“I dati sono al centro di ogni applicazione, processo e decisione aziendale. Quando i dati vengono utilizzati per migliorare l’esperienza dei clienti e promuovere l’innovazione, possono portare alla crescita del business”,
- Swami Shivasubramanian, Vicepresidente di database, analisi e machine learning presso AWS in Con un approccio ETL zero, AWS aiuta i costruttori a realizzare analisi quasi in tempo reale.
I clienti di tutti i settori sono sempre più orientati ai dati e cercano di aumentare i ricavi, ridurre i costi e ottimizzare le proprie operazioni aziendali implementando analisi quasi in tempo reale sui dati transazionali, migliorando così l'agilità. In base alle esigenze dei clienti e al loro feedback, AWS sta investendo e progredendo costantemente per dare vita alla nostra visione ETL zero in modo che i costruttori possano concentrarsi maggiormente sulla creazione di valore dai dati, invece di preparare i dati per l'analisi.
Il nostro zero-ETL integrazione con Amazon RedShift facilita lo spostamento dei dati punto a punto per prepararli per l'analisi, l'intelligenza artificiale (AI) e l'apprendimento automatico (ML) utilizzando Amazon Redshift su petabyte di dati. Entro pochi secondi dalla scrittura dei dati transazionali supportato Database AWS, zero-ETL rende i dati disponibili in modo trasparente in Amazon Redshift, eliminando la necessità di creare e mantenere complesse pipeline di dati che eseguono operazioni di estrazione, trasformazione e caricamento (ETL).
Per aiutarti a concentrarti sulla creazione di valore dai dati invece di investire tempo e risorse indifferenziati nella creazione e gestione di pipeline ETL tra database transazionali e data warehouse, noi ha annunciato quattro integrazioni zero-ETL del database AWS con Amazon Redshift in occasione di AWS re:Invent 2023:
In questo post forniamo una guida passo passo su come iniziare con l'analisi operativa quasi in tempo reale utilizzando Integrazione zero-ETL di Amazon Aurora PostgreSQL con Amazon Redshift.
Panoramica della soluzione
Per creare un'integrazione zero-ETL, specifichi un Edizione compatibile con Amazon Aurora PostgreSQL cluster (compatibile con PostgreSQL 15.4 e supporto zero-ETL) come origine e un data warehouse Redshift come destinazione. L'integrazione replica i dati dal database di origine nel data warehouse di destinazione.
È necessario creare cluster con provisioning database Aurora PostgreSQL all'interno di Ambiente di anteprima del database Amazon RDS e uno spostamento verso il rosso cluster di anteprima fornito or gruppo di lavoro di anteprima serverless, nella regione AWS degli Stati Uniti orientali (Ohio). Per Amazon Redshift, assicurati di scegliere il percorso Preview_2023 per utilizzare le integrazioni zero ETL.
Il diagramma seguente illustra l'architettura implementata in questo post.
Di seguito sono riportati i passaggi necessari per configurare l'integrazione zero-ETL per questa soluzione. Per le guide introduttive complete, fare riferimento a Utilizzo delle integrazioni Aurora zero-ETL con Amazon Redshift ed Lavorare con integrazioni zero-ETL.
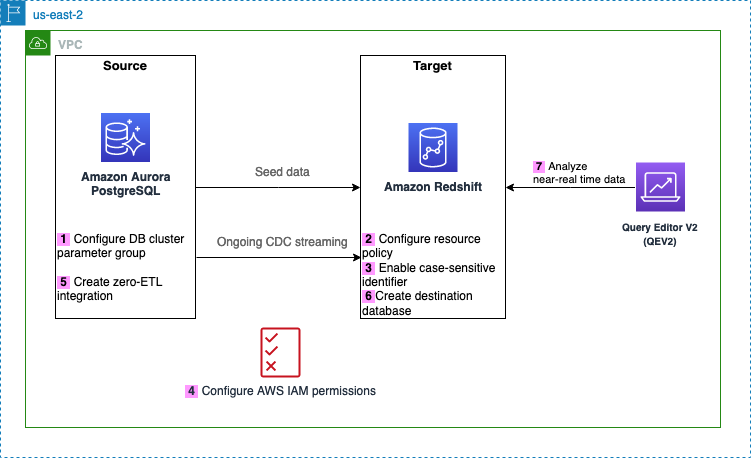
Dopo il passaggio 1, puoi anche saltare i passaggi 2–4 e iniziare direttamente a creare la tua integrazione zero ETL dal passaggio 5, nel qual caso Amazon RDS mostrerà un messaggio sulle configurazioni mancanti e potrai scegliere Risolvilo per me per consentire ad Amazon RDS di configurare automaticamente i passaggi.
- Configura l'origine Aurora PostgreSQL con un gruppo di parametri del cluster database personalizzato.
- Configura il Amazon Redshift senza server destinazione con la policy delle risorse richiesta per il relativo spazio dei nomi.
- Aggiorna il gruppo di lavoro Redshift Serverless per abilitare gli identificatori con distinzione tra maiuscole e minuscole.
- Configura le autorizzazioni richieste.
- Crea l'integrazione zero-ETL.
- Crea un database dall'integrazione in Amazon Redshift.
- Inizia ad analizzare i dati transazionali quasi in tempo reale.
Configura l'origine Aurora PostgreSQL con un gruppo di parametri del cluster database personalizzato
Per i cluster database Aurora PostgreSQL, è necessario creare il gruppo di parametri personalizzati all'interno del file Ambiente di anteprima del database Amazon RDS, nella regione degli Stati Uniti orientali (Ohio). Puoi accedere direttamente all'ambiente di anteprima di Amazon RDS.
Per creare un database Aurora PostgreSQL, completare i seguenti passaggi:
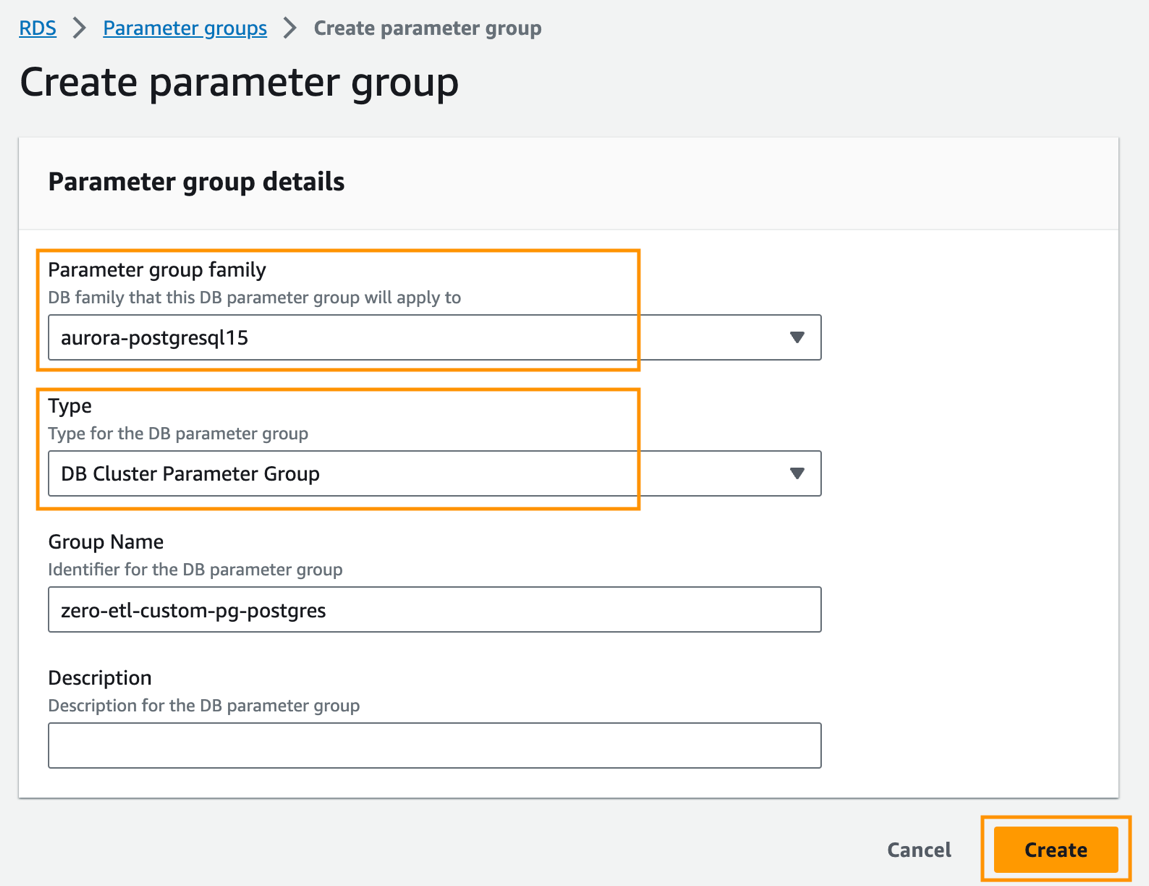
- Nella console Amazon RDS, scegli Gruppi di parametri nel pannello di navigazione.
- Scegli Crea gruppo di parametri.
- Nel Famiglia di gruppi di parametriscegli
aurora-postgresql15. - Nel Tipologiascegli
DB Cluster Parameter Group. - Nel Nome del gruppo, inserisci un nome (ad esempio,
zero-etl-custom-pg-postgres). - Scegli Creare.
Le integrazioni zero-ETL di Aurora PostgreSQL con Amazon Redshift richiedono valori specifici per il file Parametri del cluster database Aurora, che richiede una replica logica avanzata (aurora.enhanced_logical_replication).
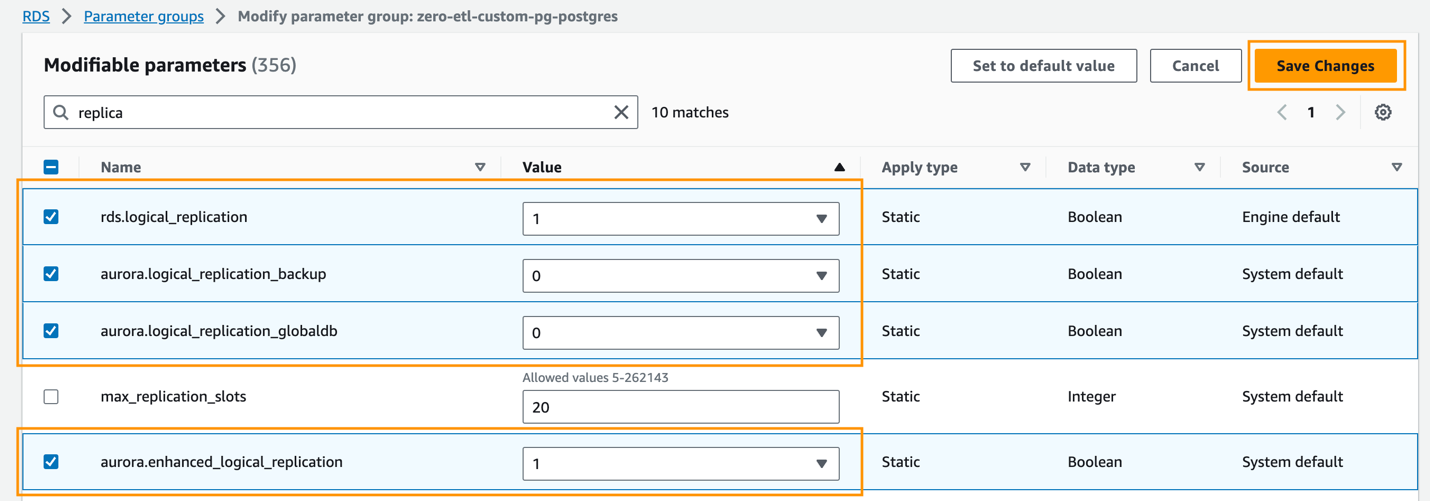
- Sulla Gruppi di parametri pagina, selezionare il gruppo di parametri appena creato.
- Sulla Azioni menù, scegliere Modifica.
- Imposta il seguente Aurora PostgreSQL (famiglia aurora-postgresql15) impostazioni dei parametri del cluster:
rds.logical_replication=1aurora.enhanced_logical_replication=1aurora.logical_replication_backup=0aurora.logical_replication_globaldb=0
L'abilitazione della replica logica avanzata (aurora.enhanced_logical_replication) imposta automaticamente il parametro REPLICA IDENTITY su FULL, il che significa che tutti i valori delle colonne vengono scritti nel log write-ahead (WAL).
- Scegli Salva modifiche.
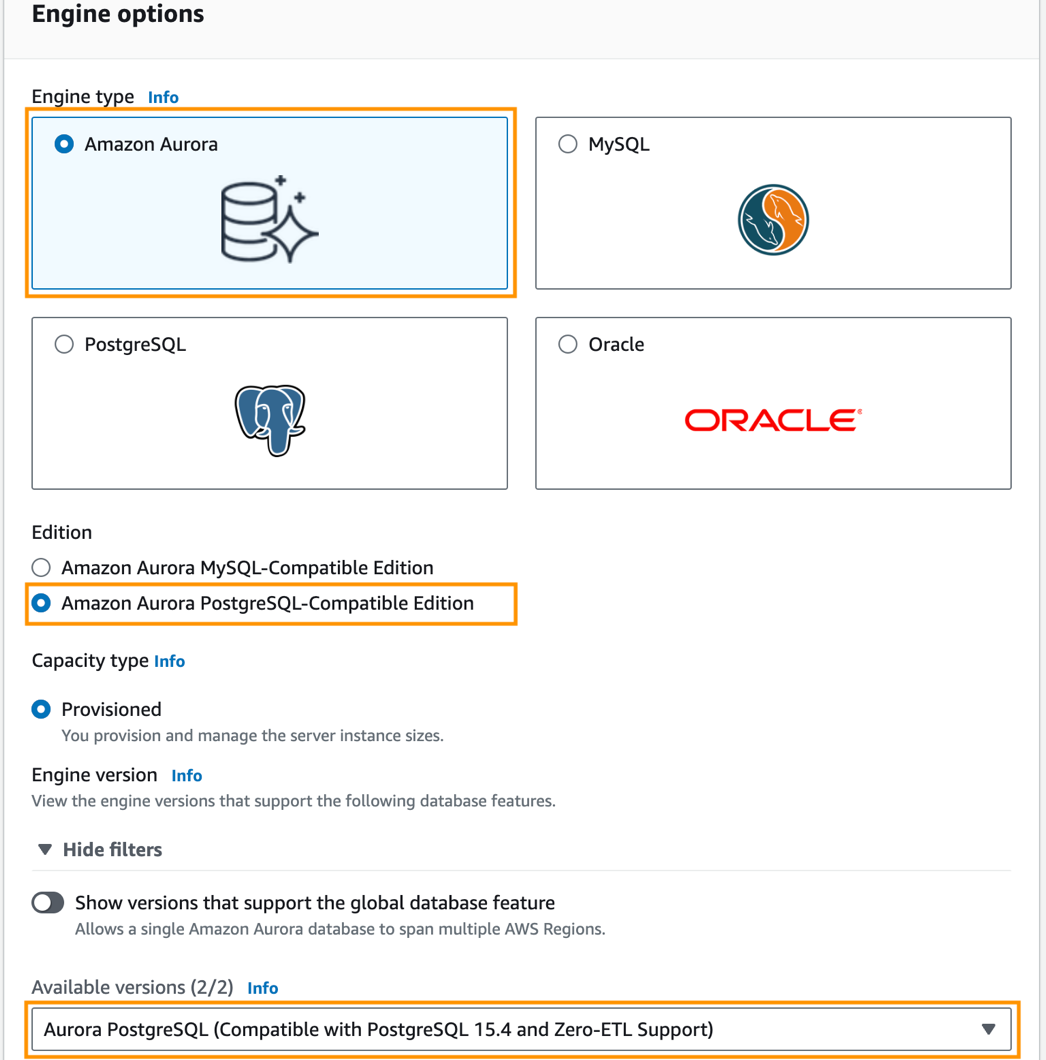
- Scegli Database nel riquadro di navigazione, quindi scegli Crea database.

- Nel Tipo di motore, selezionare Amazon Aurora.
- Nel Edizione, selezionare Edizione compatibile con Amazon Aurora PostgreSQL.
- Nel Versioni disponibiliscegli Aurora PostgreSQL (compatibile con PostgreSQL 15.4 e supporto Zero-ETL).
- Nel Modelli, selezionare Produzione.
- Nel Identificatore del cluster di database, accedere
zero-etl-source-pg.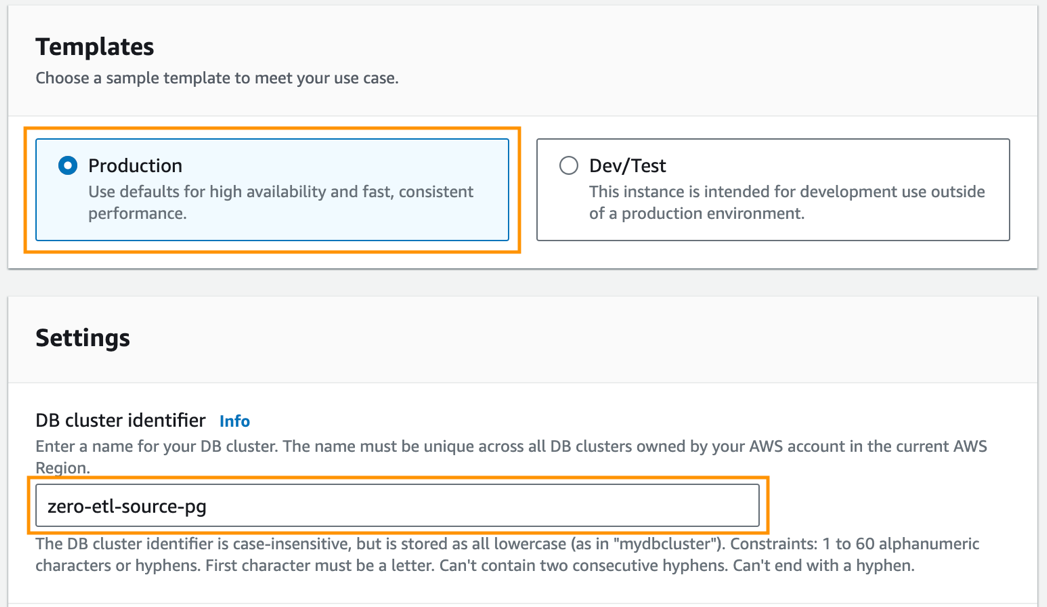
- Sotto Impostazioni delle credenziali, inserisci una password per Password principale oppure utilizza l'opzione per generare automaticamente una password per te.
- Nel Sezione di configurazione dell'istanza, selezionare Classi ottimizzate per la memoria.
- Scegli una dimensione dell'istanza adatta (l'impostazione predefinita è
db.r5.2xlarge).
- Sotto Configurazione aggiuntiva, Per Gruppo di parametri del cluster di database, scegli il gruppo di parametri che hai creato in precedenza (
zero-etl-custom-pg-postgres).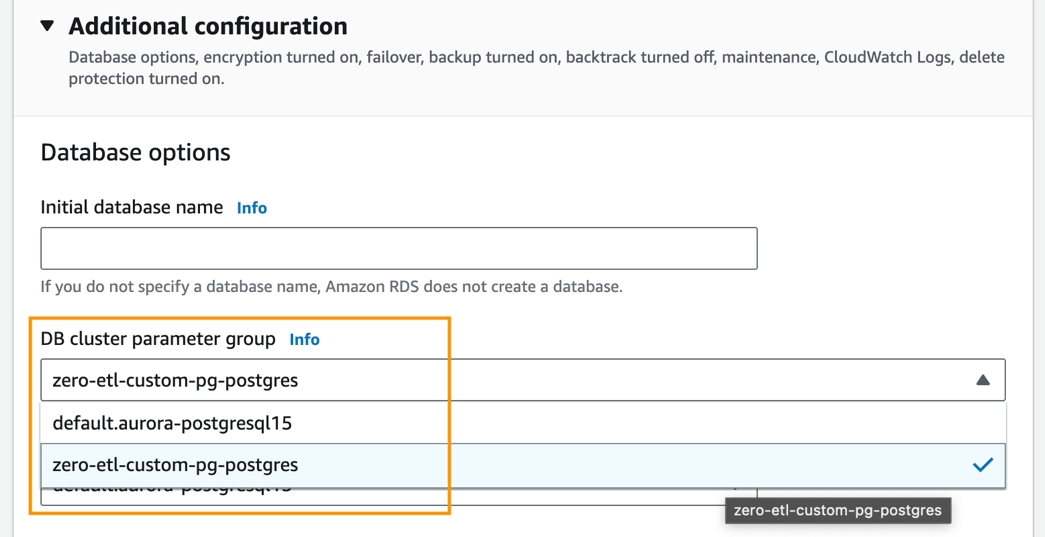
- Lasciare le impostazioni predefinite per le restanti configurazioni.
- Scegli Crea database.
In pochi minuti, questo dovrebbe avviare un cluster Aurora PostgreSQL, con un'istanza di scrittura e un'istanza di lettura, con lo stato che cambia da Creazione a Disponibile. Il cluster Aurora PostgreSQL appena creato sarà la fonte per l'integrazione zero-ETL.
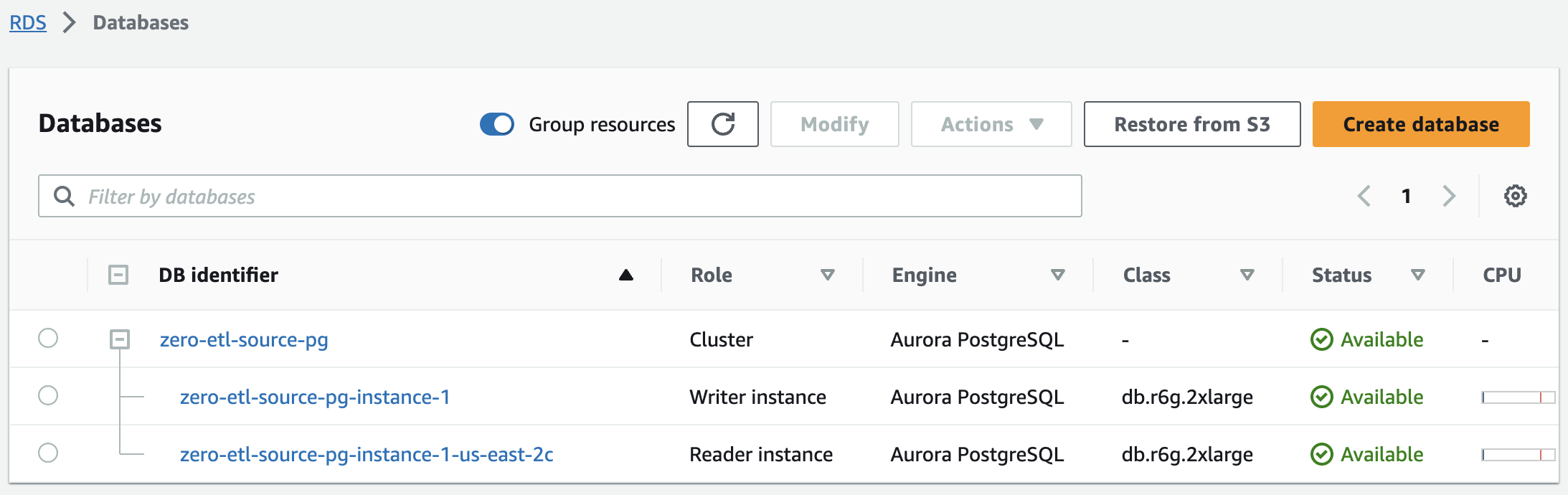
Il passaggio successivo consiste nel creare un database denominato in Amazon Aurora PostgreSQL per l'integrazione zero-ETL.
Il modello di risorsa PostgreSQL consente di creare più database all'interno di un cluster. Pertanto, durante la fase di creazione dell'integrazione zero ETL, è necessario specificare quale database si desidera utilizzare come origine per l'integrazione.
Quando si configura PostgreSQL, si ottengono tre database standard pronti all'uso: template0, template1 e postgres. Ogni volta che crei un nuovo database in PostgreSQL, in realtà lo stai basando su uno di questi tre database nel tuo cluster. Il database creato durante la creazione del cluster Aurora PostgreSQL è basato su template0. IL CREATE DATABASE Il comando funziona copiando un database esistente e, se non specificato esplicitamente, per impostazione predefinita copia il database di sistema standard template1. Per il database denominato per l'integrazione zero-ETL, è necessario che il database venga creato utilizzando template1 e non template0. Pertanto, se viene aggiunto un nome di database iniziale in Configurazione aggiuntiva, che verrebbe creato utilizzando template0 e non può essere utilizzato per l'integrazione zero-ETL.
- Per creare un nuovo database denominato utilizzando
CREATE DATABASEall'interno del nuovo cluster Aurora PostgreSQLzero-etl-source-pg, ottieni prima l'endpoint dell'istanza del writer del cluster PostgreSQL.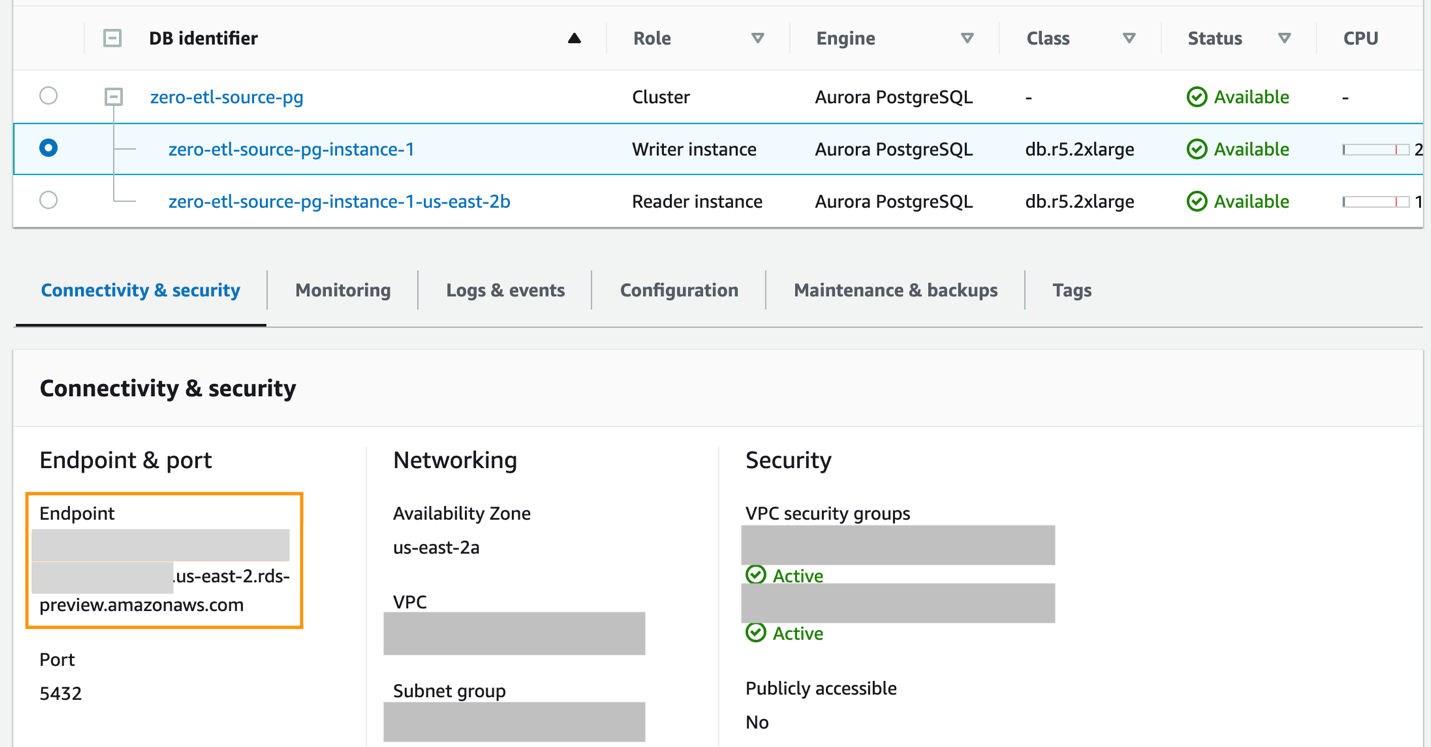
- Da un terminale o utilizzando AWS CloudShell, SSH nel cluster PostgreSQL ed esegui i seguenti comandi per installare psql e creare un nuovo database
zeroetl_db:
Aggiunta template template1 è facoltativo, perché per impostazione predefinita, se non menzionato, CREATE DATABASE userà template1.
Puoi anche connetterti tramite un client e creare il database. Fare riferimento a Connettiti a un cluster database Aurora PostgreSQL per le opzioni di connessione al cluster PostgreSQL.
Configura Redshift Serverless come destinazione
Dopo aver creato il cluster di database di origine Aurora PostgreSQL, configura un data warehouse di destinazione Redshift. Il data warehouse deve soddisfare i seguenti requisiti:
- Creato in anteprima (solo per origini Aurora PostgreSQL)
- Utilizza un tipo di nodo RA3 (ra3.16xlarge, ra3.4xlarge o ra3.xlplus) con almeno due nodi o Redshift Serverless
- Crittografato (se si utilizza un cluster con provisioning)
Per questo post, creiamo e configuriamo un gruppo di lavoro e uno spazio dei nomi Redshift Serverless come data warehouse di destinazione, seguendo questi passaggi:
- Sulla console Amazon Redshift, scegli Dashboard senza server nel pannello di navigazione.
Poiché l'integrazione zero-ETL per Amazon Aurora PostgreSQL su Amazon Redshift è stata avviata in anteprima (non per scopi di produzione), è necessario creare il data warehouse di destinazione in un ambiente di anteprima.
- Scegli Crea un gruppo di lavoro di anteprima.
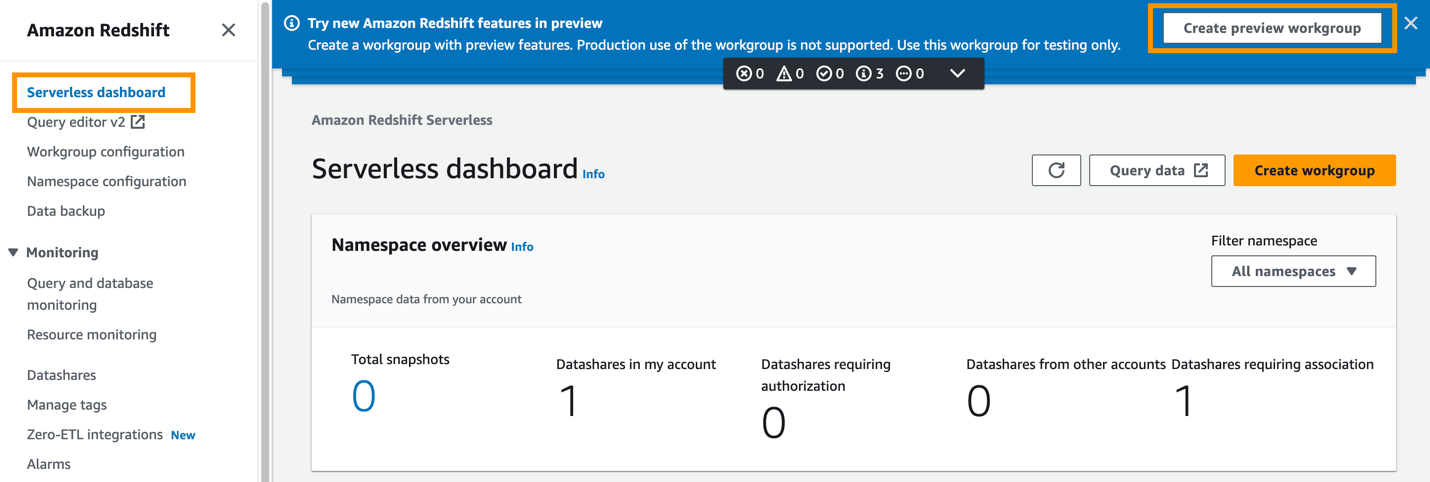
Il primo passo è configurare il gruppo di lavoro Redshift Serverless.
- Nel Nome del gruppo di lavoro, inserisci un nome (ad esempio,
zero-etl-target-rs-wg).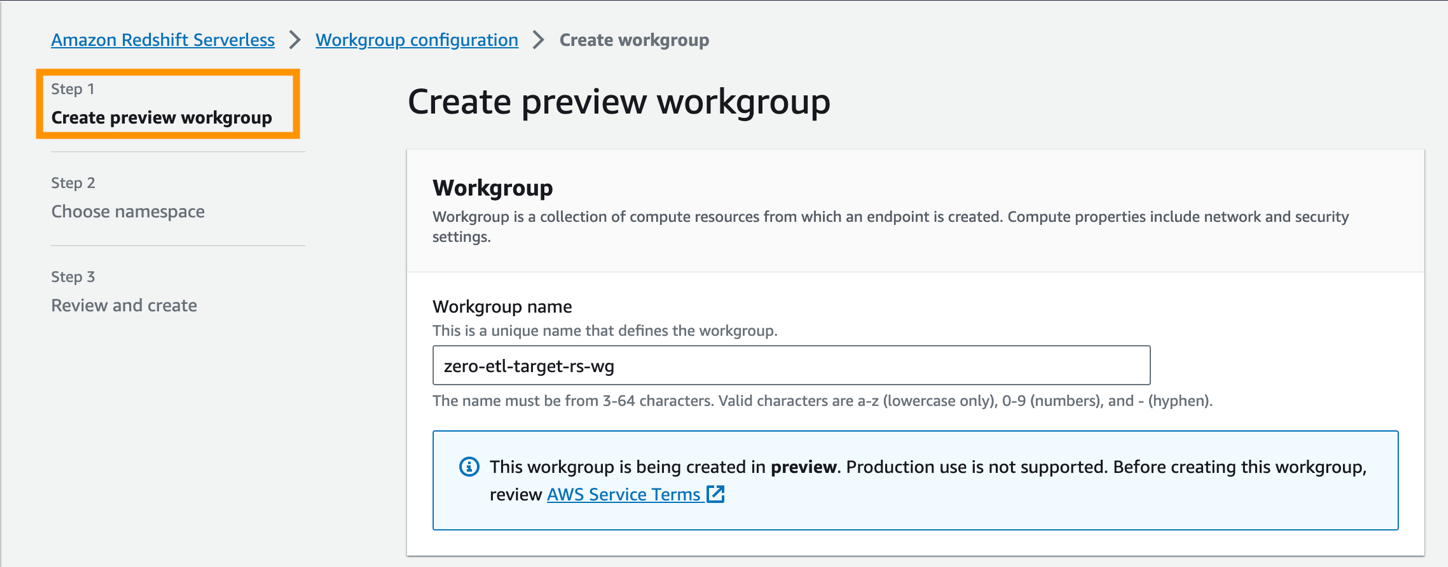
- Inoltre, puoi scegliere la capacità per limitare le risorse di elaborazione del data warehouse. La capacità può essere configurata con incrementi di 8, da 8 a 512 RPU. Per questo post, impostalo su
8RPU. - Scegli Avanti.

Successivamente, è necessario configurare lo spazio dei nomi del data warehouse.
- Seleziona Crea un nuovo spazio dei nomi.
- Nel Spazio dei nomi, inserisci un nome (ad esempio,
zero-etl-target-rs-ns). - Scegli Avanti.
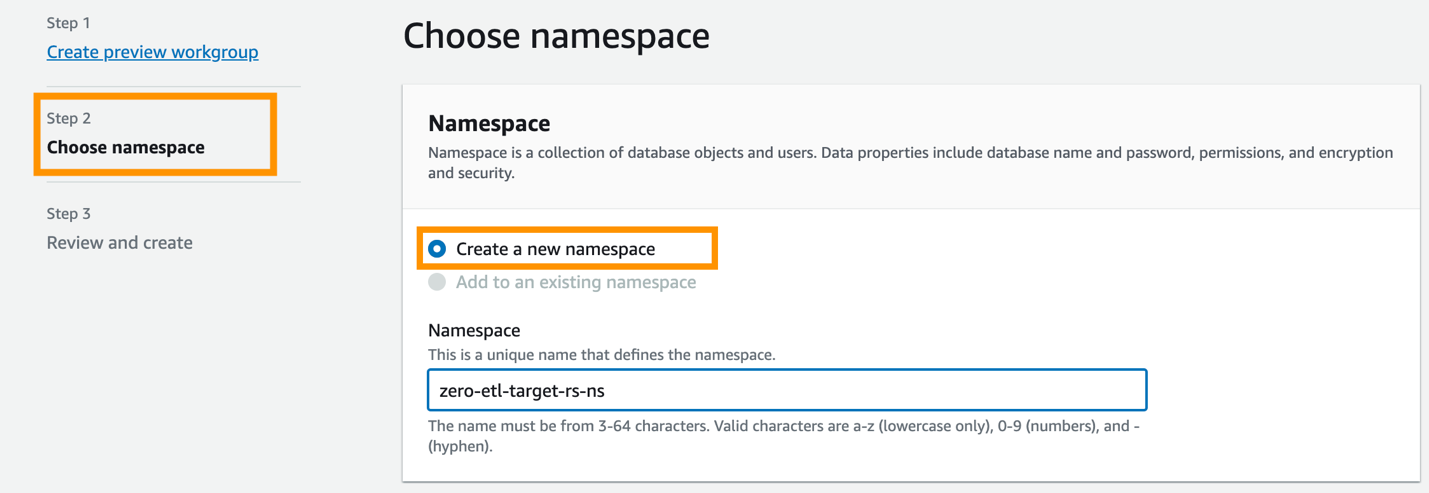
- Scegli Crea gruppo di lavoro.
- Dopo aver creato il gruppo di lavoro e lo spazio dei nomi, scegli Configurazioni dello spazio dei nomi nel riquadro di navigazione e aprire la configurazione dello spazio dei nomi.
- Sulla Politica delle risorse scheda, scegliere Aggiungi entità autorizzate.
Un'entità autorizzata identifica l'utente o il ruolo che può creare integrazioni con ETL zero nel data warehouse.

- Nel ARN principale IAM o ID account AWS, puoi inserire l'ARN dell'utente o del ruolo AWS oppure l'ID dell'account AWS a cui desideri concedere l'accesso per creare integrazioni zero ETL. (Un ID account viene archiviato come ARN.)
- Scegli Salvare le modifiche.
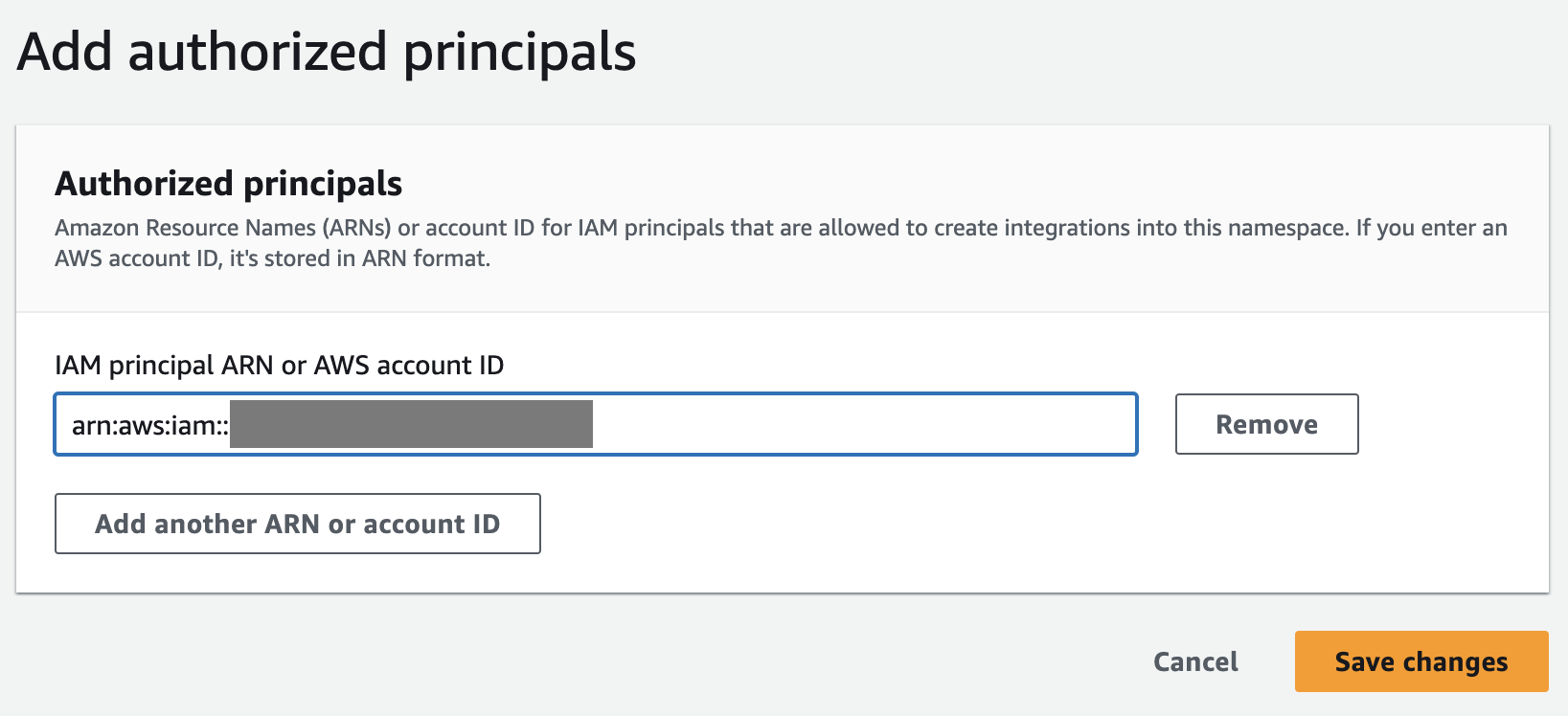
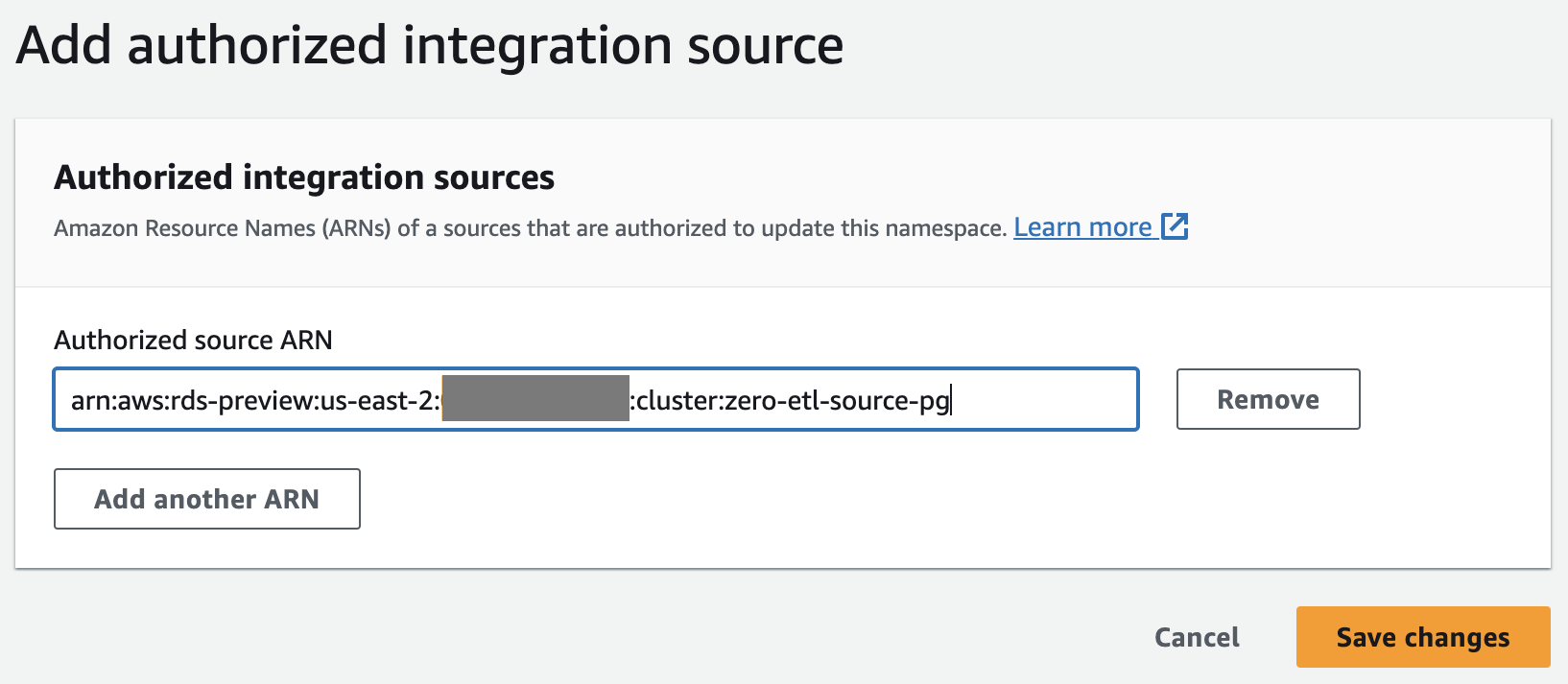
Dopo aver configurato l'entità autorizzata, è necessario consentire al database di origine di aggiornare il data warehouse Redshift. Pertanto, è necessario aggiungere il database di origine come origine di integrazione autorizzata allo spazio dei nomi.
- Scegli Aggiungi origine di integrazione autorizzata.
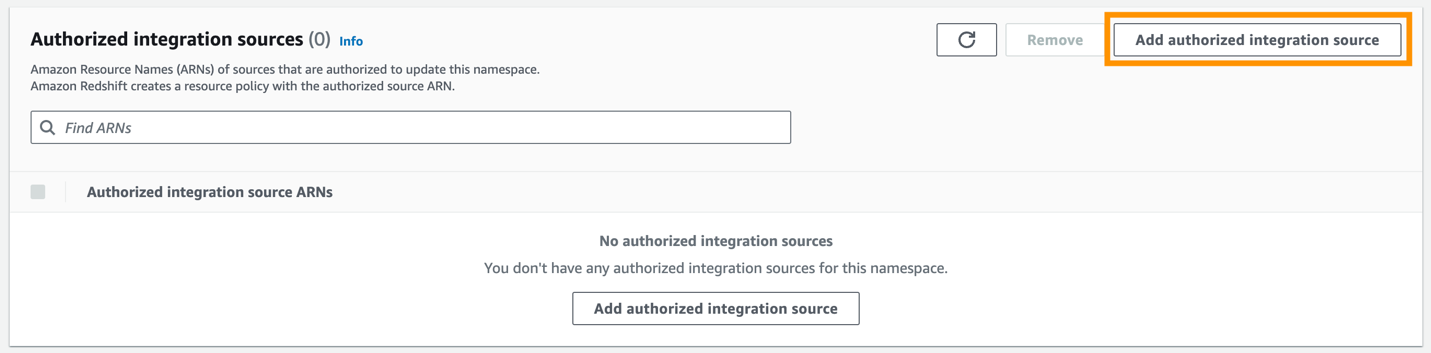
- Nel ARN fonte autorizzata, inserisci l'ARN del cluster Aurora PostgreSQL, perché è l'origine dell'integrazione zero-ETL.
Puoi ottenere l'ARN del cluster Aurora PostgreSQL sulla console Amazon RDS, il file Configurazione scheda sotto Nome della risorsa Amazon.
- Scegli Salvare le modifiche.
Aggiorna il gruppo di lavoro Redshift Serverless per abilitare gli identificatori con distinzione tra maiuscole e minuscole
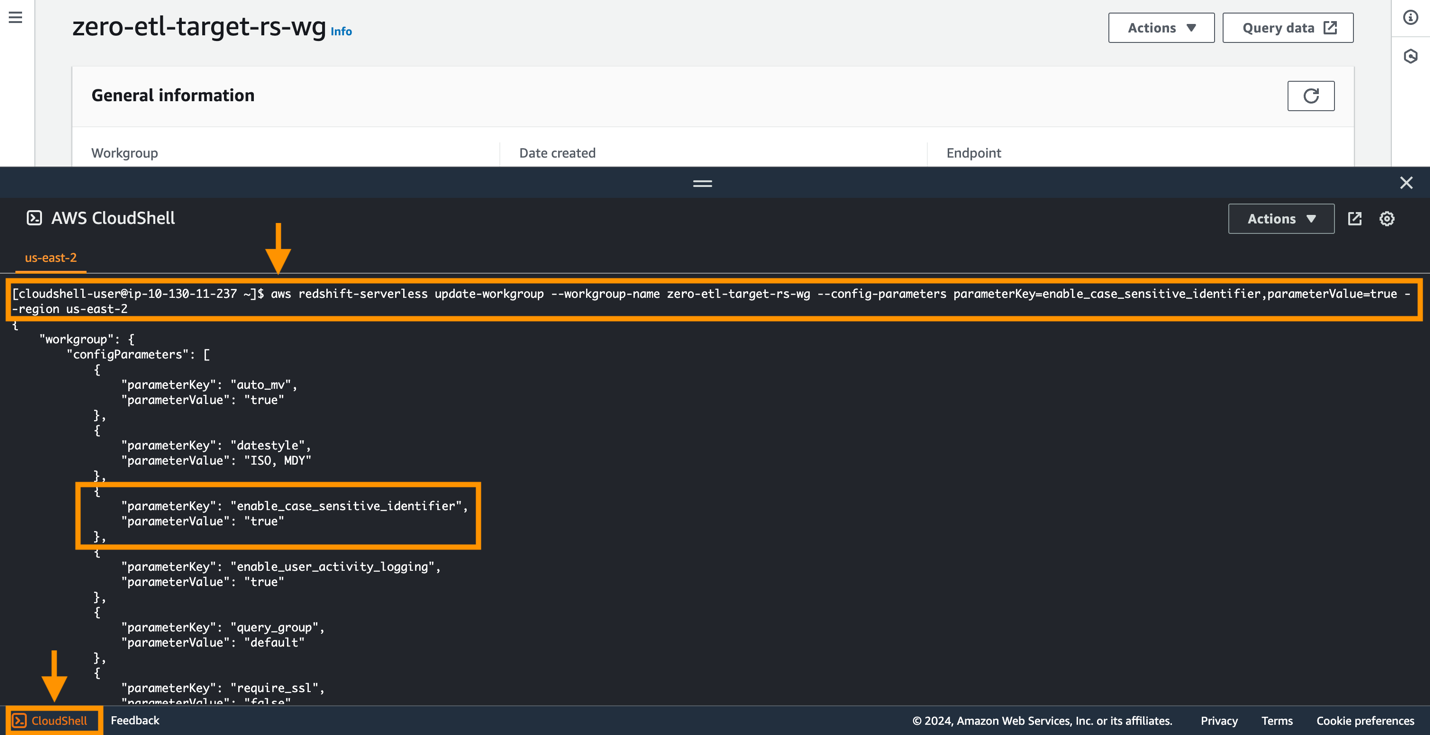
Amazon Aurora PostgreSQL distingue tra maiuscole e minuscole per impostazione predefinita e la distinzione tra maiuscole e minuscole è disabilitata su tutti i cluster sottoposti a provisioning e sui gruppi di lavoro Redshift Serverless. Affinché l'integrazione abbia successo, il parametro di distinzione tra maiuscole e minuscole abilita_case_sensitive_identificatore deve essere abilitato per il data warehouse.
Per modificare il enable_case_sensitive_identifier parametro in un gruppo di lavoro Redshift Serverless, è necessario utilizzare il file Interfaccia della riga di comando di AWS (AWS CLI), poiché la console Amazon Redshift attualmente non supporta la modifica dei valori dei parametri Redshift Serverless. Eseguire il comando seguente per aggiornare il parametro:
Un modo semplice per connettersi all'AWS CLI consiste nell'utilizzare CloudShell, una shell basata su browser che fornisce l'accesso dalla riga di comando alle risorse e agli strumenti AWS direttamente da un browser. Lo screenshot seguente illustra come eseguire il comando in CloudShell.
Configura le autorizzazioni richieste
Per creare un'integrazione zero-ETL, il tuo utente o ruolo deve avere un allegato politica basata sull'identità con l'appropriato Gestione dell'identità e dell'accesso di AWS (IAM) autorizzazioni. Il proprietario di un account AWS può farlo configurare le autorizzazioni richieste per utenti o ruoli che possono creare integrazioni con zero ETL. La policy di esempio consente all'entità associata di eseguire le seguenti azioni:
- Crea integrazioni zero-ETL per il cluster database Aurora di origine.
- Visualizza ed elimina tutte le integrazioni zero-ETL.
- Crea integrazioni in entrata nel data warehouse di destinazione. Amazon Redshift ha un formato ARN diverso per provisioning e serverless:
- Cluster con provisioning -
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - serverless -
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
Questa autorizzazione non è richiesta se lo stesso account possiede il data warehouse Redshift e questo account è un'entità autorizzata per quel data warehouse.
Completare i seguenti passaggi per configurare le autorizzazioni:
- Sulla console IAM, scegli Termini e Condizioni nel pannello di navigazione.
- Scegli Crea politica.
- Crea una nuova policy chiamata rds-integrations utilizzando il seguente JSON. Per l'anteprima di Amazon Aurora PostgreSQL, tutti gli ARN e le azioni all'interno del file Ambiente di anteprima del database Amazon RDS avere -preview aggiunto allo spazio dei nomi del servizio. Pertanto, nella seguente policy, invece di rds, è necessario utilizzare
rds-preview. Per esempio,rds-preview:CreateIntegration.
- Collega la policy che hai creato alle tue autorizzazioni utente o ruolo IAM.
Crea l'integrazione zero-ETL
Per creare l'integrazione zero-ETL, completare i seguenti passaggi:
- Nella console Amazon RDS, scegli Integrazioni Zero-ETL nel pannello di navigazione.
- Scegli Crea un'integrazione zero-ETL.
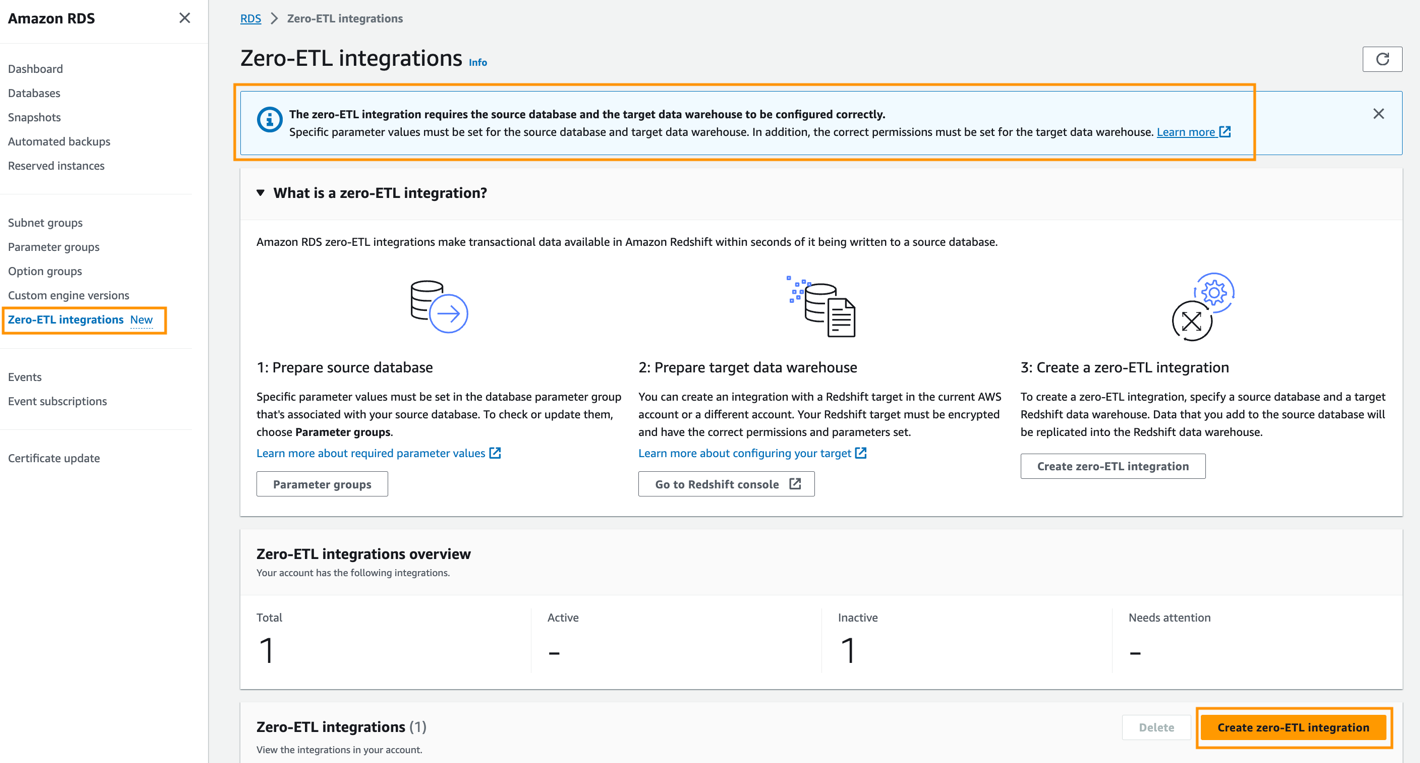
- Nel Identificatore di integrazione, inserire ad esempio un nome
zero-etl-demo. - Scegli Avanti.

- Nel Database di originescegli Sfoglia i database RDS.
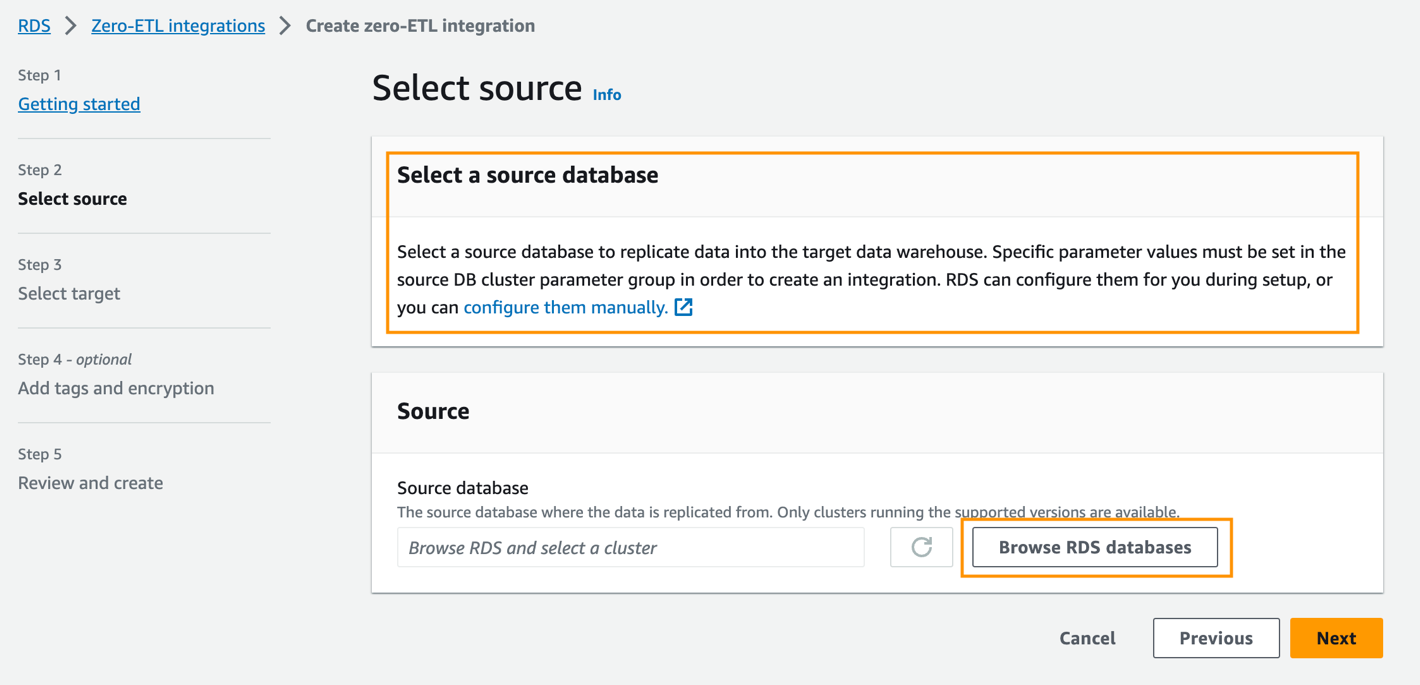
- Seleziona il database di origine
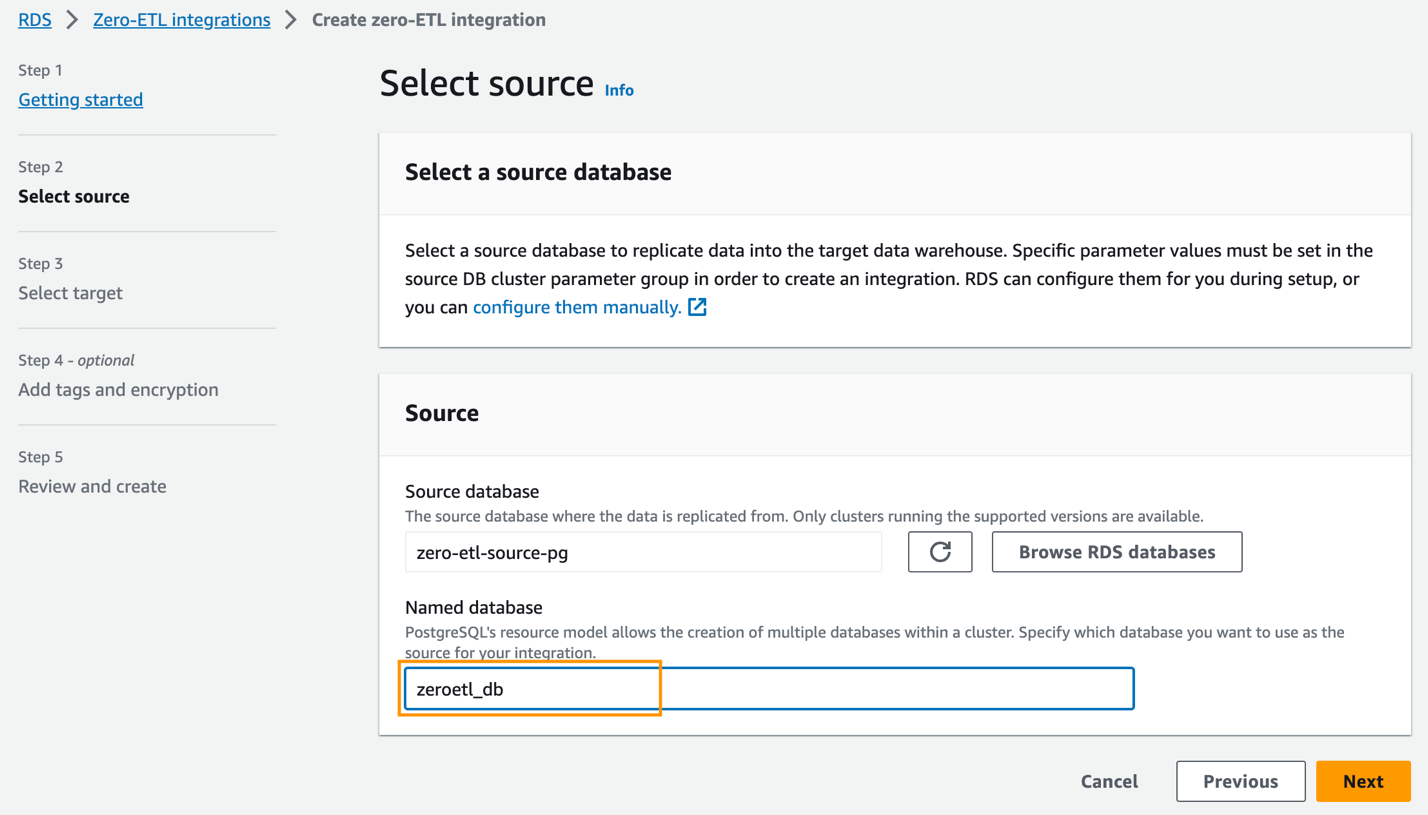
zero-etl-source-pge scegli Scegli. - Nel Banca dati denominata, inserisci il nome del nuovo database creato in Amazon Aurora PostgreSQL (
zeroetl-db). - Scegli Avanti.
- Nel Sezione obiettivo, Per Account AWS, selezionare Utilizza il conto corrente.
- Nel Data warehouse di Amazon Redshiftscegli Sfoglia i data warehouse di Redshift.

Discutiamo di Specifica un altro account opzione più avanti in questa sezione.
- Seleziona lo spazio dei nomi di destinazione Redshift Serverless (
zero-etl-target-rs-ns) e scegli Scegli.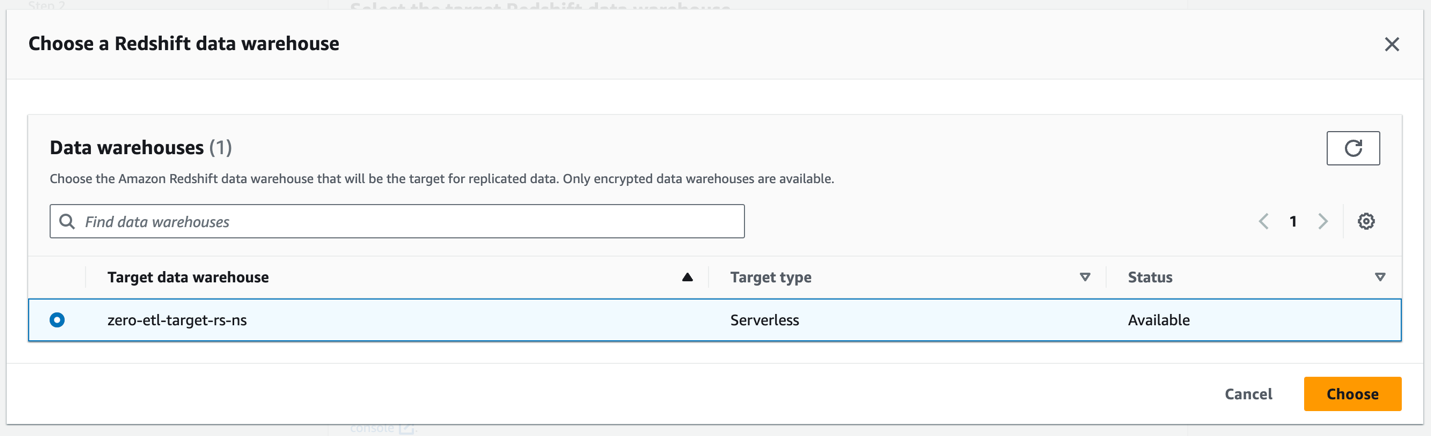
- Aggiungi tag e crittografia, se applicabile, e scegli Avanti.
- Verifica il nome dell'integrazione, l'origine, la destinazione e altre impostazioni, quindi scegli Crea un'integrazione zero-ETL.
Puoi scegliere l'integrazione sulla console Amazon RDS per visualizzarne i dettagli e monitorarne l'avanzamento. Sono necessari circa 30 minuti per modificare lo stato Creazione a Attivo, a seconda della dimensione del set di dati già disponibile nell'origine.
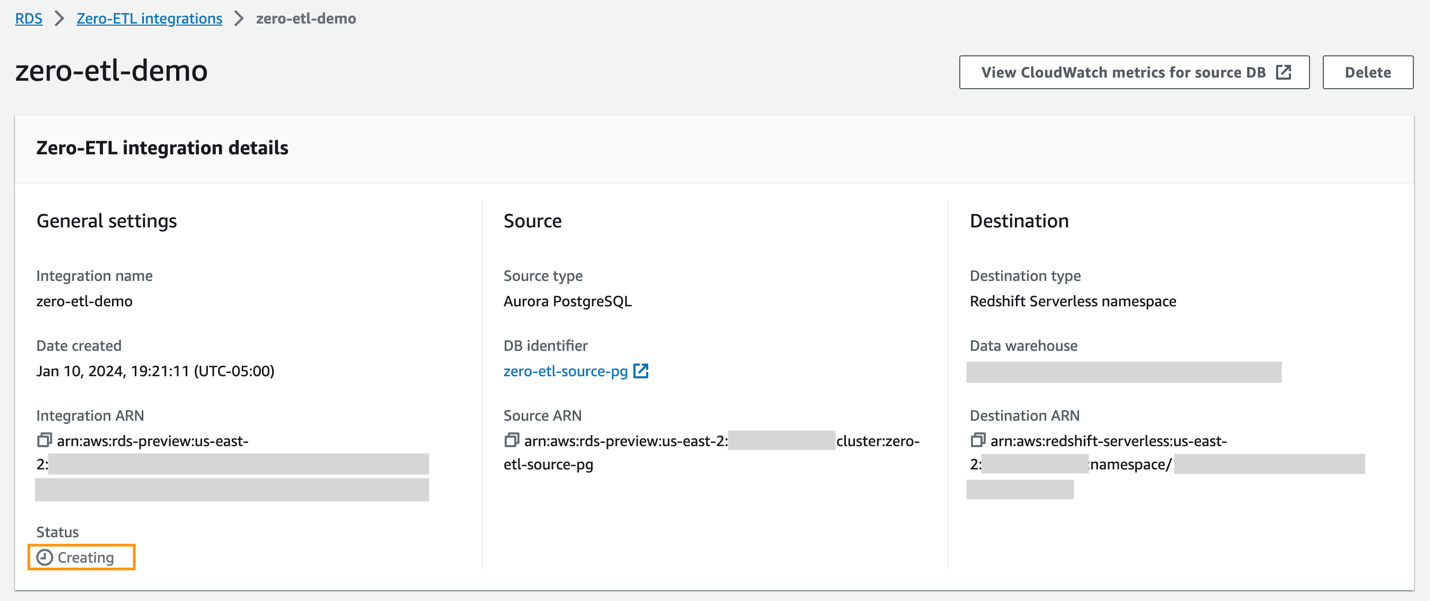
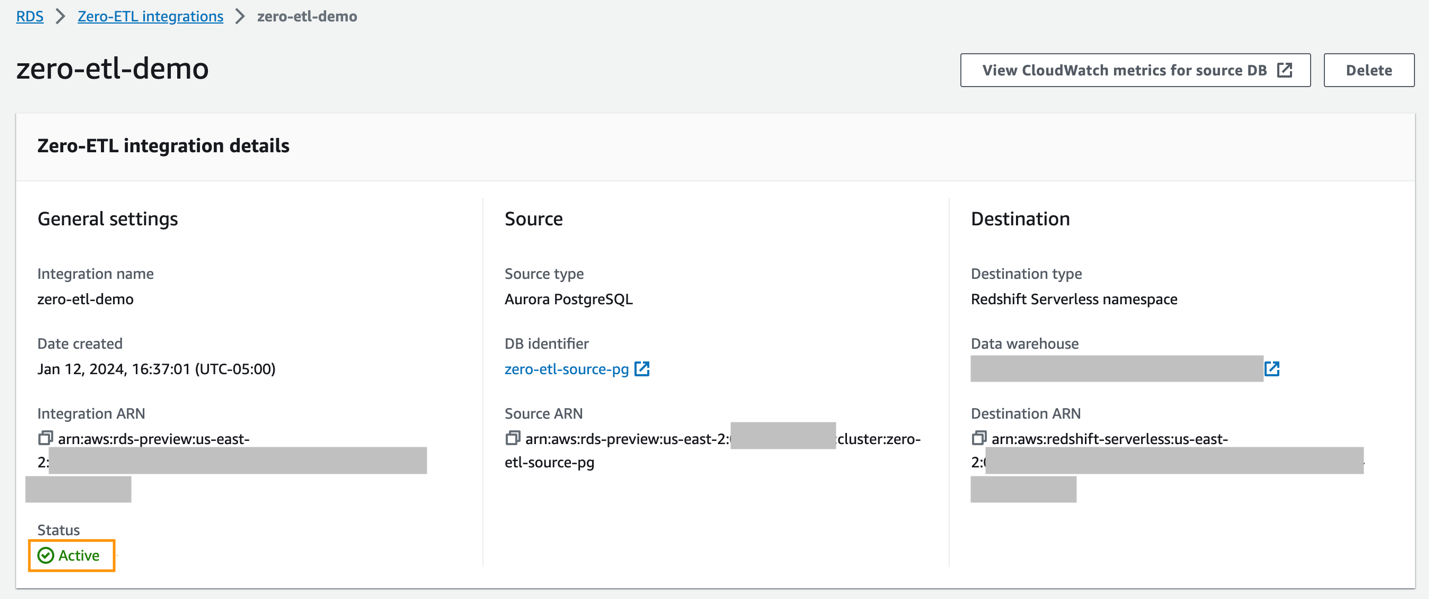
Per specificare un data warehouse Redshift di destinazione che si trova in un altro account AWS, devi creare un ruolo che consenta agli utenti dell'account corrente di accedere alle risorse nell'account di destinazione. Per ulteriori informazioni, fare riferimento a Fornire l'accesso a un utente IAM in un altro account AWS di tua proprietà.
Crea un ruolo nell'account di destinazione con le seguenti autorizzazioni:
Il ruolo deve avere la seguente policy di attendibilità, che specifica l'ID account di destinazione. Puoi farlo creando un ruolo con un'entità attendibile come ID account AWS in un altro account.
Lo screenshot seguente illustra come crearlo nella console IAM.
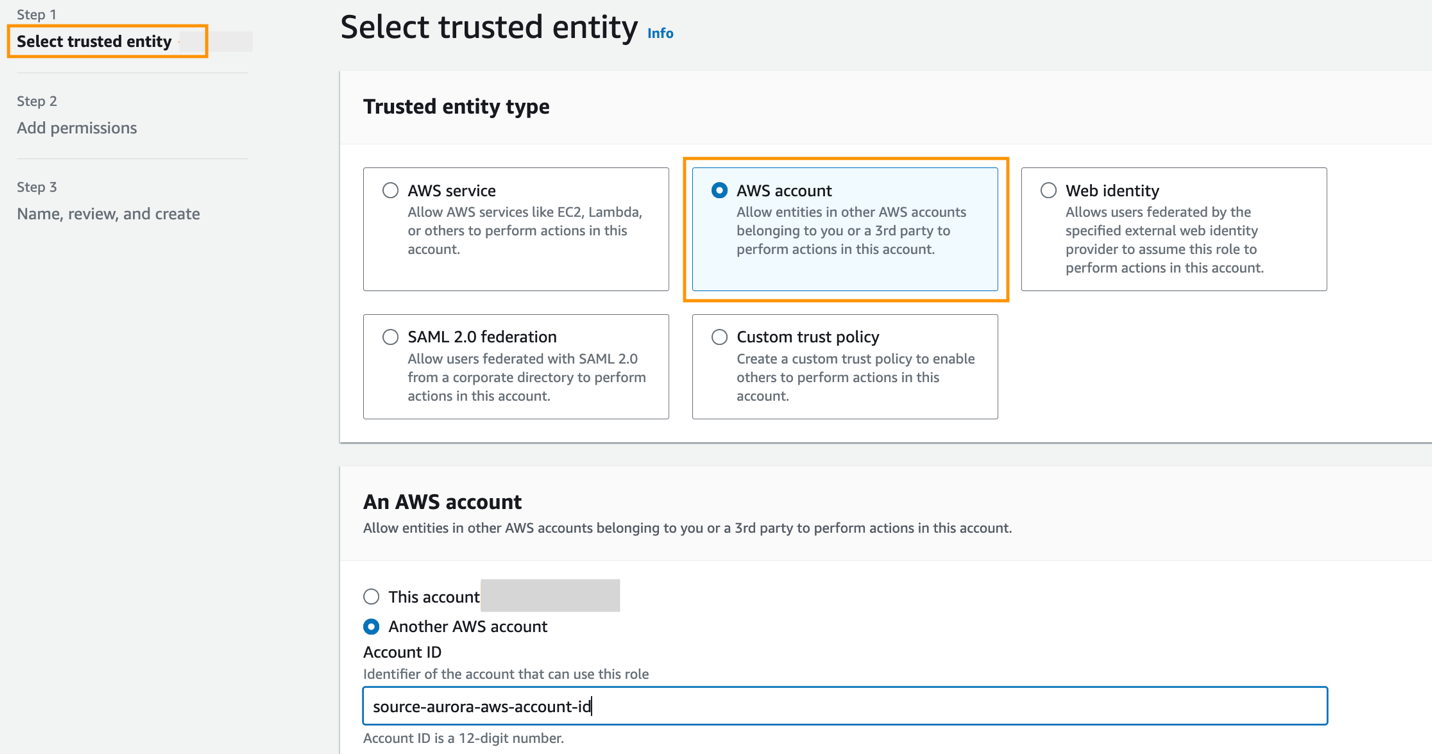
Quindi, durante la creazione dell'integrazione zero-ETL, for Specifica un altro account, scegli l'ID account di destinazione e il nome del ruolo che hai creato.
Crea un database dall'integrazione in Amazon Redshift
Per creare il tuo database, completa i seguenti passaggi:
- Nella dashboard di Redshift Serverless, vai a
zero-etl-target-rs-nsspazio dei nomi. - Scegli Interroga i dati per aprire l'editor di query v2.

- Connettiti al data warehouse Redshift Serverless scegliendo Crea connessione.
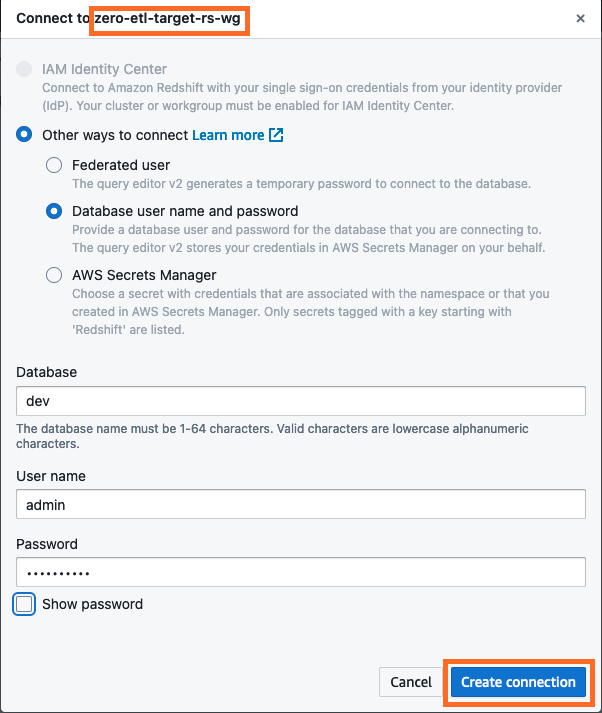
- Ottieni il file
integration_iddalsvv_integrationtabella di sistema: - Usa il
integration_iddal passaggio precedente per creare un nuovo database dall'integrazione. È inoltre necessario includere un riferimento al database denominato all'interno del cluster specificato al momento della creazione dell'integrazione.CREATE DATABASE aurora_pg_zetl FROM INTEGRATION '<result from above>' DATABASE zeroetl_db;
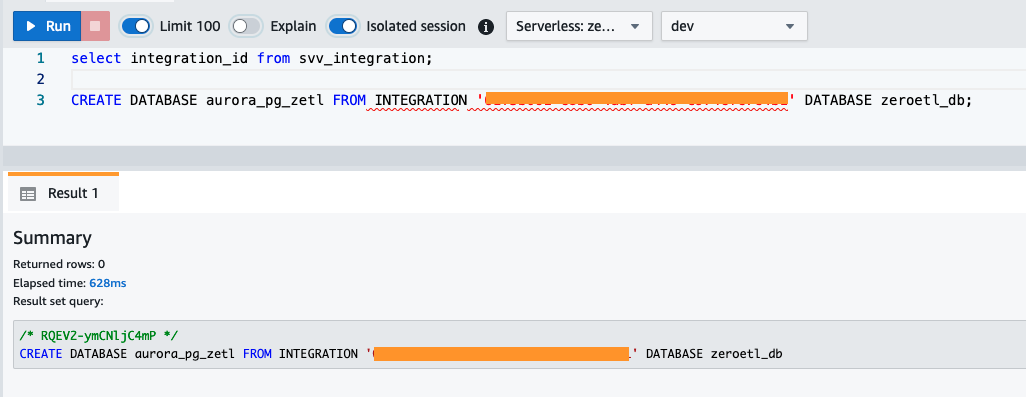
L'integrazione è ora completa e un'intera istantanea dell'origine rifletterà com'è nella destinazione. Le modifiche in corso verranno sincronizzate quasi in tempo reale.
Analizzare i dati transazionali quasi in tempo reale
Ora puoi iniziare ad analizzare i dati quasi in tempo reale dall'origine Amazon Aurora PostgreSQL alla destinazione Amazon Redshift:
- Connettiti al database Aurora PostgreSQL di origine. In questa demo utilizziamo psql per connettersi ad Amazon Aurora PostgreSQL:

- Crea una tabella di esempio con una chiave primaria. Assicurati che tutte le tabelle da replicare dall'origine alla destinazione abbiano una chiave primaria. Le tabelle senza una chiave primaria non possono essere replicate nella destinazione.
- Inserisci i dati fittizi nella tabella delle nazioni e verifica se i dati sono caricati correttamente:

Questi dati di esempio dovrebbero ora essere replicati in Amazon Redshift.
Analizzare i dati di origine nella destinazione
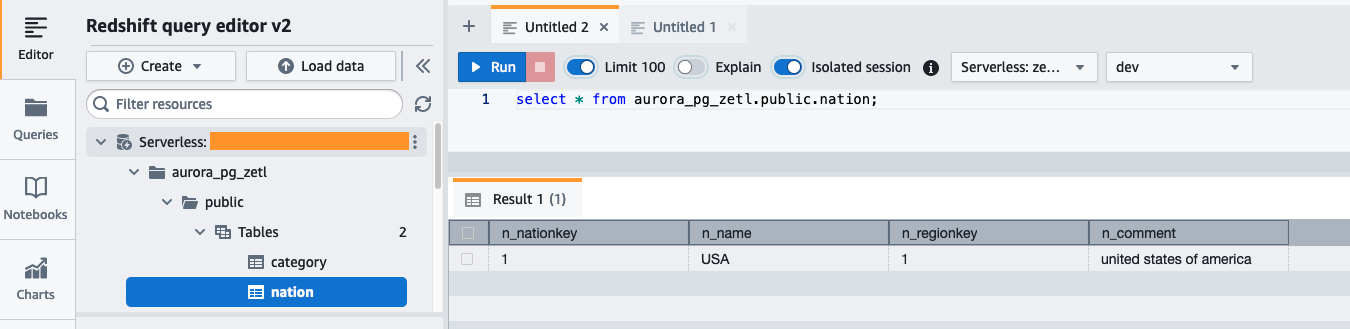
Nella dashboard Redshift Serverless, apri l'editor di query v2 e connettiti al database aurora_pg_zetl hai creato in precedenza.
Esegui la query seguente per convalidare la corretta replica dei dati di origine in Amazon Redshift:
Puoi anche utilizzare la query seguente per convalidare lo snapshot iniziale o l'attività CDC (Change Data Capture) in corso:
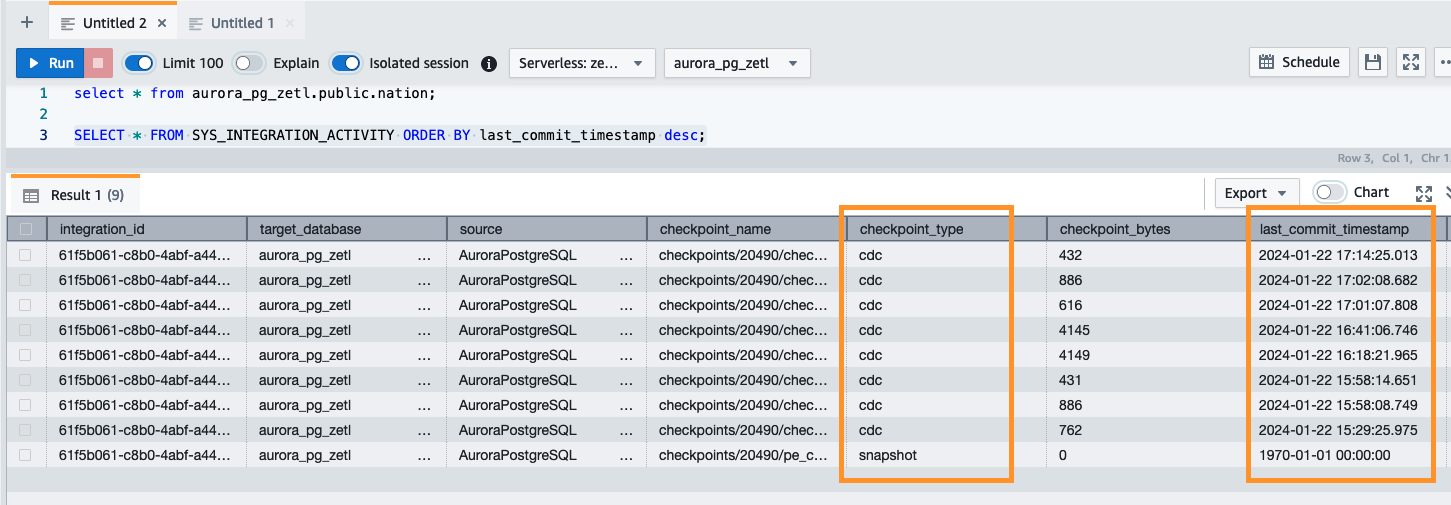
Controllo
Sono disponibili diverse opzioni per ottenere parametri sulle prestazioni e sullo stato dell'integrazione zero-ETL di Aurora PostgreSQL con Amazon Redshift.
Se accedi alla console Amazon Redshift, puoi scegliere Integrazioni Zero-ETL nel riquadro di navigazione. Puoi scegliere l'integrazione zero-ETL che desideri e visualizzare Amazon Cloud Watch metriche relative all'integrazione. Questi parametri sono direttamente disponibili anche in CloudWatch.
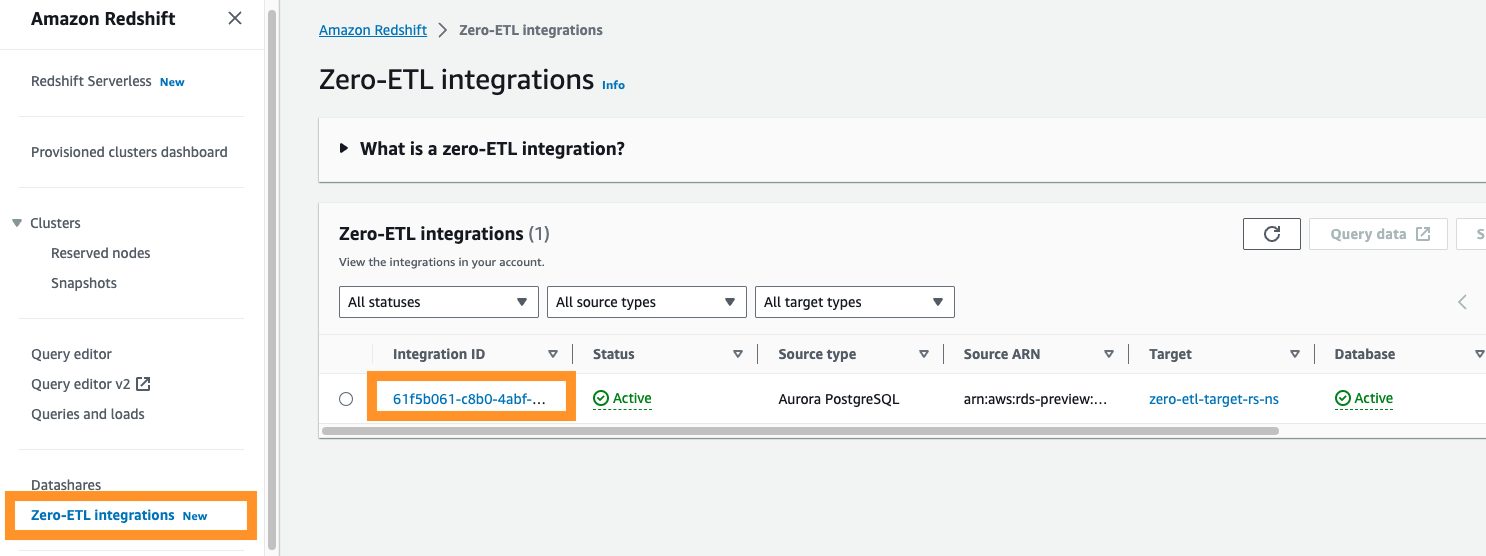
Per ciascuna integrazione sono disponibili due schede con le informazioni:
- Metriche di integrazione – Mostra parametri come il numero di tabelle replicate con successo e i dettagli sul ritardo
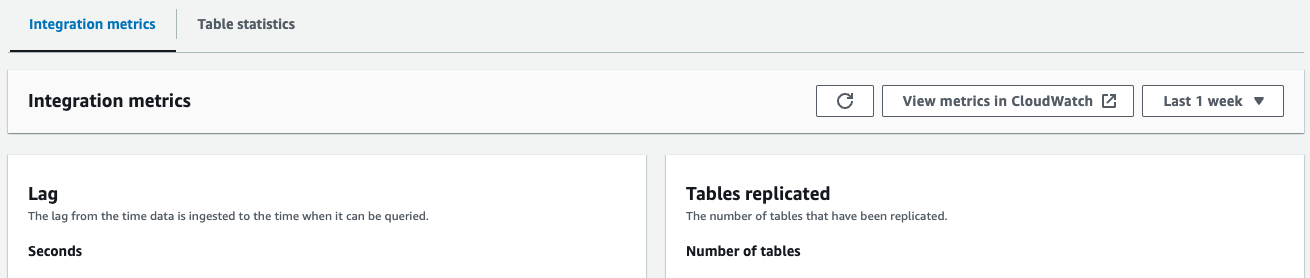
- Statistiche tabella – Mostra i dettagli su ciascuna tabella replicata da Amazon Aurora PostgreSQL ad Amazon Redshift
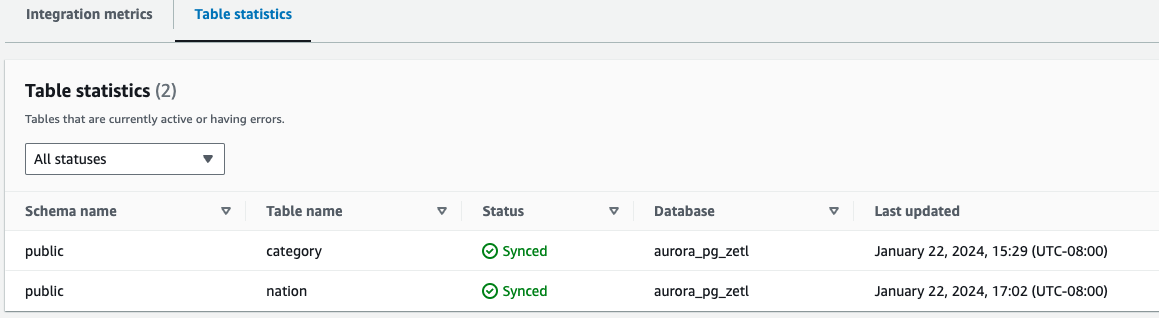
Oltre ai parametri CloudWatch, puoi eseguire query su quanto segue viste di sistema, che forniscono informazioni sulle integrazioni:
ripulire
Quando elimini un'integrazione ETL zero, i dati transazionali non vengono eliminati da Aurora o Amazon Redshift, ma Aurora non invia nuovi dati a Amazon Redshift.
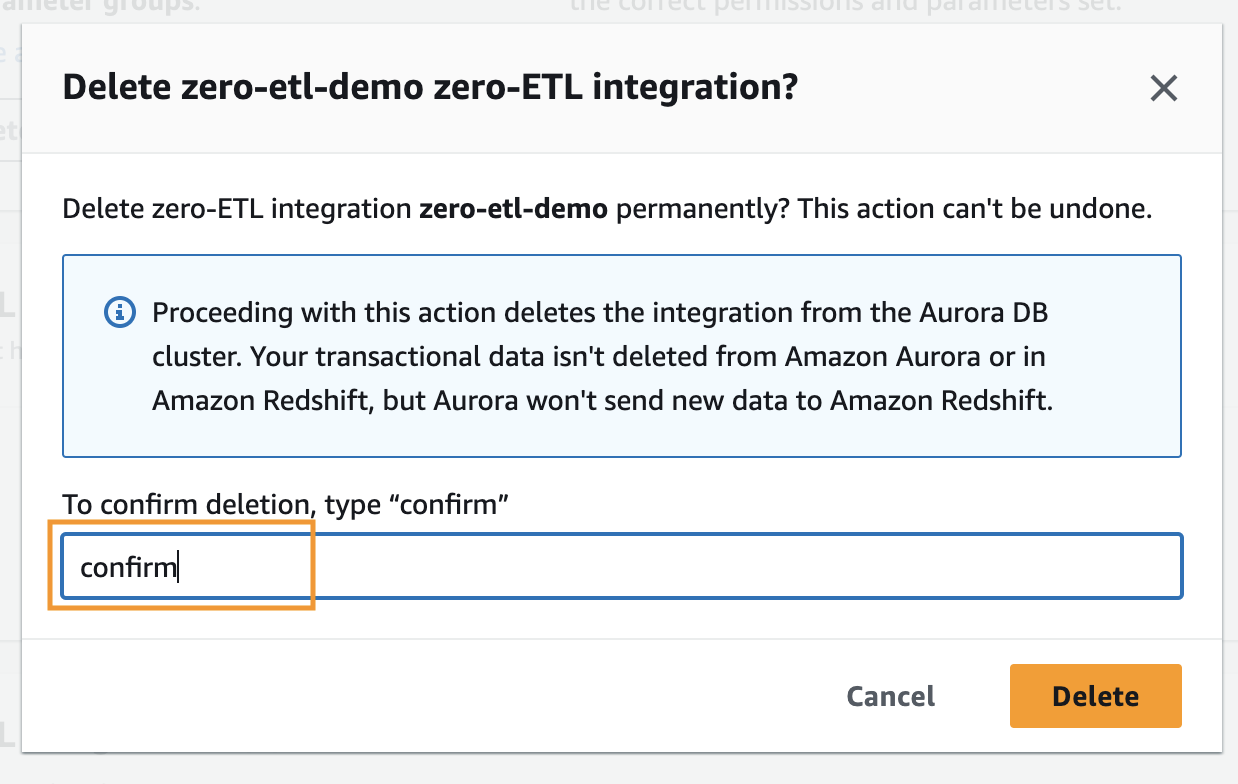
Per eliminare un'integrazione zero-ETL, completa i seguenti passaggi:
- Nella console Amazon RDS, scegli Integrazioni Zero-ETL nel pannello di navigazione.
- Selezionare l'integrazione zero-ETL che si desidera eliminare e scegliere Elimina.

- Per confermare l'eliminazione, inserire conferma e scegliere Elimina.
Conclusione
In questo post, abbiamo spiegato come configurare l'integrazione zero-ETL da Amazon Aurora PostgreSQL ad Amazon Redshift, una funzionalità che riduce lo sforzo di manutenzione delle pipeline di dati e consente analisi quasi in tempo reale sui dati transazionali e operativi.
Per ulteriori informazioni sull'integrazione zero-ETL, fare riferimento a Utilizzo delle integrazioni Aurora zero-ETL con Amazon Redshift ed Limiti.
Informazioni sugli autori
 Rak Khare è un Analytics Specialist Solutions Architect presso AWS con sede in Pennsylvania. Aiuta i clienti a progettare soluzioni di analisi dei dati su larga scala sulla piattaforma AWS.
Rak Khare è un Analytics Specialist Solutions Architect presso AWS con sede in Pennsylvania. Aiuta i clienti a progettare soluzioni di analisi dei dati su larga scala sulla piattaforma AWS.
 Juan Luis Polo Garzon è un Associate Specialist Solutions Architect presso AWS, specializzato in carichi di lavoro di analisi. Ha esperienza nell'aiutare i clienti a progettare, costruire e modernizzare le loro soluzioni di analisi basate su cloud. Al di fuori del lavoro, gli piace viaggiare, all'aria aperta, fare escursioni e partecipare ad eventi di musica dal vivo.
Juan Luis Polo Garzon è un Associate Specialist Solutions Architect presso AWS, specializzato in carichi di lavoro di analisi. Ha esperienza nell'aiutare i clienti a progettare, costruire e modernizzare le loro soluzioni di analisi basate su cloud. Al di fuori del lavoro, gli piace viaggiare, all'aria aperta, fare escursioni e partecipare ad eventi di musica dal vivo.
 Sushmita Barthakur è Senior Solutions Architect presso Amazon Web Services e supporta i clienti aziendali nella progettazione dei propri carichi di lavoro su AWS. Con un forte background in analisi e gestione dei dati, ha una vasta esperienza nell'aiutare i clienti a progettare e creare soluzioni di business intelligence e analisi, sia on-premise che nel cloud. Sushmita vive a Tampa, Florida e ama viaggiare, leggere e giocare a tennis.
Sushmita Barthakur è Senior Solutions Architect presso Amazon Web Services e supporta i clienti aziendali nella progettazione dei propri carichi di lavoro su AWS. Con un forte background in analisi e gestione dei dati, ha una vasta esperienza nell'aiutare i clienti a progettare e creare soluzioni di business intelligence e analisi, sia on-premise che nel cloud. Sushmita vive a Tampa, Florida e ama viaggiare, leggere e giocare a tennis.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/achieve-near-real-time-operational-analytics-using-amazon-aurora-postgresql-zero-etl-integration-with-amazon-redshift/

