כיום, לקוחות מכל הענפים - בין אם זה שירותים פיננסיים, בריאות ומדעי החיים, נסיעות ואירוח, מדיה ובידור, טלקומוניקציה, תוכנה כשירות (SaaS), ואפילו ספקי מודלים קנייניים - משתמשים במודלים של שפה גדולה (LLMs) כדי לבנות יישומים כמו שאלות ותשובות (QnA) צ'אטבוטים, מנועי חיפוש ומאגרי ידע. אלה AI ייצור יישומים משמשים לא רק לאוטומציה של תהליכים עסקיים קיימים, אלא יש להם גם את היכולת לשנות את החוויה עבור לקוחות המשתמשים ביישומים אלה. עם ההתקדמות שמתבצעת עם לימודי תואר שני כמו ה Mixtral-8x7B הדרכה, נגזרת של ארכיטקטורות כגון ה תערובת של מומחים (MoE), לקוחות מחפשים כל הזמן דרכים לשפר את הביצועים והדיוק של יישומי AI גנרטיביים תוך שהם מאפשרים להם להשתמש ביעילות במגוון רחב יותר של מודלים סגורים וקוד פתוח.
מספר טכניקות משמשות בדרך כלל כדי לשפר את הדיוק והביצועים של הפלט של LLM, כגון כוונון עדין עם כוונון יעיל של פרמטרים (PEFT), למידת חיזוק ממשוב אנושי (RLHF), ומופיע זיקוק ידע. עם זאת, בעת בניית יישומי AI גנרטיביים, אתה יכול להשתמש בפתרון חלופי המאפשר שילוב דינמי של ידע חיצוני ומאפשר לך לשלוט במידע המשמש ליצירת ללא צורך לכוונן את המודל הבסיסי הקיים שלך. כאן נכנס לתמונה ה-Retrieval Augmented Generation (RAG), במיוחד עבור יישומי AI גנרטיביים, בניגוד לחלופות הכוונון היקרות והחזקות יותר שדנו בהן. אם אתה מיישם יישומי RAG מורכבים במשימות היומיומיות שלך, אתה עלול להיתקל באתגרים נפוצים עם מערכות RAG שלך כגון שליפה לא מדויקת, הגדלת גודל ומורכבות המסמכים והצפת הקשר, מה שיכול להשפיע באופן משמעותי על האיכות והאמינות של התשובות שנוצרו. .
פוסט זה דן בדפוסי RAG לשיפור דיוק התגובה באמצעות LangChain וכלים כגון אחזור המסמכים האב בנוסף לטכניקות כמו דחיסה קונטקסטואלית על מנת לאפשר למפתחים לשפר יישומי AI יצירתיים קיימים.
סקירת פתרונות
בפוסט זה, אנו מדגימים את השימוש ביצירת טקסט Mixtral-8x7B Instruct בשילוב עם מודל ההטמעה של BGE Large En כדי לבנות ביעילות מערכת RAG QnA על מחברת אמזון SageMaker באמצעות כלי אחזור המסמכים האב וטכניקת הדחיסה ההקשרית. התרשים הבא ממחיש את הארכיטקטורה של פתרון זה.
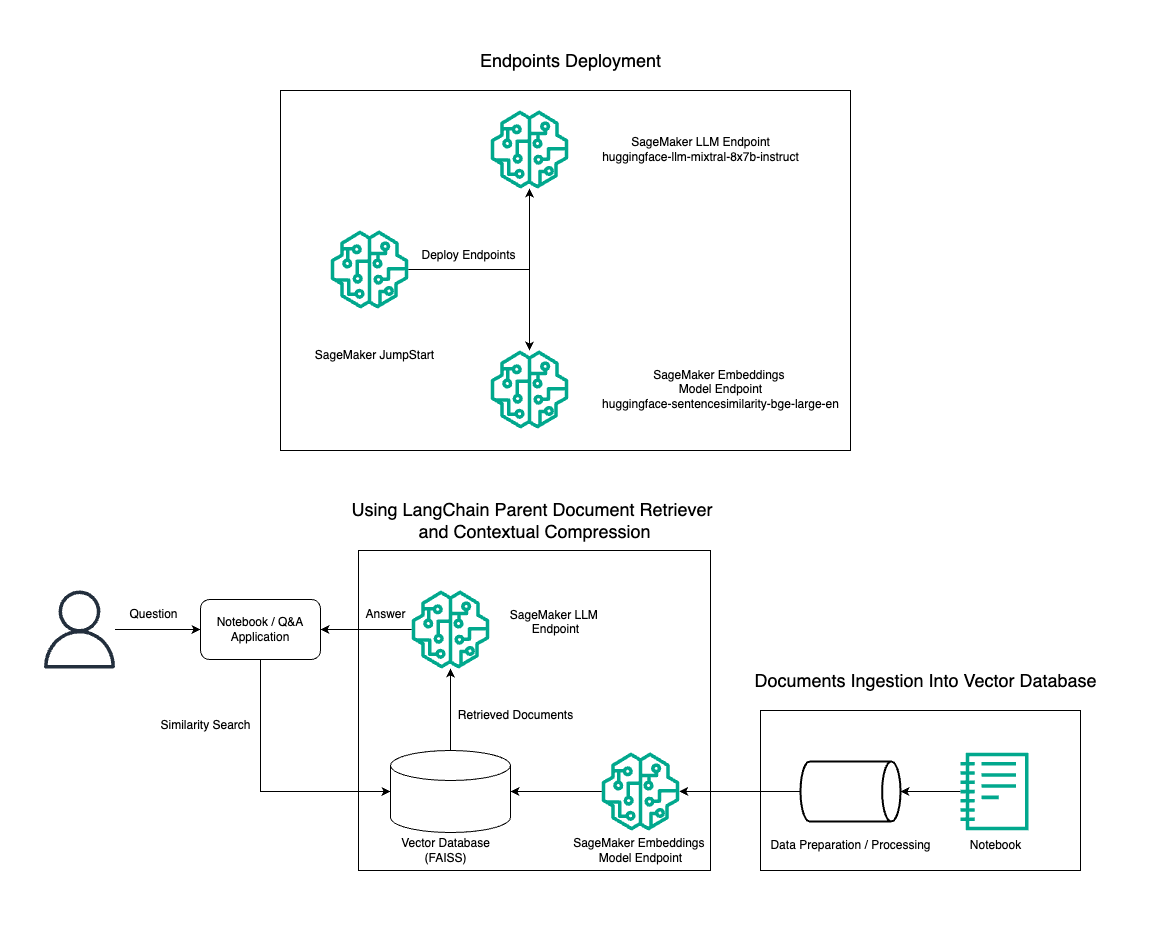
אתה יכול לפרוס פתרון זה בכמה קליקים בלבד באמצעות אמזון SageMaker JumpStart, פלטפורמה מנוהלת במלואה המציעה מודלים מתקדמים של בסיס למקרי שימוש שונים כגון כתיבת תוכן, הפקת קוד, מענה לשאלות, קופירייטינג, סיכום, סיווג ואחזור מידע. הוא מספק אוסף של מודלים מאומנים מראש שתוכל לפרוס במהירות ובקלות, להאיץ את הפיתוח והפריסה של יישומי למידת מכונה (ML). אחד המרכיבים המרכזיים של SageMaker JumpStart הוא ה-Model Hub, שמציע קטלוג עצום של דגמים שהוכשרו מראש, כמו Mixtral-8x7B, למגוון משימות.
Mixtral-8x7B משתמש בארכיטקטורת MoE. ארכיטקטורה זו מאפשרת לחלקים שונים של רשת עצבית להתמחות במשימות שונות, ולמעשה לחלק את עומס העבודה בין מספר מומחים. גישה זו מאפשרת אימון ופריסה יעילה של מודלים גדולים יותר בהשוואה לארכיטקטורות מסורתיות.
אחד היתרונות העיקריים של ארכיטקטורת MoE הוא יכולת ההרחבה שלה. על ידי חלוקת עומס העבודה על פני מספר מומחים, ניתן לאמן מודלים של MoE על מערכי נתונים גדולים יותר ולהשיג ביצועים טובים יותר ממודלים מסורתיים באותו גודל. בנוסף, מודלים של MoE יכולים להיות יעילים יותר במהלך הסקת מסקנות מכיוון שצריך להפעיל רק תת-קבוצה של מומחים עבור קלט נתון.
למידע נוסף על Mixtral-8x7B Instruct על AWS, עיין ב Mixtral-8x7B זמין כעת באמזון SageMaker JumpStart. דגם Mixtral-8x7B זמין תחת רישיון Apache 2.0 המתיר, לשימוש ללא הגבלות.
בפוסט זה, נדון כיצד אתה יכול להשתמש LangChain ליצירת יישומי RAG אפקטיביים ויעילים יותר. LangChain היא ספריית Python בקוד פתוח שנועדה לבנות יישומים עם LLMs. הוא מספק מסגרת מודולרית וגמישה לשילוב LLMs עם רכיבים אחרים, כגון בסיסי ידע, מערכות אחזור וכלי AI אחרים, ליצירת יישומים רבי עוצמה וניתנים להתאמה אישית.
אנו עוברים דרך בניית צינור RAG ב- SageMaker עם Mixtral-8x7B. אנו משתמשים במודל יצירת טקסט של Mixtral-8x7B Instruct עם מודל ההטמעה BGE Large En כדי ליצור מערכת QnA יעילה באמצעות RAG על מחברת SageMaker. אנו משתמשים במופע ml.t3.medium כדי להדגים פריסת LLMs דרך SageMaker JumpStart, שאליו ניתן לגשת דרך נקודת קצה של API שנוצרה על ידי SageMaker. הגדרה זו מאפשרת חקירה, ניסוי ואופטימיזציה של טכניקות RAG מתקדמות עם LangChain. אנו גם ממחישים את השילוב של חנות Embedding של FAISS בזרימת העבודה של RAG, תוך הדגשת תפקידה באחסון ואחזור הטבעות כדי לשפר את ביצועי המערכת.
אנו מבצעים הדרכה קצרה על מחברת SageMaker. להנחיות מפורטות יותר ושלב אחר שלב, עיין ב- דפוסי RAG מתקדמים עם Mixtral ב-SageMaker Jumpstart GitHub ריפו.
הצורך בדפוסי RAG מתקדמים
דפוסי RAG מתקדמים חיוניים כדי לשפר את היכולות הנוכחיות של LLMs בעיבוד, הבנה והפקת טקסט דמוי אדם. ככל שהגודל והמורכבות של המסמכים גדלים, ייצוג היבטים מרובים של המסמך בהטמעה אחת עלול להוביל לאובדן הספציפיות. למרות שחיוני ללכוד את המהות הכללית של מסמך, זה חיוני באותה מידה לזהות ולייצג את תת ההקשרים המגוונים שבתוכו. זהו אתגר שאתה מתמודד איתו לעתים קרובות בעבודה עם מסמכים גדולים יותר. אתגר נוסף עם RAG הוא שעם השליפה, אינך מודע לשאילתות הספציפיות שמערכת אחסון המסמכים שלך תתמודד איתן בעת הבליעה. הדבר עלול להוביל לכך שהמידע הרלוונטי ביותר לשאילתה ייקבר תחת טקסט (הצפת ההקשר). כדי לצמצם כשלים ולשפר את ארכיטקטורת RAG הקיימת, אתה יכול להשתמש בדפוסי RAG מתקדמים (שחזור מסמכים אב ודחיסה קונטקסטואלית) כדי לצמצם שגיאות אחזור, לשפר את איכות התשובה ולאפשר טיפול בשאלות מורכבות.
בעזרת הטכניקות הנדונות בפוסט זה, תוכל להתמודד עם אתגרים מרכזיים הקשורים לאחזור ושילוב ידע חיצוני, מה שיאפשר לאפליקציה שלך לספק תגובות מדויקות יותר ומודעות להקשר.
בסעיפים הבאים, אנו חוקרים כיצד מאחזרי מסמכי אב ו דחיסה הקשרית יכול לעזור לך להתמודד עם כמה מהבעיות שדנו בהן.
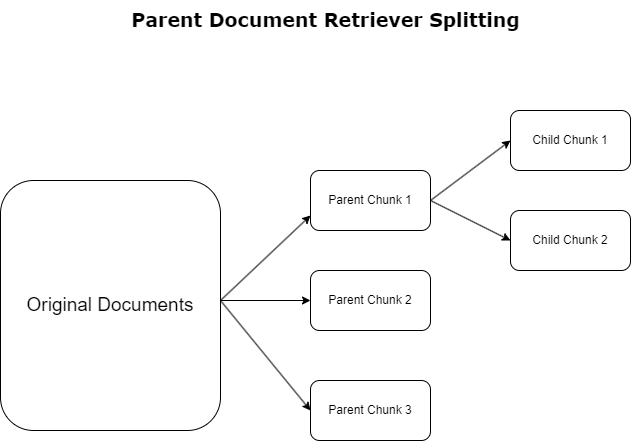
מאחזר מסמכי הורה
בסעיף הקודם הדגשנו אתגרים בהם נתקלות בקשות RAG כאשר הן מתמודדות עם מסמכים נרחבים. כדי להתמודד עם האתגרים הללו, מאחזרי מסמכי אב לסווג ולהגדיר מסמכים נכנסים כ מסמכי הורה. מסמכים אלו מוכרים בשל אופיים המקיף אך אינם מנוצלים ישירות בצורתם המקורית להטמעות. במקום לדחוס מסמך שלם להטמעה אחת, מאחזרי מסמכי אב מנתחים את מסמכי האב הללו ל מסמכי ילד. כל מסמך צאצא לוכד היבטים או נושאים שונים ממסמך האב הרחב יותר. לאחר הזיהוי של מקטעי ילד אלה, מוקצות לכל אחד הטמעות בודדות, לוכדות את המהות התמטית הספציפית שלהם (ראה את התרשים הבא). במהלך השליפה, מסמך האב מופעל. טכניקה זו מספקת יכולות חיפוש ממוקדות אך רחבות טווח, ומספקת ל-LLM פרספקטיבה רחבה יותר. מאחזרי מסמכי אב מספקים ל-LLM יתרון כפול: הספציפיות של הטבעת מסמכים ילדים לאחזור מידע מדויק ורלוונטי, יחד עם הפניה של מסמכי אב להפקת תגובה, מה שמעשיר את הפלטים של ה-LLM בהקשר מרובד ויסודי.
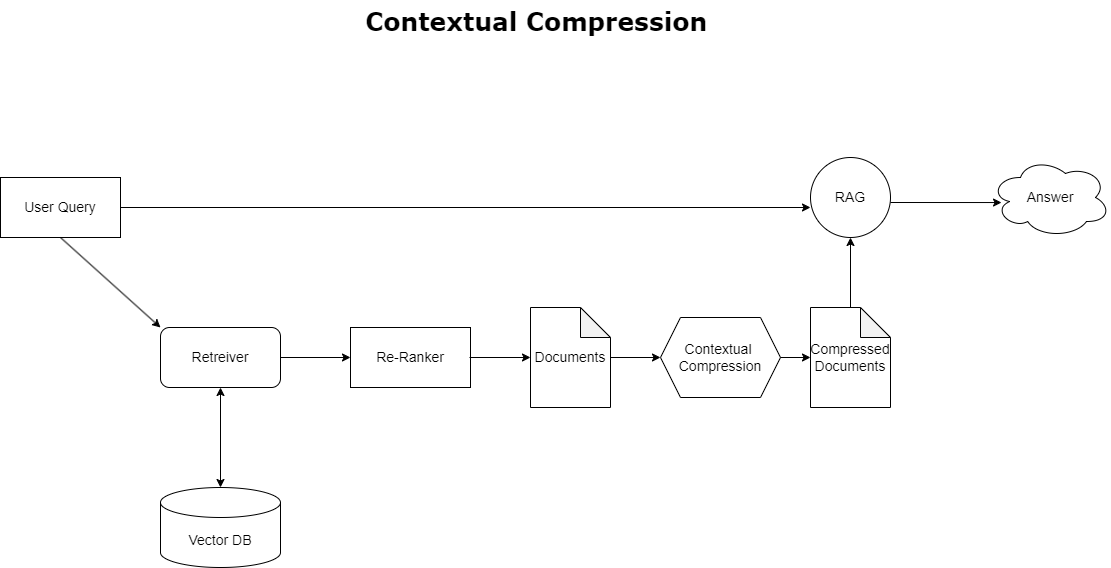
דחיסה קונטקסטואלית
כדי לטפל בסוגיית הצפת ההקשר שנדונה קודם לכן, אתה יכול להשתמש דחיסה הקשרית לדחוס ולסנן את המסמכים שאוחזרו בהתאם להקשר של השאילתה, כך שרק מידע רלוונטי נשמר ומעובד. הדבר מושג באמצעות שילוב של אחזור בסיס לאחזור מסמכים ראשוני ומדחס מסמכים לחידוד מסמכים אלה על ידי פירוק התוכן שלהם או אי הכללתם לחלוטין על סמך רלוונטיות, כפי שמודגם בתרשים הבא. גישה יעילה זו, המונחת על ידי אחזור הדחיסה ההקשרי, משפרת מאוד את יעילות יישומי RAG על ידי מתן שיטה לחילוץ וניצול רק מה שחיוני ממסה של מידע. היא מתמודדת חזיתית עם סוגיית עומס המידע ועיבוד נתונים לא רלוונטיים, מה שמוביל לשיפור איכות התגובה, פעולות LLM חסכוניות יותר ותהליך אחזור כולל חלק יותר. בעיקרו של דבר, זהו מסנן שמתאים את המידע לשאילתה הנידונה, מה שהופך אותו לכלי נחוץ עבור מפתחים שמטרתם לייעל את יישומי RAG שלהם לביצועים טובים יותר ולשביעות רצון משתמשים.
תנאים מוקדמים
אם אתה חדש ב- SageMaker, עיין ב- מדריך הפיתוח של אמזון SageMaker.
לפני שתתחיל עם הפתרון, ליצור חשבון AWS. כאשר אתה יוצר חשבון AWS, אתה מקבל זהות כניסה יחידה (SSO) בעלת גישה מלאה לכל השירותים והמשאבים של AWS בחשבון. זהות זו נקראת חשבון AWS משתמש שורש.
כניסה ל- קונסולת הניהול של AWS שימוש בכתובת הדואר האלקטרוני והסיסמה שבהם השתמשת ליצירת החשבון מעניק לך גישה מלאה לכל משאבי ה-AWS בחשבון שלך. אנו ממליצים בחום לא להשתמש במשתמש השורש למשימות יומיומיות, אפילו לא הניהוליות.
במקום זאת, היצמד ל- שיטות עבודה מומלצות לביטחון in AWS זהות וניהול גישה (IAM), ו ליצור משתמש וקבוצה מנהלתיים. לאחר מכן נעל בצורה מאובטחת את אישורי משתמש השורש והשתמש בהם לביצוע רק כמה משימות ניהול חשבון ושירות.
דגם Mixtral-8x7b דורש מופע ml.g5.48xlarge. SageMaker JumpStart מספק דרך פשוטה לגשת ולפרוס למעלה מ-100 מודלים שונים של קוד פתוח ושל צד שלישי. כדי השקת נקודת קצה לאירוח Mixtral-8x7B מ- SageMaker JumpStart, ייתכן שתצטרך לבקש הגדלת מכסת שירות כדי לגשת למופע ml.g5.48xlarge לשימוש בנקודת קצה. אתה יכול לבקש הגדלת מכסת שירות דרך הקונסולה, ממשק שורת הפקודה של AWS (AWS CLI), או API כדי לאפשר גישה למשאבים נוספים אלה.
הגדר מופע מחברת SageMaker והתקן תלות
כדי להתחיל, צור מופע מחברת SageMaker והתקן את התלות הנדרשת. עיין ב GitHub ריפו כדי להבטיח הגדרה מוצלחת. לאחר שתגדיר את מופע המחברת, תוכל לפרוס את המודל.
אתה יכול גם להפעיל את המחברת באופן מקומי בסביבת הפיתוח המשולבת המועדפת עליך (IDE). ודא שהתקנת את מעבדת המחברת Jupyter.
פרוס את הדגם
פרוס את דגם Mixtral-8X7B Instruct LLM ב- SageMaker JumpStart:
פרוס את מודל ההטמעה של BGE Large En ב- SageMaker JumpStart:
הגדר את LangChain
לאחר ייבוא כל הספריות הדרושות ופריסה של דגם Mixtral-8x7B ודגם BGE Large En embeddings, כעת תוכל להגדיר את LangChain. להוראות שלב אחר שלב, עיין ב- GitHub ריפו.
הכנת נתונים
בפוסט זה, אנו משתמשים בכמה שנים במכתבים של אמזון לבעלי מניות כקורפוס טקסט לביצוע QnA עליו. לשלבים מפורטים יותר להכנת הנתונים, עיין ב- GitHub ריפו.
תשובת שאלה
לאחר הכנת הנתונים, אתה יכול להשתמש במעטפת שסופקה על ידי LangChain, העוטפת את מאגר הווקטורים ולוקחת קלט עבור ה-LLM. עטיפה זו מבצעת את השלבים הבאים:
- קח את שאלת הקלט.
- צור הטמעת שאלה.
- אחזר מסמכים רלוונטיים.
- שלבו את המסמכים והשאלה בהנחיה.
- הפעל את המודל עם ההנחיה והפק את התשובה באופן קריא.
כעת, כשהחנות הוקטורית קיימת, אתה יכול להתחיל לשאול שאלות:
שרשרת רטריבר רגילה
בתרחיש הקודם, חקרנו את הדרך המהירה והפשוטה לקבל תשובה מודעת הקשר לשאלתך. כעת נסתכל על אפשרות הניתנת להתאמה אישית יותר בעזרת RetrievalQA, שבה ניתן להתאים אישית כיצד המסמכים שאוחזרו צריכים להתווסף להנחיה באמצעות הפרמטר chain_type. כמו כן, על מנת לשלוט בכמה מסמכים רלוונטיים יש לאחזר, ניתן לשנות את הפרמטר k בקוד הבא כדי לראות פלטים שונים. בתרחישים רבים, אולי תרצה לדעת באילו מסמכי מקור השתמש ה-LLM כדי ליצור את התשובה. אתה יכול לקבל את המסמכים האלה בפלט באמצעות return_source_documents, אשר מחזירה את המסמכים שנוספו להקשר של הנחיה LLM. RetrievalQA גם מאפשר לך לספק תבנית הנחיה מותאמת אישית שיכולה להיות ספציפית לדגם.
בוא נשאל שאלה:
שרשרת מסמכי אב
בואו נסתכל על אפשרות RAG מתקדמת יותר בעזרת ParentDocumentRetriever. כשאתה עובד עם אחזור מסמכים, אתה עלול להיתקל בהחלפה בין אחסון נתחים קטנים של מסמך להטמעות מדויקות לבין מסמכים גדולים יותר כדי לשמר יותר הקשר. מאחזר המסמכים האב משיג את האיזון הזה על ידי פיצול ואחסון של נתחים קטנים של נתונים.
אנו משתמשים ב- parent_splitter לחלק את המסמכים המקוריים לנתחים גדולים יותר הנקראים מסמכי אב וא child_splitter כדי ליצור מסמכי צאצא קטנים יותר מהמסמכים המקוריים:
לאחר מכן, מסמכי הצאצא מתווספים לאינדקס בחנות וקטורית באמצעות הטמעות. זה מאפשר אחזור יעיל של מסמכי צאצא רלוונטיים בהתבסס על דמיון. כדי לאחזר מידע רלוונטי, מאחזר המסמכים האב מביא תחילה את מסמכי הצאצא מחנות הווקטור. לאחר מכן, הוא מחפש את מזהי האב עבור מסמכי הצאצא ומחזיר את מסמכי האב הגדולים יותר המתאימים.
בוא נשאל שאלה:
שרשרת דחיסה קונטקסטואלית
בואו נסתכל על עוד אפשרות RAG מתקדמת שנקראת דחיסה הקשרית. אתגר אחד באחזור הוא שבדרך כלל איננו יודעים את השאילתות הספציפיות שתעמוד בפני מערכת אחסון המסמכים שלך כאשר אתה מכניס נתונים למערכת. המשמעות היא שהמידע הרלוונטי ביותר לשאילתה עשוי להיקבר במסמך עם הרבה טקסט לא רלוונטי. העברת המסמך המלא דרך האפליקציה שלך יכולה להוביל לשיחות LLM יקרות יותר ולתגובות גרועות יותר.
מאחזר הדחיסה ההקשרי נותן מענה לאתגר של אחזור מידע רלוונטי ממערכת אחסון מסמכים, שבה הנתונים הרלוונטיים עשויים להיקבר בתוך מסמכים המכילים הרבה טקסט. על ידי דחיסה וסינון של המסמכים שאוחזרו בהתבסס על הקשר השאילתה הנתון, מוחזר רק המידע הרלוונטי ביותר.
כדי להשתמש ב-Contextual Compression Retriever, תזדקק ל:
- רטריבר בסיס – זהו הרטריבר הראשוני שמביא מסמכים ממערכת האחסון בהתבסס על השאילתה
- מדחס מסמכים – רכיב זה לוקח את המסמכים שאוחזרו לראשונה ומקצר אותם על ידי צמצום התוכן של מסמכים בודדים או ביטול כליל של מסמכים לא רלוונטיים, תוך שימוש בהקשר השאילתה כדי לקבוע רלוונטיות
הוספת דחיסה הקשרית עם מחלץ שרשרת LLM
ראשית, עטפו את הבסיס רטריבר עם א ContextualCompressionRetriever. אתה תוסיף LLMChainExtractor, אשר יחזרו על המסמכים שהוחזרו בתחילה ויחלץ מכל אחד רק את התוכן הרלוונטי לשאילתה.
אתחול השרשרת באמצעות ContextualCompressionRetriever עם LLMChainExtractor והעבירו את ההנחיה דרך ה chain_type_kwargs ויכוח.
בוא נשאל שאלה:
סינון מסמכים עם מסנן שרשרת LLM
אל האני LLMChainFilter הוא מדחס מעט פשוט יותר אך חזק יותר שמשתמש בשרשרת LLM כדי להחליט אילו מהמסמכים שאוחזרו תחילה לסנן ואיזה להחזיר, מבלי לעשות מניפולציות על תוכן המסמך:
אתחול השרשרת באמצעות ContextualCompressionRetriever עם LLMChainFilter והעבירו את ההנחיה דרך ה chain_type_kwargs ויכוח.
בוא נשאל שאלה:
השוו תוצאות
הטבלה הבאה משווה תוצאות משאילתות שונות על סמך טכניקה.
| טכניקה | שאילתה 1 | שאילתה 2 | השוואה |
| איך AWS התפתחה? | למה אמזון מצליחה? | ||
| פלט שרשרת רטריבר רגיל | AWS (Amazon Web Services) התפתחה מהשקעה לא רווחית בתחילה לעסק בשיעור הכנסות שנתי של 85 מיליארד דולר עם רווחיות חזקה, המציעה מגוון רחב של שירותים ותכונות, והפכה לחלק משמעותי מהפורטפוליו של אמזון. למרות הספקנות ונגד הרוח הנגדית לטווח הקצר, AWS המשיכה לחדש, למשוך לקוחות חדשים ולהגר לקוחות פעילים, והציעה יתרונות כמו זריזות, חדשנות, עלות-יעילות ואבטחה. AWS גם הרחיבה את ההשקעות ארוכות הטווח שלה, כולל פיתוח שבבים, כדי לספק יכולות חדשות ולשנות את מה שאפשרי ללקוחותיה. | אמזון מצליחה בזכות החדשנות וההתרחבות המתמשכת שלה לתחומים חדשים כמו שירותי תשתית טכנולוגית, מכשירי קריאה דיגיטליים, עוזרים אישיים מונעי קול ומודלים עסקיים חדשים כמו שוק הצד השלישי. גם יכולתה להרחיב את הפעילות במהירות, כפי שניתן לראות בהתרחבות המהירה של רשתות ההגשמה והתחבורה שלה, תורמת להצלחתה. בנוסף, ההתמקדות של אמזון באופטימיזציה ורווחי יעילות בתהליכים הביאה לשיפורי פרודוקטיביות והפחתת עלויות. הדוגמה של אמזון ביזנס מדגישה את יכולתה של החברה למנף את חוזקות המסחר האלקטרוני והלוגיסטיקה שלה במגזרים שונים. | בהתבסס על התגובות של שרשרת הרטריבר הרגילה, אנו מבחינים כי למרות שהיא מספקת תשובות ארוכות, היא סובלת מהצפת הקשר ואינה מצליחה להזכיר שום פרט משמעותי מהקורפוס בכל הקשור למענה לשאילתה שסופקה. שרשרת האחזור הרגילה אינה מסוגלת ללכוד את הניואנסים עם עומק או תובנה הקשרית, ועלולה להחמיץ היבטים קריטיים של המסמך. |
| פלט אחזור מסמכי אב | AWS (Amazon Web Services) התחילה עם השקה ראשונית ירודה בתכונות של שירות Elastic Compute Cloud (EC2) בשנת 2006, המספקת רק גודל מופע אחד, במרכז נתונים אחד, באזור אחד בעולם, עם מופעי מערכת הפעלה לינוקס בלבד , וללא תכונות מפתח רבות כמו ניטור, איזון עומסים, קנה מידה אוטומטי או אחסון מתמשך. עם זאת, ההצלחה של AWS אפשרה להם לחזור ולהוסיף במהירות את היכולות החסרות, ולבסוף להתרחב ולהציע טעמים, גדלים ואופטימיזציות שונות של מחשוב, אחסון ורשתות, כמו גם לפתח שבבים משלהם (Graviton) כדי לדחוף את המחיר והביצועים עוד יותר. . תהליך החדשנות האיטרטיבי של AWS הצריך השקעות משמעותיות במשאבים פיננסיים ואנשים במשך 20 שנה, לרוב הרבה לפני מועד התשלום, כדי לענות על צורכי הלקוחות ולשפר את חוויות הלקוחות, הנאמנות והתשואות לבעלי המניות לטווח ארוך. | אמזון מצליחה בזכות יכולתה לחדש כל הזמן, להסתגל לתנאי השוק המשתנים ולענות על צרכי הלקוחות בפלחי שוק שונים. זה ניכר בהצלחתה של אמזון ביזנס, שגדלה להניב כ-35 מיליארד דולר במכירות ברוטו שנתיות על ידי אספקת מבחר, ערך ונוחות ללקוחות עסקיים. ההשקעות של אמזון ביכולות מסחר אלקטרוני ולוגיסטיקה אפשרו גם יצירת שירותים כמו Buy with Prime, שעוזר לסוחרים עם אתרים ישירות לצרכן להניע המרה מצפיות לרכישות. | מאחזר המסמכים האב מעמיק את הפרטים הספציפיים של אסטרטגיית הצמיחה של AWS, כולל התהליך האיטרטיבי של הוספת תכונות חדשות המבוססות על משוב מלקוחות והמסע המפורט מהשקה ראשונית חסרת תכונות לעמדת שוק דומיננטית, תוך מתן מענה עשיר בהקשר. . התגובות מכסות מגוון רחב של היבטים, החל מחידושים טכניים ואסטרטגיית שוק ועד ליעילות ארגונית ומיקוד בלקוחות, ומספקות ראייה הוליסטית של הגורמים התורמים להצלחה יחד עם דוגמאות. ניתן לייחס זאת ליכולות החיפוש הממוקדות אך רחבות הטווח של מאחזר המסמכים האב. |
| LLM Chain Extractor: פלט דחיסה קונטקסטואלית | AWS התפתחה על ידי התחלה כפרויקט קטן בתוך אמזון, הדורש השקעת הון משמעותית והתמודדות עם ספקנות הן בתוך החברה והן מחוצה לה. עם זאת, ל-AWS הייתה התחלה של מתחרים פוטנציאליים והאמינה בערך שהיא יכולה להביא ללקוחות ולאמזון. AWS התחייבה לטווח ארוך להמשיך ולהשקיע, והביאה ליותר מ-3,300 תכונות ושירותים חדשים שהושקו בשנת 2022. AWS שינתה את האופן שבו לקוחות מנהלים את התשתית הטכנולוגית שלהם והפכה לעסק בקצב הכנסה שנתי של 85 מיליארד דולר עם רווחיות חזקה. AWS גם שיפרה ללא הרף את ההיצע שלה, כמו שיפור EC2 עם תכונות ושירותים נוספים לאחר ההשקה הראשונית שלו. | בהתבסס על ההקשר המסופק, ניתן לייחס את הצלחתה של אמזון להתרחבותה האסטרטגית מפלטפורמת מכירת ספרים לשוק גלובלי עם מערכת אקולוגית תוססת של מוכרים של צד שלישי, השקעה מוקדמת ב-AWS, חדשנות בהחדרת ה-Kindle וה-Alexa וצמיחה משמעותית. בהכנסה שנתית מ-2019 עד 2022. צמיחה זו הובילה להרחבת טביעת הרגל של מרכז ההגשמה, יצירת רשת תחבורה של מייל אחרון, ובניית רשת מרכזי מיון חדשה, שעברו אופטימיזציה לפריון והפחתת עלויות. | מחלץ השרשרת LLM שומר על איזון בין כיסוי מקיף של נקודות מפתח לבין הימנעות מעומק מיותר. הוא מתאים באופן דינמי להקשר של השאילתה, כך שהפלט רלוונטי ומקיף ישירות. |
| מסנן שרשרת LLM: פלט דחיסה קונטקסטואלית | AWS (שירותי אינטרנט של אמזון) התפתחה על ידי השקה תחילה דל בתכונות אך חוזרת במהירות בהתבסס על משוב לקוחות כדי להוסיף את היכולות הנחוצות. גישה זו אפשרה ל-AWS להשיק את EC2 בשנת 2006 עם תכונות מוגבלות ולאחר מכן להוסיף פונקציונליות חדשות ללא הרף, כגון גדלי מופעים נוספים, מרכזי נתונים, אזורים, אפשרויות מערכת הפעלה, כלי ניטור, איזון עומסים, קנה מידה אוטומטי ואחסון מתמשך. עם הזמן, AWS הפכה משירות דל בתכונות לעסק של מיליארדי דולרים על ידי התמקדות בצרכי הלקוח, זריזות, חדשנות, עלות יעילות ואבטחה. ל-AWS יש כעת קצב הכנסות שנתי של 85 מיליארד דולר ומציעה למעלה מ-3,300 תכונות ושירותים חדשים מדי שנה, המספקים מגוון רחב של לקוחות מסטארט-אפים ועד חברות רב לאומיות וארגונים במגזר הציבורי. | אמזון מצליחה בזכות המודלים העסקיים החדשניים שלה, התקדמות טכנולוגית מתמשכת ושינויים ארגוניים אסטרטגיים. החברה שיבשה בעקביות תעשיות מסורתיות על ידי הצגת רעיונות חדשים, כגון פלטפורמת מסחר אלקטרוני עבור מוצרים ושירותים שונים, שוק של צד שלישי, שירותי תשתית ענן (AWS), ה-Kindle e-reader והעוזר האישי המונע הקולי של Alexa . בנוסף, אמזון ביצעה שינויים מבניים כדי לשפר את היעילות שלה, כגון ארגון מחדש של רשת המימוש בארה"ב שלה כדי להפחית עלויות וזמני אספקה, מה שתרם עוד יותר להצלחתה. | בדומה למחלץ שרשרת LLM, מסנן שרשרת LLM מוודא שלמרות שנקודות המפתח מכוסות, הפלט יעיל עבור לקוחות המחפשים תשובות תמציתיות והקשריות. |
בהשוואה של טכניקות שונות אלו, אנו יכולים לראות שבהקשרים כמו פירוט המעבר של AWS משירות פשוט לישות מורכבת של מיליארדי דולרים, או הסבר על ההצלחות האסטרטגיות של אמזון, רשת הרטריבר הרגילה חסרה את הדיוק שהטכניקות המתוחכמות יותר מציעות, מה שמוביל למידע פחות ממוקד. למרות שמעט מאוד הבדלים נראים בין הטכניקות המתקדמות שנדונו, הם הרבה יותר אינפורמטיביים מרשתות רטריבר רגילות.
עבור לקוחות בתעשיות כמו בריאות, טלקומוניקציה ושירותים פיננסיים המחפשים ליישם RAG ביישומים שלהם, המגבלות של שרשרת הרטריבר הרגילה באספקת דיוק, הימנעות מיותרות ודחיסת מידע יעילה הופכות אותה לפחות מתאימה למילוי צרכים אלה בהשוואה לשחזור מסמכי האב המתקדם יותר וטכניקות דחיסה קונטקסטואלית. טכניקות אלה מסוגלות לזקק כמויות עצומות של מידע לתוך התובנות המרוכזות והמשפיעות שאתה צריך, תוך כדי שיפור ביצועי המחיר.
לנקות את
כשתסיים להפעיל את המחברת, מחק את המשאבים שיצרת כדי למנוע צבירת חיובים עבור המשאבים שבשימוש:
סיכום
בפוסט זה הצגנו פתרון המאפשר לך ליישם את אחזור המסמכים האב וטכניקות שרשרת הדחיסה ההקשרית כדי לשפר את היכולת של LLMs לעבד ולהפיק מידע. בדקנו את טכניקות ה-RAG המתקדמות הללו עם הדגמים Mixtral-8x7B Instruct ו-BGE Large En הזמינים עם SageMaker JumpStart. בדקנו גם שימוש באחסון מתמשך להטמעות ונתחי מסמכים ושילוב עם מאגרי מידע ארגוניים.
הטכניקות שביצענו לא רק משכללות את הדרך שבה מודלים של LLM ניגשים ומשלבים ידע חיצוני, אלא גם משפרות משמעותית את האיכות, הרלוונטיות והיעילות של התפוקות שלהם. על ידי שילוב של שליפה מגופי טקסט גדולים עם יכולות יצירת שפה, טכניקות RAG מתקדמות אלה מאפשרות ל-LLMs לייצר תגובות עובדתיות יותר, קוהרנטיות ומתאימות להקשר, ולשפר את הביצועים שלהם במשימות שונות של עיבוד שפה טבעית.
SageMaker JumpStart עומד במרכז הפתרון הזה. עם SageMaker JumpStart, אתה מקבל גישה למבחר נרחב של מודלים של קוד פתוח וסגור, מייעל את תהליך ההתחלה עם ML ומאפשר ניסויים ופריסה מהירים. כדי להתחיל בפריסת פתרון זה, נווט אל המחברת ב- GitHub ריפו.
על הכותבים
 Niithiyn Vijeaswaran הוא אדריכל פתרונות ב-AWS. תחום המיקוד שלו הוא AI גנרטיבי ו-AWS AI Accelerators. בעל תואר ראשון במדעי המחשב וביואינפורמטיקה. Niithiyn עובדת בשיתוף פעולה הדוק עם צוות Generative AI GTM כדי לאפשר ללקוחות AWS בחזיתות מרובות ולהאיץ את האימוץ שלהם של AI גנרטיבי. הוא מעריץ נלהב של דאלאס מאבריקס ונהנה לאסוף נעלי ספורט.
Niithiyn Vijeaswaran הוא אדריכל פתרונות ב-AWS. תחום המיקוד שלו הוא AI גנרטיבי ו-AWS AI Accelerators. בעל תואר ראשון במדעי המחשב וביואינפורמטיקה. Niithiyn עובדת בשיתוף פעולה הדוק עם צוות Generative AI GTM כדי לאפשר ללקוחות AWS בחזיתות מרובות ולהאיץ את האימוץ שלהם של AI גנרטיבי. הוא מעריץ נלהב של דאלאס מאבריקס ונהנה לאסוף נעלי ספורט.
 סבסטיאן בסטילו הוא אדריכל פתרונות ב-AWS. הוא מתמקד בטכנולוגיות AI/ML עם תשוקה עמוקה לבינה מלאכותית ומאיצי מחשוב. ב-AWS, הוא עוזר ללקוחות לפתוח ערך עסקי באמצעות בינה מלאכותית. כשהוא לא בעבודה, הוא נהנה לבשל כוס קפה מיוחדת ולחקור את העולם עם אשתו.
סבסטיאן בסטילו הוא אדריכל פתרונות ב-AWS. הוא מתמקד בטכנולוגיות AI/ML עם תשוקה עמוקה לבינה מלאכותית ומאיצי מחשוב. ב-AWS, הוא עוזר ללקוחות לפתוח ערך עסקי באמצעות בינה מלאכותית. כשהוא לא בעבודה, הוא נהנה לבשל כוס קפה מיוחדת ולחקור את העולם עם אשתו.
 ארמנדו דיאז הוא אדריכל פתרונות ב-AWS. הוא מתמקד בבינה מלאכותית, AI/ML וניתוח נתונים. ב-AWS, Armando מסייעת ללקוחות לשלב יכולות בינה מלאכותית מתקדמות במערכות שלהם, תוך טיפוח חדשנות ויתרון תחרותי. כשהוא לא בעבודה, הוא נהנה לבלות עם אשתו ומשפחתו, לטייל ולטייל בעולם.
ארמנדו דיאז הוא אדריכל פתרונות ב-AWS. הוא מתמקד בבינה מלאכותית, AI/ML וניתוח נתונים. ב-AWS, Armando מסייעת ללקוחות לשלב יכולות בינה מלאכותית מתקדמות במערכות שלהם, תוך טיפוח חדשנות ויתרון תחרותי. כשהוא לא בעבודה, הוא נהנה לבלות עם אשתו ומשפחתו, לטייל ולטייל בעולם.
 ד"ר פארוק סאביר הוא ארכיטקט פתרונות בכיר בבינה מלאכותית ולמידת מכונה ב-AWS. הוא בעל תואר דוקטור ותואר שני בהנדסת חשמל מאוניברסיטת טקסס באוסטין ותואר שני במדעי המחשב מהמכון הטכנולוגי של ג'ורג'יה. יש לו למעלה מ-15 שנות ניסיון בעבודה וגם אוהב ללמד ולהדריך סטודנטים. ב-AWS הוא עוזר ללקוחות לגבש ולפתור את הבעיות העסקיות שלהם במדעי הנתונים, למידת מכונה, ראייה ממוחשבת, בינה מלאכותית, אופטימיזציה מספרית ותחומים קשורים. ממוקם בדאלאס, טקסס, הוא ומשפחתו אוהבים לטייל ולצאת לנסיעות ארוכות.
ד"ר פארוק סאביר הוא ארכיטקט פתרונות בכיר בבינה מלאכותית ולמידת מכונה ב-AWS. הוא בעל תואר דוקטור ותואר שני בהנדסת חשמל מאוניברסיטת טקסס באוסטין ותואר שני במדעי המחשב מהמכון הטכנולוגי של ג'ורג'יה. יש לו למעלה מ-15 שנות ניסיון בעבודה וגם אוהב ללמד ולהדריך סטודנטים. ב-AWS הוא עוזר ללקוחות לגבש ולפתור את הבעיות העסקיות שלהם במדעי הנתונים, למידת מכונה, ראייה ממוחשבת, בינה מלאכותית, אופטימיזציה מספרית ותחומים קשורים. ממוקם בדאלאס, טקסס, הוא ומשפחתו אוהבים לטייל ולצאת לנסיעות ארוכות.
 מרקו פוניו הוא ארכיטקט פתרונות המתמקד באסטרטגיית בינה מלאכותית, פתרונות בינה מלאכותית יישומית וביצוע מחקרים כדי לעזור ללקוחות להרחיב קנה מידה ב-AWS. מרקו הוא יועץ ענן מקורי דיגיטלי עם ניסיון בפינטק, בריאות ומדעי החיים, תוכנה כשירות ולאחרונה בתעשיות טלקומוניקציה. הוא טכנולוג מוסמך עם תשוקה ללמידת מכונה, בינה מלאכותית ומיזוגים ורכישות. מרקו יושב בסיאטל, וושינגטון ונהנה לכתוב, לקרוא, להתאמן ולבנות יישומים בזמנו הפנוי.
מרקו פוניו הוא ארכיטקט פתרונות המתמקד באסטרטגיית בינה מלאכותית, פתרונות בינה מלאכותית יישומית וביצוע מחקרים כדי לעזור ללקוחות להרחיב קנה מידה ב-AWS. מרקו הוא יועץ ענן מקורי דיגיטלי עם ניסיון בפינטק, בריאות ומדעי החיים, תוכנה כשירות ולאחרונה בתעשיות טלקומוניקציה. הוא טכנולוג מוסמך עם תשוקה ללמידת מכונה, בינה מלאכותית ומיזוגים ורכישות. מרקו יושב בסיאטל, וושינגטון ונהנה לכתוב, לקרוא, להתאמן ולבנות יישומים בזמנו הפנוי.
 AJ Dhimine הוא אדריכל פתרונות ב-AWS. הוא מתמחה ב-AI גנרטיבי, מחשוב ללא שרתים וניתוח נתונים. הוא חבר/מנטור פעיל בקהילת השדה הטכני של למידת מכונה ופרסם מספר מאמרים מדעיים בנושאי AI/ML שונים. הוא עובד עם לקוחות, החל מסטארט-אפים ועד ארגונים, כדי לפתח פתרונות AI גנרטיביים של AWSome. הוא נלהב במיוחד למינוף מודלים של שפה גדולה לניתוח נתונים מתקדם ולחקור יישומים מעשיים הנותנים מענה לאתגרים בעולם האמיתי. מחוץ לעבודה, AJ נהנית לטייל, ונמצאת כיום ב-53 מדינות במטרה לבקר בכל מדינה בעולם.
AJ Dhimine הוא אדריכל פתרונות ב-AWS. הוא מתמחה ב-AI גנרטיבי, מחשוב ללא שרתים וניתוח נתונים. הוא חבר/מנטור פעיל בקהילת השדה הטכני של למידת מכונה ופרסם מספר מאמרים מדעיים בנושאי AI/ML שונים. הוא עובד עם לקוחות, החל מסטארט-אפים ועד ארגונים, כדי לפתח פתרונות AI גנרטיביים של AWSome. הוא נלהב במיוחד למינוף מודלים של שפה גדולה לניתוח נתונים מתקדם ולחקור יישומים מעשיים הנותנים מענה לאתגרים בעולם האמיתי. מחוץ לעבודה, AJ נהנית לטייל, ונמצאת כיום ב-53 מדינות במטרה לבקר בכל מדינה בעולם.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

