חלה התקדמות אדירה בתחום למידה עמוקה מבוזרת עבור מודלים של שפות גדולות (LLMs), במיוחד לאחר שחרורו של ChatGPT בדצמבר 2022. LLMs ממשיכים לגדול בגודלם עם מיליארדי או אפילו טריליונים של פרמטרים, ולעתים קרובות הם לא יצליחו. להתאים להתקן מאיץ יחיד כגון GPU או אפילו צומת בודד כגון ml.p5.32xlarge בגלל מגבלות זיכרון. לקוחות המאמנים LLMs חייבים לעתים קרובות לחלק את עומס העבודה שלהם על פני מאות או אפילו אלפי GPUs. מתן הדרכה בקנה מידה כזה נותר אתגר בהכשרה מבוזרת, והדרכה יעילה במערכת כה גדולה היא עוד בעיה חשובה לא פחות. במהלך השנים האחרונות, קהילת ההכשרה המבוזרת הציגה מקביליות תלת-ממדית (מקביליות נתונים, מקביליות צנרת ומקביליות טנזור) וטכניקות אחרות (כגון מקביליות רצפים ומקביליות מומחים) כדי להתמודד עם אתגרים כאלה.
בדצמבר 2023, אמזון הודיעה על שחרור ה- ספריית מקבילית דגם SageMaker 2.0 (SMP), המשיגה יעילות חדישה באימון דגמים גדולים, יחד עם SageMaker הפיצה ספריית מקביליות נתונים (SMDDP). מהדורה זו היא עדכון משמעותי מ-1.x: SMP משולב כעת עם PyTorch בקוד פתוח נתונים מפוצלים לחלוטין במקביל (FSDP) APIs, המאפשרים לך להשתמש בממשק מוכר בעת אימון דגמים גדולים, ותואם עם מנוע שנאי (TE), פותחת טכניקות מקביליות טנזור לצד FSDP בפעם הראשונה. למידע נוסף על המהדורה, עיין ב ספרייה מקבילית מדגם SageMaker של אמזון מאיצה כעת את עומסי העבודה של PyTorch FSDP בעד 20%.
בפוסט זה, אנו בוחנים את יתרונות הביצועים של אמזון SageMaker (כולל SMP ו- SMDDP), וכיצד ניתן להשתמש בספרייה כדי לאמן דגמים גדולים ביעילות ב- SageMaker. אנו מדגימים את הביצועים של SageMaker עם אמות מידה על אשכולות ml.p4d.24xlarge עד 128 מופעים, ודיוק מעורב FSDP עם bfloat16 עבור דגם Llama 2. אנו מתחילים בהדגמה של יעילות קנה מידה כמעט ליניארי עבור SageMaker, ולאחר מכן ניתוח תרומות מכל תכונה לתפוקה אופטימלית, ומסיימים באימון יעיל עם אורכי רצף שונים עד 32,768 באמצעות מקביליות טנזור.
קנה מידה כמעט ליניארי עם SageMaker
כדי להפחית את זמן האימון הכולל עבור דגמי LLM, שמירה על תפוקה גבוהה בעת קנה מידה לאשכולות גדולים (אלפי GPUs) היא חיונית בהתחשב בתקורת התקשורת בין הצמתים. בפוסט זה, אנו מדגימים יעילות קנה מידה חזק וכמעט ליניארי (על ידי שינוי מספר ה-GPUs עבור גודל בעיה כולל קבוע) במופעי p4d המפעילים הן SMP והן SMDDP.
בחלק זה, אנו מדגים את ביצועי קנה המידה כמעט ליניארי של SMP. כאן אנו מאמנים דגמי Llama 2 בגדלים שונים (פרמטרים 7B, 13B ו-70B) באמצעות אורך רצף קבוע של 4,096, ה-SMDDP backend לתקשורת קולקטיבית, TE מאופשר, גודל אצווה עולמי של 4 מיליון, עם 16 עד 128 צמתים p4d . הטבלה הבאה מסכמת את ביצועי התצורה וביצועי האימון האופטימליים (מודל TFLOPs לשנייה).
| גודל דגם | מספר צמתים | TFLOPs* | sdp* | tp* | להוריד* | יעילות קנה מידה |
| 7B | 16 | 136.76 | 32 | 1 | N | 100.0% |
| 32 | 132.65 | 64 | 1 | N | 97.0% | |
| 64 | 125.31 | 64 | 1 | N | 91.6% | |
| 128 | 115.01 | 64 | 1 | N | 84.1% | |
| 13B | 16 | 141.43 | 32 | 1 | Y | 100.0% |
| 32 | 139.46 | 256 | 1 | N | 98.6% | |
| 64 | 132.17 | 128 | 1 | N | 93.5% | |
| 128 | 120.75 | 128 | 1 | N | 85.4% | |
| 70B | 32 | 154.33 | 256 | 1 | Y | 100.0% |
| 64 | 149.60 | 256 | 1 | N | 96.9% | |
| 128 | 136.52 | 64 | 2 | N | 88.5% |
*בגודל הדגם הנתון, אורך הרצף ומספר הצמתים, אנו מציגים את התפוקה והתצורות האופטימליות בעולם לאחר בחינת שילובי sdp, tp והפעלה שונים.
הטבלה הקודמת מסכמת את מספרי התפוקה האופטימליים בכפוף לדרגת המקבילה (sdp) של נתונים מרוסקים (בדרך כלל תוך שימוש בריסוק היברידי של FSDP במקום ריסוק מלא, עם פרטים נוספים בסעיף הבא), דרגת מקבילית טנזור (tp) ושינויי ערכי פריקת הפעלה, הדגמת קנה מידה כמעט ליניארי עבור SMP יחד עם SMDDP. לדוגמה, בהינתן דגם Llama 2 בגודל 7B ואורך רצף 4,096, בסך הכל הוא משיג יעילות קנה מידה של 97.0%, 91.6% ו-84.1% (ביחס ל-16 צמתים) ב-32, 64 ו-128 צמתים, בהתאמה. יעילות קנה המידה יציבה על פני גדלי דגמים שונים ועולה מעט ככל שגודל הדגם גדל.
SMP ו- SMDDP מדגימים גם יעילות קנה מידה דומים עבור אורכי רצף אחרים כגון 2,048 ו-8,192.
ביצועי ספרייה מקבילית 2.0 של SageMaker: Llama 2 70B
גדלי הדגמים המשיכו לגדול במהלך השנים האחרונות, יחד עם עדכוני ביצועים עדכניים תכופים בקהילת ה-LLM. בחלק זה, אנו מדגים את הביצועים ב- SageMaker עבור דגם ה-Llama 2 באמצעות דגם קבוע בגודל 70B, אורך רצף של 4,096 וגודל אצווה עולמי של 4 מיליון. כדי להשוות עם התצורה והתפוקה האופטימלית הגלובלית של הטבלה הקודמת (עם SMDDP backend, בדרך כלל FSDP hybrid sharding ו-TE), הטבלה הבאה מתרחבת לתפוקות אופטימליות אחרות (פוטנציאליות עם מקביליות טנזור) עם מפרטים נוספים ב-backend המבוזר (NCCL ו- SMDDP) , אסטרטגיות ריסוק FSDP (ריסוק מלא וריסוק היברידי), והפעלת TE או לא (ברירת מחדל).
| גודל דגם | מספר צמתים | TFLOPS | תצורת TFLOPs #3 | שיפור של TFLOPs לעומת קו הבסיס | ||||||||
| . | . | ריסוק מלא NCCL: #0 | SMDDP ריסוק מלא: #1 | ריסוק SMDDP היברידי: #2 | ריסוק SMDDP היברידי עם TE: #3 | sdp* | tp* | להוריד* | #0 → #1 | #1 → #2 | #2 → #3 | #0 → #3 |
| 70B | 32 | 150.82 | 149.90 | 150.05 | 154.33 | 256 | 1 | Y | -0.6% | 0.1% | 2.9% | 2.3% |
| 64 | 144.38 | 144.38 | 145.42 | 149.60 | 256 | 1 | N | 0.0% | 0.7% | 2.9% | 3.6% | |
| 128 | 68.53 | 103.06 | 130.66 | 136.52 | 64 | 2 | N | 50.4% | 26.8% | 4.5% | 99.2% | |
*בגודל הדגם הנתון, אורך הרצף ומספר הצמתים, אנו מציגים את התפוקה והתצורה האופטימליים בעולם לאחר בחינת שילובים שונים של sdp, tp והפעלה.
המהדורה האחרונה של SMP ו- SMDDP תומכת במספר תכונות כולל PyTorch FSDP מקורי, ריסוק היברידי מורחב וגמיש יותר, אינטגרציה של מנוע שנאי, מקביליות טנזור ואופטימיזציה של כל פעולה קולקטיבית. כדי להבין טוב יותר כיצד SageMaker משיגה הכשרה מבוזרת יעילה עבור LLMs, אנו בוחנים תרומות מצטברות מ-SMDDP וה-SMP הבא תכונות ליבה:
- שיפור SMDDP על פני NCCL עם רסיסה מלאה של FSDP
- החלפת רסיסה מלאה של FSDP עם ריסוק היברידי, מה שמפחית את עלות התקשורת לשיפור התפוקה
- חיזוק נוסף לתפוקה עם TE, גם כאשר מקביליות טנזור מושבתת
- בהגדרות משאבים נמוכות יותר, פריקת הפעלה עשויה לאפשר אימון שאחרת יהיה בלתי אפשרי או איטי מאוד בגלל לחץ זיכרון גבוה
רסיסה מלאה של FSDP: שיפור SMDDP על פני NCCL
כפי שמוצג בטבלה הקודמת, כאשר דגמים מנותקים במלואם עם FSDP, למרות שתפוקות NCCL (TFLOPs #0) ו-SMDDP (TFLOPs #1) ניתנות להשוואה ב-32 או 64 צמתים, יש שיפור עצום של 50.4% מ-NCCL ל-SMDDP ב-128 צמתים.
בגדלים קטנים יותר של דגמים, אנו רואים שיפורים עקביים ומשמעותיים עם SMDDP על פני NCCL, החל בגדלים קטנים יותר של אשכולות, מכיוון ש- SMDDP מסוגל להפחית את צוואר הבקבוק בתקשורת ביעילות.
רסיסה היברידית FSDP להפחתת עלות התקשורת
ב-SMP 1.0, השקנו מקביליות נתונים מרוסקים, טכניקת אימון מבוזרת המופעלת על ידי אמזון בבית MiCS טֶכנוֹלוֹגִיָה. ב-SMP 2.0, אנו מציגים את SMP hybrid sharding, טכניקת ריסוק היברידית הניתנת להרחבה וגמישה יותר, המאפשרת פיצול דגמים בין תת-קבוצה של GPUs, במקום כל ה-GPUs הכשרה, וזה המקרה של FSDP sharding מלא. זה שימושי עבור דגמים בגודל בינוני שאין צורך לפזר אותם על פני כל האשכול על מנת לספק את אילוצי הזיכרון לכל GPU. זה מוביל לאשכולות עם יותר מעתק דגם אחד וכל GPU מתקשר עם פחות עמיתים בזמן ריצה.
הרסיסה ההיברידית של SMP מאפשרת ריסוק מודלים יעיל בטווח רחב יותר, מדרגת הרסיס הקטנה ביותר ללא בעיות מחוץ לזיכרון ועד לגודל האשכול כולו (ששווה לריסוק מלא).
האיור הבא ממחיש את תלות התפוקה ב-sdp ב-tp = 1 לשם הפשטות. למרות שזה לא בהכרח זהה לערך ה-tp האופטימלי עבור NCCL או SMDDP ריסוק מלא בטבלה הקודמת, המספרים די קרובים. זה מאמת בבירור את הערך של מעבר מריסוק מלא לריסוק היברידי בגודל אשכול גדול של 128 צמתים, אשר ישים גם ל-NCCL וגם ל-SMDDP. עבור דגמים קטנים יותר, שיפורים משמעותיים עם ריסוק היברידי מתחילים בגדלים קטנים יותר של אשכול, וההבדל ממשיך לגדול עם גודל האשכול.
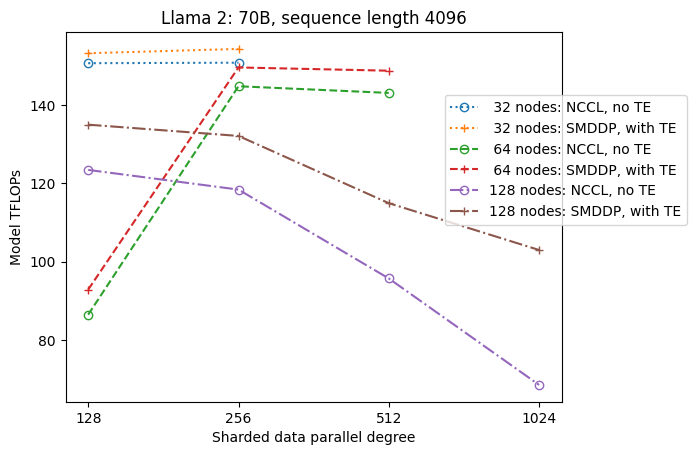
שיפורים עם TE
TE נועד להאיץ אימון LLM על מעבדי NVIDIA GPU. למרות שאיננו משתמשים ב-FP8 מכיוון שהוא אינו נתמך במופעי p4d, אנו עדיין רואים מהירות משמעותית עם TE ב-p4d.
בנוסף ל-MiCS שאומן עם ה-SMDDP backend, TE מציגה דחיפה עקבית לתפוקה בכל גדלי האשכולות (החריג היחיד הוא ריסוק מלא ב-128 צמתים), גם כאשר מקביליות טנזור מושבתת (דרגת מקבילית טנזור היא 1).
עבור דגמים קטנים יותר או אורכי רצף שונים, הגברת ה-TE היא יציבה ולא טריוויאלית, בטווח של כ-3-7.6%.
הורדת הפעלה בהגדרות משאבים נמוכות
בהגדרות משאבים נמוכות (בהינתן מספר קטן של צמתים), FSDP עלול לחוות לחץ זיכרון גבוה (או אפילו חסר זיכרון במקרה הגרוע) כאשר הפעלת נקודת ביקורת מופעלת. עבור תרחישים כאלה עם צווארי בקבוק על ידי זיכרון, הפעלת הורדת הפעלה היא אופציה פוטנציאלית לשיפור הביצועים.
לדוגמה, כפי שראינו בעבר, למרות שה-Llama 2 בגודל 13B ואורך רצף 4,096 מסוגל להתאמן בצורה מיטבית עם לפחות 32 צמתים עם נקודת ביקורת הפעלה וללא פריקת הפעלה, היא משיגה את התפוקה הטובה ביותר עם פריקת הפעלה כאשר היא מוגבלת ל-16 צמתים.
אפשר אימון עם רצפים ארוכים: מקביליות טנזור SMP
אורכי רצף ארוכים יותר רצויים עבור שיחות והקשר ארוכות, והם מקבלים יותר תשומת לב בקהילת ה- LLM. לכן, אנו מדווחים על תפוקות שונות ברצף ארוך בטבלה הבאה. הטבלה מציגה תפוקות אופטימליות לאימון Llama 2 ב- SageMaker, עם אורכי רצף שונים מ-2,048 עד 32,768. באורך רצף 32,768, אימון FSDP מקורי אינו בר ביצוע עם 32 צמתים בגודל אצווה עולמי של 4 מיליון.
| . | . | . | TFLOPS | ||
| גודל דגם | אורך רצף | מספר צמתים | FSDP ו-NCCL ילידים | SMP ו- SMDDP | שיפור SMP |
| 7B | 2048 | 32 | 129.25 | 138.17 | 6.9% |
| 4096 | 32 | 124.38 | 132.65 | 6.6% | |
| 8192 | 32 | 115.25 | 123.11 | 6.8% | |
| 16384 | 32 | 100.73 | 109.11 | 8.3% | |
| 32768 | 32 | NA | 82.87 | . | |
| 13B | 2048 | 32 | 137.75 | 144.28 | 4.7% |
| 4096 | 32 | 133.30 | 139.46 | 4.6% | |
| 8192 | 32 | 125.04 | 130.08 | 4.0% | |
| 16384 | 32 | 111.58 | 117.01 | 4.9% | |
| 32768 | 32 | NA | 92.38 | . | |
| *: מקסימום | . | . | . | . | 8.3% |
| *: חציון | . | . | . | . | 5.8% |
כאשר גודל האשכול גדול וניתן לגודל אצווה גלובלי קבוע, חלק מהדרכת מודלים עשויה להיות בלתי ניתנת לביצוע עם PyTorch FSDP מקורי, חסר צינור מובנה או תמיכה מקבילית טנזור. בטבלה הקודמת, בהינתן גודל אצווה עולמי של 4 מיליון, 32 צמתים ואורך רצף 32,768, גודל האצווה האפקטיבי לכל GPU הוא 0.5 (לדוגמה, tp = 2 עם גודל אצווה 1), שאם לא כן יהיה בלתי אפשרי ללא הצגת מקביליות טנזור.
סיכום
בפוסט זה, הדגמנו אימון LLM יעיל עם SMP ו- SMDDP במופעי p4d, וייחסנו תרומות לתכונות מפתח מרובות, כגון שיפור SMDDP על פני NCCL, ריסוק היברידי FSDP גמיש במקום ריסוק מלא, שילוב TE ואפשרות מקביליות טנזור לטובת אורכי רצף ארוכים. לאחר שנבדק על פני מגוון רחב של הגדרות עם דגמים שונים, גדלי דגמים ואורכי רצף, הוא מציג יעילות קנה מידה כמעט ליניארית, עד 128 מופעי p4d ב- SageMaker. לסיכום, SageMaker ממשיכה להיות כלי רב עוצמה עבור חוקרים ומתרגלים של LLM.
למידע נוסף, עיין ב ספריית מקביליות מודל SageMaker v2, או צור קשר עם צוות SMP בכתובת sm-model-parallel-feedback@amazon.com.
תודות
ברצוננו להודות לרוברט ואן דוזן, בן סניידר, גאוטם קומאר ולואיס קווינטלה על המשוב והדיונים הבונים שלהם.
על הכותבים

שילה ליו הוא SDE באמזון SageMaker. בזמנה הפנוי היא נהנית מקריאה וספורט בחוץ.
 סוהיט קודגולה הוא מהנדס פיתוח תוכנה בקבוצת הבינה המלאכותית AWS שעובד על מסגרות למידה עמוקה. בזמנו הפנוי הוא אוהב לטייל, לטייל ולבשל.
סוהיט קודגולה הוא מהנדס פיתוח תוכנה בקבוצת הבינה המלאכותית AWS שעובד על מסגרות למידה עמוקה. בזמנו הפנוי הוא אוהב לטייל, לטייל ולבשל.
 ויקטור ז'ו הוא מהנדס תוכנה בלמידה עמוקה מבוזרת בשירותי האינטרנט של אמזון. ניתן למצוא אותו נהנה מטיולי הליכה ומשחקי לוח ברחבי אזור מפרץ SF.
ויקטור ז'ו הוא מהנדס תוכנה בלמידה עמוקה מבוזרת בשירותי האינטרנט של אמזון. ניתן למצוא אותו נהנה מטיולי הליכה ומשחקי לוח ברחבי אזור מפרץ SF.
 דריה קוודר עובד כמהנדס תוכנה ב-AWS. תחומי העניין שלה כוללים למידה עמוקה ואופטימיזציה של אימון מבוזר.
דריה קוודר עובד כמהנדס תוכנה ב-AWS. תחומי העניין שלה כוללים למידה עמוקה ואופטימיזציה של אימון מבוזר.
 טנג שו הוא מהנדס פיתוח תוכנה בקבוצת הדרכה מבוזרת ב-AWS AI. הוא נהנה לקרוא.
טנג שו הוא מהנדס פיתוח תוכנה בקבוצת הדרכה מבוזרת ב-AWS AI. הוא נהנה לקרוא.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/distributed-training-and-efficient-scaling-with-the-amazon-sagemaker-model-parallel-and-data-parallel-libraries/

