Questo post è stato scritto da Goktug Cinar, Michael Binder e Adrian Horvath del Bosch Center for Artificial Intelligence (BCAI).
La previsione delle entrate è un compito impegnativo ma cruciale per le decisioni aziendali strategiche e la pianificazione fiscale nella maggior parte delle organizzazioni. Spesso, la previsione delle entrate viene eseguita manualmente dagli analisti finanziari ed è sia soggettiva che dispendiosa in termini di tempo. Tali sforzi manuali sono particolarmente impegnativi per le organizzazioni aziendali multinazionali su larga scala che richiedono previsioni dei ricavi su un'ampia gamma di gruppi di prodotti e aree geografiche a più livelli di granularità. Ciò richiede non solo accuratezza ma anche coerenza gerarchica delle previsioni.
Bosch è una multinazionale con entità che operano in più settori, tra cui automotive, soluzioni industriali e beni di consumo. Dato l'impatto di una previsione dei ricavi accurata e coerente su operazioni aziendali sane, il Centro Bosch per l'Intelligenza Artificiale (BCAI) ha investito molto nell'uso dell'apprendimento automatico (ML) per migliorare l'efficienza e l'accuratezza dei processi di pianificazione finanziaria. L'obiettivo è alleviare i processi manuali fornendo ragionevoli previsioni dei ricavi di base tramite ML, con solo aggiustamenti occasionali necessari agli analisti finanziari che utilizzano la loro conoscenza del settore e del dominio.
Per raggiungere questo obiettivo, BCAI ha sviluppato un framework di previsione interno in grado di fornire previsioni gerarchiche su larga scala tramite insiemi personalizzati di un'ampia gamma di modelli di base. Un meta-studente seleziona i modelli con le migliori prestazioni in base alle caratteristiche estratte da ciascuna serie temporale. Viene quindi calcolata la media delle previsioni dei modelli selezionati per ottenere la previsione aggregata. Il design dell'architettura è modularizzato ed estensibile attraverso l'implementazione di un'interfaccia in stile REST, che consente il miglioramento continuo delle prestazioni tramite l'inclusione di modelli aggiuntivi.
BCAI ha collaborato con il Laboratorio di soluzioni Amazon ML (MLSL) per incorporare gli ultimi progressi nei modelli basati sulla rete neurale profonda (DNN) per la previsione dei ricavi. I recenti progressi nei previsori neurali hanno dimostrato prestazioni all'avanguardia per molti problemi pratici di previsione. Rispetto ai modelli di previsione tradizionali, molti previsori neurali possono incorporare covariate o metadati aggiuntivi delle serie temporali. Includiamo CNN-QR e DeepAR+, due modelli standard in Previsioni Amazon, nonché un modello Transformer personalizzato addestrato utilizzando Amazon Sage Maker. I tre modelli coprono un insieme rappresentativo delle dorsali dell'encoder spesso utilizzate nei previsori neurali: rete neurale convoluzionale (CNN), rete neurale ricorrente sequenziale (RNN) e codificatori basati su trasformatore.
Una delle sfide chiave affrontate dalla partnership BCAI-MLSL è stata quella di fornire previsioni solide e ragionevoli sotto l'impatto del COVID-19, un evento globale senza precedenti che causa una grande volatilità sui risultati finanziari aziendali globali. Poiché i previsori neurali sono addestrati su dati storici, le previsioni generate sulla base di dati fuori distribuzione dai periodi più volatili potrebbero essere imprecise e inaffidabili. Pertanto, abbiamo proposto l'aggiunta di un meccanismo di attenzione mascherata nell'architettura Transformer per affrontare questo problema.
I previsori neurali possono essere raggruppati come un unico modello di insieme o incorporati individualmente nell'universo del modello Bosch e accessibili facilmente tramite gli endpoint dell'API REST. Proponiamo un approccio per riunire i previsori neurali attraverso risultati di backtest, che fornisce prestazioni competitive e solide nel tempo. Inoltre, abbiamo studiato e valutato una serie di tecniche di riconciliazione gerarchica classiche per garantire che le previsioni si aggreghino in modo coerente tra gruppi di prodotti, aree geografiche e organizzazioni aziendali.
In questo post dimostriamo quanto segue:
- Come applicare l'addestramento del modello personalizzato di Forecast e SageMaker per problemi di previsione gerarchici di serie temporali su larga scala
- Come combinare modelli personalizzati con modelli standard di Forecast
- Come ridurre l'impatto di eventi dirompenti come il COVID-19 sui problemi di previsione
- Come creare un flusso di lavoro di previsione end-to-end su AWS
Le sfide
Abbiamo affrontato due sfide: la creazione di previsioni dei ricavi su larga scala gerarchiche e l'impatto della pandemia di COVID-19 sulle previsioni a lungo termine.
Previsione dei ricavi su larga scala gerarchica
Gli analisti finanziari hanno il compito di prevedere i dati finanziari chiave, comprese le entrate, i costi operativi e le spese di ricerca e sviluppo. Queste metriche forniscono informazioni dettagliate sulla pianificazione aziendale a diversi livelli di aggregazione e consentono il processo decisionale basato sui dati. Qualsiasi soluzione di previsione automatizzata deve fornire previsioni a qualsiasi livello arbitrario di aggregazione della linea di business. In Bosch, le aggregazioni possono essere immaginate come serie temporali raggruppate come una forma più generale di struttura gerarchica. La figura seguente mostra un esempio semplificato con una struttura a due livelli, che imita la struttura gerarchica di previsione delle entrate di Bosch. Le entrate totali sono suddivise in più livelli di aggregazione in base al prodotto e alla regione.
Il numero totale di serie temporali che devono essere previste in Bosch è dell'ordine di milioni. Si noti che le serie temporali di livello superiore possono essere suddivise per prodotti o regioni, creando percorsi multipli per le previsioni di livello inferiore. Le entrate devono essere previste in ogni nodo della gerarchia con un orizzonte di previsione di 12 mesi nel futuro. Sono disponibili dati storici mensili.
La struttura gerarchica può essere rappresentata utilizzando la seguente forma con la notazione di una matrice sommatoria S (Hyndman e Athanasopoulos):
![]()
In questa equazione, Y è uguale a quanto segue:

Qui, b rappresenta la serie temporale di livello inferiore alla volta t.
Impatti della pandemia di COVID-19
La pandemia di COVID-19 ha comportato sfide significative per le previsioni a causa dei suoi effetti dirompenti e senza precedenti su quasi tutti gli aspetti del lavoro e della vita sociale. Per la previsione delle entrate a lungo termine, l'interruzione ha portato anche impatti a valle inaspettati. Per illustrare questo problema, la figura seguente mostra una serie temporale di esempio in cui i ricavi del prodotto hanno subito un calo significativo all'inizio della pandemia e si sono gradualmente ripresi in seguito. Un tipico modello di previsione neurale prenderà i dati sulle entrate, incluso il periodo COVID fuori distribuzione (OOD) come input del contesto storico, nonché la verità di base per l'addestramento del modello. Di conseguenza, le previsioni prodotte non sono più affidabili.

Approcci di modellazione
In questa sezione, discutiamo i nostri vari approcci di modellazione.
Previsioni Amazon
Forecast è un servizio AI/ML completamente gestito di AWS che fornisce modelli di previsione di serie temporali preconfigurati e all'avanguardia. Combina queste offerte con le sue capacità interne per l'ottimizzazione automatizzata degli iperparametri, la modellazione dell'insieme (per i modelli forniti da Forecast) e la generazione di previsioni probabilistiche. Ciò consente di acquisire facilmente set di dati personalizzati, preelaborare i dati, addestrare modelli di previsione e generare previsioni affidabili. Il design modulare del servizio ci consente inoltre di interrogare e combinare facilmente le previsioni da modelli personalizzati aggiuntivi sviluppati in parallelo.
Incorporiamo due previsioni neurali di Forecast: CNN-QR e DeepAR+. Entrambi sono metodi di deep learning supervisionati che addestrano un modello globale per l'intero set di dati di serie temporali. Entrambi i modelli CNNQR e DeepAR+ possono acquisire informazioni statiche sui metadati su ciascuna serie temporale, che nel nostro caso sono il prodotto, la regione e l'organizzazione aziendale corrispondenti. Inoltre, aggiungono automaticamente caratteristiche temporali come il mese dell'anno come parte dell'input del modello.
Trasformatore con mascherine di attenzione per il COVID
L'architettura del trasformatore (Vaswani et al.), originariamente progettato per l'elaborazione del linguaggio naturale (NLP), è emerso di recente come una scelta architettonica popolare per la previsione di serie temporali. Qui, abbiamo usato l'architettura Transformer descritta in Zhou et al. senza log probabilistico scarsa attenzione. Il modello utilizza un tipico progetto di architettura combinando un encoder e un decoder. Per la previsione delle entrate, configuriamo il decodificatore per produrre direttamente la previsione dell'orizzonte di 12 mesi invece di generare la previsione mese per mese in modo autoregressivo. In base alla frequenza delle serie temporali, come variabile di input vengono aggiunte ulteriori funzioni relative al tempo, come il mese dell'anno. Ulteriori variabili categoriali che descrivono le metainformazioni (prodotto, regione, organizzazione aziendale) vengono immesse nella rete tramite un livello di incorporamento addestrabile.
Il diagramma seguente illustra l'architettura Transformer e il meccanismo di mascheramento dell'attenzione. Il mascheramento dell'attenzione viene applicato a tutti i livelli di codificatore e decodificatore, come evidenziato in arancione, per evitare che i dati OOD influiscano sulle previsioni.

Riduciamo l'impatto delle finestre di contesto OOD aggiungendo maschere di attenzione. Il modello è addestrato per applicare pochissima attenzione al periodo COVID che contiene valori anomali tramite mascheramento ed esegue previsioni con informazioni mascherate. La maschera di attenzione viene applicata in ogni livello del decodificatore e dell'architettura del codificatore. La finestra mascherata può essere specificata manualmente o tramite un algoritmo di rilevamento dei valori anomali. Inoltre, quando si utilizza una finestra temporale contenente valori anomali come etichette di formazione, le perdite non vengono propagate all'indietro. Questo metodo basato sul mascheramento dell'attenzione può essere applicato per gestire interruzioni e casi di OOD causati da altri eventi rari e migliorare la solidità delle previsioni.
Completo modello
L'insieme di modelli spesso supera i singoli modelli per la previsione: migliora la generalizzabilità del modello ed è più efficace nella gestione di dati di serie temporali con caratteristiche variabili in termini di periodicità e intermittenza. Incorporiamo una serie di strategie di insieme di modelli per migliorare le prestazioni del modello e la solidità delle previsioni. Una forma comune di insieme di modelli di apprendimento profondo consiste nell'aggregare i risultati delle esecuzioni del modello con diverse inizializzazioni di peso casuale o da epoche di addestramento diverse. Utilizziamo questa strategia per ottenere previsioni per il modello Transformer.
Per costruire ulteriormente un insieme su diverse architetture di modelli, come Transformer, CNNQR e DeepAR+, utilizziamo una strategia di ensemble pan-model che seleziona i modelli k più performanti per ciascuna serie storica in base ai risultati del backtest e ne ottiene medie. Poiché i risultati dei test retrospettivi possono essere esportati direttamente da modelli di Forecast addestrati, questa strategia ci consente di sfruttare servizi chiavi in mano come Forecast con miglioramenti ottenuti da modelli personalizzati come Transformer. Un tale approccio di insieme di modelli end-to-end non richiede la formazione di un meta-studente o il calcolo delle caratteristiche delle serie temporali per la selezione del modello.
Riconciliazione gerarchica
Il framework è adattivo per incorporare un'ampia gamma di tecniche come fasi di postelaborazione per la riconciliazione gerarchica delle previsioni, tra cui la riconciliazione bottom-up (BU), la riconciliazione top-down con le proporzioni di previsione (TDFP), i minimi quadrati ordinari (OLS) e i minimi quadrati ponderati ( WLS). Tutti i risultati sperimentali in questo post sono riportati utilizzando la riconciliazione top-down con le proporzioni di previsione.
Panoramica sull'architettura
Abbiamo sviluppato un flusso di lavoro end-to-end automatizzato su AWS per generare previsioni dei ricavi utilizzando servizi tra cui Forecast, SageMaker, Servizio di archiviazione semplice Amazon (Amazon S3), AWS Lambda, Funzioni AWS Stepe Kit di sviluppo cloud AWS (AWS CDK). La soluzione distribuita fornisce previsioni di serie temporali individuali tramite un'API REST utilizzando Gateway API Amazon, restituendo i risultati nel formato JSON predefinito.
Il diagramma seguente illustra il flusso di lavoro di previsione end-to-end.

Le considerazioni di progettazione chiave per l'architettura sono versatilità, prestazioni e facilità d'uso. Il sistema dovrebbe essere sufficientemente versatile da incorporare un insieme diversificato di algoritmi durante lo sviluppo e la distribuzione, con modifiche minime richieste, e può essere facilmente esteso quando si aggiungono nuovi algoritmi in futuro. Il sistema dovrebbe anche aggiungere un sovraccarico minimo e supportare la formazione parallela sia per Forecast che per SageMaker per ridurre i tempi di formazione e ottenere più rapidamente le ultime previsioni. Infine, il sistema dovrebbe essere semplice da usare a scopo di sperimentazione.
Il flusso di lavoro end-to-end viene eseguito in sequenza attraverso i seguenti moduli:
- Un modulo di preelaborazione per la riformattazione e la trasformazione dei dati
- Un modulo di formazione del modello che incorpora sia il modello di previsione che il modello personalizzato su SageMaker (entrambi in esecuzione in parallelo)
- Un modulo di post-elaborazione che supporta l'insieme del modello, la riconciliazione gerarchica, le metriche e la generazione di report
Step Functions organizza e orchestra il flusso di lavoro da un capo all'altro come una macchina a stati. L'esecuzione della macchina a stati è configurata con un file JSON contenente tutte le informazioni necessarie, inclusa la posizione dei file CSV delle entrate storiche in Amazon S3, l'ora di inizio della previsione e le impostazioni dell'iperparametro del modello per eseguire il flusso di lavoro end-to-end. Vengono create chiamate asincrone per parallelizzare l'addestramento del modello nella macchina a stati utilizzando le funzioni Lambda. Tutti i dati storici, i file di configurazione, i risultati delle previsioni e i risultati intermedi come i risultati dei test retrospettivi sono archiviati in Amazon S3. L'API REST si basa su Amazon S3 per fornire un'interfaccia interrogabile per eseguire query sui risultati delle previsioni. Il sistema può essere esteso per incorporare nuovi modelli di previsione e funzioni di supporto come la generazione di report di visualizzazione delle previsioni.
Valutazione
In questa sezione, descriviamo in dettaglio la configurazione dell'esperimento. I componenti chiave includono il set di dati, le metriche di valutazione, le finestre di backtest e l'impostazione del modello e la formazione.
dataset
Per proteggere la privacy finanziaria di Bosch durante l'utilizzo di un set di dati significativo, abbiamo utilizzato un set di dati sintetico con caratteristiche statistiche simili a un set di dati sulle entrate del mondo reale di un'unità aziendale di Bosch. Il set di dati contiene 1,216 serie temporali in totale con ricavi registrati con frequenza mensile, da gennaio 2016 ad aprile 2022. Il set di dati viene fornito con 877 serie temporali al livello più granulare (serie temporale inferiore), con una corrispondente struttura di serie temporali raggruppate rappresentata come matrice sommatoria S. Ogni serie temporale è associata a tre attributi categoriali statici, che corrispondono a categoria di prodotto, regione e unità organizzativa nel set di dati reale (anonimizzato nei dati sintetici).
Metriche di valutazione
Per valutare le prestazioni del modello ed eseguire l'analisi comparativa, che sono le metriche standard utilizzate da Bosch, utilizziamo l'errore percentuale assoluta mediana dell'arcotangente (MAAPE mediano) e il MAAPE ponderato. MAAPE affronta le carenze della metrica MAPE (Mean Absolute Percentage Error) comunemente utilizzata nel contesto aziendale. Median-MAAPE fornisce una panoramica delle prestazioni del modello calcolando la mediana dei MAAPE calcolati individualmente su ciascuna serie temporale. Weighted-MAAPE riporta una combinazione ponderata dei singoli MAAPE. I pesi sono la proporzione delle entrate per ciascuna serie temporale rispetto alle entrate aggregate dell'intero set di dati. Weighted-MAAPE riflette meglio gli impatti sul business a valle dell'accuratezza delle previsioni. Entrambe le metriche sono riportate sull'intero set di dati di 1,216 serie temporali.
Finestre di backtest
Utilizziamo finestre di backtest a rotazione di 12 mesi per confrontare le prestazioni del modello. La figura seguente illustra le finestre di backtest utilizzate negli esperimenti ed evidenzia i dati corrispondenti utilizzati per l'addestramento e l'ottimizzazione degli iperparametri (HPO). Per le finestre di backtest dopo l'inizio di COVID-19, il risultato è influenzato dagli input OOD da aprile a maggio 2020, in base a ciò che abbiamo osservato dalle serie temporali dei ricavi.

Configurazione e formazione del modello
Per l'addestramento di Transformer, abbiamo utilizzato la perdita di quantile e scalato ogni serie temporale utilizzando il suo valore medio storico prima di inserirlo in Transformer e calcolare la perdita di addestramento. Le previsioni finali vengono ridimensionate per calcolare le metriche di precisione, utilizzando il MeanScaler implementato in GluonTS. Utilizziamo una finestra di contesto con i dati sulle entrate mensili degli ultimi 18 mesi, selezionati tramite HPO nella finestra di backtest da luglio 2018 a giugno 2019. Ulteriori metadati su ciascuna serie temporale sotto forma di variabili categoriali statiche vengono inseriti nel modello tramite un incorporamento strato prima di alimentarlo agli strati del trasformatore. Addestriamo il Transformer con cinque diverse inizializzazioni di peso casuale e facciamo la media dei risultati delle previsioni delle ultime tre epoche per ciascuna corsa, in una media totale di 15 modelli. Le cinque esecuzioni di addestramento del modello possono essere parallelizzate per ridurre i tempi di addestramento. Per il Transformer mascherato, indichiamo i mesi da aprile a maggio 2020 come valori anomali.
Per tutto l'addestramento del modello di previsione, abbiamo abilitato l'HPO automatico, che può selezionare il modello e i parametri di addestramento in base a un periodo di backtest specificato dall'utente, che è impostato sugli ultimi 12 mesi nella finestra dei dati utilizzata per l'addestramento e l'HPO.
Risultati dell'esperimento
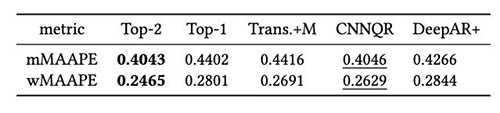
Addestriamo Transformers mascherati e non mascherati utilizzando lo stesso set di iperparametri e abbiamo confrontato le loro prestazioni per le finestre di backtest immediatamente dopo lo shock COVID-19. Nel Transformer mascherato, i due mesi mascherati sono aprile e maggio 2020. La tabella seguente mostra i risultati di una serie di periodi di backtest con finestre di previsione di 12 mesi a partire da giugno 2020. Possiamo osservare che il Transformer mascherato supera costantemente la versione non mascherata .

Abbiamo ulteriormente eseguito la valutazione sulla strategia dell'insieme del modello sulla base dei risultati del backtest. In particolare, confrontiamo i due casi in cui viene selezionato solo il modello con le migliori prestazioni rispetto a quando vengono selezionati i due modelli con le migliori prestazioni e la media del modello viene eseguita calcolando il valore medio delle previsioni. Confrontiamo le prestazioni dei modelli base e dei modelli ensemble nelle figure seguenti. Si noti che nessuno dei previsori neurali supera costantemente gli altri per le finestre di rollback del test.


La tabella seguente mostra che, in media, la modellazione d'insieme dei primi due modelli offre le migliori prestazioni. CNNQR fornisce il secondo miglior risultato.
Conclusione
Questo post ha dimostrato come creare una soluzione ML end-to-end per problemi di previsione su larga scala combinando Forecast e un modello personalizzato addestrato su SageMaker. A seconda delle esigenze aziendali e delle conoscenze ML, è possibile utilizzare un servizio completamente gestito come Forecast per alleggerire il processo di creazione, training e distribuzione di un modello di previsione; costruisci il tuo modello personalizzato con meccanismi di ottimizzazione specifici con SageMaker; oppure eseguire l'ensemble del modello combinando i due servizi.
Se desideri assistenza per accelerare l'uso del ML nei tuoi prodotti e servizi, contatta il Laboratorio di soluzioni Amazon ML .
Riferimenti
Hyndman RJ, Athanasopoulos G. Previsione: principi e pratica. Otesti; 2018 maggio 8.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. L'attenzione è tutto ciò che serve. Progressi nei sistemi neurali di elaborazione delle informazioni. 2017;30.
Zhou H, Zhang S, Peng J, Zhang S, Li J, Xiong H, Zhang W. Informatore: oltre il trasformatore efficiente per la previsione di serie temporali di lunghe sequenze. InProceedings of AAAI 2021 Feb 2.
Informazioni sugli autori
 Göktug Cinar è uno scienziato capo del ML e responsabile tecnico del ML e delle previsioni basate sulle statistiche presso Robert Bosch LLC e Bosch Center for Artificial Intelligence. Dirige la ricerca sui modelli di previsione, il consolidamento gerarchico e le tecniche di combinazione dei modelli, nonché il team di sviluppo software che ridimensiona questi modelli e li serve come parte del software interno di previsione finanziaria end-to-end.
Göktug Cinar è uno scienziato capo del ML e responsabile tecnico del ML e delle previsioni basate sulle statistiche presso Robert Bosch LLC e Bosch Center for Artificial Intelligence. Dirige la ricerca sui modelli di previsione, il consolidamento gerarchico e le tecniche di combinazione dei modelli, nonché il team di sviluppo software che ridimensiona questi modelli e li serve come parte del software interno di previsione finanziaria end-to-end.
 Michele Legante è un Product Owner presso Bosch Global Services, dove coordina lo sviluppo, l'implementazione e l'implementazione dell'applicazione di analisi predittiva a livello aziendale per la previsione automatizzata su larga scala basata sui dati di cifre chiave finanziarie.
Michele Legante è un Product Owner presso Bosch Global Services, dove coordina lo sviluppo, l'implementazione e l'implementazione dell'applicazione di analisi predittiva a livello aziendale per la previsione automatizzata su larga scala basata sui dati di cifre chiave finanziarie.
 Adrian Horvat è uno sviluppatore di software presso il Bosch Center for Artificial Intelligence, dove sviluppa e gestisce sistemi per creare previsioni basate su vari modelli di previsione.
Adrian Horvat è uno sviluppatore di software presso il Bosch Center for Artificial Intelligence, dove sviluppa e gestisce sistemi per creare previsioni basate su vari modelli di previsione.
 Panpan Xu è un Senior Applied Scientist e Manager con Amazon ML Solutions Lab presso AWS. Sta lavorando alla ricerca e allo sviluppo di algoritmi di Machine Learning per applicazioni dei clienti ad alto impatto in una varietà di verticali industriali per accelerare la loro adozione di intelligenza artificiale e cloud. Il suo interesse di ricerca include l'interpretazione dei modelli, l'analisi causale, l'intelligenza artificiale umana e la visualizzazione interattiva dei dati.
Panpan Xu è un Senior Applied Scientist e Manager con Amazon ML Solutions Lab presso AWS. Sta lavorando alla ricerca e allo sviluppo di algoritmi di Machine Learning per applicazioni dei clienti ad alto impatto in una varietà di verticali industriali per accelerare la loro adozione di intelligenza artificiale e cloud. Il suo interesse di ricerca include l'interpretazione dei modelli, l'analisi causale, l'intelligenza artificiale umana e la visualizzazione interattiva dei dati.
 Jasleen Grewal è una scienziata applicata presso Amazon Web Services, dove lavora con i clienti AWS per risolvere i problemi del mondo reale utilizzando l'apprendimento automatico, con particolare attenzione alla medicina di precisione e alla genomica. Ha un forte background in bioinformatica, oncologia e genomica clinica. È appassionata di utilizzare AI/ML e servizi cloud per migliorare l'assistenza ai pazienti.
Jasleen Grewal è una scienziata applicata presso Amazon Web Services, dove lavora con i clienti AWS per risolvere i problemi del mondo reale utilizzando l'apprendimento automatico, con particolare attenzione alla medicina di precisione e alla genomica. Ha un forte background in bioinformatica, oncologia e genomica clinica. È appassionata di utilizzare AI/ML e servizi cloud per migliorare l'assistenza ai pazienti.
 Selvan Sentivel è un Senior ML Engineer presso Amazon ML Solutions Lab presso AWS, incentrato sull'assistenza ai clienti in materia di machine learning, problemi di deep learning e soluzioni di machine learning end-to-end. È stato uno dei fondatori dell'ingegneria di Amazon Comprehend Medical e ha contribuito alla progettazione e all'architettura di diversi servizi di intelligenza artificiale di AWS.
Selvan Sentivel è un Senior ML Engineer presso Amazon ML Solutions Lab presso AWS, incentrato sull'assistenza ai clienti in materia di machine learning, problemi di deep learning e soluzioni di machine learning end-to-end. È stato uno dei fondatori dell'ingegneria di Amazon Comprehend Medical e ha contribuito alla progettazione e all'architettura di diversi servizi di intelligenza artificiale di AWS.
 Rulin Zhang è un SDE con Amazon ML Solutions Lab presso AWS. Aiuta i clienti ad adottare i servizi di intelligenza artificiale di AWS creando soluzioni per affrontare problemi aziendali comuni.
Rulin Zhang è un SDE con Amazon ML Solutions Lab presso AWS. Aiuta i clienti ad adottare i servizi di intelligenza artificiale di AWS creando soluzioni per affrontare problemi aziendali comuni.
 Shane Rai è uno stratega Sr. ML con Amazon ML Solutions Lab presso AWS. Lavora con clienti in una vasta gamma di settori per risolvere le loro esigenze aziendali più urgenti e innovative utilizzando l'ampia gamma di servizi AI/ML basati su cloud di AWS.
Shane Rai è uno stratega Sr. ML con Amazon ML Solutions Lab presso AWS. Lavora con clienti in una vasta gamma di settori per risolvere le loro esigenze aziendali più urgenti e innovative utilizzando l'ampia gamma di servizi AI/ML basati su cloud di AWS.
 Lin Lee Cheong è un Applied Science Manager con il team Amazon ML Solutions Lab di AWS. Lavora con clienti strategici di AWS per esplorare e applicare l'intelligenza artificiale e l'apprendimento automatico per scoprire nuove informazioni e risolvere problemi complessi.
Lin Lee Cheong è un Applied Science Manager con il team Amazon ML Solutions Lab di AWS. Lavora con clienti strategici di AWS per esplorare e applicare l'intelligenza artificiale e l'apprendimento automatico per scoprire nuove informazioni e risolvere problemi complessi.

