכים. זה כמו הדירוג הכולל של מסעדה בהתבסס על כל הביקורות. הנוסחה המתמטית של הממוצע ניתנת להלן:

חֲצִיוֹן: הערך האמצעי כאשר הנתונים מסודרים מהקטן לגדול ביותר. אם מספר התצפיות הוא זוגי, זה הממוצע של שני המספרים האמצעיים. הוא משמש כדי למצוא את נקודת האמצע של גשר.
אם n זוגי, החציון הוא הממוצע של שני המספרים המרכזיים.
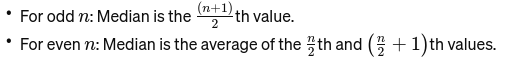
מצב: זה הערך השכיח ביותר במערך נתונים. תחשוב על זה כעל המנה הפופולרית ביותר במסעדה.
מדדי השתנות: בעוד שמדדים של נטייה מרכזית מביאים אותנו למרכז, מדדים של שונות מספרים לנו על ההתפשטות או הפיזור.
טווח: ההבדל בין הערכים הגבוהים והנמוכים ביותר. זה נותן מושג בסיסי על ההתפשטות.
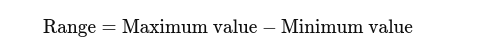
שׁוֹנוּת: מודד כמה רחוק כל מספר בקבוצה מהממוצע ובכך מכל מספר אחר בקבוצה. עבור דוגמה, זה מופיע כך:
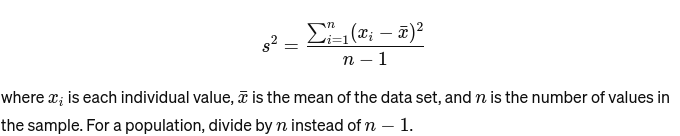
סטיית תקן: השורש הריבועי של השונות מספק מדד למרחק הממוצע מהממוצע. זה כמו להעריך את העקביות של גדלי העוגה של אופה. זה מיוצג כ:
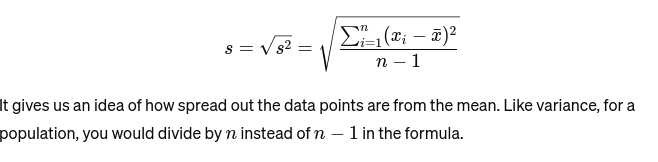
לפני שנעבור למושג הסטטיסטיקה הבסיסי הבא, הנה א מדריך למתחילים לניתוח סטטיסטי בשבילך!
4. ויזואליזציה של נתונים
נתונים להדמיה הוא האמנות והמדע לספר סיפורים עם נתונים. זה הופך תוצאות מורכבות מהניתוח שלנו למשהו מוחשי ומובן. זה חיוני לניתוח נתונים חקרני, כאשר המטרה היא לחשוף דפוסים, מתאמים ותובנות מנתונים מבלי להגיע למסקנות רשמיות.
- תרשימים וגרפים: החל מהיסודות, תרשימי עמודות, תרשימי קווים ותרשימי עוגה מספקים תובנות בסיסיות לגבי הנתונים. הם ה-ABC של הדמיית נתונים, חיוניים לכל מספר נתונים.
יש לנו דוגמה של תרשים עמודות (משמאל) ותרשים קווים (מימין) למטה.
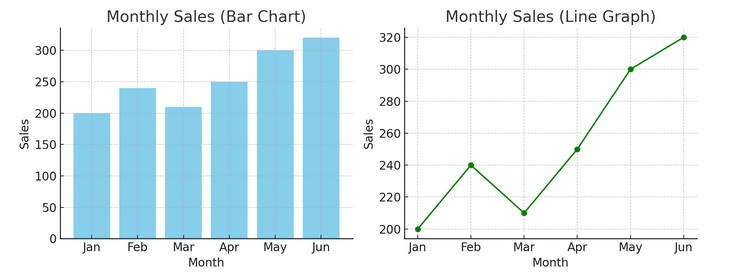
- הדמיות מתקדמות: ככל שאנו צוללים לעומק, מפות חום, עלילות פיזור והיסטוגרמות מאפשרות ניתוח ניואנסים יותר. כלים אלה עוזרים לזהות מגמות, התפלגות וחריגים.
להלן דוגמה של עלילת פיזור והיסטוגרמה

הדמיות מגשרות בין נתונים גולמיים והכרה אנושית, ומאפשרות לנו לפרש ולהבין את מערכי הנתונים המורכבים במהירות.
5. יסודות הסתברות
הסתברות הוא הדקדוק של שפת הסטטיסטיקה. זה לגבי הסיכוי או הסבירות שיתרחשו אירועים. הבנת מושגים בהסתברות חיונית לפירוש תוצאות סטטיסטיות וביצוע תחזיות.
- אירועים עצמאיים ותלויים:
- אירועים עצמאיים: תוצאה של אירוע אחד לא משפיעה על התוצאה של אחר. בדומה להטלת מטבע, להפיל ראשים אחד לא משנה את הסיכויים להעיף הבא.
- אירועים תלויים: התוצאה של אירוע אחד משפיעה על התוצאה של אחר. לדוגמה, אם אתה שולף קלף מחפיסה ולא מחליף אותו, הסיכוי שלך למשוך קלף ספציפי אחר ישתנה.
הסתברות מספקת את הבסיס להסקת מסקנות לגבי נתונים והיא קריטית להבנת מובהקות סטטיסטית ובדיקת השערות.
6. התפלגויות הסתברות נפוצות
התפלגויות הסתברות הם כמו מינים שונים במערכת האקולוגית הסטטיסטית, כל אחד מותאם לנישה של היישומים שלו.
- תפוצה רגילה: מכונה לעתים קרובות עקומת הפעמון בגלל צורתה, התפלגות זו מאופיינת בסטיית התקן והממוצע שלה. זוהי הנחה נפוצה במבחנים סטטיסטיים רבים מכיוון שמשתנים רבים מתחלקים באופן טבעי כך בעולם האמיתי.
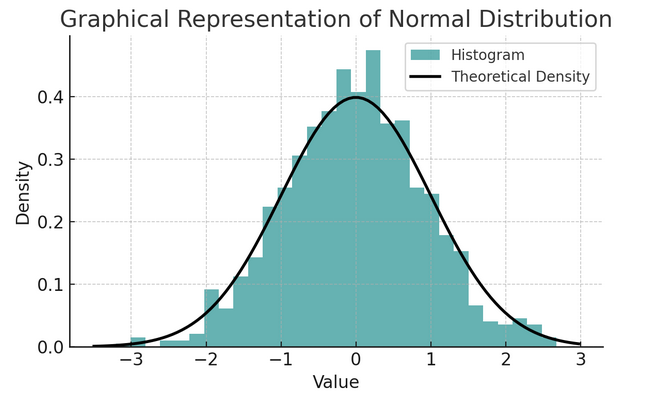
קבוצת כללים המכונה הכלל האמפירי או הכלל 68-95-99.7 מסכמת את המאפיינים של התפלגות נורמלית, המתארת כיצד הנתונים מתפזרים סביב הממוצע.
כלל 68-95-99.7 (כלל אמפירי)
כלל זה חל על התפלגות נורמלית לחלוטין ומתאר את הדברים הבאים:
- 68% מהנתונים נופלים בסטיית תקן אחת (σ) מהממוצע (μ).
- 95% מהנתונים נופלים בתוך שתי סטיות תקן של הממוצע.
- בְּעֵרֶך 99.7% מהנתונים נופלים בתוך שלוש סטיות תקן של הממוצע.
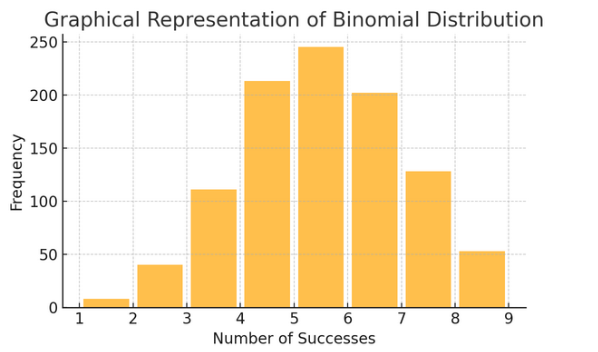
התפלגות הבינומית: התפלגות זו חלה על מצבים עם שתי תוצאות (כמו הצלחה או כישלון) שחוזרות על עצמן מספר פעמים. זה עוזר לדגמן אירועים כמו הטלת מטבע או ביצוע מבחן נכון/שקר.
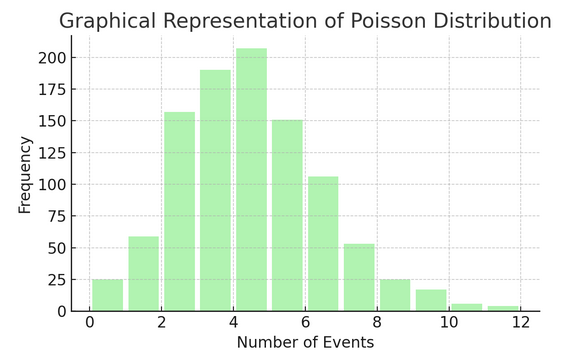
חלוקת דגים סופר את מספר הפעמים שמשהו קורה במרווח או רווח מסוים. זה אידיאלי למצבים שבהם אירועים מתרחשים באופן עצמאי ומתמשך, כמו הודעות האימייל היומיות שאתה מקבל.
לכל הפצה יש קבוצה משלה של נוסחאות ומאפיינים, והבחירה הנכונה תלויה באופי הנתונים שלך ובמה שאתה מנסה לברר. הבנת התפלגויות אלו מאפשרת לסטטיסטיקאים ולמדעני נתונים לדגמן תופעות בעולם האמיתי ולחזות אירועים עתידיים במדויק.
7 . בדיקת השערות
לחשוב על בדיקת השערה כעבודת בילוש בסטטיסטיקה. זו שיטה לבדוק אם תיאוריה מסוימת לגבי הנתונים שלנו יכולה להיות נכונה. תהליך זה מתחיל בשתי השערות מנוגדות:
- השערת אפס (H0): זוהי הנחת ברירת המחדל, המעידה על השפעתו או על ההבדל. זה אומר, "לא" חדש כאן."
- אל "השערה חלופית (H1 או Ha): זה מאתגר את הסטטוס קוו, מציע השפעה או הבדל. הוא טוען, "משהו מעניין קורה".
דוגמה: בדיקה אם תוכנית דיאטה חדשה מובילה לירידה במשקל לעומת אי הקפדה על דיאטה כלשהי.
- השערת אפס (H0): תוכנית הדיאטה החדשה אינה מביאה לירידה במשקל (אין הבדל בירידה במשקל בין מי שעוקב אחר תוכנית הדיאטה החדשה לאלו שלא).
- השערה חלופית (H1): תוכנית הדיאטה החדשה מביאה לירידה במשקל (הבדל בירידה במשקל בין מי שעוקב אחריה לאלו שלא).
בדיקת השערות כוללת בחירה בין שני אלה על סמך העדויות (הנתונים שלנו).
רמות שגיאה ומשמעות מסוג I ו-II:
- שגיאה מסוג I: זה קורה כאשר אנו דוחים בטעות את השערת האפס. זה מרשיע אדם חף מפשע.
- שגיאה מסוג II: זה קורה כאשר איננו מצליחים לדחות השערת אפס שקרית. זה נותן לאדם אשם לצאת לחופשי.
- רמת מובהקות (α): זהו הסף להחלטה כמה ראיות מספיקות כדי לדחות את השערת האפס. לרוב הוא מוגדר ל-5% (0.05), מה שמצביע על סיכון של 5% לשגיאה מסוג I.
8. רווחי סמך
מרווחי אמון תן לנו טווח של ערכים שבתוכם אנו מצפים שפרמטר האוכלוסייה התקף (כמו ממוצע או פרופורציה) ייפול ברמת ביטחון מסוימת (בדרך כלל 95%). זה כמו לחזות את התוצאה הסופית של קבוצת ספורט עם מרווח טעות; אנחנו אומרים, "אנחנו בטוחים ב-95% שהציון האמיתי יהיה בטווח הזה."
בנייה ופירוש של רווחי סמך עוזרים לנו להבין את הדיוק של ההערכות שלנו. ככל שהמרווח רחב יותר, ההערכה שלנו פחות מדויקת, ולהיפך.
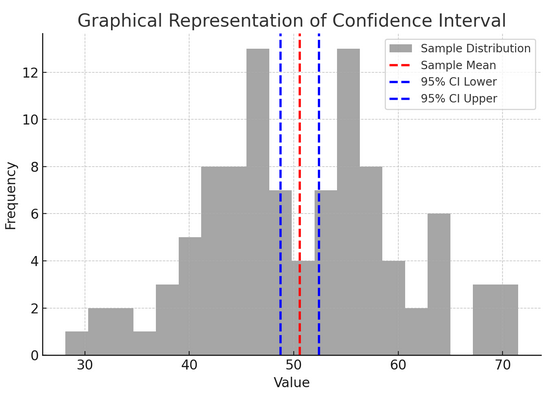
האיור שלמעלה ממחיש את הרעיון של רווח סמך (CI) בסטטיסטיקה, תוך שימוש בהתפלגות מדגם ורווח סמך של 95% שלו סביב ממוצע המדגם.
להלן פירוט של המרכיבים הקריטיים באיור:
- התפלגות לדוגמה (היסטוגרמה אפורה): זה מייצג את ההתפלגות של 100 נקודות נתונים שנוצרות באופן אקראי מהתפלגות נורמלית עם ממוצע של 50 וסטיית תקן של 10. ההיסטוגרמה מתארת באופן ויזואלי כיצד נקודות הנתונים מפוזרות סביב הממוצע.
- ממוצע לדוגמא (קו מקווקו אדום): שורה זו מציינת את הערך הממוצע (הממוצע) של נתוני המדגם. הוא משמש כאומדן נקודתי שסביבה אנו בונים את רווח הסמך. במקרה זה, הוא מייצג את הממוצע של כל ערכי המדגם.
- רווח סמך של 95% (קווים כחולים מקווקוים): שני קווים אלה מסמנים את הגבול התחתון והעליון של רווח הסמך של 95% סביב ממוצע המדגם. המרווח מחושב באמצעות שגיאת התקן של הממוצע (SEM) וציון Z המקביל לרמת הביטחון הרצויה (1.96 עבור 95% ביטחון). רווח הסמך מצביע על כך שאנו בטוחים ב-95% שממוצע האוכלוסייה נמצא בטווח זה.
9. מתאם וסיבתי
מתאם וסיבתי לעתים קרובות מתערבבים, אבל הם שונים:
- מתאם: מציין קשר או קשר בין שני משתנים. כשאחד משתנה, גם השני נוטה להשתנות. מתאם נמדד על ידי מקדם מתאם שנע בין -1 ל-1. ערך קרוב יותר ל-1 או -1 מצביע על קשר חזק, בעוד ש-0 מצביע על שום קשר.
- גְרִימָה: זה מרמז ששינויים במשתנה אחד גורמים ישירות לשינויים במשתנה אחר. זוהי קביעה חזקה יותר מאשר מתאם ודורשת בדיקה קפדנית.
זה ששני משתנים נמצאים בקורלציה לא אומר שאחד גורם לשני. זהו מקרה קלאסי של אי בלבול בין "מתאם" ל"סיבתיות".
10. רגרסיה ליניארית פשוטה
פָּשׁוּט רגרסיה לינארית היא דרך למודל של הקשר בין שני משתנים על ידי התאמת משוואה ליניארית לנתונים שנצפו. משתנה אחד נחשב למשתנה מסביר (בלתי תלוי), והשני הוא משתנה תלוי.
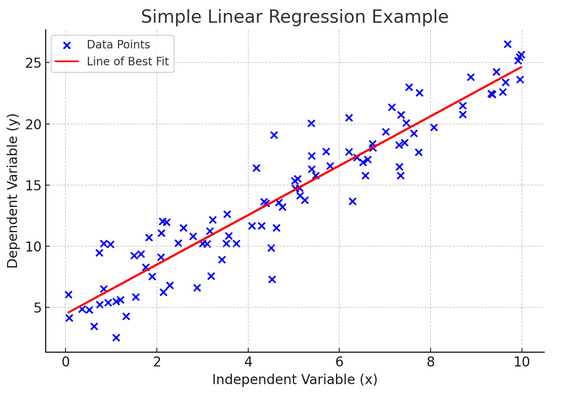
רגרסיה ליניארית פשוטה עוזרת לנו להבין כיצד שינויים במשתנה הבלתי תלוי משפיעים על המשתנה התלוי. זהו כלי רב עוצמה לחיזוי והוא הבסיס להרבה מודלים סטטיסטיים מורכבים אחרים. על ידי ניתוח הקשר בין שני משתנים, נוכל ליצור תחזיות מושכלות לגבי האופן שבו הם יתקשרו.
רגרסיה ליניארית פשוטה מניחה קשר ליניארי בין המשתנה הבלתי תלוי (משתנה מסביר) למשתנה התלוי. אם הקשר בין שני המשתנים הללו אינו ליניארי, אזי ההנחות של רגרסיה ליניארית פשוטה עשויות להיות מופרות, מה שעלול להוביל לתחזיות או פרשנויות לא מדויקות. לפיכך, אימות קשר ליניארי בנתונים חיוני לפני החלת רגרסיה ליניארית פשוטה.
11. רגרסיה לינארית מרובה
חשבו על רגרסיה לינארית מרובה כהרחבה של רגרסיה ליניארית פשוטה. ובכל זאת, במקום לנסות לחזות תוצאה עם אביר אחד בשריון נוצץ (מנבא), יש לך צוות שלם. זה כמו לשדרג ממשחק כדורסל אחד על אחד למאמץ קבוצתי שלם, שבו כל שחקן (מנבא) מביא מיומנויות ייחודיות. הרעיון הוא לראות כיצד מספר משתנים יחד משפיעים על תוצאה אחת.
עם זאת, עם צוות גדול יותר מגיע האתגר של ניהול מערכות יחסים, המכונה מולטי-קולינאריות. זה מתרחש כאשר מנבאים קרובים מדי זה לזה וחולקים מידע דומה. תארו לעצמכם שני שחקני כדורסל מנסים כל הזמן לקחת את אותה זריקה; הם יכולים להפריע זה לזו. רגרסיה עלולה להקשות על התרומה הייחודית של כל מנבא, ועלולה להטות את ההבנה שלנו לגבי המשתנים המשמעותיים.
12. רגרסיה לוגיסטית
בעוד רגרסיה ליניארית מנבאת תוצאות מתמשכות (כמו טמפרטורה או מחירים), - רגרסיה לוגיסטית משמש כאשר התוצאה מוגדרת (כמו כן/לא, ניצחון/הפסד). דמיינו שאתם מנסים לחזות אם קבוצה תנצח או תפסיד על סמך גורמים שונים; רגרסיה לוגיסטית היא האסטרטגיה המומלצת שלך.
הוא הופך את המשוואה הליניארית כך שהפלט שלה נופל בין 0 ל-1, המייצג את ההסתברות להשתייך לקטגוריה מסוימת. זה כמו שיש עדשת קסם שממירה ציונים רציפים לתצוגה ברורה של "זה או זה", המאפשרת לנו לחזות תוצאות קטגוריות.
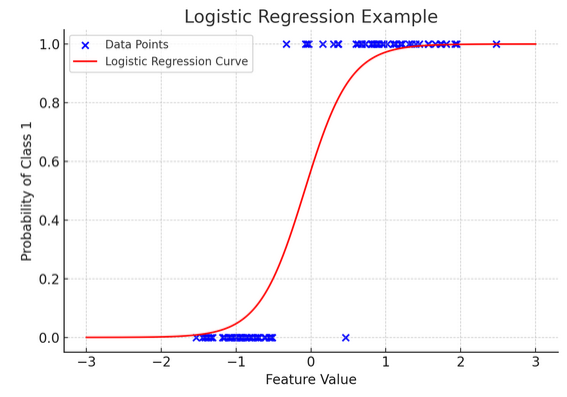
הייצוג הגרפי ממחיש דוגמה של רגרסיה לוגיסטית המיושמת על מערך סיווג בינארי סינתטי. הנקודות הכחולות מייצגות את נקודות הנתונים, כאשר מיקומן לאורך ציר ה-x מציין את ערך התכונה וציר ה-y מציין את הקטגוריה (0 או 1). העקומה האדומה מייצגת את חיזוי מודל הרגרסיה הלוגיסטית לגבי ההסתברות להשתייך למחלקה 1 (למשל, "לנצח") עבור ערכי תכונה שונים. כפי שניתן לראות, העקומה עוברת בצורה חלקה מההסתברות של מחלקה 0 למחלקה 1, מה שמדגים את יכולתו של המודל לחזות תוצאות קטגוריות על סמך תכונה רציפה בסיסית.
הנוסחה לרגרסיה לוגיסטית ניתנת על ידי:

נוסחה זו משתמשת בפונקציה הלוגיסטית כדי להפוך את הפלט של המשוואה הליניארית להסתברות בין 0 ל-1. טרנספורמציה זו מאפשרת לנו לפרש את התפוקות כהסתברויות להשתייכות לקטגוריה מסוימת על סמך הערך של המשתנה הבלתי תלוי xx.
13. מבחני ANOVA וצ'י ריבוע
ANOVA (ניתוח שונות) ו בדיקות צ'י מרובע הם כמו בלשים בעולם הסטטיסטיקה, ועוזרים לנו לפתור תעלומות שונות. אניt מאפשר לנו להשוות אמצעים על פני מספר קבוצות כדי לראות אם לפחות אחת שונה סטטיסטית. תחשוב על זה כדוגמת טעימה מכמה קבוצות של עוגיות כדי לקבוע אם אצווה כלשהי טעימה שונה באופן משמעותי.
מצד שני, מבחן Chi-Square משמש לנתונים קטגוריים. זה עוזר לנו להבין אם יש קשר משמעותי בין שני משתנים קטגוריים. למשל, האם יש קשר בין ז'אנר המוזיקה האהוב על אדם לבין קבוצת הגיל שלו? מבחן הצ'י ריבוע עוזר לענות על שאלות כאלה.
14. משפט הגבול המרכזי וחשיבותו במדעי הנתונים
אל האני משפט הגבול המרכזי (CLT) הוא עיקרון סטטיסטי בסיסי שמרגיש כמעט קסום. זה אומר לנו שאם לוקחים מספיק דגימות מאוכלוסיה ומחשבים את הממוצע שלהן, האמצעים האלה יהוו התפלגות נורמלית (עקומת הפעמון), ללא קשר להתפלגות המקורית של האוכלוסייה. זה חזק להפליא מכיוון שהוא מאפשר לנו להסיק מסקנות לגבי אוכלוסיות גם כשאיננו יודעים את התפוצה המדויקת שלהן.
במדעי הנתונים, ה-CLT עומד בבסיס טכניקות רבות, המאפשרות לנו להשתמש בכלים המיועדים לנתונים מבוזרים נורמליים גם כאשר הנתונים שלנו אינם עומדים בקריטריונים אלה בתחילה. זה כמו למצוא מתאם אוניברסלי לשיטות סטטיסטיות, מה שהופך כלים רבי עוצמה לישימים בעוד מצבים.
15. שיוויון הטיה-שונות
In דוגמנות ניבוי ו למידת מכונה, ה פשרה בין הטיה לשונות הוא מושג מכריע שמדגיש את המתח בין שני סוגי שגיאות עיקריים שיכולים לגרום לדגמים שלנו להשתבש. הטיה מתייחסת לשגיאות ממודלים פשטניים מדי שאינם תופסים היטב את המגמות הבסיסיות. תאר לעצמך שאתה מנסה להתאים קו ישר דרך כביש מעוקל; אתה תפספס את המטרה. לעומת זאת, שינויים מדגמים מורכבים מדי לוכדים רעש בנתונים כאילו הם דפוס ממשי - כמו מעקב אחר כל פיתול ופנייה על שביל מהמורות, לחשוב שזה הדרך קדימה.
האומנות טמונה באיזון בין שני אלה כדי למזער את השגיאה הכוללת, למצוא את הנקודה המתוקה שבה הדגם שלך בדיוק מתאים - מורכב מספיק כדי ללכוד את הדפוסים המדויקים אבל פשוט מספיק כדי להתעלם מהרעש האקראי. זה כמו לכוון גיטרה; זה לא יישמע נכון אם הוא צמוד מדי או רופף. הפער בין הטיה לשונות עוסק במציאת האיזון המושלם בין שני אלה. הפשרה בין הטיה לשונות היא המהות של כוונון המודלים הסטטיסטיים שלנו לביצוע המיטב שלהם בחיזוי תוצאות במדויק.
סיכום
מדגימה סטטיסטית ועד לשינוי ההטיה-שונות, עקרונות אלה אינם רק מושגים אקדמיים אלא כלים חיוניים לניתוח נתונים בעל תובנות. הם מציידים מדעני נתונים שואפים במיומנויות להפוך נתונים עצומים לתובנות ניתנות לפעולה, תוך שימת דגש על סטטיסטיקה כעמוד השדרה של קבלת החלטות מונעות נתונים וחדשנות בעידן הדיגיטלי.
האם פספסנו מושג סטטיסטי בסיסי כלשהו? ספר לנו בקטע התגובות למטה.
סייר שלנו מדריך סטטיסטיקה מקצה לקצה למדעי הנתונים לדעת על הנושא!
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

