Generatore di immagini Amazon Titan G1 è un modello da testo a immagine all'avanguardia, disponibile tramite Roccia Amazzonica, che è in grado di comprendere le istruzioni che descrivono più oggetti in vari contesti e cattura questi dettagli rilevanti nelle immagini che genera. È disponibile nelle regioni AWS Stati Uniti orientali (Virginia settentrionale) e Stati Uniti occidentali (Oregon) e può eseguire attività avanzate di modifica delle immagini come ritaglio intelligente, pittura interna e modifiche dello sfondo. Tuttavia, gli utenti vorrebbero adattare il modello a caratteristiche uniche nei set di dati personalizzati su cui il modello non è già addestrato. I set di dati personalizzati possono includere dati altamente proprietari che sono coerenti con le linee guida del tuo brand o con stili specifici come una campagna precedente. Per affrontare questi casi d'uso e generare immagini completamente personalizzate, puoi ottimizzare Amazon Titan Image Generator con i tuoi dati utilizzando modelli personalizzati per Amazon Bedrock.
Dalla generazione di immagini alla loro modifica, i modelli da testo a immagine hanno ampie applicazioni in tutti i settori. Possono migliorare la creatività dei dipendenti e fornire la capacità di immaginare nuove possibilità semplicemente con descrizioni testuali. Ad esempio, può aiutare gli architetti nella progettazione e nella pianificazione dei piani e consentire un'innovazione più rapida fornendo la possibilità di visualizzare vari progetti senza il processo manuale di creazione. Allo stesso modo, può aiutare nella progettazione in vari settori come la produzione, il design della moda nella vendita al dettaglio e il design di giochi semplificando la generazione di grafica e illustrazioni. I modelli da testo a immagine migliorano inoltre l'esperienza del cliente consentendo pubblicità personalizzata e chatbot visivi interattivi e coinvolgenti nei casi d'uso dei media e dell'intrattenimento.
In questo post, ti guidiamo attraverso il processo di messa a punto del modello Amazon Titan Image Generator per apprendere due nuove categorie: Ron il cane e Smila il gatto, i nostri animali domestici preferiti. Discuteremo di come preparare i dati per l'attività di ottimizzazione del modello e di come creare un processo di personalizzazione del modello in Amazon Bedrock. Infine, ti mostriamo come testare e distribuire il tuo modello ottimizzato Throughput assegnato.
 |
 |
| Ron il cane | Smila la gatta |
Valutazione delle capacità del modello prima di mettere a punto un lavoro
I modelli di base vengono addestrati su grandi quantità di dati, quindi è possibile che il tuo modello funzioni abbastanza bene fin da subito. Ecco perché è buona norma verificare se è effettivamente necessario ottimizzare il modello per il proprio caso d'uso o se è sufficiente un'ingegneria tempestiva. Proviamo a generare alcune immagini del cane Ron e del gatto Smila con il modello base di Amazon Titan Image Generator, come mostrato negli screenshot seguenti.
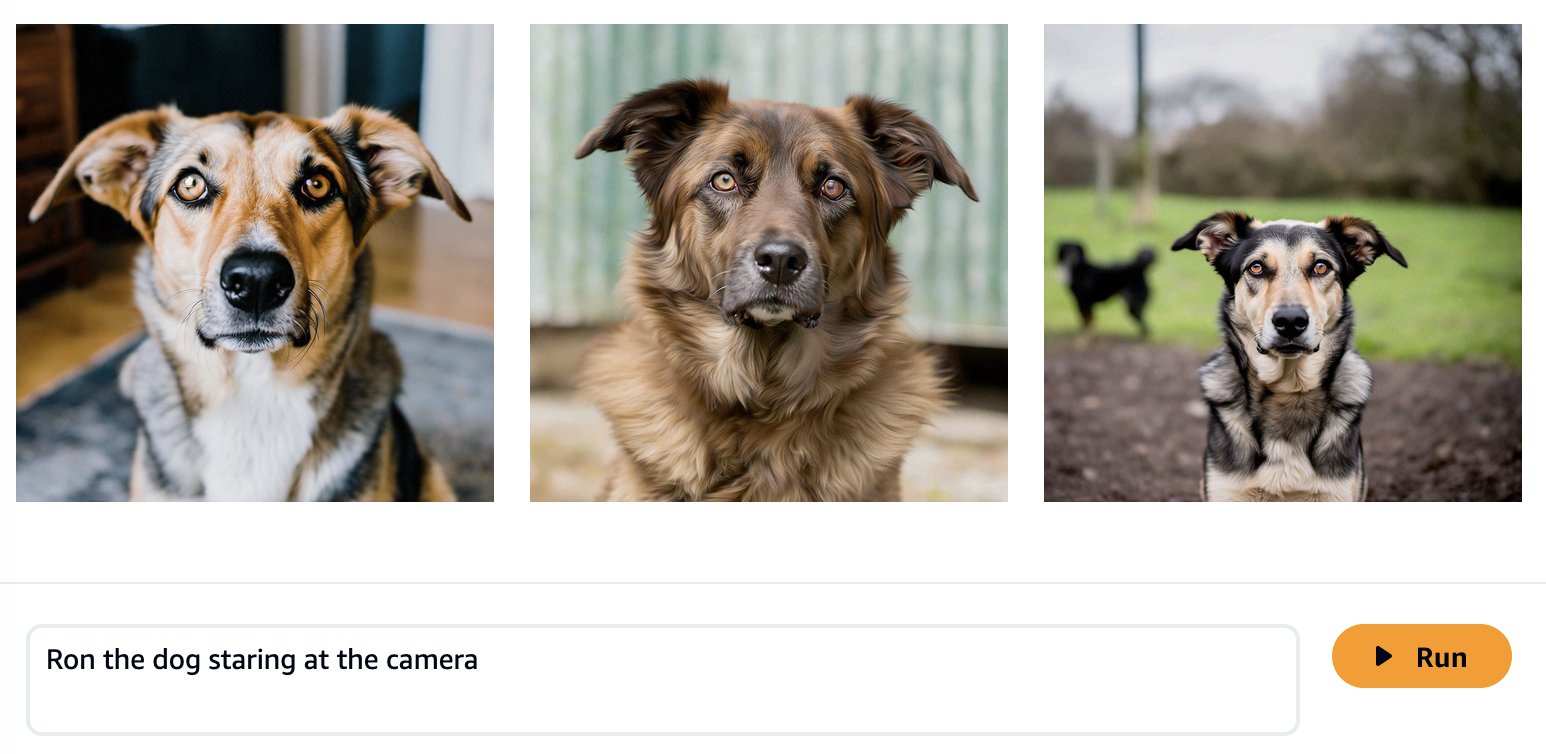

Come previsto, il modello pronto all'uso non conosce ancora Ron e Smila e gli output generati mostrano cani e gatti diversi. Con un po' di ingegneria tempestiva, possiamo fornire maggiori dettagli per avvicinarci all'aspetto dei nostri animali domestici preferiti.


Sebbene le immagini generate siano più simili a Ron e Smila, vediamo che il modello non è in grado di riprodurne la piena somiglianza. Iniziamo ora un lavoro di messa a punto con le foto di Ron e Smila per ottenere risultati coerenti e personalizzati.
Ottimizzazione del generatore di immagini Amazon Titan
Amazon Bedrock ti offre un'esperienza serverless per ottimizzare il tuo modello di generatore di immagini Amazon Titan. Devi solo preparare i dati e selezionare gli iperparametri e AWS gestirà il lavoro pesante per te.
Quando utilizzi il modello Amazon Titan Image Generator per la messa a punto, viene creata una copia di questo modello nell'account di sviluppo del modello AWS, di proprietà e gestito da AWS, e viene creato un processo di personalizzazione del modello. Questo lavoro accede quindi ai dati di messa a punto da un VPC e i pesi del modello Amazon Titan vengono aggiornati. Il nuovo modello viene quindi salvato in un file Servizio di archiviazione semplice Amazon (Amazon S3) situato nello stesso account di sviluppo del modello del modello pre-addestrato. Ora può essere utilizzato per l'inferenza solo dal tuo account e non è condiviso con nessun altro account AWS. Quando si esegue l'inferenza, si accede a questo modello tramite a calcolo della capacità fornita o direttamente, utilizzando inferenza batch per Amazon Bedrock. Indipendentemente dalla modalità di inferenza scelta, i tuoi dati rimangono nel tuo account e non vengono copiati su nessun account di proprietà di AWS né utilizzati per migliorare il modello Amazon Titan Image Generator.
Il diagramma seguente illustra questo flusso di lavoro.
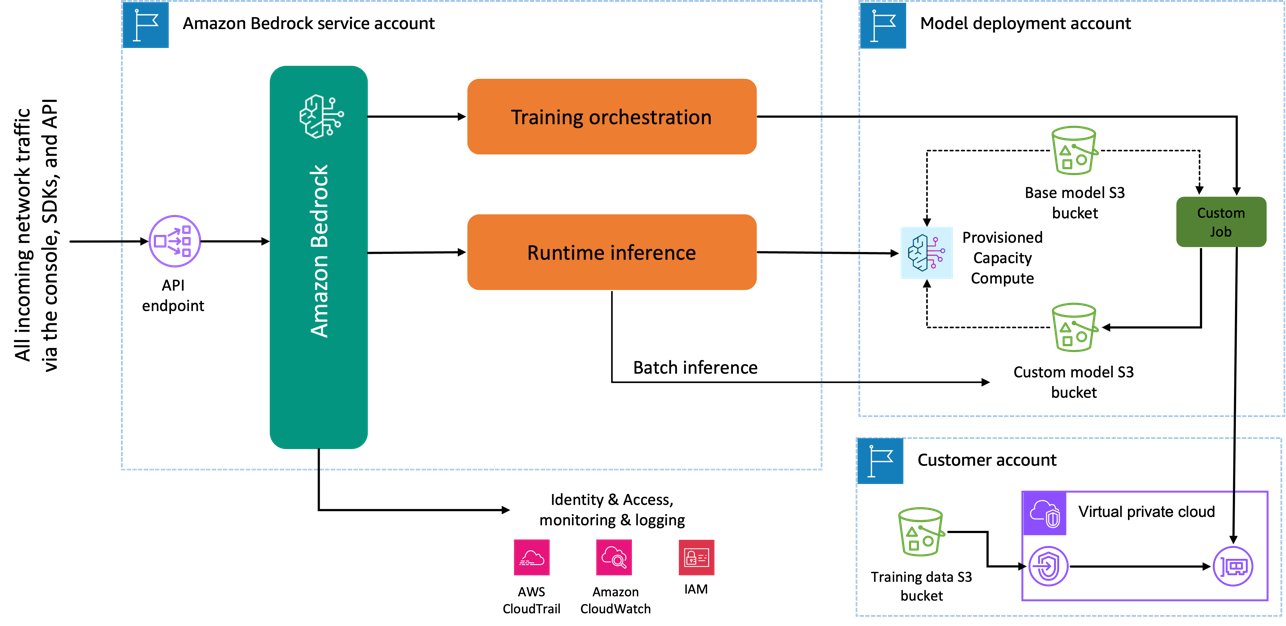
Privacy dei dati e sicurezza della rete
I tuoi dati utilizzati per la messa a punto, inclusi i prompt, nonché i modelli personalizzati, rimangono privati nel tuo account AWS. Non vengono condivisi né utilizzati per la formazione dei modelli o per il miglioramento dei servizi e non vengono condivisi con fornitori di modelli di terze parti. Tutti i dati utilizzati per la messa a punto sono crittografati in transito e a riposo. I dati rimangono nella stessa regione in cui viene elaborata la chiamata API. Puoi anche usare Collegamento privato AWS per creare una connessione privata tra l'account AWS in cui risiedono i tuoi dati e il VPC.
Preparazione dei dati
Prima di poter creare un processo di personalizzazione del modello, è necessario farlo preparare il set di dati di addestramento. Il formato del set di dati di addestramento dipende dal tipo di lavoro di personalizzazione che stai creando (ottimizzazione o pre-addestramento continuo) e dalla modalità dei dati (da testo a testo, da testo a immagine o da immagine a immagine). incorporamento). Per il modello Amazon Titan Image Generator, devi fornire le immagini che desideri utilizzare per la messa a punto e una didascalia per ciascuna immagine. Amazon Bedrock prevede che le tue immagini vengano archiviate su Amazon S3 e che le coppie di immagini e didascalie vengano fornite in un formato JSONL con più righe JSON.
Ogni riga JSON è un esempio contenente un riferimento immagine, l'URI S3 per un'immagine e una didascalia che include un prompt testuale per l'immagine. Le tue immagini devono essere in formato JPEG o PNG. Il codice seguente mostra un esempio del formato:
{"image-ref": "s3://bucket/path/to/image001.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image002.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image003.png", "caption": ""}
Poiché “Ron” e “Smila” sono nomi che potrebbero essere utilizzati anche in altri contesti, come il nome di una persona, aggiungiamo gli identificatori “Ron il cane” e “Smila il gatto” quando creiamo il prompt per mettere a punto il nostro modello . Sebbene non sia un requisito per il flusso di lavoro di messa a punto, queste informazioni aggiuntive forniscono maggiore chiarezza contestuale per il modello quando viene personalizzato per le nuove classi ed eviteranno la confusione di "Ron il cane" con una persona chiamata Ron e " Smila the cat” con la città Smila in Ucraina. Utilizzando questa logica, le immagini seguenti mostrano un esempio del nostro set di dati di addestramento.
 |
 |
 |
| Ron il cane sdraiato su una cuccia bianca | Ron il cane seduto su un pavimento piastrellato | Ron il cane sdraiato sul seggiolino per auto |
 |
 |
 |
| Smila la gatta sdraiata su un divano | Smila la gatta fissa la telecamera sdraiata su un divano | Smila la gatta sdraiata nel trasportino |
Quando trasformiamo i nostri dati nel formato previsto dal lavoro di personalizzazione, otteniamo la seguente struttura di esempio:
{"immagine-rif": "/ron_01.jpg", "caption": "Ron il cane sdraiato su una cuccia bianca"} {"image-ref": "/ron_02.jpg", "caption": "Ron il cane seduto su un pavimento piastrellato"} {"image-ref": "/ron_03.jpg", "caption": "Ron il cane sdraiato sul seggiolino per auto"} {"image-ref": "/smila_01.jpg", "caption": "Smila la gatta sdraiata su un divano"} {"image-ref": "/smila_02.jpg", "caption": "Smila il gatto seduto accanto alla finestra accanto a una statua di gatto"} {"image-ref": "/smila_03.jpg", "caption": "Smila la gatta sdraiata sul trasportino"}
Dopo aver creato il nostro file JSONL, dobbiamo memorizzarlo su un bucket S3 per iniziare il nostro lavoro di personalizzazione. I processi di regolazione fine di Amazon Titan Image Generator G1 funzioneranno con 5-10,000 immagini. Per l'esempio discusso in questo post, utilizziamo 60 immagini: 30 del cane Ron e 30 del gatto Smila. In generale, fornire più varietà dello stile o della classe che stai cercando di apprendere migliorerà la precisione del tuo modello perfezionato. Tuttavia, maggiore è il numero di immagini utilizzate per la regolazione fine, maggiore sarà il tempo necessario per completare il lavoro di regolazione fine. Il numero di immagini utilizzate influenza anche il prezzo del tuo lavoro perfezionato. Fare riferimento a Prezzi di Amazon Bedrock per maggiori informazioni.
Ottimizzazione del generatore di immagini Amazon Titan
Ora che abbiamo pronti i dati di addestramento, possiamo iniziare un nuovo lavoro di personalizzazione. Questo processo può essere eseguito sia tramite la console Amazon Bedrock che tramite API. Per utilizzare la console Amazon Bedrock, completa i seguenti passaggi:
- Sulla console Amazon Bedrock, scegli Modelli personalizzati nel pannello di navigazione.
- Sulla Personalizza il modello menù, scegliere Creare un lavoro di messa a punto.
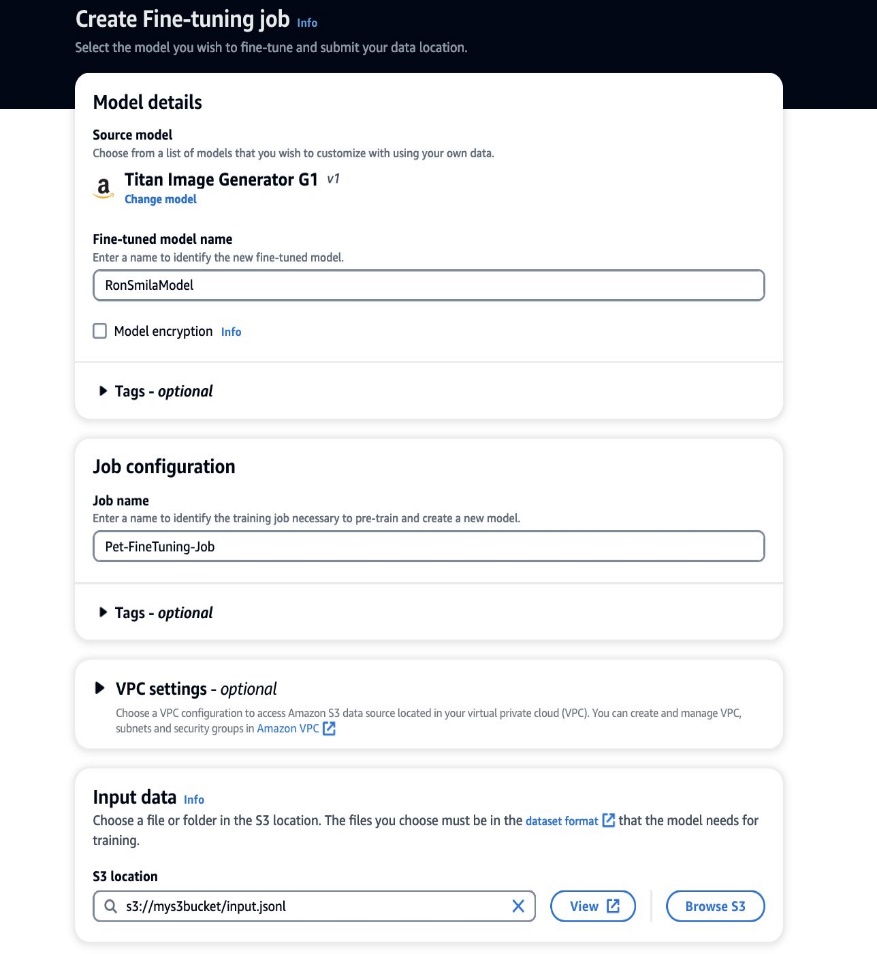
- Nel Nome del modello perfezionato, inserisci un nome per il tuo nuovo modello.
- Nel Configurazione del lavoro, inserisci un nome per il lavoro di formazione.
- Nel Dati in ingresso, immettere il percorso S3 dei dati di input.
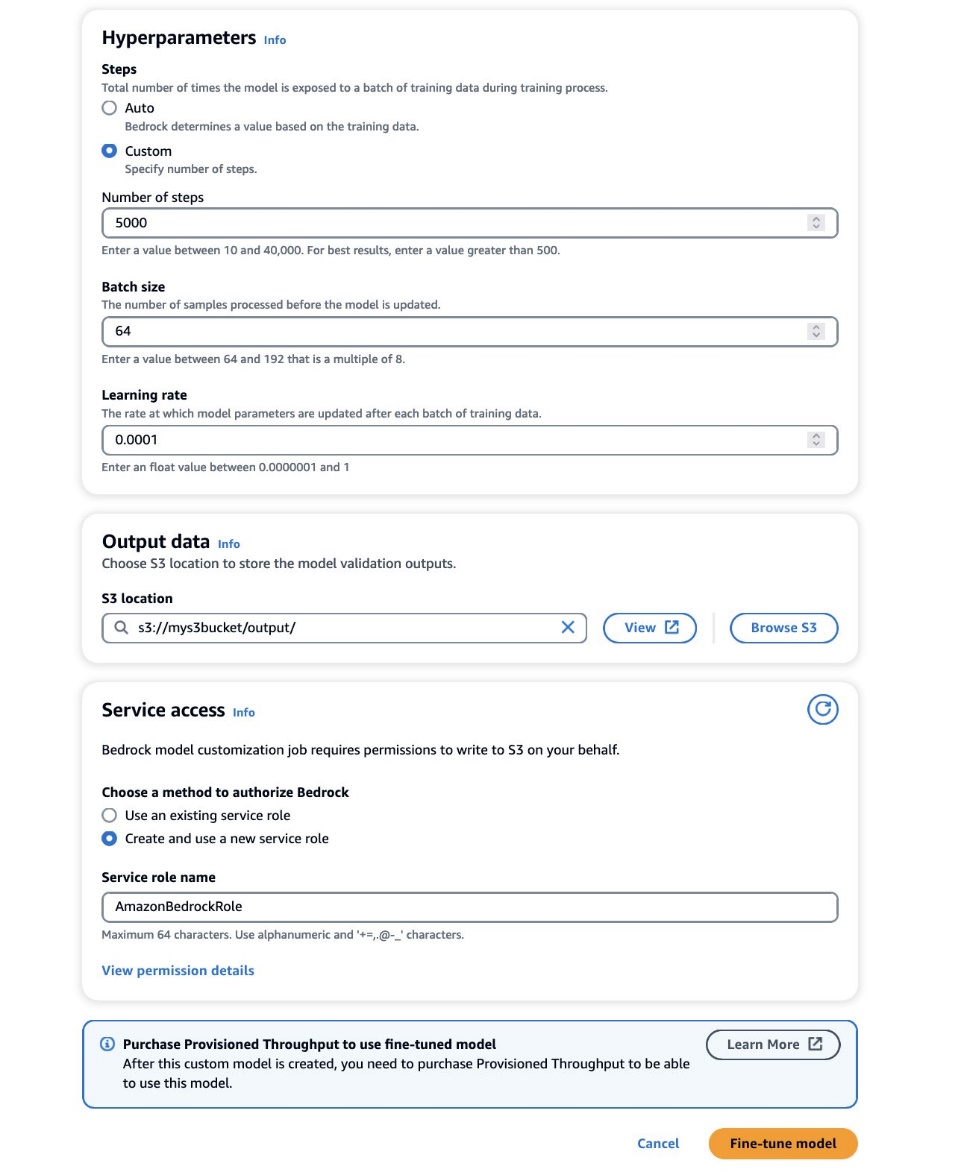
- Nel iperparametri sezione, fornire i valori per quanto segue:
- Numero di passaggi – Il numero di volte in cui il modello viene esposto a ciascun batch.
- Dimensione del lotto – Il numero di campioni elaborati prima dell'aggiornamento dei parametri del modello.
- Tasso di apprendimento – La velocità con cui i parametri del modello vengono aggiornati dopo ciascun batch. La scelta di questi parametri dipende da un dato set di dati. Come linea guida generale, ti consigliamo di iniziare fissando la dimensione del batch su 8, la velocità di apprendimento su 1e-5 e impostando il numero di passaggi in base al numero di immagini utilizzate, come dettagliato nella tabella seguente.
| Numero di immagini fornite | 8 | 32 | 64 | 1,000 | 10,000 |
| Numero di passaggi consigliati | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
Se i risultati del tuo lavoro di messa a punto non sono soddisfacenti, considera di aumentare il numero di passaggi se non osservi alcun segno dello stile nelle immagini generate e di diminuire il numero di passaggi se osservi lo stile nelle immagini generate ma con artefatti o sfocature. Se il modello ottimizzato non riesce ad apprendere lo stile univoco nel set di dati anche dopo 40,000 passaggi, valuta la possibilità di aumentare la dimensione del batch o la velocità di apprendimento.
- Nel Dati di output sezione, immettere il percorso di output S3 in cui sono archiviati gli output di convalida, inclusi i parametri di perdita di convalida e accuratezza registrati periodicamente.
- Nel Accesso al servizio sezione, generarne una nuova Gestione dell'identità e dell'accesso di AWS (IAM) o scegli un ruolo IAM esistente con le autorizzazioni necessarie per accedere ai tuoi bucket S3.
Questa autorizzazione consente ad Amazon Bedrock di recuperare set di dati di input e di convalida dal bucket designato e di archiviare gli output di convalida senza problemi nel bucket S3.
- Scegli Modello perfezionato.
Con le configurazioni corrette impostate, Amazon Bedrock addestrerà ora il tuo modello personalizzato.
Distribuisci il generatore di immagini Amazon Titan ottimizzato con throughput assegnato
Dopo aver creato un modello personalizzato, Provisioned Throughput consente di allocare una capacità di elaborazione fissa e predeterminata al modello personalizzato. Questa allocazione fornisce un livello coerente di prestazioni e capacità per la gestione dei carichi di lavoro, che si traduce in prestazioni migliori nei carichi di lavoro di produzione. Il secondo vantaggio del Provisioned Throughput è il controllo dei costi, poiché i prezzi standard basati su token con modalità di inferenza su richiesta possono essere difficili da prevedere su larga scala.
Una volta completata la messa a punto del tuo modello, questo modello apparirà sul Modelli personalizzati' pagina sulla console Amazon Bedrock.
Per acquistare Provisioned Throughput, seleziona il modello personalizzato che hai appena messo a punto e scegli Acquistare il throughput assegnato.
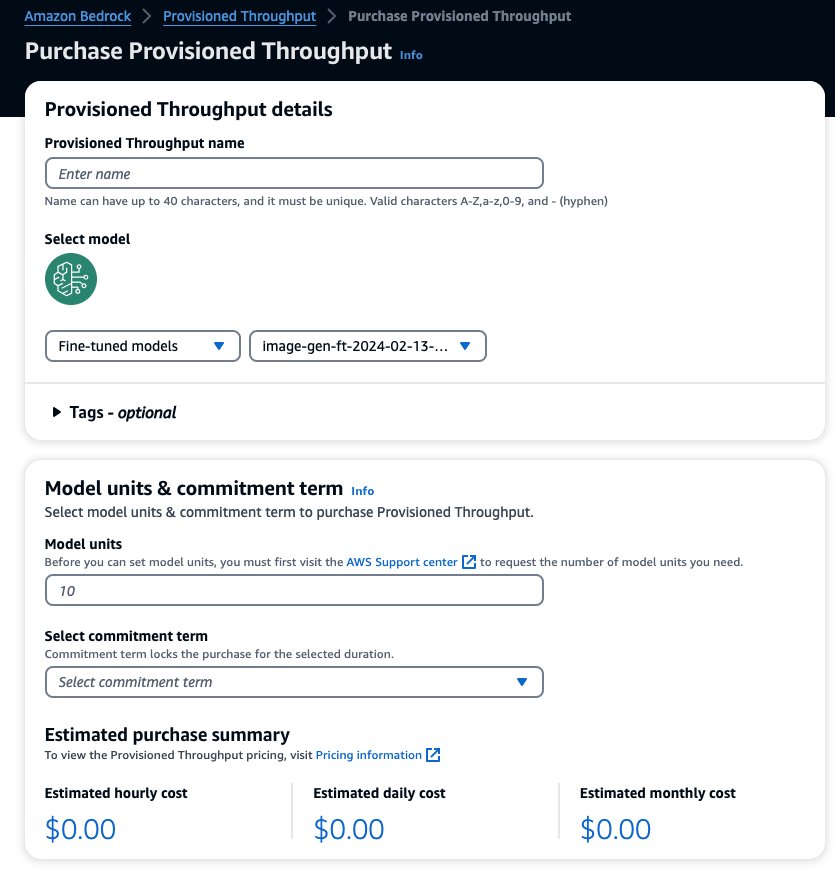
Ciò precompila il modello selezionato per il quale desideri acquistare il throughput assegnato. Per testare il modello ottimizzato prima della distribuzione, imposta le unità del modello su un valore pari a 1 e imposta il termine dell'impegno su Nessun impegno. Ciò ti consente di iniziare rapidamente a testare i tuoi modelli con le tue istruzioni personalizzate e verificare se la formazione è adeguata. Inoltre, quando sono disponibili nuovi modelli ottimizzati e nuove versioni, è possibile aggiornare il throughput assegnato purché lo aggiorni con altre versioni dello stesso modello.
Risultati di messa a punto
Per il nostro compito di personalizzare il modello sul cane Ron e sul gatto Smila, gli esperimenti hanno dimostrato che i migliori iperparametri erano 5,000 passaggi con una dimensione batch di 8 e una velocità di apprendimento di 1e-5.
Di seguito sono riportati alcuni esempi delle immagini generate dal modello personalizzato.
 |
 |
 |
| Ron il cane che indossa un mantello da supereroe | Ron il cane sulla luna | Ron il cane in una piscina con gli occhiali da sole |
 |
 |
 |
| Smila il gatto sulla neve | Smila il gatto in bianco e nero che fissa la telecamera | Smila il gatto che indossa un cappello di Natale |
Conclusione
In questo post, abbiamo discusso quando utilizzare la regolazione fine invece di progettare le istruzioni per la generazione di immagini di migliore qualità. Abbiamo mostrato come ottimizzare il modello Amazon Titan Image Generator e distribuire il modello personalizzato su Amazon Bedrock. Abbiamo inoltre fornito linee guida generali su come preparare i dati per la messa a punto e impostare iperparametri ottimali per una personalizzazione del modello più accurata.
Come passaggio successivo, puoi adattare quanto segue esempio al tuo caso d'uso per generare immagini iper-personalizzate utilizzando Amazon Titan Image Generator.
Informazioni sugli autori
 Maira Ladeira Tanke è un Senior Data Scientist di intelligenza artificiale generativa presso AWS. Con un background nell'apprendimento automatico, ha oltre 10 anni di esperienza nell'architettura e nella creazione di applicazioni IA con clienti di tutti i settori. In qualità di responsabile tecnico, aiuta i clienti ad accelerare il raggiungimento del valore aziendale attraverso soluzioni di intelligenza artificiale generativa su Amazon Bedrock. Nel tempo libero, Maira ama viaggiare, giocare con il suo gatto Smila e trascorrere del tempo con la sua famiglia in un posto caldo.
Maira Ladeira Tanke è un Senior Data Scientist di intelligenza artificiale generativa presso AWS. Con un background nell'apprendimento automatico, ha oltre 10 anni di esperienza nell'architettura e nella creazione di applicazioni IA con clienti di tutti i settori. In qualità di responsabile tecnico, aiuta i clienti ad accelerare il raggiungimento del valore aziendale attraverso soluzioni di intelligenza artificiale generativa su Amazon Bedrock. Nel tempo libero, Maira ama viaggiare, giocare con il suo gatto Smila e trascorrere del tempo con la sua famiglia in un posto caldo.
 Dan Mitchell è un AI/ML Specialist Solutions Architect presso Amazon Web Services. Si concentra sui casi d'uso della visione artificiale e aiuta i clienti in tutta l'area EMEA ad accelerare il loro percorso verso il machine learning.
Dan Mitchell è un AI/ML Specialist Solutions Architect presso Amazon Web Services. Si concentra sui casi d'uso della visione artificiale e aiuta i clienti in tutta l'area EMEA ad accelerare il loro percorso verso il machine learning.
 Bharathi Srinivasan è una scienziata dei dati presso AWS Professional Services, dove ama creare cose interessanti su Amazon Bedrock. La sua passione è generare valore aziendale dalle applicazioni di machine learning, con particolare attenzione all'intelligenza artificiale responsabile. Oltre a creare nuove esperienze di intelligenza artificiale per i clienti, Bharathi ama scrivere fantascienza e mettersi alla prova con sport di resistenza.
Bharathi Srinivasan è una scienziata dei dati presso AWS Professional Services, dove ama creare cose interessanti su Amazon Bedrock. La sua passione è generare valore aziendale dalle applicazioni di machine learning, con particolare attenzione all'intelligenza artificiale responsabile. Oltre a creare nuove esperienze di intelligenza artificiale per i clienti, Bharathi ama scrivere fantascienza e mettersi alla prova con sport di resistenza.
 Achin Jain è uno scienziato applicato del team Amazon Artificial General Intelligence (AGI). Ha esperienza nei modelli da testo a immagine e si concentra sulla creazione di Amazon Titan Image Generator.
Achin Jain è uno scienziato applicato del team Amazon Artificial General Intelligence (AGI). Ha esperienza nei modelli da testo a immagine e si concentra sulla creazione di Amazon Titan Image Generator.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

