Krones fornisce birrifici, imbottigliatori di bevande e produttori alimentari in tutto il mondo con macchine individuali e linee di produzione complete. Ogni giorno milioni di bottiglie di vetro, lattine e contenitori in PET attraversano una linea Krones. Le linee di produzione sono sistemi complessi con molti possibili errori che potrebbero bloccarla e diminuire la resa produttiva. Krones vuole individuare il guasto il prima possibile (a volte anche prima che si verifichi) e avvisare gli operatori della linea di produzione per aumentare l'affidabilità e la produttività. Quindi, come rilevare un guasto? Krones equipaggia le proprie linee con sensori per la raccolta dei dati, che possono poi essere valutati rispetto alle regole. Krones, in quanto produttore della linea, così come l'operatore della linea hanno la possibilità di creare regole di monitoraggio per le macchine. Pertanto, gli imbottigliatori di bevande e altri operatori possono definire il proprio margine di errore per la linea. In passato Krones utilizzava un sistema basato su una banca dati di serie temporali. Le sfide principali erano che questo sistema era difficile da eseguire il debug e inoltre le query rappresentavano lo stato attuale delle macchine ma non le transizioni di stato.
Questo post mostra come Krones ha costruito una soluzione di streaming per monitorare le proprie linee, basata su Cinesi amazzonica ed Servizio gestito da Amazon per Apache Flink. Questi servizi completamente gestiti riducono la complessità della creazione di applicazioni di streaming con Apache Flink. Managed Service per Apache Flink gestisce i componenti Apache Flink sottostanti che forniscono stato dell'applicazione, parametri, log e altro ancora durevoli, mentre Kinesis ti consente di elaborare in modo conveniente i dati in streaming su qualsiasi scala. Se vuoi iniziare con la tua applicazione Apache Flink, dai un'occhiata al Repository GitHub per gli esempi che utilizzano le API Java, Python o SQL di Flink.
Panoramica della soluzione
Il monitoraggio della linea di Krones fa parte di Guida Krones all'area di produzione sistema. Fornisce supporto nell'organizzazione, nella definizione delle priorità, nella gestione e nella documentazione di tutte le attività dell'azienda. Consente loro di avvisare un operatore se la macchina è ferma o se sono necessari materiali, indipendentemente da dove si trova l'operatore sulla linea. Le regole comprovate di monitoraggio delle condizioni sono già integrate ma possono anche essere definite dall'utente tramite l'interfaccia utente. Ad esempio, se un determinato punto dati monitorato viola una soglia, sulla linea può essere presente un messaggio di testo o un trigger per un ordine di manutenzione.
Il sistema di monitoraggio delle condizioni e di valutazione delle regole è basato su AWS, utilizzando i servizi di analisi AWS. Il diagramma seguente illustra l'architettura.
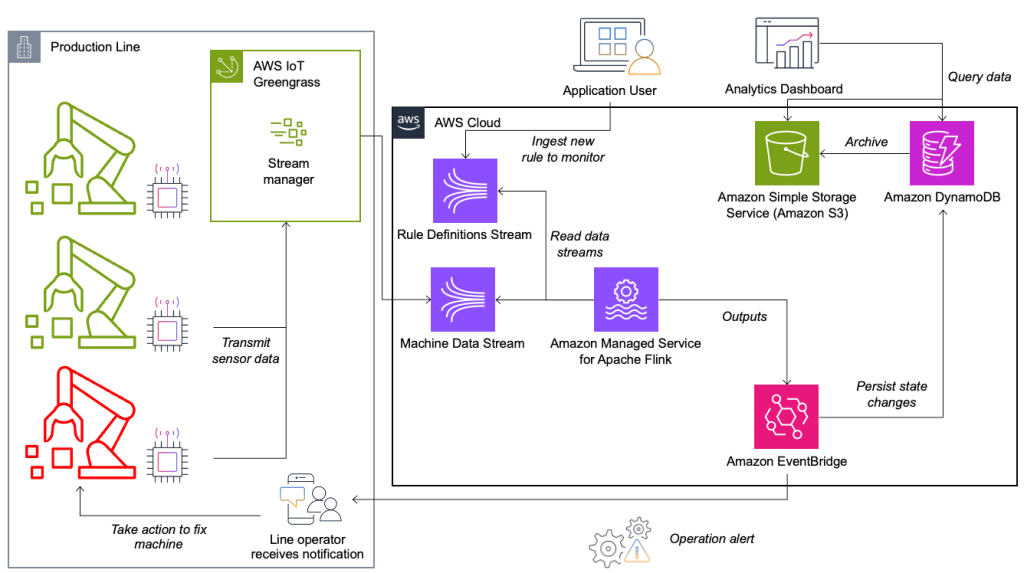
Quasi tutte le applicazioni di streaming di dati sono costituite da cinque livelli: origine dati, acquisizione del flusso, archiviazione del flusso, elaborazione del flusso e una o più destinazioni. Nelle sezioni seguenti approfondiremo ogni livello e spiegheremo come funziona in dettaglio la soluzione di monitoraggio della linea creata da Krones.
Fonte di dati
I dati vengono raccolti da un servizio in esecuzione su un dispositivo edge che legge diversi protocolli come Siemens S7 o OPC/UA. I dati grezzi vengono preelaborati per creare una struttura JSON unificata, che ne facilita l'elaborazione successiva nel motore delle regole. Un payload di esempio convertito in JSON potrebbe essere simile al seguente:
{
"version": 1,
"timestamp": 1234,
"equipmentId": "84068f2f-3f39-4b9c-a995-d2a84d878689",
"tag": "water_temperature",
"value": 13.45,
"quality": "Ok",
"meta": {
"sequenceNumber": 123,
"flags": ["Fst", "Lst", "Wmk", "Syn", "Ats"],
"createdAt": 12345690,
"sourceId": "filling_machine"
}
}Inserimento del flusso
AWS IoT Greengrass è un servizio cloud e runtime edge Internet of Things (IoT) open source. Ciò consente di agire sui dati localmente e di aggregare e filtrare i dati del dispositivo. AWS IoT Greengrass fornisce componenti predefiniti che possono essere distribuiti all'edge. La soluzione della linea di produzione utilizza il componente stream manager, che può elaborare i dati e trasferirli a destinazioni AWS come Analisi AWS IoT, Servizio di archiviazione semplice Amazon (Amazon S3) e Kinesis. Il gestore del flusso memorizza nel buffer e aggrega i record, quindi li invia a un flusso di dati Kinesis.
Archiviazione in streaming
Il compito dello stream storage è quello di bufferizzare i messaggi con tolleranza agli errori e renderli disponibili per l'utilizzo in una o più applicazioni consumer. Per raggiungere questo obiettivo su AWS, le tecnologie più comuni sono Kinesis e Streaming gestito da Amazon per Apache Kafka (AmazonMSK). Per memorizzare i dati dei nostri sensori dalle linee di produzione, Krones sceglie Kinesis. Kinesis è un servizio dati in streaming serverless che funziona su qualsiasi scala con bassa latenza. Gli shard all'interno di un flusso di dati Kinesis sono una sequenza di record di dati identificata in modo univoco, in cui un flusso è composto da uno o più shard. Ogni frammento ha 2 MB/s di capacità di lettura e 1 MB/s di capacità di scrittura (con un massimo di 1,000 record/s). Per evitare di raggiungere tali limiti, i dati dovrebbero essere distribuiti tra gli shard nel modo più uniforme possibile. Ogni record inviato a Kinesis dispone di una chiave di partizione, utilizzata per raggruppare i dati in uno shard. Pertanto, è necessario disporre di un numero elevato di chiavi di partizione per distribuire il carico in modo uniforme. Il gestore del flusso in esecuzione su AWS IoT Greengrass supporta assegnazioni di chiavi di partizione casuali, il che significa che tutti i record finiscono in uno shard casuale e il carico viene distribuito uniformemente. Uno svantaggio delle assegnazioni casuali delle chiavi di partizione è che i record non vengono archiviati in ordine in Kinesis. Spieghiamo come risolvere questo problema nella sezione successiva, dove parliamo di filigrane.
Filigrane
A filigrana è un meccanismo utilizzato per tracciare e misurare l'avanzamento del tempo dell'evento in un flusso di dati. L'ora dell'evento è il timestamp da quando l'evento è stato creato all'origine. La filigrana indica l'avanzamento tempestivo dell'applicazione di elaborazione del flusso, quindi tutti gli eventi con un timestamp precedente o uguale vengono considerati elaborati. Queste informazioni sono essenziali affinché Flink possa anticipare il tempo dell'evento e attivare calcoli rilevanti, come le valutazioni delle finestre. Il ritardo consentito tra l'ora dell'evento e la filigrana può essere configurato per determinare quanto tempo attendere i dati tardivi prima di considerare una finestra completa e far avanzare la filigrana.
Krones dispone di sistemi in tutto il mondo e doveva gestire gli arrivi in ritardo a causa di perdite di connessione o altri vincoli di rete. Hanno iniziato monitorando gli arrivi in ritardo e impostando la gestione dei ritardi Flink predefinita sul valore massimo riscontrato in questa metrica. Hanno riscontrato problemi con la sincronizzazione dell'ora dai dispositivi periferici, che li hanno portati a adottare modalità di watermarking più sofisticate. Hanno creato una filigrana globale per tutti i mittenti e hanno utilizzato il valore più basso come filigrana. I timestamp vengono archiviati in una HashMap per tutti gli eventi in arrivo. Quando le filigrane vengono emesse periodicamente, viene utilizzato il valore più piccolo di questa HashMap. Per evitare il blocco delle filigrane a causa della mancanza di dati, hanno configurato un file idleTimeOut parametro, che ignora i timestamp precedenti a una determinata soglia. Ciò aumenta la latenza ma garantisce una forte coerenza dei dati.
public class BucketWatermarkGenerator implements WatermarkGenerator<DataPointEvent> {
private HashMap <String, WatermarkAndTimestamp> lastTimestamps;
private Long idleTimeOut;
private long maxOutOfOrderness;
}
Elaborazione del flusso
Dopo che i dati sono stati raccolti dai sensori e inseriti in Kinesis, devono essere valutati da un motore di regole. Una regola in questo sistema rappresenta lo stato di una singola metrica (come la temperatura) o di una raccolta di metriche. Per interpretare una metrica, viene utilizzato più di un punto dati, che è un calcolo con stato. In questa sezione, approfondiamo lo stato con chiave e lo stato di trasmissione in Apache Flink e il modo in cui vengono utilizzati per creare il motore di regole Krones.
Controlla il flusso e il modello dello stato di trasmissione
In Apache Flink, stato si riferisce alla capacità del sistema di archiviare e gestire le informazioni in modo persistente nel tempo e nelle operazioni, consentendo l'elaborazione di dati in streaming con il supporto per calcoli con stato.
I modello di stato di trasmissione consente la distribuzione di uno stato a tutte le istanze parallele di un operatore. Pertanto, tutti gli operatori hanno lo stesso stato e i dati possono essere elaborati utilizzando questo stesso stato. Questi dati di sola lettura possono essere inseriti utilizzando un flusso di controllo. Un flusso di controllo è un flusso di dati regolare, ma solitamente con una velocità dati molto inferiore. Questo modello consente di aggiornare dinamicamente lo stato su tutti gli operatori, consentendo all'utente di modificare lo stato e il comportamento dell'applicazione senza la necessità di una ridistribuzione. Più precisamente, la distribuzione dello stato avviene mediante l'utilizzo di un flusso di controllo. Aggiungendo un nuovo record nel flusso di controllo, tutti gli operatori ricevono questo aggiornamento e utilizzano il nuovo stato per l'elaborazione dei nuovi messaggi.
Ciò consente agli utenti dell'applicazione Krones di inserire nuove regole nell'applicazione Flink senza riavviarla. Ciò evita tempi di inattività e offre un'ottima esperienza utente poiché le modifiche avvengono in tempo reale. Una regola copre uno scenario per rilevare una deviazione del processo. A volte i dati della macchina non sono così facili da interpretare come potrebbe sembrare a prima vista. Se un sensore di temperatura invia valori elevati, ciò potrebbe indicare un errore, ma anche essere l'effetto di una procedura di manutenzione in corso. È importante contestualizzare le metriche e filtrare alcuni valori. Ciò è ottenuto da un concetto chiamato raggruppamento.
Raggruppamento di metriche
Il raggruppamento di dati e metriche consente di definire la pertinenza dei dati in ingresso e produrre risultati accurati. Esaminiamo l'esempio nella figura seguente.
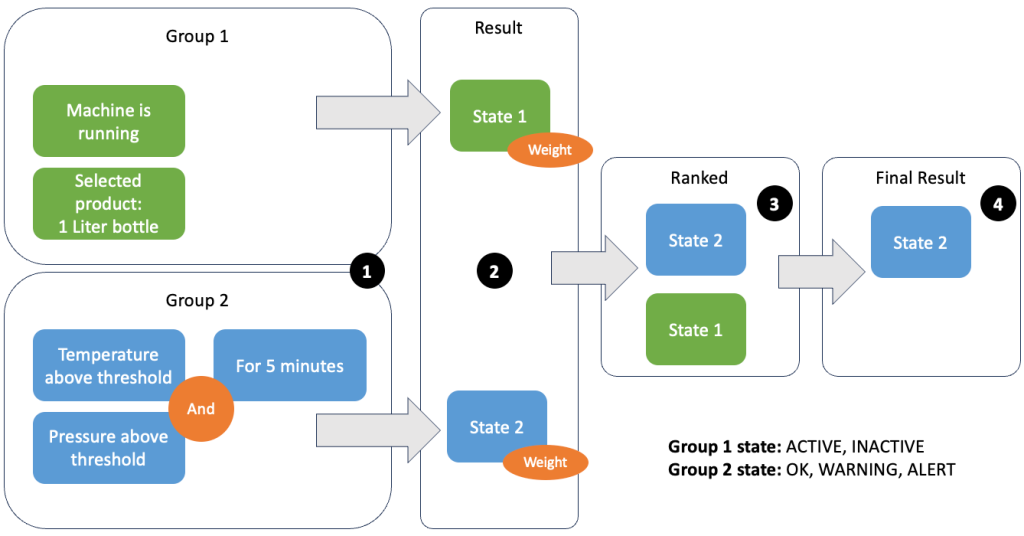
Nel passaggio 1 definiamo due gruppi di condizioni. Il gruppo 1 raccoglie lo stato della macchina e quale prodotto sta attraversando la linea. Il gruppo 2 utilizza il valore dei sensori di temperatura e pressione. Un gruppo di condizioni può avere stati diversi a seconda dei valori che riceve. In questo esempio, il gruppo 1 riceve i dati che la macchina è in funzione e come prodotto viene selezionata la bottiglia da un litro; questo dà a questo gruppo lo stato ACTIVE. Il Gruppo 2 ha parametri per temperatura e pressione; entrambi i parametri sono al di sopra delle rispettive soglie per più di 5 minuti. Ciò fa sì che il gruppo 2 sia in a WARNING stato. Ciò significa che il gruppo 1 riferisce che tutto va bene e il gruppo 2 no. Nel passaggio 2 i pesi vengono aggiunti ai gruppi. Ciò è necessario in alcune situazioni perché i gruppi potrebbero riportare informazioni contrastanti. In questo scenario, il gruppo 1 riporta ACTIVE e rapporti del gruppo 2 WARNING, quindi non è chiaro al sistema quale sia lo stato della linea. Dopo aver aggiunto i pesi, gli stati possono essere classificati, come mostrato nel passaggio 3. Infine, lo stato con il punteggio più alto viene scelto come vincitore, come mostrato nel passaggio 4.
Dopo aver valutato le regole e definito lo stato finale della macchina, i risultati verranno ulteriormente elaborati. L'azione intrapresa dipende dalla configurazione della regola; può trattarsi di una notifica all'operatore di linea per rifornire i materiali, eseguire qualche manutenzione o semplicemente un aggiornamento visivo sul dashboard. Questa parte del sistema, che valuta metriche e regole e intraprende azioni in base ai risultati, viene definita a motore di regole.
Ridimensionamento del motore delle regole
Consentendo agli utenti di creare le proprie regole, il motore delle regole può avere un numero elevato di regole da valutare e alcune regole potrebbero utilizzare gli stessi dati dei sensori di altre regole. Flink è un sistema distribuito che si adatta molto bene in senso orizzontale. Per distribuire un flusso di dati a diverse attività, puoi utilizzare il file keyBy() metodo. Ciò consente di partizionare un flusso di dati in modo logico e inviare parti dei dati a diversi task manager. Questo viene spesso fatto scegliendo una chiave arbitraria in modo da ottenere un carico distribuito uniformemente. In questo caso Krones ha aggiunto a ruleId al punto dati e lo ha utilizzato come chiave. In caso contrario, i punti dati necessari verranno elaborati da un'altra attività. Il flusso di dati con chiave può essere utilizzato in tutte le regole proprio come una normale variabile.
Destinazioni
Quando una regola cambia il suo stato, le informazioni vengono inviate a un flusso Kinesis e quindi tramite Amazon EventBridge ai consumatori. Uno dei consumatori crea una notifica dell'evento che viene trasmessa alla linea di produzione e avvisa il personale di agire. Per poter analizzare le modifiche dello stato della regola, un altro servizio scrive i dati su un file Amazon DynamoDB tabella per un accesso rapido ed è disponibile un TTL per scaricare la cronologia a lungo termine su Amazon S3 per ulteriori report.
Conclusione
In questo post ti abbiamo mostrato come Krones ha realizzato un sistema di monitoraggio della linea di produzione in tempo reale su AWS. Il servizio gestito per Apache Flink ha consentito al team Krones di iniziare rapidamente concentrandosi sullo sviluppo delle applicazioni piuttosto che sull'infrastruttura. Le funzionalità in tempo reale di Flink hanno consentito a Krones di ridurre i tempi di fermo macchina del 10% e di aumentare l'efficienza fino al 5%.
Se desideri creare le tue applicazioni di streaming, controlla gli esempi disponibili su Repository GitHub. Se desideri estendere la tua applicazione Flink con connettori personalizzati, consulta Semplificare la creazione di connettori con Apache Flink: presentazione di Async Sink. Il sink Async è disponibile in Apache Flink versione 1.15.1 e successive.
Informazioni sugli autori
 Florian Mair è un Senior Solutions Architect ed esperto di streaming di dati presso AWS. È un esperto di tecnologia che aiuta i clienti in Europa ad avere successo e a innovare risolvendo le sfide aziendali utilizzando i servizi cloud AWS. Oltre a lavorare come Solutions Architect, Florian è un appassionato alpinista e ha scalato alcune delle montagne più alte d'Europa.
Florian Mair è un Senior Solutions Architect ed esperto di streaming di dati presso AWS. È un esperto di tecnologia che aiuta i clienti in Europa ad avere successo e a innovare risolvendo le sfide aziendali utilizzando i servizi cloud AWS. Oltre a lavorare come Solutions Architect, Florian è un appassionato alpinista e ha scalato alcune delle montagne più alte d'Europa.
 Emil Dietl è un Senior Tech Lead presso Krones specializzato in ingegneria dei dati, con un campo chiave in Apache Flink e microservizi. Il suo lavoro spesso prevede lo sviluppo e la manutenzione di software mission-critical. Al di fuori della sua vita professionale, apprezza profondamente trascorrere del tempo di qualità con la sua famiglia.
Emil Dietl è un Senior Tech Lead presso Krones specializzato in ingegneria dei dati, con un campo chiave in Apache Flink e microservizi. Il suo lavoro spesso prevede lo sviluppo e la manutenzione di software mission-critical. Al di fuori della sua vita professionale, apprezza profondamente trascorrere del tempo di qualità con la sua famiglia.
 Simone Peyer è un Solutions Architect presso AWS con sede in Svizzera. È una persona pratica ed è appassionato di connettere tecnologia e persone che utilizzano i servizi cloud AWS. Un focus speciale per lui è lo streaming di dati e le automazioni. Oltre al lavoro, a Simon piace la famiglia, la vita all'aria aperta e le escursioni in montagna.
Simone Peyer è un Solutions Architect presso AWS con sede in Svizzera. È una persona pratica ed è appassionato di connettere tecnologia e persone che utilizzano i servizi cloud AWS. Un focus speciale per lui è lo streaming di dati e le automazioni. Oltre al lavoro, a Simon piace la famiglia, la vita all'aria aperta e le escursioni in montagna.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/krones-real-time-production-line-monitoring-with-amazon-managed-service-for-apache-flink/

