
Immagine dell'autore
Uno dei campi su cui si fonda la scienza dei dati è l’apprendimento automatico. Quindi, se vuoi entrare nel mondo della scienza dei dati, comprendere l’apprendimento automatico è uno dei primi passi che devi compiere.
Ma da dove iniziare? Inizi comprendendo la differenza tra i due principali tipi di algoritmi di machine learning. Solo dopo potremo parlare dei singoli algoritmi che dovrebbero essere nella tua lista di priorità da imparare come principiante.
La principale distinzione tra gli algoritmi si basa sul modo in cui apprendono.

Immagine dell'autore
Algoritmi di apprendimento supervisionato sono addestrati su a set di dati etichettato. Questo set di dati serve come supervisione (da cui il nome) per l'apprendimento perché alcuni dati in esso contenuti sono già etichettati come risposta corretta. Sulla base di questo input, l'algoritmo può apprendere e applicare tale apprendimento al resto dei dati.
D'altro canto, algoritmi di apprendimento non supervisionati imparare su un set di dati senza etichetta, nel senso che si impegnano a trovare modelli nei dati senza che gli esseri umani diano indicazioni.
Puoi leggere più in dettaglio su algoritmi di apprendimento automatico e tipologie di apprendimento.
Esistono anche altri tipi di apprendimento automatico, ma non per principianti.
Gli algoritmi vengono utilizzati per risolvere due principali problemi distinti all'interno di ciascun tipo di apprendimento automatico.
Ancora una volta, ci sono altri compiti, ma non sono per principianti.

Immagine dell'autore
Compiti di apprendimento supervisionato
Regressione è il compito di prevedere a valore numerico, chiamato variabile di risultato continua o variabile dipendente. La previsione si basa sulle variabili predittive o sulle variabili indipendenti.
Pensa a prevedere i prezzi del petrolio o la temperatura dell’aria.
Classificazione viene utilizzato per prevedere il categoria (classe) dei dati in ingresso. IL variabile di risultato qui è categorico o discreto.
Pensa a prevedere se la posta è spam o non spam o se il paziente contrarrà o meno una determinata malattia.
Compiti di apprendimento non supervisionato
il clustering si intende dividendo i dati in sottoinsiemi o cluster. L'obiettivo è raggruppare i dati nel modo più naturale possibile. Ciò significa che i punti dati all'interno dello stesso cluster sono più simili tra loro rispetto ai punti dati di altri cluster.
Riduzione dimensionale si riferisce alla riduzione del numero di variabili di input in un set di dati. Fondamentalmente significa riducendo il set di dati a pochissime variabili pur cogliendone l'essenza.
Ecco una panoramica degli algoritmi che tratterò.
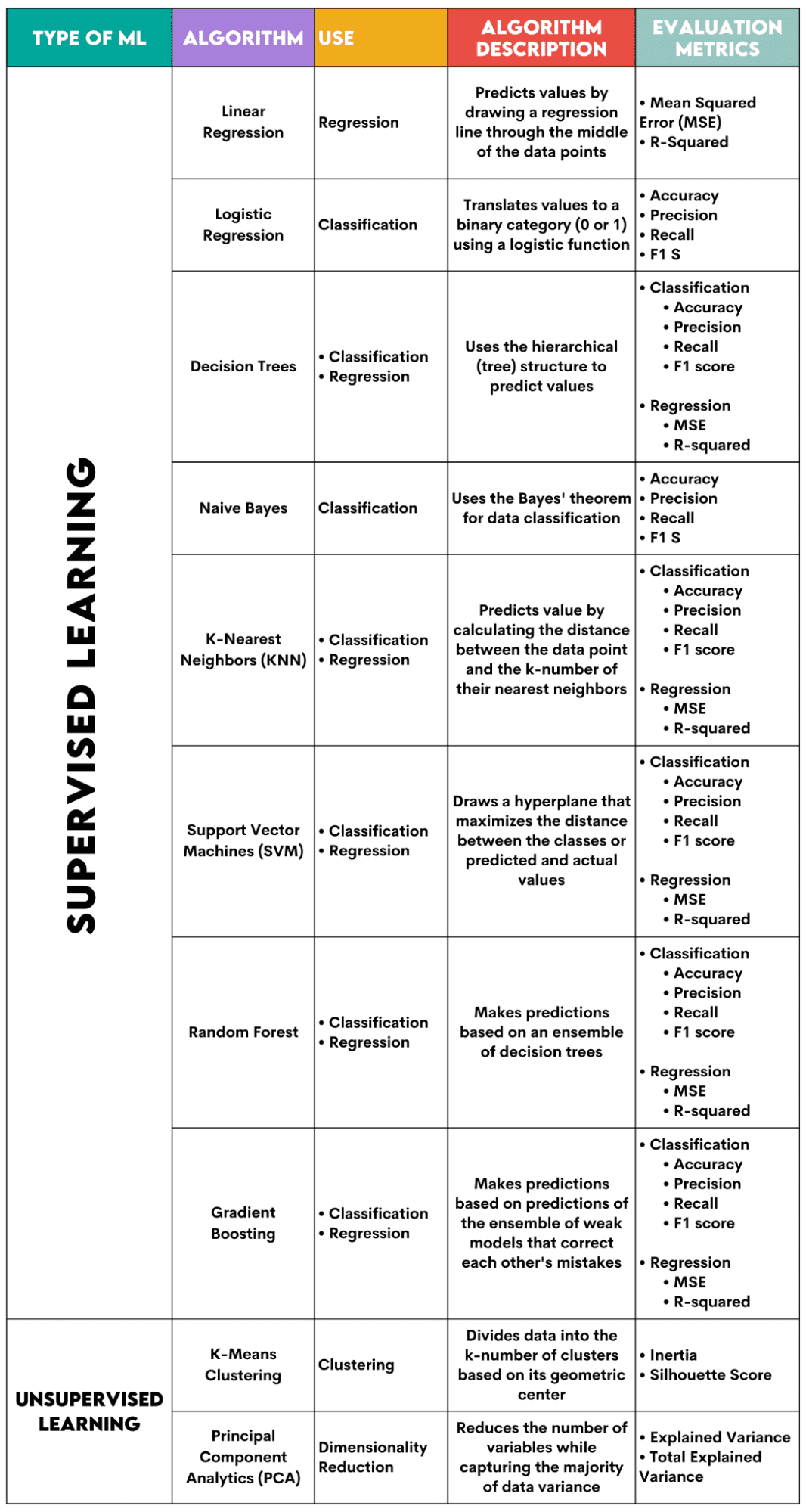
Immagine dell'autore
Algoritmi di apprendimento supervisionato
Quando scegli l'algoritmo per il tuo problema, è importante sapere per quale compito viene utilizzato l'algoritmo.
In qualità di scienziato dei dati, probabilmente applicherai questi algoritmi in Python utilizzando il file libreria scikit-learn. Anche se fa (quasi) tutto per te, è consigliabile che tu conosca almeno i principi generali del funzionamento interno di ciascun algoritmo.
Infine, dopo aver addestrato l'algoritmo, dovresti valutare le sue prestazioni. Per questo, ogni algoritmo ha alcune metriche standard.
1. Regressione lineare
Usato per: Regressione
Descrizione: La regressione lineare traccia una linea retta chiamata retta di regressione tra le variabili. Questa linea attraversa approssimativamente la metà dei punti dati, riducendo così al minimo l'errore di stima. Mostra il valore previsto della variabile dipendente in base al valore delle variabili indipendenti.
Metriche di valutazione:
- Errore quadratico medio (MSE): Rappresenta la media dell'errore quadrato, essendo l'errore la differenza tra i valori effettivi e quelli previsti. Più basso è il valore, migliori saranno le prestazioni dell'algoritmo.
- R-quadro: Rappresenta la percentuale di varianza della variabile dipendente che può essere prevista dalla variabile indipendente. Per questa misura, dovresti cercare di arrivare a 1 il più vicino possibile.
2. Regressione logistica
Usato per: Classificazione
Descrizione: Usa a funzione logistica per tradurre i valori dei dati in una categoria binaria, ovvero 0 o 1. Ciò viene fatto utilizzando la soglia, solitamente impostata su 0.5. Il risultato binario rende questo algoritmo perfetto per prevedere risultati binari, come SÌ/NO, VERO/FALSO o 0/1.
Metriche di valutazione:
- Precisione: il rapporto tra le previsioni corrette e quelle totali. Più si avvicina a 1, meglio è.
- Precisione: la misura dell'accuratezza del modello nelle previsioni positive; mostrato come il rapporto tra le previsioni positive corrette e il totale dei risultati positivi attesi. Più si avvicina a 1, meglio è.
- Ricordiamo: anch'esso misura l'accuratezza del modello nelle previsioni positive. È espresso come rapporto tra le previsioni positive corrette e il totale delle osservazioni effettuate nella classe. Ulteriori informazioni su queste metriche qui.
- Punteggio F1: La media armonica del richiamo e della precisione del modello. Più si avvicina a 1, meglio è.
3. Alberi decisionali
Usato per: Regressione e classificazione
Descrizione: Alberi decisionali sono algoritmi che utilizzano la struttura gerarchica o ad albero per prevedere un valore o una classe. Il nodo radice rappresenta l'intero set di dati, che poi si ramifica in nodi decisionali, rami e foglie in base ai valori delle variabili.
Metriche di valutazione:
- Accuratezza, precisione, richiamo e punteggio F1 -> per la classificazione
- MSE, R quadrato -> per la regressione
4. Ingenuo Bayes
Usato per: Classificazione
Descrizione: Questa è una famiglia di algoritmi di classificazione che utilizzano Teorema di Bayes, nel senso che presuppongono l'indipendenza tra le funzionalità all'interno di una classe.
Metriche di valutazione:
- Precisione
- Precisione
- Richiamo
- punteggio F1
5. K-Vicini più vicini (KNN)
Usato per: Regressione e classificazione
Descrizione: Calcola la distanza tra i dati del test e il numero k dei punti dati più vicini dai dati di allenamento. I dati del test appartengono ad una classe con un numero maggiore di "vicini". Per quanto riguarda la regressione, il valore previsto è la media dei k punti di allenamento scelti.
Metriche di valutazione:
- Accuratezza, precisione, richiamo e punteggio F1 -> per la classificazione
- MSE, R quadrato -> per la regressione
6. Supporta le macchine vettoriali (SVM)
Usato per: Regressione e classificazione
Descrizione: Questo algoritmo disegna a iperpiano separare diverse classi di dati. È posizionato alla massima distanza dai punti più vicini di ogni classe. Maggiore è la distanza del punto dati dall'iperpiano, più appartiene alla sua classe. Per la regressione il principio è simile: l’iperpiano massimizza la distanza tra i valori previsti e quelli effettivi.
Metriche di valutazione:
- Accuratezza, precisione, richiamo e punteggio F1 -> per la classificazione
- MSE, R quadrato -> per la regressione
7. Foresta casuale
Usato per: Regressione e classificazione
Descrizione: L'algoritmo della foresta casuale utilizza un insieme di alberi decisionali, che poi compongono una foresta decisionale. La previsione dell'algoritmo si basa sulla previsione di numerosi alberi decisionali. I dati verranno assegnati alla classe che riceverà il maggior numero di voti. Per la regressione, il valore previsto è una media dei valori previsti di tutti gli alberi.
Metriche di valutazione:
- Accuratezza, precisione, richiamo e punteggio F1 -> per la classificazione
- MSE, R quadrato -> per la regressione
8. Aumento del gradiente
Usato per: Regressione e classificazione
Descrizione: Questi algoritmi utilizzare un insieme di modelli deboli, in cui ciascun modello successivo riconosce e corregge gli errori del modello precedente. Questo processo viene ripetuto finché l'errore (funzione di perdita) non viene ridotto al minimo.
Metriche di valutazione:
- Accuratezza, precisione, richiamo e punteggio F1 -> per la classificazione
- MSE, R quadrato -> per la regressione
Algoritmi di apprendimento non supervisionati
9. Cluster di mezzi K
Usato per: il clustering
Descrizione: L'algoritmo divide il set di dati in cluster di numeri k, ciascuno rappresentato dal suo baricentro o centro geometrico. Attraverso il processo iterativo di divisione dei dati in un numero k di cluster, l'obiettivo è ridurre al minimo la distanza tra i punti dati e il centroide del relativo cluster. D'altra parte, cerca anche di massimizzare la distanza di questi punti dati dal centroide degli altri cluster. In poche parole, i dati appartenenti allo stesso cluster dovrebbero essere il più simili possibile e il più diversi possibile rispetto ai dati di altri cluster.
Metriche di valutazione:
- Inerzia: la somma dei quadrati della distanza di ciascun punto dati dal centroide del cluster più vicino. Più basso è il valore di inerzia, più compatto è il cluster.
- Punteggio Silhouette: misura la coesione (somiglianza dei dati all'interno del proprio cluster) e la separazione (differenza dei dati rispetto ad altri cluster) dei cluster. Il valore di questo punteggio varia da -1 a +1. Più alto è il valore, più i dati sono ben abbinati al relativo cluster e peggio sono abbinati ad altri cluster.
10. Analisi delle componenti principali (PCA)
Usato per: Riduzione dimensionale
Descrizione: L'algoritmo riduce il numero di variabili utilizzate costruendo nuove variabili (componenti principali) tentando comunque di massimizzare la varianza catturata dei dati. In altre parole, limita i dati ai suoi componenti più comuni senza perderne l'essenza.
Metriche di valutazione:
- Varianza spiegata: la percentuale della varianza coperta da ciascuna componente principale.
- Varianza totale spiegata: la percentuale della varianza coperta da tutte le componenti principali.
L’apprendimento automatico è una parte essenziale della scienza dei dati. Con questi dieci algoritmi coprirai le attività più comuni nell'apprendimento automatico. Naturalmente, questa panoramica fornisce solo un’idea generale di come funziona ciascun algoritmo. Quindi, questo è solo l'inizio.
Ora devi imparare come implementare questi algoritmi in Python e risolvere problemi reali. In questo, consiglio di usare scikit-learn. Non solo perché è una libreria ML relativamente facile da usare, ma anche per la sua materiali estesi sugli algoritmi ML.
Nato Rosidi è uno scienziato dei dati e si occupa di strategia di prodotto. È anche professore a contratto che insegna analisi ed è il fondatore di StrataScratch, una piattaforma che aiuta i data scientist a prepararsi per le loro interviste con domande reali da parte delle migliori aziende. Nate scrive sulle ultime tendenze nel mercato del lavoro, fornisce consigli sui colloqui, condivide progetti di data science e copre tutto ciò che riguarda SQL.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.kdnuggets.com/a-beginner-guide-to-the-top-10-machine-learning-algorithms?utm_source=rss&utm_medium=rss&utm_campaign=a-beginners-guide-to-the-top-10-machine-learning-algorithms

