Con Basi di conoscenza per Amazon Bedrock, è possibile connettere in modo sicuro i modelli di fondazione (FM). Roccia Amazzonica ai dati aziendali per il Retrieval Augmented Generation (RAG). L'accesso a dati aggiuntivi aiuta il modello a generare risposte più pertinenti, specifiche per il contesto e accurate senza dover riqualificare i FM.
In questo post, discutiamo due nuove funzionalità delle Knowledge Base per Amazon Bedrock specifiche per RetrieveAndGenerate API: configurazione del numero massimo di risultati e creazione di prompt personalizzati con un modello di prompt della knowledge base. Ora puoi sceglierli come opzioni di query insieme al tipo di ricerca.
Panoramica e vantaggi delle nuove funzionalità
L'opzione del numero massimo di risultati ti dà il controllo sul numero di risultati della ricerca da recuperare dall'archivio dei vettori e passare al FM per generare la risposta. Ciò consente di personalizzare la quantità di informazioni di base fornite per la generazione, fornendo così più contesto per domande complesse o meno per domande più semplici. Ti consente di recuperare fino a 100 risultati. Questa opzione aiuta a migliorare la probabilità del contesto rilevante, migliorando così la precisione e riducendo l'allucinazione della risposta generata.
Il modello di prompt personalizzato della Knowledge Base consente di sostituire il modello di prompt predefinito con il proprio per personalizzare il prompt inviato al modello per la generazione della risposta. Ciò consente di personalizzare il tono, il formato di output e il comportamento dell'FM quando risponde alla domanda di un utente. Con questa opzione, puoi ottimizzare la terminologia per adattarla meglio al tuo settore o dominio (ad esempio sanitario o legale). Inoltre, puoi aggiungere istruzioni personalizzate ed esempi su misura per i tuoi flussi di lavoro specifici.
Nelle sezioni seguenti, spieghiamo come utilizzare queste funzionalità con il Console di gestione AWS o SDK.
Prerequisiti
Per seguire questi esempi, è necessario disporre di una base di conoscenza esistente. Per istruzioni su come crearne uno, vedere Crea una base di conoscenza.
Configura il numero massimo di risultati utilizzando la console
Per utilizzare l'opzione del numero massimo di risultati utilizzando la console, completare i seguenti passaggi:
- Sulla console Amazon Bedrock, scegli Basi di conoscenza nel riquadro di navigazione a sinistra.
- Seleziona la knowledge base che hai creato.
- Scegli Testare la base di conoscenza.
- Scegli l'icona di configurazione.
- Scegli Sincronizza origine dati prima di iniziare a testare la tua base di conoscenza.

- Sotto Configurazioni, Per Tipo di ricerca, seleziona un tipo di ricerca in base al tuo caso d'uso.
Per questo post utilizziamo la ricerca ibrida perché combina la ricerca semantica e testuale per garantire una maggiore precisione del provider. Per ulteriori informazioni sulla ricerca ibrida, vedere Le basi di conoscenza per Amazon Bedrock ora supportano la ricerca ibrida.
- Espandere Numero massimo di blocchi di origine e imposta il numero massimo di risultati.

Per dimostrare il valore della nuova funzionalità, mostriamo esempi di come aumentare la precisione della risposta generata. Abbiamo usato Documento Amazon 10K per il 2023 come dati di origine per la creazione della base di conoscenza. Utilizziamo la seguente query per la sperimentazione: "In quale anno le entrate annuali di Amazon sono aumentate da $ 245 miliardi a $ 434 miliardi?"
La risposta corretta a questa domanda è "Le entrate annuali di Amazon sono aumentate da 245 miliardi di dollari nel 2019 a 434 miliardi di dollari nel 2022", in base ai documenti nella knowledge base. Abbiamo utilizzato Claude v2 come FM per generare la risposta finale sulla base delle informazioni contestuali recuperate dalla knowledge base. Anche Claude 3 Sonnet e Claude 3 Haiku sono supportati come generazione FM.
Abbiamo eseguito un'altra query per dimostrare il confronto del recupero con diverse configurazioni. Abbiamo utilizzato la stessa query di input ("In quale anno le entrate annuali di Amazon sono aumentate da $ 245 miliardi a $ 434 miliardi?") e abbiamo impostato il numero massimo di risultati su 5.
Come mostrato nello screenshot seguente, la risposta generata è stata "Mi dispiace, non posso assisterti con questa richiesta".

Successivamente, impostiamo i risultati massimi su 12 e poniamo la stessa domanda. La risposta generata è “L’aumento delle entrate annuali di Amazon da 245 miliardi di dollari nel 2019 a 434 miliardi di dollari nel 2022”.

Come mostrato in questo esempio, siamo in grado di recuperare la risposta corretta in base al numero di risultati recuperati. Se vuoi saperne di più sull'attribuzione della fonte che costituisce l'output finale, scegli Mostra i dettagli della fonte per convalidare la risposta generata in base alla base di conoscenza.
Personalizza un modello di richiesta della knowledge base utilizzando la console
È inoltre possibile personalizzare il prompt predefinito con il proprio prompt in base al caso d'uso. Per farlo sulla console, completare i seguenti passaggi:
- Ripeti i passaggi nella sezione precedente per iniziare a testare la tua knowledge base.
- permettere Genera risposte.

- Seleziona il modello che preferisci per la generazione della risposta.
Usiamo il modello Claude v2 come esempio in questo post. Per la generazione è disponibile anche il modello Claude 3 Sonnet e Haiku.
- Scegli APPLICA procedere.

Dopo aver scelto il modello, una nuova sezione chiamata Modello di richiesta della base di conoscenza appare sotto Configurazioni.
- Scegli Modifica per iniziare a personalizzare il prompt.
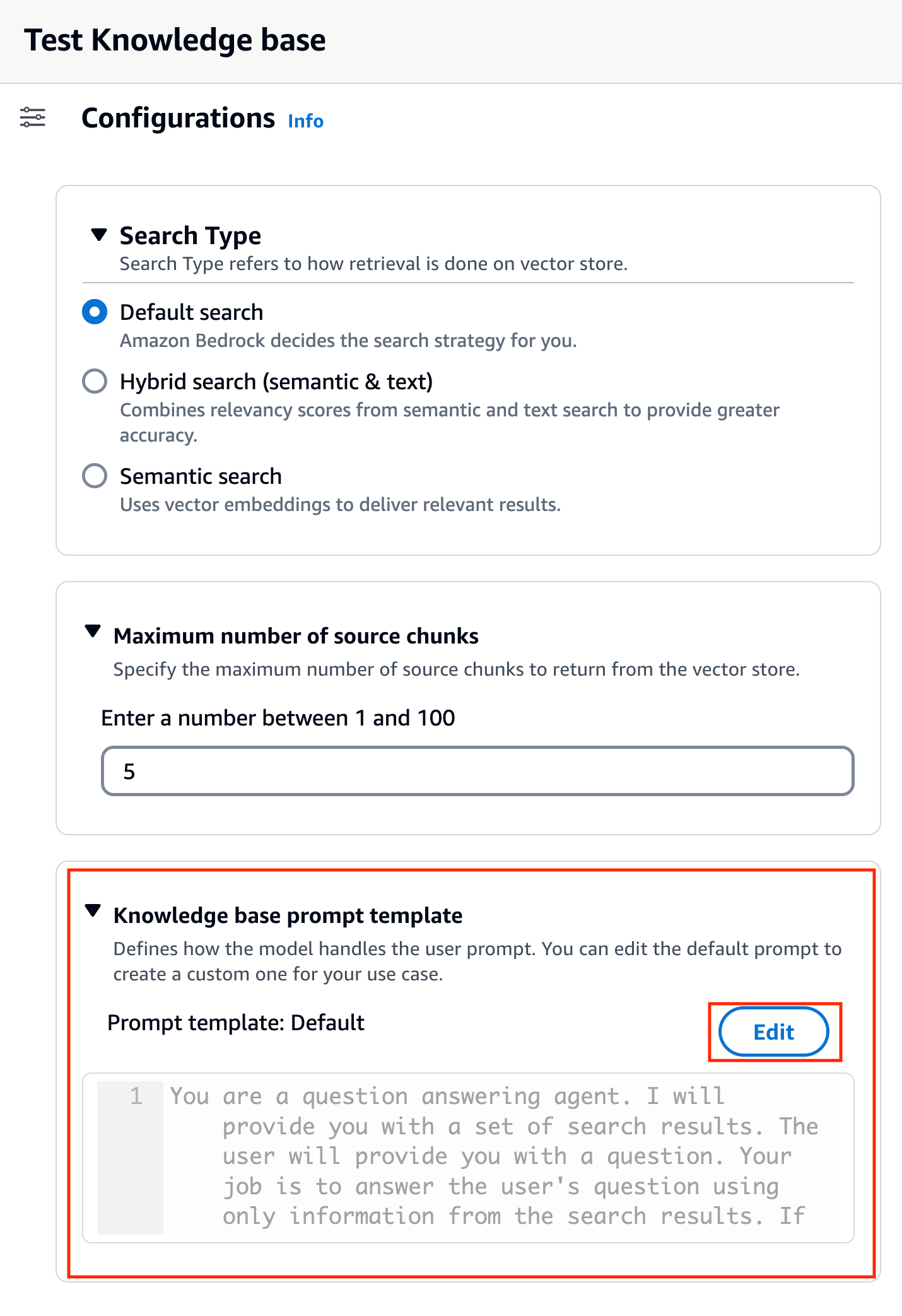
- Modifica il modello di richiesta per personalizzare il modo in cui desideri utilizzare i risultati recuperati e generare contenuto.
Per questo post, abbiamo fornito alcuni esempi per la creazione di un "sistema AI per consulenti finanziari" utilizzando i report finanziari di Amazon con istruzioni personalizzate. Per le migliori pratiche sul prompt engineering, fare riferimento a Linee guida ingegneristiche tempestive.
Ora personalizziamo il modello di prompt predefinito in diversi modi e osserviamo le risposte.
Proviamo prima una query con il prompt predefinito. Chiediamo: “Quali sono state le entrate di Amazon nel 2019 e nel 2021?” Quanto segue mostra i nostri risultati.

Dall'output, scopriamo che sta generando la risposta in formato libero basata sulla conoscenza recuperata. Le citazioni sono elencate anche come riferimento.
Supponiamo di voler fornire istruzioni aggiuntive su come formattare la risposta generata, ad esempio standardizzandola come JSON. Possiamo aggiungere queste istruzioni come passaggio separato dopo aver recuperato le informazioni, come parte del modello di richiesta:
La risposta finale ha la struttura richiesta.

Personalizzando il prompt, puoi anche cambiare la lingua della risposta generata. Nell'esempio seguente, chiediamo al modello di fornire una risposta in spagnolo.

Dopo aver rimosso $output_format_instructions$ dal prompt predefinito, la citazione dalla risposta generata viene rimossa.
Nelle sezioni seguenti spieghiamo come utilizzare queste funzionalità con l'SDK.
Configura il numero massimo di risultati utilizzando l'SDK
Per modificare il numero massimo di risultati con l'SDK, utilizzare la seguente sintassi. Per questo esempio, la query è "In quale anno le entrate annuali di Amazon sono aumentate da $ 245 miliardi a $ 434 miliardi?" La risposta corretta è “L’aumento delle entrate annuali di Amazon da 245 miliardi di dollari nel 2019 a 434 miliardi di dollari nel 2022”.
Il 'numberOfResults'opzione sotto'retrievalConfiguration' ti consente di selezionare il numero di risultati che desideri recuperare. L'uscita del RetrieveAndGenerate L'API include la risposta generata, l'attribuzione della fonte e i blocchi di testo recuperati.
Di seguito sono riportati i risultati per diversi valori di 'numberOfResultsparametri. Per prima cosa, impostiamo numberOfResults = 5.
Poi ci sistemiamo numberOfResults = 12.
Personalizza il modello di richiesta della knowledge base utilizzando l'SDK
Per personalizzare il prompt utilizzando l'SDK, utilizziamo la seguente query con diversi modelli di prompt. Per questo esempio, la query è "Quali sono state le entrate di Amazon nel 2019 e nel 2021?"
Di seguito è riportato il modello di prompt predefinito:
Di seguito è riportato il modello di richiesta personalizzato:
Con il modello di prompt predefinito, otteniamo la seguente risposta:
![]()
Se desideri fornire istruzioni aggiuntive sul formato di output della generazione della risposta, come standardizzare la risposta in un formato specifico (come JSON), puoi personalizzare il prompt esistente fornendo ulteriori indicazioni. Con il nostro modello di prompt personalizzato, otteniamo la seguente risposta.

Il 'promptTemplate'opzione in'generationConfiguration' consente di personalizzare la richiesta per un migliore controllo sulla generazione della risposta.
Conclusione
In questo post abbiamo introdotto due nuove funzionalità nelle Knowledge Base per Amazon Bedrock: la regolazione del numero massimo di risultati di ricerca e la personalizzazione del modello di prompt predefinito per RetrieveAndGenerate API. Abbiamo dimostrato come configurare queste funzionalità sulla console e tramite SDK per migliorare le prestazioni e la precisione della risposta generata. L'aumento dei risultati massimi fornisce informazioni più complete, mentre la personalizzazione del modello di richiesta consente di ottimizzare le istruzioni per il modello di base per allinearsi meglio a casi d'uso specifici. Questi miglioramenti offrono maggiore flessibilità e controllo, consentendoti di offrire esperienze su misura per applicazioni basate su RAG.
Per risorse aggiuntive per iniziare l'implementazione nel tuo ambiente AWS, fai riferimento a quanto segue:
Circa gli autori
 Sandeep Singh è un Senior Generative AI Data Scientist presso Amazon Web Services e aiuta le aziende a innovare con l'intelligenza artificiale generativa. È specializzato in intelligenza artificiale generativa, intelligenza artificiale, machine learning e progettazione di sistemi. La sua passione è lo sviluppo di soluzioni all'avanguardia basate su AI/ML per risolvere problemi aziendali complessi per diversi settori, ottimizzando efficienza e scalabilità.
Sandeep Singh è un Senior Generative AI Data Scientist presso Amazon Web Services e aiuta le aziende a innovare con l'intelligenza artificiale generativa. È specializzato in intelligenza artificiale generativa, intelligenza artificiale, machine learning e progettazione di sistemi. La sua passione è lo sviluppo di soluzioni all'avanguardia basate su AI/ML per risolvere problemi aziendali complessi per diversi settori, ottimizzando efficienza e scalabilità.
 Suyin Wang è un AI/ML Specialist Solutions Architect presso AWS. Ha un background formativo interdisciplinare in machine learning, servizi di informazione finanziaria ed economia, oltre ad anni di esperienza nella creazione di applicazioni di data science e machine learning che hanno risolto problemi aziendali reali. Le piace aiutare i clienti a identificare le giuste domande aziendali e a creare le giuste soluzioni AI/ML. Nel tempo libero ama cantare e cucinare.
Suyin Wang è un AI/ML Specialist Solutions Architect presso AWS. Ha un background formativo interdisciplinare in machine learning, servizi di informazione finanziaria ed economia, oltre ad anni di esperienza nella creazione di applicazioni di data science e machine learning che hanno risolto problemi aziendali reali. Le piace aiutare i clienti a identificare le giuste domande aziendali e a creare le giuste soluzioni AI/ML. Nel tempo libero ama cantare e cucinare.
 Sherry Ding è un architetto senior di soluzioni specializzato in intelligenza artificiale (AI) e machine learning (ML) presso Amazon Web Services (AWS). Ha una vasta esperienza nell'apprendimento automatico con un dottorato di ricerca in informatica. Lavora principalmente con clienti del settore pubblico su varie sfide aziendali legate all'intelligenza artificiale/ML, aiutandoli ad accelerare il loro percorso di apprendimento automatico sul cloud AWS. Quando non aiuta i clienti, le piacciono le attività all'aria aperta.
Sherry Ding è un architetto senior di soluzioni specializzato in intelligenza artificiale (AI) e machine learning (ML) presso Amazon Web Services (AWS). Ha una vasta esperienza nell'apprendimento automatico con un dottorato di ricerca in informatica. Lavora principalmente con clienti del settore pubblico su varie sfide aziendali legate all'intelligenza artificiale/ML, aiutandoli ad accelerare il loro percorso di apprendimento automatico sul cloud AWS. Quando non aiuta i clienti, le piacciono le attività all'aria aperta.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-custom-prompts-for-the-retrieveandgenerate-api-and-configuration-of-the-maximum-number-of-retrieved-results/

