Questo post è stato scritto in collaborazione con Pramod Nayak, LakshmiKanth Mannem e Vivek Aggarwal del Low Latency Group di LSEG.
L'analisi dei costi di transazione (TCA) è ampiamente utilizzata da trader, gestori di portafoglio e broker per analisi pre- e post-negoziazione e li aiuta a misurare e ottimizzare i costi di transazione e l'efficacia delle loro strategie di trading. In questo post, analizziamo gli spread bid-ask delle opzioni dal Cronologia zecche LSEG – PCAP set di dati utilizzando Amazon Athena per Apache Spark. Ti mostriamo come accedere ai dati, definire funzioni personalizzate da applicare sui dati, interrogare e filtrare il set di dati e visualizzare i risultati dell'analisi, il tutto senza doversi preoccupare di impostare l'infrastruttura o configurare Spark, anche per set di dati di grandi dimensioni.
sfondo
L'OPRA (Options Price Reporting Authority) funge da fondamentale elaboratore di informazioni sui titoli, raccogliendo, consolidando e diffondendo i rapporti sulle ultime vendite, le quotazioni e le informazioni pertinenti per le opzioni statunitensi. Con 18 scambi di opzioni statunitensi attivi e oltre 1.5 milioni di contratti idonei, OPRA svolge un ruolo fondamentale nel fornire dati di mercato completi.
Il 5 febbraio 2024, la Securities Industry Automation Corporation (SIAC) aggiornerà il feed OPRA da 48 a 96 canali multicast. Questo miglioramento mira a ottimizzare la distribuzione dei simboli e l'utilizzo della capacità della linea in risposta alla crescente attività di negoziazione e alla volatilità nel mercato delle opzioni statunitense. La SIAC ha raccomandato alle aziende di prepararsi per velocità di trasmissione dati massime fino a 37.3 GBit al secondo.
Nonostante l’aggiornamento non modifichi immediatamente il volume totale dei dati pubblicati, consente all’OPRA di diffondere i dati a un ritmo significativamente più rapido. Questa transizione è cruciale per rispondere alle richieste del mercato dinamico delle opzioni.
OPRA si distingue come uno dei feed più voluminosi, con un picco di 150.4 miliardi di messaggi in un solo giorno nel terzo trimestre del 3 e un requisito di capacità di 2023 miliardi di messaggi in un solo giorno. Catturare ogni singolo messaggio è fondamentale per l'analisi dei costi di transazione, il monitoraggio della liquidità del mercato, la valutazione della strategia di trading e le ricerche di mercato.
Informazioni sui dati
Cronologia zecche LSEG – PCAP è un repository basato su cloud, che supera i 30 PB, che ospita dati di mercato globale di altissima qualità. Questi dati vengono meticolosamente acquisiti direttamente all'interno dei data center di scambio, utilizzando processi di acquisizione ridondanti posizionati strategicamente nei principali data center di scambio primari e di backup in tutto il mondo. La tecnologia di acquisizione di LSEG garantisce l'acquisizione di dati senza perdite e utilizza una sorgente temporale GPS per una precisione di marcatura temporale nell'ordine dei nanosecondi. Inoltre, vengono impiegate sofisticate tecniche di arbitraggio dei dati per colmare eventuali lacune nei dati. Successivamente all'acquisizione, i dati vengono sottoposti a meticolosa elaborazione e arbitraggio e vengono quindi normalizzati nel formato Parquet Real Time Ultra Direct di LSEG (RTUD) gestori di mangimi.
Il processo di normalizzazione, che è parte integrante della preparazione dei dati per l'analisi, genera fino a 6 TB di file Parquet compressi al giorno. L’enorme volume di dati è attribuito alla natura onnicomprensiva di OPRA, che abbraccia più borse e presenta numerosi contratti di opzione caratterizzati da attributi diversi. L’aumento della volatilità del mercato e l’attività di market making sulle borse delle opzioni contribuiscono ulteriormente al volume di dati pubblicati su OPRA.
Gli attributi di Tick History – PCAP consentono alle aziende di condurre varie analisi, tra cui:
- Analisi pre-negoziazione – Valutare il potenziale impatto commerciale ed esplorare diverse strategie di esecuzione basate su dati storici
- Valutazione post-negoziazione – Misurare i costi di esecuzione effettivi rispetto ai parametri di riferimento per valutare le prestazioni delle strategie di esecuzione
- Ottimizzato esecuzione – Perfezionare le strategie di esecuzione basate su modelli storici di mercato per ridurre al minimo l’impatto sul mercato e ridurre i costi di negoziazione complessivi
- Gestione del rischio – Identificare modelli di slittamento, identificare valori anomali e gestire in modo proattivo i rischi associati alle attività di trading
- Attribuzione delle prestazioni – Separare l’impatto delle decisioni di trading dalle decisioni di investimento quando si analizza la performance del portafoglio
Il set di dati LSEG Tick History – PCAP è disponibile in Scambio di dati AWS ed è possibile accedervi su Mercato AWS. Con Scambio di dati AWS per Amazon S3, puoi accedere ai dati PCAP direttamente da LSEG Servizio di archiviazione semplice Amazon (Amazon S3), eliminando la necessità per le aziende di archiviare la propria copia dei dati. Questo approccio semplifica la gestione e l'archiviazione dei dati, fornendo ai clienti l'accesso immediato a dati PCAP o normalizzati di alta qualità con facilità d'uso, integrazione e sostanziali risparmi in termini di archiviazione dei dati.
Atena per Apache Spark
Per gli sforzi analitici, Atena per Apache Spark offre un'esperienza notebook semplificata accessibile tramite la console Athena o le API Athena, consentendoti di creare applicazioni Apache Spark interattive. Con un runtime Spark ottimizzato, Athena facilita l'analisi di petabyte di dati scalando dinamicamente il numero di motori Spark in meno di un secondo. Inoltre, le librerie Python comuni come panda e NumPy sono perfettamente integrate, consentendo la creazione di una logica applicativa complessa. La flessibilità si estende all'importazione di librerie personalizzate da utilizzare nei notebook. Athena per Spark supporta la maggior parte dei formati dati aperti ed è perfettamente integrato con Colla AWS Catalogo dati.
dataset
Per questa analisi, abbiamo utilizzato il set di dati LSEG Tick History – PCAP OPRA del 17 maggio 2023. Questo set di dati comprende i seguenti componenti:
- Migliore offerta e offerta (BBO) – Riporta l'offerta più alta e la richiesta più bassa per un titolo in una determinata borsa valori
- Migliore offerta e offerta nazionale (NBBO) – Riporta l’offerta più alta e la richiesta più bassa per un titolo in tutte le borse
- Trades – Registra le operazioni completate su tutte le borse
Il set di dati comprende i seguenti volumi di dati:
- Trades – 160 MB distribuiti in circa 60 file Parquet compressi
- BBO – 2.4 TB distribuiti su circa 300 file Parquet compressi
- NBBO – 2.8 TB distribuiti su circa 200 file Parquet compressi
Panoramica dell'analisi
L'analisi dei dati della cronologia dei tick OPRA per l'analisi dei costi di transazione (TCA) implica l'esame accurato delle quotazioni di mercato e delle negoziazioni attorno a un evento commerciale specifico. Utilizziamo i seguenti parametri come parte di questo studio:
- Spread quotato (QS) – Calcolato come differenza tra BBO ask e BBO bid
- Spread effettivo (ES) – Calcolato come differenza tra il prezzo di scambio e il punto medio del BBO (BBO bid + (BBO ask – BBO bid)/2)
- Spread effettivo/quotato (EQF) – Calcolato come (ES / QS) * 100
Calcoliamo questi spread prima dell'operazione e inoltre a quattro intervalli dopo l'operazione (subito dopo, 1 secondo, 10 secondi e 60 secondi dopo l'operazione).
Configura Athena per Apache Spark
Per configurare Athena per Apache Spark, completare i seguenti passaggi:
- Sulla console Athena, sotto Inizia, selezionare Analizza i tuoi dati utilizzando PySpark e Spark SQL.
- Se è la prima volta che usi Athena Spark, scegli Crea gruppo di lavoro.

- Nel Nome del gruppo di lavoro¸ immettere un nome per il gruppo di lavoro, ad esempio
tca-analysis. - Nel Motore di analisi sezione, selezionare Apache Spark.
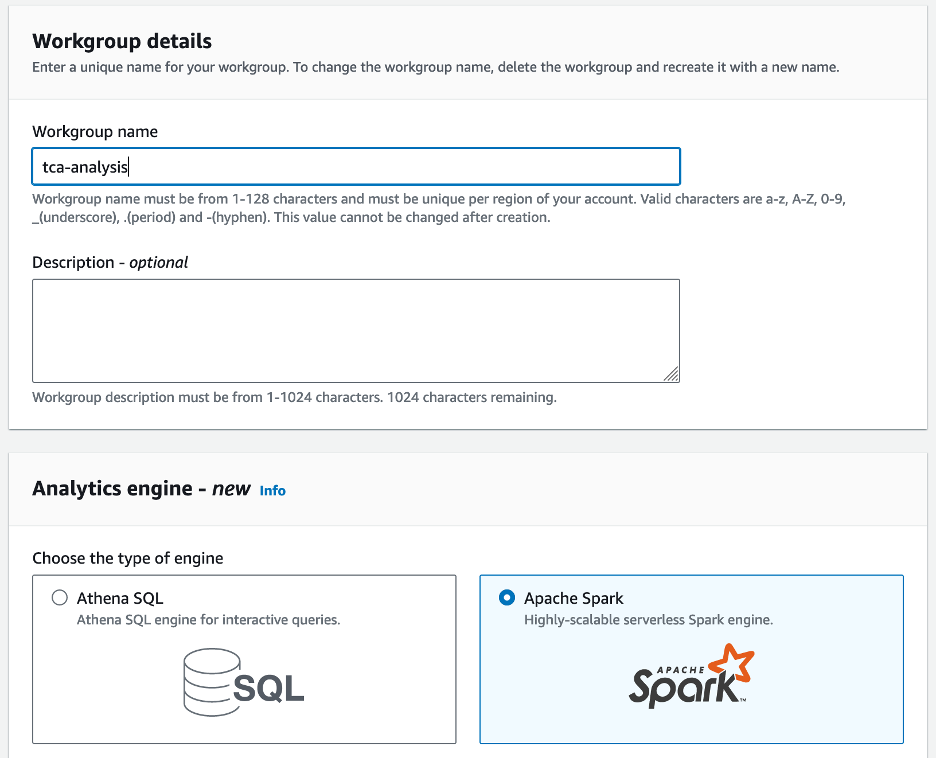
- Nel Ulteriori configurazioni sezione, puoi scegliere Usa le impostazioni predefinite o fornire un'abitudine Gestione dell'identità e dell'accesso di AWS (IAM) e posizione Amazon S3 per i risultati del calcolo.
- Scegli Crea gruppo di lavoro.
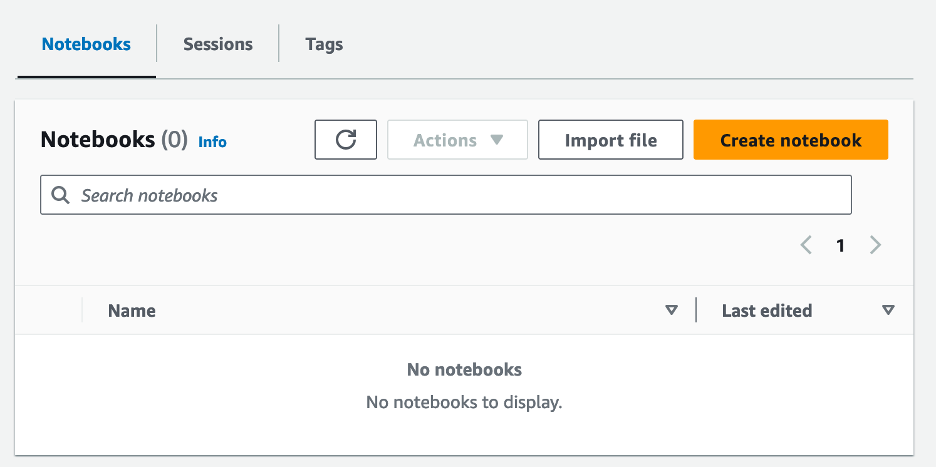
- Dopo aver creato il gruppo di lavoro, vai al file Notebook scheda e scegliere Crea quaderno.
- Inserisci un nome per il tuo taccuino, ad esempio
tca-analysis-with-tick-history. - Scegli Creare per creare il tuo quaderno.
Avvia il tuo taccuino
Se hai già creato un gruppo di lavoro Spark, seleziona Avvia l'editor del taccuino per Inizia.
![]()
Dopo aver creato il tuo taccuino, verrai reindirizzato all'editor interattivo del taccuino.
![]()
Ora possiamo aggiungere ed eseguire il seguente codice sul nostro notebook.
Crea un'analisi
Completare i seguenti passaggi per creare un'analisi:
- Importa librerie comuni:
- Crea i nostri frame di dati per BBO, NBBO e operazioni:
- Ora possiamo identificare un'operazione da utilizzare per l'analisi dei costi di transazione:
Otteniamo il seguente output:
Utilizzeremo le informazioni commerciali evidenziate per il prodotto commerciale (tp), il prezzo commerciale (tpr) e il tempo commerciale (tt).
- Qui creiamo una serie di funzioni di supporto per la nostra analisi
- Nella funzione seguente, creiamo il set di dati che contiene tutte le quotazioni prima e dopo l'operazione. Athena Spark determina automaticamente quante DPU avviare per l'elaborazione del nostro set di dati.
- Ora chiamiamo la funzione di analisi TCA con le informazioni dalla nostra operazione selezionata:
Visualizzare i risultati dell'analisi
Ora creiamo i frame di dati che utilizziamo per la nostra visualizzazione. Ogni frame di dati contiene virgolette per uno dei cinque intervalli di tempo per ciascun feed di dati (BBO, NBBO):
Nelle sezioni seguenti forniamo codice di esempio per creare diverse visualizzazioni.
Traccia QS e NBBO prima dello scambio
Utilizza il seguente codice per tracciare lo spread quotato e il NBBO prima dell'operazione:
![]()
Traccia QS per ciascun mercato e NBBO dopo l'operazione
Utilizza il seguente codice per tracciare lo spread quotato per ciascun mercato e NBBO immediatamente dopo l'operazione:
![]()
Traccia QS per ogni intervallo di tempo e ciascun mercato per BBO
Utilizza il seguente codice per tracciare lo spread quotato per ciascun intervallo di tempo e ciascun mercato per BBO:
![]()
Traccia ES per ogni intervallo di tempo e mercato per BBO
Utilizza il seguente codice per tracciare lo spread effettivo per ciascun intervallo di tempo e mercato per BBO:
Traccia l'EQF per ogni intervallo di tempo e mercato per BBO
Utilizza il seguente codice per tracciare lo spread effettivo/quotato per ciascun intervallo di tempo e mercato per BBO:
Prestazioni di calcolo di Athena Spark
Quando esegui un blocco di codice, Athena Spark determina automaticamente quante DPU sono necessarie per completare il calcolo. Nell'ultimo blocco di codice, dove chiamiamo il file tca_analysis funzione, stiamo effettivamente istruendo Spark per elaborare i dati e quindi convertire i dataframe Spark risultanti in dataframe Pandas. Ciò costituisce la parte di elaborazione più intensa dell'analisi e quando Athena Spark esegue questo blocco, mostra la barra di avanzamento, il tempo trascorso e quante DPU stanno elaborando i dati attualmente. Ad esempio, nel calcolo seguente, Athena Spark utilizza 18 DPU.
![]()
Quando configuri il tuo notebook Athena Spark, hai la possibilità di impostare il numero massimo di DPU che può utilizzare. Il valore predefinito è 20 DPU, ma abbiamo testato questo calcolo con 10, 20 e 40 DPU per dimostrare come Athena Spark si ridimensioni automaticamente per eseguire la nostra analisi. Abbiamo osservato che Athena Spark scala in modo lineare, impiegando 15 minuti e 21 secondi quando il notebook è stato configurato con un massimo di 10 DPU, 8 minuti e 23 secondi quando il notebook è stato configurato con 20 DPU e 4 minuti e 44 secondi quando il notebook è stato configurato con 40 DPU. configurato con XNUMX DPU. Poiché Athena Spark addebita i costi in base all'utilizzo della DPU, con una granularità al secondo, il costo di questi calcoli è simile, ma se imposti un valore DPU massimo più elevato, Athena Spark può restituire il risultato dell'analisi molto più velocemente. Per maggiori dettagli sui prezzi di Athena Spark, fare clic su qui.
Conclusione
In questo post, abbiamo dimostrato come utilizzare i dati OPRA ad alta fedeltà provenienti da Tick History-PCAP di LSEG per eseguire analisi dei costi di transazione utilizzando Athena Spark. La disponibilità tempestiva dei dati OPRA, integrata con le innovazioni di accessibilità di AWS Data Exchange per Amazon S3, riduce strategicamente i tempi di analisi per le aziende che desiderano creare informazioni utili per decisioni commerciali critiche. OPRA genera circa 7 TB di dati Parquet normalizzati ogni giorno e gestire l'infrastruttura per fornire analisi basate sui dati OPRA è impegnativo.
La scalabilità di Athena nella gestione dell'elaborazione dati su larga scala per Tick History – PCAP per dati OPRA lo rende una scelta interessante per le organizzazioni che cercano soluzioni di analisi rapide e scalabili in AWS. Questo post mostra la perfetta interazione tra l'ecosistema AWS e i dati Tick History-PCAP e come gli istituti finanziari possono trarre vantaggio da questa sinergia per guidare il processo decisionale basato sui dati per strategie di trading e investimento critiche.
Informazioni sugli autori
![]() Pramod Nayak è il Direttore della gestione del prodotto del gruppo Low Latency presso LSEG. Pramod ha oltre 10 anni di esperienza nel settore della tecnologia finanziaria, concentrandosi sullo sviluppo di software, analisi e gestione dei dati. Pramod è un ex ingegnere informatico e appassionato di dati di mercato e trading quantitativo.
Pramod Nayak è il Direttore della gestione del prodotto del gruppo Low Latency presso LSEG. Pramod ha oltre 10 anni di esperienza nel settore della tecnologia finanziaria, concentrandosi sullo sviluppo di software, analisi e gestione dei dati. Pramod è un ex ingegnere informatico e appassionato di dati di mercato e trading quantitativo.
![]() Lakshmi Kanth Mannem è un Product Manager nel gruppo Low Latency di LSEG. Si concentra su dati e prodotti di piattaforma per il settore dei dati di mercato a bassa latenza. LakshmiKanth aiuta i clienti a creare le soluzioni più ottimali per le loro esigenze di dati di mercato.
Lakshmi Kanth Mannem è un Product Manager nel gruppo Low Latency di LSEG. Si concentra su dati e prodotti di piattaforma per il settore dei dati di mercato a bassa latenza. LakshmiKanth aiuta i clienti a creare le soluzioni più ottimali per le loro esigenze di dati di mercato.
![]() Vivek Aggarwal è un Senior Data Engineer nel gruppo Low Latency di LSEG. Vivek lavora allo sviluppo e al mantenimento di pipeline di dati per l'elaborazione e la fornitura di feed di dati di mercato acquisiti e feed di dati di riferimento.
Vivek Aggarwal è un Senior Data Engineer nel gruppo Low Latency di LSEG. Vivek lavora allo sviluppo e al mantenimento di pipeline di dati per l'elaborazione e la fornitura di feed di dati di mercato acquisiti e feed di dati di riferimento.
![]() Alket Memushaj è Principal Architect nel team di sviluppo del mercato dei servizi finanziari presso AWS. Alket è responsabile della strategia tecnica e collabora con partner e clienti per distribuire anche i carichi di lavoro dei mercati dei capitali più impegnativi nel cloud AWS.
Alket Memushaj è Principal Architect nel team di sviluppo del mercato dei servizi finanziari presso AWS. Alket è responsabile della strategia tecnica e collabora con partner e clienti per distribuire anche i carichi di lavoro dei mercati dei capitali più impegnativi nel cloud AWS.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/

