Introduzione
I dati sono carburante per il settore IT e per i... Progetto di scienza dei dati nel mondo online di oggi. Le industrie IT fanno molto affidamento sugli insight in tempo reale derivati da dati in streaming fonti. La gestione e l'elaborazione dei dati in streaming è il lavoro più difficile Analisi dei dati. Sappiamo che i dati in streaming sono dati emessi ad alto volume in un'elaborazione continua, il che significa che i dati cambiano ogni secondo. Per gestire questi dati che stiamo utilizzando Piattaforma confluente – Una distribuzione autogestita di livello aziendale Apache Kafka.
Kafka è un errore distribuito che può essere gestito dall'architettura, che funge da scelta popolare per la gestione di flussi di dati ad alto rendimento. I dati quindi di Kafka vengono raccolti nel file MongoDB sotto forma di collezioni. In questo articolo, creeremo la pipeline end-to-end in cui i dati vengono recuperati con l'aiuto dell'API nella pipeline e quindi raccolti in Kafka sotto forma di argomenti e quindi archiviati in MongoDB da lì possiamo usarli nel progetto o eseguire l'ingegneria delle funzionalità.
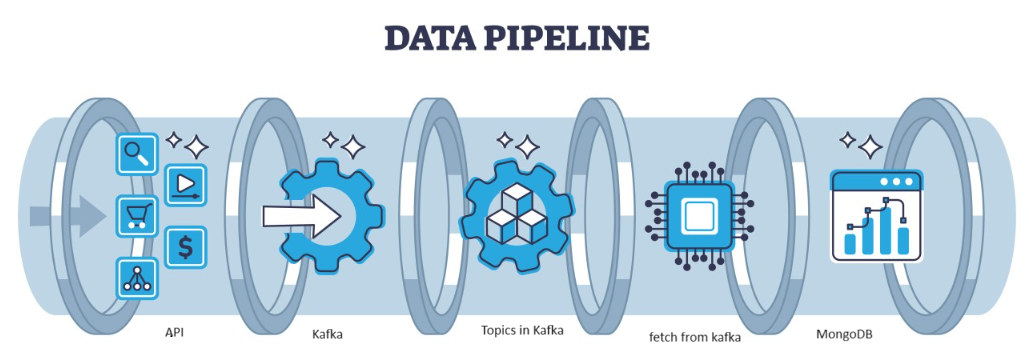
obiettivi formativi
- Scopri cosa sono i dati in streaming e come gestire i dati in streaming con l'aiuto di Kafka.
- Comprendere la piattaforma Confluent: una distribuzione autogestita di livello aziendale di Apache Kafka.
- Archivia i dati raccolti da Kafka nel MongoDB che è un database NoSQL che archivia i dati non strutturati.
- Crea una pipeline completamente end-to-end per recuperare e archiviare i dati nel database.
Questo articolo è stato pubblicato come parte di Blogathon sulla scienza dei dati.
Sommario
Identifica il problema
Per gestire i dati in streaming provenienti dal sensore, i veicoli che contengono i dati del sensore vengono prodotti al secondo ed è difficile gestire e preelaborare i dati da utilizzare nel Progetto di scienza dei dati. Quindi, per risolvere questo problema stiamo creando la pipeline end-to-end che gestisce i dati e li archivia.
Cos'è lo streaming di dati?
Dati in streaming sono dati generati continuamente da diverse fonti che sono dati non strutturati. Si riferisce a un flusso continuo di dati generati da diverse fonti in tempo reale o quasi in tempo reale. Nell'elaborazione batch tradizionale in cui i dati vengono raccolti e questi dati in streaming vengono elaborati non appena vengono generati. I dati in streaming possono essere dati IOT come sensori di temperatura e localizzatori GPS, o dati macchina. Come dati generati da macchine e apparecchiature industriali come dati di telemetria provenienti da veicoli e macchinari di produzione. Esistono piattaforme di elaborazione dati in streaming come Apache-Kafka.
Cos'è Kafka?
Apache Kafka è una piattaforma utilizzata per creare pipeline di dati in tempo reale e applicazioni di streaming. L'API Kafka Streams è una potente libreria che consente l'elaborazione al volo, consentendoti di raccogliere e creare parametri di finestra, eseguire unioni di dati all'interno di un flusso e altro ancora. Apache Kafka è costituito da un livello di archiviazione e un livello di elaborazione che combina l'acquisizione efficiente dei dati in tempo reale, lo streaming di pipeline di dati e l'archiviazione tra i sistemi.
Quale sarà l'approccio?
Si tratta di una pipeline di machine learning che ci aiuta a sapere come pubblicare ed elaborare i dati da e verso Kafka Confluent in formato JSON. Ci sono due parti del consumatore e del produttore dell'elaborazione dei dati Kafka. Per archiviare i dati in streaming dai diversi produttori e archiviarli in confluente, quindi viene eseguita la deserializzazione sui dati e tali dati vengono archiviati nel database.
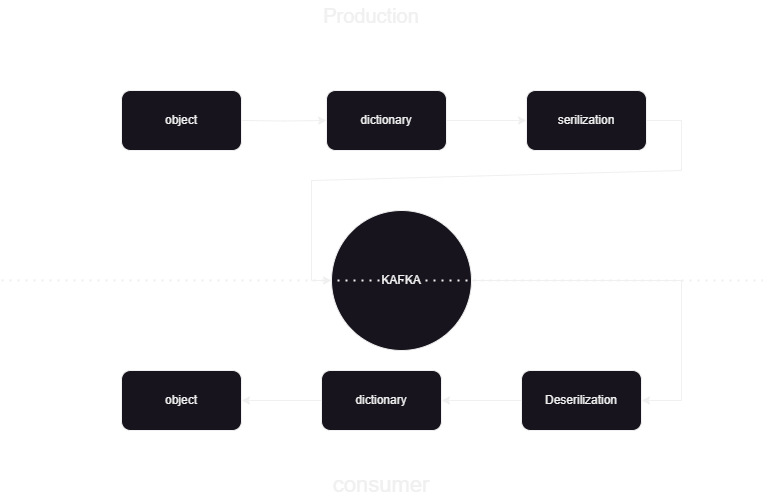
Panoramica dell'architettura del sistema
Stiamo elaborando i dati in streaming con l'aiuto di Kafka confluente e Kafka è diviso in due parti:
- Produttore Kafka: il produttore Kafka è responsabile della produzione e dell'invio di dati agli argomenti Kafka.
- Kafka Consumer: Kafka Consumer consiste nel leggere ed elaborare i dati dagli argomenti Kafka.
Start
│
├─ Kafka Consumer (Read from Kafka Topic)
│ ├─ Process Message
│ └─ Store Data in MongoDB
│
├─ Kafka Producer (Generate Sensor Data)
│ ├─ Send Data to Kafka Topic
│ └─ Repeat
│
End
Cosa sono i componenti?
- Temi: Gli argomenti sono canali o categorie logici pubblicati dai produttori. Ogni argomento è diviso in una o più partizioni e ogni argomento viene replicato su più broker per la tolleranza agli errori. I produttori pubblicano dati su argomenti specifici e i consumatori si iscrivono ad argomenti per utilizzare i dati.
- Produttori: Un Apache Kafka Producer è un'applicazione client che pubblica (scrive) eventi in un cluster Kafka. Le applicazioni che inviano dati agli argomenti sono note come produttori Kafka. Questa sezione offre una panoramica del produttore Kafka.
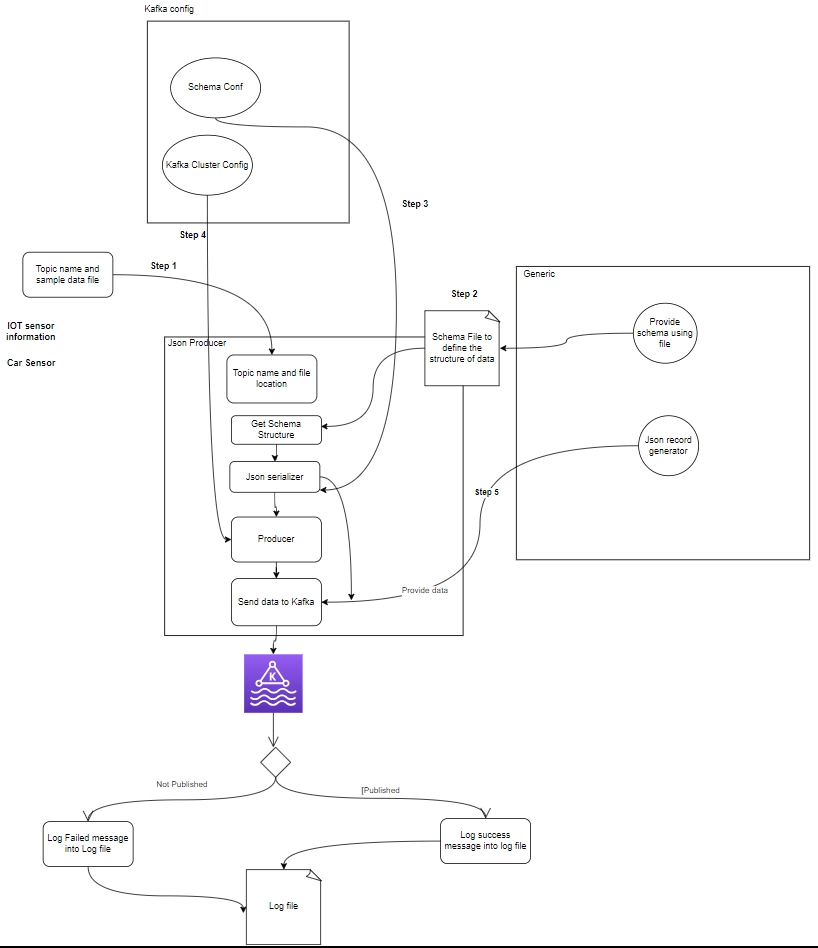
- Consumatore: I consumatori Kafka sono responsabili della lettura e dell'elaborazione dei dati dagli argomenti Kafka e della loro elaborazione. I consumatori possono far parte di qualsiasi applicazione che debba utilizzare e reagire ai dati di Kafka. Si iscrivono a uno o più argomenti e dati dai broker Kafka. I consumatori possono essere organizzati in gruppi di consumatori, in cui ciascun gruppo di consumatori ha uno o più consumatori e ciascun argomento di un argomento viene consumato da un solo consumatore all'interno del gruppo. Ciò consente l'elaborazione parallela e il bilanciamento del carico del consumo di dati.
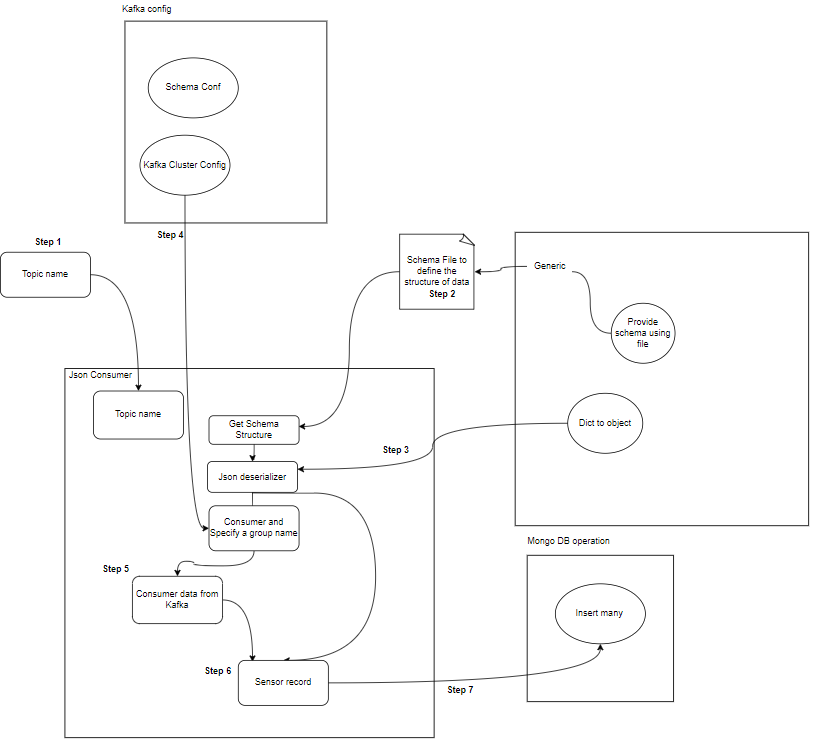
Qual è la struttura del progetto?
Questo mostra il diagramma di flusso del progetto come la cartella e i file sono divisi nel progetto:
flowchart/
│
├── consumer.drawio.svg
├── flow of kafka.drawio
└── producer.drawio.svg
sample_data/
│
└── aps_failure_training_set1.csv
env/
sensor_data-pipeline_kafka
/
│
├── src/
│ ├── database/
│ │ ├── mongodb.py
│ │
│ ├── kafka_config/
│ │ └──__init__.py/
│ │
│ │
│ ├── constant/
│ │ ├── __init__.py
│ │
│ │
│ ├── data_access/
│ │ ├── user_data.py
│ │ └── user_embedding_data.py
│ │
│ ├── entity/
│ │ ├── __init__.py
│ │ └── generic.py
│ │
│ ├── exception/
│ │ └── (exception handling)
│ │
│ ├── kafka_logger/
│ │ └── (logging configuration)
│ │
│ ├── kafka_consumer/
│ │ └── util.py
│ │
│ └── __init__.py
│
└── logs/
└── (log files)
.dockerignore
.gitignore
Dockerfile
schema.json
consumer_main.py
producer_main.py
requirments.txt
setup.py- Produttore Kafka: Il produttore è la parte principale che genera i dati del sensore (ad esempio, dai file CSV in sample_data/) e li pubblica in un argomento Kafka. condizioni di errore che possono verificarsi durante la generazione o la pubblicazione dei dati.
- Broker Kafka: I broker Kafka archiviano e replicano i dati nel cluster Kafka, gestiscono il partizionamento dei dati e garantiscono tolleranza agli errori e disponibilità elevata.
- Consumatore/i Kafka: I consumatori leggono i dati dagli argomenti Kafka, li elaborano (ad esempio trasformazioni, aggregazioni) e li archiviano in MongoDB. Monitorano inoltre le condizioni di errore che possono verificarsi durante l'elaborazione dei dati.
- MongoDB: MongoDB memorizza i dati dei sensori ricevuti dai consumatori Kafka. Fornisce una query per il recupero dei dati e garantisce la durabilità dei dati attraverso meccanismi di replica e tolleranza agli errori.
Start
│
├── Kafka Producer ──────────────────┐
│ ├── Generate Sensor Data │
│ └── Publish Data to Kafka Topic │
│ │
│ └── Error Handling
│ │
├── Kafka Broker(s) ─────────────────┤
│ ├── Store and Replicate Data │
│ └── Handle Data Partitioning │
│ │
├── Kafka Consumer(s) ───────────────┤
│ ├── Read Data from Kafka Topic │
│ ├── Process Data │
│ └── Store Data in MongoDB │
│ │
│ └── Error Handling
│ │
├── MongoDB ────────────────────────┤
│ ├── Store Sensor Data │
│ ├── Provide Query Interface │
│ └── Ensure Data Durability │
│ │
└── End │
Prerequisiti per la memorizzazione dei dati
Kafka confluente
- Crea un account: per capire Kafka serve Confluent. Ami Apache Kafka®, ma non lo gestisci. Il servizio cloud-native, completo e completamente gestito va ben oltre Kafka, consentendo ai tuoi collaboratori migliori di concentrarsi sulla creazione di valore per la tua azienda.
- Crea argomenti:
- Vai alla Home page e sulla barra laterale
- Vai su Ambiente quindi fai clic su Predefinito
- Vai agli argomenti

- selezionare il Nuovo argomento e dare il nome dell'argomento

MongoDB
Crea la registrazione, quindi accedi all'Atlante MongoDB e salva il collegamento di connessione dell'Atlante MongoDB per un ulteriore utilizzo.
Guida passo passo per l'impostazione del progetto
- Installazione di Python: assicurati che Python sia installato sul tuo computer. È possibile scaricare e installare Python dal sito ufficiale.
- Versione Conda: controlla la versione di Conda nel terminale.
- Creazione dell'ambiente virtuale: crea un ambiente virtuale utilizzando venv.
conda create -p venv python==3.10 -y- Attivazione dell'ambiente virtuale: Attiva l'ambiente virtuale:
conda activate venv/- Installa i pacchetti richiesti: Utilizza pip per installare le dipendenze necessarie elencate nel file require.txt:
pip install -r requirements.txt- dobbiamo impostare alcune variabili di ambiente nel sistema locale. Questa è la variabile di ambiente del cluster confluente del cloud
API_KEY
API_SECRET_KEY
BOOTSTRAP_SERVER
SCHEMA_REGISTRY_API_KEY
SCHEMA_REGISTRY_API_SECRET
ENDPOINT_SCHEMA_URL
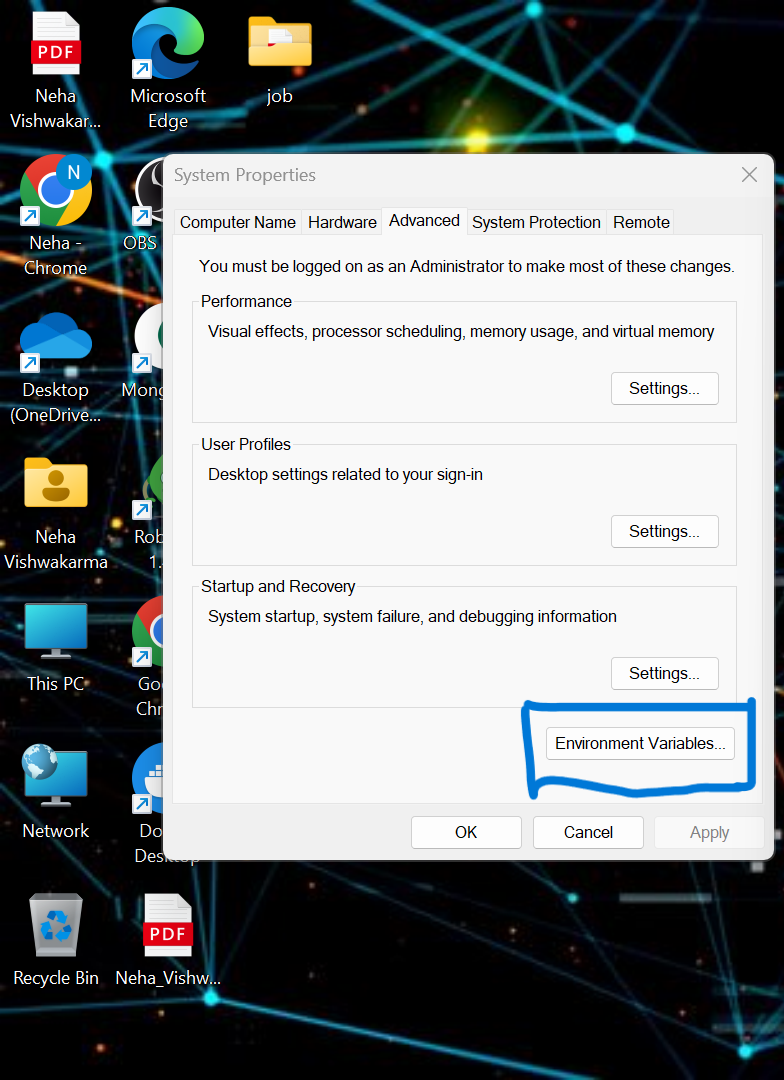
Aggiorna le credenziali nel file .env ed esegui il comando seguente per eseguire l'applicazione nella finestra mobile.
- Crea il file .env nella directory principale del tuo progetto se non è disponibile, incolla il contenuto seguente e aggiorna le credenziali
API_KEY=asgdakhlsa
API_SECRET_KEY=dsdfsdf
BOOTSTRAP_SERVER=sdfasd
SCHEMA_REGISTRY_API_KEY=sdfsaf
SCHEMA_REGISTRY_API_SECRET=sdfasdf
ENDPOINT_SCHEMA_URL=sdafasf
MONGO_DB_URL=sdfasdfas
- Esecuzione del file produttore e consumatore:
python producer_main.py
python consumer_main.pyCome implementare il codice?
- origine/: Questa directory è la cartella principale per tutti i file del codice sorgente. All'interno di questa directory abbiamo le seguenti sottodirectory:
consumer/: questa directory contiene il codice per Kafka_consumer, responsabile della lettura dei dati dagli argomenti Kafka e della loro elaborazione.
produttore/: questa directory contiene il codice per Kafka_producer, responsabile della generazione e dell'invio dei dati dei sensori agli argomenti Kafka. - README.md: Questo file Markdown contiene documentazione e istruzioni per il progetto, inclusa una panoramica del suo scopo, le istruzioni, le linee guida sull'utilizzo e qualsiasi informazione.
- requisiti.txt: Questo file elenca la libreria Python richiesta per il progetto. Ogni dipendenza è elencata insieme al relativo numero di versione. Strumenti come pip possono utilizzare questo file per installare automaticamente le dipendenze necessarie.
sensor_data-pipeline_kafka/
│
├── src/
│ ├── consumer/
│ │ ├── __init__.py
│ │ └── kafka_consumer.py
│ │
│ ├── producer/
│ │ ├── __init__.py
│ │ └── kafka_producer.py
│ │
│ └── __init__.py
│
├── README.md
└── requirements.txt
mongodb.py: Per connettere MongoDB Altas tramite il collegamento stiamo scrivendo lo script python
import pymongo
import os
import certifi
ca = certifi.where()
db_link ="mongodb+srv://Neha:<password>@cluster0.jsogkox.mongodb.net/"
class MongodbOperation:
def __init__(self) -> None:
#self.client = pymongo.MongoClient(os.getenv('MONGO_DB_URL'),tlsCAFile=ca)
self.client = pymongo.MongoClient(db_link,tlsCAFile=ca)
self.db_name="NehaDB"
def insert_many(self,collection_name,records:list):
self.client[self.db_name][collection_name].insert_many(records)
def insert(self,collection_name,record):
self.client[self.db_name][collection_name].insert_one(record)
inserisci il tuo URL che è copiato da MongoDb Altas
Produzione:
from src.kafka_producer.json_producer import product_data_using_file
from src.constant import SAMPLE_DIR
import os
if __name__ == '__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
product_data_using_file(topic=topic,file_path=sample_file_path)
Questo file viene eseguito, quindi chiamiamo il file python produttore_main.py e questo chiamerà il file seguente:
import argparse
from uuid import uuid4
from src.kafka_config import sasl_conf, schema_config
from six.moves import input
from src.kafka_logger import logging
from confluent_kafka import Producer
from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.json_schema import JSONSerializer
import pandas as pd
from typing import List
from src.entity.generic import Generic, instance_to_dict
FILE_PATH = "C:/Users/RAJIV/Downloads/ml-data-pipeline-main/sample_data/kafka-sensor-topic.csv"
def delivery_report(err, msg):
"""
Reports the success or failure of a message delivery.
Args:
err (KafkaError): The error that occurred on None on success.
msg (Message): The message that was produced or failed.
"""
if err is not None:
logging.info("Delivery failed for User record {}: {}".format(msg.key(), err))
return
logging.info('User record {} successfully produced to {} [{}] at offset {}'
.format(
msg.key(), msg.topic(), msg.partition(), msg.offset()))
def product_data_using_file(topic,file_path):
logging.info(f"Topic: {topic} file_path:{file_path}")
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
schema_registry_conf = schema_config()
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
string_serializer = StringSerializer('utf_8')
json_serializer = JSONSerializer(schema_str, schema_registry_client,
instance_to_dict)
producer = Producer(sasl_conf())
print("Producing user records to topic {}. ^C to exit.".format(topic))
# while True:
# Serve on_delivery callbacks from previous calls to produce()
producer.poll(0.0)
try:
for instance in Generic.get_object(file_path=file_path):
print(instance)
logging.info(f"Topic: {topic} file_path:{instance.to_dict()}")
producer.produce(topic=topic,
key=string_serializer(str(uuid4()), instance.to_dict()),
value=json_serializer(instance,
SerializationContext(topic, MessageField.VALUE)),
on_delivery=delivery_report)
print("nFlushing records...")
producer.flush()
except KeyboardInterrupt:
pass
except ValueError:
print("Invalid input, discarding record...")
pass
Produzione:

from src.kafka_consumer.json_consumer import consumer_using_sample_file
from src.constant import SAMPLE_DIR
import os
if __name__=='__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
consumer_using_sample_file(topic="kafka-sensor-topic",file_path = sample_file_path)
Questo file viene eseguito, quindi chiamiamo il file python consumatore_main.py e questo chiamerà il file seguente:
import argparse
from confluent_kafka import Consumer
from confluent_kafka.serialization import SerializationContext, MessageField
from confluent_kafka.schema_registry.json_schema import JSONDeserializer
from src.entity.generic import Generic
from src.kafka_config import sasl_conf
from src.database.mongodb import MongodbOperation
def consumer_using_sample_file(topic,file_path):
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
json_deserializer = JSONDeserializer(schema_str,
from_dict=Generic.dict_to_object)
consumer_conf = sasl_conf()
consumer_conf.update({
'group.id': 'group7',
'auto.offset.reset': "earliest"})
consumer = Consumer(consumer_conf)
consumer.subscribe([topic])
mongodb = MongodbOperation()
records = []
x = 0
while True:
try:
# SIGINT can't be handled when polling, limit timeout to 1 second.
msg = consumer.poll(1.0)
if msg is None:
continue
record: Generic = json_deserializer(msg.value(),
SerializationContext(msg.topic(), MessageField.VALUE))
# mongodb.insert(collection_name="car",record=car.record)
if record is not None:
records.append(record.to_dict())
if x % 5000 == 0:
mongodb.insert_many(collection_name="sensor", records=records)
records = []
x = x + 1
except KeyboardInterrupt:
break
consumer.close()Produzione:

Quando gestiamo sia il consumatore che il produttore, il sistema funziona su Kafka e le informazioni/i dati vengono raccolti più velocemente

Produzione:
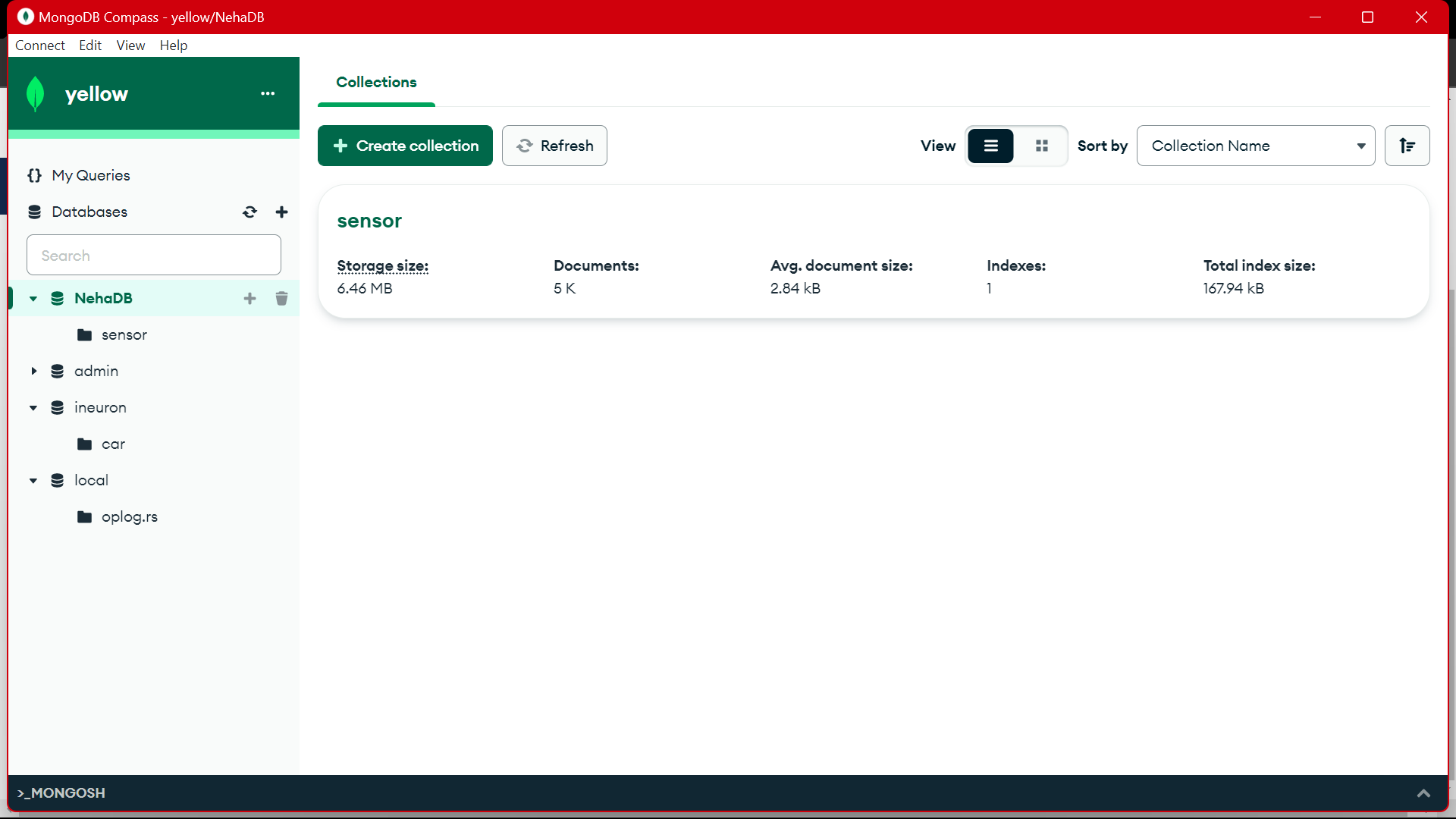
Da MongoDB utilizziamo questi dati per la preelaborazione in EDA, su questi dati viene svolto il lavoro di ingegneria delle funzionalità e di analisi dei dati.
[Contenuto incorporato]
Conclusione
In questo articolo, comprendiamo come stiamo archiviando ed elaborando i dati in streaming dal sensore a Kafka sotto forma di formato JSON, quindi archiviamo i dati su MongoDB. Sappiamo che i dati in streaming sono dati emessi ad alto volume in un'elaborazione continua, il che significa che i dati cambiano ogni secondo. Abbiamo creato la pipeline end-to-end in cui i dati vengono recuperati con l'aiuto dell'API nella pipeline e quindi raccolti in Kafka sotto forma di argomenti e quindi archiviati in MongoDB da lì possiamo utilizzarli nel progetto o eseguire il ingegneria delle funzionalità.
Punti chiave
- Scopri cosa sono i dati in streaming e come gestire i dati in streaming con l'aiuto di Kafka.
- comprendere la piattaforma Confluent: una distribuzione autogestita di livello aziendale di Apache Kafka.
- memorizza i dati raccolti da Kafka nel MongoDB che è un database NoSQL che memorizza i dati non strutturati.
- Crea una pipeline completamente end-to-end per recuperare e archiviare i dati nel database.
- comprendere la funzionalità di ogni componente del progetto implementarlo sulla finestra mobile e implementarlo su un cloud per utilizzarlo in qualsiasi momento.
Risorse
Domande frequenti
R. MongoDB memorizza i dati in dati non strutturati. i dati in streaming sono forme di dati non strutturate per l'utilizzo della memoria che utilizziamo MongoDB come database.
R. Lo scopo è creare una pipeline di elaborazione dati in tempo reale in cui i dati inseriti negli argomenti Kafka possano essere consumati, elaborati e archiviati in MongoDB per ulteriori analisi, reporting o utilizzo dell'applicazione.
R. I casi d'uso includono analisi in tempo reale, elaborazione dei dati IoT, aggregazione di log, monitoraggio dei social media e sistemi di consigli, in cui i dati in streaming devono essere elaborati e archiviati per ulteriori analisi o utilizzo delle applicazioni.
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e vengono utilizzati a discrezione dell'autore.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.analyticsvidhya.com/blog/2024/02/kafka-to-mongodb-building-a-streamlined-data-pipeline/

