Questo è un guest post scritto in collaborazione con Brandon Abear, Dinesh Sharma, John Bush e Ozcan IIikhan di GoDaddy.
Vai papà dà potere agli imprenditori di tutti i giorni fornendo tutto l'aiuto e gli strumenti per avere successo online. Con oltre 20 milioni di clienti in tutto il mondo, GoDaddy è il luogo in cui le persone vengono per esprimere le proprie idee, creare un sito Web professionale, attirare clienti e gestire il proprio lavoro.
Noi di GoDaddy siamo orgogliosi di essere un'azienda basata sui dati. La nostra incessante ricerca di informazioni preziose dai dati alimenta le nostre decisioni aziendali e garantisce la soddisfazione del cliente. Il nostro impegno per l'efficienza è costante e abbiamo intrapreso un'entusiasmante iniziativa per ottimizzare i nostri lavori di elaborazione batch. In questo viaggio, abbiamo identificato un approccio strutturato che chiamiamo i sette livelli di opportunità di miglioramento. Questa metodologia è diventata la nostra guida nella ricerca dell’efficienza.
In questo post, discutiamo di come abbiamo migliorato l'efficienza operativa con Amazon EMR senza server. Condividiamo i nostri risultati e la nostra metodologia di benchmarking, nonché approfondimenti sul rapporto costo-efficacia di EMR Serverless rispetto alla capacità fissa Amazon EMR su EC2 cluster temporanei sui nostri flussi di lavoro di dati orchestrati utilizzando Flussi di lavoro gestiti da Amazon per Apache Airflow (Amazon MWAA). Condividiamo la nostra strategia per l'adozione di EMR Serverless negli ambiti in cui eccelle. I nostri risultati rivelano vantaggi significativi, tra cui una riduzione dei costi di oltre il 60%, carichi di lavoro Spark più veloci del 50%, un notevole miglioramento di cinque volte nella velocità di sviluppo e test e una significativa riduzione delle nostre emissioni di carbonio.
sfondo
Alla fine del 2020, la piattaforma dati di GoDaddy ha avviato il suo viaggio nel cloud AWS, migrando un cluster Hadoop da 800 nodi con 2.5 PB di dati dal suo data center a EMR su EC2. Questo approccio lift-and-shift ha facilitato un confronto diretto tra ambienti on-premise e cloud, garantendo una transizione graduale alle pipeline AWS, riducendo al minimo i problemi di convalida dei dati e i ritardi di migrazione.
All'inizio del 2022, abbiamo migrato con successo i nostri carichi di lavoro Big Data su EMR su EC2. Utilizzando le best practice apprese dal programma AWS FinHack, abbiamo perfezionato i lavori ad uso intensivo di risorse, convertito i lavori Pig e Hive in Spark e ridotto la spesa per i carichi di lavoro batch del 22.75% nel 2022. Tuttavia, sono emerse sfide di scalabilità a causa della moltitudine di lavori . Ciò ha spinto GoDaddy a intraprendere un percorso di ottimizzazione sistematica, gettando le basi per un’elaborazione dei big data più sostenibile ed efficiente.
Sette livelli di opportunità di miglioramento
Nella nostra ricerca dell'efficienza operativa, abbiamo identificato sette livelli distinti di opportunità di ottimizzazione all'interno dei nostri lavori di elaborazione batch, come mostrato nella figura seguente. Questi livelli vanno da miglioramenti precisi a livello di codice a miglioramenti più completi della piattaforma. Questo approccio multilivello è diventato il nostro modello strategico nella continua ricerca di prestazioni migliori e maggiore efficienza.

Gli strati sono i seguenti:
- Ottimizzazione del codice – Si concentra sul perfezionamento della logica del codice e su come può essere ottimizzato per prestazioni migliori. Ciò comporta miglioramenti delle prestazioni attraverso il caching selettivo, l'eliminazione delle partizioni e delle proiezioni, l'ottimizzazione dei join e altre ottimizzazioni specifiche del lavoro. Anche l’utilizzo di soluzioni di codifica AI è parte integrante di questo processo.
- Aggiornamenti software - Aggiornamento alle ultime versioni del software open source (OSS) per sfruttare nuove funzionalità e miglioramenti. Ad esempio, l'esecuzione di query adattive in Spark 3 apporta miglioramenti significativi in termini di prestazioni e costi.
- Configurazioni Spark personalizzate - Ottimizzazione delle configurazioni Spark personalizzate per massimizzare l'utilizzo delle risorse, la memoria e il parallelismo. Possiamo ottenere miglioramenti significativi dimensionando correttamente le attività, ad esempio attraverso
spark.sql.shuffle.partitions,spark.sql.files.maxPartitionBytes,spark.executor.coresespark.executor.memory. Tuttavia, queste configurazioni personalizzate potrebbero essere controproducenti se non sono compatibili con la versione Spark specifica. - Tempo di provisioning delle risorse - Il tempo necessario per avviare risorse come i cluster EMR temporanei Cloud di calcolo elastico di Amazon (Amazon EC2). Sebbene alcuni fattori che influenzano questo tempo siano al di fuori del controllo del tecnico, identificare e affrontare i fattori che possono essere ottimizzati può aiutare a ridurre il tempo complessivo di provisioning.
- Ridimensionamento a grana fine a livello di attività - Regolazione dinamica di risorse quali CPU, memoria, disco e larghezza di banda di rete in base alle esigenze di ciascuna fase all'interno di un'attività. L’obiettivo qui è evitare dimensioni fisse dei cluster che potrebbero comportare uno spreco di risorse.
- Scalabilità dettagliata tra più attività in un flusso di lavoro - Dato che ogni attività ha requisiti di risorse univoci, il mantenimento di una dimensione di risorsa fissa può comportare un provisioning insufficiente o eccessivo per determinate attività all'interno dello stesso flusso di lavoro. Tradizionalmente, la dimensione dell'attività più grande determina la dimensione del cluster per un flusso di lavoro multi-task. Tuttavia, la regolazione dinamica delle risorse su più attività e passaggi all'interno di un flusso di lavoro si traduce in un'implementazione più conveniente.
- Miglioramenti a livello di piattaforma – I miglioramenti ai livelli precedenti possono solo ottimizzare un determinato lavoro o un flusso di lavoro. Il miglioramento della piattaforma mira a raggiungere l’efficienza a livello aziendale. Possiamo raggiungere questo obiettivo attraverso vari mezzi, come l'aggiornamento o il potenziamento dell'infrastruttura principale, l'introduzione di nuovi framework, l'allocazione di risorse adeguate per ciascun profilo lavorativo, il bilanciamento dell'utilizzo dei servizi, l'ottimizzazione dell'uso dei piani di risparmio e delle istanze Spot o l'implementazione di altre modifiche globali per potenziare efficienza in tutte le attività e flussi di lavoro.
Livelli 1–3: precedenti riduzioni dei costi
Dopo la migrazione da locale ad AWS Cloud, abbiamo concentrato i nostri sforzi di ottimizzazione dei costi principalmente sui primi tre livelli mostrati nel diagramma. Trasferendo le nostre pipeline Pig e Hive legacy più costose a Spark e ottimizzando le configurazioni Spark per Amazon EMR, abbiamo ottenuto notevoli risparmi sui costi.
Ad esempio, un lavoro legacy di Pig ha richiesto 10 ore per essere completato e si è classificato tra i primi 10 lavori EMR più costosi. Dopo aver esaminato i log TEZ e le metriche del cluster, abbiamo scoperto che il cluster aveva un provisioning ampiamente eccessivo per il volume di dati da elaborare ed è rimasto sottoutilizzato per la maggior parte del tempo di esecuzione. La transizione da Pig a Spark è stata più efficiente. Sebbene non fossero disponibili strumenti automatizzati per la conversione, sono state apportate ottimizzazioni manuali, tra cui:
- Riduzione delle scritture su disco non necessarie, risparmiando tempo di serializzazione e deserializzazione (Livello 1)
- Sostituita la parallelizzazione delle attività Airflow con Spark, semplificando il DAG Airflow (Livello 1)
- Eliminate le trasformazioni Spark ridondanti (Livello 1)
- Aggiornato da Spark 2 a 3, utilizzando l'esecuzione di query adattive (livello 2)
- Risoluzione dei giunti obliqui e tabelle delle dimensioni più piccole ottimizzate (Livello 3)
Di conseguenza, il costo del lavoro è diminuito del 95% e il tempo di completamento del lavoro è stato ridotto a 1 ora. Tuttavia, questo approccio era ad alta intensità di manodopera e non scalabile per numerosi lavori.
Livelli 4-6: trovare e adottare la giusta soluzione di elaborazione
Alla fine del 2022, in seguito ai risultati significativi ottenuti nell’ottimizzazione dei livelli precedenti, la nostra attenzione si è spostata sul miglioramento dei livelli rimanenti.
Comprendere lo stato della nostra elaborazione batch
Utilizziamo Amazon MWAA per orchestrare i nostri flussi di lavoro di dati nel cloud su larga scala. Flusso d'aria Apache è uno strumento open source utilizzato per creare, pianificare e monitorare a livello di codice sequenze di processi e attività denominate flussi di lavoro. In questo post, i termini flusso di lavoro ed lavoro sono usati in modo intercambiabile, facendo riferimento ai grafici aciclici diretti (DAG) costituiti da attività orchestrate da Amazon MWAA. Per ogni flusso di lavoro, abbiamo attività sequenziali o parallele e persino una combinazione di entrambe nel DAG intermedio create_emr ed terminate_emr attività in esecuzione su un cluster EMR temporaneo con capacità di elaborazione fissa durante l'esecuzione del flusso di lavoro. Anche dopo aver ottimizzato una parte del nostro carico di lavoro, avevamo ancora numerosi flussi di lavoro non ottimizzati che erano sottoutilizzati a causa del provisioning eccessivo delle risorse di elaborazione in base all'attività più dispendiosa in termini di risorse nel flusso di lavoro, come mostrato nella figura seguente.
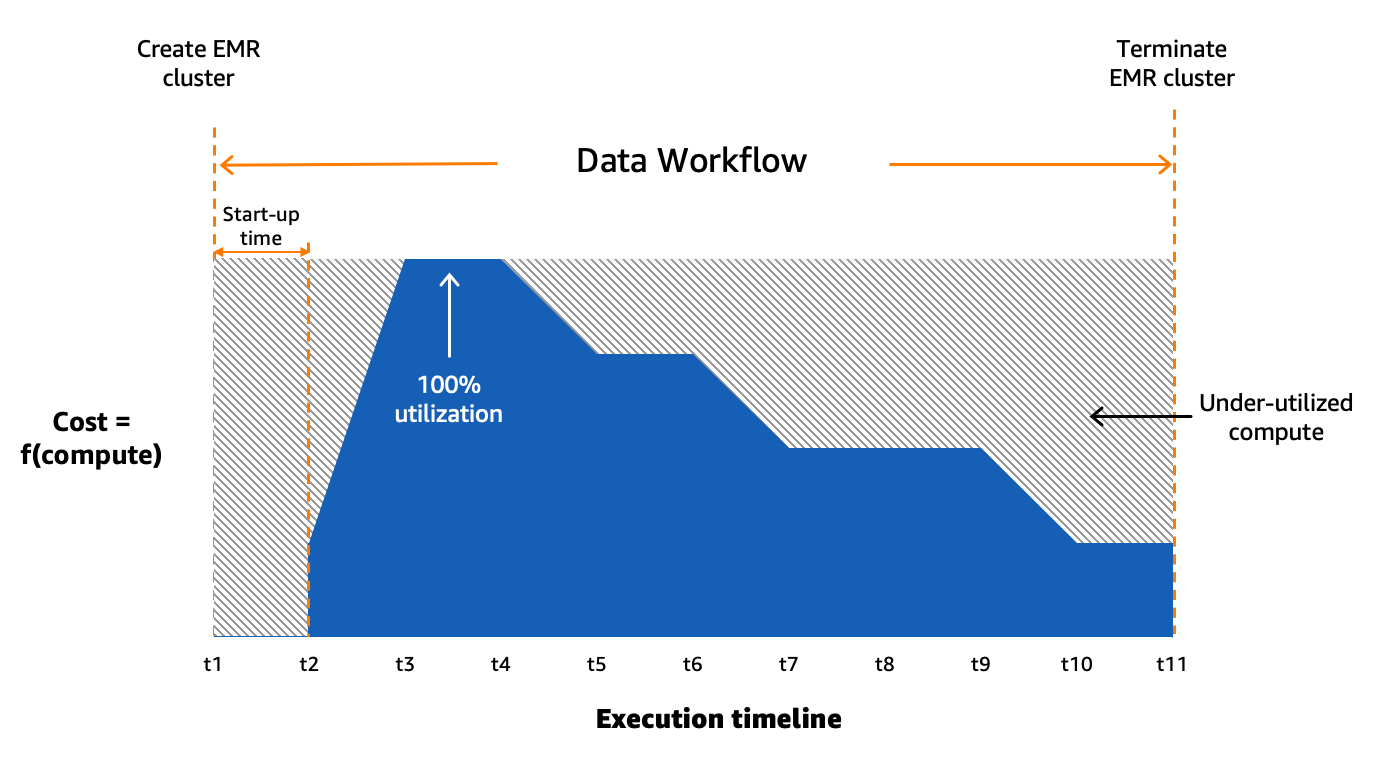
Ciò ha evidenziato l’impraticabilità dell’allocazione statica delle risorse e ci ha portato a riconoscere la necessità di un sistema di allocazione dinamica delle risorse (DRA). Prima di proporre una soluzione, abbiamo raccolto dati estesi per comprendere a fondo la nostra elaborazione batch. L'analisi del tempo di passaggio del cluster, escludendo il provisioning e i tempi di inattività, ha rivelato informazioni significative: una distribuzione distorta a destra con oltre la metà dei flussi di lavoro completati in 20 minuti o meno e solo il 10% che impiega più di 60 minuti. Questa distribuzione ha guidato la nostra scelta di una soluzione di elaborazione a provisioning rapido, riducendo drasticamente i tempi di esecuzione del flusso di lavoro. Il seguente diagramma illustra i tempi delle fasi (esclusi il provisioning e i tempi di inattività) di EMR sui cluster transitori EC2 in uno dei nostri account di elaborazione batch.
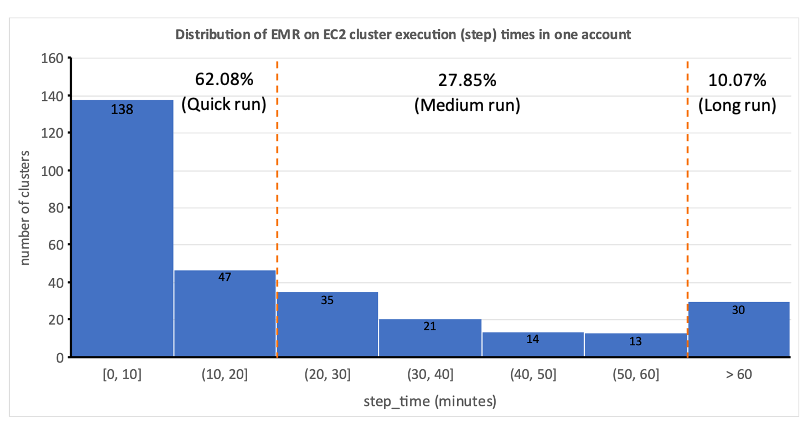
Inoltre, in base alla distribuzione del tempo di passaggio (esclusi provisioning e tempi di inattività) dei flussi di lavoro, abbiamo classificato i nostri flussi di lavoro in tre gruppi:
- Corsa veloce – Della durata di 20 minuti o meno
- Tiratura media – Durata compresa tra 20 e 60 minuti
- Lunga corsa – Superiore a 60 minuti, che spesso copre diverse ore o più
Un altro fattore che dovevamo considerare era l'uso estensivo di cluster temporanei per motivi quali sicurezza, isolamento di posti di lavoro e costi e cluster appositamente creati. Inoltre, si è verificata una variazione significativa nel fabbisogno di risorse tra le ore di punta e i periodi di basso utilizzo.
Invece di cluster a dimensione fissa, potremmo potenzialmente utilizzare la scalabilità gestita su EMR su EC2 per ottenere alcuni vantaggi in termini di costi. Tuttavia, la migrazione a EMR Serverless sembra essere una direzione più strategica per la nostra piattaforma dati. Oltre ai potenziali vantaggi in termini di costi, EMR Serverless offre ulteriori vantaggi come l'aggiornamento con un clic alle versioni più recenti di Amazon EMR, un'esperienza operativa e di debug semplificata e aggiornamenti automatici alle ultime generazioni al momento del lancio. Queste funzionalità semplificano collettivamente il processo di gestione di una piattaforma su scala più ampia.
Valutazione di EMR Serverless: un caso di studio presso GoDaddy
EMR Serverless è un'opzione serverless in Amazon EMR che elimina le complessità di configurazione, gestione e dimensionamento dei cluster durante l'esecuzione di framework per big data come Apache Spark e Apache Hive. Con EMR Serverless, le aziende possono usufruire di numerosi vantaggi, tra cui convenienza, provisioning più rapido, esperienza semplificata per gli sviluppatori e migliore resilienza ai guasti della zona di disponibilità.
Riconoscendo il potenziale di EMR Serverless, abbiamo condotto uno studio comparativo approfondito utilizzando flussi di lavoro di produzione reali. Lo studio mirava a valutare le prestazioni e l'efficienza di EMR Serverless, creando allo stesso tempo un piano di adozione per l'implementazione su larga scala. I risultati sono stati molto incoraggianti e hanno dimostrato che EMR Serverless può gestire efficacemente i nostri carichi di lavoro.
Metodologia di benchmarking
Dividiamo i nostri flussi di lavoro dei dati in tre categorie in base al tempo totale del passaggio (esclusi il provisioning e il tempo di inattività): esecuzione rapida (0–20 minuti), esecuzione media (20–60 minuti) e esecuzione lunga (oltre 60 minuti). Abbiamo analizzato l'impatto del tipo di distribuzione EMR (Amazon EC2 rispetto a EMR Serverless) su due parametri chiave: efficienza in termini di costi e accelerazione totale del tempo di esecuzione, che sono serviti come criteri di valutazione generali. Sebbene non abbiamo misurato formalmente la facilità d'uso e la resilienza, questi fattori sono stati considerati durante tutto il processo di valutazione.
I passaggi di alto livello per valutare l’ambiente sono i seguenti:
- Preparare i dati e l'ambiente:
- Scegli da tre a cinque lavori di produzione casuali da ciascuna categoria di lavoro.
- Implementare le modifiche necessarie per evitare interferenze con la produzione.
- Esegui test:
- Esegui script per diversi giorni o attraverso più iterazioni per raccogliere punti dati precisi e coerenti.
- Esegui test utilizzando EMR su EC2 ed EMR Serverless.
- Convalidare i dati e le esecuzioni di test:
- Convalida set di dati di input e output, partizioni e conteggi di righe per garantire un'elaborazione dei dati identica.
- Raccogli parametri e analizza i risultati:
- Raccogli le metriche rilevanti dai test.
- Analizzare i risultati per trarre approfondimenti e conclusioni.
Risultati di riferimento
I nostri risultati di benchmark hanno mostrato miglioramenti significativi in tutte e tre le categorie di lavoro sia in termini di accelerazione del tempo di esecuzione che di efficienza dei costi. I miglioramenti sono stati più pronunciati per i lavori rapidi, derivanti direttamente da tempi di avvio più rapidi. Ad esempio, un flusso di lavoro di dati di 20 minuti (compreso il provisioning e l'arresto del cluster) in esecuzione su un cluster transitorio EMR su EC2 con capacità di elaborazione fissa termina in 10 minuti su EMR Serverless, fornendo un tempo di esecuzione più breve con vantaggi in termini di costi. Nel complesso, il passaggio a EMR Serverless ha apportato miglioramenti sostanziali delle prestazioni e riduzioni dei costi su larga scala in tutte le fasce di lavoro, come mostrato nella figura seguente.
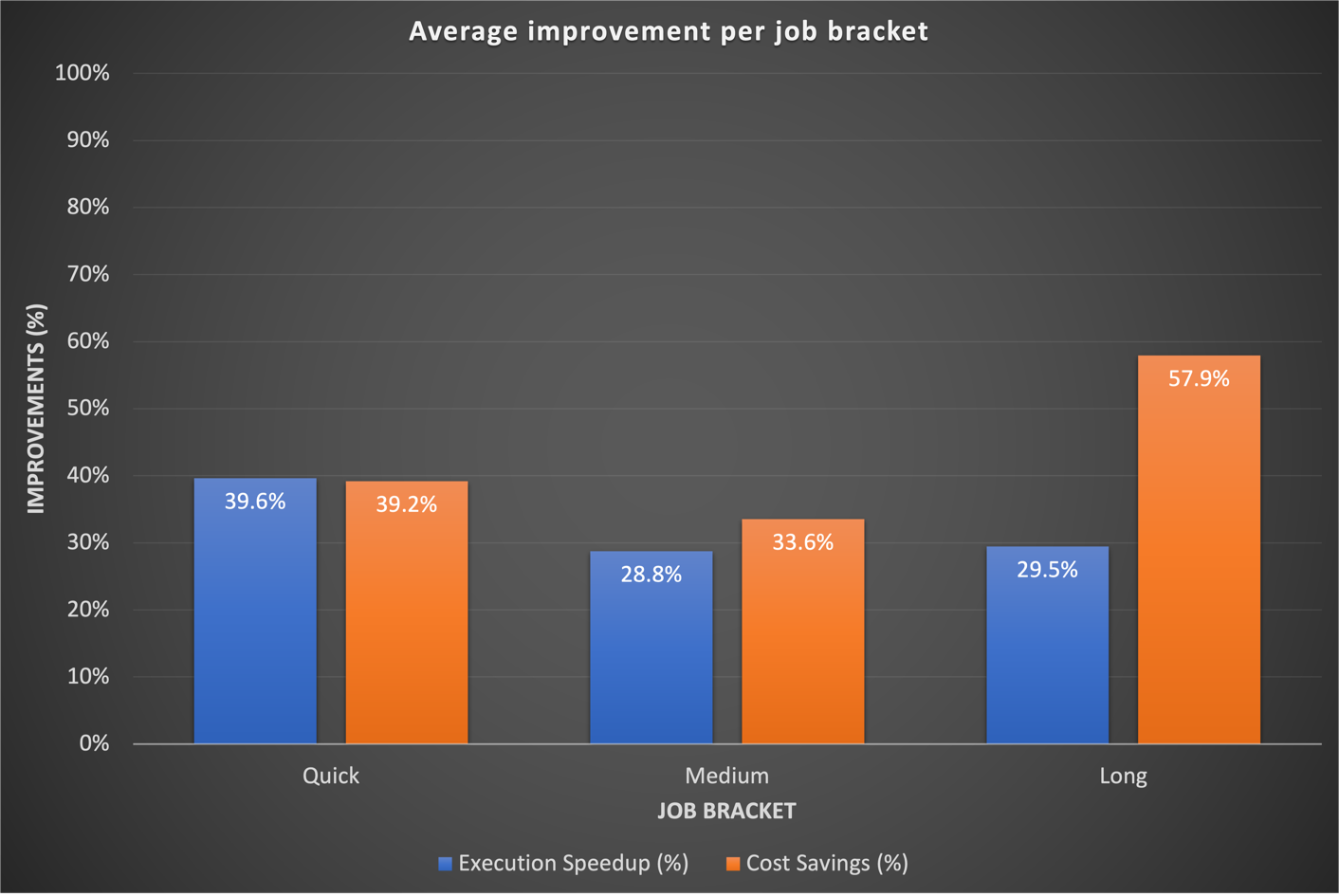
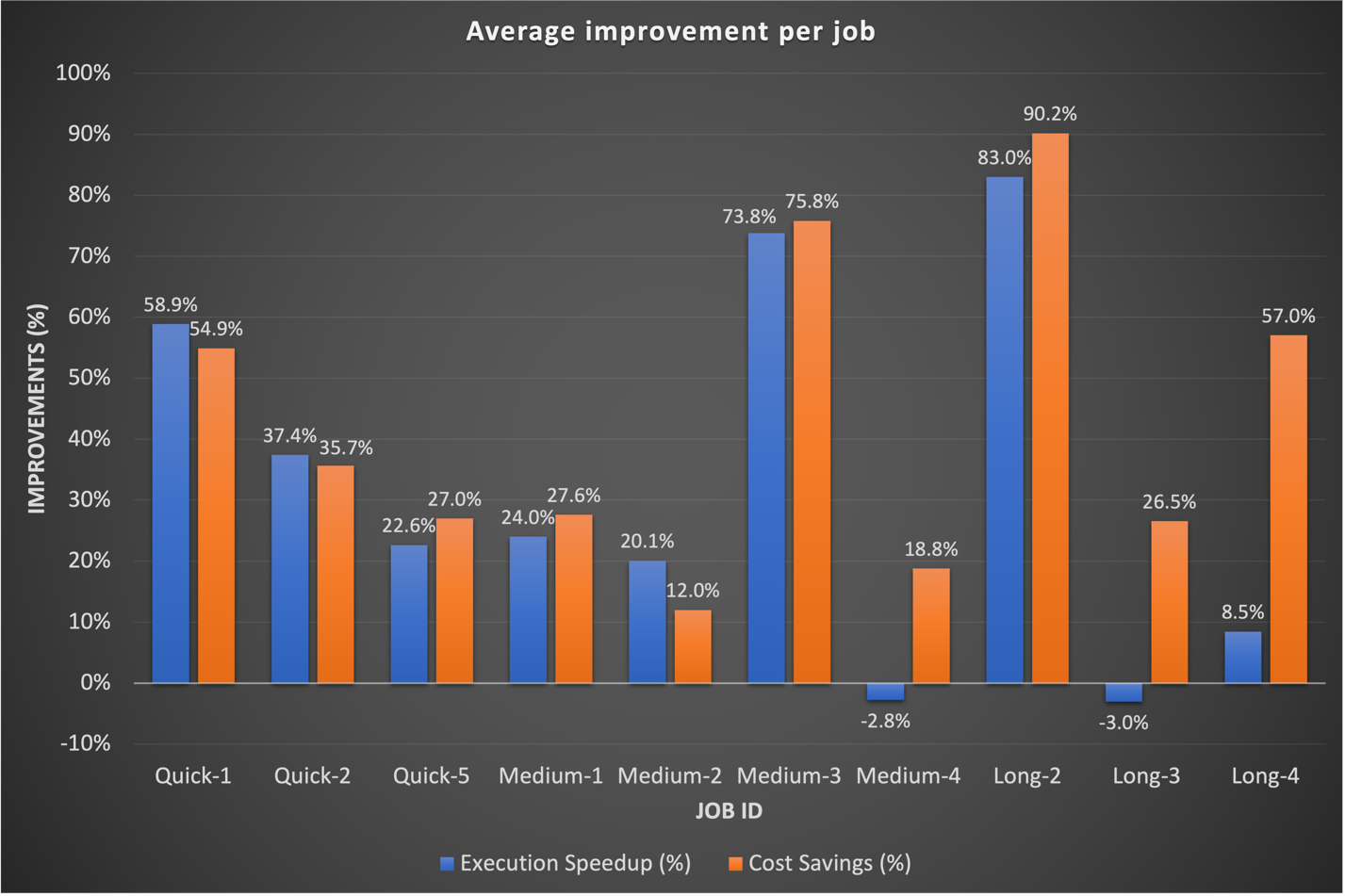
Storicamente, abbiamo dedicato più tempo alla messa a punto dei nostri flussi di lavoro a lungo termine. È interessante notare che abbiamo scoperto che le configurazioni Spark personalizzate esistenti per questi lavori non sempre si traducevano bene in EMR Serverless. Nei casi in cui i risultati erano insignificanti, un approccio comune era quello di scartare le precedenti configurazioni Spark relative ai core esecutori. Consentendo a EMR Serverless di gestire in modo autonomo queste configurazioni Spark, abbiamo spesso osservato risultati migliori. Il grafico seguente mostra il miglioramento medio del tempo di esecuzione e dei costi per lavoro confrontando EMR Serverless con EMR su EC2.
La tabella seguente mostra un esempio di confronto dei risultati per lo stesso flusso di lavoro in esecuzione su diverse opzioni di distribuzione di Amazon EMR (EMR su EC2 ed EMR Serverless).
| Metrico | EMR su EC2 (Media) |
EMR senza server (Media) |
EMR su EC2 vs EMR senza server |
| Costo totale di esecuzione ($) | $ 5.82 | $ 2.60 | 55% |
| Tempo di esecuzione totale (minuti) | 53.40 | 39.40 | 26% |
| Tempo di provisioning (minuti) | 10.20 | 0.05 | . |
| Costo di provisioning ($) | € 1.19 | . | . |
| Passi Tempo (Minuti) | 38.20 | 39.16 | -3% |
| Costo dei passaggi ($) | € 4.30 | . | . |
| Tempo di inattività (minuti) | 4.80 | . | . |
| Etichetta di rilascio EMR | em-6.9.0 | . | |
| Distribuzione Hadoop | Amazon 3.3.3 | . | |
| Versione Scintilla | Spark 3.3.0 | . | |
| Versione Hive/HCatalog | Hive 3.1.3, HCatalogo 3.1.3 | . | |
| Tipo di lavoro | Scintilla | . | |
AWS Graviton2 sulla valutazione delle prestazioni serverless EMR
Dopo aver riscontrato risultati convincenti con EMR Serverless per i nostri carichi di lavoro, abbiamo deciso di analizzare ulteriormente le prestazioni di AWS Gravitone2 (arm64) all'interno di EMR Serverless. AWS aveva confrontato Carichi di lavoro Spark su Graviton2 EMR Serverless utilizzando la scala TPC-DS da 3 TB, mostrando un miglioramento complessivo del rapporto prezzo/prestazioni del 27%.
Per comprendere meglio i vantaggi dell'integrazione, abbiamo condotto il nostro studio utilizzando i carichi di lavoro di produzione di GoDaddy secondo una pianificazione giornaliera e abbiamo osservato un impressionante miglioramento del rapporto prezzo-prestazioni del 23.8% in una serie di lavori quando si utilizza Graviton2. Per maggiori dettagli su questo studio, cfr Il benchmarking di GoDaddy porta a un rapporto prezzo/prestazioni migliore fino al 24% per i carichi di lavoro Spark con AWS Graviton2 su Amazon EMR Serverless.
Strategia di adozione per EMR Serverless
Abbiamo implementato strategicamente un'implementazione graduale di EMR Serverless tramite anelli di distribuzione, consentendo un'integrazione sistematica. Questo approccio graduale ci ha consentito di convalidare i miglioramenti e di interrompere l'ulteriore adozione di EMR Serverless, se necessario. È servito sia come rete di sicurezza per individuare tempestivamente i problemi, sia come mezzo per perfezionare la nostra infrastruttura. Il processo ha mitigato l'impatto del cambiamento attraverso operazioni fluide, rafforzando al contempo le competenze dei nostri team di Data Engineering e DevOps. Inoltre, ha favorito stretti cicli di feedback, consentendo rapidi aggiustamenti e garantendo un’efficiente integrazione EMR Serverless.
Abbiamo diviso i nostri flussi di lavoro in tre gruppi principali di adozione, come mostrato nell'immagine seguente:
- Canarie - Questo gruppo aiuta a rilevare e risolvere eventuali problemi nelle prime fasi della fase di distribuzione.
- I primi ad adottare - Questo è il secondo lotto di flussi di lavoro che adottano la nuova soluzione di calcolo dopo che i problemi iniziali sono stati identificati e risolti dal gruppo Canary.
- Anelli di distribuzione larghi - Il più grande gruppo di anelli, questo gruppo rappresenta l'implementazione su larga scala della soluzione. Questi vengono distribuiti dopo aver testato e implementato con successo nei due gruppi precedenti.
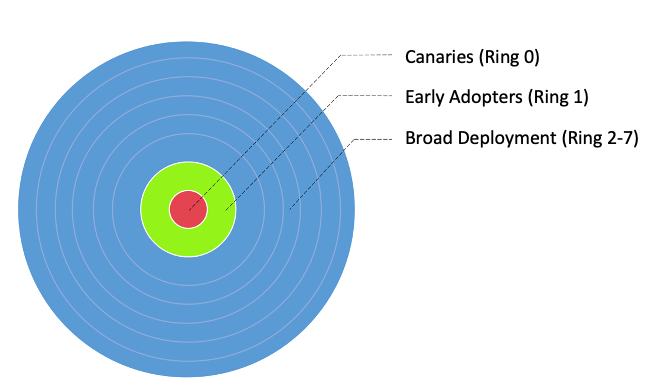
Abbiamo ulteriormente suddiviso questi flussi di lavoro in anelli di distribuzione granulari per adottare EMR Serverless, come mostrato nella tabella seguente.
| Squillo # | Nome | Dettagli |
| Anello 0 | Canarino | Lavori a basso rischio di adozione che dovrebbero produrre alcuni vantaggi in termini di risparmio sui costi. |
| Anello 1 | Primi adottivi | Basso rischio Lavori Spark a esecuzione rapida che prevedono di produrre guadagni elevati. |
| Anello 2 | Corri veloce | Resto della corsa veloce (step_time <= 20 min) Lavori Spark |
| Anello 3 | LargerJobs_EZ | Guadagno potenziale elevato, spostamento facile, lavori Spark a medio e lungo termine |
| Anello 4 | Lavori più grandi | Resto dei lavori Spark a medio e lungo termine con potenziali guadagni |
| Anello 5 | Alveare | Lavori Hive con risparmi sui costi potenzialmente più elevati |
| Anello 6 | Redshift_EZ | Migrazione semplice Lavori Redshift adatti a EMR Serverless |
| Anello 7 | Colla_EZ | Migrazione semplice Lavori di colla adatti a EMR Serverless |
Riepilogo dei risultati dell'adozione della produzione
Gli incoraggianti risultati del benchmarking e dell'adozione di Canary hanno generato un notevole interesse per una più ampia adozione di EMR Serverless presso GoDaddy. Ad oggi, il lancio di EMR Serverless rimane in corso. Finora ha ridotto i costi del 62.5% e accelerato il completamento totale del flusso di lavoro batch del 50.4%.
Sulla base dei parametri di riferimento preliminari, il nostro team prevedeva guadagni sostanziali per i lavori rapidi. Con nostra sorpresa, le implementazioni di produzione effettive hanno superato le proiezioni, con una media del 64.4% più veloce rispetto al 42% previsto e del 71.8% più economica rispetto al 40% previsto.
Sorprendentemente, i lavori di lunga durata hanno visto anche miglioramenti significativi delle prestazioni grazie al rapido provisioning di EMR Serverless e alla scalabilità aggressiva consentita dall’allocazione dinamica delle risorse. Abbiamo osservato una sostanziale parallelizzazione durante i segmenti ad alto contenuto di risorse, con conseguente runtime totale più veloce del 40.5% rispetto agli approcci tradizionali. Il grafico seguente illustra i miglioramenti medi per categoria lavorativa.
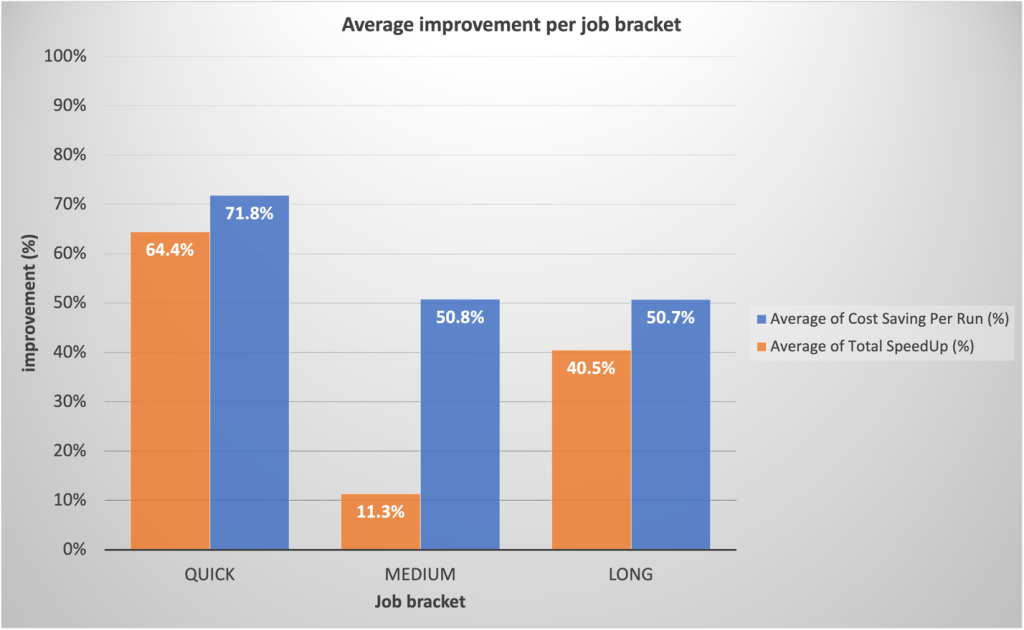
Inoltre, abbiamo osservato il più alto grado di dispersione per i miglioramenti della velocità all'interno della categoria di lavoro a lungo termine, come mostrato nel seguente grafico a scatola e baffi.
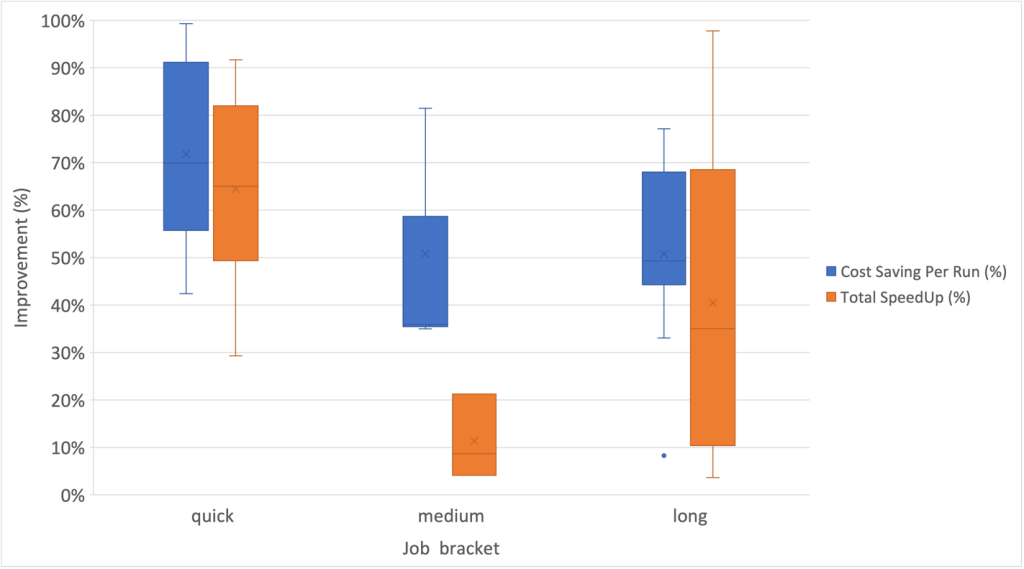
I flussi di lavoro di esempio hanno adottato EMR Serverless
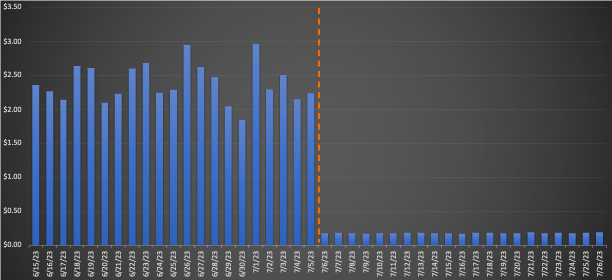
Per un flusso di lavoro di grandi dimensioni migrato a EMR Serverless, il confronto delle medie di 3 settimane prima e dopo la migrazione ha rivelato notevoli risparmi sui costi: una diminuzione del 75.30% in base ai prezzi al dettaglio con un miglioramento del 10% nel tempo di esecuzione totale, aumentando l'efficienza operativa. Il grafico seguente illustra l'andamento dei costi.
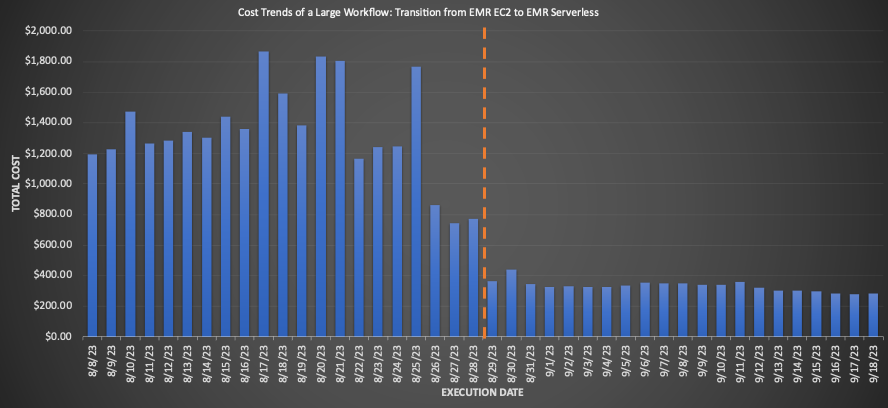
Sebbene i lavori di rapida esecuzione abbiano consentito riduzioni minime dei costi per dollaro, hanno consentito di ottenere il risparmio percentuale più significativo. Con migliaia di questi flussi di lavoro eseguiti ogni giorno, i risparmi accumulati sono sostanziali. Il grafico seguente mostra l'andamento dei costi per un piccolo carico di lavoro migrato da EMR su EC2 a EMR Serverless. Il confronto delle medie pre e post migrazione di 3 settimane ha rivelato un notevole risparmio sui costi del 92.43% sui prezzi al dettaglio on-demand, insieme a un'accelerazione dell'80.6% nel tempo di esecuzione totale.
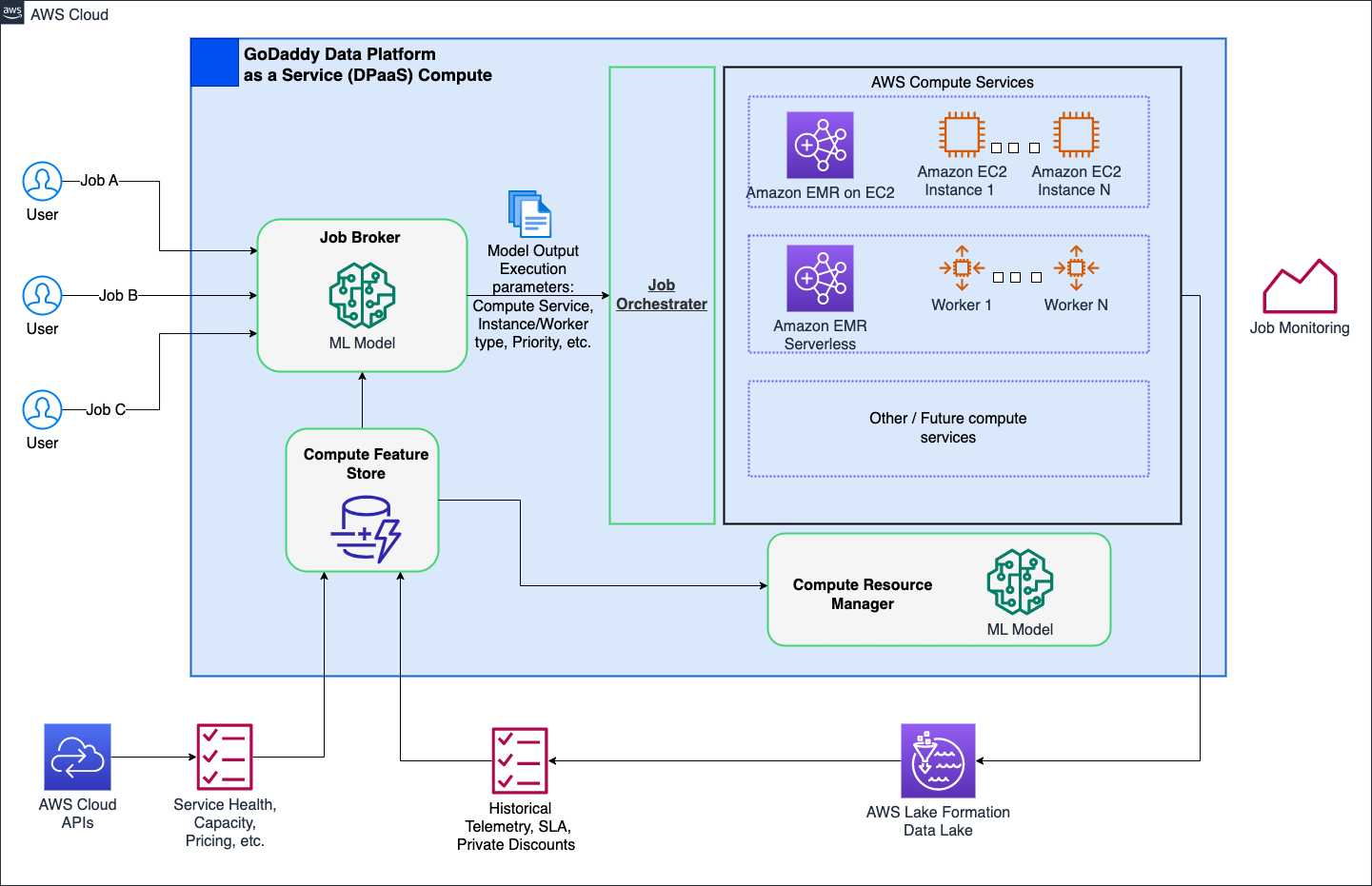
Livello 7: miglioramenti a livello di piattaforma
Il nostro obiettivo è rivoluzionare le operazioni di elaborazione in GoDaddy, fornendo soluzioni semplificate ma potenti per tutti gli utenti con la nostra piattaforma di elaborazione intelligente. Con le soluzioni di elaborazione AWS come EMR Serverless ed EMR su EC2, ha fornito esecuzioni ottimizzate di carichi di lavoro di elaborazione dati e machine learning (ML). Un job broker basato sul ML determina in modo intelligente quando e come eseguire i lavori in base a vari parametri, consentendo comunque agli utenti esperti di personalizzarli. Inoltre, un gestore delle risorse di elaborazione basato su ML effettua il pre-provisioning delle risorse in base al carico e ai dati storici, fornendo un provisioning efficiente e veloce a costi ottimali. Il calcolo intelligente offre agli utenti un'ottimizzazione pronta all'uso, adattandosi a personaggi diversi senza compromettere gli utenti esperti.
Il diagramma seguente mostra un'illustrazione di alto livello dell'architettura di calcolo intelligente.
Approfondimenti e best practice consigliate
Nella sezione seguente vengono illustrati gli approfondimenti che abbiamo raccolto e le migliori pratiche consigliate che abbiamo sviluppato durante le fasi preliminari e più ampie di adozione.
Preparazione delle infrastrutture
Sebbene EMR Serverless sia un metodo di distribuzione all'interno di EMR, richiede una certa preparazione dell'infrastruttura per ottimizzarne il potenziale. Considerare i seguenti requisiti e indicazioni pratiche sull’implementazione:
- Utilizza sottoreti di grandi dimensioni su più zone di disponibilità: Quando esegui carichi di lavoro EMR Serverless all'interno del tuo VPC, assicurati che le sottoreti si estendano su più zone di disponibilità e non siano vincolate da indirizzi IP. Fare riferimento a Configurazione dell'accesso VPC ed Migliori pratiche per la pianificazione della sottorete per i dettagli.
- Modifica la quota massima vCPU simultanea - Per requisiti di elaborazione estesi, si consiglia di aumentare il tuo numero massimo di vCPU simultanee per account quota di servizio.
- Compatibilità della versione di Amazon MWAA - Durante l'adozione di EMR Serverless, l'ecosistema decentralizzato Amazon MWAA di GoDaddy per l'orchestrazione della pipeline di dati ha creato problemi di compatibilità con le diverse versioni dei provider AWS. L'aggiornamento diretto di Amazon MWAA si è rivelato più efficiente rispetto all'aggiornamento di numerosi DAG. Abbiamo facilitato l'adozione aggiornando noi stessi le istanze Amazon MWAA, documentando i problemi e condividendo risultati e stime dell'impegno per un'accurata pianificazione dell'aggiornamento.
- Operatore EMR di GoDaddy - Per semplificare la migrazione di numerosi DAG Airflow da EMR su EC2 a EMR Serverless, abbiamo sviluppato operatori personalizzati adattando le interfacce esistenti. Ciò ha consentito transizioni fluide pur mantenendo le opzioni di ottimizzazione familiari. I data engineer potrebbero facilmente migrare le pipeline con semplici importazioni di ricerca e sostituzione e utilizzare immediatamente EMR Serverless.
Mitigazione del comportamento imprevisto
Di seguito sono riportati i comportamenti imprevisti in cui ci siamo imbattuti e cosa abbiamo fatto per mitigarli:
- Ridimensionamento aggressivo di Spark DRA - Per alcuni lavori (8.33% dei benchmark iniziali, 13.6% della produzione), i costi sono aumentati dopo la migrazione a EMR Serverless. Ciò era dovuto al fatto che Spark DRA assegnava in modo eccessivo nuovi lavoratori per brevi periodi, dando priorità alle prestazioni rispetto ai costi. Per contrastare questo problema, impostiamo le soglie massime dell'esecutore mediante aggiustamento
spark.dynamicAllocation.maxExecutor, limitando efficacemente l'aggressività del ridimensionamento EMR Serverless. Durante la migrazione da EMR su EC2, suggeriamo di osservare il numero massimo di core nell'interfaccia utente di Spark History per replicare limiti di calcolo simili in EMR Serverless, come ad esempio--conf spark.executor.coresed--conf spark.dynamicAllocation.maxExecutors. - Gestione dello spazio su disco per lavori su larga scala - Durante la transizione di processi che elaborano grandi volumi di dati con mescolamenti sostanziali e requisiti di disco significativi a EMR Serverless, si consiglia di configurare
spark.emr-serverless.executor.diskfacendo riferimento alle metriche del lavoro Spark esistenti. Inoltre, configurazioni comespark.executor.corescombinato conspark.emr-serverless.executor.diskedspark.dynamicAllocation.maxExecutorsconsentire il controllo sulle dimensioni del lavoratore sottostante e sullo spazio di archiviazione totale collegato quando vantaggioso. Ad esempio, un lavoro con uso intensivo della riproduzione casuale con un utilizzo del disco relativamente basso può trarre vantaggio dall'utilizzo di un lavoratore più grande per aumentare la probabilità di recuperi casuali locali.
Conclusione
Come discusso in questo post, le nostre esperienze con l'adozione di EMR Serverless su arm64 sono state estremamente positive. Gli straordinari risultati che abbiamo ottenuto, tra cui una riduzione del 60% dei costi, un'esecuzione più veloce del 50% dei carichi di lavoro Spark batch e un sorprendente miglioramento di cinque volte nella velocità di sviluppo e test, la dicono lunga sul potenziale di questa tecnologia. Inoltre, i nostri risultati attuali suggeriscono che adottando ampiamente Graviton2 su EMR Serverless, potremmo potenzialmente ridurre l’impronta di carbonio fino al 60% per la nostra elaborazione batch.
Tuttavia, è fondamentale capire che questi risultati non rappresentano uno scenario valido per tutti. I miglioramenti che puoi aspettarti sono soggetti a fattori tra cui, a titolo esemplificativo, la natura specifica dei flussi di lavoro, le configurazioni dei cluster, i livelli di utilizzo delle risorse e le fluttuazioni della capacità di calcolo. Pertanto, quando si considera l'integrazione di EMR Serverless, sosteniamo fortemente una strategia di distribuzione basata sui dati e ad anello, che può aiutare a ottimizzarne al massimo i vantaggi.
Un ringraziamento speciale a Mukul sharma ed Boris Berlino per il loro contributo al benchmarking. Molte grazie a Travis Muhlestein (CDO), Abhijit Kundu (VP Ing.), Vincenzo Yung (Sr. Direttore Ing.), e Wai Kin Lau (Sr. Director Data Eng.) per il loro continuo supporto.
Informazioni sugli autori
 Brandon Abear è Principal Data Engineer nell'organizzazione Data & Analytics (DnA) di GoDaddy. Gli piacciono tutti i big data. Nel tempo libero gli piace viaggiare, guardare film e giocare a giochi di ritmo.
Brandon Abear è Principal Data Engineer nell'organizzazione Data & Analytics (DnA) di GoDaddy. Gli piacciono tutti i big data. Nel tempo libero gli piace viaggiare, guardare film e giocare a giochi di ritmo.
 Dinesh Sharma è Principal Data Engineer nell'organizzazione Data & Analytics (DnA) di GoDaddy. È appassionato dell'esperienza utente e della produttività degli sviluppatori, sempre alla ricerca di modi per ottimizzare i processi di progettazione e risparmiare sui costi. Nel tempo libero ama leggere ed è un appassionato fan dei manga.
Dinesh Sharma è Principal Data Engineer nell'organizzazione Data & Analytics (DnA) di GoDaddy. È appassionato dell'esperienza utente e della produttività degli sviluppatori, sempre alla ricerca di modi per ottimizzare i processi di progettazione e risparmiare sui costi. Nel tempo libero ama leggere ed è un appassionato fan dei manga.
 Giovanni Bush è Principal Software Engineer nell'organizzazione Data & Analytics (DnA) di GoDaddy. La sua passione è rendere più semplice per le organizzazioni la gestione dei dati e il loro utilizzo per far avanzare le proprie attività. Nel tempo libero ama fare escursioni, campeggiare e andare in bicicletta.
Giovanni Bush è Principal Software Engineer nell'organizzazione Data & Analytics (DnA) di GoDaddy. La sua passione è rendere più semplice per le organizzazioni la gestione dei dati e il loro utilizzo per far avanzare le proprie attività. Nel tempo libero ama fare escursioni, campeggiare e andare in bicicletta.
 Ozcan Ilikhan è il direttore dell'ingegneria per la piattaforma dati e ML di GoDaddy. Ha oltre due decenni di esperienza di leadership multidisciplinare, che spazia dalle startup alle imprese globali. Ha una passione per lo sfruttamento dei dati e dell'intelligenza artificiale nella creazione di soluzioni che soddisfano i clienti, consentono loro di ottenere di più e aumentano l'efficienza operativa. Al di fuori della sua vita professionale, gli piace leggere, fare escursioni, fare giardinaggio, fare volontariato e intraprendere progetti fai-da-te.
Ozcan Ilikhan è il direttore dell'ingegneria per la piattaforma dati e ML di GoDaddy. Ha oltre due decenni di esperienza di leadership multidisciplinare, che spazia dalle startup alle imprese globali. Ha una passione per lo sfruttamento dei dati e dell'intelligenza artificiale nella creazione di soluzioni che soddisfano i clienti, consentono loro di ottenere di più e aumentano l'efficienza operativa. Al di fuori della sua vita professionale, gli piace leggere, fare escursioni, fare giardinaggio, fare volontariato e intraprendere progetti fai-da-te.
 Harsh Vardhan è un AWS Solutions Architect, specializzato in big data e analisi. Ha oltre 8 anni di esperienza di lavoro nel campo dei big data e della data science. La sua passione è aiutare i clienti ad adottare le migliori pratiche e scoprire approfondimenti dai loro dati.
Harsh Vardhan è un AWS Solutions Architect, specializzato in big data e analisi. Ha oltre 8 anni di esperienza di lavoro nel campo dei big data e della data science. La sua passione è aiutare i clienti ad adottare le migliori pratiche e scoprire approfondimenti dai loro dati.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/how-the-godaddy-data-platform-achieved-over-60-cost-reduction-and-50-performance-boost-by-adopting-amazon-emr-serverless/

