מודלים של שפה גדולה (LLMs) מאומנים בדרך כלל על מערכי נתונים גדולים זמינים לציבור שהם אגנוסטיים לתחום. לדוגמה, הלאמה של מטא מודלים מאומנים על מערכי נתונים כגון CommonCrawl, C4, ויקיפדיה ו ArXiv. מערכי נתונים אלה מקיפים מגוון רחב של נושאים ותחומים. למרות שהמודלים המתקבלים מניבים תוצאות טובות להפליא עבור משימות כלליות, כגון יצירת טקסט וזיהוי ישויות, יש ראיות לכך שמודלים מאומנים עם מערכי נתונים ספציפיים לתחום יכולים לשפר עוד יותר את ביצועי LLM. לדוגמה, נתוני האימון המשמשים עבור BloombergGPT הוא 51% מסמכים ספציפיים לדומיין, כולל חדשות פיננסיות, הגשות וחומרים פיננסיים אחרים. ה-LLM שהתקבל עולה על ביצועי ה-LLM שהוכשרו על מערכי נתונים שאינם ספציפיים לתחום, כאשר נבדק על משימות ספציפיות לכספים. המחברים של BloombergGPT הגיעו למסקנה שהמודל שלהם עולה על כל המודלים האחרים שנבדקו עבור ארבע מתוך חמש המשימות הפיננסיות. המודל סיפק ביצועים טובים עוד יותר כאשר נבחן עבור המשימות הפיננסיות הפנימיות של בלומברג בהפרש גדול - עד 60 נקודות טובות יותר (מתוך 100). למרות שאתה יכול ללמוד עוד על תוצאות ההערכה המקיפות ב- מאמר, הדוגמה הבאה שנלכדה מה- BloombergGPT נייר יכול לתת לך הצצה לתועלת שבהכשרת אנשי LLM באמצעות נתונים ספציפיים לתחום פיננסי. כפי שמוצג בדוגמה, מודל BloombergGPT סיפק תשובות נכונות בעוד שמודלים אחרים שאינם ספציפיים לתחום התקשו:
פוסט זה מספק מדריך להכשרת לימודי LLM במיוחד עבור התחום הפיננסי. אנו מכסים את התחומים המרכזיים הבאים:
- איסוף נתונים והכנה – הדרכה לגבי חיפוש ואצירת נתונים פיננסיים רלוונטיים להכשרת מודלים יעילה
- אימון מקדים מתמשך לעומת כוונון עדין - מתי להשתמש בכל טכניקה כדי לייעל את ביצועי ה-LLM שלך
- אימון מקדים מתמשך יעיל – אסטרטגיות לייעל את תהליך ההכשרה המתמשך, תוך חיסכון בזמן ומשאבים
פוסט זה מפגיש את המומחיות של צוות המחקר המדע היישומי בתוך Amazon Finance Technology וצוות המומחים העולמי של AWS לתעשייה הפיננסית העולמית. חלק מהתוכן מבוסס על הנייר אימון מקדים מתמשך יעיל לבניית מודלים ספציפיים לתחום שפות גדולות.
איסוף והכנת נתוני כספים
אימון מקדים מתמשך לתחום מצריך מערך נתונים בקנה מידה גדול ואיכותי ספציפי לתחום. להלן השלבים העיקריים לאיסוף מערכי נתונים של דומיין:
- זיהוי מקורות נתונים - מקורות נתונים פוטנציאליים עבור קורפוס תחום כוללים אינטרנט פתוח, ויקיפדיה, ספרים, מדיה חברתית ומסמכים פנימיים.
- מסנני נתוני דומיין – מכיוון שהמטרה הסופית היא לאצור את קורפוס הדומיין, ייתכן שתצטרך ליישם שלבים נוספים כדי לסנן דגימות שאינן רלוונטיות לתחום היעד. זה מפחית קורפוס חסר תועלת לאימון מקדים מתמשך ומפחית את עלויות ההדרכה.
- עיבוד מוקדם - כדאי לשקול סדרה של שלבי עיבוד מקדים לשיפור איכות הנתונים ויעילות ההדרכה. לדוגמה, מקורות נתונים מסוימים יכולים להכיל מספר לא מבוטל של אסימונים רועשים; מניעת כפילויות נחשבת לצעד שימושי לשיפור איכות הנתונים ולהפחתת עלויות ההדרכה.
כדי לפתח LLMs פיננסיים, אתה יכול להשתמש בשני מקורות נתונים חשובים: News CommonCrawl ו-SEC הגשות. הגשת SEC היא דוח כספי או מסמך רשמי אחר המוגש לרשות ניירות הערך האמריקאית (SEC). חברות ציבוריות נדרשות להגיש מסמכים שונים באופן קבוע. זה יוצר מספר רב של מסמכים לאורך השנים. News CommonCrawl הוא מערך נתונים ששוחרר על ידי CommonCrawl בשנת 2016. הוא מכיל מאמרי חדשות מאתרי חדשות בכל רחבי העולם.
חדשות CommonCrawl זמין ב- שירות אחסון פשוט של אמזון (אמזון S3) ב- commoncrawl דלי ב crawl-data/CC-NEWS/. אתה יכול לקבל את רשימות הקבצים באמצעות ממשק שורת הפקודה של AWS (AWS CLI) והפקודה הבאה:
In אימון מקדים מתמשך יעיל לבניית מודלים ספציפיים לתחום שפות גדולות, המחברים משתמשים בגישה מבוססת URL ומילות מפתח כדי לסנן מאמרי חדשות פיננסיים מחדשות כלליות. באופן ספציפי, המחברים מנהלים רשימה של ערוצי חדשות פיננסיים חשובים וקבוצה של מילות מפתח הקשורות לחדשות פיננסיות. אנו מזהים מאמר כחדשות פיננסיות אם הוא מגיע מכלי חדשות פיננסיים או אם מילות מפתח כלשהן מופיעות בכתובת האתר. גישה פשוטה אך יעילה זו מאפשרת לך לזהות חדשות פיננסיות לא רק מאמצעי חדשות פיננסיים אלא גם מחלקי פיננסים של כלי חדשות כלליים.
הגשות SEC זמינות באופן מקוון דרך מסד הנתונים EDGAR (איסוף נתונים אלקטרוניים, ניתוח ואחזור) של ה-SEC, המספק גישה לנתונים פתוחים. אתה יכול לגרד את התיקים מ-EDGAR ישירות, או להשתמש בממשקי API אמזון SageMaker עם כמה שורות קוד, לכל פרק זמן ולמספר רב של טיקרים (כלומר, המזהה שהוקצה ל-SEC). למידע נוסף, עיין ב אחזור תיוק של SEC.
הטבלה הבאה מסכמת את הפרטים העיקריים של שני מקורות הנתונים.
| . | חדשות CommonCrawl | הגשת SEC |
| סיקור | 2016-2022 | 1993-2022 |
| מידה | 25.8 מיליארד מילים | 5.1 מיליארד מילים |
המחברים עוברים כמה שלבי עיבוד מקדים נוספים לפני שהנתונים מוזנים לאלגוריתם אימון. ראשית, אנו מבחינים כי מסמכי SEC מכילים טקסט רועש עקב הסרת טבלאות ואיורים, ולכן המחברים מסירים משפטים קצרים הנחשבים כתוויות טבלה או דמויות. שנית, אנו מיישמים אלגוריתם גיבוב רגיש למיקום כדי לבטל את הכפילות של המאמרים וההגשות החדשות. עבור הגשות SEC, אנו מבצעים ביטול כפילות ברמת הסעיף במקום ברמת המסמך. לבסוף, אנו משרשרים מסמכים למחרוזת ארוכה, מעבירים אותה לאסימונים ומחלקים את האסימון לפיסות באורך קלט מקסימלי הנתמך על ידי המודל שיש לאמן. זה משפר את התפוקה של אימון מקדים מתמשך ומפחית את עלות ההדרכה.
אימון מקדים מתמשך לעומת כוונון עדין
רוב ה-LLMs הזמינים הם למטרות כלליות וחסרות יכולות ספציפיות לתחום. לימודי LLM של תחום הראו ביצועים ניכרים בתחומים רפואיים, פיננסים או מדעיים. כדי ש-LLM ירכוש ידע ספציפי לתחום, ישנן ארבע שיטות: אימון מאפס, אימון מקדים מתמשך, כוונון עדין של הדרכה על משימות תחום ו-Retrieval Augmented Generation (RAG).
במודלים מסורתיים, כוונון עדין משמש בדרך כלל ליצירת מודלים ספציפיים למשימה עבור תחום. משמעות הדבר היא שמירה על מודלים מרובים עבור משימות מרובות כמו מיצוי ישויות, סיווג כוונות, ניתוח סנטימנטים או מענה לשאלות. עם הופעתן של לימודי LLM, הצורך לשמור על מודלים נפרדים התיישן על ידי שימוש בטכניקות כמו למידה בהקשר או הנחיה. זה חוסך את המאמץ הנדרש כדי לשמור על ערימה של מודלים עבור משימות קשורות אך שונות.
באופן אינטואיטיבי, אתה יכול לאמן LLMs מאפס עם נתונים ספציפיים לדומיין. למרות שרוב העבודה ליצירת LLMs בתחום התמקדה בהדרכה מאפס, היא יקרה באופן בלתי רגיל. לדוגמה, דגם GPT-4 עולה מעל $ 100 מיליון דולר לאמן. מודלים אלה מאומנים על שילוב של נתוני דומיין פתוח ונתוני דומיין. אימון מקדים מתמשך יכול לעזור למודלים לרכוש ידע ספציפי לתחום מבלי לשאת בעלות של אימון מקדים מאפס, מכיוון שאתה מכשיר מראש LLM של תחום פתוח קיים רק על נתוני התחום.
עם כוונון עדין של הוראות במשימה, אינך יכול לגרום למודל לרכוש ידע בתחום מכיוון שה-LLM רוכש רק מידע על דומיין הכלול במערך הנתונים לכוונון עדין של ההוראות. אלא אם כן נעשה שימוש במערך נתונים גדול מאוד לכוונון עדין של הוראה, זה לא מספיק כדי לרכוש ידע בתחום. רכישת מערכי נתונים באיכות גבוהה של הוראות היא בדרך כלל מאתגרת והיא הסיבה להשתמש ב-LLMs במקום הראשון. כמו כן, כוונון עדין של הוראות במשימה אחת יכול להשפיע על הביצועים במשימות אחרות (כפי שניתן לראות ב מאמר זה). עם זאת, כוונון עדין של הוראות הוא חסכוני יותר מכל אחת מהחלופות לפני ההכשרה.
האיור הבא משווה כוונון עדין מסורתי ספציפי למשימה. לעומת פרדיגמת למידה בתוך הקשר עם לימודי LLM.
 RAG היא הדרך היעילה ביותר להנחות LLM ליצור תגובות המבוססות על תחום. למרות שהוא יכול להנחות מודל ליצור תגובות על ידי מתן עובדות מהתחום כמידע עזר, הוא לא רוכש את השפה הספציפית לתחום מכיוון שה-LLM עדיין מסתמך על סגנון שפת לא-דומיין כדי ליצור את התגובות.
RAG היא הדרך היעילה ביותר להנחות LLM ליצור תגובות המבוססות על תחום. למרות שהוא יכול להנחות מודל ליצור תגובות על ידי מתן עובדות מהתחום כמידע עזר, הוא לא רוכש את השפה הספציפית לתחום מכיוון שה-LLM עדיין מסתמך על סגנון שפת לא-דומיין כדי ליצור את התגובות.
אימון מקדים מתמשך הוא דרך ביניים בין אימון מקדים לכיוונון הדרכה במונחים של עלות תוך כדי היותה אלטרנטיבה חזקה להשגת ידע וסגנון ספציפיים לתחום. זה יכול לספק מודל כללי שעליו ניתן לבצע כוונון הוראות נוסף על נתוני הוראות מוגבלים. אימון מקדים מתמשך יכול להיות אסטרטגיה חסכונית עבור תחומים מיוחדים שבהם מערך המשימות במורד הזרם גדול או לא ידוע ונתוני כוונון הוראות מסומנים מוגבלים. בתרחישים אחרים, כוונון עדין של הוראות או RAG עשוי להיות מתאים יותר.
למידע נוסף על כוונון עדין, RAG ואימון מודלים, עיין ב כוונן מודל יסוד, Generation Augmented של אחזור (RAG), ו אימון דגם עם Amazon SageMaker, בהתאמה. עבור פוסט זה, אנו מתמקדים באימון מקדים מתמשך יעיל.
מתודולוגיה של אימון מקדים מתמשך יעיל
אימון מקדים מתמשך מורכב מהמתודולוגיה הבאה:
- אימון מקדים מותאם לתחום (DACP) - בנייר אימון מקדים מתמשך יעיל לבניית מודלים ספציפיים לתחום שפות גדולות, המחברים מאמנים ללא הרף את חבילת מודל השפה של Pythia על הקורפוס הפיננסי כדי להתאים אותו לתחום הפיננסי. המטרה היא ליצור לימודי LLM פיננסיים על ידי הזנת נתונים מכל התחום הפיננסי למודל בקוד פתוח. מכיוון שקורפוס ההדרכה מכיל את כל מערכי הנתונים שנאספו בתחום, המודל המתקבל אמור לרכוש ידע ספציפי למימון, ובכך להפוך למודל רב-תכליתי למשימות פיננסיות שונות. זה מביא למודלים של FinPythia.
- אימון מקדים מותאם למשימות (TACP) - המחברים מאמנים את המודלים מראש על נתוני משימות מסומנים ובלתי מסומנים כדי להתאים אותם למשימות ספציפיות. בנסיבות מסוימות, מפתחים עשויים להעדיף מודלים המספקים ביצועים טובים יותר בקבוצה של משימות בדומיין במקום מודל כללי לתחום. TACP תוכנן כהכשרה מקדימה מתמשכת במטרה לשפר את הביצועים במשימות ממוקדות, ללא דרישות לנתונים מסומנים. ליתר דיוק, המחברים מאמנים כל הזמן מראש את המודלים במקור פתוח על אסימוני המשימות (ללא תוויות). המגבלה העיקרית של TACP נעוצה בבניית LLMs ספציפיים למשימה במקום LLMs יסודות, בשל השימוש הבלעדי בנתוני משימה ללא תווית להדרכה. למרות ש-DACP משתמש בקורפוס גדול בהרבה, הוא יקר באופן בלתי רגיל. כדי לאזן את המגבלות הללו, הכותבים מציעים שתי גישות שמטרתן לבנות LLM בסיס ספציפי לתחום תוך שמירה על ביצועים מעולים במשימות היעד:
- DACP יעיל למשימה דומה (ETS-DACP) - המחברים מציעים לבחור תת-קבוצה של קורפוס פיננסי הדומה מאוד לנתוני המשימה באמצעות דמיון הטמעה. תת-קבוצה זו משמשת לאימון מקדים מתמשך כדי להפוך אותה ליעילה יותר. באופן ספציפי, המחברים מאמנים ללא הרף את ה-LLM בקוד פתוח על קורפוס קטן המופק מהקורפוס הפיננסי הקרוב למשימות היעד בהפצה. זה יכול לעזור לשפר את ביצועי המשימות מכיוון שאנו מאמצים את המודל להפצה של אסימוני משימות למרות שאין צורך בנתונים מסומנים.
- DACP יעיל לאגנוסטית משימות (ETA-DACP) - המחברים מציעים להשתמש במדדים כמו תמיהה ואנטרופיה מסוג אסימון שאינם דורשים נתוני משימות כדי לבחור דוגמאות מהקורפוס הפיננסי לצורך אימון מקדים מתמשך יעיל. גישה זו נועדה להתמודד עם תרחישים שבהם נתוני משימות אינם זמינים או שמועדפים מודלים מגוונים יותר עבור התחום הרחב יותר. המחברים מאמצים שני מימדים לבחירת דגימות נתונים שחשובות להשגת מידע תחום מתת-קבוצה של נתוני תחום טרום אימון: חידוש וגיוון. חידוש, הנמדד על ידי התמיהה שנרשמה על ידי מודל היעד, מתייחס למידע שלא נראה על ידי ה-LLM קודם לכן. נתונים בעלי חידוש גבוה מצביעים על ידע חדש עבור ה-LLM, ונתונים כאלה נתפסים כקשים יותר ללמידה. זה מעדכן לימודי LLM גנריים עם ידע תחום אינטנסיבי במהלך אימון מקדים מתמשך. גיוון, לעומת זאת, לוכד את מגוון ההפצות של סוגי אסימונים בקורפוס התחום, אשר תועד כמאפיין שימושי במחקר של לימוד תוכניות לימודים על מודלים של שפות.
האיור הבא משווה דוגמה של ETS-DACP (משמאל) לעומת ETA-DACP (מימין).

אנו מאמצים שתי סכימות דגימה לבחירה אקטיבית של נקודות נתונים מהקורפוס הפיננסי שנאסף: דגימה קשה ודגימה רכה. הראשון נעשה על ידי דירוג תחילה של הקורפוס הפיננסי לפי מדדים מתאימים ולאחר מכן בחירת הדגימות העליון-k, כאשר k נקבע מראש בהתאם לתקציב ההכשרה. עבור האחרונים, המחברים מקצים משקלי דגימה עבור כל נקודות נתונים בהתאם לערכים המטריים, ולאחר מכן דוגמים באקראי k נקודות נתונים כדי לעמוד בתקציב האימון.
תוצאה וניתוח
המחברים מעריכים את ה-LLMs הפיננסיים המתקבלים על מגוון משימות פיננסיות כדי לחקור את היעילות של אימון מקדים מתמשך:
- בנק משפטים פיננסיים - משימת סיווג רגשות על חדשות פיננסיות.
- FiQA SA – משימת סיווג סנטימנטים מבוססת היבטים המבוססת על חדשות פיננסיות וכותרות.
- כותרת – משימת סיווג בינארי לגבי האם כותרת על ישות פיננסית מכילה מידע מסוים.
- נר – משימת מיצוי של ישות פיננסית המבוססת על סעיף הערכת סיכוני אשראי בדוחות SEC. מילים במשימה זו מסומנות ב-PER, LOC, ORG ו-MISC.
מכיוון שלימודי LLM פיננסיים מכוונים הוראות, המחברים מעריכים מודלים בהגדרה של 5 יריות עבור כל משימה למען החוסן. בממוצע, ה-FinPythia 6.9B מתגבר על Pythia 6.9B ב-10% על פני ארבע משימות, מה שמדגים את היעילות של אימון מקדים מתמשך ספציפי לתחום. עבור מודל 1B, השיפור פחות עמוק, אך הביצועים עדיין משתפרים ב-2% בממוצע.
האיור הבא ממחיש את ההבדל בביצועים לפני ואחרי DACP בשני הדגמים.

האיור הבא מציג שתי דוגמאות איכותיות שנוצרו על ידי Pythia 6.9B ו-FinPythia 6.9B. עבור שתי שאלות הקשורות לפיננסים לגבי מנהל משקיעים ומונח פיננסי, Pythia 6.9B אינו מבין את המונח או מזהה את השם, בעוד FinPythia 6.9B מייצר תשובות מפורטות בצורה נכונה. הדוגמאות האיכותיות מוכיחות שהכשרה מוקדמת מתמשכת מאפשרת ל-LLMs לרכוש ידע בתחום במהלך התהליך.

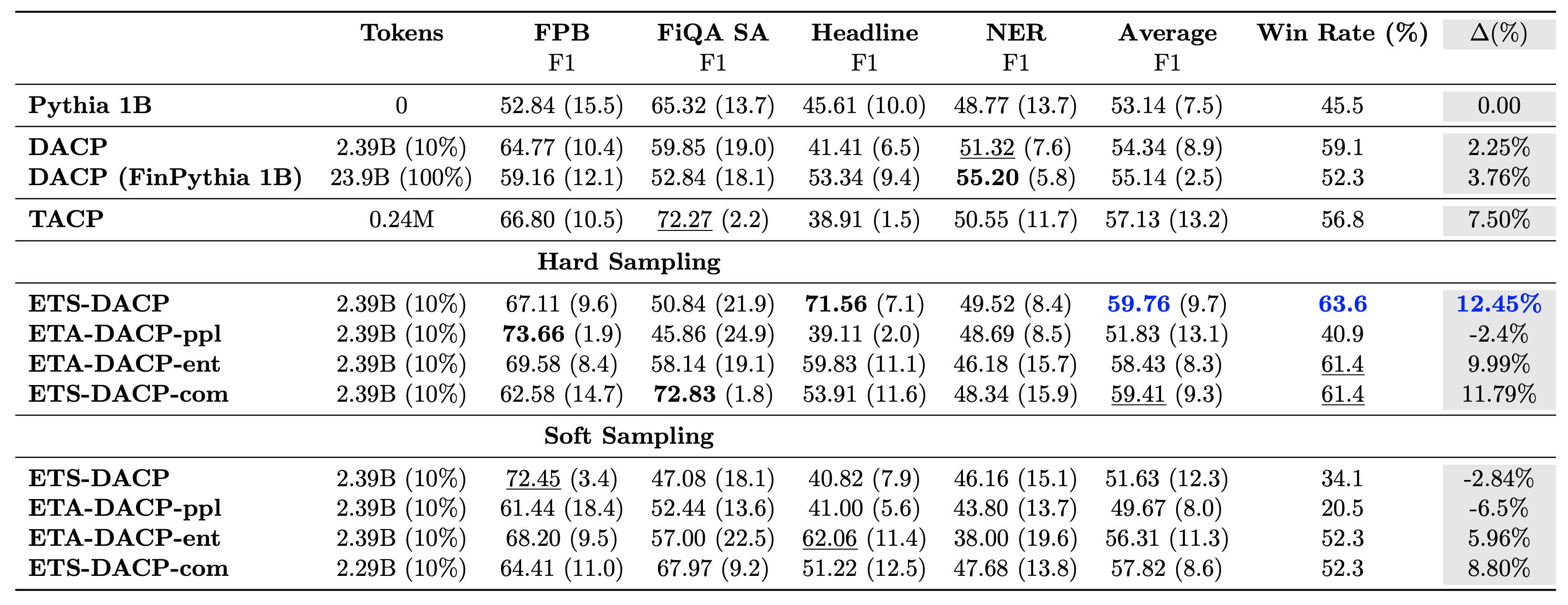
הטבלה הבאה משווה בין גישות קדם אימון מתמשכות יעילות שונות. ETA-DACP-ppl הוא ETA-DACP המבוסס על תמיהה (חידוש), ו-ETA-DACP-ent מבוסס על אנטרופיה (גיוון). ETS-DACP-com דומה ל-DACP עם בחירת נתונים על ידי ממוצע כל שלושת המדדים. להלן מספר נקודות מוצא מהתוצאות:
- שיטות בחירת הנתונים יעילות - הם עולים על אימון מקדים מתמשך סטנדרטי עם רק 10% מנתוני האימון. אימון מקדים מתמשך יעיל הכולל Task-Similar DACP (ETS-DACP), Task-Agnostic DACP המבוסס על אנטרופיה (ESA-DACP-ent) ו-Task-Similar DACP המבוסס על כל שלושת המדדים (ETS-DACP-com) עולה על ה-DACP הסטנדרטי בממוצע למרות העובדה שהם מאומנים רק על 10% מהקורפוס הפיננסי.
- בחירת נתונים מודע למשימה פועלת בצורה הטובה ביותר בהתאם למחקר מודלים של שפות קטנות - ETS-DACP רושם את הביצועים הממוצעים הטובים ביותר מבין כל השיטות, ובהתבסס על שלושת המדדים, רושם את ביצועי המשימות השני בטובו. זה מצביע על כך ששימוש בנתוני משימות ללא תווית הוא עדיין גישה יעילה לשיפור ביצועי המשימות במקרה של LLMs.
- בחירת נתונים אגנוסטית למשימה נמצאת במקום השני – ESA-DACP-ent עוקב אחר הביצועים של גישת בחירת הנתונים המודעת למשימה, מה שרומז שעדיין נוכל להגביר את ביצועי המשימות על ידי בחירה אקטיבית של דוגמאות באיכות גבוהה שאינן קשורות למשימות ספציפיות. זה סולל את הדרך לבניית LLMs פיננסיים לכל התחום תוך השגת ביצועי משימות מעולים.
שאלה קריטית אחת לגבי אימון מקדים מתמשך היא האם זה משפיע לרעה על הביצועים במשימות שאינן תחום. המחברים גם מעריכים את המודל המתאמן מראש על ארבע משימות גנריות בשימוש נרחב: ARC, MMLU, TruthQA ו-HellaSwag, אשר מודדות את יכולת המענה לשאלות, הנמקה והשלמה. המחברים מוצאים שאימון מקדים מתמשך אינו משפיע לרעה על ביצועים שאינם בתחום. לפרטים נוספים, עיין ב אימון מקדים מתמשך יעיל לבניית מודלים ספציפיים לתחום שפות גדולות.
סיכום
פוסט זה הציע תובנות לגבי איסוף נתונים ואסטרטגיות הדרכה מתמשכות להכשרת לימודי LLM לתחום פיננסי. אתה יכול להתחיל להכשיר את ה-LLM שלך למשימות פיננסיות באמצעות אימון אמזון SageMaker or סלע אמזון היום.
על הכותבים
 יונג שי הוא מדען יישומי באמזון פינטק. הוא מתמקד בפיתוח מודלים של שפה גדולים ויישומי AI Generative למימון.
יונג שי הוא מדען יישומי באמזון פינטק. הוא מתמקד בפיתוח מודלים של שפה גדולים ויישומי AI Generative למימון.
 קארן אגרוואל הוא מדען יישומי בכיר ב-Amazon FinTech עם התמקדות בבינה מלאכותית גנרטיבית למקרי שימוש פיננסיים. לקארן יש ניסיון רב בניתוח סדרות זמן ו-NLP, עם עניין מיוחד בלמידה מנתונים מסומנים מוגבלים
קארן אגרוואל הוא מדען יישומי בכיר ב-Amazon FinTech עם התמקדות בבינה מלאכותית גנרטיבית למקרי שימוש פיננסיים. לקארן יש ניסיון רב בניתוח סדרות זמן ו-NLP, עם עניין מיוחד בלמידה מנתונים מסומנים מוגבלים
 עייצז אחמד הוא מנהל מדע יישומי באמזון, שם הוא מוביל צוות של מדענים בונה יישומים שונים של למידת מכונה ובינה מלאכותית גנרטיבית בפיננסים. תחומי המחקר שלו הם ב-NLP, AI Generative ו-LLM. הוא קיבל את הדוקטורט שלו בהנדסת חשמל מאוניברסיטת טקסס A&M.
עייצז אחמד הוא מנהל מדע יישומי באמזון, שם הוא מוביל צוות של מדענים בונה יישומים שונים של למידת מכונה ובינה מלאכותית גנרטיבית בפיננסים. תחומי המחקר שלו הם ב-NLP, AI Generative ו-LLM. הוא קיבל את הדוקטורט שלו בהנדסת חשמל מאוניברסיטת טקסס A&M.
 צ'ינגווי לי הוא מומחה למידת מכונה בשירותי האינטרנט של אמזון. הוא קיבל את הדוקטורט שלו. במחקר תפעולי לאחר ששבר את חשבון מענקי המחקר של יועצו ולא הצליח לקיים את פרס נובל שהבטיח. נכון לעכשיו הוא עוזר ללקוחות בשירות פיננסי לבנות פתרונות למידת מכונה ב-AWS.
צ'ינגווי לי הוא מומחה למידת מכונה בשירותי האינטרנט של אמזון. הוא קיבל את הדוקטורט שלו. במחקר תפעולי לאחר ששבר את חשבון מענקי המחקר של יועצו ולא הצליח לקיים את פרס נובל שהבטיח. נכון לעכשיו הוא עוזר ללקוחות בשירות פיננסי לבנות פתרונות למידת מכונה ב-AWS.
 ראחונדר ארני מוביל את צוות האצת הלקוחות (CAT) בתוך AWS Industries. ה-CAT הוא צוות חוצה-תפקודי גלובלי של אדריכלי ענן מול לקוחות, מהנדסי תוכנה, מדעני נתונים, ומומחי ומעצבי AI/ML המניע חדשנות באמצעות אב טיפוס מתקדם, ומניע מצוינות תפעולית בענן באמצעות מומחיות טכנית מיוחדת.
ראחונדר ארני מוביל את צוות האצת הלקוחות (CAT) בתוך AWS Industries. ה-CAT הוא צוות חוצה-תפקודי גלובלי של אדריכלי ענן מול לקוחות, מהנדסי תוכנה, מדעני נתונים, ומומחי ומעצבי AI/ML המניע חדשנות באמצעות אב טיפוס מתקדם, ומניע מצוינות תפעולית בענן באמצעות מומחיות טכנית מיוחדת.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

