
Gli alberi decisionali sono uno degli algoritmi supervisionati non lineari più semplici nel mondo del machine learning. Come suggerisce il nome, vengono utilizzati per prendere decisioni in termini ML, la chiamiamo classificazione (sebbene possano essere utilizzati anche per la regressione).
Gli alberi decisionali hanno una struttura ad albero unidirezionale, ovvero in ogni nodo l'algoritmo decide di dividersi in nodi figli in base a determinati criteri di arresto. Più comunemente i DT utilizzano entropia, guadagno di informazioni, indice di Gini, ecc.
Esistono alcuni algoritmi noti nei DT come ID3, C4.5, CART, C5.0, CHAID, QUEST, CRUISE. In questo articolo parleremo del più semplice e antico: ID3.
ID3, o Iternative Dichotomizer, è stata la prima delle tre implementazioni dell'albero decisionale sviluppate da Ross Quinlan.
L'algoritmo costruisce un albero secondo un metodo top-down, partendo da un insieme di righe/oggetti e da una specificazione di caratteristiche. In ciascun nodo dell'albero, viene testata una caratteristica basata sulla minimizzazione dell'entropia o sulla massimizzazione del guadagno di informazioni per dividere l'insieme di oggetti. Questo processo continua finché l'insieme in un dato nodo non diventa omogeneo (cioè il nodo contiene oggetti della stessa categoria). L'algoritmo utilizza una ricerca avida. Seleziona un test utilizzando il criterio del guadagno di informazioni e quindi non esplora mai la possibilità di scelte alternative.
Contro:
- Il modello potrebbe essere troppo aderente.
- Funziona solo su funzionalità categoriali
- Non gestisce i valori mancanti
- Bassa velocità
- Non supporta la potatura
- Non supporta il potenziamento
Ci sono così tanti svantaggi di un algoritmo, perché ne stiamo discutendo?
Risposta: è semplice ed è fantastico sviluppare l'intuizione per gli algoritmi degli alberi.
Una delle filastrocche più popolari in cui la pioggia decide se Johny/Arthur giocherà fuori è il nostro esempio di oggi. L’unico cambiamento è che non solo la pioggia ma qualsiasi maltempo influisce sul gioco del bambino e utilizzeremmo un DT per prevedere la sua presenza all’esterno.

Fonte: Wikipedia
I dati appaiono così:
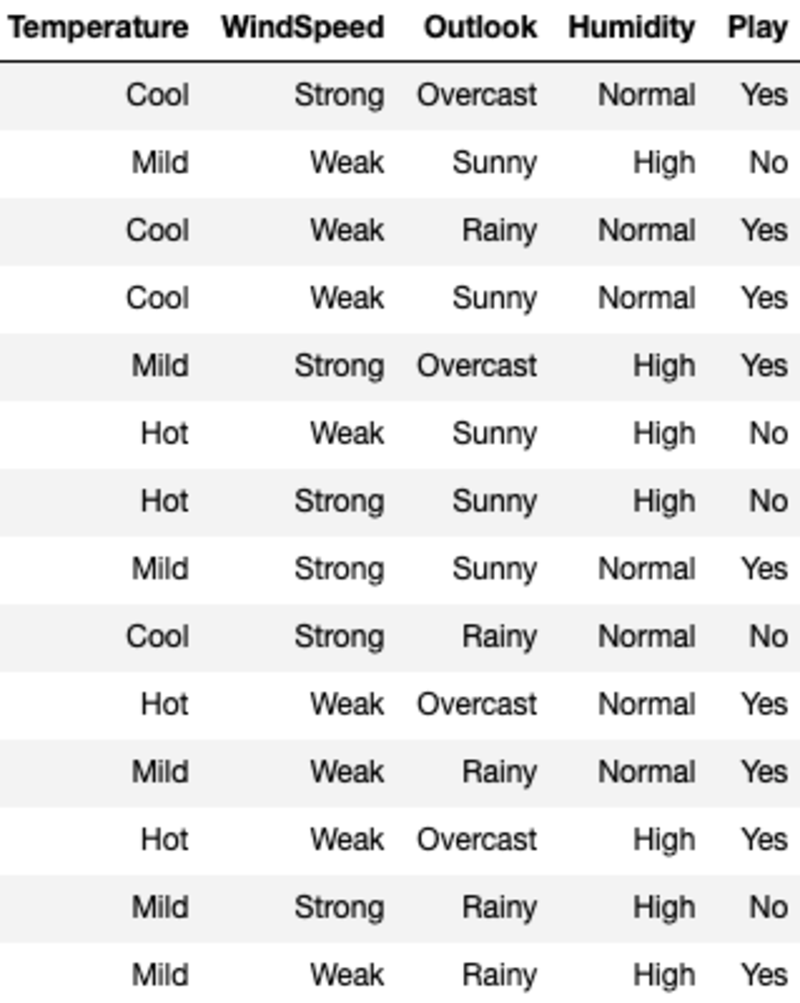
"Temperatura", "Velocità del vento", "Outlook" e "Umidità" sono le funzionalità e "Gioco" è la variabile target. Solo i dati categorici e nessun valore mancante significano che possiamo utilizzare ID3.
Esaminiamo i criteri di suddivisione prima di passare all'algoritmo stesso. Per semplicità, discuteremo ciascun criterio solo per il caso di classificazione binaria.
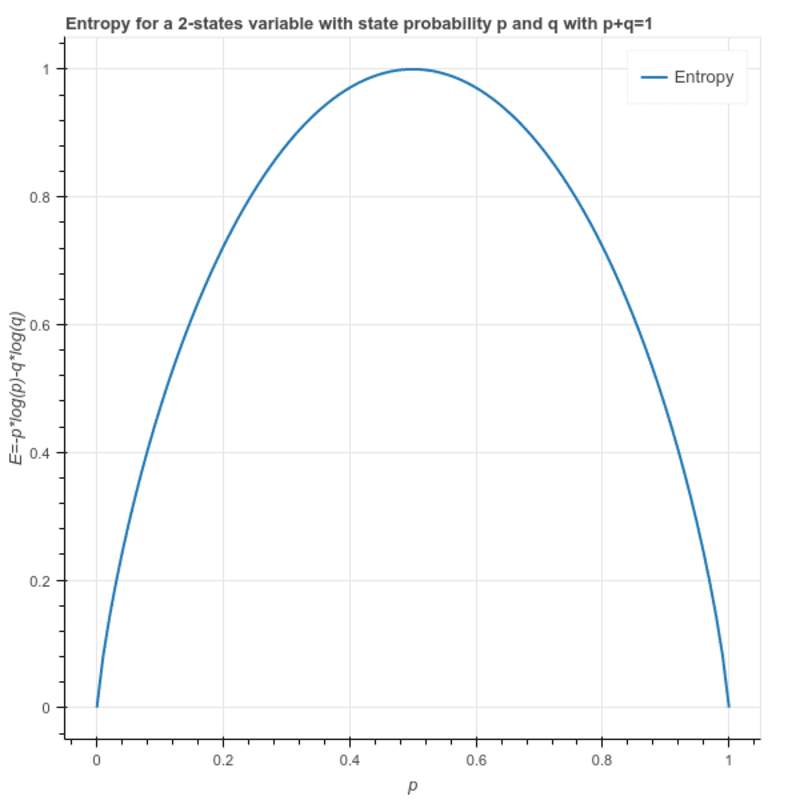
entropia: Viene utilizzato per calcolare l'eterogeneità di un campione e il suo valore è compreso tra 0 e 1. Se il campione è omogeneo l'entropia è 0 e se il campione ha la stessa proporzione di tutte le classi ha un'entropia pari a 1.
S = -(p * log₂p + q * log₂q)
Dove p ed q sono le rispettive proporzioni delle 2 classi nel campione.
Questo può anche essere scritto come: S = -(p * log₂p + (1-p)* log₂(1-p))
Guadagno di informazioni: È la differenza nell'entropia di un nodo e l'entropia media per tutti i valori di un nodo figlio. Per la suddivisione viene scelta la funzione che fornisce il massimo guadagno di informazioni.
L'entropia del nodo radice: (9 — Sì e 5 — No)
S = -(9/14)*log(9/14) — (5/14) * log(5/14) = 0.94
Esistono 4 modi possibili per dividere il nodo radice. ("Temperatura", "Velocità del vento", "Prospettive" e "Umidità"). Pertanto calcoliamo l'entropia media ponderata del nodo figlio se scegliamo una delle opzioni precedenti:
I(Temperature) = Hot*E(Temperature=Hot) + Mild*E(Temperature=Mild) + Cool*E(Temperature=Cool)
Dove Caldo, Medio e Freddo rappresentano la proporzione dei 3 valori nei dati.
I(Temperature) = (4/14)*1 + (6/14)*0.918 + (4/14)*0.811 = 0.911
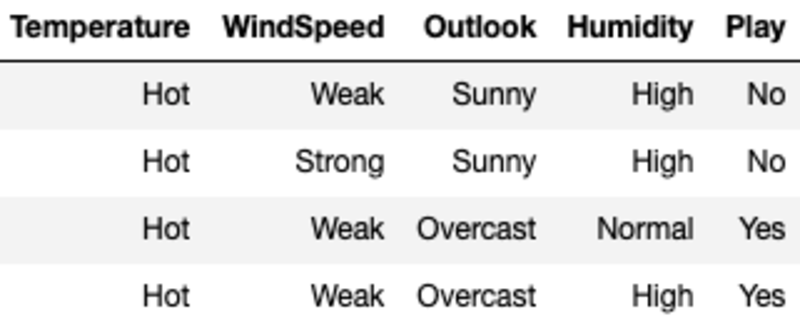
Qui l'entropia per ciascun valore viene calcolata filtrando il campione utilizzando il valore della caratteristica e quindi utilizzando la formula per l'entropia. Ad esempio, E(Temperatura=Calda) viene calcolata filtrando il campione originale in cui la Temperatura è Calda (in questo caso abbiamo un numero uguale di Sì e No, il che significa che Entropia è uguale a 1).
Calcoliamo il guadagno di informazioni della suddivisione sulla temperatura sottraendo l'entropia media per la temperatura dall'entropia dei nodi radice.
G(Temperature) = S — I(Temperature) = 0.94–0.911 = 0.029
Allo stesso modo, calcoliamo il guadagno da tutte e quattro le funzionalità e scegliamo quella con il guadagno massimo.
G(WindSpeed) = S — I(WindSpeed) = 0.94–0.892 =0.048
G(Outlook) = S — I(Outlook) = 0.94–0.693 =0.247
G(Humidity) = S — I(Humidity) = 0.94–0.788 =0.152
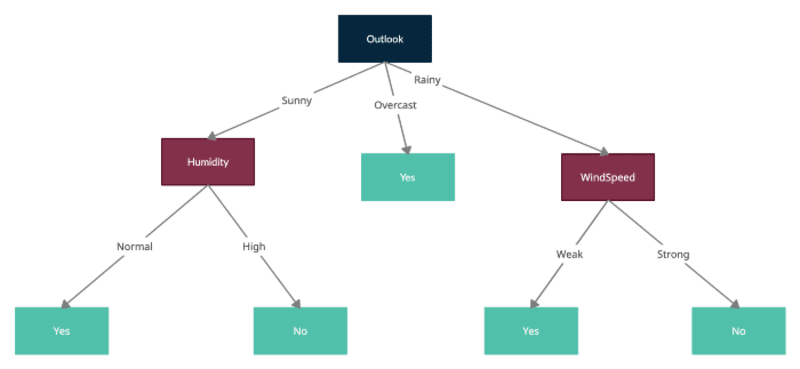
Outlook ha il massimo guadagno di informazioni, quindi divideremo il nodo radice su Outlook e ciascuno dei nodi figlio rappresenta il campione filtrato da uno dei valori di Outlook, ad esempio Soleggiato, Coperto e Piovoso.
Ora ripeteremo lo stesso processo trattando i nuovi nodi formati come nodi radice con campioni filtrati e calcolando le entropie per ciascuno e testando le suddivisioni calcolando l'entropia media per ogni ulteriore suddivisione e sottraendo quella dall'entropia del nodo corrente per ottenere il guadagno di informazioni. Tieni presente che ID3 non consente l'utilizzo di funzionalità già utilizzate per dividere i nodi secondari. Pertanto ciascuna funzionalità può essere utilizzata solo una volta nell'albero per la suddivisione.
Ecco l'albero finale formato da tutte le divisioni:
È possibile trovare una semplice implementazione con codice Python qui
Conclusione
Ho fatto del mio meglio per spiegare il funzionamento dell'ID3, ma so che potresti avere domande. Fatemelo sapere nei commenti e sarò felice di prenderli tutti.
Grazie per la lettura!
Ankit Malik sta creando soluzioni AI/ML scalabili in più ambiti come marketing, catena di fornitura, vendita al dettaglio, pubblicità e automazione dei processi. Ha lavorato su entrambe le estremità dello spettro, dalla guida di progetti di data science in aziende Fortune 500 all'essere membro fondatore di un incubatore di data science in numerose start-up. È stato pioniere di vari prodotti e servizi innovativi e crede nella leadership di servizio.
Originale. Ripubblicato con il permesso.

