AutoML מאפשר לך להפיק תובנות מהירות וכלליות מהנתונים שלך ממש בתחילת מחזור החיים של פרויקט למידת מכונה (ML). הבנה מראש אילו טכניקות עיבוד מקדים וסוגי אלגוריתמים מספקים את התוצאות הטובות ביותר מפחיתה את הזמן לפיתוח, אימון ופריסה של המודל הנכון. הוא ממלא תפקיד מכריע בתהליך הפיתוח של כל מודל ומאפשר למדעני נתונים להתמקד בטכניקות ה-ML המבטיחות ביותר. בנוסף, AutoML מספקת ביצועי מודל בסיסי שיכולים לשמש נקודת התייחסות לצוות מדעי הנתונים.
כלי AutoML מחיל שילוב של אלגוריתמים שונים וטכניקות עיבוד מקדים שונות על הנתונים שלך. לדוגמה, הוא יכול לשנות את קנה המידה של הנתונים, לבצע בחירת תכונה חד-משתנית, לבצע PCA ברמות סף שונות של שונות ולהחיל אשכולות. ניתן ליישם טכניקות עיבוד מקדים כאלה בנפרד או לשלב בצנרת. לאחר מכן, כלי AutoML יאמן סוגי מודלים שונים, כגון Linear Regression, Elastic-Net או Random Forest, על גרסאות שונות של מערך הנתונים המעובדים מראש שלך ויבצע אופטימיזציה של היפרפרמטרים (HPO). טייס אוטומטי של אמזון מבטל את ההרמה הכבדה של בניין דגמי ML. לאחר מתן מערך הנתונים, SageMaker Autopilot בוחן אוטומטית פתרונות שונים כדי למצוא את הדגם הטוב ביותר. אבל מה אם אתה רוצה לפרוס את הגרסה המותאמת שלך של זרימת עבודה AutoML?
פוסט זה מראה כיצד ליצור זרימת עבודה AutoML בהתאמה אישית אמזון SageMaker באמצעות אמזון SageMaker כוונון דגם אוטומטי עם קוד לדוגמה זמין ב-a ריפו GitHub.
סקירת פתרונות
במקרה השימוש הזה, נניח שאתה חלק מצוות מדעי נתונים שמפתח מודלים בתחום מיוחד. פיתחת קבוצה של טכניקות עיבוד מוקדם מותאמות אישית ובחרת מספר אלגוריתמים שאתה מצפה בדרך כלל שיעבדו היטב עם בעיית ה-ML שלך. כשאתה עובד על מקרי שימוש חדשים ב-ML, תרצה תחילה לבצע ריצת AutoML באמצעות טכניקות העיבוד המקדים והאלגוריתמים שלך כדי לצמצם את היקף הפתרונות הפוטנציאליים.
עבור דוגמה זו, אינך משתמש במערך נתונים מיוחד; במקום זאת, אתה עובד עם מערך הנתונים של California Housing שממנו תייבא שירות אחסון פשוט של אמזון (אמזון S3). ההתמקדות היא להדגים את היישום הטכני של הפתרון באמצעות SageMaker HPO, שבהמשך ניתן ליישם אותו על כל מערך נתונים ותחום.
התרשים הבא מציג את זרימת העבודה הכוללת של הפתרון.

תנאים מוקדמים
להלן תנאים מוקדמים להשלמת ההדרכה בפוסט זה:
מיישמים את הפתרון
הקוד המלא זמין ב- GitHub ריפו.
השלבים ליישום הפתרון (כפי שמצוין בתרשים זרימת העבודה) הם כדלקמן:
- צור מופע מחברת וציין את הדברים הבאים:
- בעד סוג מופע מחברת, בחר ml.t3.בינוני.
- בעד מסקנות אלסטיות, בחר אף לא אחד.
- בעד מזהה פלטפורמה, בחר אמזון לינוקס 2, Jupyter Lab 3.
- בעד תפקיד IAM, בחר את ברירת המחדל
AmazonSageMaker-ExecutionRole. אם הוא לא קיים, צור חדש AWS זהות וניהול גישה (IAM) תפקיד ולצרף את מדיניות AmazonSageMakerFullAccess IAM.
שים לב שעליך ליצור תפקיד ומדיניות ביצוע בהיקף מינימלי בייצור.
- פתח את ממשק JupyterLab עבור מופע המחברת שלך ושבט את המאגר של GitHub.
אתה יכול לעשות זאת על ידי התחלת הפעלת טרמינל חדשה והפעלת ה git clone <REPO> פקודה או באמצעות פונקציונליות ממשק המשתמש, כפי שמוצג בצילום המסך הבא.

- פתח את
automl.ipynbקובץ המחברת, בחר אתconda_python3קרנל, ופעל לפי ההוראות כדי להפעיל את a סט משרות HPO.
כדי להפעיל את הקוד ללא כל שינוי, עליך להגדיל את מכסת השירות עבור ml.m5.large לשימוש בעבודה הדרכה ו מספר המקרים בכל משרות ההדרכה. AWS מאפשרת כברירת מחדל רק 20 עבודות הכשרה מקבילות של SageMaker עבור שתי המכסות. עליך לבקש הגדלת מכסה ל-30 עבור שניהם. בדרך כלל יש לאשר את שני שינויי המכסה תוך מספר דקות. מתייחס מבקש הגדלת מכסה לקבלת מידע נוסף.

אם אינך רוצה לשנות את המכסה, אתה יכול פשוט לשנות את הערך של ה- MAX_PARALLEL_JOBS משתנה בסקריפט (לדוגמה, עד 5).
- כל עבודת HPO תשלים סט של עבודת הכשרה ניסויים ומציינים את המודל עם היפרפרמטרים אופטימליים.
- נתח את התוצאות ו לפרוס את המודל בעל הביצועים הטובים ביותר.
פתרון זה יגרור עלויות בחשבון AWS שלך. העלות של פתרון זה תהיה תלויה במספר ומשך משרות ההכשרה של HPO. ככל שאלו יעלו, כך גם העלות תגדל. אתה יכול להפחית עלויות על ידי הגבלת זמן ההדרכה והגדרת התצורה TuningJobCompletionCriteriaConfig לפי ההנחיות שנדונו בהמשך הפוסט הזה. למידע על תמחור, עיין ב תמחור SageMaker של אמזון.
בסעיפים הבאים, אנו דנים במחברת ביתר פירוט עם דוגמאות קוד והשלבים לניתוח התוצאות ולבחירת המודל הטוב ביותר.
התקנה ראשונית
בואו נתחיל עם הפעלת ה יבוא והגדרה סעיף ב custom-automl.ipynb מחברת. הוא מתקין ומייבא את כל התלות הנדרשת, מפעיל הפעלה ולקוח של SageMaker, ומגדיר את ברירת המחדל של אזור ודלי S3 לאחסון נתונים.
הכנת נתונים
הורד את מערך הנתונים של California Housing והכן אותו על ידי הפעלת הורד נתונים חלק של המחברת. מערך הנתונים מפוצל למסגרות נתוני אימון ובדיקה ומועלה לדלי ברירת המחדל של הפעלת SageMaker S3.
למערך הנתונים כולו 20,640 רשומות ו-9 עמודות בסך הכל, כולל היעד. המטרה היא לחזות את הערך החציוני של בית (medianHouseValue טור). צילום המסך הבא מציג את השורות העליונות של מערך הנתונים.

תבנית תסריט הדרכה
זרימת העבודה של AutoML בפוסט זה מבוססת על סקיקיט-לימוד צינורות ואלגוריתמים לעיבוד מקדים. המטרה היא ליצור שילוב גדול של צינורות עיבוד מוקדם ואלגוריתמים שונים כדי למצוא את ההגדרה בעלת הביצועים הטובים ביותר. נתחיל עם יצירת סקריפט הדרכה גנרי, אשר קיים באופן מקומי במופע המחברת. בסקריפט זה, ישנם שני בלוקי הערות ריקים: האחד להזרקת הפרמטרים והשני עבור אובייקט הצינור של מודל ה-preprocessing. הם יוזרקו באופן דינמי עבור כל מועמד למודל עיבוד מקדים. המטרה של סקריפט גנרי אחד היא לשמור על היישום DRY (אל תחזור על עצמך).
צור שילובי עיבוד מקדים ומודלים
השמיים preprocessors המילון מכיל מפרט של טכניקות עיבוד מקדים המיושמות על כל תכונות הקלט של המודל. כל מתכון מוגדר באמצעות א Pipeline או FeatureUnion אובייקט מ-scikit-learn, שמשרשרת יחד טרנספורמציות נתונים בודדות ומערימה אותן יחד. לדוגמה, mean-imp-scale הוא מתכון פשוט המבטיח שהערכים החסרים יזקפו באמצעות ערכים ממוצעים של עמודות מתאימות ושכל התכונות יעברו קנה מידה באמצעות StandardScaler. לעומת זאת, ה mean-imp-scale-pca מתכונים משלבים עוד כמה פעולות:
- זקוף ערכים חסרים בעמודות עם הממוצע שלו.
- החל קנה מידה של תכונה באמצעות ממוצע וסטיית תקן.
- חשב PCA על גבי נתוני הקלט בערך סף שונות שצוין ומיזג אותו יחד עם תכונות הקלט הזקיפות והמותאם.
בפוסט זה, כל תכונות הקלט הן מספריות. אם יש לך יותר סוגי נתונים במערך הקלט שלך, עליך לציין צינור מסובך יותר שבו ענפי עיבוד מקדים שונים מוחלים על ערכות סוגי תכונות שונות.
השמיים models המילון מכיל מפרטים של אלגוריתמים שונים שאליהם אתה מתאים את מערך הנתונים. כל סוג דגם מגיע עם המפרט הבא במילון:
- script_output – מצביע על מיקומו של תסריט האימון המשמש את האומד. שדה זה מתמלא באופן דינמי כאשר
modelsהמילון משולב עם הpreprocessorsמילון. - הכנסות – מגדיר קוד שיוכנס לתוך
script_draft.pyובהמשך נשמר תחתscript_output. המפתח“preprocessor”נותר ריק בכוונה מכיוון שמיקום זה מלא באחד ממעבדי הקדם כדי ליצור שילובים מרובים של דגם-קדם מעבד. - יתר פרמטרים – קבוצה של היפרפרמטרים שעברו אופטימיזציה על ידי עבודת HPO.
- include_cls_metadata - פרטי תצורה נוספים הנדרשים על ידי SageMaker
Tunerמעמד.
דוגמה מלאה של models המילון זמין במאגר GitHub.
לאחר מכן, בואו נעבור דרך ה preprocessors ו models מילונים וליצור את כל השילובים האפשריים. לדוגמה, אם שלך preprocessors המילון מכיל 10 מתכונים ויש לך 5 הגדרות מודל ב models מילון, מילון הצינורות החדש שנוצר מכיל 50 צינורות מודל קדם-מעבד אשר מוערכים במהלך HPO. שים לב שסקריפטים בודדים של צינורות לא נוצרו עדיין בשלב זה. בלוק הקוד הבא (תא 9) של המחברת Jupyter חוזרת דרך כל האובייקטים של מודל קדם-מעבד ב- pipelines מילון, מוסיף את כל חלקי הקוד הרלוונטיים, ומחזיק גרסה ספציפית לצינור של הסקריפט באופן מקומי במחברת. סקריפטים אלה משמשים בשלבים הבאים בעת יצירת אומדנים בודדים שאתה מחבר לעבודת HPO.
הגדר אומדנים
כעת תוכל לעבוד על הגדרת SageMaker Estimators שעבודת HPO משתמשת בהם לאחר שהסקריפטים מוכנים. נתחיל ביצירת מחלקה עטיפה המגדירה כמה מאפיינים משותפים לכל האומדנים. זה יורש מה SKLearn class ומציין את התפקיד, ספירת המופעים והסוג, כמו גם אילו עמודות משמשות את הסקריפט כתכונות וכמטרה.
בואו נבנה את estimators מילון על ידי איטרציה של כל הסקריפטים שנוצרו לפני וממוקמים ב- scripts מַדרִיך. אתה יוצר אומדן חדש באמצעות ה- SKLearnBase כיתה, עם שם אומד ייחודי, ואחד מהסקריפטים. שימו לב שה- estimators למילון שתי רמות: הרמה העליונה מגדירה א pipeline_family. זוהי קיבוץ לוגי המבוסס על סוג המודלים שיש להעריך ושווה לאורך ה- models מילון. הרמה השנייה מכילה סוגי קדם-מעבד בודדים בשילוב עם הנתון pipeline_family. קיבוץ לוגי זה נדרש בעת יצירת עבודת HPO.
הגדר ארגומנטים של טיונר HPO
כדי לייעל את העברת הטיעונים ל-HPO Tuner הכיתה, ה HyperparameterTunerArgs מחלקת הנתונים מאותחלת עם ארגומנטים הנדרשים על ידי מחלקת HPO. זה מגיע עם קבוצת פונקציות, המבטיחות שארגומנטים של HPO מוחזרים בפורמט הצפוי בעת פריסת הגדרות מודל מרובות בו-זמנית.
בלוק הקוד הבא משתמש בקוד שהוצג קודם לכן HyperparameterTunerArgs מחלקת נתונים. אתה יוצר עוד מילון בשם hp_args וליצור קבוצה של פרמטרי קלט ספציפיים לכל אחד estimator_family מ estimators מילון. טיעונים אלה משמשים בשלב הבא בעת אתחול עבודות HPO עבור כל משפחת מודל.
צור אובייקטים של מקלט HPO
בשלב זה, אתה יוצר מקלטים בודדים עבור כל אחד estimator_family. מדוע אתה יוצר שלוש משרות נפרדות של HPO במקום להשיק רק אחת בכל האומדנים? ה HyperparameterTuner המחלקה מוגבלת ל-10 הגדרות מודל המצורפות אליו. לכן, כל HPO אחראי למציאת הפרה-מעבד בעל הביצועים הטובים ביותר עבור משפחת דגמים נתונה וכוונון הפרמטרים ההיפרפרמטרים של משפחת דגמים זו.
להלן מספר נקודות נוספות לגבי ההגדרה:
- אסטרטגיית האופטימיזציה היא Bayesian, מה שאומר שה-HPO עוקב באופן פעיל אחר הביצועים של כל הניסויים ומנווט את האופטימיזציה לעבר שילובי היפרפרמטרים מבטיחים יותר. יש להגדיר עצירה מוקדמת ל כבוי or אוטומטי כאשר עובדים עם אסטרטגיה בייסיאנית, שמטפלת בהיגיון הזה בעצמה.
- כל משרת HPO פועלת ל-100 משרות לכל היותר ופועלת 10 משרות במקביל. אם אתה מתמודד עם מערכי נתונים גדולים יותר, ייתכן שתרצה להגדיל את מספר המשרות הכולל.
- בנוסף, ייתכן שתרצה להשתמש בהגדרות השולטות כמה זמן עבודה פועלת וכמה עבודות ה-HPO שלך מפעיל. אחת הדרכים לעשות זאת היא להגדיר את זמן הריצה המקסימלי בשניות (עבור פוסט זה, הגדרנו אותו לשעה אחת). אחר הוא להשתמש בגרסה ששוחררה לאחרונה
TuningJobCompletionCriteriaConfig. הוא מציע סט של הגדרות שמנטרות את התקדמות העבודות שלך ומחליטות אם סביר להניח שעבודות נוספות ישפרו את התוצאה. בפוסט זה, הגדרנו את המספר המרבי של משרות הכשרה שאינן משתפרות ל-20. כך, אם הציון אינו משתפר (לדוגמה, מהניסיון הארבעים), לא תצטרכו לשלם עבור שאר הניסיון עדmax_jobsמושג.
עכשיו בואו נעבור דרך ה tuners ו hp_args מילונים ומפעילים את כל משרות HPO ב- SageMaker. שימו לב לשימוש בארגומנט המתנה שהוגדר ל False, מה שאומר שהקרנל לא ימתין עד להשלמת התוצאות ותוכל להפעיל את כל המשימות בבת אחת.
סביר להניח שלא כל עבודות ההדרכה יסתיימו וחלקן עשויות להיעצר על ידי עבודת HPO. הסיבה לכך היא ה TuningJobCompletionCriteriaConfig-האופטימיזציה מסתיימת אם מתקיים אחד מהקריטריונים שצוינו. במקרה זה, כאשר קריטריוני האופטימיזציה אינם משתפרים עבור 20 משרות רצופות.
ניתוח תוצאות
תא 15 של המחברת בודק אם כל עבודות HPO הושלמו ומשלב את כל התוצאות בצורה של מסגרת נתונים של פנדה לניתוח נוסף. לפני שננתח את התוצאות בפירוט, בואו נסתכל ברמה גבוהה על קונסולת SageMaker.
בחלק העליון של עבודות כוונון היפרפרמטרים בדף, תוכל לראות את שלוש משרות ה-HPO שהושקו. כולם סיימו מוקדם ולא ביצעו את כל 100 עבודות ההדרכה. בצילום המסך הבא, אתה יכול לראות שמשפחת דגמי Elastic-Net השלימה את המספר הגבוה ביותר של ניסויים, בעוד שאחרים לא היו צריכים כל כך הרבה עבודות אימון כדי למצוא את התוצאה הטובה ביותר.
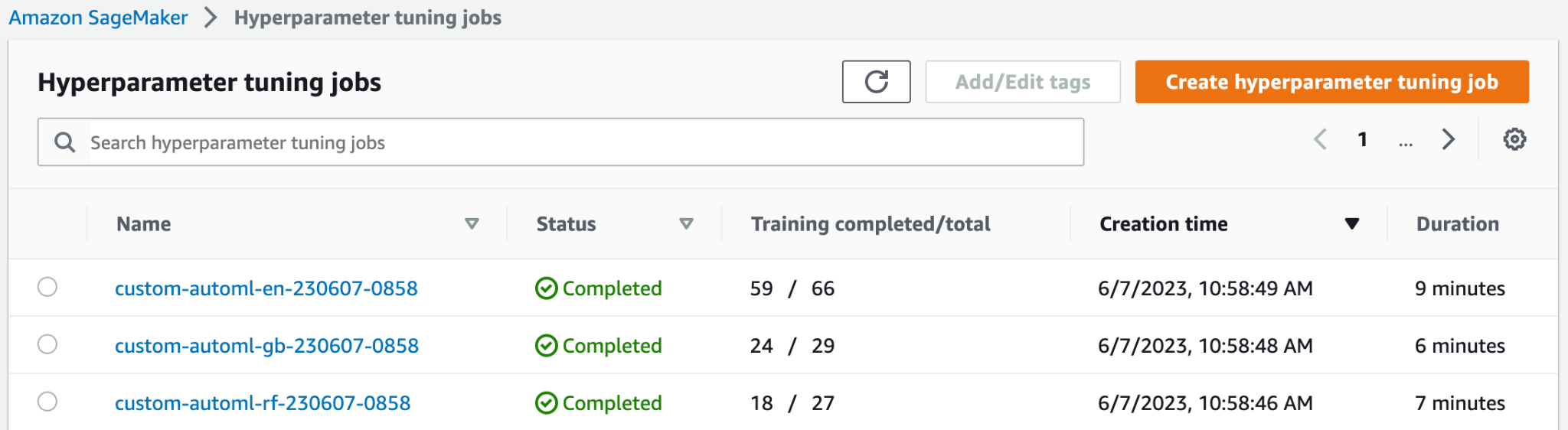
אתה יכול לפתוח את משימת ה-HPO כדי לגשת לפרטים נוספים, כגון עבודות הכשרה בודדות, תצורת עבודה והמידע והביצועים הטובים ביותר של עבודת ההדרכה.

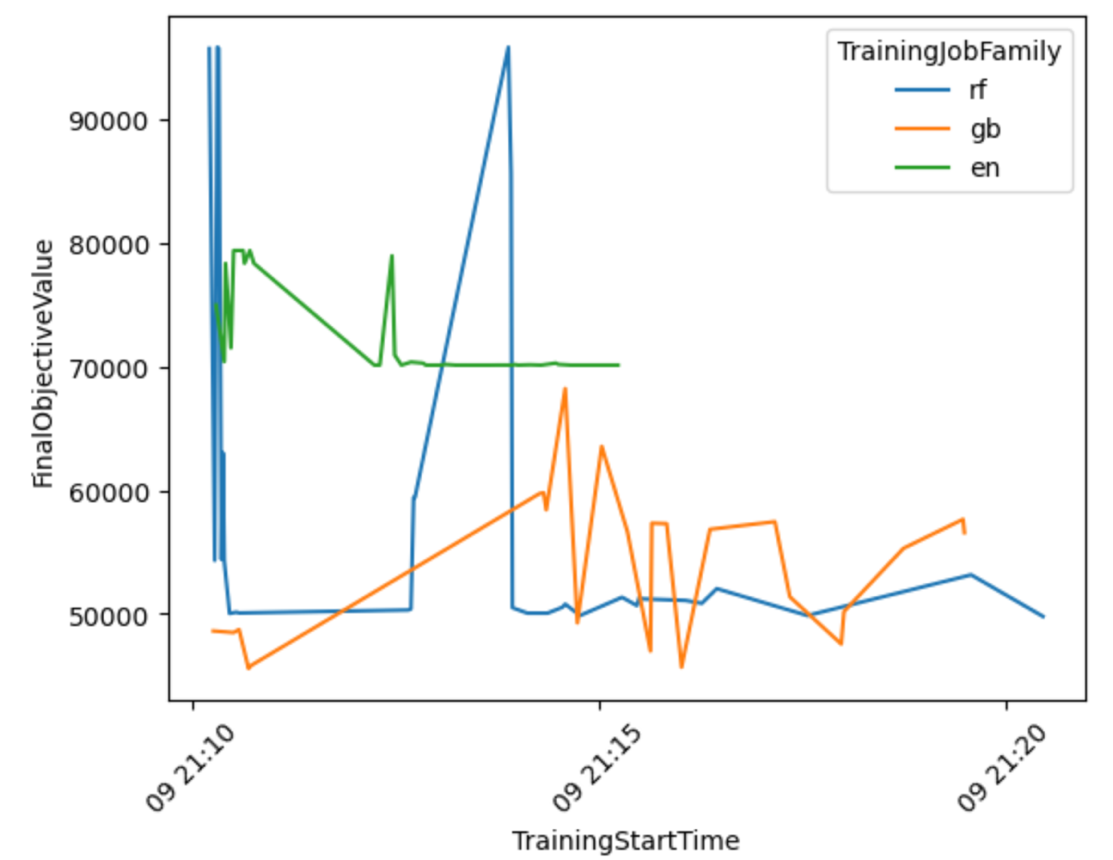
בואו נפיק הדמיה המבוססת על התוצאות כדי לקבל יותר תובנות לגבי ביצועי זרימת העבודה של AutoML בכל משפחות הדגמים.
מהגרף הבא, אתה יכול להסיק כי Elastic-Net הביצועים של המודל נעו בין 70,000 ל-80,000 RMSE ולבסוף נתקעו, מכיוון שהאלגוריתם לא הצליח לשפר את הביצועים שלו למרות שניסיתם טכניקות עיבוד מקדים וערכי היפרפרמטרים שונים. גם כך נראה RandomForest הביצועים השתנו מאוד בהתאם לקבוצת ההיפרפרמטרים שנחקרה על ידי HPO, אך למרות ניסויים רבים הוא לא יכול היה לרדת מתחת לשגיאת 50,000 RMSE. GradientBoosting השיג את הביצועים הטובים ביותר כבר מההתחלה וירד מתחת ל-50,000 RMSE. HPO ניסה לשפר את התוצאה הזו עוד יותר אך לא הצליח להשיג ביצועים טובים יותר בשילובי היפרפרמטרים אחרים. מסקנה כללית לכל משרות ה-HPO היא שלא נדרשו כל כך הרבה עבודות כדי למצוא את קבוצת ההיפרפרמטרים בעלת הביצועים הטובים ביותר עבור כל אלגוריתם. כדי לשפר עוד יותר את התוצאה, תצטרך להתנסות ביצירת תכונות נוספות וביצוע הנדסת תכונות נוספת.
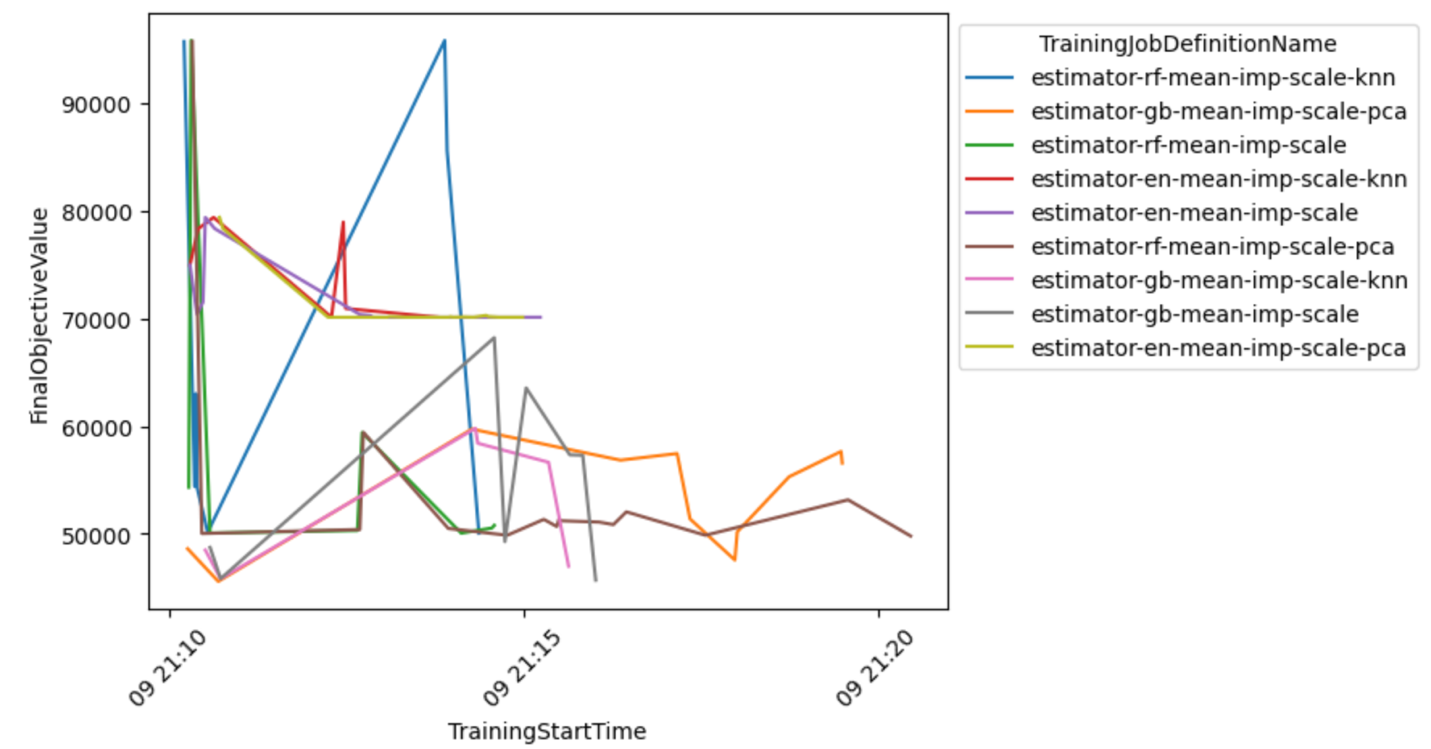
אתה יכול גם לבחון תצוגה מפורטת יותר של שילוב הדגם-קדם-מעבד כדי להסיק מסקנות לגבי השילובים המבטיחים ביותר.
בחר את הדגם הטוב ביותר ופרוס אותו
קטע הקוד הבא בוחר את המודל הטוב ביותר על סמך ערך המטרה הנמוך ביותר שהושג. לאחר מכן תוכל לפרוס את המודל כנקודת קצה של SageMaker.
לנקות את
כדי למנוע חיובים לא רצויים לחשבון AWS שלך, אנו ממליצים למחוק את משאבי AWS שבהם השתמשת בפוסט זה:
- בקונסולת Amazon S3, רוקן את הנתונים מדלי ה-S3 שבו אוחסנו נתוני האימון.

- במסוף SageMaker, עצור את מופע המחברת.

- מחק את נקודת הקצה של הדגם אם פרסת אותה. יש למחוק נקודות קצה כאשר אינן בשימוש עוד, מכיוון שהן מחויבות לפי זמן הפריסה.
סיכום
בפוסט זה, הצגנו כיצד ליצור עבודת HPO מותאמת אישית ב- SageMaker באמצעות מבחר מותאם אישית של אלגוריתמים וטכניקות עיבוד מקדים. בפרט, דוגמה זו מדגימה כיצד להפוך את התהליך של יצירת סקריפטים אימון רבים וכיצד להשתמש במבני תכנות של Python לפריסה יעילה של מספר עבודות אופטימיזציה מקבילות. אנו מקווים שהפתרון הזה יהווה את הפיגום של כל עבודת כוונון מודלים מותאמים אישית שתפרוס באמצעות SageMaker כדי להשיג ביצועים גבוהים יותר ולהאיץ את זרימות העבודה שלך ב-ML.
עיין במשאבים הבאים כדי להעמיק עוד יותר את הידע שלך כיצד להשתמש ב- SageMaker HPO:
על הכותבים
 קונרד סמש הוא ארכיטקט בכיר ML Solutions בצוות מעבדת הנתונים של Amazon Web Services. הוא עוזר ללקוחות להשתמש בלמידת מכונה כדי לפתור את האתגרים העסקיים שלהם עם AWS. הוא נהנה להמציא ולפשט כדי לאפשר ללקוחות פתרונות פשוטים ופרגמטיים לפרויקטים של AI/ML שלהם. הוא נלהב ביותר מ-MlOps וממדעי הנתונים המסורתיים. מחוץ לעבודה, הוא מעריץ גדול של גלישת רוח וגלישת עפיפונים.
קונרד סמש הוא ארכיטקט בכיר ML Solutions בצוות מעבדת הנתונים של Amazon Web Services. הוא עוזר ללקוחות להשתמש בלמידת מכונה כדי לפתור את האתגרים העסקיים שלהם עם AWS. הוא נהנה להמציא ולפשט כדי לאפשר ללקוחות פתרונות פשוטים ופרגמטיים לפרויקטים של AI/ML שלהם. הוא נלהב ביותר מ-MlOps וממדעי הנתונים המסורתיים. מחוץ לעבודה, הוא מעריץ גדול של גלישת רוח וגלישת עפיפונים.
 טונה ארסוי הוא אדריכל פתרונות בכיר ב-AWS. המיקוד העיקרי שלה הוא לעזור ללקוחות במגזר הציבורי לאמץ טכנולוגיות ענן לעומסי העבודה שלהם. יש לה רקע בפיתוח אפליקציות, ארכיטקטורה ארגונית וטכנולוגיות מרכז קשר. תחומי העניין שלה כוללים ארכיטקטורות ללא שרת ו-AI/ML.
טונה ארסוי הוא אדריכל פתרונות בכיר ב-AWS. המיקוד העיקרי שלה הוא לעזור ללקוחות במגזר הציבורי לאמץ טכנולוגיות ענן לעומסי העבודה שלהם. יש לה רקע בפיתוח אפליקציות, ארכיטקטורה ארגונית וטכנולוגיות מרכז קשר. תחומי העניין שלה כוללים ארכיטקטורות ללא שרת ו-AI/ML.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/implement-a-custom-automl-job-using-pre-selected-algorithms-in-amazon-sagemaker-automatic-model-tuning/

