Amazon Relational Database Service (Amazon RDS) per MySQL integrazione zero-ETL con Amazon RedShift Prima ha annunciato in anteprima su AWS re:Invent 2023 per Amazon RDS per MySQL versione 8.0.28 o successiva. In questo post forniamo una guida passo passo su come iniziare con l'analisi operativa quasi in tempo reale utilizzando questa funzionalità. Questo post è la continuazione della serie zero-ETL iniziata con Guida introduttiva per l'analisi operativa in tempo quasi reale utilizzando l'integrazione zero-ETL di Amazon Aurora con Amazon Redshift.
Le sfide
I clienti di tutti i settori oggi cercano di utilizzare i dati per ottenere un vantaggio competitivo e aumentare le entrate e il coinvolgimento dei clienti implementando casi d'uso di analisi quasi in tempo reale come strategie di personalizzazione, rilevamento di frodi, monitoraggio dell'inventario e molto altro. Esistono due approcci generali per analizzare i dati operativi per questi casi d'uso:
- Analizzare i dati sul posto nel database operativo (come repliche di lettura, query federate e acceleratori di analisi)
- Sposta i dati in un datastore ottimizzato per l'esecuzione di query specifiche per casi d'uso come un data warehouse
L'integrazione zero-ETL si concentra sulla semplificazione di quest'ultimo approccio.
Il processo di estrazione, trasformazione e caricamento (ETL) è stato un modello comune per lo spostamento dei dati da un database operativo a un data warehouse di analisi. ELT è il luogo in cui i dati estratti vengono prima caricati così come sono nella destinazione e poi trasformati. Le condotte ETL ed ELT possono essere costose da costruire e complesse da gestire. Con più punti di contatto, errori intermittenti nelle pipeline ETL ed ELT possono portare a lunghi ritardi, lasciando le applicazioni di data warehouse con dati obsoleti o mancanti, con conseguente perdita di opportunità di business.
In alternativa, le soluzioni che analizzano i dati sul posto possono funzionare benissimo per accelerare le query su un singolo database, ma tali soluzioni non sono in grado di aggregare dati da più database operativi per i clienti che necessitano di eseguire analisi unificate.
Zero ETL
A differenza dei sistemi tradizionali in cui i dati sono archiviati in un unico database e l'utente deve trovare un compromesso tra analisi unificata e prestazioni, i data engineer possono ora replicare i dati da più database RDS per MySQL in un unico data warehouse Redshift per ricavare informazioni olistiche su tutti i fronti. molte applicazioni o partizioni. Gli aggiornamenti nei database transazionali vengono propagati automaticamente e continuamente ad Amazon Redshift in modo che i data engineer dispongano delle informazioni più recenti quasi in tempo reale. Non c'è alcuna infrastruttura da gestire e l'integrazione può aumentare o diminuire automaticamente in base al volume dei dati.
In AWS, abbiamo fatto progressi costanti per portare il nostro visione a zero ETL alla vita. Le seguenti origini sono attualmente supportate per le integrazioni zero-ETL:
Quando crei un'integrazione ETL zero per Amazon Redshift, continui a pagare per il database di origine sottostante e per l'utilizzo del database Redshift di destinazione. Fare riferimento a Costi di integrazione Zero-ETL (Anteprima) per ulteriori dettagli.
Con l'integrazione zero ETL con Amazon Redshift, l'integrazione replica i dati dal database di origine nel data warehouse di destinazione. I dati diventano disponibili in Amazon Redshift in pochi secondi, consentendoti di utilizzare le funzionalità di analisi di Amazon Redshift e funzionalità come la condivisione dei dati, l'ottimizzazione autonoma del carico di lavoro, il dimensionamento della concorrenza, l'apprendimento automatico e molto altro. Puoi continuare con l'elaborazione delle transazioni su Amazon RDS o Amazon Aurora utilizzando contemporaneamente Amazon Redshift per carichi di lavoro di analisi come reporting e dashboard.
Il diagramma seguente illustra questa architettura.
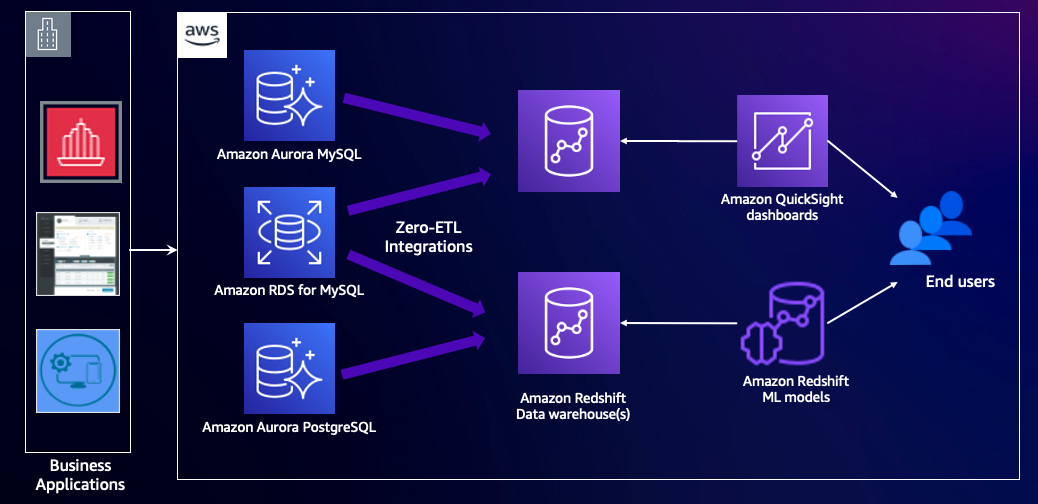
Panoramica della soluzione
Consideriamo TICCHETTO, un sito web immaginario in cui gli utenti acquistano e vendono biglietti online per eventi sportivi, spettacoli e concerti. I dati transazionali di questo sito Web vengono caricati in un database Amazon RDS per MySQL 8.0.28 (o versione successiva). Gli analisti aziendali dell'azienda desiderano generare parametri per identificare il movimento dei biglietti nel tempo, le percentuali di successo per i venditori e gli eventi, i luoghi e le stagioni più venduti. Vorrebbero ottenere questi parametri quasi in tempo reale utilizzando un'integrazione zero-ETL.
L'integrazione viene configurata tra Amazon RDS for MySQL (origine) e Amazon Redshift (destinazione). I dati transazionali dall'origine vengono aggiornati quasi in tempo reale sulla destinazione, che elabora le query analitiche.
Puoi utilizzare l'opzione serverless o un cluster RA3 crittografato per Amazon Redshift. Per questo post utilizziamo un database RDS con provisioning e un data warehouse con provisioning Redshift.
Il diagramma seguente illustra l'architettura di alto livello.
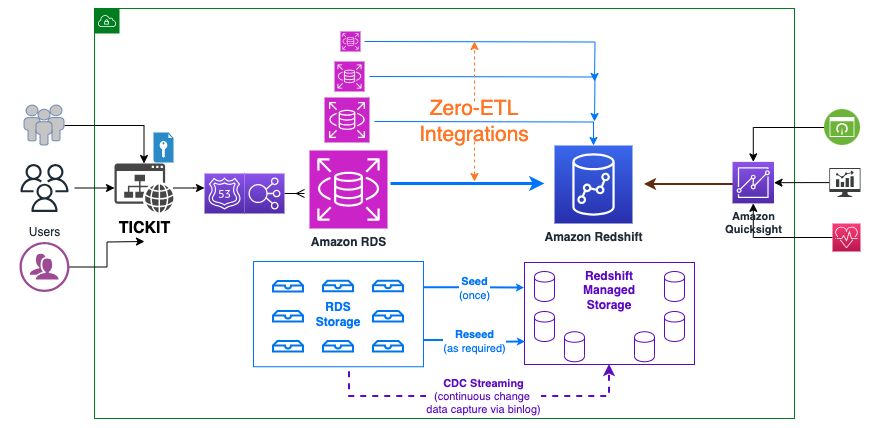
Di seguito sono riportati i passaggi necessari per impostare l'integrazione zero-ETL. Questi passaggi possono essere eseguiti automaticamente dalla procedura guidata zero-ETL, ma sarà necessario un riavvio se la procedura guidata modifica l'impostazione per Amazon RDS o Amazon Redshift. Puoi eseguire questi passaggi manualmente, se non già configurati, ed eseguire i riavvii a tuo piacimento. Per le guide introduttive complete, fare riferimento a Utilizzo delle integrazioni zero-ETL di Amazon RDS con Amazon Redshift (anteprima) ed Lavorare con integrazioni zero-ETL.
- Configura l'origine RDS per MySQL con un gruppo di parametri DB personalizzato.
- Configura il cluster Redshift per abilitare gli identificatori con distinzione tra maiuscole e minuscole.
- Configura le autorizzazioni richieste.
- Crea l'integrazione zero-ETL.
- Crea un database dall'integrazione in Amazon Redshift.
Configura l'origine RDS for MySQL con un gruppo di parametri DB personalizzato
Per creare un database RDS per MySQL, completare i seguenti passaggi:
- Nella console Amazon RDS, crea un gruppo di parametri DB chiamato
zero-etl-custom-pg.
L'integrazione Zero-ETL funziona utilizzando log binari (binlog) generati dal database MySQL. Per abilitare i binlog su Amazon RDS for MySQL, è necessario abilitare un set specifico di parametri.
- Impostare le seguenti impostazioni dei parametri del cluster binlog:
binlog_format = ROWbinlog_row_image = FULLbinlog_checksum = NONE
Inoltre, assicurati che binlog_row_value_options il parametro non è impostato su PARTIAL_JSON. Per impostazione predefinita, questo parametro non è impostato.
- Scegli Database nel riquadro di navigazione, quindi scegli Crea database.
- Nel Versione del motorescegli MySQL 8.0.28 (o più alto).

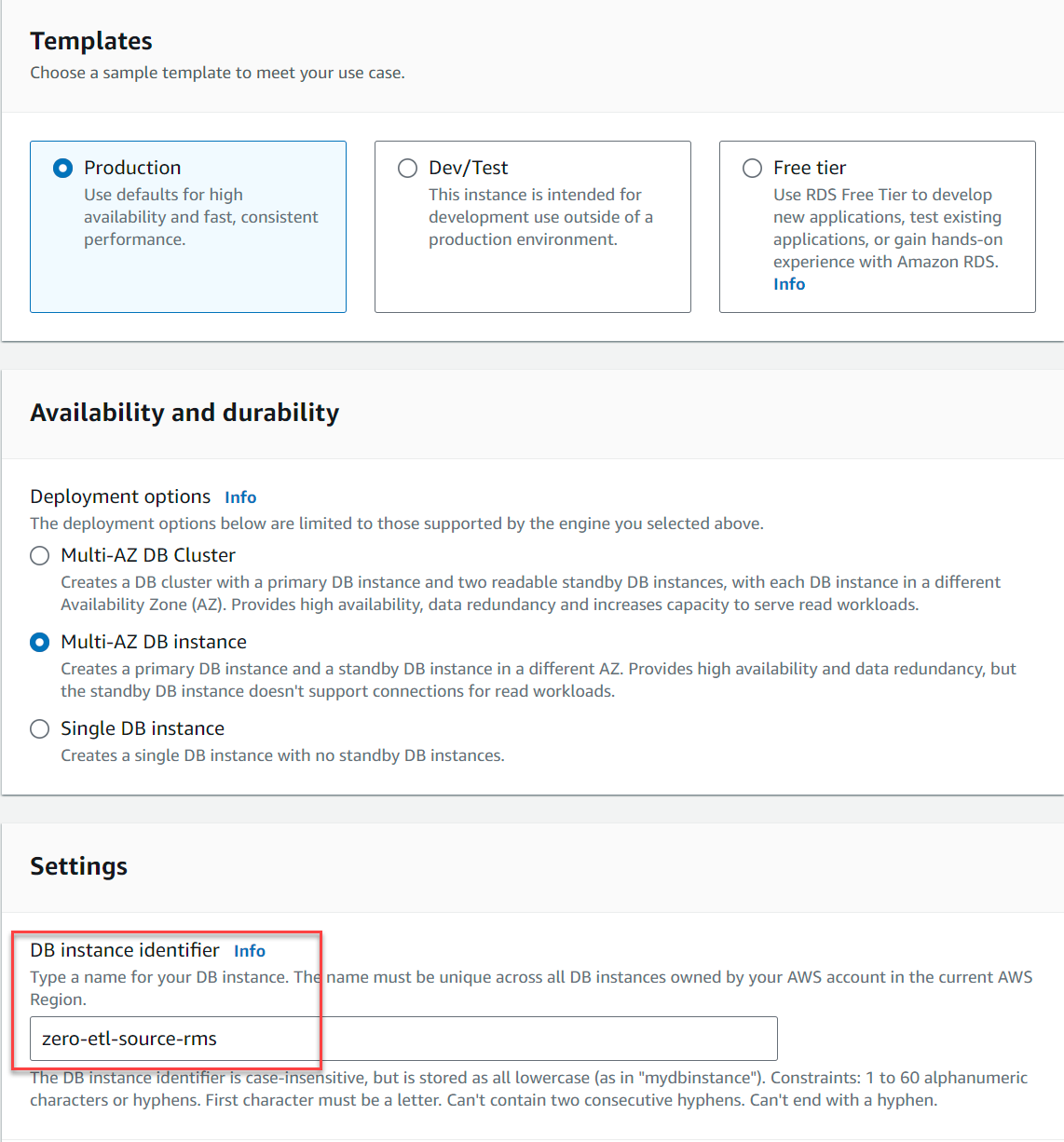
- Nel Modelli, selezionare Produzione.
- Nel Disponibilità e durabilità, selezionare uno Istanza database multi-AZ or Istanza database singola (I cluster DB Multi-AZ non sono supportati al momento della stesura di questo documento).
- Nel Identificatore dell'istanza database, accedere
zero-etl-source-rms.
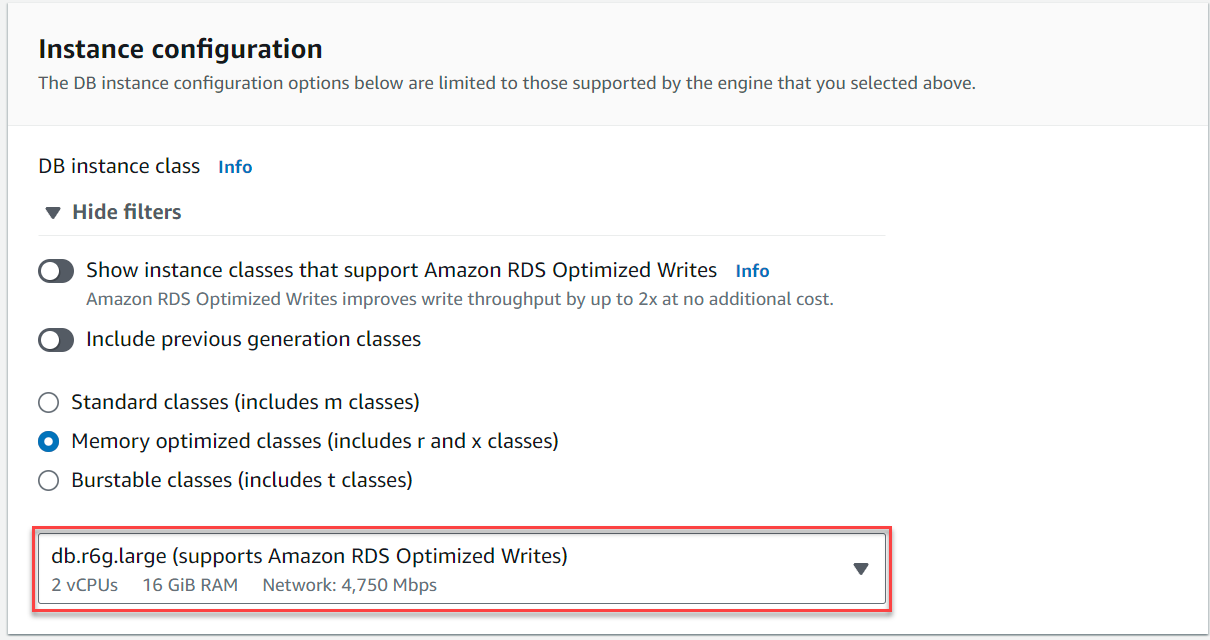
- Sotto Configurazione dell'istanza, selezionare Classi ottimizzate per la memoria e scegli l'istanza
db.r6g.large, che dovrebbe essere sufficiente per il caso d'uso TICKIT.
- Sotto Configurazione aggiuntiva, Per Gruppo di parametri del cluster di database, scegli il gruppo di parametri che hai creato in precedenza (
zero-etl-custom-pg).
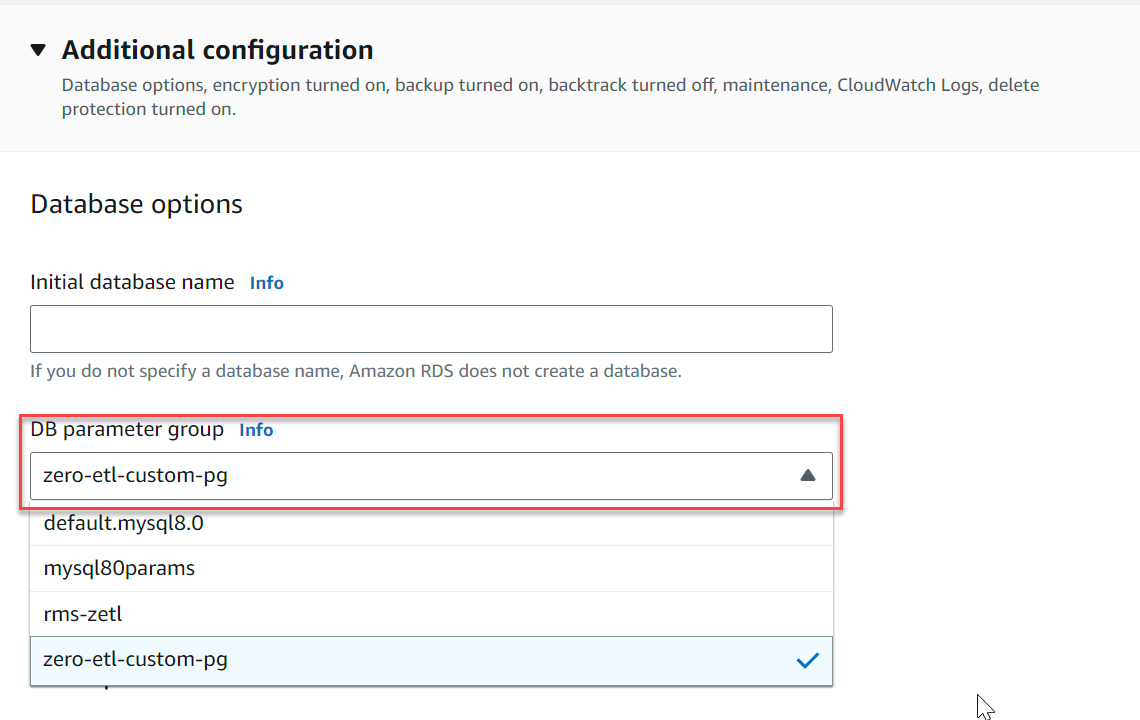
- Scegli Crea database.
In un paio di minuti, dovrebbe avviare un database RDS per MySQL come fonte per l'integrazione zero-ETL.
Configura la destinazione Redshift
Dopo aver creato il cluster DB di origine, devi creare e configurare un data warehouse di destinazione in Amazon Redshift. Il data warehouse deve soddisfare i seguenti requisiti:
- Utilizzando un tipo di nodo RA3 (
ra3.16xlarge,ra3.4xlarge, ora3.xlplus) o puoi Amazon Redshift senza server - Crittografato (se si utilizza un cluster con provisioning)
Per il nostro caso d'uso, crea un cluster Redshift completando i seguenti passaggi:
- Sulla console Amazon Redshift, scegli Configurazioni e quindi scegliere Gestione del carico di lavoro.
- Nella sezione del gruppo di parametri, scegli Creare.
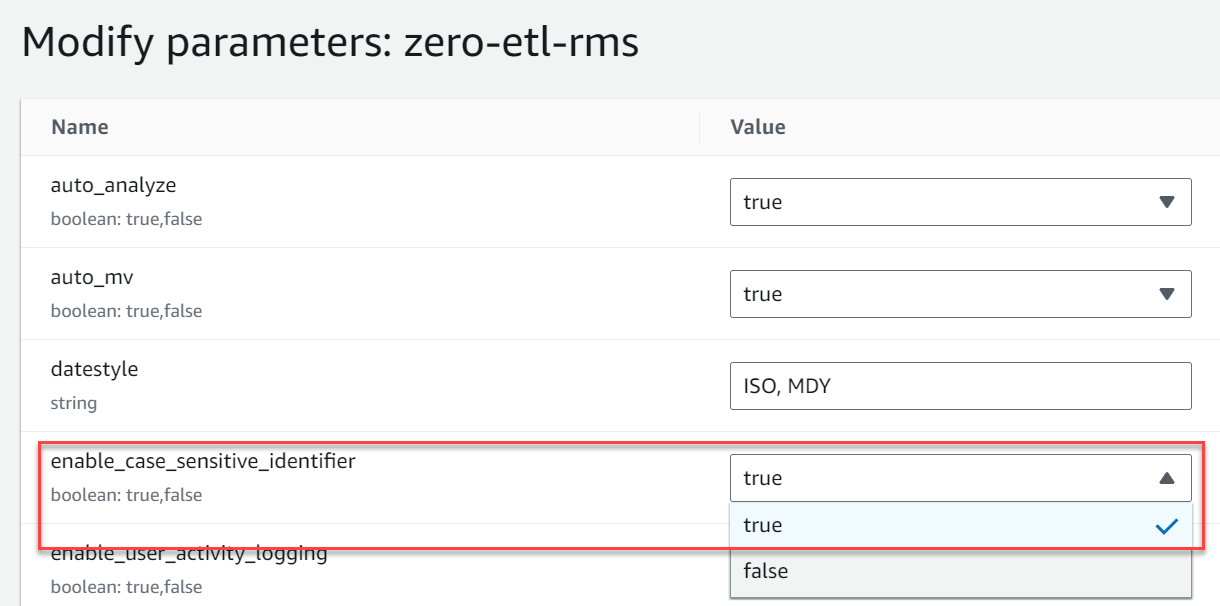
- Crea un nuovo gruppo di parametri denominato
zero-etl-rms. - Scegli Modifica parametri e modificare il valore di
enable_case_sensitive_identifieraTrue. - Scegli Risparmi.
È inoltre possibile utilizzare il Interfaccia della riga di comando di AWS (AWS CLI). gruppo di lavoro di aggiornamento per Redshift Serverless:
- Scegli Dashboard dei cluster con provisioning.
Nella parte superiore della finestra della console, vedrai a Prova le nuove funzionalità di Amazon Redshift in anteprima banner.
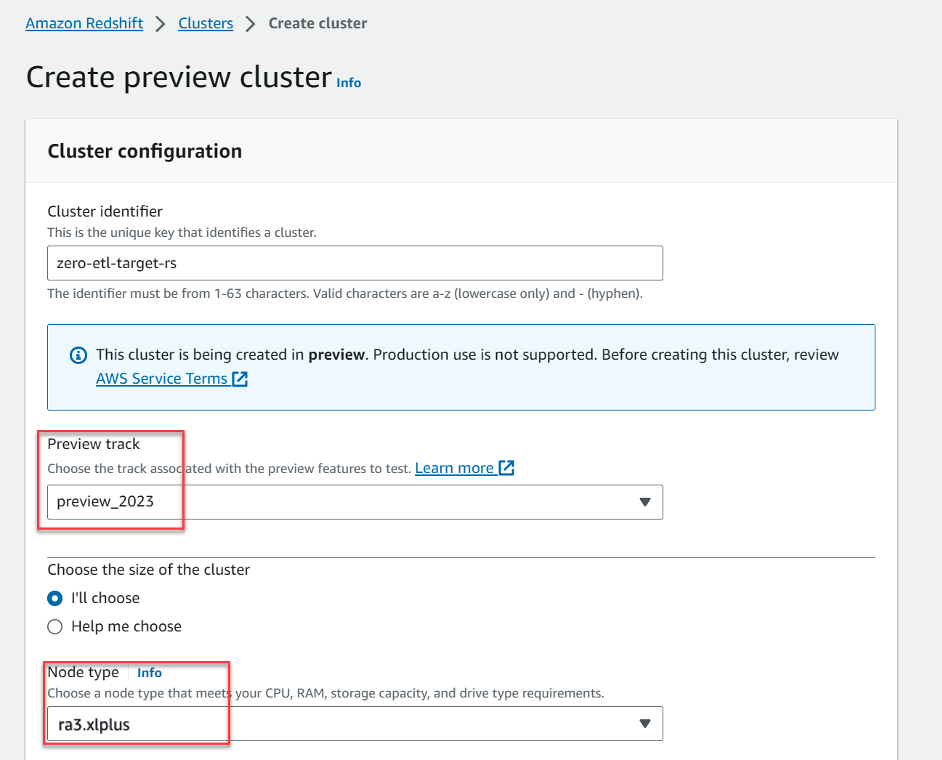
- Scegli Crea cluster di anteprima.

- Nel Anteprima traccia, ha scelto
preview_2023. - Nel Tipo di nodo, scegli uno dei tipi di nodo supportati (per questo post utilizziamo
ra3.xlplus).
- Sotto Ulteriori configurazioni, espandi Configurazioni database.
- Nel Gruppi di parametriscegli
zero-etl-rms. - Nel crittografia, selezionare Utilizza AWS Key Management Service.
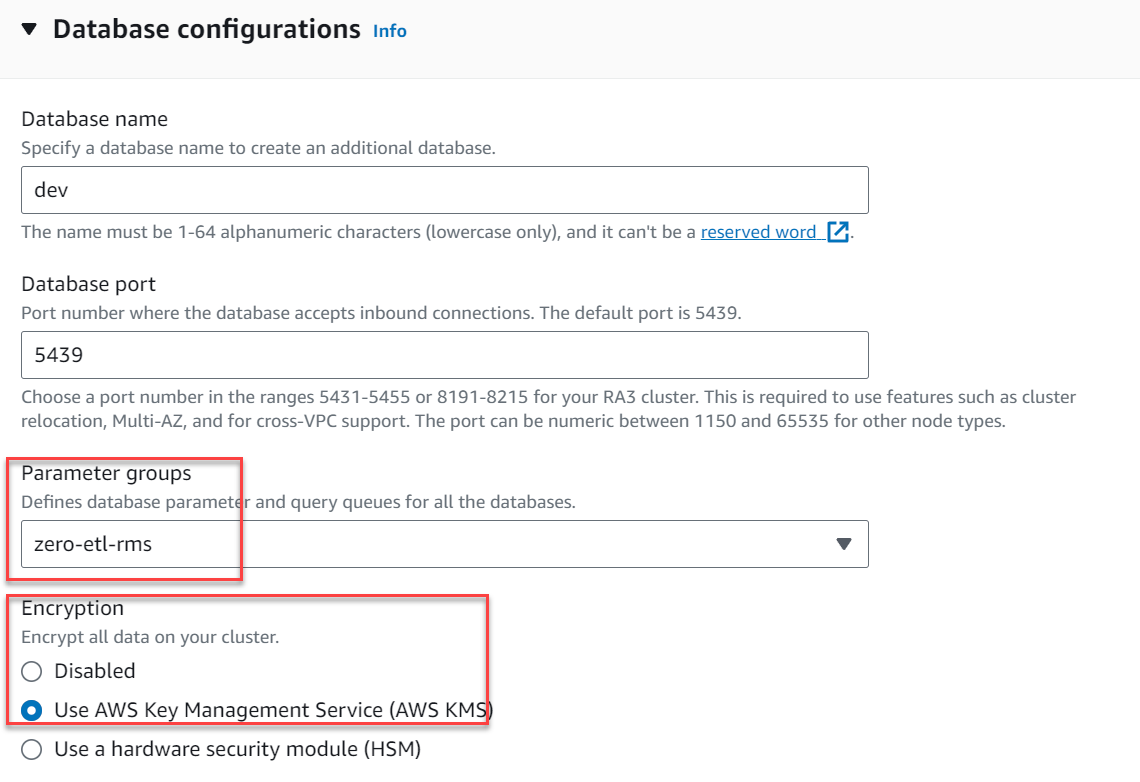
- Scegli Crea cluster.
Il cluster dovrebbe diventare Disponibile in pochi minuti.

- Passare allo spazio dei nomi
zero-etl-target-rs-nse scegliere il Politica delle risorse scheda. - Scegli Aggiungi entità autorizzate.
- Inserisci l'Amazon Resource Name (ARN) dell'utente o del ruolo AWS oppure l'ID dell'account AWS (principali IAM) a cui è consentito creare integrazioni.
Un ID account viene archiviato come ARN con l'utente root.
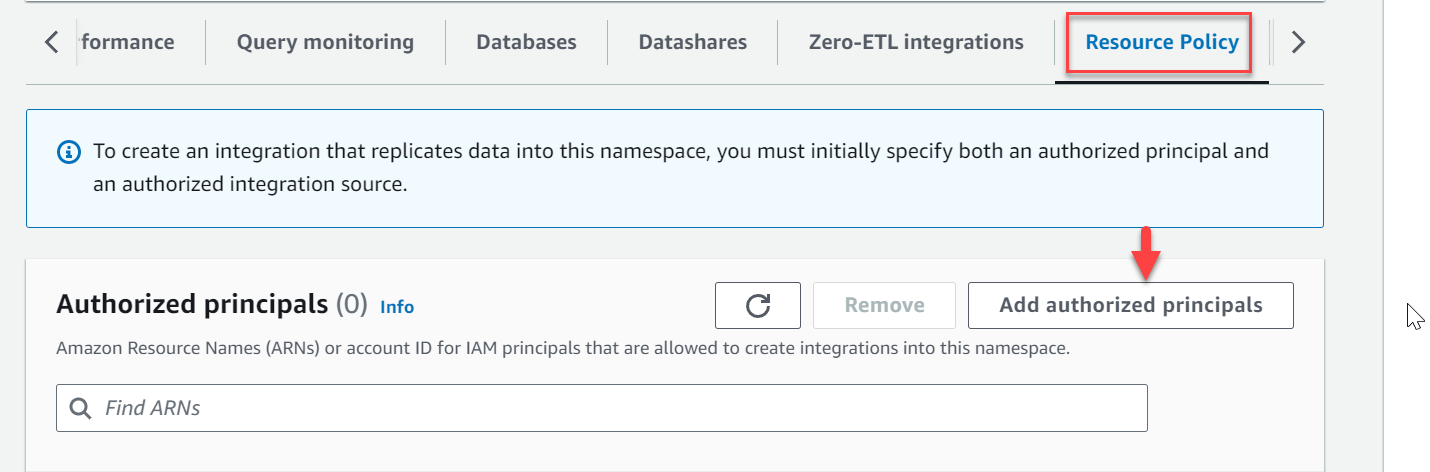
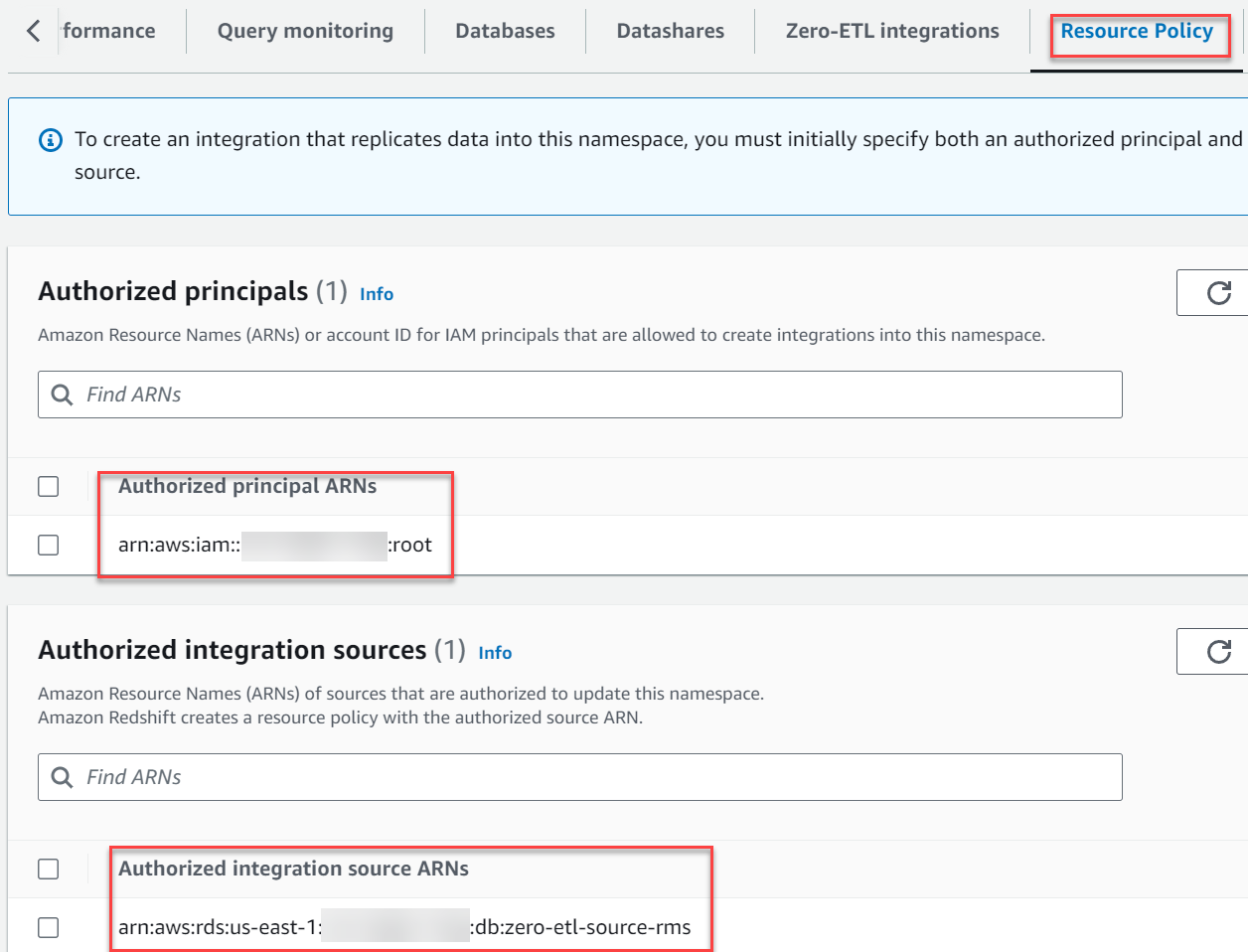
- Nel Fonti di integrazione autorizzate sezione, scegliere Aggiungi origine di integrazione autorizzata per aggiungere l'ARN dell'istanza database RDS for MySQL che è l'origine dati per l'integrazione zero-ETL.
Puoi trovare questo valore accedendo alla console Amazon RDS e accedendo al file Configurazione scheda del zero-etl-source-rms Istanza database.

La policy delle risorse dovrebbe essere simile alla schermata seguente.
Configura le autorizzazioni richieste
Per creare un'integrazione zero-ETL, il tuo utente o ruolo deve avere un allegato politica basata sull'identità con l'appropriato Gestione dell'identità e dell'accesso di AWS (IAM) autorizzazioni. Il proprietario di un account AWS può farlo configurare le autorizzazioni richieste per utenti o ruoli che possono creare integrazioni con ETL zero. La policy di esempio consente all'entità associata di eseguire le seguenti azioni:
- Crea integrazioni zero-ETL per l'istanza database RDS for MySQL di origine.
- Visualizza ed elimina tutte le integrazioni zero-ETL.
- Crea integrazioni in entrata nel data warehouse di destinazione. Questa autorizzazione non è richiesta se lo stesso account possiede il data warehouse Redshift e questo account è un'entità autorizzata per quel data warehouse. Tieni inoltre presente che Amazon Redshift ha un formato ARN diverso per i cluster con provisioning e serverless:
- Fornito -
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - serverless -
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
- Fornito -
Completare i seguenti passaggi per configurare le autorizzazioni:
- Sulla console IAM, scegli Termini e Condizioni nel pannello di navigazione.
- Scegli Crea politica.
- Crea una nuova politica chiamata
rds-integrationsutilizzando il seguente JSON (sostituisciregionedaccount-idcon i tuoi valori effettivi):
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": [
"rds:CreateIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:db:source-instancename",
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"rds:DescribeIntegration"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": [
"rds:DeleteIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"redshift:CreateInboundIntegration"
],
"Resource": [
"arn:aws:redshift:{region}:{account-id}:cluster:namespace-uuid"
]
}]
}
- Collega la policy che hai creato alle tue autorizzazioni utente o ruolo IAM.
Crea l'integrazione zero-ETL
Per creare l'integrazione zero-ETL, completare i seguenti passaggi:
- Nella console Amazon RDS, scegli Integrazioni Zero-ETL nel pannello di navigazione.
- Scegli Crea un'integrazione zero-ETL.

- Nel Identificatore di integrazione, inserire ad esempio un nome
zero-etl-demo.
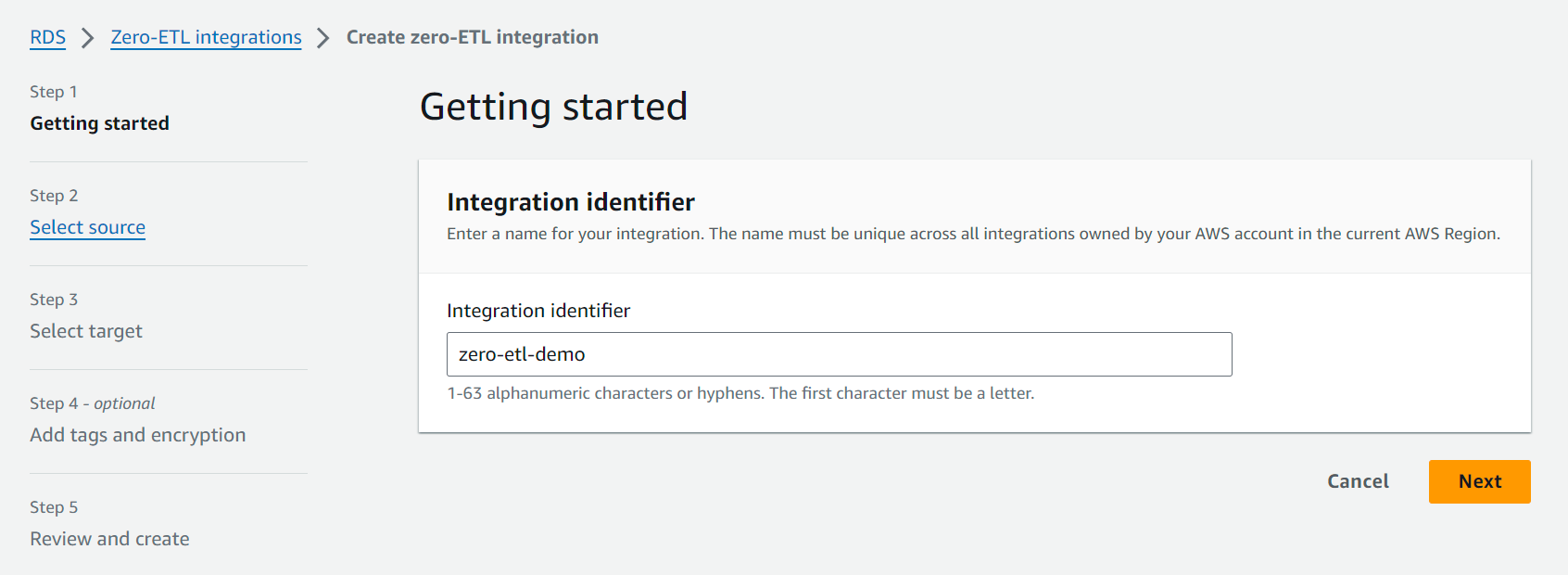
- Nel Database di originescegli Sfoglia i database RDS e scegli il cluster di origine
zero-etl-source-rms. - Scegli Avanti.

- Sotto Target, Per Data warehouse di Amazon Redshiftscegli Sfoglia i data warehouse di Redshift e scegli il data warehouse Redshift (
zero-etl-target-rs). - Scegli Avanti.
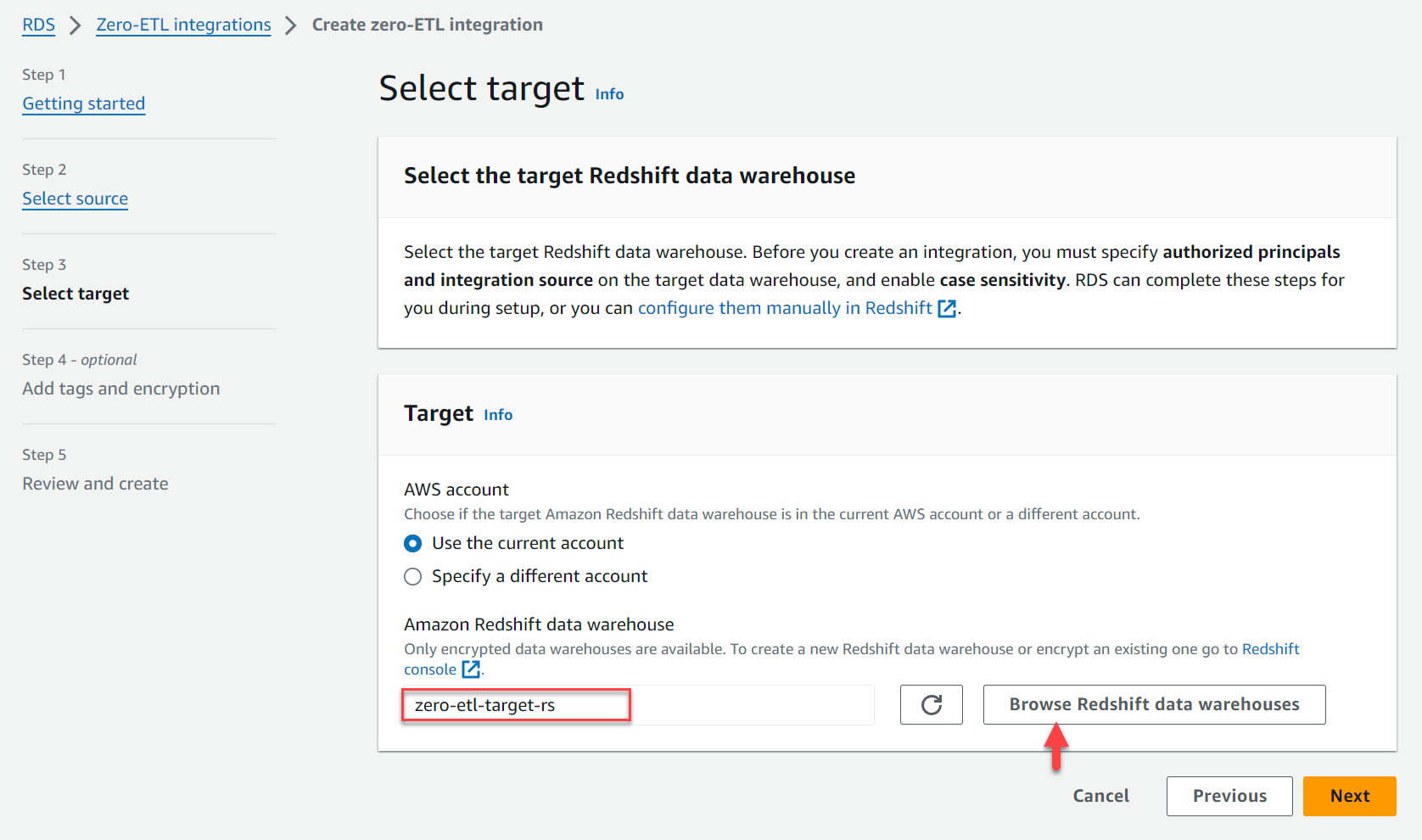
- Aggiungi tag e crittografia, se applicabile.
- Scegli Avanti.
- Verifica il nome dell'integrazione, l'origine, la destinazione e altre impostazioni.
- Scegli Crea un'integrazione zero-ETL.
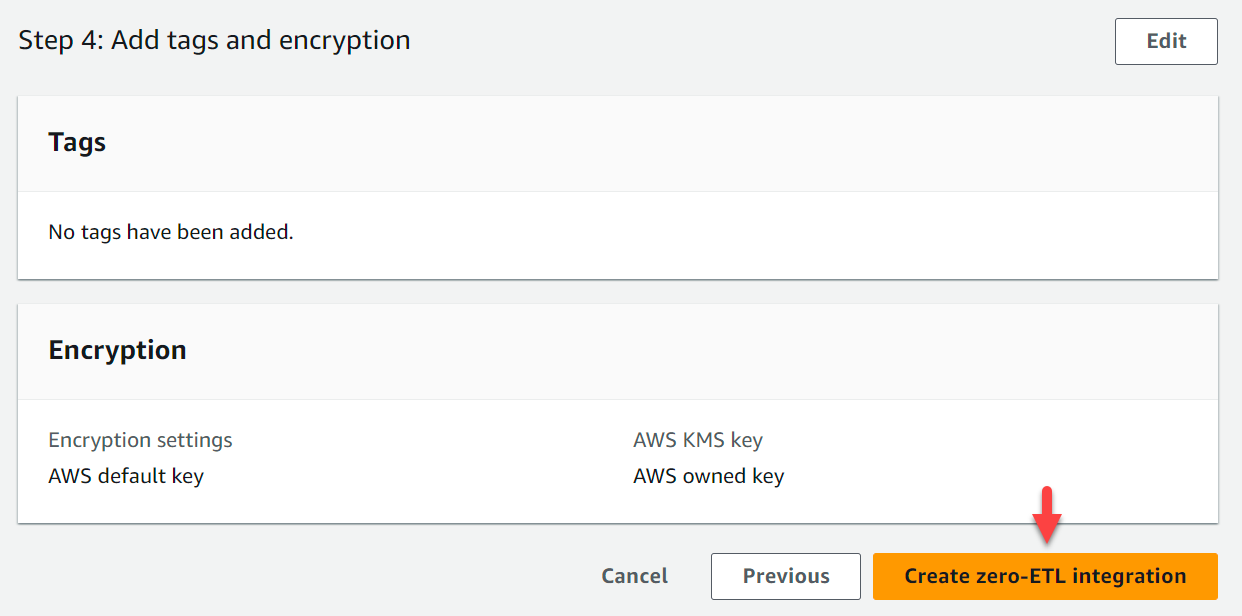
Puoi scegliere l'integrazione per visualizzarne i dettagli e monitorarne l'avanzamento. Ci sono voluti circa 30 minuti perché lo stato cambiasse Creazione a Attivo.

Il tempo varierà a seconda della dimensione del set di dati nell'origine.
Crea un database dall'integrazione in Amazon Redshift
Per creare il tuo database dall'integrazione zero-ETL, completa i seguenti passaggi:
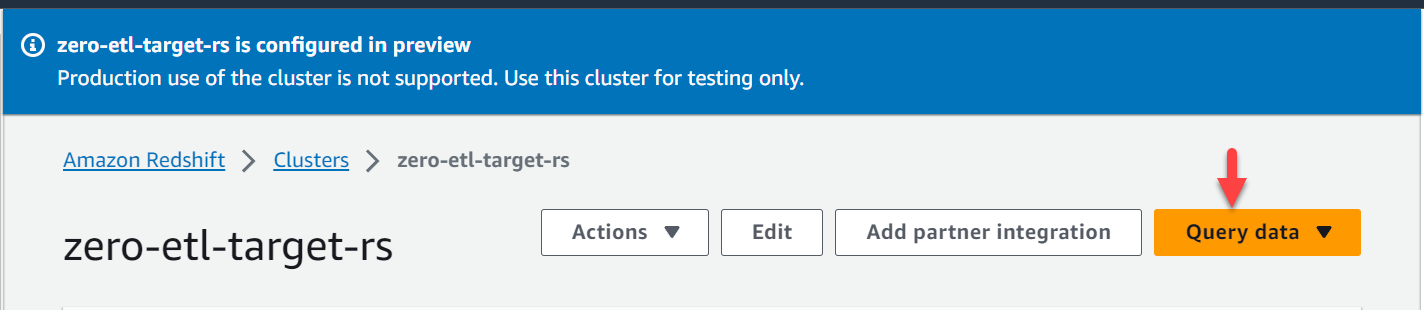
- Sulla console Amazon Redshift, scegli Cluster nel pannello di navigazione.
- Aprire il
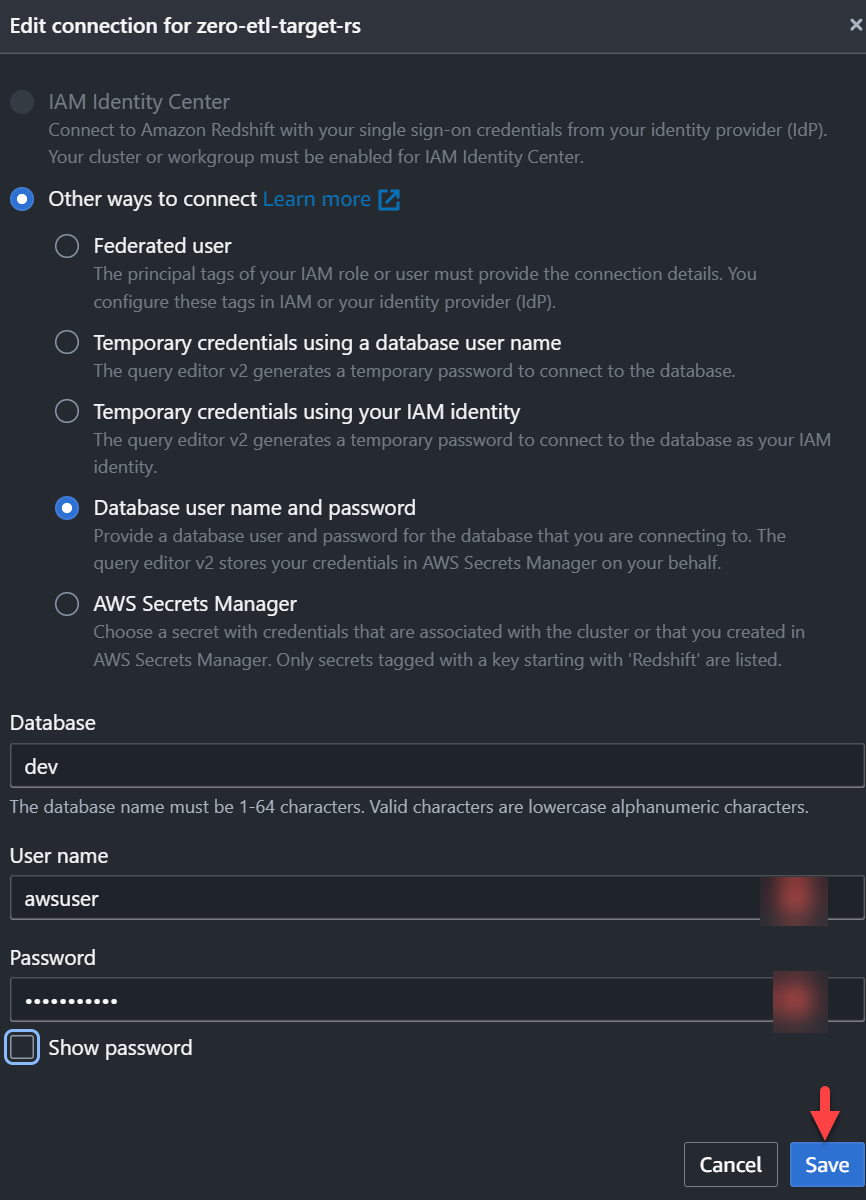
zero-etl-target-rsgrappolo. - Scegli Interroga i dati per aprire l'editor di query v2.
- Connettiti al data warehouse Redshift scegliendo Risparmi.
- Ottieni il file
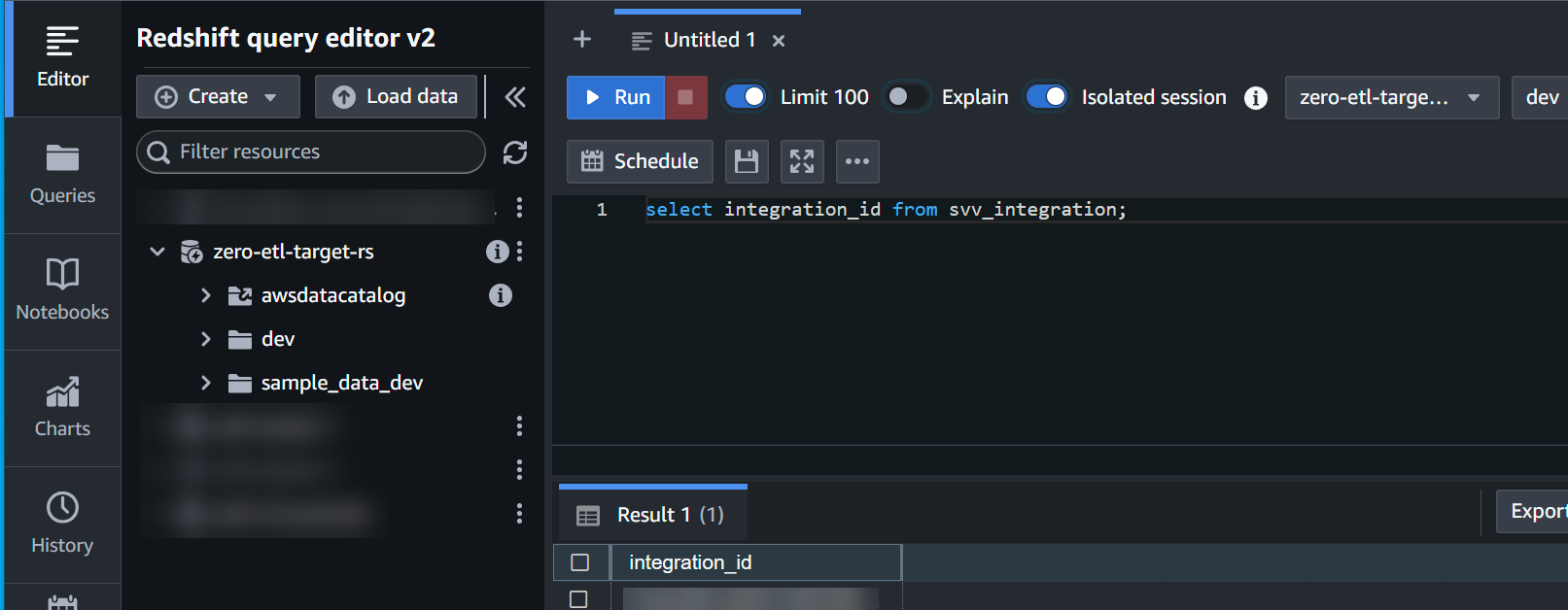
integration_iddalsvv_integrationtabella di sistema:
select integration_id from svv_integration; -- copy this result, use in the next sql
- Usa il
integration_iddal passaggio precedente per creare un nuovo database dall'integrazione:
CREATE DATABASE zetl_source FROM INTEGRATION '<result from above>';
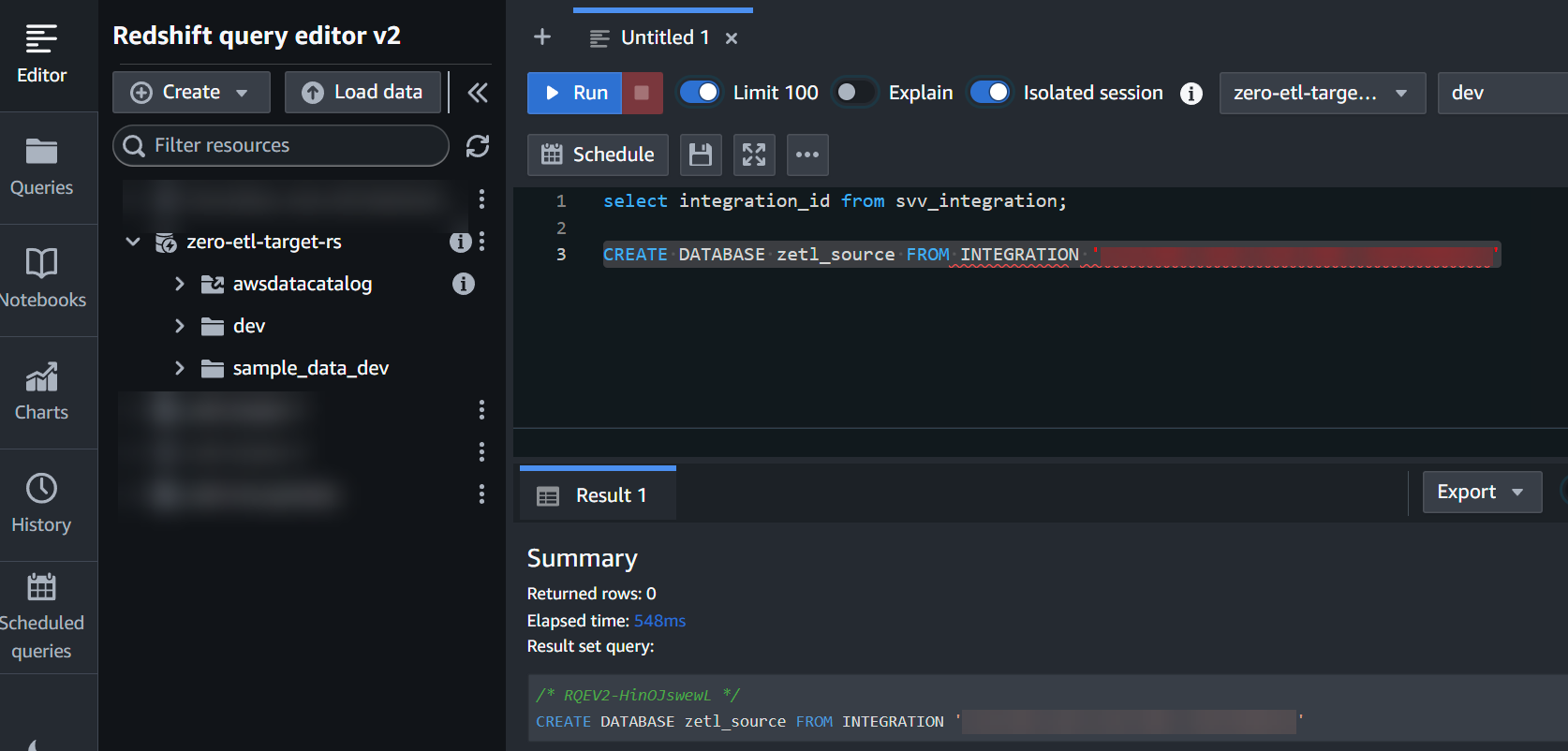
L'integrazione è ora completa e un'intera istantanea dell'origine rifletterà com'è nella destinazione. Le modifiche in corso verranno sincronizzate quasi in tempo reale.
Analizzare i dati transazionali quasi in tempo reale
Ora possiamo eseguire analisi sui dati operativi di TICKIT.
Popolare i dati TICKIT di origine
Per popolare i dati di origine, completare i seguenti passaggi:
- Copiare i file di dati di input CSV in una directory locale. Quello che segue è un comando di esempio:
aws s3 cp 's3://redshift-blogs/zero-etl-integration/data/tickit' . --recursive
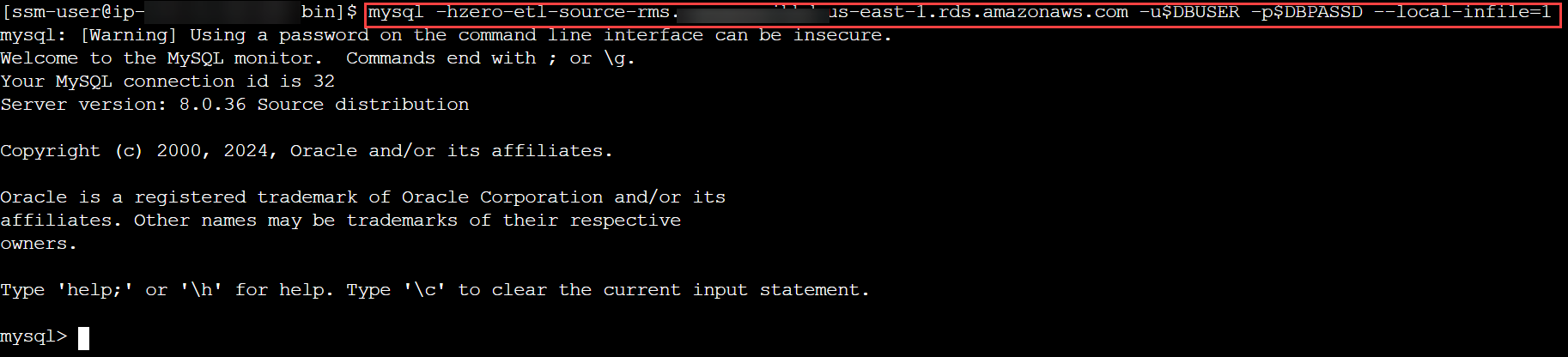
- Connettiti al tuo cluster RDS for MySQL e crea un database o uno schema per il modello dati TICKIT, verifica che le tabelle in quello schema abbiano una chiave primaria e avvia il processo di caricamento:
mysql -h <rds_db_instance_endpoint> -u admin -p password --local-infile=1
- Utilizza il seguente comandi CREA TABELLA.
- Caricare i dati dai file locali utilizzando il comando LOAD DATA.
Quanto segue è un esempio. Tieni presente che il file CSV di input è suddiviso in più file. Questo comando deve essere eseguito per ogni file se si desidera caricare tutti i dati. A scopo dimostrativo, dovrebbe funzionare anche un caricamento parziale dei dati.

Analizza i dati TICKIT di origine nella destinazione
Nella console Amazon Redshift, apri l'editor di query v2 utilizzando il database creato come parte della configurazione di integrazione. Utilizza il codice seguente per convalidare il seed o l'attività CDC:

Ora puoi applicare la logica aziendale per le trasformazioni direttamente sui dati che sono stati replicati nel data warehouse. Puoi anche utilizzare tecniche di ottimizzazione delle prestazioni come la creazione di una vista materializzata Redshift che unisca le tabelle replicate e altre tabelle locali per migliorare le prestazioni delle query per le tue query analitiche.
Controllo
Puoi eseguire query sulle seguenti visualizzazioni di sistema e tabelle in Amazon Redshift per ottenere informazioni sulle integrazioni zero ETL con Amazon Redshift:
Per visualizzare le metriche relative all'integrazione pubblicate in Amazon Cloud Watch, apri la console Amazon Redshift. Scegliere Integrazioni Zero-ETL nel riquadro di navigazione e scegli l'integrazione per visualizzare le metriche delle attività.
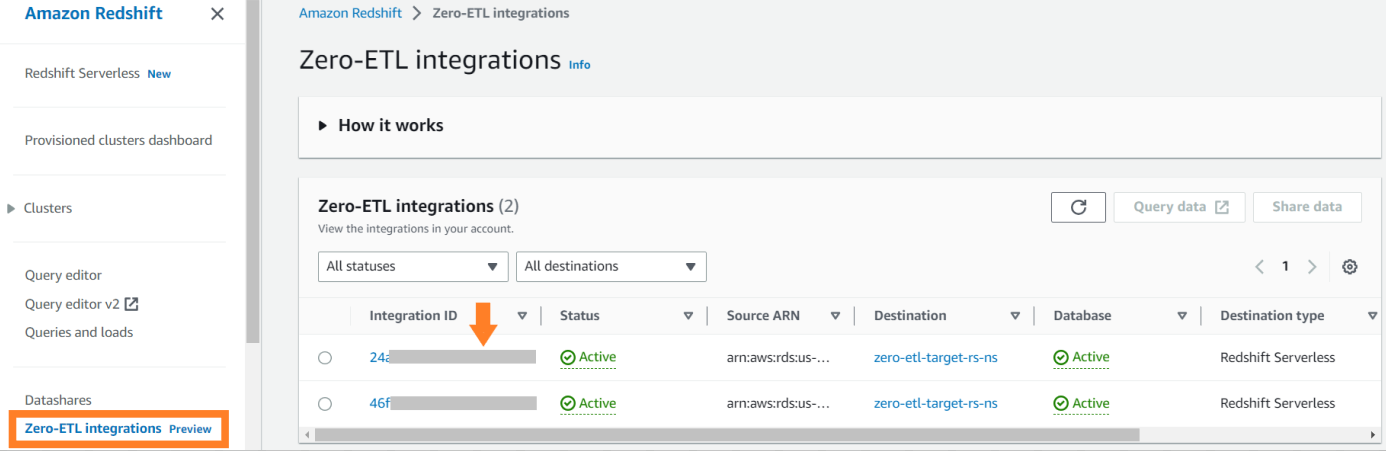
I parametri disponibili sulla console Amazon Redshift sono parametri di integrazione e statistiche di tabella, con le statistiche di tabella che forniscono dettagli di ciascuna tabella replicata da Amazon RDS per MySQL ad Amazon Redshift.

Le metriche di integrazione contengono il conteggio dei successi e degli errori di replica delle tabelle e i dettagli sui ritardi.
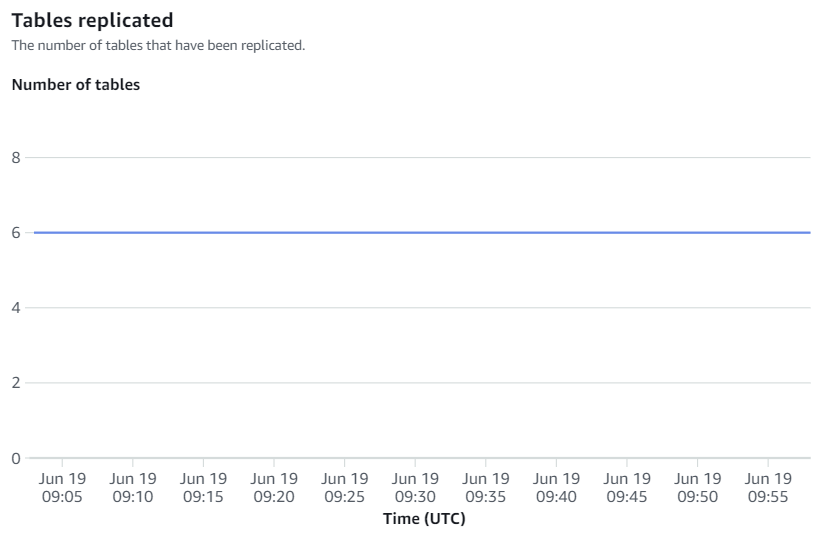
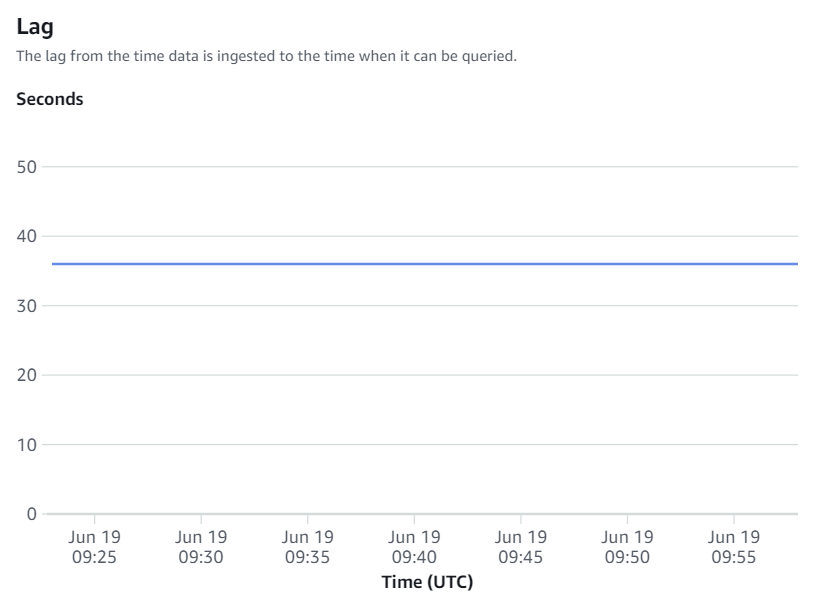
Risincronizzazione manuale
L'integrazione zero-ETL avvierà automaticamente una risincronizzazione se lo stato di sincronizzazione di una tabella viene visualizzato come non riuscito o se è necessaria una risincronizzazione. Ma nel caso in cui la risincronizzazione automatica fallisca, puoi avviare una risincronizzazione con granularità a livello di tabella:
ALTER DATABASE zetl_source INTEGRATION REFRESH TABLES tbl1, tbl2;
Una tabella può entrare in uno stato non riuscito per diversi motivi:
- La chiave primaria è stata rimossa dalla tabella. In questi casi, è necessario aggiungere nuovamente la chiave primaria ed eseguire il comando ALTER menzionato in precedenza.
- Durante la replica viene rilevato un valore non valido oppure viene aggiunta una nuova colonna alla tabella con un tipo di dati non supportato. In questi casi, è necessario rimuovere la colonna con il tipo di dati non supportato ed eseguire il comando ALTER menzionato in precedenza.
- Un errore interno, in rari casi, può causare un errore nella tabella. Il comando ALTER dovrebbe risolverlo.
ripulire
Quando elimini un'integrazione zero-ETL, i dati transazionali non vengono eliminati dai database RDS di origine o Redshift di destinazione, ma Amazon RDS non invia nuove modifiche a Amazon Redshift.
Per eliminare un'integrazione zero-ETL, completa i seguenti passaggi:
- Nella console Amazon RDS, scegli Integrazioni Zero-ETL nel pannello di navigazione.
- Selezionare l'integrazione zero-ETL che si desidera eliminare e scegliere Elimina.
- Per confermare l'eliminazione, scegli Elimina.

Conclusione
In questo post ti abbiamo mostrato come configurare un'integrazione zero ETL da Amazon RDS for MySQL ad Amazon Redshift. Ciò riduce al minimo la necessità di mantenere pipeline di dati complesse e consente analisi quasi in tempo reale sui dati transazionali e operativi.
Per ulteriori informazioni sull'integrazione zero-ETL di Amazon RDS con Amazon Redshift, fare riferimento a Utilizzo delle integrazioni zero-ETL di Amazon RDS con Amazon Redshift (anteprima).
Informazioni sugli autori
 Gentile Oke è un architetto senior di soluzioni specializzate in Redshift che ha lavorato presso Amazon Web Services per tre anni. È titolare della certificazione SA Associate, Security Specialty e Analytics Speciality con certificazione AWS, con sede nel Queens, New York.
Gentile Oke è un architetto senior di soluzioni specializzate in Redshift che ha lavorato presso Amazon Web Services per tre anni. È titolare della certificazione SA Associate, Security Specialty e Analytics Speciality con certificazione AWS, con sede nel Queens, New York.
 Aditya Samant è un veterano del settore dei database relazionali con oltre 2 decenni di esperienza di lavoro con database commerciali e open source. Attualmente lavora presso Amazon Web Services come Principal Database Specialist Solutions Architect. Nel suo ruolo, trascorre il tempo lavorando con i clienti progettando architetture native del cloud scalabili, sicure e robuste. Aditya lavora a stretto contatto con i team di assistenza e collabora alla progettazione e alla fornitura delle nuove funzionalità per i database gestiti di Amazon.
Aditya Samant è un veterano del settore dei database relazionali con oltre 2 decenni di esperienza di lavoro con database commerciali e open source. Attualmente lavora presso Amazon Web Services come Principal Database Specialist Solutions Architect. Nel suo ruolo, trascorre il tempo lavorando con i clienti progettando architetture native del cloud scalabili, sicure e robuste. Aditya lavora a stretto contatto con i team di assistenza e collabora alla progettazione e alla fornitura delle nuove funzionalità per i database gestiti di Amazon.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/unlock-insights-on-amazon-rds-for-mysql-data-with-zero-etl-integration-to-amazon-redshift/

