Introduzione
Questo articolo introdurrà il concetto di modellazione dei dati, un processo cruciale che delinea il modo in cui i dati vengono archiviati, organizzati e accessibili all'interno di un database o sistema di dati. Implica la conversione delle esigenze aziendali del mondo reale in un formato logico e strutturato che può essere realizzato in un database o data warehouse. Esploreremo come la modellazione dei dati crea un quadro concettuale per comprendere le relazioni e le interconnessioni dei dati all'interno di un'organizzazione o di un dominio specifico. Inoltre, discuteremo dell'importanza di progettare strutture e relazioni di dati per garantire un'archiviazione, un recupero e una manipolazione efficienti dei dati.

Casi d'uso della modellazione dei dati
La modellazione dei dati è fondamentale per gestire e utilizzare i dati in modo efficace in vari scenari. Ecco alcuni casi d'uso tipici per la modellazione dei dati, ciascuno spiegato in dettaglio:
Acquisizione Dati
Nella modellazione dei dati, l'acquisizione dei dati implica la definizione del modo in cui i dati vengono raccolti o generati da varie fonti. Questa fase include la definizione della struttura dati necessaria per conservare i dati in entrata, garantendo che possano essere integrati e archiviati in modo efficiente. Modellando i dati in questa fase, le organizzazioni possono garantire che i dati raccolti siano strutturati per allinearsi alle loro esigenze analitiche e ai processi aziendali. Aiuta a identificare il tipo di dati necessari, il formato in cui dovrebbero essere e come verranno elaborati per un ulteriore utilizzo.
Caricamento dei dati
Una volta acquisiti i dati, devono essere caricati nel sistema di destinazione, come un database, data warehouseo data lago. La modellazione dei dati gioca un ruolo cruciale in questo caso definendo lo schema o la struttura in cui verranno inseriti i dati. Ciò include la specificazione del modo in cui i dati provenienti da origini diverse verranno mappati alle tabelle e alle colonne del database e l'impostazione delle relazioni tra le diverse entità di dati. Una corretta modellazione dei dati garantisce che i dati vengano caricati in modo ottimale, facilitando l'efficienza di archiviazione, accesso e prestazioni delle query.
Calcolo aziendale
La modellazione dei dati è parte integrante della creazione delle strutture per i calcoli aziendali. Questi calcoli generano approfondimenti, metriche e indicatori chiave di prestazione (KPI) dai dati archiviati. Stabilendo un modello dati chiaro, le organizzazioni possono definire il modo in cui i dati provenienti da varie fonti possono essere aggregati, trasformati e analizzati per eseguire calcoli aziendali complessi. Ciò garantisce che i dati sottostanti supportino la derivazione di dati significativi e accurati business intelligence, che può guidare il processo decisionale e la pianificazione strategica.
Distribuzione
La fase di distribuzione rende i dati elaborati disponibili agli utenti finali o ad altri sistemi per l'analisi, il reporting e il processo decisionale. La modellazione dei dati in questa fase si concentra sul garantire che i dati siano strutturati e formattati in modo che siano accessibili e comprensibili per il pubblico previsto. Ciò potrebbe comportare la modellazione dei dati in schemi dimensionali da utilizzare negli strumenti di business intelligence, la creazione di API per l'accesso programmatico o la definizione di formati di esportazione per la condivisione dei dati. Un'efficace modellazione dei dati garantisce che i dati possano essere facilmente distribuiti e consumati su diverse piattaforme e da varie parti interessate, migliorandone l'utilità e il valore.
Ciascuno di questi casi d'uso illustra l'importanza dell'intero ciclo di vita dei dati, dalla raccolta e archiviazione all'analisi e distribuzione. Progettando attentamente le strutture e le relazioni dei dati in ogni fase, le organizzazioni possono garantire che la loro architettura dei dati supporti le loro esigenze operative e analitiche in modo efficiente ed efficace.
Ingegneri/modellatori di dati
Ingegneri di dati e i Data Modeler svolgono un ruolo fondamentale nella gestione e nell'analisi dei dati, ciascuno apportando competenze e competenze uniche per sfruttare la potenza dei dati all'interno di un'organizzazione. Comprendere i ruoli e le responsabilità reciproci può aiutare a chiarire come lavorano insieme per costruire e mantenere solide infrastrutture di dati.
Ingegneri di dati
I Data Engineers sono responsabili della progettazione, costruzione e manutenzione dei sistemi e delle architetture che consentono la gestione efficiente e l'accessibilità dei dati. Il loro ruolo spesso comporta:
- Creazione e manutenzione di pipeline di dati: Creano l'infrastruttura per estrarre, trasformare e caricare dati (ETL) da varie fonti.
- Archiviazione e gestione dei dati: Progettano e implementano sistemi di database, data lake e altre soluzioni di archiviazione per mantenere i dati organizzati e accessibili.
- Ottimizzazione delle prestazioni: I Data Engineer lavorano per garantire che i processi relativi ai dati funzionino in modo efficiente, spesso ottimizzando l'archiviazione dei dati e l'esecuzione delle query.
- Collaborazione con le parti interessate: Lavorano a stretto contatto con analisti aziendali, data scientist e altri utenti per comprendere le esigenze dei dati e implementare soluzioni che consentano un processo decisionale basato sui dati.
- Garantire la qualità e l'integrità dei dati: Implementano sistemi e processi per monitorare, convalidare e pulire i dati, garantendo che gli utenti abbiano accesso a informazioni affidabili e accurate.
Modellatori di dati
I modellatori di dati si concentrano sulla progettazione del progetto sistemi di gestione dei dati. Il loro lavoro prevede la comprensione dei requisiti aziendali e la loro traduzione in strutture di dati che supportino l'archiviazione, il recupero e l'analisi efficiente dei dati. Le responsabilità principali includono:
- Sviluppo di modelli di dati concettuali, logici e fisici: Creano modelli che definiscono come sono correlati i dati e come verranno archiviati nei database.
- Definizione di entità e relazioni di dati: I modellatori di dati identificano le entità chiave di cui il sistema dati di un'organizzazione ha bisogno per rappresentare e definiscono il modo in cui queste entità sono correlate tra loro.
- Garantire la coerenza e la standardizzazione dei dati: Stabiliscono convenzioni e standard di denominazione per gli elementi dei dati per garantire la coerenza all'interno dell'organizzazione.
- Collaborazione con ingegneri e architetti di dati: I Data Modeler lavorano a stretto contatto con i Data Engineer per garantire che l'architettura dei dati supporti efficacemente i modelli progettati.
- Governance e strategia dei dati: Spesso svolgono un ruolo nella governance dei dati, aiutando a definire politiche e standard per la gestione dei dati all'interno dell'organizzazione.
Sebbene esista una certa sovrapposizione nelle competenze e nei compiti di Data Engineer e Data Modeler, i due ruoli si completano a vicenda. I Data Engineers si concentrano sulla costruzione e la manutenzione dell'infrastruttura che supporta l'archiviazione e l'accesso ai dati, mentre i Data Modeler progettano la struttura e l'organizzazione dei dati all'interno di questi sistemi. Garantiscono che l'architettura dei dati di un'organizzazione sia solida, scalabile e allineata agli obiettivi aziendali, consentendo un processo decisionale efficace basato sui dati.
Componenti chiave della modellazione dei dati
La modellazione dei dati è un processo critico nella progettazione e implementazione di database e sistemi di dati che siano efficienti, scalabili e in grado di soddisfare i requisiti di varie applicazioni. I componenti chiave includono entità, attributi, relazioni e chiavi. Comprendere questi componenti è essenziale per creare un modello di dati coerente e funzionale.
Entità
Un'entità rappresenta un oggetto o un concetto del mondo reale che può essere distintamente identificato. In un database, un'entità spesso si traduce in una tabella. Le entità vengono utilizzate per classificare le informazioni che vogliamo archiviare. Ad esempio, in un sistema di gestione delle relazioni con i clienti (CRM), le entità tipiche potrebbero includere "Cliente", "Ordine" e Product.
attributi
Gli attributi sono proprietà o caratteristiche di un'entità. Forniscono dettagli sull'entità, aiutando a descriverla in modo più completo. In una tabella di database, gli attributi rappresentano le colonne. Per l'entità "Cliente", gli attributi possono includere "ID cliente", "Nome", "Indirizzo", "Numero di telefono" e così via. Gli attributi definiscono il tipo di dati (come numero intero, stringa, data e così via) archiviato per ciascuna entità esempio.
Relazioni
Le relazioni descrivono come le entità in un sistema sono collegate tra loro, rappresentando le loro interazioni. Esistono diversi tipi di relazioni:
- Uno a uno (1:1): Ogni istanza dell'Entità A è correlata ad una ed una sola istanza dell'Entità B e viceversa.
- Uno-a-molti (1:N): Ogni istanza dell'Entità A può essere associata a zero, una o più istanze dell'Entità B, ma ogni istanza dell'Entità B è correlata a una sola istanza dell'Entità A.
- Molti-a-molti (M:N): Ogni istanza dell'Entità A può essere associata a zero, una o più istanze dell'Entità B e ogni istanza dell'Entità B può essere associata a zero, una o più istanze dell'Entità A.
Le relazioni sono fondamentali per collegare i dati archiviati in entità diverse, facilitando il recupero dei dati e il reporting su più tabelle.
Keys
Le chiavi sono attributi specifici utilizzati per identificare in modo univoco i record all'interno di una tabella e stabilire relazioni tra tabelle. Esistono diversi tipi di chiavi:
- Chiave primaria: Una colonna, o un insieme di colonne, identifica in modo univoco ciascun record della tabella. All'interno di una tabella non possono essere presenti due record con lo stesso valore di chiave primaria.
- Chiave esterna: Una colonna o un insieme di colonne in una tabella che fa riferimento alla chiave primaria di un'altra tabella. Le chiavi esterne vengono utilizzate per stabilire e rafforzare le relazioni tra le tabelle.
- Chiave composita: Una combinazione di due o più colonne in una tabella che può essere utilizzata per identificare in modo univoco ciascun record della tabella.
- Chiave del candidato: Qualsiasi colonna o insieme di colonne che potrebbe essere considerato una chiave primaria nella tabella.
Comprendere e implementare correttamente questi componenti chiave è fondamentale per creare sistemi efficaci di archiviazione, recupero e gestione dei dati. Una corretta modellazione dei dati porta a database ben organizzati e ottimizzati per prestazioni e scalabilità, supportando le esigenze sia degli sviluppatori che degli utenti finali.
Fasi dei modelli di dati
La modellazione dei dati si svolge tipicamente in tre fasi principali: il modello concettuale dei dati, il modello logico dei dati e il modello fisico dei dati. Ogni fase ha uno scopo specifico e si basa su quella precedente per trasformare progressivamente le idee astratte in una progettazione concreta di database. Comprendere queste fasi è fondamentale per chiunque crei o gestisca sistemi di dati.
Modello di dati concettuale
Il modello concettuale dei dati è il livello più astratto della modellazione dei dati. Questa fase si concentra sulla definizione delle entità di alto livello e delle relazioni tra loro senza entrare nei dettagli di come verranno archiviati i dati. L'obiettivo principale è delineare i principali oggetti dati rilevanti per il dominio aziendale e le loro interazioni in modo che le parti interessate non tecniche possano comprenderle. Questo modello viene spesso utilizzato per la pianificazione e la comunicazione iniziale, collegando i requisiti aziendali e l'implementazione tecnica.
Le caratteristiche chiave includono
- Identificazione di entità importanti e delle loro relazioni.
- Di alto livello, che spesso utilizza la terminologia aziendale.
- Indipendente da qualsiasi sistema di gestione di database (DBMS) o tecnologia.
Modello logico dei dati
Il modello logico dei dati aggiunge maggiori dettagli al modello concettuale, specificando la struttura degli elementi dei dati e impostando le relazioni tra loro. Include la definizione di entità, attributi di ciascuna entità, chiavi primarie e chiavi esterne. Tuttavia, rimane indipendente dalla tecnologia che verrà utilizzata per l’implementazione. Il modello logico è più dettagliato e strutturato rispetto al modello concettuale e inizia a introdurre regole e vincoli che governano i dati.
Le caratteristiche chiave includono
- Definizione dettagliata di entità, relazioni e attributi.
- L'inclusione di chiavi primarie e chiavi esterne è necessaria per stabilire relazioni.
- Vengono applicati processi di normalizzazione per garantire l'integrità dei dati e ridurre la ridondanza.
- Ancora indipendente dalla specifica tecnologia DBMS.
Modello fisico dei dati
Il Physical Data Model è la fase più dettagliata e prevede l'implementazione del modello dati all'interno di uno specifico sistema di gestione del database. Questo modello traduce il modello logico dei dati in uno schema dettagliato che può essere implementato in un database. Include tutti i dettagli necessari per l'implementazione, come tabelle, colonne, tipi di dati, vincoli, indici, trigger e altre funzionalità specifiche del database.
Le caratteristiche principali includono
- Specifico per un particolare DBMS e include l'ottimizzazione specifica del database.
- Specifiche dettagliate di tabelle, colonne, tipi di dati e vincoli.
- Considerazione delle opzioni di archiviazione fisica, strategie di indicizzazione e ottimizzazione delle prestazioni.
La transizione attraverso queste fasi consente la pianificazione e la progettazione meticolosa di un sistema dati allineato ai requisiti aziendali e ottimizzato per le prestazioni all'interno di un ambiente tecnico specifico. Il modello concettuale garantisce che la struttura complessiva sia in linea con gli obiettivi aziendali, il modello logico colma il divario tra pianificazione concettuale e implementazione fisica e il modello fisico garantisce che il database sia ottimizzato per l'uso effettivo.
Esempio di set di dati scolastici
Entità: studenti, insegnanti e classi.
Modello di dati concettuale
Questo modello concettuale di dati delinea un sistema di database per la gestione dei registri scolastici, caratterizzato da tre entità principali: studente, insegnante e classe. In questo modello, gli studenti possono essere associati a più insegnanti e classi, mentre gli insegnanti possono istruire più studenti e condurre varie classi. Ogni classe accoglie numerosi studenti ma è insegnata da un unico insegnante. Il progetto mira a semplificare la comprensione delle relazioni tra le entità per le parti interessate sia tecniche che non tecniche, fornendo una panoramica chiara e intuitiva della struttura del sistema. Partire da un modello concettuale consente la graduale integrazione di elementi più dettagliati, ponendo solide basi per lo sviluppo di sofisticati modelli di database.
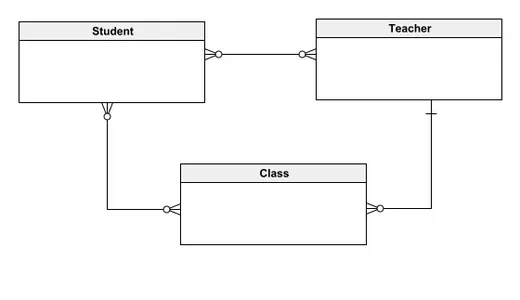
Modello logico dei dati
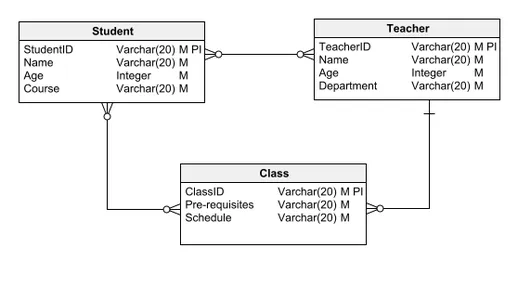
Il modello logico dei dati, molto apprezzato per il suo equilibrio tra chiarezza e dettaglio, incorpora entità, relazioni, attributi, CHIAVI PRIMARIE e CHIAVI ESTERE. Delinea meticolosamente la progressione logica dei dati all'interno di un database, chiarendo dettagli granulari come la sua composizione o i tipi di dati utilizzati. Il modello logico dei dati fornisce basi sufficienti affinché lo sviluppo del software possa iniziare la costruzione vera e propria del database.
Partendo dal modello concettuale dei dati discusso in precedenza, esaminiamo un tipico modello logico dei dati. A differenza del suo predecessore concettuale, questo modello è arricchito di attributi e chiavi primarie. Ad esempio, l'entità Student è distinta da uno StudentID come chiave primaria e identificatore univoco, insieme ad altri attributi vitali come nome ed età.
Questo approccio viene applicato in modo coerente ad altre entità, come Insegnante e Classe, preservando le relazioni stabilite nel modello concettuale e migliorando allo stesso tempo il modello con uno schema dettagliato che include attributi e identificatori chiave.
Modello fisico dei dati
Il modello fisico dei dati è il più dettagliato tra i livelli di astrazione, incorporando specifiche su misura per il sistema di gestione del database scelto, come PostgreSQL, Oracle o MySQL. In questo modello, le entità vengono tradotte in tabelle e gli attributi diventano colonne, rispecchiando la struttura di un database reale. A ciascuna colonna viene assegnato un tipo di dati specifico, ad esempio INT per numeri interi, VARCHAR per stringhe di caratteri variabili o DATE per le date.
Data la sua natura dettagliata, il modello fisico dei dati approfondisce gli aspetti tecnici esclusivi della piattaforma di database in uso. Questi aspetti comprensivi si estendono oltre l’ambito di una panoramica di alto livello. Ciò include considerazioni come l'allocazione dello spazio di archiviazione, le strategie di indicizzazione e i vincoli di implementazione, che sono cruciali per le prestazioni e l'integrità del database ma sono in genere troppo granulari per una discussione preliminare.

Fasi della modellazione dei dati
- Comprendere i requisiti aziendali: Partecipare a discussioni dettagliate con le parti interessate per comprendere lo scopo aziendale del database. Le considerazioni chiave includono l'identificazione del dominio aziendale, le esigenze di archiviazione dei dati e i problemi che il database intende risolvere. Concentrarsi sull'allineamento della progettazione del database con gli obiettivi aziendali in termini di prestazioni, costi e sicurezza.
- Collaborazione in team: Lavorare a stretto contatto con altri team (ad esempio, progettisti e sviluppatori UX/UI) per garantire che il database supporti la soluzione più ampia. Adattare formati e tipologie di dati per soddisfare i requisiti applicativi, enfatizzando la progettazione collaborativa e le capacità di comunicazione.
- Sfruttare gli standard di settore: Ricerca modelli e standard esistenti per evitare di iniziare da zero. Utilizza le migliori pratiche del settore per risparmiare tempo e risorse, concentrando sforzi unici sugli aspetti del tuo database che lo differenziano dai modelli esistenti.
- Inizia la modellazione del database: Con una solida conoscenza delle esigenze aziendali, degli input del team e degli standard di settore, inizia con la modellazione concettuale, passa a quella logica e finalizza con il modello fisico. Questo approccio strutturato garantisce una comprensione completa delle entità, degli attributi e delle relazioni richieste, facilitando un'implementazione fluida del database in linea con gli obiettivi aziendali.
Gli strumenti di modellazione dei dati sono essenziali per la progettazione, il mantenimento e l'evoluzione delle strutture dati organizzative. Questi strumenti offrono una gamma di funzionalità per supportare l'intero ciclo di vita di progettazione e gestione del database. Le caratteristiche principali da cercare negli strumenti di modellazione dei dati includono:
- Costruisci modelli di dati: Facilitare la creazione di modelli di dati concettuali, logici e fisici, consentendo la chiara definizione di entità, attributi e relazioni. Questa funzionalità principale supporta la progettazione iniziale e continua dell'architettura del database.
- Collaborazione e archivio centrale: Consenti ai membri del team di collaborare alla progettazione e alle modifiche del modello dati. Un repository centrale garantisce che le versioni più recenti siano accessibili a tutte le parti interessate, promuovendo coerenza ed efficienza nello sviluppo.
- Ingegneria inversa: Fornire la possibilità di importare script SQL o connettersi a database esistenti per generare modelli di dati. Ciò è particolarmente utile per comprendere e documentare i sistemi legacy o integrare database esistenti.
- Ingegneria avanzata: Consente di generare script o codice SQL dal modello dati. Questa funzionalità semplifica l'implementazione delle modifiche nella struttura del database, garantendo che il database fisico rifletta il modello più recente.
- Supporto per vari tipi di database: Offri compatibilità con più sistemi di gestione di database (DBMS), come MySQL, PostgreSQL, Oracle, SQL Server e altri. Questa flessibilità garantisce che lo strumento possa essere utilizzato in diversi progetti e ambienti tecnologici.
- Controllo della versione: Includere o integrare sistemi di controllo della versione per tenere traccia delle modifiche apportate ai modelli di dati nel tempo. Questa funzionalità è fondamentale per gestire le iterazioni della struttura del database e facilitare il rollback alle versioni precedenti, se necessario.
- Esportazione di diagrammi in diversi formati: Consenti agli utenti di esportare modelli di dati e diagrammi in vari formati (ad esempio, PDF, PNG, XML), facilitando la condivisione e la documentazione. Ciò garantisce che anche le parti interessate non tecniche possano rivedere e comprendere l'architettura dei dati.
La scelta di uno strumento di modellazione dei dati con queste funzionalità può migliorare in modo significativo l'efficienza, l'accuratezza e la collaborazione delle attività di gestione dei dati all'interno di un'organizzazione, garantendo che i database siano ben progettati, aggiornati e allineati alle esigenze aziendali.
Pronto Soccorso/Studio

Offre funzionalità di modellazione complete e funzionalità di collaborazione e supporta varie piattaforme di database.
Collegamento pronto soccorso/Studio
IBM InfoSphere Data Architect

Fornisce un ambiente robusto per la progettazione e la gestione di modelli di dati con supporto per l'integrazione e la sincronizzazione con altri prodotti IBM.
Collegamento a IBM InfoSphere Data Architect
Modellatore dati per sviluppatori Oracle SQL

Uno strumento gratuito che supporta il forward engineering e il reverse engineering, il controllo della versione e il supporto multi-database.
Collegamento al modellatore dati Oracle SQL Developer
PowerDesigner (SAP)

Offre funzionalità di modellazione estese, tra cui dati, informazioni e supporto per l'architettura aziendale.
Collegamento a PowerDesigner (SAP).
Modellatore dati Navicat
Conosciuto per la sua interfaccia intuitiva e il supporto per un'ampia gamma di database, consente il forward engineering e il reverse engineering.
Collegamento al modellatore dati Navicat
Questi strumenti semplificano il processo di modellazione dei dati, migliorano la collaborazione del team e garantiscono la compatibilità tra diversi sistemi di database.
Leggi anche: Domande per l'intervista sulla modellazione dei dati
Conclusione
Questo articolo ha approfondito la pratica essenziale della modellazione dei dati, evidenziandone il ruolo fondamentale nell'organizzazione, archiviazione e accesso ai dati all'interno di database e sistemi di dati. Suddividendo il processo in modelli concettuali, logici e fisici, abbiamo illustrato come la modellazione dei dati traduce le esigenze aziendali in framework di dati strutturati, facilitando una gestione efficiente dei dati e un'analisi approfondita.
I punti chiave includono l’importanza di comprendere i requisiti aziendali, la natura collaborativa della progettazione del database che coinvolge varie parti interessate e l’uso strategico degli strumenti di modellazione dei dati per semplificare il processo di sviluppo. La modellazione dei dati garantisce che le strutture dei dati siano ottimizzate per le esigenze attuali e fornisce scalabilità per la crescita futura.
La modellazione dei dati è al centro di una gestione efficace dei dati, consentendo alle organizzazioni di sfruttare i propri dati per il processo decisionale strategico e l'efficienza operativa.
Domande frequenti
Ris. La modellazione dei dati rappresenta visivamente i dati di un sistema, delineando il modo in cui vengono archiviati, organizzati e accessibili. È fondamentale per tradurre i requisiti aziendali in un formato di database strutturato, consentendo un utilizzo efficiente dei dati.
Ris. I casi d'uso chiave includono l'acquisizione, il caricamento, i calcoli aziendali e la distribuzione dei dati, garantendo che i dati vengano raccolti, archiviati e utilizzati in modo efficace per approfondimenti aziendali.
Ris. Gli ingegneri dei dati creano e mantengono l'infrastruttura dei dati, mentre i modellatori dei dati progettano la struttura e l'organizzazione dei dati per supportare gli obiettivi aziendali e l'integrità dei dati.
Ris. Il processo passa dalla comprensione dei requisiti aziendali alla collaborazione con i team, allo sfruttamento degli standard di settore e alla modellazione del database attraverso fasi concettuali, logiche e fisiche.
Ris. Questi strumenti facilitano la progettazione, la collaborazione e l'evoluzione dei modelli di dati, supportando vari tipi di database e consentendo il reverse e forward engineering per una gestione efficiente del database.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.analyticsvidhya.com/blog/2024/03/data-modeling-demystified-crafting-efficient-databases-for-business-insights/

