Nel suo nucleo, LangChain è un framework innovativo su misura per creare applicazioni che sfruttano le capacità dei modelli linguistici. È un toolkit progettato per consentire agli sviluppatori di creare applicazioni sensibili al contesto e capaci di ragionamenti sofisticati.
Ciò significa che le applicazioni LangChain possono comprendere il contesto, come istruzioni tempestive o risposte di base del contenuto, e utilizzare modelli linguistici per compiti di ragionamento complessi, come decidere come rispondere o quali azioni intraprendere. LangChain rappresenta un approccio unificato allo sviluppo di applicazioni intelligenti, semplificando il percorso dall'ideazione all'esecuzione con i suoi diversi componenti.
Comprendere LangChain
LangChain è molto più di un semplice framework; è un ecosistema a tutti gli effetti che comprende diverse parti integranti.
- Innanzitutto ci sono le librerie LangChain, disponibili sia in Python che in JavaScript. Queste librerie sono la spina dorsale di LangChain, offrendo interfacce e integrazioni per vari componenti. Forniscono un runtime di base per combinare questi componenti in catene e agenti coesi, insieme a implementazioni pronte per l'uso immediato.
- Successivamente, abbiamo i modelli LangChain. Si tratta di una raccolta di architetture di riferimento distribuibili su misura per un'ampia gamma di attività. Che tu stia costruendo un chatbot o uno strumento analitico complesso, questi modelli offrono un solido punto di partenza.
- LangServe interviene come libreria versatile per la distribuzione di catene LangChain come API REST. Questo strumento è essenziale per trasformare i tuoi progetti LangChain in servizi web accessibili e scalabili.
- Infine, LangSmith funge da piattaforma per sviluppatori. È progettato per eseguire il debug, testare, valutare e monitorare le catene costruite su qualsiasi framework LLM. La perfetta integrazione con LangChain lo rende uno strumento indispensabile per gli sviluppatori che desiderano perfezionare e perfezionare le proprie applicazioni.
Insieme, questi componenti ti consentono di sviluppare, produrre e distribuire applicazioni con facilità. Con LangChain, inizi scrivendo le tue applicazioni utilizzando le librerie, facendo riferimento ai modelli come guida. LangSmith ti aiuta quindi a ispezionare, testare e monitorare le tue catene, assicurando che le tue applicazioni siano costantemente migliorate e pronte per la distribuzione. Infine, con LangServe, puoi trasformare facilmente qualsiasi catena in un'API, rendendo la distribuzione un gioco da ragazzi.
Nelle prossime sezioni, approfondiremo come configurare LangChain e iniziare il tuo viaggio nella creazione di applicazioni intelligenti basate su modelli linguistici.
Automatizza le attività manuali e i flussi di lavoro con il nostro generatore di flussi di lavoro basato sull'intelligenza artificiale, progettato da Nanonets per te e i tuoi team.
Installazione e configurazione
Sei pronto a tuffarti nel mondo di LangChain? La configurazione è semplice e questa guida ti guiderà attraverso il processo passo dopo passo.
Il primo passo nel tuo viaggio con LangChain è installarlo. Puoi farlo facilmente usando pip o conda. Esegui il seguente comando nel tuo terminale:
pip install langchain
Per coloro che preferiscono le funzionalità più recenti e si sentono a proprio agio con un po' più di avventura, è possibile installare LangChain direttamente dalla fonte. Clona il repository e vai al file langchain/libs/langchain directory. Quindi, esegui:
pip install -e .
Per le funzionalità sperimentali, valuta l'installazione langchain-experimental. È un pacchetto che contiene codice all'avanguardia ed è destinato a scopi di ricerca e sperimentali. Installalo utilizzando:
pip install langchain-experimental
LangChain CLI è uno strumento utile per lavorare con i modelli LangChain e i progetti LangServe. Per installare la CLI LangChain, utilizzare:
pip install langchain-cli
LangServe è essenziale per distribuire le catene LangChain come API REST. Viene installato insieme alla CLI LangChain.
LangChain richiede spesso integrazioni con fornitori di modelli, archivi dati, API, ecc. Per questo esempio, utilizzeremo le API del modello di OpenAI. Installa il pacchetto OpenAI Python utilizzando:
pip install openai
Per accedere all'API, imposta la chiave API OpenAI come variabile di ambiente:
export OPENAI_API_KEY="your_api_key"
In alternativa, passa la chiave direttamente nel tuo ambiente Python:
import os
os.environ['OPENAI_API_KEY'] = 'your_api_key'
LangChain consente la creazione di applicazioni di modelli linguistici tramite moduli. Questi moduli possono essere autonomi o essere composti per casi d'uso complessi. Questi moduli sono:
- Modello I/O: Facilita l'interazione con vari modelli linguistici, gestendo i loro input e output in modo efficiente.
- Recupero: consente l'accesso e l'interazione con dati specifici dell'applicazione, fondamentali per l'utilizzo dinamico dei dati.
- Agenti: Consentire alle applicazioni di selezionare strumenti appropriati sulla base di direttive di alto livello, migliorando le capacità decisionali.
- Catene: offre composizioni predefinite e riutilizzabili che fungono da elementi costitutivi per lo sviluppo di applicazioni.
- Memorie: mantiene lo stato dell'applicazione attraverso più esecuzioni della catena, essenziale per le interazioni sensibili al contesto.
Ogni modulo risponde a esigenze di sviluppo specifiche, rendendo LangChain un kit di strumenti completo per la creazione di applicazioni di modelli linguistici avanzati.
Insieme ai componenti di cui sopra, abbiamo anche Linguaggio di espressione LangChain (LCEL), che è un modo dichiarativo per comporre facilmente i moduli insieme e ciò consente il concatenamento di componenti utilizzando un'interfaccia Runnable universale.
LCEL assomiglia a questo:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import BaseOutputParser # Example chain
chain = ChatPromptTemplate() | ChatOpenAI() | CustomOutputParser()
Ora che abbiamo trattato le nozioni di base, continueremo a:
- Approfondisci ogni modulo Langchain in dettaglio.
- Scopri come utilizzare LangChain Expression Language.
- Esplora casi d'uso comuni e implementali.
- Distribuisci un'applicazione end-to-end con LangServe.
- Dai un'occhiata a LangSmith per il debug, i test e il monitoraggio.
Cominciamo!
Modulo I: modello I/O
In LangChain, l’elemento centrale di qualsiasi applicazione ruota attorno al modello linguistico. Questo modulo fornisce gli elementi essenziali per interfacciarsi efficacemente con qualsiasi modello linguistico, garantendo integrazione e comunicazione senza soluzione di continuità.
Componenti chiave del modello I/O
- LLM e modelli di chat (usati in modo intercambiabile):
- LLM:
- Definizione: Modelli di completamento del testo puro.
- Input Output: prende una stringa di testo come input e restituisce una stringa di testo come output.
- Modelli di chat
- LLM:
- Definizione: modelli che utilizzano un modello linguistico come base ma differiscono nei formati di input e output.
- Input Output: accetta un elenco di messaggi di chat come input e restituisce un messaggio di chat.
- Prompt: modellizza, seleziona dinamicamente e gestisci gli input del modello. Consente la creazione di prompt flessibili e specifici del contesto che guidano le risposte del modello linguistico.
- Parser di output: estrae e formatta le informazioni dagli output del modello. Utile per convertire l'output grezzo dei modelli linguistici in dati strutturati o formati specifici necessari all'applicazione.
LLM
L'integrazione di LangChain con Large Language Models (LLM) come OpenAI, Cohere e Hugging Face è un aspetto fondamentale della sua funzionalità. LangChain in sé non ospita LLM ma offre un'interfaccia uniforme per interagire con vari LLM.
Questa sezione fornisce una panoramica dell'utilizzo del wrapper OpenAI LLM in LangChain, applicabile anche ad altri tipi di LLM. Lo abbiamo già installato nella sezione "Per iniziare". Inizializziamo il LLM.
from langchain.llms import OpenAI
llm = OpenAI()
- Gli LLM implementano il Interfaccia eseguibile, l'elemento costitutivo di base del Linguaggio di espressione LangChain (LCEL). Ciò significa che supportano
invoke,ainvoke,stream,astream,batch,abatch,astream_logchiamate. - Gli LLM accettano stringhe come input o oggetti che possono essere costretti a richiedere stringhe, inclusi
List[BaseMessage]edPromptValue. (ne parleremo più avanti)
Diamo un'occhiata ad alcuni esempi.
response = llm.invoke("List the seven wonders of the world.")
print(response)

In alternativa puoi chiamare il metodo stream per trasmettere in streaming la risposta testuale.
for chunk in llm.stream("Where were the 2012 Olympics held?"): print(chunk, end="", flush=True)

Modelli di chat
L'integrazione di LangChain con i modelli di chat, una variazione specializzata dei modelli linguistici, è essenziale per creare applicazioni di chat interattive. Sebbene utilizzino modelli linguistici internamente, i modelli di chat presentano un'interfaccia distinta incentrata sui messaggi di chat come input e output. Questa sezione fornisce una panoramica dettagliata dell'utilizzo del modello di chat di OpenAI in LangChain.
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
I modelli di chat in LangChain funzionano con diversi tipi di messaggi come AIMessage, HumanMessage, SystemMessage, FunctionMessagee ChatMessage (con un parametro di ruolo arbitrario). Generalmente, HumanMessage, AIMessagee SystemMessage sono quelli più frequentemente utilizzati.
I modelli di chat accettano principalmente List[BaseMessage] come input. Le stringhe possono essere convertite in HumanMessagee PromptValue è anche supportato.
from langchain.schema.messages import HumanMessage, SystemMessage
messages = [ SystemMessage(content="You are Micheal Jordan."), HumanMessage(content="Which shoe manufacturer are you associated with?"),
]
response = chat.invoke(messages)
print(response.content)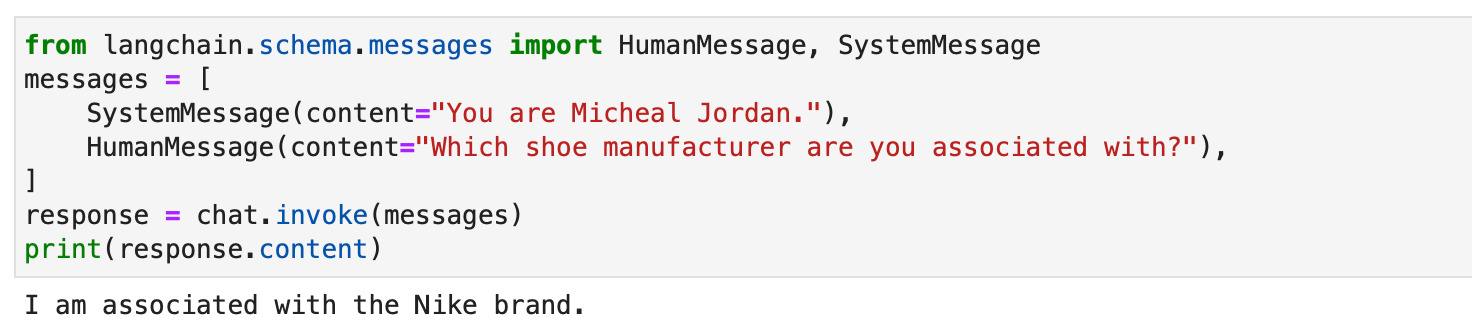
Prompt
I suggerimenti sono essenziali per guidare i modelli linguistici e generare risultati pertinenti e coerenti. Possono variare da semplici istruzioni a complessi esempi di pochi scatti. In LangChain, la gestione dei prompt può essere un processo molto snello, grazie a diverse classi e funzioni dedicate.
di Lang Chain PromptTemplate class è uno strumento versatile per creare prompt di stringhe. Utilizza Python str.format sintassi, consentendo la generazione dinamica di prompt. Puoi definire un modello con segnaposto e riempirli con valori specifici secondo necessità.
from langchain.prompts import PromptTemplate # Simple prompt with placeholders
prompt_template = PromptTemplate.from_template( "Tell me a {adjective} joke about {content}."
) # Filling placeholders to create a prompt
filled_prompt = prompt_template.format(adjective="funny", content="robots")
print(filled_prompt)Per i modelli di chat, le richieste sono più strutturate e coinvolgono messaggi con ruoli specifici. Offerte LangChain ChatPromptTemplate per questo scopo.
from langchain.prompts import ChatPromptTemplate # Defining a chat prompt with various roles
chat_template = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful AI bot. Your name is {name}."), ("human", "Hello, how are you doing?"), ("ai", "I'm doing well, thanks!"), ("human", "{user_input}"), ]
) # Formatting the chat prompt
formatted_messages = chat_template.format_messages(name="Bob", user_input="What is your name?")
for message in formatted_messages: print(message)
Questo approccio consente la creazione di chatbot interattivi e coinvolgenti con risposte dinamiche.
Entrambi PromptTemplate ed ChatPromptTemplate si integrano perfettamente con LangChain Expression Language (LCEL), consentendo loro di far parte di flussi di lavoro più ampi e complessi. Ne discuteremo più approfonditamente in seguito.
I modelli di prompt personalizzati sono talvolta essenziali per attività che richiedono una formattazione univoca o istruzioni specifiche. La creazione di un modello di prompt personalizzato implica la definizione di variabili di input e un metodo di formattazione personalizzato. Questa flessibilità consente a LangChain di soddisfare un'ampia gamma di requisiti specifici dell'applicazione. Per saperne di più qui.
LangChain supporta anche la richiesta di pochi scatti, consentendo al modello di apprendere dagli esempi. Questa funzionalità è vitale per le attività che richiedono comprensione contestuale o modelli specifici. È possibile creare modelli di prompt con poche operazioni da una serie di esempi o utilizzando un oggetto Selettore di esempio. Per saperne di più qui.
Parser di output
I parser di output svolgono un ruolo cruciale in Langchain, consentendo agli utenti di strutturare le risposte generate dai modelli linguistici. In questa sezione esploreremo il concetto di parser di output e forniremo esempi di codice utilizzando PydanticOutputParser, SimpleJsonOutputParser, CommaSeparatedListOutputParser, DatetimeOutputParser e XMLOutputParser di Langchain.
PydanticOutputParser
Langchain fornisce PydanticOutputParser per l'analisi delle risposte nelle strutture dati Pydantic. Di seguito è riportato un esempio passo passo di come utilizzarlo:
from typing import List
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain.pydantic_v1 import BaseModel, Field, validator # Initialize the language model
model = OpenAI(model_name="text-davinci-003", temperature=0.0) # Define your desired data structure using Pydantic
class Joke(BaseModel): setup: str = Field(description="question to set up a joke") punchline: str = Field(description="answer to resolve the joke") @validator("setup") def question_ends_with_question_mark(cls, field): if field[-1] != "?": raise ValueError("Badly formed question!") return field # Set up a PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Joke) # Create a prompt with format instructions
prompt = PromptTemplate( template="Answer the user query.n{format_instructions}n{query}n", input_variables=["query"], partial_variables={"format_instructions": parser.get_format_instructions()},
) # Define a query to prompt the language model
query = "Tell me a joke." # Combine prompt, model, and parser to get structured output
prompt_and_model = prompt | model
output = prompt_and_model.invoke({"query": query}) # Parse the output using the parser
parsed_result = parser.invoke(output) # The result is a structured object
print(parsed_result)
L'output sarà:

SimpleJsonOutputParser
SimpleJsonOutputParser di Langchain viene utilizzato quando si desidera analizzare output simili a JSON. Ecco un esempio:
from langchain.output_parsers.json import SimpleJsonOutputParser # Create a JSON prompt
json_prompt = PromptTemplate.from_template( "Return a JSON object with `birthdate` and `birthplace` key that answers the following question: {question}"
) # Initialize the JSON parser
json_parser = SimpleJsonOutputParser() # Create a chain with the prompt, model, and parser
json_chain = json_prompt | model | json_parser # Stream through the results
result_list = list(json_chain.stream({"question": "When and where was Elon Musk born?"})) # The result is a list of JSON-like dictionaries
print(result_list)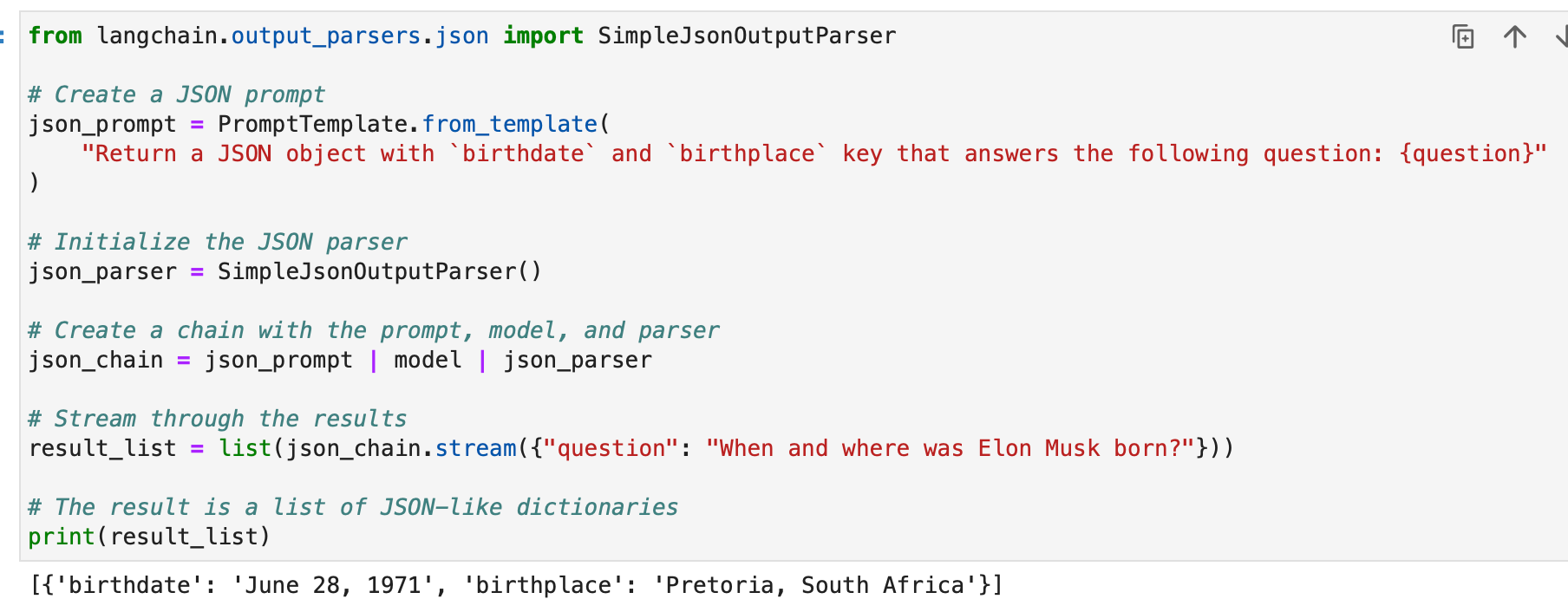
CommaSeparatedListOutputParser
CommaSeparatedListOutputParser è utile quando si desidera estrarre elenchi separati da virgole dalle risposte del modello. Ecco un esempio:
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI # Initialize the parser
output_parser = CommaSeparatedListOutputParser() # Create format instructions
format_instructions = output_parser.get_format_instructions() # Create a prompt to request a list
prompt = PromptTemplate( template="List five {subject}.n{format_instructions}", input_variables=["subject"], partial_variables={"format_instructions": format_instructions}
) # Define a query to prompt the model
query = "English Premier League Teams" # Generate the output
output = model(prompt.format(subject=query)) # Parse the output using the parser
parsed_result = output_parser.parse(output) # The result is a list of items
print(parsed_result)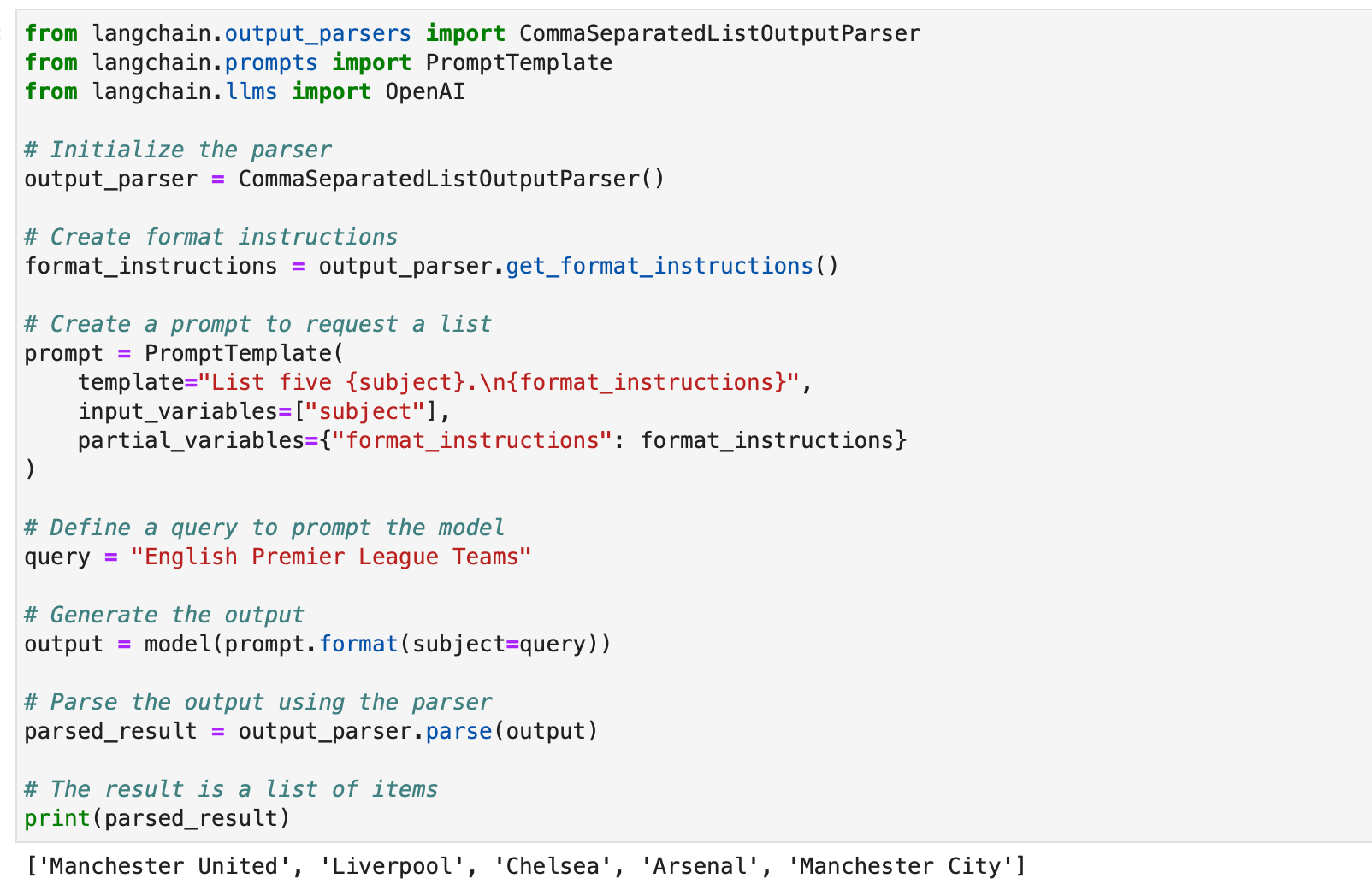
DatetimeOutputParser
DatetimeOutputParser di Langchain è progettato per analizzare le informazioni di data e ora. Ecco come usarlo:
from langchain.prompts import PromptTemplate
from langchain.output_parsers import DatetimeOutputParser
from langchain.chains import LLMChain
from langchain.llms import OpenAI # Initialize the DatetimeOutputParser
output_parser = DatetimeOutputParser() # Create a prompt with format instructions
template = """
Answer the user's question:
{question}
{format_instructions} """ prompt = PromptTemplate.from_template( template, partial_variables={"format_instructions": output_parser.get_format_instructions()},
) # Create a chain with the prompt and language model
chain = LLMChain(prompt=prompt, llm=OpenAI()) # Define a query to prompt the model
query = "when did Neil Armstrong land on the moon in terms of GMT?" # Run the chain
output = chain.run(query) # Parse the output using the datetime parser
parsed_result = output_parser.parse(output) # The result is a datetime object
print(parsed_result)
Questi esempi mostrano come i parser di output di Langchain possono essere utilizzati per strutturare vari tipi di risposte del modello, rendendoli adatti a diverse applicazioni e formati. I parser di output sono uno strumento prezioso per migliorare l'usabilità e l'interpretabilità degli output del modello linguistico in Langchain.
Automatizza le attività manuali e i flussi di lavoro con il nostro generatore di flussi di lavoro basato sull'intelligenza artificiale, progettato da Nanonets per te e i tuoi team.
Modulo II: Recupero
Il recupero in LangChain gioca un ruolo cruciale nelle applicazioni che richiedono dati specifici dell'utente, non inclusi nel set di training del modello. Questo processo, noto come Retrieval Augmented Generation (RAG), prevede il recupero di dati esterni e la loro integrazione nel processo di generazione del modello linguistico. LangChain fornisce una suite completa di strumenti e funzionalità per facilitare questo processo, soddisfacendo sia applicazioni semplici che complesse.
LangChain ottiene il recupero attraverso una serie di componenti di cui parleremo uno per uno.
Caricatori di documenti
I caricatori di documenti in LangChain consentono l'estrazione di dati da varie fonti. Con oltre 100 caricatori disponibili, supportano una vasta gamma di tipi di documenti, app e origini (bucket s3 privati, siti Web pubblici, database).
Puoi scegliere un caricatore di documenti in base alle tue esigenze qui.
Tutti questi caricatori inseriscono i dati in funzionalità di classi. Impareremo come utilizzare i dati inseriti nelle classi Document in seguito.
Caricatore file di testo: Carica un semplice .txt archiviare in un documento.
from langchain.document_loaders import TextLoader loader = TextLoader("./sample.txt")
document = loader.load()
Caricatore CSV: Carica un file CSV in un documento.
from langchain.document_loaders.csv_loader import CSVLoader loader = CSVLoader(file_path='./example_data/sample.csv')
documents = loader.load()
Possiamo scegliere di personalizzare l'analisi specificando i nomi dei campi –
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', csv_args={ 'delimiter': ',', 'quotechar': '"', 'fieldnames': ['MLB Team', 'Payroll in millions', 'Wins']
})
documents = loader.load()
Caricatori PDF: I caricatori PDF in LangChain offrono vari metodi per analizzare ed estrarre contenuto dai file PDF. Ogni caricatore soddisfa requisiti diversi e utilizza librerie sottostanti diverse. Di seguito sono riportati esempi dettagliati per ciascun caricatore.
PyPDFLoader viene utilizzato per l'analisi PDF di base.
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
MathPixLoader è ideale per estrarre contenuti e diagrammi matematici.
from langchain.document_loaders import MathpixPDFLoader loader = MathpixPDFLoader("example_data/math-content.pdf")
data = loader.load()
PyMuPDFLoader è veloce e include l'estrazione dettagliata dei metadati.
from langchain.document_loaders import PyMuPDFLoader loader = PyMuPDFLoader("example_data/layout-parser-paper.pdf")
data = loader.load() # Optionally pass additional arguments for PyMuPDF's get_text() call
data = loader.load(option="text")
PDFMiner Loader viene utilizzato per un controllo più granulare sull'estrazione del testo.
from langchain.document_loaders import PDFMinerLoader loader = PDFMinerLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
AmazonTextractPDFParser utilizza AWS Textract per l'OCR e altre funzionalità avanzate di analisi dei PDF.
from langchain.document_loaders import AmazonTextractPDFLoader # Requires AWS account and configuration
loader = AmazonTextractPDFLoader("example_data/complex-layout.pdf")
documents = loader.load()
PDFMinerPDFasHTMLLoader genera HTML da PDF per l'analisi semantica.
from langchain.document_loaders import PDFMinerPDFasHTMLLoader loader = PDFMinerPDFasHTMLLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
PDFPlumberLoader fornisce metadati dettagliati e supporta un documento per pagina.
from langchain.document_loaders import PDFPlumberLoader loader = PDFPlumberLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
Caricatori integrati: LangChain offre un'ampia varietà di caricatori personalizzati per caricare direttamente i dati dalle tue app (come Slack, Sigma, Notion, Confluence, Google Drive e molti altri) e database e utilizzarli nelle applicazioni LLM.
L'elenco completo è qui.
Di seguito sono riportati un paio di esempi per illustrare questo:
Esempio I – Allentamento
Slack, una piattaforma di messaggistica istantanea ampiamente utilizzata, può essere integrata nei flussi di lavoro e nelle applicazioni LLM.
- Vai alla pagina di gestione dell'area di lavoro Slack.
- Spostarsi
{your_slack_domain}.slack.com/services/export. - Seleziona l'intervallo di date desiderato e avvia l'esportazione.
- Slack avvisa via email e DM una volta che l'esportazione è pronta.
- L'esportazione risulta in a
.zipfile situato nella cartella Download o nel percorso di download designato. - Assegnare il percorso del download
.zipfile perLOCAL_ZIPFILE. - Usa il
SlackDirectoryLoaderdallangchain.document_loaderspacchetto.
from langchain.document_loaders import SlackDirectoryLoader SLACK_WORKSPACE_URL = "https://xxx.slack.com" # Replace with your Slack URL
LOCAL_ZIPFILE = "" # Path to the Slack zip file loader = SlackDirectoryLoader(LOCAL_ZIPFILE, SLACK_WORKSPACE_URL)
docs = loader.load()
print(docs)
Esempio II – Figma
Figma, uno strumento popolare per la progettazione dell'interfaccia, offre un'API REST per l'integrazione dei dati.
- Ottieni la chiave del file Figma dal formato URL:
https://www.figma.com/file/{filekey}/sampleFilename. - Gli ID nodo si trovano nel parametro URL
?node-id={node_id}. - Genera un token di accesso seguendo le istruzioni nella Centro assistenza Figma.
- I
FigmaFileLoaderclasse dalangchain.document_loaders.figmaviene utilizzato per caricare i dati Figma. - Vari moduli LangChain come
CharacterTextSplitter,ChatOpenAI, ecc., vengono utilizzati per l'elaborazione.
import os
from langchain.document_loaders.figma import FigmaFileLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import ConversationChain, LLMChain
from langchain.memory import ConversationBufferWindowMemory
from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate, AIMessagePromptTemplate, HumanMessagePromptTemplate figma_loader = FigmaFileLoader( os.environ.get("ACCESS_TOKEN"), os.environ.get("NODE_IDS"), os.environ.get("FILE_KEY"),
) index = VectorstoreIndexCreator().from_loaders([figma_loader])
figma_doc_retriever = index.vectorstore.as_retriever()
- I
generate_codela funzione utilizza i dati Figma per creare codice HTML/CSS. - Utilizza una conversazione basata su modelli con un modello basato su GPT.
def generate_code(human_input): # Template for system and human prompts system_prompt_template = "Your coding instructions..." human_prompt_template = "Code the {text}. Ensure it's mobile responsive" # Creating prompt templates system_message_prompt = SystemMessagePromptTemplate.from_template(system_prompt_template) human_message_prompt = HumanMessagePromptTemplate.from_template(human_prompt_template) # Setting up the AI model gpt_4 = ChatOpenAI(temperature=0.02, model_name="gpt-4") # Retrieving relevant documents relevant_nodes = figma_doc_retriever.get_relevant_documents(human_input) # Generating and formatting the prompt conversation = [system_message_prompt, human_message_prompt] chat_prompt = ChatPromptTemplate.from_messages(conversation) response = gpt_4(chat_prompt.format_prompt(context=relevant_nodes, text=human_input).to_messages()) return response # Example usage
response = generate_code("page top header")
print(response.content)
- I
generate_codela funzione, quando eseguita, restituisce codice HTML/CSS basato sull'input di progettazione Figma.
Usiamo ora le nostre conoscenze per creare alcuni set di documenti.
Per prima cosa carichiamo un PDF, il rapporto annuale di sostenibilità di BCG.

Usiamo PyPDFLoader per questo.
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("bcg-2022-annual-sustainability-report-apr-2023.pdf")
pdfpages = loader.load_and_split()
Ora inseriremo i dati da Airtable. Abbiamo un Airtable contenente informazioni su vari modelli OCR e di estrazione dei dati –
Usiamo a questo scopo l'AirtableLoader, che si trova nell'elenco dei caricatori integrati.
from langchain.document_loaders import AirtableLoader api_key = "XXXXX"
base_id = "XXXXX"
table_id = "XXXXX" loader = AirtableLoader(api_key, table_id, base_id)
airtabledocs = loader.load()
Procediamo ora e impariamo come utilizzare queste classi di documenti.
Trasformatori di documenti
I trasformatori di documenti in LangChain sono strumenti essenziali progettati per manipolare i documenti, che abbiamo creato nella nostra sottosezione precedente.
Vengono utilizzati per attività come la suddivisione di documenti lunghi in blocchi più piccoli, la combinazione e il filtraggio, che sono cruciali per adattare i documenti alla finestra di contesto di un modello o per soddisfare esigenze applicative specifiche.
Uno di questi strumenti è RecursiveCharacterTextSplitter, un versatile divisore di testo che utilizza un elenco di caratteri per la divisione. Consente parametri come dimensione del blocco, sovrapposizione e indice iniziale. Ecco un esempio di come viene utilizzato in Python:
from langchain.text_splitter import RecursiveCharacterTextSplitter state_of_the_union = "Your long text here..." text_splitter = RecursiveCharacterTextSplitter( chunk_size=100, chunk_overlap=20, length_function=len, add_start_index=True,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
Un altro strumento è CharacterTextSplitter, che divide il testo in base a un carattere specificato e include controlli per la dimensione dei blocchi e la sovrapposizione:
from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter( separator="nn", chunk_size=1000, chunk_overlap=200, length_function=len, is_separator_regex=False,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
HTMLHeaderTextSplitter è progettato per dividere il contenuto HTML in base ai tag di intestazione, mantenendo la struttura semantica:
from langchain.text_splitter import HTMLHeaderTextSplitter html_string = "Your HTML content here..."
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")] html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
print(html_header_splits[0])
Una manipolazione più complessa può essere ottenuta combinando HTMLHeaderTextSplitter con un altro splitter, come Pipelined Splitter:
from langchain.text_splitter import HTMLHeaderTextSplitter, RecursiveCharacterTextSplitter url = "https://example.com"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url) chunk_size = 500
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size)
splits = text_splitter.split_documents(html_header_splits)
print(splits[0])
LangChain offre anche splitter specifici per diversi linguaggi di programmazione, come Python Code Splitter e JavaScript Code Splitter:
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language python_code = """
def hello_world(): print("Hello, World!")
hello_world() """ python_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.PYTHON, chunk_size=50
)
python_docs = python_splitter.create_documents([python_code])
print(python_docs[0]) js_code = """
function helloWorld() { console.log("Hello, World!");
}
helloWorld(); """ js_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.JS, chunk_size=60
)
js_docs = js_splitter.create_documents([js_code])
print(js_docs[0])
Per dividere il testo in base al conteggio dei token, utile per i modelli linguistici con limiti di token, viene utilizzato TokenTextSplitter:
from langchain.text_splitter import TokenTextSplitter text_splitter = TokenTextSplitter(chunk_size=10)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
Infine, LongContextReorder riordina i documenti per prevenire il degrado delle prestazioni nei modelli a causa di contesti lunghi:
from langchain.document_transformers import LongContextReorder reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
print(reordered_docs[0])
Questi strumenti dimostrano vari modi per trasformare i documenti in LangChain, dalla semplice suddivisione del testo al riordino complesso e alla suddivisione specifica della lingua. Per casi d'uso più approfonditi e specifici si consiglia di consultare la sezione Documentazione e Integrazioni di LangChain.
Nei nostri esempi, i caricatori hanno già creato per noi documenti in blocchi e questa parte è già gestita.
Modelli di incorporamento del testo
I modelli di incorporamento del testo in LangChain forniscono un'interfaccia standardizzata per vari fornitori di modelli di incorporamento come OpenAI, Cohere e Hugging Face. Questi modelli trasformano il testo in rappresentazioni vettoriali, consentendo operazioni come la ricerca semantica attraverso la somiglianza del testo nello spazio vettoriale.
Per iniziare con i modelli di incorporamento del testo, in genere è necessario installare pacchetti specifici e configurare le chiavi API. Lo abbiamo già fatto per OpenAI
In LangChain, il embed_documents Il metodo viene utilizzato per incorporare più testi, fornendo un elenco di rappresentazioni vettoriali. Ad esempio:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a list of texts
embeddings = embeddings_model.embed_documents( ["Hi there!", "Oh, hello!", "What's your name?", "My friends call me World", "Hello World!"]
)
print("Number of documents embedded:", len(embeddings))
print("Dimension of each embedding:", len(embeddings[0]))
Per incorporare un singolo testo, come una query di ricerca, il file embed_query viene utilizzato il metodo. Ciò è utile per confrontare una query con un insieme di incorporamenti di documenti. Per esempio:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a single query
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")
print("First five dimensions of the embedded query:", embedded_query[:5])
Comprendere questi incorporamenti è cruciale. Ogni porzione di testo viene convertita in un vettore, la cui dimensione dipende dal modello utilizzato. Ad esempio, i modelli OpenAI producono tipicamente vettori a 1536 dimensioni. Questi incorporamenti vengono quindi utilizzati per recuperare informazioni rilevanti.
La funzionalità di incorporamento di LangChain non è limitata a OpenAI ma è progettata per funzionare con vari fornitori. La configurazione e l'utilizzo potrebbero differire leggermente a seconda del provider, ma il concetto fondamentale di incorporare testi nello spazio vettoriale rimane lo stesso. Per un utilizzo dettagliato, comprese configurazioni avanzate e integrazioni con diversi fornitori di modelli di incorporamento, la documentazione LangChain nella sezione Integrazioni è una risorsa preziosa.
Negozi di vettore
Gli archivi vettoriali in LangChain supportano l'archiviazione e la ricerca efficienti degli incorporamenti di testo. LangChain si integra con oltre 50 negozi vettoriali, fornendo un'interfaccia standardizzata per facilità d'uso.
Esempio: memorizzazione e ricerca di incorporamenti
Dopo aver incorporato i testi, possiamo memorizzarli in un archivio vettoriale come Chroma ed eseguire ricerche di somiglianza:
from langchain.vectorstores import Chroma db = Chroma.from_texts(embedded_texts)
similar_texts = db.similarity_search("search query")
In alternativa utilizziamo l'archivio vettoriale FAISS per creare indici per i nostri documenti.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS pdfstore = FAISS.from_documents(pdfpages, embedding=OpenAIEmbeddings()) airtablestore = FAISS.from_documents(airtabledocs, embedding=OpenAIEmbeddings())

Retriever
I recuperatori in LangChain sono interfacce che restituiscono documenti in risposta a una query non strutturata. Sono più generali degli archivi vettoriali e si concentrano sul recupero piuttosto che sull'archiviazione. Sebbene gli archivi vettoriali possano essere utilizzati come spina dorsale di un retriever, esistono anche altri tipi di retriever.
Per configurare un Chroma Retriever, devi prima installarlo utilizzando pip install chromadb. Quindi, carichi, dividi, incorpori e recuperi i documenti utilizzando una serie di comandi Python. Ecco un esempio di codice per impostare un Chroma Retriever:
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma full_text = open("state_of_the_union.txt", "r").read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
texts = text_splitter.split_text(full_text) embeddings = OpenAIEmbeddings()
db = Chroma.from_texts(texts, embeddings)
retriever = db.as_retriever() retrieved_docs = retriever.invoke("What did the president say about Ketanji Brown Jackson?")
print(retrieved_docs[0].page_content)
MultiQueryRetriever automatizza l'ottimizzazione dei prompt generando più query per una query di input dell'utente e combina i risultati. Ecco un esempio del suo semplice utilizzo:
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever question = "What are the approaches to Task Decomposition?"
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm( retriever=db.as_retriever(), llm=llm
) unique_docs = retriever_from_llm.get_relevant_documents(query=question)
print("Number of unique documents:", len(unique_docs))
La compressione contestuale in LangChain comprime i documenti recuperati utilizzando il contesto della query, garantendo che vengano restituite solo le informazioni rilevanti. Ciò comporta la riduzione dei contenuti e il filtraggio dei documenti meno rilevanti. L'esempio di codice seguente mostra come utilizzare Contextual Compression Retriever:
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever) compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown")
print(compressed_docs[0].page_content)
EnsembleRetriever combina diversi algoritmi di recupero per ottenere prestazioni migliori. Un esempio di combinazione di BM25 e FAIISS Retriever è mostrato nel seguente codice:
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import FAISS bm25_retriever = BM25Retriever.from_texts(doc_list).set_k(2)
faiss_vectorstore = FAISS.from_texts(doc_list, OpenAIEmbeddings())
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2}) ensemble_retriever = EnsembleRetriever( retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
) docs = ensemble_retriever.get_relevant_documents("apples")
print(docs[0].page_content)
MultiVector Retriever in LangChain consente di interrogare documenti con più vettori per documento, il che è utile per acquisire diversi aspetti semantici all'interno di un documento. I metodi per creare più vettori includono la suddivisione in parti più piccole, il riepilogo o la generazione di domande ipotetiche. Per dividere i documenti in pezzi più piccoli, è possibile utilizzare il seguente codice Python:
python
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.storage import InMemoryStore
from langchain.document_loaders from TextLoader
import uuid loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000)
docs = text_splitter.split_documents(docs) vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(vectorstore=vectorstore, docstore=store, id_key=id_key) doc_ids = [str(uuid.uuid4()) for _ in docs]
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
sub_docs = [sub_doc for doc in docs for sub_doc in child_text_splitter.split_documents([doc])]
for sub_doc in sub_docs: sub_doc.metadata[id_key] = doc_ids[sub_docs.index(sub_doc)] retriever.vectorstore.add_documents(sub_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Un altro metodo è generare riepiloghi per un migliore recupero grazie a una rappresentazione del contenuto più mirata. Ecco un esempio di generazione di riepiloghi:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.document import Document chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Summarize the following document:nn{doc}") | ChatOpenAI(max_retries=0) | StrOutputParser()
summaries = chain.batch(docs, {"max_concurrency": 5}) summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(summaries)]
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Generare domande ipotetiche rilevanti per ciascun documento utilizzando LLM è un altro approccio. Questo può essere fatto con il seguente codice:
functions = [{"name": "hypothetical_questions", "parameters": {"questions": {"type": "array", "items": {"type": "string"}}}}]
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Generate 3 hypothetical questions:nn{doc}") | ChatOpenAI(max_retries=0).bind(functions=functions, function_call={"name": "hypothetical_questions"}) | JsonKeyOutputFunctionsParser(key_name="questions")
hypothetical_questions = chain.batch(docs, {"max_concurrency": 5}) question_docs = [Document(page_content=q, metadata={id_key: doc_ids[i]}) for i, questions in enumerate(hypothetical_questions) for q in questions]
retriever.vectorstore.add_documents(question_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Il Parent Document Retriever è un altro retriever che trova un equilibrio tra l'accuratezza dell'incorporamento e la conservazione del contesto memorizzando piccole porzioni e recuperando i documenti principali più grandi. La sua implementazione è la seguente:
from langchain.retrievers import ParentDocumentRetriever loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()] child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
retriever = ParentDocumentRetriever(vectorstore=vectorstore, docstore=store, child_splitter=child_splitter) retriever.add_documents(docs, ids=None) retrieved_docs = retriever.get_relevant_documents("query")
Un retriever auto-interrogante costruisce query strutturate da input in linguaggio naturale e le applica al VectorStore sottostante. La sua implementazione è mostrata nel seguente codice:
from langchain.chat_models from ChatOpenAI
from langchain.chains.query_constructor.base from AttributeInfo
from langchain.retrievers.self_query.base from SelfQueryRetriever metadata_field_info = [AttributeInfo(name="genre", description="...", type="string"), ...]
document_content_description = "Brief summary of a movie"
llm = ChatOpenAI(temperature=0) retriever = SelfQueryRetriever.from_llm(llm, vectorstore, document_content_description, metadata_field_info) retrieved_docs = retriever.invoke("query")
WebResearchRetriever esegue ricerche web in base a una determinata query:
from langchain.retrievers.web_research import WebResearchRetriever # Initialize components
llm = ChatOpenAI(temperature=0)
search = GoogleSearchAPIWrapper()
vectorstore = Chroma(embedding_function=OpenAIEmbeddings()) # Instantiate WebResearchRetriever
web_research_retriever = WebResearchRetriever.from_llm(vectorstore=vectorstore, llm=llm, search=search) # Retrieve documents
docs = web_research_retriever.get_relevant_documents("query")
Per i nostri esempi, possiamo anche utilizzare il retriever standard già implementato come parte del nostro oggetto archivio vettoriale come segue:

Ora possiamo interrogare i retriever. L'output della nostra query saranno oggetti documento rilevanti per la query. Questi verranno infine utilizzati per creare risposte pertinenti nelle sezioni successive.


Automatizza le attività manuali e i flussi di lavoro con il nostro generatore di flussi di lavoro basato sull'intelligenza artificiale, progettato da Nanonets per te e i tuoi team.
Modulo III: Agenti
LangChain introduce un potente concetto chiamato "Agenti" che porta l'idea di catene a un livello completamente nuovo. Gli agenti sfruttano i modelli linguistici per determinare dinamicamente le sequenze di azioni da eseguire, rendendoli incredibilmente versatili e adattivi. A differenza delle catene tradizionali, in cui le azioni sono codificate nel codice, gli agenti utilizzano modelli linguistici come motori di ragionamento per decidere quali azioni intraprendere e in quale ordine.
L'agente è la componente principale responsabile del processo decisionale. Sfrutta la potenza di un modello linguistico e un suggerimento per determinare i passaggi successivi per raggiungere un obiettivo specifico. Gli input per un agente in genere includono:
- Strumenti: Descrizioni degli strumenti disponibili (ne parleremo più avanti).
- Input dell'utente: L'obiettivo di alto livello o la query dell'utente.
- Passaggi intermedi: Una cronologia di coppie (azione, output dello strumento) eseguite per raggiungere l'input dell'utente corrente.
L'output di un agente può essere il successivo azione intraprendere azioni (Azioni dell'agente) o la finale risposta da inviare all'utente (AgenteFinish). Un azione specifica a e la ingresso per quello strumento.
Strumenti
Gli strumenti sono interfacce che un agente può utilizzare per interagire con il mondo. Consentono agli agenti di eseguire varie attività, come la ricerca sul Web, l'esecuzione di comandi della shell o l'accesso ad API esterne. In LangChain, gli strumenti sono essenziali per estendere le capacità degli agenti e consentire loro di svolgere diversi compiti.
Per utilizzare gli strumenti in LangChain, puoi caricarli utilizzando il seguente snippet:
from langchain.agents import load_tools tool_names = [...]
tools = load_tools(tool_names)
Alcuni strumenti potrebbero richiedere l'inizializzazione di un modello linguistico di base (LLM). In questi casi, puoi anche superare un LLM:
from langchain.agents import load_tools tool_names = [...]
llm = ...
tools = load_tools(tool_names, llm=llm)
Questa configurazione ti consente di accedere a una varietà di strumenti e di integrarli nei flussi di lavoro del tuo agente. L'elenco completo degli strumenti con la documentazione sull'utilizzo è qui.
Vediamo alcuni esempi di Strumenti.
DuckDuckGo
Lo strumento DuckDuckGo ti consente di eseguire ricerche sul web utilizzando il suo motore di ricerca. Ecco come usarlo:
from langchain.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
search.run("manchester united vs luton town match summary")

DataForSeo
Il toolkit DataForSeo ti consente di ottenere risultati dai motori di ricerca utilizzando l'API DataForSeo. Per utilizzare questo toolkit, dovrai impostare le tue credenziali API. Ecco come configurare le credenziali:
import os os.environ["DATAFORSEO_LOGIN"] = "<your_api_access_username>"
os.environ["DATAFORSEO_PASSWORD"] = "<your_api_access_password>"
Una volta impostate le credenziali, puoi creare un file DataForSeoAPIWrapper strumento per accedere all'API:
from langchain.utilities.dataforseo_api_search import DataForSeoAPIWrapper wrapper = DataForSeoAPIWrapper() result = wrapper.run("Weather in Los Angeles")
I DataForSeoAPIWrapper lo strumento recupera i risultati dei motori di ricerca da varie fonti.
Puoi personalizzare il tipo di risultati e di campi restituiti nella risposta JSON. Ad esempio, puoi specificare i tipi di risultati, i campi e impostare un conteggio massimo per il numero di risultati principali da restituire:
json_wrapper = DataForSeoAPIWrapper( json_result_types=["organic", "knowledge_graph", "answer_box"], json_result_fields=["type", "title", "description", "text"], top_count=3,
) json_result = json_wrapper.results("Bill Gates")
Questo esempio personalizza la risposta JSON specificando tipi di risultati, campi e limitando il numero di risultati.
Puoi anche specificare la posizione e la lingua per i risultati della ricerca passando parametri aggiuntivi al wrapper API:
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en"},
) customized_result = customized_wrapper.results("coffee near me")
Fornendo parametri di località e lingua, puoi personalizzare i risultati della ricerca per regioni e lingue specifiche.
Hai la flessibilità di scegliere il motore di ricerca che desideri utilizzare. Basta specificare il motore di ricerca desiderato:
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en", "se_name": "bing"},
) customized_result = customized_wrapper.results("coffee near me")
In questo esempio, la ricerca è personalizzata per utilizzare Bing come motore di ricerca.
Il wrapper API ti consente inoltre di specificare il tipo di ricerca che desideri eseguire. Ad esempio, puoi eseguire una ricerca sulle mappe:
maps_search = DataForSeoAPIWrapper( top_count=10, json_result_fields=["title", "value", "address", "rating", "type"], params={ "location_coordinate": "52.512,13.36,12z", "language_code": "en", "se_type": "maps", },
) maps_search_result = maps_search.results("coffee near me")
Ciò personalizza la ricerca per recuperare informazioni relative alle mappe.
Conchiglia (bash)
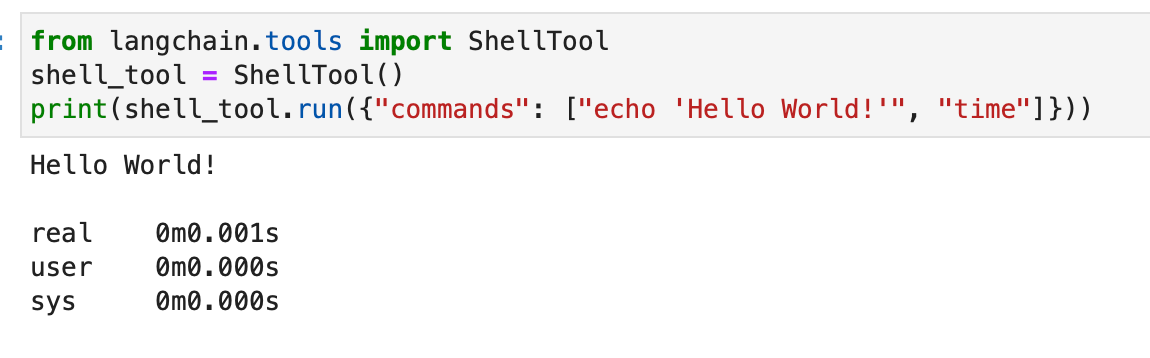
Il toolkit Shell fornisce agli agenti l'accesso all'ambiente shell, consentendo loro di eseguire comandi shell. Questa funzionalità è potente ma deve essere utilizzata con cautela, soprattutto in ambienti sandbox. Ecco come utilizzare lo strumento Shell:
from langchain.tools import ShellTool shell_tool = ShellTool() result = shell_tool.run({"commands": ["echo 'Hello World!'", "time"]})
In questo esempio, lo strumento Shell esegue due comandi shell: echo "Hello World!" e visualizzare l'ora corrente.
È possibile fornire lo strumento Shell a un agente per eseguire attività più complesse. Ecco un esempio di un agente che recupera collegamenti da una pagina Web utilizzando lo strumento Shell:
from langchain.agents import AgentType, initialize_agent
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0.1) shell_tool.description = shell_tool.description + f"args {shell_tool.args}".replace( "{", "{{"
).replace("}", "}}")
self_ask_with_search = initialize_agent( [shell_tool], llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
self_ask_with_search.run( "Download the langchain.com webpage and grep for all urls. Return only a sorted list of them. Be sure to use double quotes."
)
In questo scenario, l'agente utilizza lo strumento Shell per eseguire una sequenza di comandi per recuperare, filtrare e ordinare gli URL da una pagina Web.
Gli esempi forniti dimostrano alcuni degli strumenti disponibili in LangChain. Questi strumenti estendono in definitiva le capacità degli agenti (esplorate nella sottosezione successiva) e consentono loro di eseguire varie attività in modo efficiente. A seconda delle tue esigenze, puoi scegliere gli strumenti e i toolkit che meglio si adattano alle esigenze del tuo progetto e integrarli nei flussi di lavoro del tuo agente.
Torniamo agli agenti
Passiamo ora agli agenti.
AgentExecutor è l'ambiente di runtime per un agente. È responsabile di chiamare l'agente, eseguire le azioni selezionate, restituire gli output dell'azione all'agente e ripetere il processo finché l'agente non termina. Nello pseudocodice, AgentExecutor potrebbe assomigliare a questo:
next_action = agent.get_action(...)
while next_action != AgentFinish: observation = run(next_action) next_action = agent.get_action(..., next_action, observation)
return next_action
AgentExecutor gestisce varie complessità, come la gestione dei casi in cui l'agente seleziona uno strumento inesistente, la gestione degli errori dello strumento, la gestione degli output prodotti dall'agente e la fornitura di registrazione e osservabilità a tutti i livelli.
Sebbene la classe AgentExecutor sia il runtime dell'agente principale in LangChain, sono supportati altri runtime più sperimentali, tra cui:
- Agente di pianificazione ed esecuzione
- Bambino AGI
- GPT automatico
Per comprendere meglio la struttura dell'agente, creiamo da zero un agente di base, quindi passiamo all'esplorazione degli agenti precostruiti.
Prima di immergerci nella creazione dell'agente, è essenziale rivisitare alcuni schemi e terminologia chiave:
- Azione agente: Questa è una classe di dati che rappresenta l'azione che un agente dovrebbe intraprendere. È composto da a
toolproprietà (il nome dello strumento da richiamare) e atool_inputproprietà (l'input per quello strumento). - Fine agente: Questa classe di dati indica che l'agente ha terminato la sua attività e dovrebbe restituire una risposta all'utente. In genere include un dizionario di valori restituiti, spesso con una chiave "output" contenente il testo della risposta.
- Passaggi intermedi: Questi sono i record delle azioni precedenti dell'agente e degli output corrispondenti. Sono cruciali per passare il contesto alle future iterazioni dell'agente.
Nel nostro esempio, utilizzeremo OpenAI Function Calling per creare il nostro agente. Questo approccio è affidabile per la creazione dell'agente. Inizieremo creando un semplice strumento che calcola la lunghezza di una parola. Questo strumento è utile perché i modelli linguistici a volte possono commettere errori a causa della tokenizzazione quando si contano le lunghezze delle parole.
Per prima cosa carichiamo il modello linguistico che utilizzeremo per controllare l'agente:
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
Testiamo il modello con un calcolo della lunghezza delle parole:
llm.invoke("how many letters in the word educa?")
La risposta dovrebbe indicare il numero di lettere della parola “educa”.
Successivamente, definiremo una semplice funzione Python per calcolare la lunghezza di una parola:
from langchain.agents import tool @tool
def get_word_length(word: str) -> int: """Returns the length of a word.""" return len(word)
Abbiamo creato uno strumento denominato get_word_length che prende una parola come input e ne restituisce la lunghezza.
Ora creiamo il prompt per l'agente. Il prompt indica all'agente come ragionare e formattare l'output. Nel nostro caso, utilizziamo OpenAI Function Calling, che richiede istruzioni minime. Definiremo il prompt con segnaposto per l'input dell'utente e il blocco note dell'agente:
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
Ora, come fa l'agente a sapere quali strumenti può utilizzare? Facciamo affidamento sulla funzione OpenAI che chiama modelli linguistici, che richiedono che le funzioni vengano passate separatamente. Per fornire i nostri strumenti all'agente, li formatteremo come chiamate di funzione OpenAI:
from langchain.tools.render import format_tool_to_openai_function llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools])
Ora possiamo creare l'agente definendo le mappature degli input e collegando i componenti:
Questo è il linguaggio LCEL. Ne discuteremo più avanti in dettaglio.
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai _function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
Abbiamo creato il nostro agente, che comprende l'input dell'utente, utilizza gli strumenti disponibili e formatta l'output. Ora interagiamo con esso:
agent.invoke({"input": "how many letters in the word educa?", "intermediate_steps": []})
L'agente dovrebbe rispondere con un AgentAction, indicando l'azione successiva da intraprendere.
Abbiamo creato l'agente, ma ora dobbiamo scriverne il runtime. Il runtime più semplice è quello che chiama continuamente l'agente, esegue azioni e si ripete finché l'agente non termina. Ecco un esempio:
from langchain.schema.agent import AgentFinish user_input = "how many letters in the word educa?"
intermediate_steps = [] while True: output = agent.invoke( { "input": user_input, "intermediate_steps": intermediate_steps, } ) if isinstance(output, AgentFinish): final_result = output.return_values["output"] break else: print(f"TOOL NAME: {output.tool}") print(f"TOOL INPUT: {output.tool_input}") tool = {"get_word_length": get_word_length}[output.tool] observation = tool.run(output.tool_input) intermediate_steps.append((output, observation)) print(final_result)
In questo ciclo chiamiamo ripetutamente l'agente, eseguiamo azioni e aggiorniamo i passaggi intermedi finché l'agente non termina. Gestiamo anche le interazioni degli strumenti all'interno del ciclo.

Per semplificare questo processo, LangChain fornisce la classe AgentExecutor, che incapsula l'esecuzione dell'agente e offre gestione degli errori, arresto anticipato, tracciamento e altri miglioramenti. Usiamo AgentExecutor per interagire con l'agente:
from langchain.agents import AgentExecutor agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) agent_executor.invoke({"input": "how many letters in the word educa?"})
AgentExecutor semplifica il processo di esecuzione e fornisce un modo conveniente per interagire con l'agente.
Anche la memoria verrà discussa in dettaglio più avanti.
L'agente che abbiamo creato finora è stateless, ovvero non ricorda le interazioni precedenti. Per abilitare domande e conversazioni di follow-up, dobbiamo aggiungere memoria all'agente. Ciò comporta due passaggi:
- Aggiungi una variabile di memoria nel prompt per archiviare la cronologia della chat.
- Tieni traccia della cronologia della chat durante le interazioni.
Iniziamo aggiungendo un segnaposto di memoria nel prompt:
from langchain.prompts import MessagesPlaceholder MEMORY_KEY = "chat_history"
prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), MessagesPlaceholder(variable_name=MEMORY_KEY), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
Ora crea un elenco per tenere traccia della cronologia della chat:
from langchain.schema.messages import HumanMessage, AIMessage chat_history = []
Nella fase di creazione dell'agente, includeremo anche la memoria:
agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), "chat_history": lambda x: x["chat_history"], } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
Ora, quando esegui l'agente, assicurati di aggiornare la cronologia della chat:
input1 = "how many letters in the word educa?"
result = agent_executor.invoke({"input": input1, "chat_history": chat_history})
chat_history.extend([ HumanMessage(content=input1), AIMessage(content=result["output"]),
])
agent_executor.invoke({"input": "is that a real word?", "chat_history": chat_history})
Ciò consente all'agente di mantenere una cronologia delle conversazioni e di rispondere alle domande di follow-up in base alle interazioni precedenti.
Congratulazioni! Hai creato ed eseguito con successo il tuo primo agente end-to-end in LangChain. Per approfondire le capacità di LangChain, puoi esplorare:
- Sono supportati diversi tipi di agenti.
- Agenti predefiniti
- Come lavorare con gli strumenti e le integrazioni degli strumenti.
Tipi di agenti
LangChain offre vari tipi di agenti, ciascuno adatto a casi d'uso specifici. Ecco alcuni degli agenti disponibili:
- Reazione a tiro zero: Questo agente utilizza il framework ReAct per scegliere gli strumenti basandosi esclusivamente sulle loro descrizioni. Richiede descrizioni per ogni strumento ed è altamente versatile.
- Ingresso strutturato ReAct: Questo agente gestisce strumenti multi-input ed è adatto per attività complesse come la navigazione in un browser web. Utilizza uno schema di argomenti degli strumenti per l'input strutturato.
- Funzioni OpenAI: Progettato specificatamente per i modelli ottimizzati per la chiamata di funzioni, questo agente è compatibile con modelli come gpt-3.5-turbo-0613 e gpt-4-0613. Lo abbiamo usato per creare il nostro primo agente sopra.
- Conversazionale: Progettato per impostazioni di conversazione, questo agente utilizza ReAct per la selezione degli strumenti e utilizza la memoria per ricordare le interazioni precedenti.
- Auto-chiediti con la ricerca: Questo agente si basa su un unico strumento, "Risposta intermedia", che cerca risposte concrete alle domande. È equivalente all'auto-domanda originale con documento di ricerca.
- Archivio documenti ReAct: Questo agente interagisce con un archivio documenti utilizzando il framework ReAct. Richiede gli strumenti "Cerca" e "Ricerca" ed è simile all'esempio Wikipedia del documento ReAct originale.
Esplora questi tipi di agenti per trovare quello più adatto alle tue esigenze in LangChain. Questi agenti consentono di associare una serie di strumenti al loro interno per gestire azioni e generare risposte. Scopri di più su come costruire il tuo agente con gli strumenti qui.
Agenti predefiniti
Continuiamo la nostra esplorazione degli agenti, concentrandoci sugli agenti predefiniti disponibili in LangChain.
Gmail
LangChain offre un toolkit Gmail che ti consente di connettere la tua email LangChain all'API Gmail. Per iniziare, dovrai impostare le tue credenziali, che sono spiegate nella documentazione dell'API Gmail. Una volta scaricato il credentials.json file, puoi procedere con l'utilizzo dell'API Gmail. Inoltre, dovrai installare alcune librerie richieste utilizzando i seguenti comandi:
pip install --upgrade google-api-python-client > /dev/null
pip install --upgrade google-auth-oauthlib > /dev/null
pip install --upgrade google-auth-httplib2 > /dev/null
pip install beautifulsoup4 > /dev/null # Optional for parsing HTML messages
Puoi creare il toolkit Gmail come segue:
from langchain.agents.agent_toolkits import GmailToolkit toolkit = GmailToolkit()
Puoi anche personalizzare l'autenticazione in base alle tue esigenze. Dietro le quinte, una risorsa googleapi viene creata utilizzando i seguenti metodi:
from langchain.tools.gmail.utils import build_resource_service, get_gmail_credentials credentials = get_gmail_credentials( token_file="token.json", scopes=["https://mail.google.com/"], client_secrets_file="credentials.json",
)
api_resource = build_resource_service(credentials=credentials)
toolkit = GmailToolkit(api_resource=api_resource)
Il toolkit offre vari strumenti che possono essere utilizzati all'interno di un agente, tra cui:
GmailCreateDraft: crea una bozza di email con i campi del messaggio specificati.GmailSendMessage: invia messaggi e-mail.GmailSearch: consente di cercare messaggi e-mail o thread.GmailGetMessage: recupera un'e-mail in base all'ID del messaggio.GmailGetThread: cerca messaggi e-mail.
Per utilizzare questi strumenti all'interno di un agente, è possibile inizializzare l'agente come segue:
from langchain.llms import OpenAI
from langchain.agents import initialize_agent, AgentType llm = OpenAI(temperature=0)
agent = initialize_agent( tools=toolkit.get_tools(), llm=llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
)
Ecco un paio di esempi di come possono essere utilizzati questi strumenti:
- Crea una bozza di Gmail per la modifica:
agent.run( "Create a gmail draft for me to edit of a letter from the perspective of a sentient parrot " "who is looking to collaborate on some research with her estranged friend, a cat. " "Under no circumstances may you send the message, however."
)
- Cerca l'email più recente nelle tue bozze:
agent.run("Could you search in my drafts for the latest email?")
Questi esempi dimostrano le funzionalità del toolkit Gmail di LangChain all'interno di un agente, consentendoti di interagire con Gmail in modo programmatico.
Agente del database SQL
Questa sezione fornisce una panoramica di un agente progettato per interagire con i database SQL, in particolare il database Chinook. Questo agente può rispondere a domande generali su un database e ripristinare gli errori. Tieni presente che è ancora in fase di sviluppo attivo e non tutte le risposte potrebbero essere corrette. Fai attenzione quando lo esegui su dati sensibili, poiché potrebbe eseguire istruzioni DML sul tuo database.
Per utilizzare questo agente, è possibile inizializzarlo come segue:
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
from langchain.agents import AgentExecutor
from langchain.agents.agent_types import AgentType
from langchain.chat_models import ChatOpenAI db = SQLDatabase.from_uri("sqlite:///../../../../../notebooks/Chinook.db")
toolkit = SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0)) agent_executor = create_sql_agent( llm=OpenAI(temperature=0), toolkit=toolkit, verbose=True, agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
Questo agente può essere inizializzato utilizzando il file ZERO_SHOT_REACT_DESCRIPTION tipo di agente. È progettato per rispondere a domande e fornire descrizioni. In alternativa, è possibile inizializzare l'agente utilizzando il file OPENAI_FUNCTIONS tipo di agente con il modello GPT-3.5-turbo di OpenAI, che abbiamo utilizzato nel nostro client precedente.
Negazione di responsabilità
- La catena di query può generare query di inserimento/aggiornamento/eliminazione. Sii cauto e, se necessario, utilizza un prompt personalizzato o crea un utente SQL senza autorizzazioni di scrittura.
- Tieni presente che l'esecuzione di determinate query, come "esegui la query più grande possibile", potrebbe sovraccaricare il tuo database SQL, soprattutto se contiene milioni di righe.
- I database orientati al data warehouse spesso supportano quote a livello di utente per limitare l'utilizzo delle risorse.
Puoi chiedere all'agente di descrivere una tabella, come la tabella "playlisttrack". Ecco un esempio di come farlo:
agent_executor.run("Describe the playlisttrack table")
L'agente fornirà informazioni sullo schema della tabella e sulle righe di esempio.
Se chiedi erroneamente informazioni su una tabella che non esiste, l'agente può recuperare e fornire informazioni sulla tabella corrispondente più vicina. Per esempio:
agent_executor.run("Describe the playlistsong table")
L'agente troverà la tabella corrispondente più vicina e fornirà informazioni a riguardo.
Puoi anche chiedere all'agente di eseguire query sul database. Ad esempio:
agent_executor.run("List the total sales per country. Which country's customers spent the most?")
L'agente eseguirà la query e fornirà il risultato, ad esempio il paese con le vendite totali più elevate.
Per ottenere il numero totale di tracce in ciascuna playlist, puoi utilizzare la seguente query:
agent_executor.run("Show the total number of tracks in each playlist. The Playlist name should be included in the result.")
L'agente restituirà i nomi delle playlist insieme ai conteggi totali delle tracce corrispondenti.
Nei casi in cui l'agente riscontra errori, può ripristinare e fornire risposte accurate. Ad esempio:
agent_executor.run("Who are the top 3 best selling artists?")
Anche dopo aver riscontrato un errore iniziale, l'agente si adatterà e fornirà la risposta corretta, che, in questo caso, corrisponde ai 3 artisti più venduti.
Agente DataFrame di Panda
Questa sezione introduce un agente progettato per interagire con Pandas DataFrames per scopi di risposta alle domande. Tieni presente che questo agente utilizza l'agente Python dietro le quinte per eseguire il codice Python generato da un modello linguistico (LLM). Prestare attenzione quando si utilizza questo agente per evitare potenziali danni derivanti da codice Python dannoso generato da LLM.
È possibile inizializzare l'agente Pandas DataFrame come segue:
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain.chat_models import ChatOpenAI
from langchain.agents.agent_types import AgentType from langchain.llms import OpenAI
import pandas as pd df = pd.read_csv("titanic.csv") # Using ZERO_SHOT_REACT_DESCRIPTION agent type
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True) # Alternatively, using OPENAI_FUNCTIONS agent type
# agent = create_pandas_dataframe_agent(
# ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613"),
# df,
# verbose=True,
# agent_type=AgentType.OPENAI_FUNCTIONS,
# )
Puoi chiedere all'agente di contare il numero di righe nel DataFrame:
agent.run("how many rows are there?")
L'agente eseguirà il codice df.shape[0] e fornire la risposta, ad esempio "Ci sono 891 righe nel dataframe".
Puoi anche chiedere all'agente di filtrare le righe in base a criteri specifici, come trovare il numero di persone con più di 3 fratelli:
agent.run("how many people have more than 3 siblings")
L'agente eseguirà il codice df[df['SibSp'] > 3].shape[0] e fornisci la risposta, ad esempio "30 persone hanno più di 3 fratelli".
Se vuoi calcolare la radice quadrata dell'età media, puoi chiedere all'agente:
agent.run("whats the square root of the average age?")
L'agente calcolerà l'età media utilizzando df['Age'].mean() e poi calcola la radice quadrata usando math.sqrt(). Fornirà la risposta, ad esempio "La radice quadrata dell'età media è 5.449689683556195".
Creiamo una copia del DataFrame e i valori di età mancanti vengono riempiti con l'età media:
df1 = df.copy()
df1["Age"] = df1["Age"].fillna(df1["Age"].mean())
Quindi, puoi inizializzare l'agente con entrambi i DataFrame e porre una domanda:
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), [df, df1], verbose=True)
agent.run("how many rows in the age column are different?")
L'agente confronterà le colonne età in entrambi i DataFrame e fornirà la risposta, ad esempio "177 righe nella colonna età sono diverse".
Kit di strumenti Jira
Questa sezione spiega come utilizzare il toolkit Jira, che consente agli agenti di interagire con un'istanza Jira. È possibile eseguire varie azioni come la ricerca di problemi e la creazione di problemi utilizzando questo toolkit. Utilizza la libreria atlassian-python-api. Per utilizzare questo toolkit, devi impostare le variabili di ambiente per la tua istanza Jira, tra cui JIRA_API_TOKEN, JIRA_USERNAME e JIRA_INSTANCE_URL. Inoltre, potrebbe essere necessario impostare la chiave API OpenAI come variabile di ambiente.
Per iniziare, installa la libreria atlassian-python-api e imposta le variabili di ambiente richieste:
%pip install atlassian-python-api import os
from langchain.agents import AgentType
from langchain.agents import initialize_agent
from langchain.agents.agent_toolkits.jira.toolkit import JiraToolkit
from langchain.llms import OpenAI
from langchain.utilities.jira import JiraAPIWrapper os.environ["JIRA_API_TOKEN"] = "abc"
os.environ["JIRA_USERNAME"] = "123"
os.environ["JIRA_INSTANCE_URL"] = "https://jira.atlassian.com"
os.environ["OPENAI_API_KEY"] = "xyz" llm = OpenAI(temperature=0)
jira = JiraAPIWrapper()
toolkit = JiraToolkit.from_jira_api_wrapper(jira)
agent = initialize_agent( toolkit.get_tools(), llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
Puoi istruire l'agente a creare un nuovo problema in un progetto specifico con un riepilogo e una descrizione:
agent.run("make a new issue in project PW to remind me to make more fried rice")
L'agente eseguirà le azioni necessarie per creare il problema e fornirà una risposta, ad esempio "È stato creato un nuovo problema nel progetto PW con il riepilogo 'Preparare più riso fritto' e la descrizione 'Promemoria per preparare più riso fritto'."
Ciò ti consente di interagire con la tua istanza Jira utilizzando le istruzioni in linguaggio naturale e il toolkit Jira.
Automatizza le attività manuali e i flussi di lavoro con il nostro generatore di flussi di lavoro basato sull'intelligenza artificiale, progettato da Nanonets per te e i tuoi team.
Modulo IV: Catene
LangChain è uno strumento progettato per l'utilizzo di Large Language Models (LLM) in applicazioni complesse. Fornisce strutture per la creazione di catene di componenti, inclusi LLM e altri tipi di componenti. Due quadri principali
- Il linguaggio di espressione LangChain (LCEL)
- Interfaccia della catena legacy
Il LangChain Expression Language (LCEL) è una sintassi che consente la composizione intuitiva delle catene. Supporta funzionalità avanzate come streaming, chiamate asincrone, batch, parallelizzazione, nuovi tentativi, fallback e traccia. Ad esempio, puoi comporre un prompt, un modello e un parser di output in LCEL come mostrato nel codice seguente:
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = ChatPromptTemplate.from_messages([ ("system", "You're a very knowledgeable historian who provides accurate and eloquent answers to historical questions."), ("human", "{question}")
])
runnable = prompt | model | StrOutputParser() for chunk in runnable.stream({"question": "What are the seven wonders of the world"}): print(chunk, end="", flush=True)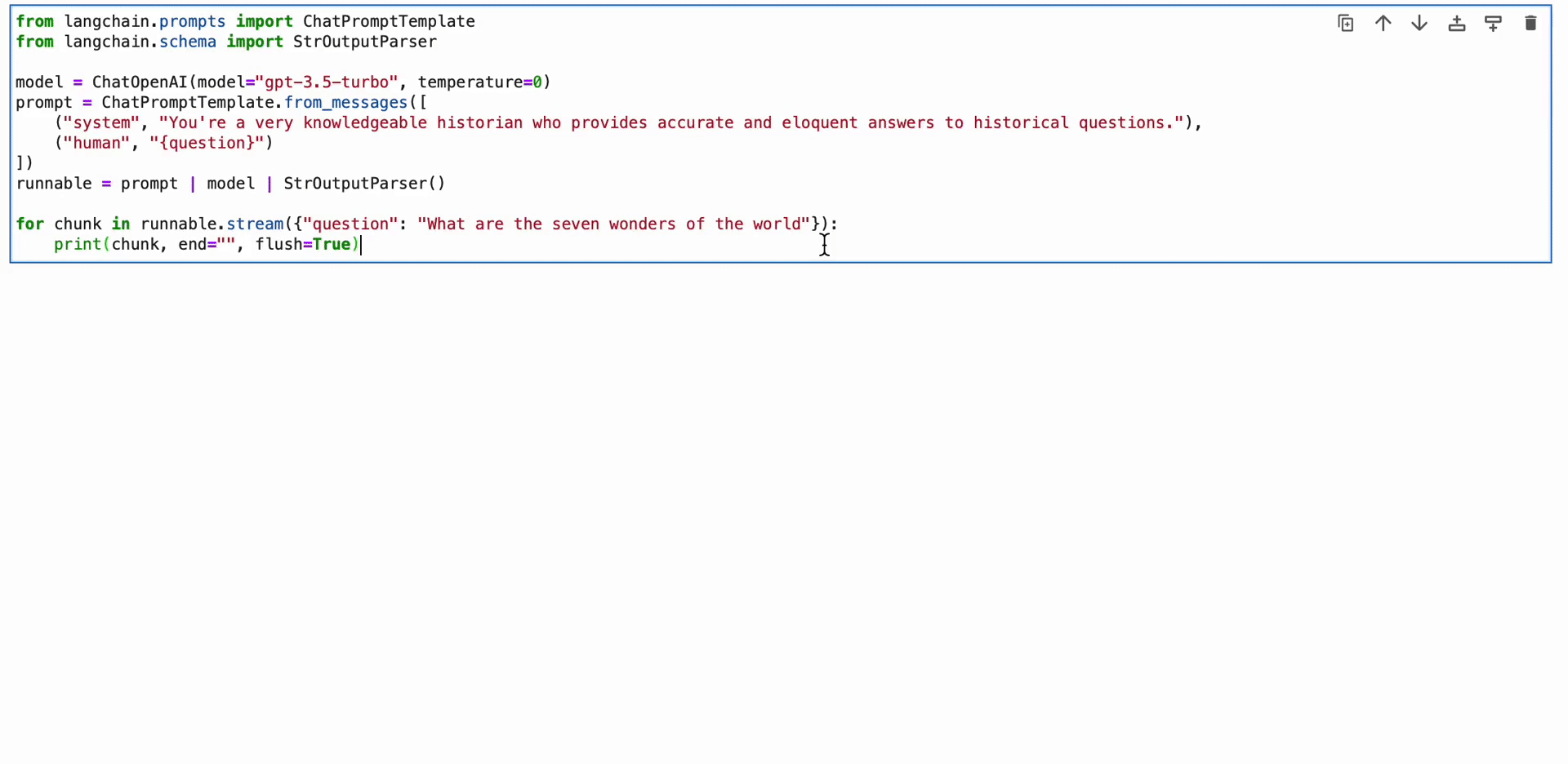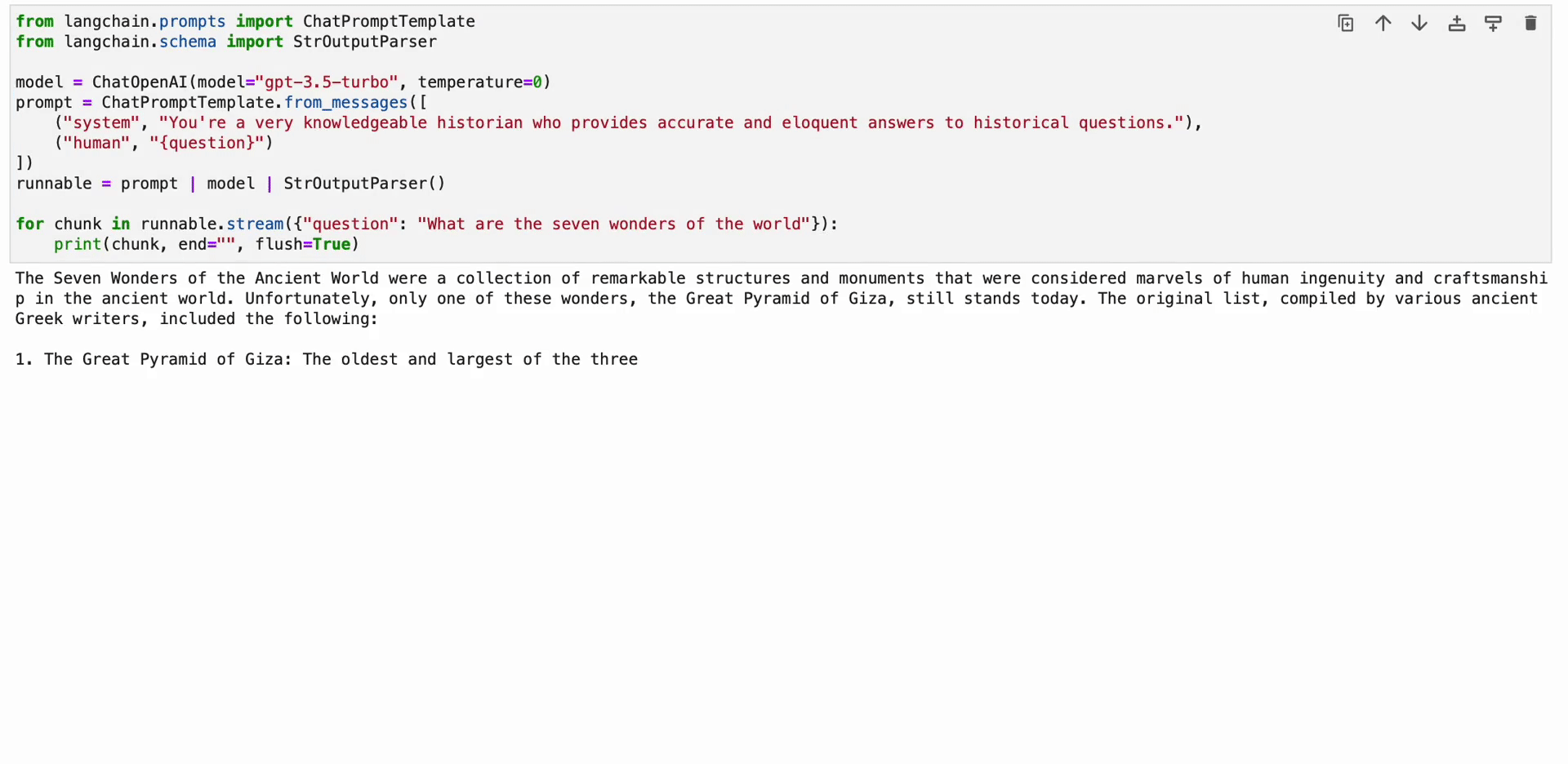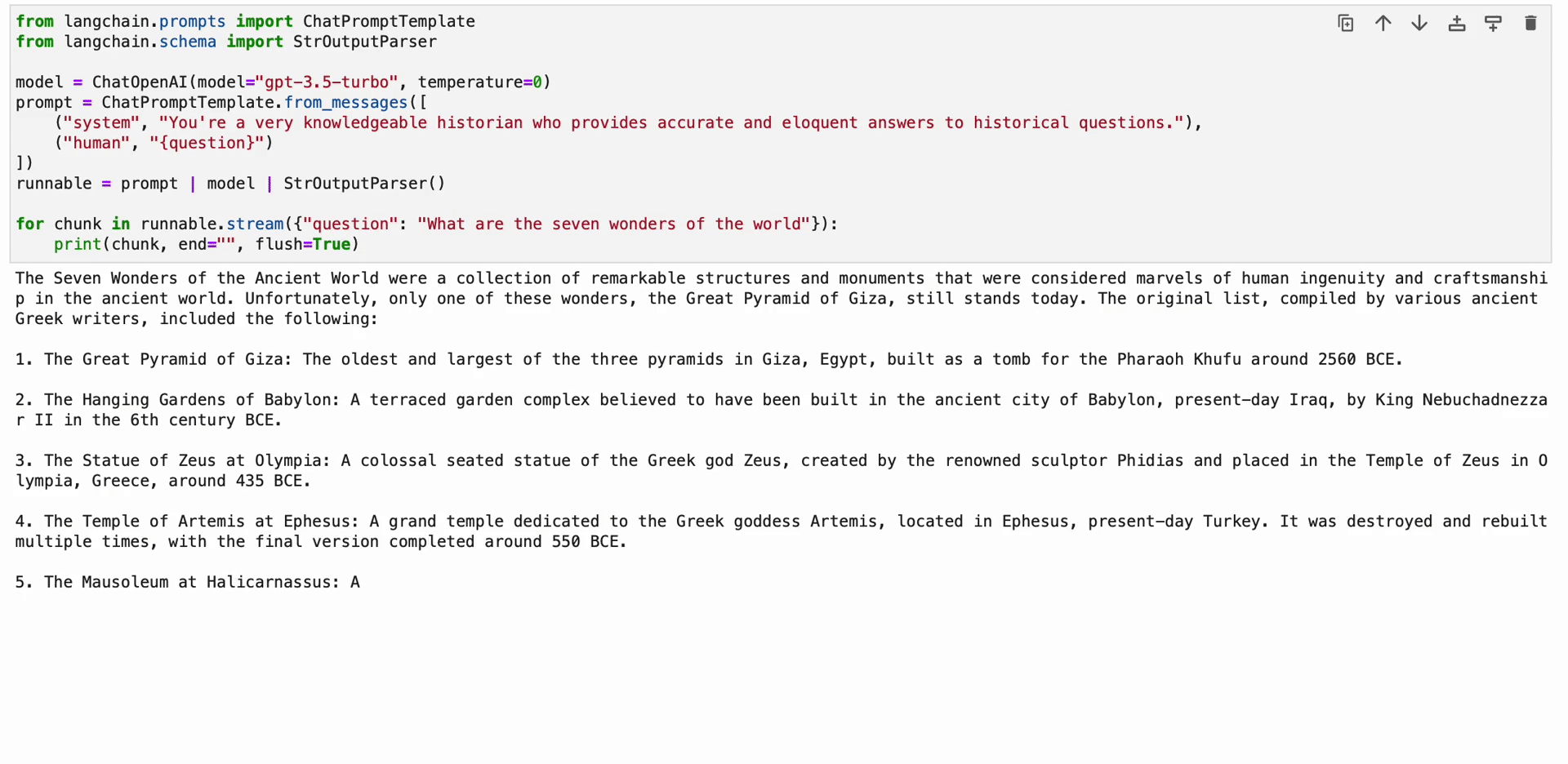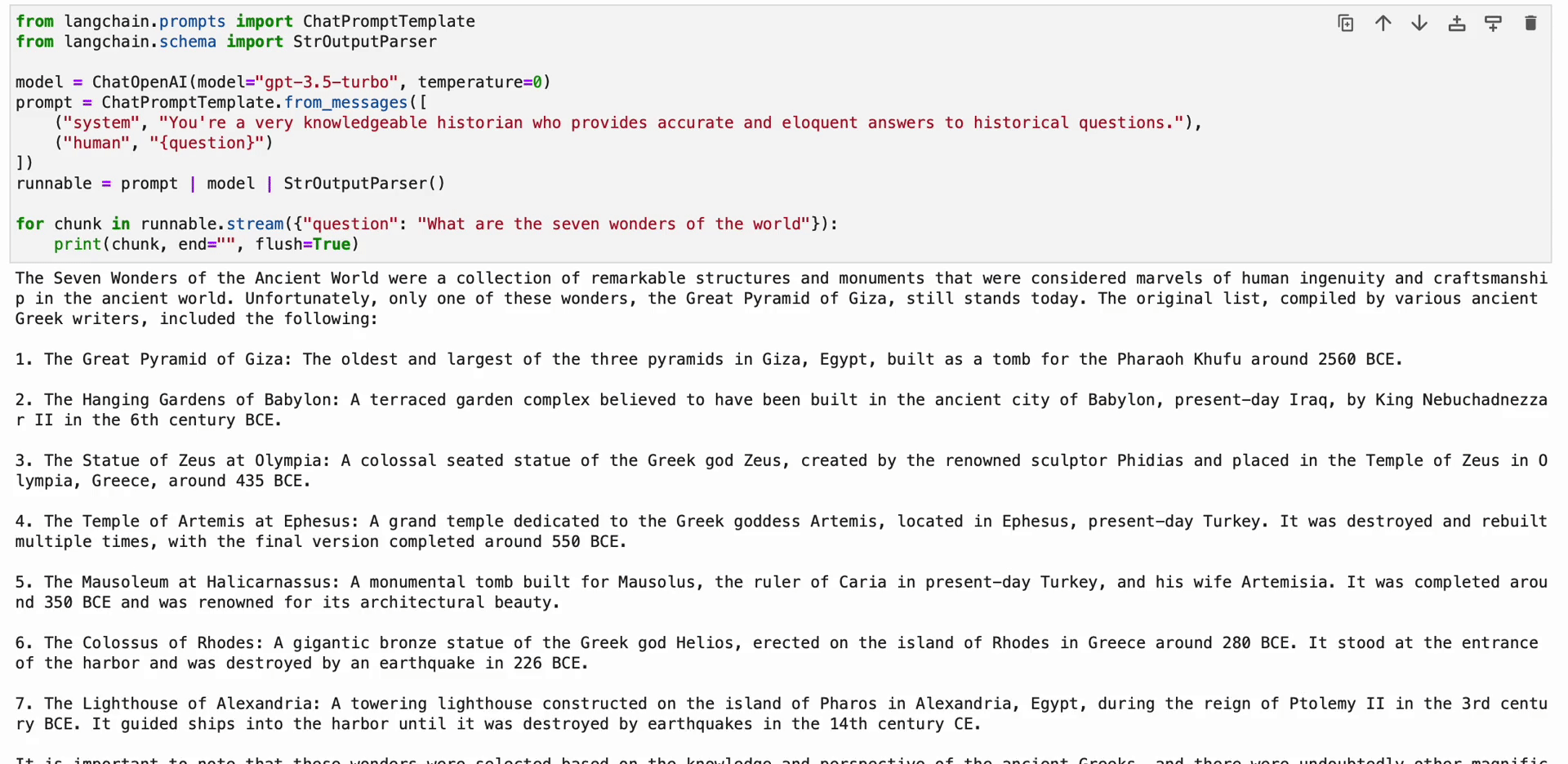
In alternativa, LLMChain è un'opzione simile a LCEL per la composizione dei componenti. L'esempio LLMChain è il seguente:
from langchain.chains import LLMChain chain = LLMChain(llm=model, prompt=prompt, output_parser=StrOutputParser())
chain.run(question="What are the seven wonders of the world")
Le catene in LangChain possono anche essere stateful incorporando un oggetto Memory. Ciò consente la persistenza dei dati tra le chiamate, come mostrato in questo esempio:
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory conversation = ConversationChain(llm=chat, memory=ConversationBufferMemory())
conversation.run("Answer briefly. What are the first 3 colors of a rainbow?")
conversation.run("And the next 4?")
LangChain supporta anche l'integrazione con le API di chiamata di funzioni di OpenAI, utile per ottenere output strutturati ed eseguire funzioni all'interno di una catena. Per ottenere output strutturati, puoi specificarli utilizzando le classi Pydantic o JsonSchema, come illustrato di seguito:
from langchain.pydantic_v1 import BaseModel, Field
from langchain.chains.openai_functions import create_structured_output_runnable
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") fav_food: Optional[str] = Field(None, description="The person's favorite food") llm = ChatOpenAI(model="gpt-4", temperature=0)
prompt = ChatPromptTemplate.from_messages([ # Prompt messages here
]) runnable = create_structured_output_runnable(Person, llm, prompt)
runnable.invoke({"input": "Sally is 13"})
Per gli output strutturati è disponibile anche un approccio legacy che utilizza LLMChain:
from langchain.chains.openai_functions import create_structured_output_chain class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") chain = create_structured_output_chain(Person, llm, prompt, verbose=True)
chain.run("Sally is 13")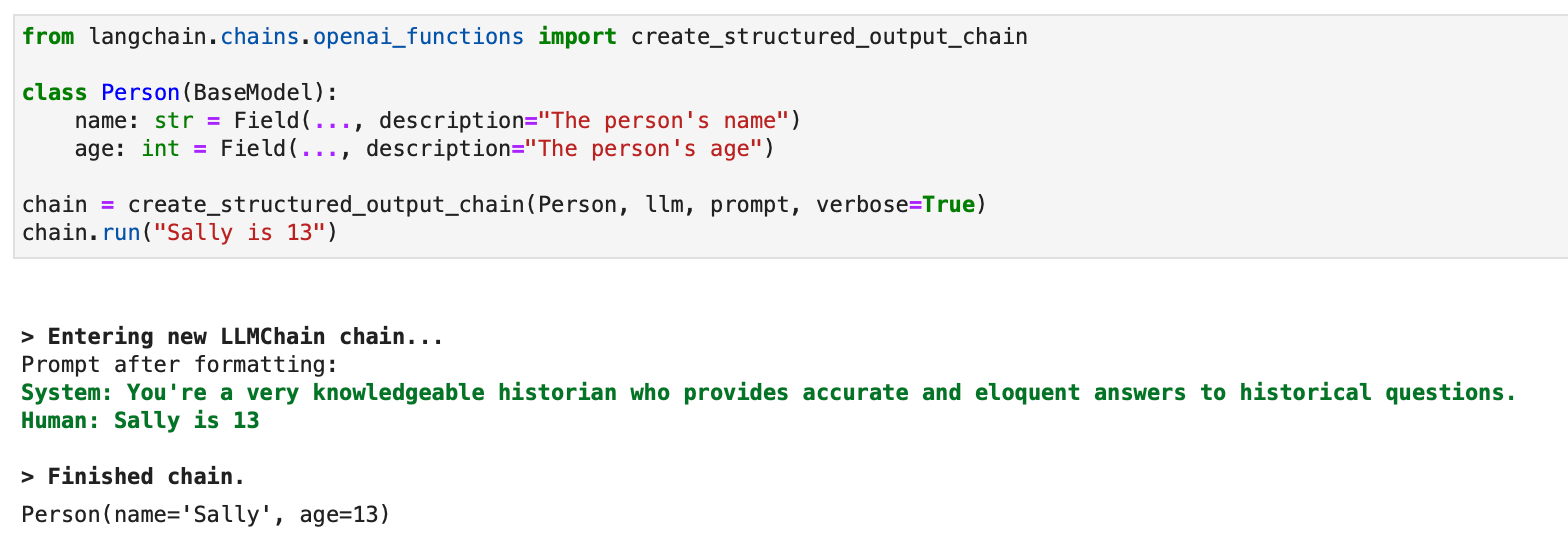
LangChain sfrutta le funzioni OpenAI per creare varie catene specifiche per scopi diversi. Questi includono catene per estrazione, tagging, OpenAPI e QA con citazioni.
Nel contesto dell'estrazione, il processo è simile alla catena di output strutturata ma si concentra sull'estrazione di informazioni o entità. Per l'etichettatura, l'idea è quella di etichettare un documento con classi come sentimento, lingua, stile, argomenti trattati o tendenza politica.
Un esempio di come funziona il tagging in LangChain può essere dimostrato con un codice Python. Il processo inizia con l'installazione dei pacchetti necessari e la configurazione dell'ambiente:
pip install langchain openai
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv() from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import create_tagging_chain, create_tagging_chain_pydantic
Viene definito lo schema per il tagging, specificando le proprietà e le relative tipologie previste:
schema = { "properties": { "sentiment": {"type": "string"}, "aggressiveness": {"type": "integer"}, "language": {"type": "string"}, }
} llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_tagging_chain(schema, llm)
Esempi di esecuzione della catena di tagging con input diversi mostrano la capacità del modello di interpretare sentimenti, linguaggi e aggressività:
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"
chain.run(inp)
# {'sentiment': 'positive', 'language': 'Spanish'} inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"
chain.run(inp)
# {'sentiment': 'enojado', 'aggressiveness': 1, 'language': 'es'}
Per un controllo più preciso, lo schema può essere definito in modo più specifico, includendo possibili valori, descrizioni e proprietà richieste. Di seguito è riportato un esempio di questo controllo avanzato:
schema = { "properties": { # Schema definitions here }, "required": ["language", "sentiment", "aggressiveness"],
} chain = create_tagging_chain(schema, llm)
Gli schemi Pydantic possono essere utilizzati anche per definire criteri di tagging, fornendo un modo Python per specificare le proprietà e i tipi richiesti:
from enum import Enum
from pydantic import BaseModel, Field class Tags(BaseModel): # Class fields here chain = create_tagging_chain_pydantic(Tags, llm)
Inoltre, il trasformatore di documenti tagger di metadati di LangChain può essere utilizzato per estrarre metadati dai documenti LangChain, offrendo funzionalità simili alla catena di tagging ma applicate a un documento LangChain.
Citare le fonti di recupero è un'altra caratteristica di LangChain, che utilizza le funzioni OpenAI per estrarre citazioni dal testo. Ciò è dimostrato nel seguente codice:
from langchain.chains import create_citation_fuzzy_match_chain
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_citation_fuzzy_match_chain(llm)
# Further code for running the chain and displaying results
In LangChain, il concatenamento di applicazioni LLM (Large Language Model) comporta in genere la combinazione di un modello di prompt con un LLM e facoltativamente un parser di output. Il modo consigliato per eseguire questa operazione è tramite LangChain Expression Language (LCEL), sebbene sia supportato anche l'approccio LLMChain legacy.
Utilizzando LCEL, BasePromptTemplate, BaseLanguageModel e BaseOutputParser implementano tutti l'interfaccia Runnable e possono essere facilmente collegati l'uno all'altro. Ecco un esempio che lo dimostra:
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser prompt = PromptTemplate.from_template( "What is a good name for a company that makes {product}?"
)
runnable = prompt | ChatOpenAI() | StrOutputParser()
runnable.invoke({"product": "colorful socks"})
# Output: 'VibrantSocks'
Il routing in LangChain consente di creare catene non deterministiche in cui l'output di un passaggio precedente determina il passaggio successivo. Ciò aiuta a strutturare e mantenere la coerenza nelle interazioni con i LLM. Ad esempio, se disponi di due modelli ottimizzati per diversi tipi di domande, puoi scegliere il modello in base all'input dell'utente.
Ecco come è possibile ottenere questo risultato utilizzando LCEL con RunnableBranch, che viene inizializzato con un elenco di coppie (condizione, eseguibile) e un eseguibile predefinito:
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableBranch
# Code for defining physics_prompt and math_prompt general_prompt = PromptTemplate.from_template( "You are a helpful assistant. Answer the question as accurately as you can.nn{input}"
)
prompt_branch = RunnableBranch( (lambda x: x["topic"] == "math", math_prompt), (lambda x: x["topic"] == "physics", physics_prompt), general_prompt,
) # More code for setting up the classifier and final chain
La catena finale viene quindi costruita utilizzando vari componenti, come un classificatore di argomenti, un ramo di prompt e un parser di output, per determinare il flusso in base all'argomento dell'input:
from operator import itemgetter
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough final_chain = ( RunnablePassthrough.assign(topic=itemgetter("input") | classifier_chain) | prompt_branch | ChatOpenAI() | StrOutputParser()
) final_chain.invoke( { "input": "What is the first prime number greater than 40 such that one plus the prime number is divisible by 3?" }
)
# Output: Detailed answer to the math question
Questo approccio esemplifica la flessibilità e la potenza di LangChain nel gestire query complesse e instradarle in modo appropriato in base all'input.
Nell'ambito dei modelli linguistici, una pratica comune è quella di far seguire a una chiamata iniziale una serie di chiamate successive, utilizzando l'output di una chiamata come input per quella successiva. Questo approccio sequenziale è particolarmente utile quando si desidera sfruttare le informazioni generate nelle interazioni precedenti. Sebbene LangChain Expression Language (LCEL) sia il metodo consigliato per creare queste sequenze, il metodo SequentialChain è ancora documentato per la sua compatibilità con le versioni precedenti.
Per illustrare ciò, consideriamo uno scenario in cui generiamo prima una sinossi dell'opera teatrale e poi una revisione basata su tale sinossi. Utilizzando Python langchain.prompts, ne creiamo due PromptTemplate istanze: una per la sinossi e un'altra per la recensione. Ecco il codice per impostare questi modelli:
from langchain.prompts import PromptTemplate synopsis_prompt = PromptTemplate.from_template( "You are a playwright. Given the title of play, it is your job to write a synopsis for that title.nnTitle: {title}nPlaywright: This is a synopsis for the above play:"
) review_prompt = PromptTemplate.from_template( "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
)
Nell'approccio LCEL, concatenamo questi prompt con ChatOpenAI ed StrOutputParser per creare una sequenza che generi prima una sinossi e poi una recensione. Lo snippet di codice è il seguente:
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser llm = ChatOpenAI()
chain = ( {"synopsis": synopsis_prompt | llm | StrOutputParser()} | review_prompt | llm | StrOutputParser()
)
chain.invoke({"title": "Tragedy at sunset on the beach"})
Se abbiamo bisogno sia della sinossi che della recensione, possiamo usare RunnablePassthrough per creare una catena separata per ciascuno e quindi combinarli:
from langchain.schema.runnable import RunnablePassthrough synopsis_chain = synopsis_prompt | llm | StrOutputParser()
review_chain = review_prompt | llm | StrOutputParser()
chain = {"synopsis": synopsis_chain} | RunnablePassthrough.assign(review=review_chain)
chain.invoke({"title": "Tragedy at sunset on the beach"})
Per scenari che coinvolgono sequenze più complesse, il SequentialChain entra in gioco il metodo. Ciò consente più ingressi e uscite. Consideriamo il caso in cui abbiamo bisogno di una sinossi basata sul titolo e sull'epoca di un'opera teatrale. Ecco come potremmo configurarlo:
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SequentialChain
from langchain.prompts import PromptTemplate llm = OpenAI(temperature=0.7) synopsis_template = "You are a playwright. Given the title of play and the era it is set in, it is your job to write a synopsis for that title.nnTitle: {title}nEra: {era}nPlaywright: This is a synopsis for the above play:"
synopsis_prompt_template = PromptTemplate(input_variables=["title", "era"], template=synopsis_template)
synopsis_chain = LLMChain(llm=llm, prompt=synopsis_prompt_template, output_key="synopsis") review_template = "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
prompt_template = PromptTemplate(input_variables=["synopsis"], template=review_template)
review_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="review") overall_chain = SequentialChain( chains=[synopsis_chain, review_chain], input_variables=["era", "title"], output_variables=["synopsis", "review"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
Negli scenari in cui desideri mantenere il contesto lungo tutta la catena o per una parte successiva della catena, SimpleMemory può essere utilizzata. Ciò è particolarmente utile per gestire relazioni input/output complesse. Ad esempio, in uno scenario in cui vogliamo generare post sui social media in base al titolo, all'epoca, alla sinossi e alla recensione di un'opera teatrale, SimpleMemory può aiutare a gestire queste variabili:
from langchain.memory import SimpleMemory
from langchain.chains import SequentialChain template = "You are a social media manager for a theater company. Given the title of play, the era it is set in, the date, time and location, the synopsis of the play, and the review of the play, it is your job to write a social media post for that play.nnHere is some context about the time and location of the play:nDate and Time: {time}nLocation: {location}nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:n{review}nnSocial Media Post:"
prompt_template = PromptTemplate(input_variables=["synopsis", "review", "time", "location"], template=template)
social_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="social_post_text") overall_chain = SequentialChain( memory=SimpleMemory(memories={"time": "December 25th, 8pm PST", "location": "Theater in the Park"}), chains=[synopsis_chain, review_chain, social_chain], input_variables=["era", "title"], output_variables=["social_post_text"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
Oltre alle catene sequenziali, esistono catene specializzate per lavorare con i documenti. Ognuna di queste catene ha uno scopo diverso, dalla combinazione di documenti al perfezionamento delle risposte sulla base dell'analisi iterativa dei documenti, alla mappatura e riduzione del contenuto dei documenti per il riepilogo o la riclassificazione in base alle risposte con punteggio. Queste catene possono essere ricreate con LCEL per ulteriore flessibilità e personalizzazione.
-
StuffDocumentsChaincombina un elenco di documenti in un unico prompt passato a un LLM. -
RefineDocumentsChainaggiorna la sua risposta in modo iterativo per ciascun documento, adatto per attività in cui i documenti superano la capacità del contesto del modello. -
MapReduceDocumentsChainapplica una catena a ciascun documento individualmente e quindi combina i risultati. -
MapRerankDocumentsChainassegna un punteggio a ciascuna risposta basata su documenti e seleziona quella con il punteggio più alto.
Ecco un esempio di come potresti impostare un file MapReduceDocumentsChain utilizzando LCEL:
from functools import partial
from langchain.chains.combine_documents import collapse_docs, split_list_of_docs
from langchain.schema import Document, StrOutputParser
from langchain.schema.prompt_template import format_document
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough llm = ChatAnthropic()
document_prompt = PromptTemplate.from_template("{page_content}")
partial_format_document = partial(format_document, prompt=document_prompt) map_chain = ( {"context": partial_format_document} | PromptTemplate.from_template("Summarize this content:nn{context}") | llm | StrOutputParser()
) map_as_doc_chain = ( RunnableParallel({"doc": RunnablePassthrough(), "content": map_chain}) | (lambda x: Document(page_content=x["content"], metadata=x["doc"].metadata))
).with_config(run_name="Summarize (return doc)") def format_docs(docs): return "nn".join(partial_format_document(doc) for doc in docs) collapse_chain = ( {"context": format_docs} | PromptTemplate.from_template("Collapse this content:nn{context}") | llm | StrOutputParser()
) reduce_chain = ( {"context": format_docs} | PromptTemplate.from_template("Combine these summaries:nn{context}") | llm | StrOutputParser()
).with_config(run_name="Reduce") map_reduce = (map_as_doc_chain.map() | collapse | reduce_chain).with_config(run_name="Map reduce")
Questa configurazione consente un'analisi dettagliata e completa del contenuto del documento, sfruttando i punti di forza di LCEL e del modello linguistico sottostante.
Automatizza le attività manuali e i flussi di lavoro con il nostro generatore di flussi di lavoro basato sull'intelligenza artificiale, progettato da Nanonets per te e i tuoi team.
Modulo V: Memoria
In LangChain, la memoria è un aspetto fondamentale delle interfacce conversazionali, poiché consente ai sistemi di fare riferimento alle interazioni passate. Ciò si ottiene memorizzando e interrogando informazioni, con due azioni principali: lettura e scrittura. Il sistema di memoria interagisce con una catena due volte durante una corsa, aumentando gli input dell'utente e memorizzando gli input e gli output per riferimento futuro.
Costruire la memoria in un sistema
- Memorizzazione dei messaggi di chat: Il modulo di memoria LangChain integra vari metodi per archiviare i messaggi di chat, dagli elenchi in memoria ai database. Ciò garantisce che tutte le interazioni della chat vengano registrate per riferimento futuro.
- Interrogazione dei messaggi di chat: Oltre a memorizzare i messaggi di chat, LangChain utilizza strutture di dati e algoritmi per creare una visualizzazione utile di questi messaggi. I sistemi di memoria semplici potrebbero restituire messaggi recenti, mentre i sistemi più avanzati potrebbero riassumere le interazioni passate o concentrarsi sulle entità menzionate nell'interazione corrente.
Per dimostrare l'uso della memoria in LangChain, considera il ConversationBufferMemory class, un semplice modulo di memoria che memorizza i messaggi di chat in un buffer. Ecco un esempio:
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("Hello!")
memory.chat_memory.add_ai_message("How can I assist you?")
Quando si integra la memoria in una catena, è fondamentale comprendere le variabili restituite dalla memoria e il modo in cui vengono utilizzate nella catena. Ad esempio, il load_memory_variables Il metodo aiuta ad allineare le variabili lette dalla memoria con le aspettative della catena.
Esempio end-to-end con LangChain
Prendi in considerazione l'utilizzo ConversationBufferMemory Organizza una LLMChain. La catena, combinata con un modello di prompt appropriato e con la memoria, fornisce un'esperienza di conversazione fluida. Ecco un esempio semplificato:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory llm = OpenAI(temperature=0)
template = "Your conversation template here..."
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(llm=llm, prompt=prompt, memory=memory) response = conversation({"question": "What's the weather like?"})
Questo esempio illustra come il sistema di memoria di LangChain si integra con le sue catene per fornire un'esperienza di conversazione coerente e contestualmente consapevole.
Tipi di memoria in Langchain
Langchain offre vari tipi di memoria che possono essere utilizzati per migliorare le interazioni con i modelli AI. Ogni tipo di memoria ha i propri parametri e tipi di restituzione, che li rendono adatti a diversi scenari. Esploriamo alcuni dei tipi di memoria disponibili in Langchain insieme ad esempi di codice.
1. Memoria buffer di conversazione
Questo tipo di memoria consente di archiviare ed estrarre messaggi dalle conversazioni. Puoi estrarre la cronologia come stringa o come elenco di messaggi.
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) # Extract history as a string
{'history': 'Human: hinAI: whats up'} # Extract history as a list of messages
{'history': [HumanMessage(content='hi', additional_kwargs={}), AIMessage(content='whats up', additional_kwargs={})]}
Puoi anche utilizzare la memoria buffer di conversazione in una catena per interazioni simili a chat.
2. Memoria della finestra del buffer di conversazione
Questo tipo di memoria conserva un elenco delle interazioni recenti e utilizza le ultime K interazioni, evitando che il buffer diventi troppo grande.
from langchain.memory import ConversationBufferWindowMemory memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
Come la memoria buffer di conversazione, puoi anche utilizzare questo tipo di memoria in una catena per interazioni simili a chat.
3. Memoria dell'entità di conversazione
Questo tipo di memoria ricorda fatti su entità specifiche in una conversazione ed estrae informazioni utilizzando un LLM.
from langchain.memory import ConversationEntityMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationEntityMemory(llm=llm)
_input = {"input": "Deven & Sam are working on a hackathon project"}
memory.load_memory_variables(_input)
memory.save_context( _input, {"output": " That sounds like a great project! What kind of project are they working on?"}
)
memory.load_memory_variables({"input": 'who is Sam'}) {'history': 'Human: Deven & Sam are working on a hackathon projectnAI: That sounds like a great project! What kind of project are they working on?', 'entities': {'Sam': 'Sam is working on a hackathon project with Deven.'}}
4. Memoria del grafico della conoscenza della conversazione
Questo tipo di memoria utilizza un grafico della conoscenza per ricreare la memoria. È possibile estrarre entità correnti e triplette di conoscenze dai messaggi.
from langchain.memory import ConversationKGMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationKGMemory(llm=llm)
memory.save_context({"input": "say hi to sam"}, {"output": "who is sam"})
memory.save_context({"input": "sam is a friend"}, {"output": "okay"})
memory.load_memory_variables({"input": "who is sam"}) {'history': 'On Sam: Sam is friend.'}
È inoltre possibile utilizzare questo tipo di memoria in una catena per il recupero della conoscenza basato sulla conversazione.
5. Memoria di riepilogo delle conversazioni
Questo tipo di memoria crea un riepilogo della conversazione nel tempo, utile per condensare informazioni da conversazioni più lunghe.
from langchain.memory import ConversationSummaryMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=llm)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) {'history': 'nThe human greets the AI, to which the AI responds.'}
6. Memoria buffer di riepilogo delle conversazioni
Questo tipo di memoria combina il riepilogo della conversazione e il buffer, mantenendo un equilibrio tra le interazioni recenti e un riepilogo. Utilizza la lunghezza del token per determinare quando eliminare le interazioni.
from langchain.memory import ConversationSummaryBufferMemory
from langchain.llms import OpenAI llm = OpenAI()
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'System: nThe human says "hi", and the AI responds with "whats up".nHuman: not much younAI: not much'}
Puoi utilizzare questi tipi di memoria per migliorare le tue interazioni con i modelli AI in Langchain. Ciascun tipo di memoria ha uno scopo specifico e può essere selezionato in base alle proprie esigenze.
7. Memoria buffer dei token di conversazione
ConversationTokenBufferMemory è un altro tipo di memoria che mantiene in memoria un buffer delle interazioni recenti. A differenza dei tipi di memoria precedenti che si concentrano sul numero di interazioni, questo utilizza la lunghezza del token per determinare quando eliminare le interazioni.
Utilizzo della memoria con LLM:
from langchain.memory import ConversationTokenBufferMemory
from langchain.llms import OpenAI llm = OpenAI() memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"}) memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
In questo esempio, la memoria è impostata per limitare le interazioni in base alla lunghezza del token anziché al numero di interazioni.
È inoltre possibile ottenere la cronologia sotto forma di elenco di messaggi quando si utilizza questo tipo di memoria.
memory = ConversationTokenBufferMemory( llm=llm, max_token_limit=10, return_messages=True
)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
Utilizzo in una catena:
Puoi utilizzare ConversationTokenBufferMemory in una catena per migliorare le interazioni con il modello AI.
from langchain.chains import ConversationChain conversation_with_summary = ConversationChain( llm=llm, # We set a very low max_token_limit for the purposes of testing. memory=ConversationTokenBufferMemory(llm=OpenAI(), max_token_limit=60), verbose=True,
)
conversation_with_summary.predict(input="Hi, what's up?")
In questo esempio, ConversationTokenBufferMemory viene utilizzato in ConversationChain per gestire la conversazione e limitare le interazioni in base alla lunghezza del token.
8. Memoria di VectorStore Retriever
VectorStoreRetrieverMemory memorizza i ricordi in un archivio vettoriale e interroga i documenti più "salienti" ogni volta che viene chiamato. Questo tipo di memoria non tiene traccia esplicitamente dell'ordine delle interazioni ma utilizza il recupero dei vettori per recuperare ricordi rilevanti.
from datetime import datetime
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.memory import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate # Initialize your vector store (specifics depend on the chosen vector store)
import faiss
from langchain.docstore import InMemoryDocstore
from langchain.vectorstores import FAISS embedding_size = 1536 # Dimensions of the OpenAIEmbeddings
index = faiss.IndexFlatL2(embedding_size)
embedding_fn = OpenAIEmbeddings().embed_query
vectorstore = FAISS(embedding_fn, index, InMemoryDocstore({}), {}) # Create your VectorStoreRetrieverMemory
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever) # Save context and relevant information to the memory
memory.save_context({"input": "My favorite food is pizza"}, {"output": "that's good to know"})
memory.save_context({"input": "My favorite sport is soccer"}, {"output": "..."})
memory.save_context({"input": "I don't like the Celtics"}, {"output": "ok"}) # Retrieve relevant information from memory based on a query
print(memory.load_memory_variables({"prompt": "what sport should i watch?"})["history"])
In questo esempio, VectorStoreRetrieverMemory viene utilizzato per archiviare e recuperare informazioni rilevanti da una conversazione basata sul recupero di vettori.
Puoi anche utilizzare VectorStoreRetrieverMemory in una catena per il recupero della conoscenza basato sulla conversazione, come mostrato negli esempi precedenti.
Questi diversi tipi di memoria in Langchain forniscono vari modi per gestire e recuperare informazioni dalle conversazioni, migliorando le capacità dei modelli di intelligenza artificiale nella comprensione e nella risposta alle domande e al contesto degli utenti. Ciascun tipo di memoria può essere selezionato in base ai requisiti specifici della propria applicazione.
Ora impareremo come utilizzare la memoria con LLMChain. La memoria in una LLMChain consente al modello di ricordare le interazioni e il contesto precedenti per fornire risposte più coerenti e consapevoli del contesto.
Per configurare la memoria in LLMChain, è necessario creare una classe di memoria, ad esempio ConversationBufferMemory. Ecco come puoi configurarlo:
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate template = """You are a chatbot having a conversation with a human. {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history") llm = OpenAI()
llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) llm_chain.predict(human_input="Hi there my friend")
In questo esempio, ConversationBufferMemory viene utilizzato per archiviare la cronologia delle conversazioni. IL memory_key Il parametro specifica la chiave utilizzata per archiviare la cronologia delle conversazioni.
Se utilizzi un modello di chat invece di un modello in stile completamento, puoi strutturare le tue istruzioni in modo diverso per utilizzare meglio la memoria. Ecco un esempio di come configurare una LLMChain basata sul modello di chat con memoria:
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage
from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder,
) # Create a ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages( [ SystemMessage( content="You are a chatbot having a conversation with a human." ), # The persistent system prompt MessagesPlaceholder( variable_name="chat_history" ), # Where the memory will be stored. HumanMessagePromptTemplate.from_template( "{human_input}" ), # Where the human input will be injected ]
) memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True) llm = ChatOpenAI() chat_llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) chat_llm_chain.predict(human_input="Hi there my friend")
In questo esempio, ChatPromptTemplate viene utilizzato per strutturare il prompt e ConversationBufferMemory viene utilizzato per archiviare e recuperare la cronologia delle conversazioni. Questo approccio è particolarmente utile per le conversazioni in stile chat in cui il contesto e la cronologia svolgono un ruolo cruciale.
È inoltre possibile aggiungere memoria a una catena con più input, ad esempio una catena di domande/risposte. Ecco un esempio di come impostare la memoria in una catena di domande/risposte:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
from langchain.docstore.document import Document
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory # Split a long document into smaller chunks
with open("../../state_of_the_union.txt") as f: state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union) # Create an ElasticVectorSearch instance to index and search the document chunks
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts( texts, embeddings, metadatas=[{"source": i} for i in range(len(texts))]
) # Perform a question about the document
query = "What did the president say about Justice Breyer"
docs = docsearch.similarity_search(query) # Set up a prompt for the question-answering chain with memory
template = """You are a chatbot having a conversation with a human. Given the following extracted parts of a long document and a question, create a final answer. {context} {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input", "context"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input")
chain = load_qa_chain( OpenAI(temperature=0), chain_type="stuff", memory=memory, prompt=prompt
) # Ask the question and retrieve the answer
query = "What did the president say about Justice Breyer"
result = chain({"input_documents": docs, "human_input": query}, return_only_outputs=True) print(result)
print(chain.memory.buffer)
In questo esempio, si risponde a una domanda utilizzando un documento suddiviso in parti più piccole. ConversationBufferMemory viene utilizzato per archiviare e recuperare la cronologia delle conversazioni, consentendo al modello di fornire risposte sensibili al contesto.
L'aggiunta di memoria a un agente gli consente di ricordare e utilizzare le interazioni precedenti per rispondere a domande e fornire risposte sensibili al contesto. Ecco come è possibile impostare la memoria in un agente:
from langchain.agents import ZeroShotAgent, Tool, AgentExecutor
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.utilities import GoogleSearchAPIWrapper # Create a tool for searching
search = GoogleSearchAPIWrapper()
tools = [ Tool( name="Search", func=search.run, description="useful for when you need to answer questions about current events", )
] # Create a prompt with memory
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:"""
suffix = """Begin!" {chat_history}
Question: {input}
{agent_scratchpad}""" prompt = ZeroShotAgent.create_prompt( tools, prefix=prefix, suffix=suffix, input_variables=["input", "chat_history", "agent_scratchpad"],
)
memory = ConversationBufferMemory(memory_key="chat_history") # Create an LLMChain with memory
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools( agent=agent, tools=tools, verbose=True, memory=memory
) # Ask a question and retrieve the answer
response = agent_chain.run(input="How many people live in Canada?")
print(response) # Ask a follow-up question
response = agent_chain.run(input="What is their national anthem called?")
print(response)
In questo esempio, la memoria viene aggiunta a un agente, consentendogli di ricordare la cronologia delle conversazioni precedenti e fornire risposte sensibili al contesto. Ciò consente all'agente di rispondere accuratamente alle domande di follow-up in base alle informazioni archiviate in memoria.
Linguaggio di espressione LangChain
Nel mondo dell’elaborazione del linguaggio naturale e dell’apprendimento automatico, comporre complesse catene di operazioni può essere un compito arduo. Fortunatamente, LangChain Expression Language (LCEL) viene in soccorso, fornendo un modo dichiarativo ed efficiente per creare e distribuire sofisticate pipeline di elaborazione del linguaggio. LCEL è progettata per semplificare il processo di composizione delle catene, consentendo di passare con facilità dalla prototipazione alla produzione. In questo blog esploreremo cos'è LCEL e perché potresti volerlo utilizzare, insieme ad esempi pratici di codice per illustrarne le capacità.
LCEL, o LangChain Expression Language, è un potente strumento per comporre catene di elaborazione linguistica. È stato creato appositamente per supportare la transizione dalla prototipazione alla produzione senza interruzioni, senza richiedere modifiche estese al codice. Che tu stia costruendo una semplice catena "prompt + LLM" o una pipeline complessa con centinaia di passaggi, LCEL è quello che fa per te.
Ecco alcuni motivi per utilizzare LCEL nei tuoi progetti di elaborazione linguistica:
- Streaming veloce di token: LCEL fornisce token da un modello linguistico a un parser di output in tempo reale, migliorando la reattività e l'efficienza.
- API versatili: LCEL supporta API sia sincrone che asincrone per la prototipazione e l'utilizzo in produzione, gestendo più richieste in modo efficiente.
- Parallelizzazione automatica: LCEL ottimizza l'esecuzione parallela quando possibile, riducendo la latenza nelle interfacce sia sincronizzate che asincrone.
- Configurazioni affidabili: configura tentativi e fallback per una maggiore affidabilità della catena su larga scala, con supporto dello streaming in fase di sviluppo.
- Streaming di risultati intermedi: accedi ai risultati intermedi durante l'elaborazione per aggiornamenti utente o scopi di debug.
- Generazione di schemi: LCEL genera schemi Pydantic e JSONSchema per la convalida di input e output.
- Tracciamento completo: LangSmith traccia automaticamente tutti i passaggi in catene complesse per l'osservabilità e il debug.
- Distribuzione semplice: distribuisci facilmente catene create da LCEL utilizzando LangServe.
Analizziamo ora esempi pratici di codice che dimostrano la potenza di LCEL. Esploreremo attività comuni e scenari in cui LCEL brilla.
Prompt + LLM
La composizione più fondamentale prevede la combinazione di un prompt e di un modello linguistico per creare una catena che accetta l'input dell'utente, lo aggiunge a un prompt, lo passa a un modello e restituisce l'output del modello non elaborato. Ecco un esempio:
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI prompt = ChatPromptTemplate.from_template("tell me a joke about {foo}")
model = ChatOpenAI()
chain = prompt | model result = chain.invoke({"foo": "bears"})
print(result)
In questo esempio, la catena genera una battuta sugli orsi.
Puoi allegare sequenze di interruzioni alla catena per controllare il modo in cui elabora il testo. Per esempio:
chain = prompt | model.bind(stop=["n"])
result = chain.invoke({"foo": "bears"})
print(result)
Questa configurazione interrompe la generazione del testo quando viene incontrato un carattere di nuova riga.
LCEL supporta l'aggiunta di informazioni sulla chiamata di funzione alla catena. Ecco un esempio:
functions = [ { "name": "joke", "description": "A joke", "parameters": { "type": "object", "properties": { "setup": {"type": "string", "description": "The setup for the joke"}, "punchline": { "type": "string", "description": "The punchline for the joke", }, }, "required": ["setup", "punchline"], }, }
]
chain = prompt | model.bind(function_call={"name": "joke"}, functions=functions)
result = chain.invoke({"foo": "bears"}, config={})
print(result)
Questo esempio allega informazioni sulla chiamata di funzione per generare una battuta.
Prompt + LLM + OutputParser
È possibile aggiungere un parser di output per trasformare l'output del modello non elaborato in un formato più praticabile. Ecco come puoi farlo:
from langchain.schema.output_parser import StrOutputParser chain = prompt | model | StrOutputParser()
result = chain.invoke({"foo": "bears"})
print(result)
L'output è ora in formato stringa, più comodo per le attività downstream.
Quando si specifica una funzione da restituire, è possibile analizzarla direttamente utilizzando LCEL. Per esempio:
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser chain = ( prompt | model.bind(function_call={"name": "joke"}, functions=functions) | JsonOutputFunctionsParser()
)
result = chain.invoke({"foo": "bears"})
print(result)
Questo esempio analizza direttamente l'output della funzione "joke".
Questi sono solo alcuni esempi di come LCEL semplifica le complesse attività di elaborazione del linguaggio. Che tu stia creando chatbot, generando contenuti o eseguendo trasformazioni di testo complesse, LCEL può semplificare il tuo flusso di lavoro e rendere il tuo codice più gestibile.
RAG (generazione aumentata di recupero)
LCEL può essere utilizzato per creare catene di generazione aumentata dal recupero, che combinano le fasi di recupero e generazione del linguaggio. Ecco un esempio:
from operator import itemgetter from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.vectorstores import FAISS # Create a vector store and retriever
vectorstore = FAISS.from_texts( ["harrison worked at kensho"], embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever() # Define templates for prompts
template = """Answer the question based only on the following context:
{context} Question: {question} """
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() # Create a retrieval-augmented generation chain
chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | model | StrOutputParser()
) result = chain.invoke("where did harrison work?")
print(result)
In questo esempio, la catena recupera informazioni rilevanti dal contesto e genera una risposta alla domanda.
Catena di recupero conversazionale
Puoi aggiungere facilmente la cronologia delle conversazioni alle tue catene. Ecco un esempio di catena di recupero conversazionale:
from langchain.schema.runnable import RunnableMap
from langchain.schema import format_document from langchain.prompts.prompt import PromptTemplate # Define templates for prompts
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language. Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template) template = """Answer the question based only on the following context:
{context} Question: {question} """
ANSWER_PROMPT = ChatPromptTemplate.from_template(template) # Define input map and context
_inputs = RunnableMap( standalone_question=RunnablePassthrough.assign( chat_history=lambda x: _format_chat_history(x["chat_history"]) ) | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
)
_context = { "context": itemgetter("standalone_question") | retriever | _combine_documents, "question": lambda x: x["standalone_question"],
}
conversational_qa_chain = _inputs | _context | ANSWER_PROMPT | ChatOpenAI() result = conversational_qa_chain.invoke( { "question": "where did harrison work?", "chat_history": [], }
)
print(result)
In questo esempio, la catena gestisce una domanda di follow-up all'interno di un contesto conversazionale.
Con memoria e restituzione di documenti di origine
LCEL supporta anche la memoria e la restituzione di documenti di origine. Ecco come è possibile utilizzare la memoria in una catena:
from operator import itemgetter
from langchain.memory import ConversationBufferMemory # Create a memory instance
memory = ConversationBufferMemory( return_messages=True, output_key="answer", input_key="question"
) # Define steps for the chain
loaded_memory = RunnablePassthrough.assign( chat_history=RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
) standalone_question = { "standalone_question": { "question": lambda x: x["question"], "chat_history": lambda x: _format_chat_history(x["chat_history"]), } | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
} retrieved_documents = { "docs": itemgetter("standalone_question") | retriever, "question": lambda x: x["standalone_question"],
} final_inputs = { "context": lambda x: _combine_documents(x["docs"]), "question": itemgetter("question"),
} answer = { "answer": final_inputs | ANSWER_PROMPT | ChatOpenAI(), "docs": itemgetter("docs"),
} # Create the final chain by combining the steps
final_chain = loaded_memory | standalone_question | retrieved_documents | answer inputs = {"question": "where did harrison work?"}
result = final_chain.invoke(inputs)
print(result)
In questo esempio, la memoria viene utilizzata per archiviare e recuperare la cronologia delle conversazioni e i documenti di origine.
Catene multiple
Puoi mettere insieme più catene usando Runnables. Ecco un esempio:
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser prompt1 = ChatPromptTemplate.from_template("what is the city {person} is from?")
prompt2 = ChatPromptTemplate.from_template( "what country is the city {city} in? respond in {language}"
) model = ChatOpenAI() chain1 = prompt1 | model | StrOutputParser() chain2 = ( {"city": chain1, "language": itemgetter("language")} | prompt2 | model | StrOutputParser()
) result = chain2.invoke({"person": "obama", "language": "spanish"})
print(result)
In questo esempio, due catene vengono combinate per generare informazioni su una città e il suo paese in una lingua specifica.
Ramificazione e fusione
LCEL ti consente di dividere e unire catene utilizzando RunnableMaps. Ecco un esempio di ramificazione e fusione:
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser planner = ( ChatPromptTemplate.from_template("Generate an argument about: {input}") | ChatOpenAI() | StrOutputParser() | {"base_response": RunnablePassthrough()}
) arguments_for = ( ChatPromptTemplate.from_template( "List the pros or positive aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
)
arguments_against = ( ChatPromptTemplate.from_template( "List the cons or negative aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
) final_responder = ( ChatPromptTemplate.from_messages( [ ("ai", "{original_response}"), ("human", "Pros:n{results_1}nnCons:n{results_2}"), ("system", "Generate a final response given the critique"), ] ) | ChatOpenAI() | StrOutputParser()
) chain = ( planner | { "results_1": arguments_for, "results_2": arguments_against, "original_response": itemgetter("base_response"), } | final_responder
) result = chain.invoke({"input": "scrum"})
print(result)
In questo esempio, viene utilizzata una catena di ramificazione e fusione per generare un argomento e valutarne i pro e i contro prima di generare una risposta finale.
Scrivere codice Python con LCEL
Una delle potenti applicazioni di LangChain Expression Language (LCEL) è scrivere codice Python per risolvere i problemi degli utenti. Di seguito è riportato un esempio di come utilizzare LCEL per scrivere codice Python:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain_experimental.utilities import PythonREPL template = """Write some python code to solve the user's problem. Return only python code in Markdown format, e.g.: ```python
....
```"""
prompt = ChatPromptTemplate.from_messages([("system", template), ("human", "{input}")]) model = ChatOpenAI() def _sanitize_output(text: str): _, after = text.split("```python") return after.split("```")[0] chain = prompt | model | StrOutputParser() | _sanitize_output | PythonREPL().run result = chain.invoke({"input": "what's 2 plus 2"})
print(result)
In questo esempio, un utente fornisce input e LCEL genera codice Python per risolvere il problema. Il codice viene quindi eseguito utilizzando un REPL Python e il codice Python risultante viene restituito in formato Markdown.
Tieni presente che l'utilizzo di un REPL Python può eseguire codice arbitrario, quindi usalo con cautela.
Aggiunta di memoria a una catena
La memoria è essenziale in molte applicazioni di intelligenza artificiale conversazionale. Ecco come aggiungere memoria a una catena arbitraria:
from operator import itemgetter
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder model = ChatOpenAI()
prompt = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful chatbot"), MessagesPlaceholder(variable_name="history"), ("human", "{input}"), ]
) memory = ConversationBufferMemory(return_messages=True) # Initialize memory
memory.load_memory_variables({}) chain = ( RunnablePassthrough.assign( history=RunnableLambda(memory.load_memory_variables) | itemgetter("history") ) | prompt | model
) inputs = {"input": "hi, I'm Bob"}
response = chain.invoke(inputs)
response # Save the conversation in memory
memory.save_context(inputs, {"output": response.content}) # Load memory to see the conversation history
memory.load_memory_variables({})
In questo esempio, la memoria viene utilizzata per archiviare e recuperare la cronologia delle conversazioni, consentendo al chatbot di mantenere il contesto e rispondere in modo appropriato.
Utilizzo di strumenti esterni con eseguibili
LCEL ti consente di integrare perfettamente strumenti esterni con Runnables. Ecco un esempio che utilizza lo strumento di ricerca DuckDuckGo:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.tools import DuckDuckGoSearchRun search = DuckDuckGoSearchRun() template = """Turn the following user input into a search query for a search engine: {input}"""
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() chain = prompt | model | StrOutputParser() | search search_result = chain.invoke({"input": "I'd like to figure out what games are tonight"})
print(search_result)
In questo esempio, LCEL integra lo strumento DuckDuckGo Search nella catena, consentendogli di generare una query di ricerca dall'input dell'utente e recuperare i risultati della ricerca.
La flessibilità di LCEL semplifica l'integrazione di vari strumenti e servizi esterni nelle pipeline di elaborazione linguistica, migliorandone le capacità e le funzionalità.
Aggiunta della moderazione a un'applicazione LLM
Per garantire che la tua applicazione LLM aderisca alle politiche sui contenuti e includa misure di salvaguardia della moderazione, puoi integrare i controlli di moderazione nella tua catena. Ecco come aggiungere la moderazione utilizzando LangChain:
from langchain.chains import OpenAIModerationChain
from langchain.llms import OpenAI
from langchain.prompts import ChatPromptTemplate moderate = OpenAIModerationChain() model = OpenAI()
prompt = ChatPromptTemplate.from_messages([("system", "repeat after me: {input}")]) chain = prompt | model # Original response without moderation
response_without_moderation = chain.invoke({"input": "you are stupid"})
print(response_without_moderation) moderated_chain = chain | moderate # Response after moderation
response_after_moderation = moderated_chain.invoke({"input": "you are stupid"})
print(response_after_moderation)
In questo esempio, il OpenAIModerationChain viene utilizzato per aggiungere moderazione alla risposta generata da LLM. La catena di moderazione controlla la risposta per i contenuti che violano la politica sui contenuti di OpenAI. Se vengono rilevate violazioni, contrassegnerà la risposta di conseguenza.
Routing per similarità semantica
LCEL consente di implementare una logica di routing personalizzata basata sulla somiglianza semantica dell'input dell'utente. Ecco un esempio di come determinare dinamicamente la logica della catena in base all'input dell'utente:
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.utils.math import cosine_similarity physics_template = """You are a very smart physics professor. You are great at answering questions about physics in a concise and easy to understand manner. When you don't know the answer to a question you admit that you don't know. Here is a question:
{query}""" math_template = """You are a very good mathematician. You are great at answering math questions. You are so good because you are able to break down hard problems into their component parts, answer the component parts, and then put them together to answer the broader question. Here is a question:
{query}""" embeddings = OpenAIEmbeddings()
prompt_templates = [physics_template, math_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates) def prompt_router(input): query_embedding = embeddings.embed_query(input["query"]) similarity = cosine_similarity([query_embedding], prompt_embeddings)[0] most_similar = prompt_templates[similarity.argmax()] print("Using MATH" if most_similar == math_template else "Using PHYSICS") return PromptTemplate.from_template(most_similar) chain = ( {"query": RunnablePassthrough()} | RunnableLambda(prompt_router) | ChatOpenAI() | StrOutputParser()
) print(chain.invoke({"query": "What's a black hole"}))
print(chain.invoke({"query": "What's a path integral"}))
In questo esempio, il prompt_router la funzione calcola la somiglianza del coseno tra l'input dell'utente e i modelli di prompt predefiniti per domande di fisica e matematica. In base al punteggio di somiglianza, la catena seleziona dinamicamente il modello di prompt più pertinente, garantendo che il chatbot risponda in modo appropriato alla domanda dell'utente.
Utilizzo di agenti ed eseguibili
LangChain ti consente di creare agenti combinando Runnable, prompt, modelli e strumenti. Ecco un esempio di creazione di un agente e utilizzo:
from langchain.agents import XMLAgent, tool, AgentExecutor
from langchain.chat_models import ChatAnthropic model = ChatAnthropic(model="claude-2") @tool
def search(query: str) -> str: """Search things about current events.""" return "32 degrees" tool_list = [search] # Get prompt to use
prompt = XMLAgent.get_default_prompt() # Logic for going from intermediate steps to a string to pass into the model
def convert_intermediate_steps(intermediate_steps): log = "" for action, observation in intermediate_steps: log += ( f"<tool>{action.tool}</tool><tool_input>{action.tool_input}" f"</tool_input><observation>{observation}</observation>" ) return log # Logic for converting tools to a string to go in the prompt
def convert_tools(tools): return "n".join([f"{tool.name}: {tool.description}" for tool in tools]) agent = ( { "question": lambda x: x["question"], "intermediate_steps": lambda x: convert_intermediate_steps( x["intermediate_steps"] ), } | prompt.partial(tools=convert_tools(tool_list)) | model.bind(stop=["</tool_input>", "</final_answer>"]) | XMLAgent.get_default_output_parser()
) agent_executor = AgentExecutor(agent=agent, tools=tool_list, verbose=True) result = agent_executor.invoke({"question": "What's the weather in New York?"})
print(result)
In questo esempio, un agente viene creato combinando un modello, strumenti, un prompt e una logica personalizzata per i passaggi intermedi e la conversione dello strumento. L'agente viene quindi eseguito, fornendo una risposta alla query dell'utente.
Interrogazione di un database SQL
È possibile utilizzare LangChain per interrogare un database SQL e generare query SQL in base alle domande degli utenti. Ecco un esempio:
from langchain.prompts import ChatPromptTemplate template = """Based on the table schema below, write a SQL query that would answer the user's question:
{schema} Question: {question}
SQL Query:"""
prompt = ChatPromptTemplate.from_template(template) from langchain.utilities import SQLDatabase # Initialize the database (you'll need the Chinook sample DB for this example)
db = SQLDatabase.from_uri("sqlite:///./Chinook.db") def get_schema(_): return db.get_table_info() def run_query(query): return db.run(query) from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough model = ChatOpenAI() sql_response = ( RunnablePassthrough.assign(schema=get_schema) | prompt | model.bind(stop=["nSQLResult:"]) | StrOutputParser()
) result = sql_response.invoke({"question": "How many employees are there?"})
print(result) template = """Based on the table schema below, question, SQL query, and SQL response, write a natural language response:
{schema} Question: {question}
SQL Query: {query}
SQL Response: {response}"""
prompt_response = ChatPromptTemplate.from_template(template) full_chain = ( RunnablePassthrough.assign(query=sql_response) | RunnablePassthrough.assign( schema=get_schema, response=lambda x: db.run(x["query"]), ) | prompt_response | model
) response = full_chain.invoke({"question": "How many employees are there?"})
print(response)
In questo esempio, LangChain viene utilizzato per generare query SQL basate sulle domande dell'utente e recuperare le risposte da un database SQL. Le richieste e le risposte sono formattate per fornire interazioni in linguaggio naturale con il database.
Automatizza le attività manuali e i flussi di lavoro con il nostro generatore di flussi di lavoro basato sull'intelligenza artificiale, progettato da Nanonets per te e i tuoi team.
LangServe e LangSmith
LangServe aiuta gli sviluppatori a distribuire eseguibili e catene LangChain come API REST. Questa libreria è integrata con FastAPI e utilizza pydantic per la convalida dei dati. Inoltre, fornisce un client che può essere utilizzato per richiamare i eseguibili distribuiti su un server e un client JavaScript è disponibile in LangChainJS.
Caratteristiche
- Gli schemi di input e output vengono automaticamente dedotti dal tuo oggetto LangChain e applicati a ogni chiamata API, con ricchi messaggi di errore.
- È disponibile una pagina di documentazione API con JSONSchema e Swagger.
- Endpoint /invoke, /batch e /stream efficienti con supporto per molte richieste simultanee su un singolo server.
- /stream_log endpoint per lo streaming di tutti (o alcuni) passaggi intermedi dalla catena/agente.
- Pagina Playground in /playground con output di streaming e passaggi intermedi.
- Tracciatura integrata (opzionale) su LangSmith; aggiungi semplicemente la tua chiave API (vedi Istruzioni).
- Il tutto costruito con librerie Python open source testate sul campo come FastAPI, Pydantic, uvloop e asyncio.
limitazioni
- Le richiamate del client non sono ancora supportate per gli eventi che hanno origine sul server.
- I documenti OpenAPI non verranno generati quando si utilizza Pydantic V2. FastAPI non supporta la combinazione di spazi dei nomi pydantic v1 e v2. Per maggiori dettagli vedere la sezione seguente.
Utilizza la CLI LangChain per avviare rapidamente un progetto LangServe. Per utilizzare la CLI langchain, assicurati di avere installata una versione recente di langchain-cli. Puoi installarlo con pip install -U langchain-cli.
langchain app new ../path/to/directory
Avvia rapidamente la tua istanza LangServe con LangChain Templates. Per ulteriori esempi, vedere l'indice dei modelli o la directory degli esempi.
Ecco un server che distribuisce un modello di chat OpenAI, un modello di chat antropico e una catena che utilizza il modello antropico per raccontare una barzelletta su un argomento.
#!/usr/bin/env python
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes app = FastAPI( title="LangChain Server", version="1.0", description="A simple api server using Langchain's Runnable interfaces",
) add_routes( app, ChatOpenAI(), path="/openai",
) add_routes( app, ChatAnthropic(), path="/anthropic",
) model = ChatAnthropic()
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
add_routes( app, prompt | model, path="/chain",
) if __name__ == "__main__": import uvicorn uvicorn.run(app, host="localhost", port=8000)
Dopo aver distribuito il server sopra, puoi visualizzare i documenti OpenAPI generati utilizzando:
curl localhost:8000/docs
Assicurati di aggiungere il suffisso /docs.
from langchain.schema import SystemMessage, HumanMessage
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableMap
from langserve import RemoteRunnable openai = RemoteRunnable("http://localhost:8000/openai/")
anthropic = RemoteRunnable("http://localhost:8000/anthropic/")
joke_chain = RemoteRunnable("http://localhost:8000/chain/") joke_chain.invoke({"topic": "parrots"}) # or async
await joke_chain.ainvoke({"topic": "parrots"}) prompt = [ SystemMessage(content='Act like either a cat or a parrot.'), HumanMessage(content='Hello!')
] # Supports astream
async for msg in anthropic.astream(prompt): print(msg, end="", flush=True) prompt = ChatPromptTemplate.from_messages( [("system", "Tell me a long story about {topic}")]
) # Can define custom chains
chain = prompt | RunnableMap({ "openai": openai, "anthropic": anthropic,
}) chain.batch([{ "topic": "parrots" }, { "topic": "cats" }])
In TypeScript (richiede LangChain.js versione 0.0.166 o successiva):
import { RemoteRunnable } from "langchain/runnables/remote"; const chain = new RemoteRunnable({ url: `http://localhost:8000/chain/invoke/`,
});
const result = await chain.invoke({ topic: "cats",
});
Python utilizzando le richieste:
import requests
response = requests.post( "http://localhost:8000/chain/invoke/", json={'input': {'topic': 'cats'}}
)
response.json()
Puoi anche usare l'arricciatura:
curl --location --request POST 'http://localhost:8000/chain/invoke/' --header 'Content-Type: application/json' --data-raw '{ "input": { "topic": "cats" } }'
Il seguente codice:
...
add_routes( app, runnable, path="/my_runnable",
)
aggiunge questi endpoint al server:
- POST /my_runnable/invoke – richiama l'eseguibile su un singolo input
- POST /my_runnable/batch – richiama il eseguibile su un batch di input
- POST /my_runnable/stream: richiama su un singolo input e trasmette in streaming l'output
- POST /my_runnable/stream_log: richiama un singolo input e trasmette in streaming l'output, incluso l'output dei passaggi intermedi man mano che viene generato
- GET /my_runnable/input_schema – schema json per l'input dell'eseguibile
- GET /my_runnable/output_schema – schema json per l'output dell'eseguibile
- GET /my_runnable/config_schema – schema json per la configurazione dell'eseguibile
Puoi trovare una pagina del parco giochi per il tuo eseguibile su /my_runnable/playground. Ciò espone una semplice interfaccia utente per configurare e richiamare il tuo eseguibile con output di streaming e passaggi intermedi.
Sia per client che per server:
pip install "langserve[all]"
oppure pip install “langserve[client]” per il codice client e pip install “langserve[server]” per il codice server.
Se devi aggiungere l'autenticazione al tuo server, fai riferimento alla documentazione sulla sicurezza e alla documentazione del middleware di FastAPI.
Puoi eseguire la distribuzione su GCP Cloud Run utilizzando il comando seguente:
gcloud run deploy [your-service-name] --source . --port 8001 --allow-unauthenticated --region us-central1 --set-env-vars=OPENAI_API_KEY=your_key
LangServe fornisce supporto per Pydantic 2 con alcune limitazioni. I documenti OpenAPI non verranno generati per invoke/batch/stream/stream_log quando si utilizza Pydantic V2. L'API veloce non supporta la combinazione di spazi dei nomi pydantic v1 e v2. LangChain utilizza lo spazio dei nomi v1 in Pydantic v2. Si prega di leggere le seguenti linee guida per garantire la compatibilità con LangChain. Fatta eccezione per queste limitazioni, prevediamo che gli endpoint API, il parco giochi e qualsiasi altra funzionalità funzionino come previsto.
Le applicazioni LLM spesso gestiscono file. Esistono diverse architetture che possono essere realizzate per implementare l'elaborazione dei file; ad alto livello:
- Il file può essere caricato sul server tramite un endpoint dedicato ed elaborato utilizzando un endpoint separato.
- Il file può essere caricato per valore (byte di file) o per riferimento (ad esempio, URL s3 per il contenuto del file).
- L'endpoint di elaborazione può essere bloccante o non bloccante.
- Se è necessaria un'elaborazione significativa, l'elaborazione può essere scaricata su un pool di processi dedicato.
Dovresti determinare qual è l'architettura appropriata per la tua applicazione. Attualmente, per caricare file in base al valore su un eseguibile, utilizzare la codifica base64 per il file (multipart/form-data non è ancora supportato).
Ecco uno esempio che mostra come utilizzare la codifica base64 per inviare un file a un eseguibile remoto. Ricorda, puoi sempre caricare i file per riferimento (ad esempio, URL s3) o caricarli come multipart/form-data su un endpoint dedicato.
I tipi di input e output sono definiti su tutti i eseguibili. È possibile accedervi tramite le proprietà input_schema e output_schema. LangServe utilizza questi tipi per la convalida e la documentazione. Se desideri sovrascrivere i tipi dedotti predefiniti, puoi utilizzare il metodo with_types.
Ecco un esempio di giocattolo per illustrare l'idea:
from typing import Any
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda app = FastAPI() def func(x: Any) -> int: """Mistyped function that should accept an int but accepts anything.""" return x + 1 runnable = RunnableLambda(func).with_types( input_schema=int,
) add_routes(app, runnable)
Eredita da CustomUserType se desideri che i dati vengano deserializzati in un modello pydantic anziché nella rappresentazione dict equivalente. Al momento, questo tipo funziona solo lato server e viene utilizzato per specificare il comportamento di decodifica desiderato. Se eredita da questo tipo, il server manterrà il tipo decodificato come modello pydantic invece di convertirlo in un dict.
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda
from langserve import add_routes
from langserve.schema import CustomUserType app = FastAPI() class Foo(CustomUserType): bar: int def func(foo: Foo) -> int: """Sample function that expects a Foo type which is a pydantic model""" assert isinstance(foo, Foo) return foo.bar add_routes(app, RunnableLambda(func), path="/foo")
Il parco giochi ti consente di definire widget personalizzati per il tuo eseguibile dal backend. Un widget viene specificato a livello di campo e fornito come parte dello schema JSON del tipo di input. Un widget deve contenere una chiave denominata type il cui valore sia uno di un elenco noto di widget. Altre chiavi widget saranno associate a valori che descrivono percorsi in un oggetto JSON.
Schema generale:
type JsonPath = number | string | (number | string)[];
type NameSpacedPath = { title: string; path: JsonPath }; // Using title to mimic json schema, but can use namespace
type OneOfPath = { oneOf: JsonPath[] }; type Widget = { type: string // Some well-known type (e.g., base64file, chat, etc.) [key: string]: JsonPath | NameSpacedPath | OneOfPath;
};
Consente la creazione di un input per il caricamento di file nel parco giochi dell'interfaccia utente per i file caricati come stringhe con codifica base64. Ecco l'esempio completo.
try: from pydantic.v1 import Field
except ImportError: from pydantic import Field from langserve import CustomUserType # ATTENTION: Inherit from CustomUserType instead of BaseModel otherwise
# the server will decode it into a dict instead of a pydantic model.
class FileProcessingRequest(CustomUserType): """Request including a base64 encoded file.""" # The extra field is used to specify a widget for the playground UI. file: str = Field(..., extra={"widget": {"type": "base64file"}}) num_chars: int = 100
Automatizza le attività manuali e i flussi di lavoro con il nostro generatore di flussi di lavoro basato sull'intelligenza artificiale, progettato da Nanonets per te e i tuoi team.
Introduzione a LangSmith
LangChain semplifica la prototipazione di applicazioni e agenti LLM. Tuttavia, fornire applicazioni LLM alla produzione può essere apparentemente difficile. Probabilmente dovrai personalizzare e iterare pesantemente i tuoi prompt, catene e altri componenti per creare un prodotto di alta qualità.
Per facilitare questo processo, è stata introdotta LangSmith, una piattaforma unificata per il debug, il test e il monitoraggio delle applicazioni LLM.
Quando potrebbe tornare utile? Potrebbe essere utile quando si desidera eseguire rapidamente il debug di una nuova catena, agente o set di strumenti, visualizzare come i componenti (catene, llm, retriever, ecc.) si correlano e vengono utilizzati, valutare diversi prompt e LLM per un singolo componente, eseguire una determinata catena più volte su un set di dati per garantire che soddisfi costantemente un livello di qualità oppure acquisire tracce di utilizzo e utilizzare LLM o pipeline di analisi per generare approfondimenti.
Prerequisiti:
- Crea un account LangSmith e crea una chiave API (vedi angolo in basso a sinistra).
- Acquisisci familiarità con la piattaforma esaminando la documentazione.
Ora cominciamo!
Innanzitutto, configura le variabili di ambiente per indicare a LangChain di registrare le tracce. Questo viene fatto impostando la variabile di ambiente LANGCHAIN_TRACING_V2 su true. Puoi indicare a LangChain a quale progetto accedere impostando la variabile di ambiente LANGCHAIN_PROJECT (se questa non è impostata, le esecuzioni verranno registrate nel progetto predefinito). Questo creerà automaticamente il progetto per te se non esiste. È inoltre necessario impostare le variabili di ambiente LANGCHAIN_ENDPOINT e LANGCHAIN_API_KEY.
NOTA: puoi anche utilizzare un gestore di contesto in Python per registrare le tracce utilizzando:
from langchain.callbacks.manager import tracing_v2_enabled with tracing_v2_enabled(project_name="My Project"): agent.run("How many people live in canada as of 2023?")
Tuttavia, in questo esempio utilizzeremo le variabili di ambiente.
%pip install openai tiktoken pandas duckduckgo-search --quiet import os
from uuid import uuid4 unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Walkthrough - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "<YOUR-API-KEY>" # Update to your API key # Used by the agent in this tutorial
os.environ["OPENAI_API_KEY"] = "<YOUR-OPENAI-API-KEY>"
Crea il client LangSmith per interagire con l'API:
from langsmith import Client client = Client()
Crea un componente LangChain e registra le esecuzioni sulla piattaforma. In questo esempio, creeremo un agente in stile ReAct con accesso a uno strumento di ricerca generale (DuckDuckGo). La richiesta dell'agente può essere visualizzata nell'Hub qui:
from langchain import hub
from langchain.agents import AgentExecutor
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.chat_models import ChatOpenAI
from langchain.tools import DuckDuckGoSearchResults
from langchain.tools.render import format_tool_to_openai_function # Fetches the latest version of this prompt
prompt = hub.pull("wfh/langsmith-agent-prompt:latest") llm = ChatOpenAI( model="gpt-3.5-turbo-16k", temperature=0,
) tools = [ DuckDuckGoSearchResults( name="duck_duck_go" ), # General internet search using DuckDuckGo
] llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools]) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
) agent_executor = AgentExecutor( agent=runnable_agent, tools=tools, handle_parsing_errors=True
)
Stiamo eseguendo l'agente contemporaneamente su più input per ridurre la latenza. Le esecuzioni vengono registrate su LangSmith in background, quindi la latenza di esecuzione non viene influenzata:
inputs = [ "What is LangChain?", "What's LangSmith?", "When was Llama-v2 released?", "What is the langsmith cookbook?", "When did langchain first announce the hub?",
] results = agent_executor.batch([{"input": x} for x in inputs], return_exceptions=True) results[:2]
Supponendo che tu abbia configurato correttamente il tuo ambiente, le tracce dell'agente dovrebbero essere visualizzate nella sezione Progetti dell'app. Congratulazioni!
Sembra però che l'agente non stia utilizzando gli strumenti in modo efficace. Valutiamolo in modo da avere una linea di base.
Oltre a registrare le esecuzioni, LangSmith ti consente anche di testare e valutare le tue applicazioni LLM.
In questa sezione utilizzerai LangSmith per creare un set di dati di riferimento ed eseguire valutatori assistiti dall'intelligenza artificiale su un agente. Lo farai in pochi passaggi:
- Crea un set di dati LangSmith:
Di seguito, utilizziamo il client LangSmith per creare un set di dati dalle domande di input dall'alto e un elenco di etichette. Li utilizzerai in seguito per misurare le prestazioni di un nuovo agente. Un set di dati è una raccolta di esempi, che non sono altro che coppie input-output che puoi utilizzare come casi di test per la tua applicazione:
outputs = [ "LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.", "LangSmith is a unified platform for debugging, testing, and monitoring language model applications and agents powered by LangChain", "July 18, 2023", "The langsmith cookbook is a github repository containing detailed examples of how to use LangSmith to debug, evaluate, and monitor large language model-powered applications.", "September 5, 2023",
] dataset_name = f"agent-qa-{unique_id}" dataset = client.create_dataset( dataset_name, description="An example dataset of questions over the LangSmith documentation.",
) for query, answer in zip(inputs, outputs): client.create_example( inputs={"input": query}, outputs={"output": answer}, dataset_id=dataset.id )
- Inizializza un nuovo agente da confrontare:
LangSmith ti consente di valutare qualsiasi LLM, catena, agente o anche una funzione personalizzata. Gli agenti conversazionali sono stateful (hanno memoria); per garantire che questo stato non sia condiviso tra le esecuzioni del set di dati, passeremo un chain_factory (
ovvero un costruttore) funzione da inizializzare per ogni chiamata:
# Since chains can be stateful (e.g. they can have memory), we provide
# a way to initialize a new chain for each row in the dataset. This is done
# by passing in a factory function that returns a new chain for each row.
def agent_factory(prompt): llm_with_tools = llm.bind( functions=[format_tool_to_openai_function(t) for t in tools] ) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser() ) return AgentExecutor(agent=runnable_agent, tools=tools, handle_parsing_errors=True)
- Configura valutazione:
Il confronto manuale dei risultati delle catene nell'interfaccia utente è efficace, ma può richiedere molto tempo. Può essere utile utilizzare metriche automatizzate e feedback assistito dall'intelligenza artificiale per valutare le prestazioni del tuo componente:
from langchain.evaluation import EvaluatorType
from langchain.smith import RunEvalConfig evaluation_config = RunEvalConfig( evaluators=[ EvaluatorType.QA, EvaluatorType.EMBEDDING_DISTANCE, RunEvalConfig.LabeledCriteria("helpfulness"), RunEvalConfig.LabeledScoreString( { "accuracy": """
Score 1: The answer is completely unrelated to the reference.
Score 3: The answer has minor relevance but does not align with the reference.
Score 5: The answer has moderate relevance but contains inaccuracies.
Score 7: The answer aligns with the reference but has minor errors or omissions.
Score 10: The answer is completely accurate and aligns perfectly with the reference.""" }, normalize_by=10, ), ], custom_evaluators=[],
)
- Esegui l'agente e i valutatori:
Utilizza la funzione run_on_dataset (o asincrona arun_on_dataset) per valutare il tuo modello. Questo sarà:
- Recupera righe di esempio dal set di dati specificato.
- Esegui il tuo agente (o qualsiasi funzione personalizzata) su ciascun esempio.
- Applicare i valutatori alle tracce di esecuzione risultanti e agli esempi di riferimento corrispondenti per generare feedback automatizzato.
I risultati saranno visibili nell'app LangSmith:
chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-5d466cbc-{unique_id}", tags=[ "testing-notebook", "prompt:5d466cbc", ],
)
Ora che abbiamo i risultati dei test, possiamo apportare modifiche al nostro agente e confrontarli. Proviamo di nuovo con un prompt diverso e vediamo i risultati:
candidate_prompt = hub.pull("wfh/langsmith-agent-prompt:39f3bbd0") chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=candidate_prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-39f3bbd0-{unique_id}", tags=[ "testing-notebook", "prompt:39f3bbd0", ],
)
LangSmith ti consente di esportare i dati in formati comuni come CSV o JSONL direttamente nell'app Web. È inoltre possibile utilizzare il client per recuperare esecuzioni per ulteriori analisi, per archiviarle nel proprio database o per condividerle con altri. Recuperiamo le tracce dell'esecuzione dall'esecuzione di valutazione:
runs = client.list_runs(project_name=chain_results["project_name"], execution_order=1) # After some time, these will be populated.
client.read_project(project_name=chain_results["project_name"]).feedback_stats
Questa era una guida rapida per iniziare, ma ci sono molti altri modi per utilizzare LangSmith per accelerare il flusso di sviluppo e produrre risultati migliori.
Per ulteriori informazioni su come ottenere il massimo da LangSmith, consulta la documentazione di LangSmith.
Sali di livello con i Nanonet
Sebbene LangChain sia uno strumento prezioso per integrare i modelli linguistici (LLM) con le tue applicazioni, potrebbe presentare limitazioni quando si tratta di casi d'uso aziendali. Esploriamo come Nanonets va oltre LangChain per affrontare queste sfide:
1. Connettività dati completa:
LangChain offre connettori, ma potrebbe non coprire tutte le app dello spazio di lavoro e i formati di dati su cui fanno affidamento le aziende. Nanonets fornisce connettori dati per oltre 100 app per spazi di lavoro ampiamente utilizzate, tra cui Slack, Notion, Google Suite, Salesforce, Zendesk e molte altre. Supporta inoltre tutti i tipi di dati non strutturati come PDF, TXT, immagini, file audio e file video, nonché tipi di dati strutturati come CSV, fogli di calcolo, MongoDB e database SQL.

2. Automazione delle attività per le app Workspace:
Sebbene la generazione di testo/risposta funzioni alla grande, le capacità di LangChain sono limitate quando si tratta di utilizzare il linguaggio naturale per eseguire attività in varie applicazioni. Nanonets offre agenti di attivazione/azione per le app dello spazio di lavoro più popolari, consentendoti di impostare flussi di lavoro in grado di ascoltare eventi ed eseguire azioni. Ad esempio, puoi automatizzare le risposte alle email, le voci CRM, le query SQL e altro ancora, il tutto tramite comandi in linguaggio naturale.
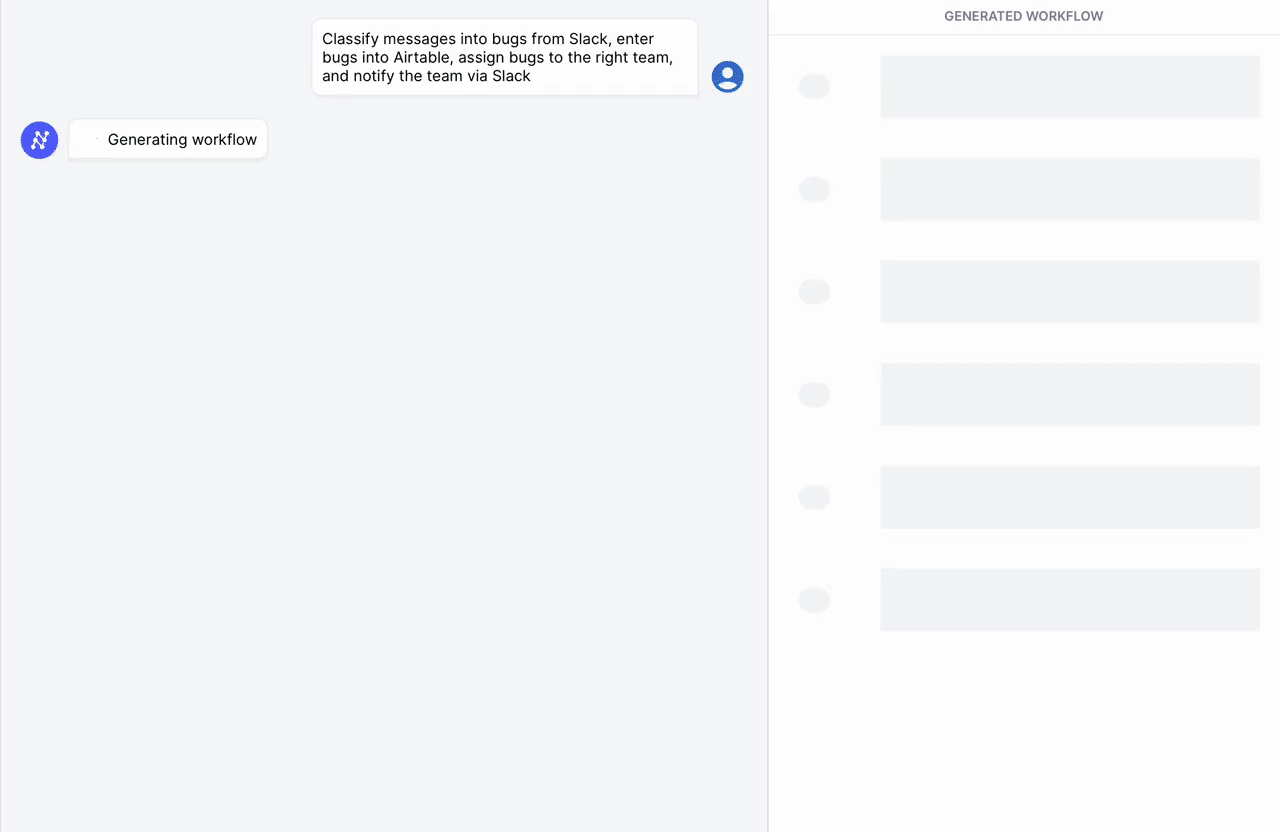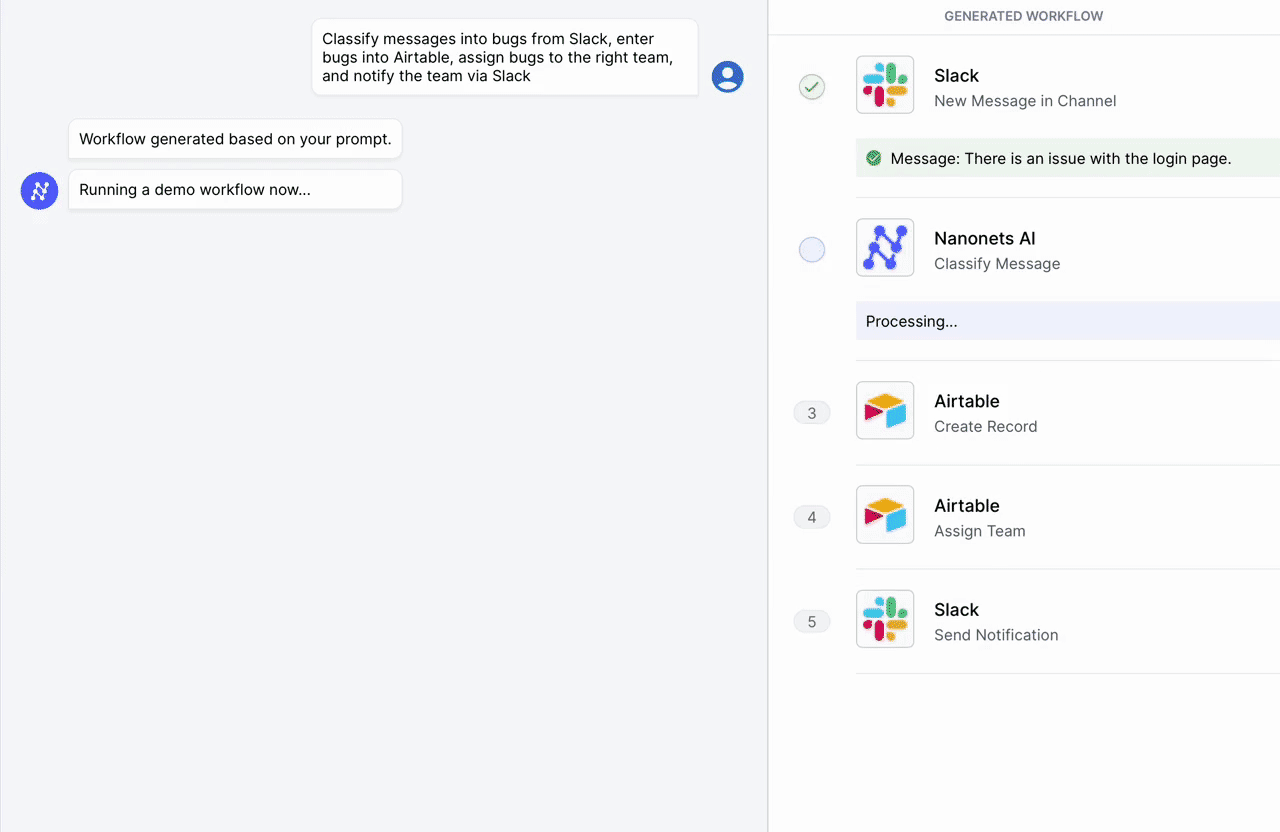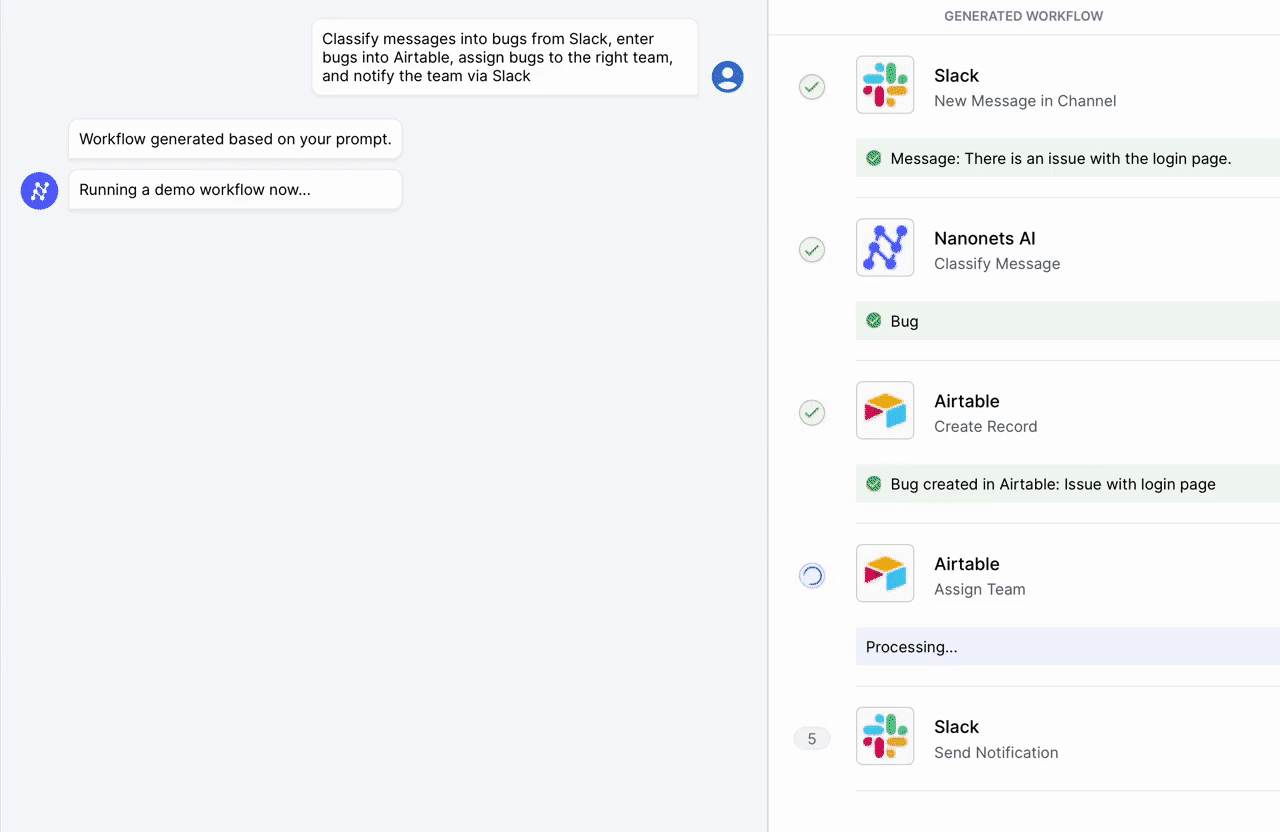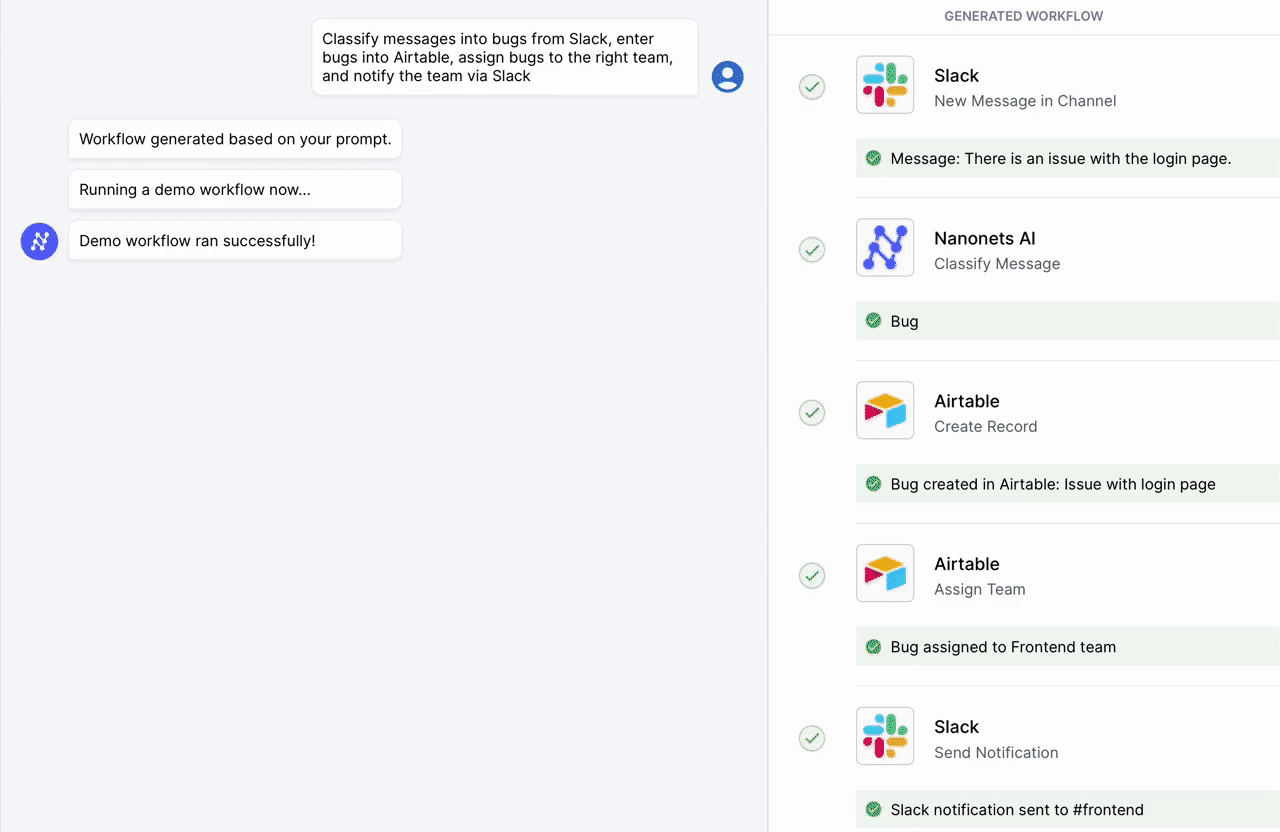
3. Sincronizzazione dei dati in tempo reale:
LangChain recupera i dati statici con connettori dati, che potrebbero non tenere il passo con le modifiche dei dati nel database di origine. Al contrario, Nanonets garantisce la sincronizzazione in tempo reale con le origini dati, garantendoti di lavorare sempre con le informazioni più recenti.

3. Configurazione semplificata:
La configurazione degli elementi della pipeline LangChain, come retriever e sintetizzatori, può essere un processo complesso e dispendioso in termini di tempo. Nanonets semplifica tutto ciò fornendo acquisizione e indicizzazione dei dati ottimizzate per ciascun tipo di dati, il tutto gestito in background dall'Assistente AI. Ciò riduce l'onere della messa a punto e semplifica la configurazione e l'utilizzo.
4. Soluzione unificata:
A differenza di LangChain, che può richiedere implementazioni uniche per ogni attività, Nanonets funge da soluzione unica per connettere i tuoi dati con LLM. Che tu abbia bisogno di creare applicazioni LLM o flussi di lavoro AI, Nanonets offre una piattaforma unificata per le tue diverse esigenze.
Flussi di lavoro AI Nanonet
Nanonets Workflows è un assistente AI sicuro e multiuso che semplifica l'integrazione delle tue conoscenze e dei tuoi dati con LLM e facilita la creazione di applicazioni e flussi di lavoro senza codice. Offre un'interfaccia utente facile da usare, rendendola accessibile sia agli individui che alle organizzazioni.
Per iniziare, puoi programmare una chiamata con uno dei nostri esperti di intelligenza artificiale, che può fornire una demo personalizzata e una prova dei flussi di lavoro Nanonets su misura per il tuo caso d'uso specifico.
Una volta configurato, puoi utilizzare il linguaggio naturale per progettare ed eseguire applicazioni e flussi di lavoro complessi basati su LLM, integrandosi perfettamente con le tue app e i tuoi dati.

Potenzia i tuoi team con l'intelligenza artificiale di Nanonets per creare app e integrare i tuoi dati con applicazioni e flussi di lavoro basati sull'intelligenza artificiale, consentendo ai tuoi team di concentrarsi su ciò che conta veramente.
Automatizza le attività manuali e i flussi di lavoro con il nostro generatore di flussi di lavoro basato sull'intelligenza artificiale, progettato da Nanonets per te e i tuoi team.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://nanonets.com/blog/langchain/

