בפוסט זה, אנו דנים כיצד יונייטד איירליינס, בשיתוף עם מעבדת פתרונות למידת מכונות של אמזון, בנה מסגרת למידה פעילה ב-AWS כדי להפוך את העיבוד של מסמכי נוסעים לאוטומטיים.
"על מנת לספק את חווית הטיסה הטובה ביותר לנוסעים שלנו ולהפוך את התהליך העסקי הפנימי שלנו ליעיל ככל האפשר, פיתחנו צינור עיבוד מסמכים מבוסס למידת מכונה אוטומטית ב-AWS. על מנת להפעיל את היישומים הללו, כמו גם את אלה המשתמשים באופני נתונים אחרים כמו ראייה ממוחשבת, אנו זקוקים לזרימת עבודה חזקה ויעילה כדי להוסיף הערות לנתונים במהירות, לאמן ולהעריך מודלים ולחזור במהירות. במהלך הקורס של כמה חודשים, יונייטד שיתפה פעולה עם מעבדות הפתרונות ללמידה מכונה של אמזון כדי לעצב ולפתח זרימת עבודה פעילה של למידה אקטיבית לשימוש חוזרת לשימוש חוזר באמצעות AWS CDK. זרימת עבודה זו תהיה הבסיסית ליישומי למידת מכונה לא מובנים מבוססי נתונים שלנו, שכן היא תאפשר לנו למזער את מאמץ התיוג האנושי, לספק ביצועי מודל חזקים במהירות ולהסתגל לסחף נתונים."
– ג'ון נלסון, מנהל בכיר של מדעי הנתונים ולמידת מכונה בחברת יונייטד איירליינס.
בעיה
צוות הטכנולוגיה הדיגיטלית של יונייטד מורכב מאנשים מגוונים ברחבי העולם העובדים יחד עם טכנולוגיה מתקדמת כדי להניע תוצאות עסקיות ולשמור על רמות שביעות רצון גבוהות של לקוחות. הם רצו לנצל את הטכניקות של למידת מכונה (ML) כגון ראייה ממוחשבת (CV) ועיבוד שפה טבעית (NLP) כדי להפוך את צינורות עיבוד המסמכים לאוטומטיים. כחלק מאסטרטגיה זו, הם פיתחו מודל ניתוח דרכונים פנימי לאימות מזהי נוסעים. התהליך מסתמך על הערות ידניות לאימון מודלים של ML, שהם יקרים מאוד.
יונייטד רצתה ליצור מסגרת ML גמישה, גמישה וחסכונית לאוטומציה של אימות פרטי דרכון, אימות זהות הנוסע וזיהוי מסמכי הונאה אפשריים. הם העסיקו את מעבדת ML Solutions כדי לסייע בהשגת מטרה זו, המאפשרת ליונייטד להמשיך לספק שירות ברמה עולמית מול גידול נוסעים עתידי.
סקירת פתרונות
הצוות המשותף שלנו עיצב ופיתח מסגרת למידה פעילה המופעלת על ידי ערכת פיתוח ענן AWS (AWS CDK), אשר מגדירה ומספקת באופן פרוגרמטי את כל שירותי ה-AWS הדרושים. המסגרת משתמשת אמזון SageMaker לעיבוד נתונים ללא תווית, יוצר תוויות רכות, משיק עבודות תיוג ידניות איתן האמת של אמזון SageMaker, ומאמן מודל ML שרירותי עם מערך הנתונים המתקבל. השתמשנו טקסטורה באמזון לאוטומטי של חילוץ מידע משדות מסמכים ספציפיים כגון שם ומספר דרכון. ברמה גבוהה, ניתן לתאר את הגישה באמצעות התרשים הבא.
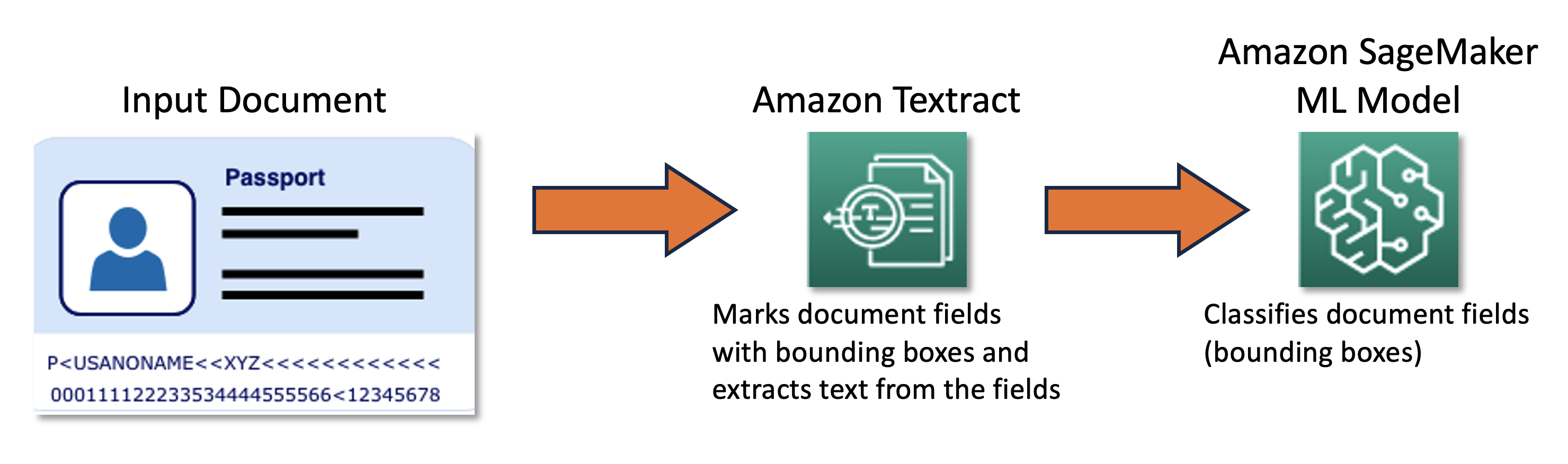
נתונים
מערך הנתונים העיקרי לבעיה זו מורכב מעשרות אלפי תמונות דרכון בעמוד הראשי שמהן יש לחלץ מידע אישי (שם, תאריך לידה, מספר דרכון וכן הלאה). גודל התמונה, הפריסה והמבנה משתנים בהתאם לארץ הנפקת המסמך. אנו מנרמלים את התמונות הללו לסט של תמונות ממוזערות אחידות, המהוות את הקלט הפונקציונלי עבור צינור הלמידה הפעיל (תיוג אוטומטי והסקת הסקה).
מערך הנתונים השני מכיל קובצי מניפסט בפורמט קו JSON המתייחסים לתמונות דרכון גולמיות, תמונות ממוזערות ומידע על תוויות כגון תוויות רכות ומיקומי תיבה תוחמת. קובצי מניפסט משמשים כסט מטא נתונים המאחסן תוצאות משירותי AWS שונים בפורמט מאוחד, ומנתקים את צינור הלמידה הפעילה משירותי ההמשך המשמשים את United. התרשים הבא ממחיש ארכיטקטורה זו.
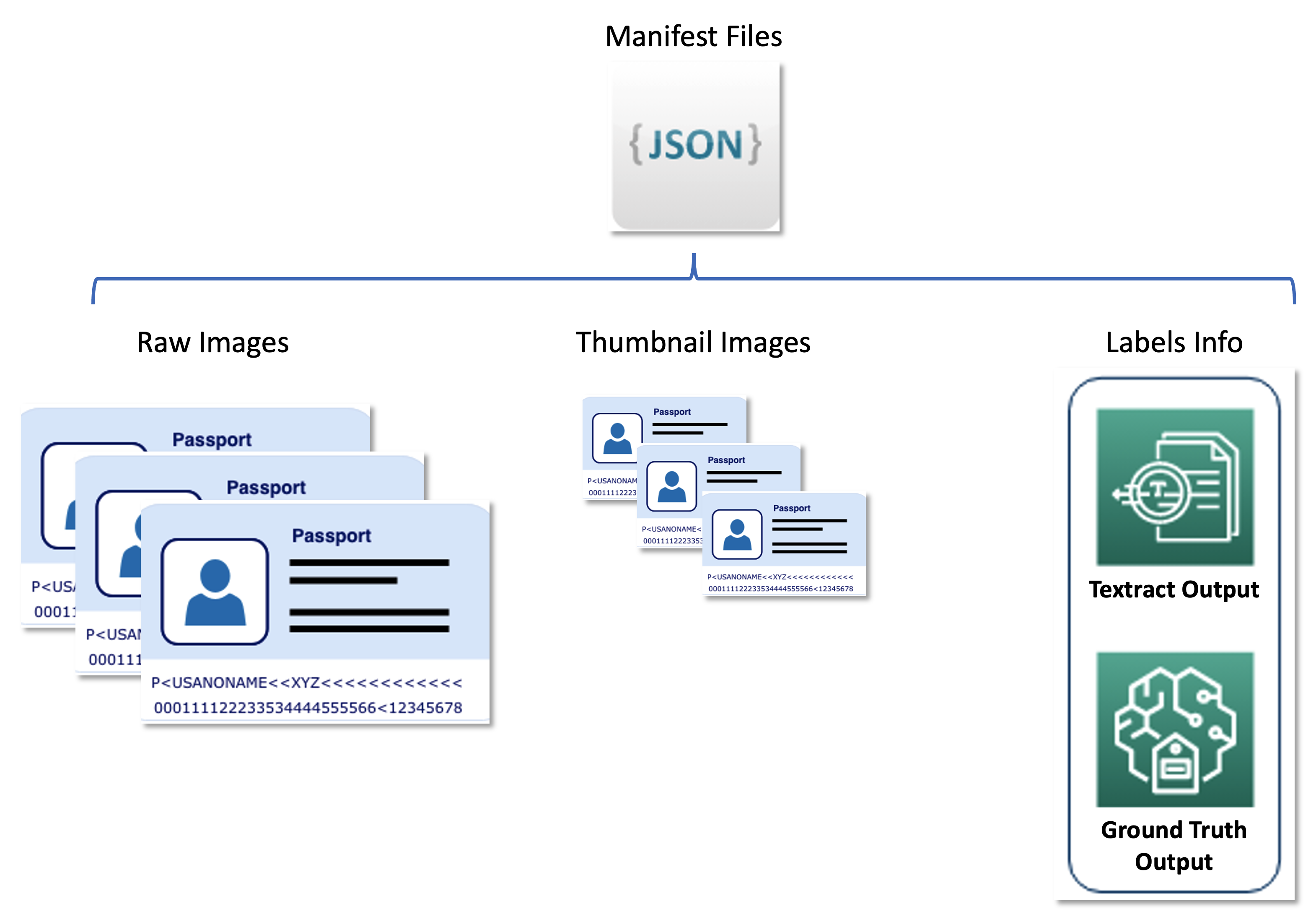
הקוד הבא הוא קובץ מניפסט לדוגמה:
רכיבי פתרון
הפתרון כולל שני מרכיבים עיקריים:
- מסגרת ML, שאחראית על הכשרת המודל
- צינור תיוג אוטומטי, שאחראי על שיפור דיוק המודל המיומן בצורה חסכונית
מסגרת ה-ML אחראית להכשרת מודל ה-ML ופריסה שלו כנקודת קצה של SageMaker. צינור התיוג האוטומטי מתמקד באוטומציה של עבודות SageMaker Ground Truth ודגימת תמונות לתיוג באמצעות עבודות אלו.
שני הרכיבים מנותקים זה מזה ומקיימים אינטראקציה רק דרך קבוצת התמונות המסומנות המיוצרות על ידי צינור התיוג האוטומטי. כלומר, צינור התיוג יוצר תוויות המשמשות מאוחר יותר את מסגרת ה-ML כדי להכשיר את מודל ה-ML.
מסגרת ML
צוות ML Solutions Lab בנה את מסגרת ה-ML תוך שימוש ביישום Hugging Face של מודל LayoutLMV2 המתקדם (LayoutLMv2: אימון מקדים רב-מודאלי להבנת מסמכים עשירים מבחינה ויזואלית, Yang Xu, et al.). ההדרכה התבססה על פלטי Amazon Textract, אשר שימשו כמעבד קדם והפיק תיבות תוחמות סביב טקסט של עניין. המסגרת משתמשת באימון מבוזר ופועלת על קונטיינר Docker מותאם אישית המבוסס על תמונת Hugging Face שנבנתה מראש SageMaker עם תלות נוספת (תלות שחסרות בתמונת SageMaker Docker הבנויה מראש אך נדרשות עבור Hugging Face LayoutLMv2).
מודל ה-ML הוכשר לסיווג שדות מסמכים ב-11 המחלקות הבאות:
ניתן לסכם את צינור ההדרכה בתרשים הבא.
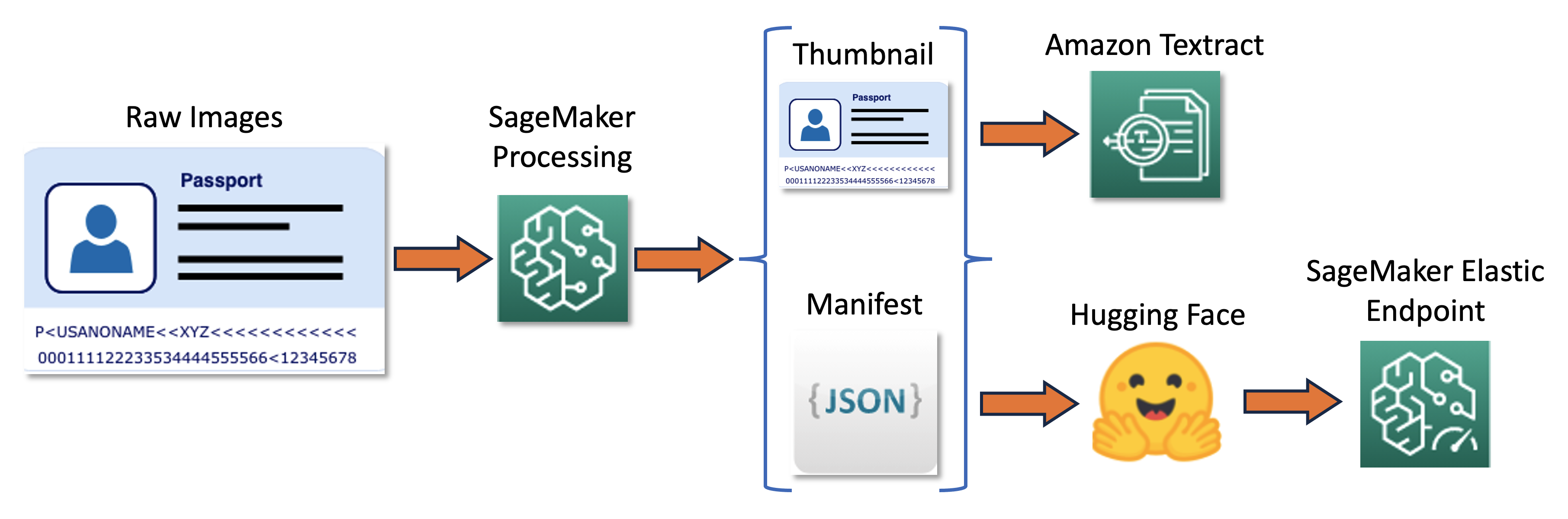
ראשית, אנו משנים גודל ומנרמלים אצווה של תמונות גולמיות לתמונות ממוזערות. במקביל, נוצר קובץ מניפסט קו JSON עם שורה אחת לתמונה עם מידע על תמונות גולמיות ותמונות ממוזערות מהאצווה. לאחר מכן, אנו משתמשים ב- Amazon Textract כדי לחלץ תיבות תוחמות טקסט בתמונות הממוזערות. כל המידע המיוצר על ידי Amazon Textract מתועד באותו קובץ מניפסט. לבסוף, אנו משתמשים בתמונות הממוזערות ובנתוני המניפסט כדי לאמן מודל, שנפרס מאוחר יותר כנקודת קצה של SageMaker.
צינור תיוג אוטומטי
פיתחנו צינור תיוג אוטומטי שנועד לבצע את הפונקציות הבאות:
- הפעל הסקת אצווה תקופתית על מערך נתונים ללא תווית.
- סנן תוצאות על סמך אסטרטגיית דגימת אי ודאות ספציפית.
- הפעל משימת SageMaker Ground Truth כדי לתייג את התמונות שנדגמו באמצעות כוח עבודה אנושי.
- הוסף תמונות שסומנו לאחרונה למערך ההדרכה לצורך חידוד המודלים הבאים.
אסטרטגיית דגימת אי הוודאות מפחיתה את מספר התמונות הנשלחות לעבודת התיוג האנושי על ידי בחירת תמונות שכנראה יתרמו הכי הרבה לשיפור דיוק המודל. מכיוון שתיוג אנושי הוא משימה יקרה, דגימה כזו היא טכניקה חשובה להפחתת עלויות. אנו תומכים בארבע אסטרטגיות דגימה, שניתן לבחור כפרמטר המאוחסן ב חנות פרמטרים, יכולת של מנהל מערכות AWS:
- הכי פחות ביטחון
- אמון בשוליים
- יחס אמון
- אנטרופיה
כל זרימת העבודה של תיוג אוטומטי יושמה עם פונקציות שלב AWS, שמתזמר את עבודת העיבוד (המכונה נקודת הקצה האלסטית להסקת אצווה), דגימת אי ודאות ו- SageMaker Ground Truth. התרשים הבא ממחיש את זרימת העבודה של Step Functions.
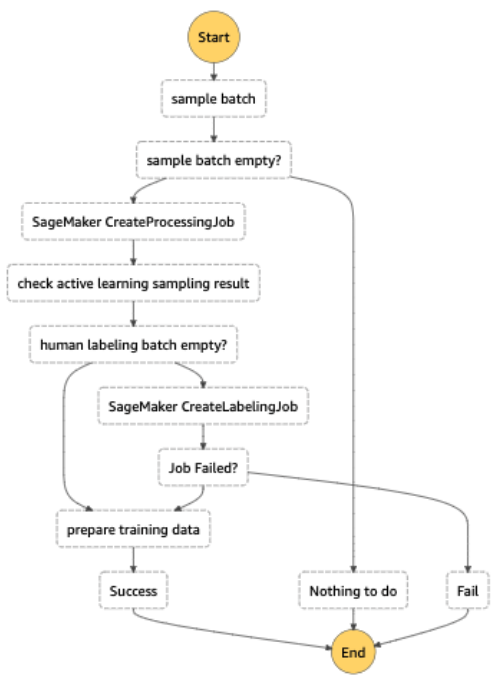
יעילות מחיר
הגורם העיקרי המשפיע על עלויות התיוג הוא הערה ידנית. לפני פריסת הפתרון הזה, הצוות של United היה צריך להשתמש בגישה מבוססת כללים, שדרשה הערות נתונים ידניות יקרות וטכניקות OCR לניתוח של צד שלישי. עם הפתרון שלנו, United צמצמה את עומס העבודה של תיוג ידני על ידי תיוג ידני רק של תמונות שיביאו לשיפורי הדגם הגדולים ביותר. מכיוון שהמסגרת היא מודל-אגנוסטית, ניתן להשתמש בה בתרחישים דומים אחרים, ולהרחיב את ערכה מעבר לתמונות דרכון למערך רחב הרבה יותר של מסמכים.
ביצענו ניתוח עלויות על סמך ההנחות הבאות:
- כל אצווה מכילה 1,000 תמונות
- האימון מתבצע באמצעות מופע mlg4dn.16xlarge
- הסקה מבוצעת על מופע mlg4dn.xlarge
- ההדרכה מתבצעת לאחר כל אצווה עם 10% של תוויות מוערות
- כל סבב אימון מביא לשיפורי הדיוק הבאים:
- 50% לאחר המנה הראשונה
- 25% לאחר המנה השנייה
- 10% לאחר המנה השלישית
הניתוח שלנו מראה שעלות ההכשרה נשארת קבועה וגבוהה ללא למידה אקטיבית. שילוב למידה אקטיבית מביא לירידה אקספוננציאלית בעלויות עם כל אצווה חדשה של נתונים.
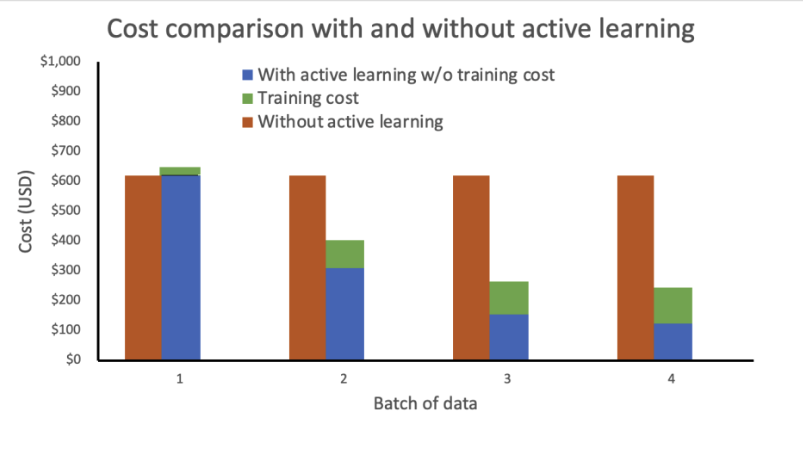
הפחתנו עוד יותר את העלויות על ידי פריסת נקודת הסיום כנקודת קצה אלסטית על ידי הוספת מדיניות קנה מידה אוטומטי. משאבי נקודת הקצה יכולים להגדיל או להקטין בין אפס למספר מרבי מוגדר של מופעים.
ארכיטקטורת פתרון סופי
המיקוד שלנו היה לעזור לצוות United לעמוד בדרישות הפונקציונליות שלהם תוך בניית אפליקציית ענן ניתנת להרחבה וגמישה. צוות ML Solutions Lab פיתח את הפתרון המלא המוכן לייצור בעזרת AWS CDK, אוטומציה של ניהול ואספקה של כל משאבי הענן והשירותים. אפליקציית הענן הסופית נפרסה כיחידה AWS CloudFormation מחסנית עם ארבע ערימות מקוננות, כל אחת מייצגת רכיב פונקציונלי יחיד.
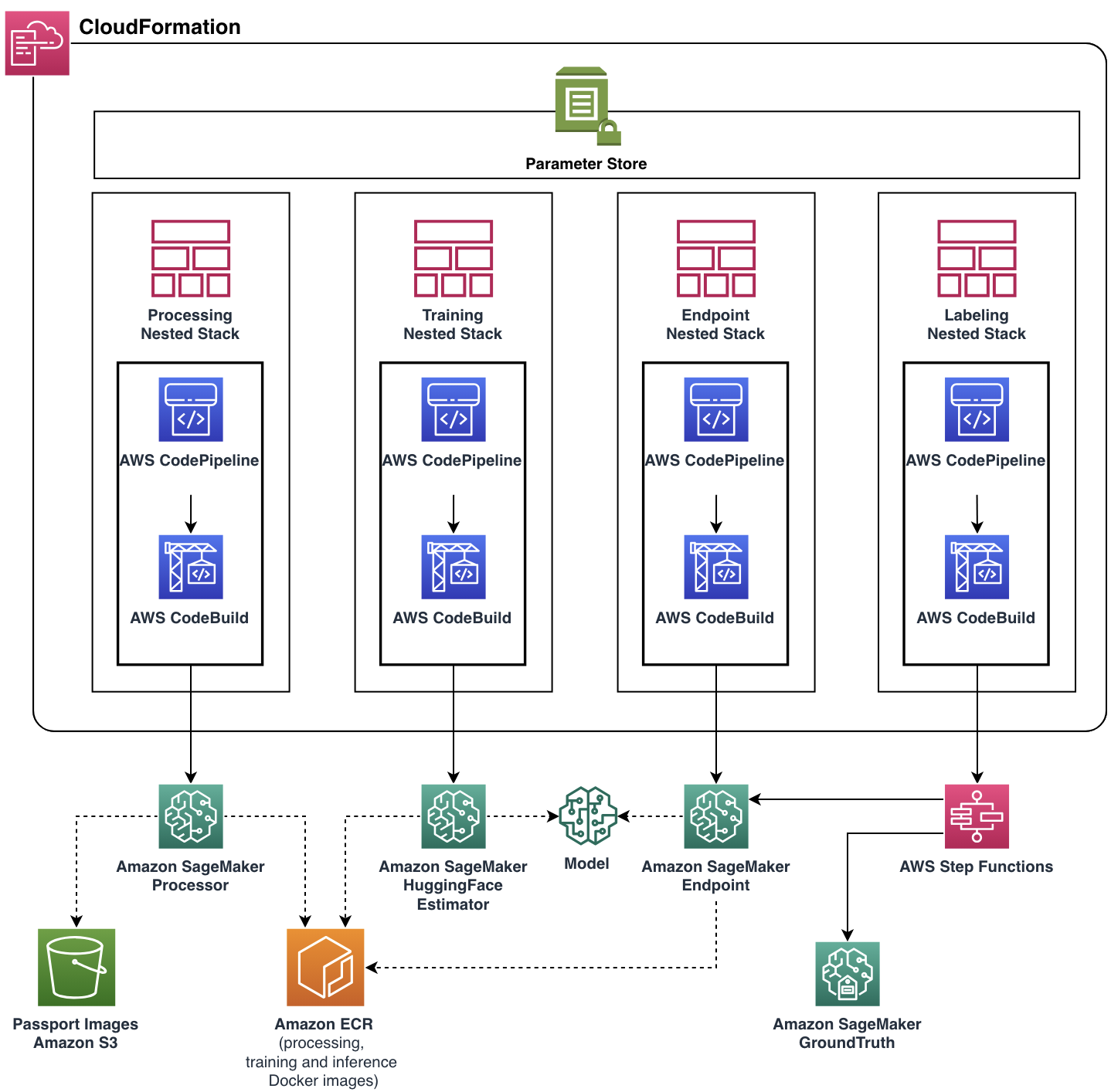
כמעט כל תכונת צינור, כולל תמונות Docker, מדיניות קנה מידה אוטומטי של נקודות קצה ועוד, עברה פרמטרים דרך Parameter Store. עם גמישות כזו, ניתן להפעיל את אותו מופע צינור עם מגוון רחב של הגדרות, ולהוסיף את היכולת להתנסות.
סיכום
בפוסט זה, דנו כיצד יונייטד איירליינס, בשיתוף עם מעבדת הפתרונות של ML, בנתה מסגרת למידה פעילה ב-AWS כדי להפוך את העיבוד של מסמכי נוסעים לאוטומטיים. לפתרון הייתה השפעה רבה על שני היבטים חשובים של יעדי האוטומציה של יונייטד:
- שימוש חוזר - בשל העיצוב המודולרי והיישום האגנוסטי של המודל, יונייטד איירליינס יכולה לעשות שימוש חוזר בפתרון זה כמעט בכל מקרה שימוש אחר ב-ML לתיוג אוטומטי
- הפחתת עלויות חוזרת - על ידי שילוב מושכל של תהליכי תיוג ידניים ואוטומטיים, צוות יונייטד יכול להפחית את עלויות התיוג הממוצעות ולהחליף שירותי תיוג יקרים של צד שלישי
אם אתה מעוניין ליישם פתרון דומה או רוצה ללמוד עוד על מעבדת פתרונות ML, צור קשר עם מנהל החשבון שלך או בקר אותנו בכתובת מעבדת פתרונות למידת מכונות של אמזון.
על הכותבים
 שין גו הוא מדען הנתונים המוביל - למידת מכונה בחטיבת הניתוח והחדשנות המתקדמים של יונייטד איירליינס. היא תרמה באופן משמעותי לתכנון אוטומציה של הבנת מסמכים בעזרת לימוד מכונה ומילאה תפקיד מפתח בהרחבת זרימות עבודה פעילות של למידה פעילה של הערות נתונים על פני משימות ומודלים מגוונים. המומחיות שלה טמונה בהעלאת יעילות ויעילות בינה מלאכותית, בהשגת התקדמות יוצאת דופן בתחום ההתקדמות הטכנולוגית החכמה בחברת יונייטד איירליינס.
שין גו הוא מדען הנתונים המוביל - למידת מכונה בחטיבת הניתוח והחדשנות המתקדמים של יונייטד איירליינס. היא תרמה באופן משמעותי לתכנון אוטומציה של הבנת מסמכים בעזרת לימוד מכונה ומילאה תפקיד מפתח בהרחבת זרימות עבודה פעילות של למידה פעילה של הערות נתונים על פני משימות ומודלים מגוונים. המומחיות שלה טמונה בהעלאת יעילות ויעילות בינה מלאכותית, בהשגת התקדמות יוצאת דופן בתחום ההתקדמות הטכנולוגית החכמה בחברת יונייטד איירליינס.
 ג'ון נלסון הוא המנהל הבכיר של מדעי הנתונים ולמידת מכונה בחברת יונייטד איירליינס.
ג'ון נלסון הוא המנהל הבכיר של מדעי הנתונים ולמידת מכונה בחברת יונייטד איירליינס.
 אלכס גוראיינוב הוא מהנדס למידת מכונה באמזון AWS. הוא בונה ארכיטקטורה ומיישם רכיבי ליבה של למידה אקטיבית וצינור תיוג אוטומטי המופעל על ידי AWS CDK. אלכס הוא מומחה ב-MLOps, ארכיטקטורת מחשוב ענן, ניתוח נתונים סטטיסטי ועיבוד נתונים בקנה מידה גדול.
אלכס גוראיינוב הוא מהנדס למידת מכונה באמזון AWS. הוא בונה ארכיטקטורה ומיישם רכיבי ליבה של למידה אקטיבית וצינור תיוג אוטומטי המופעל על ידי AWS CDK. אלכס הוא מומחה ב-MLOps, ארכיטקטורת מחשוב ענן, ניתוח נתונים סטטיסטי ועיבוד נתונים בקנה מידה גדול.
 וישאל דאס הוא מדען יישומי במעבדת פתרונות ML של אמזון. לפני MLSL, וישאל היה אדריכל פתרונות, אנרגיה, AWS. הוא קיבל את הדוקטורט שלו בגיאופיזיקה עם דוקטורט קטן בסטטיסטיקה מאוניברסיטת סטנפורד. הוא מחויב לעבוד עם לקוחות כדי לעזור להם לחשוב בגדול ולספק תוצאות עסקיות. הוא מומחה בלמידת מכונה ויישומה בפתרון בעיות עסקיות.
וישאל דאס הוא מדען יישומי במעבדת פתרונות ML של אמזון. לפני MLSL, וישאל היה אדריכל פתרונות, אנרגיה, AWS. הוא קיבל את הדוקטורט שלו בגיאופיזיקה עם דוקטורט קטן בסטטיסטיקה מאוניברסיטת סטנפורד. הוא מחויב לעבוד עם לקוחות כדי לעזור להם לחשוב בגדול ולספק תוצאות עסקיות. הוא מומחה בלמידת מכונה ויישומה בפתרון בעיות עסקיות.
 טיאני מאו הוא מדען יישומי ב-AWS הממוקם מאזור שיקגו. יש לו 5+ שנות ניסיון בבניית פתרונות למידת מכונה ולמידה עמוקה והוא מתמקד בראייה ממוחשבת ולמידת חיזוק עם משוב אנושי. הוא נהנה לעבוד עם לקוחות כדי להבין את האתגרים שלהם ולפתור אותם על ידי יצירת פתרונות חדשניים באמצעות שירותי AWS.
טיאני מאו הוא מדען יישומי ב-AWS הממוקם מאזור שיקגו. יש לו 5+ שנות ניסיון בבניית פתרונות למידת מכונה ולמידה עמוקה והוא מתמקד בראייה ממוחשבת ולמידת חיזוק עם משוב אנושי. הוא נהנה לעבוד עם לקוחות כדי להבין את האתגרים שלהם ולפתור אותם על ידי יצירת פתרונות חדשניים באמצעות שירותי AWS.
 יונזשי שי הוא מדען יישומי במעבדת פתרונות ML של אמזון, שם הוא עובד עם לקוחות בתחומים שונים בתעשייה כדי לעזור להם לתכנן, לפתח ולפרוס פתרונות AI/ML הבנויים על שירותי ענן AWS כדי לפתור את האתגרים העסקיים שלהם. הוא עבד עם לקוחות בתחום הרכב, הגיאו-מרחבי, התחבורה והייצור. Yunzhi השיג את הדוקטורט שלו. בגיאופיזיקה מאוניברסיטת טקסס באוסטין.
יונזשי שי הוא מדען יישומי במעבדת פתרונות ML של אמזון, שם הוא עובד עם לקוחות בתחומים שונים בתעשייה כדי לעזור להם לתכנן, לפתח ולפרוס פתרונות AI/ML הבנויים על שירותי ענן AWS כדי לפתור את האתגרים העסקיים שלהם. הוא עבד עם לקוחות בתחום הרכב, הגיאו-מרחבי, התחבורה והייצור. Yunzhi השיג את הדוקטורט שלו. בגיאופיזיקה מאוניברסיטת טקסס באוסטין.
 דייגו סוקולינסקי הוא מנהל מדע יישומי בכיר במרכז החדשנות של AWS Generative AI, שם הוא מוביל את צוות האספקה של אזורי מזרח ארה"ב ואמריקה הלטינית. יש לו למעלה מעשרים שנות ניסיון בלמידת מכונה וראייה ממוחשבת, ובעל תואר דוקטור במתמטיקה מאוניברסיטת ג'ונס הופקינס.
דייגו סוקולינסקי הוא מנהל מדע יישומי בכיר במרכז החדשנות של AWS Generative AI, שם הוא מוביל את צוות האספקה של אזורי מזרח ארה"ב ואמריקה הלטינית. יש לו למעלה מעשרים שנות ניסיון בלמידת מכונה וראייה ממוחשבת, ובעל תואר דוקטור במתמטיקה מאוניברסיטת ג'ונס הופקינס.
 שין חן הוא כיום ראש מעבדת פתרונות מדעי האנשים ב-Amazon People eXperience Technology (PXT, aka HR) Central Science. הוא מוביל צוות של מדענים יישומיים לבניית פתרונות מדעיים בדרגת ייצור כדי לזהות ולהשיק מנגנונים ושיפורי תהליכים באופן יזום. בעבר הוא היה ראש מרכז ארה"ב, אזור סין רבתי, LATAM ו-Automotive Vertical במעבדת פתרונות למידת מכונה של AWS. הוא עזר ללקוחות AWS לזהות ולבנות פתרונות למידת מכונה כדי לתת מענה להזדמנויות למידת המכונה הגבוהה ביותר של הארגון שלהם עם ההחזר על ההשקעה. שין הוא סגל נלווה באוניברסיטת נורת'ווסטרן ובמכון הטכנולוגי של אילינוי. הוא השיג את הדוקטורט שלו במדעי המחשב והנדסה באוניברסיטת נוטרדאם.
שין חן הוא כיום ראש מעבדת פתרונות מדעי האנשים ב-Amazon People eXperience Technology (PXT, aka HR) Central Science. הוא מוביל צוות של מדענים יישומיים לבניית פתרונות מדעיים בדרגת ייצור כדי לזהות ולהשיק מנגנונים ושיפורי תהליכים באופן יזום. בעבר הוא היה ראש מרכז ארה"ב, אזור סין רבתי, LATAM ו-Automotive Vertical במעבדת פתרונות למידת מכונה של AWS. הוא עזר ללקוחות AWS לזהות ולבנות פתרונות למידת מכונה כדי לתת מענה להזדמנויות למידת המכונה הגבוהה ביותר של הארגון שלהם עם ההחזר על ההשקעה. שין הוא סגל נלווה באוניברסיטת נורת'ווסטרן ובמכון הטכנולוגי של אילינוי. הוא השיג את הדוקטורט שלו במדעי המחשב והנדסה באוניברסיטת נוטרדאם.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/how-united-airlines-built-a-cost-efficient-optical-character-recognition-active-learning-pipeline/

