Il volume dei dati generati a livello globale continua ad aumentare, dai giochi, alla vendita al dettaglio e alla finanza, alla produzione, all’assistenza sanitaria e ai viaggi. Le organizzazioni sono alla ricerca di nuovi modi per utilizzare rapidamente il costante flusso di dati per innovare per le proprie aziende e i propri clienti. Devono acquisire, elaborare, analizzare e caricare in modo affidabile i dati in una miriade di archivi dati, il tutto in tempo reale.
Apache Kafka è una scelta popolare per queste esigenze di streaming in tempo reale. Tuttavia, può essere difficile configurare un cluster Kafka insieme ad altri componenti di elaborazione dati che si adattano automaticamente in base alle esigenze dell'applicazione. Si rischia di effettuare un provisioning insufficiente per i picchi di traffico, che può portare a tempi di inattività, o un provisioning eccessivo per il carico di base, con conseguenti sprechi. AWS offre più servizi serverless come Streaming gestito da Amazon per Apache Kafka (Amazzonia MSK), Amazon Data Firehose, Amazon DynamoDBe AWS Lambda che si ridimensiona automaticamente in base alle tue esigenze.
In questo post spieghiamo come utilizzare alcuni di questi servizi, tra cui MSK senza server, per creare una piattaforma dati serverless in grado di soddisfare le tue esigenze in tempo reale.
Panoramica della soluzione
Immaginiamo uno scenario. Sei responsabile della gestione di migliaia di modem per un provider di servizi Internet distribuito in più aree geografiche. Desideri monitorare la qualità della connettività del modem che ha un impatto significativo sulla produttività e sulla soddisfazione dei clienti. La tua distribuzione include diversi modem che devono essere monitorati e mantenuti per garantire tempi di inattività minimi. Ogni dispositivo trasmette migliaia di record da 1 KB ogni secondo, come l'utilizzo della CPU, l'utilizzo della memoria, l'allarme e lo stato della connessione. Desideri l'accesso in tempo reale a questi dati in modo da poter monitorare le prestazioni in tempo reale e rilevare e mitigare rapidamente i problemi. È inoltre necessario un accesso a lungo termine a questi dati per i modelli di machine learning (ML) per eseguire valutazioni di manutenzione predittiva, trovare opportunità di ottimizzazione e prevedere la domanda.
I tuoi clienti che raccolgono i dati in loco sono scritti in Python e possono inviare tutti i dati come argomenti Apache Kafka ad Amazon MSK. Per l'accesso ai dati a bassa latenza e in tempo reale della tua applicazione, puoi utilizzare Lambda e DynamoDB. Per l'archiviazione dei dati a lungo termine, è possibile utilizzare il servizio connettore serverless gestito Amazon Data Firehose per inviare dati al tuo data Lake.
Il diagramma seguente mostra come creare questa applicazione serverless end-to-end.
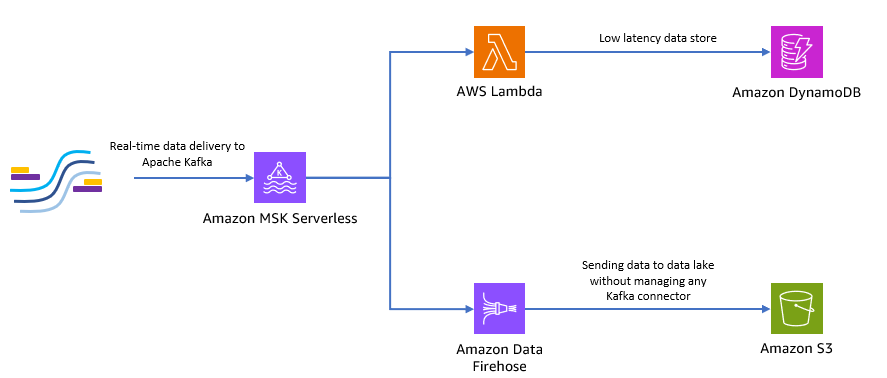
Seguiamo i passaggi nelle sezioni seguenti per implementare questa architettura.
Crea un cluster Kafka serverless su Amazon MSK
Utilizziamo Amazon MSK per acquisire dati di telemetria in tempo reale dai modem. La creazione di un cluster Kafka serverless è semplice su Amazon MSK. Ci vogliono solo pochi minuti utilizzando il Console di gestione AWS o SDK AWS. Per utilizzare la console, fare riferimento a Iniziare a utilizzare i cluster MSK Serverless. Crei un cluster serverless, Gestione dell'identità e dell'accesso di AWS (IAM) e macchina client.
Crea un argomento Kafka utilizzando Python
Quando il cluster e la macchina client sono pronti, esegui SSH sulla macchina client e installa Kafka Python e la libreria MSK IAM per Python.
- Esegui i comandi seguenti per installare Kafka Python e il file Libreria MSK IAM:
- Crea un nuovo file chiamato
createTopic.py. - Copia il seguente codice in questo file, sostituendo il file
bootstrap_serversedregioninformazioni con i dettagli del tuo cluster. Per istruzioni su come recuperare il filebootstrap_serversinformazioni per il tuo cluster MSK, vedi Ottenere i broker bootstrap per un cluster Amazon MSK.
- Corri il
createTopic.pyscript per creare un nuovo argomento Kafka chiamatomytopicsul tuo cluster serverless:
Produrre record utilizzando Python
Generiamo alcuni dati di telemetria del modem di esempio.
- Crea un nuovo file chiamato
kafkaDataGen.py. - Copia il seguente codice in questo file, aggiornando il file
BROKERSedregioninformazioni con i dettagli per il tuo cluster:
- Corri il
kafkaDataGen.pyper generare continuamente dati casuali e pubblicarli nell'argomento Kafka specificato:
Archiviare eventi in Amazon S3
Ora memorizzi tutti i dati grezzi degli eventi in un file Servizio di archiviazione semplice Amazon (Amazon S3) data Lake per l'analisi. Puoi utilizzare gli stessi dati per addestrare modelli ML. IL integrazione con Amazon Data Firehose consente ad Amazon MSK di caricare facilmente i dati dai cluster Apache Kafka in un data Lake S3. Completa i seguenti passaggi per eseguire lo streaming continuo dei dati da Kafka ad Amazon S3, eliminando la necessità di creare o gestire le tue applicazioni di connessione:
- Nella console Amazon S3, crea un nuovo bucket. Puoi anche utilizzare un bucket esistente.
- Crea una nuova cartella nel tuo bucket S3 chiamata
streamingDataLake. - Nella console Amazon MSK, scegli il tuo cluster MSK Serverless.
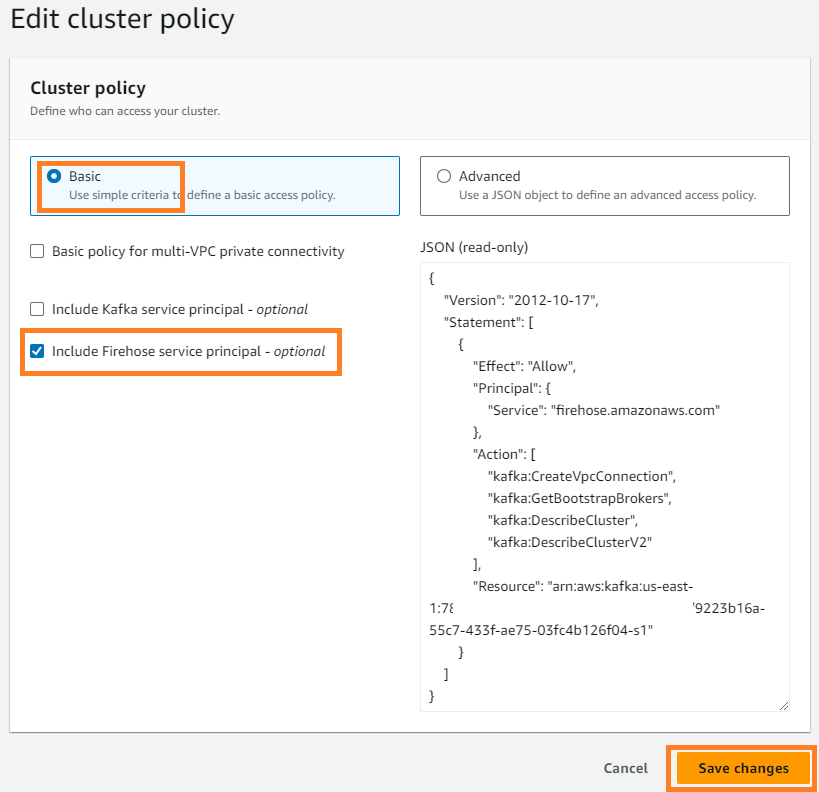
- Sulla Azioni menù, scegliere Modifica criterio cluster.

- Seleziona Includere l'entità servizio Firehose e scegli Salvare le modifiche.
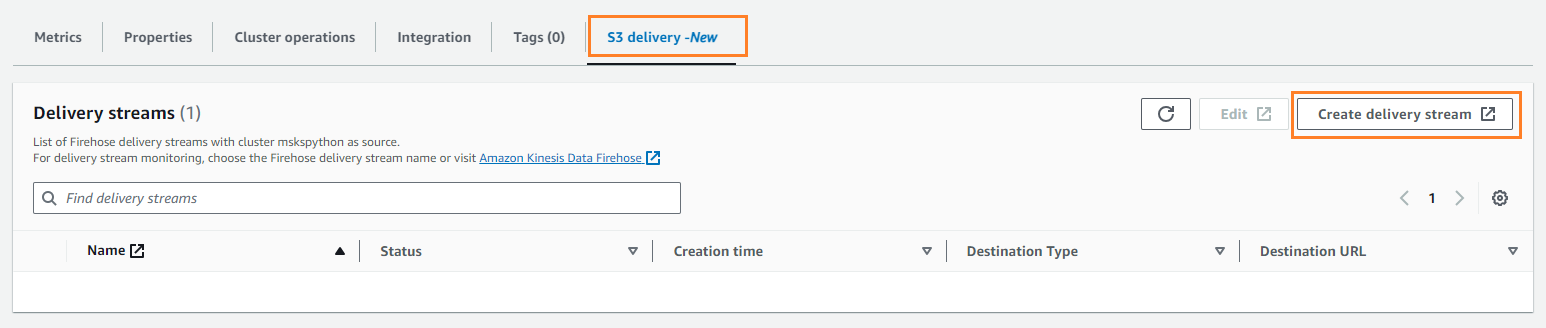
- Sulla Consegna S3 scheda, scegliere Crea flusso di consegna.
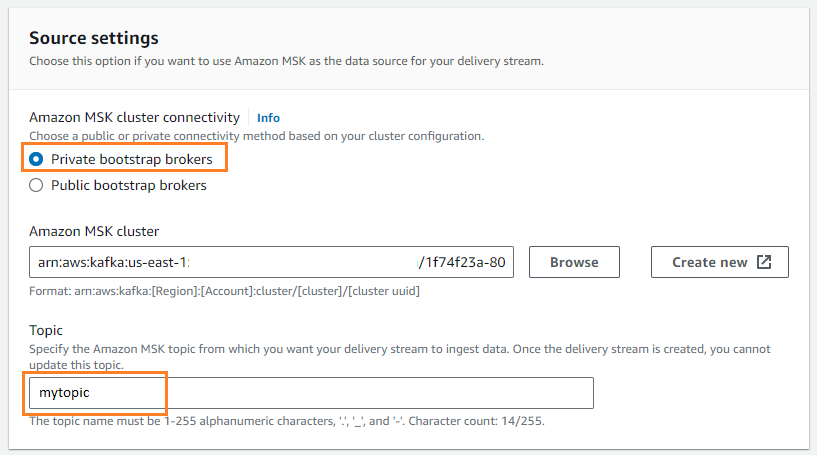
- Nel Fontescegli AmazonMSK.
- Nel Nei Dintorniscegli Amazon S3.

- Nel Connettività del cluster Amazon MSK, selezionare Broker di bootstrap privati.
- Nel Argomento, inserisci il nome di un argomento (per questo post,
mytopic).
- Nel Benna S3scegli Scopri la nostra gamma di prodotti e scegli il tuo secchio S3.
- entrare
streamingDataLakecome prefisso del bucket S3. - entrare
streamingDataLakeErrcome prefisso di output dell'errore del bucket S3.

- Scegli Crea flusso di consegna.
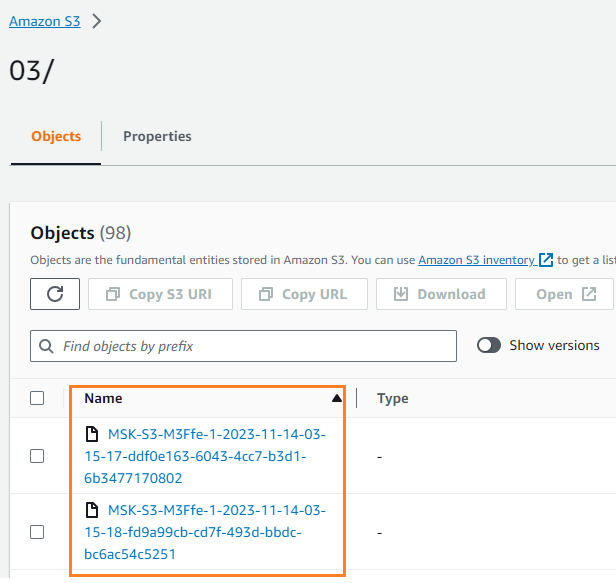
Puoi verificare che i dati siano stati scritti nel tuo bucket S3. Dovresti vedere che il streamingDataLake è stata creata la directory e i file sono archiviati in partizioni.
Archivia gli eventi in DynamoDB
Nell'ultimo passaggio, memorizzi i dati del modem più recenti in DynamoDB. Ciò consente all'applicazione client di accedere allo stato del modem e interagire con il modem in remoto da qualsiasi luogo, con bassa latenza e disponibilità elevata. Lambda funziona perfettamente con Amazon MSK. Lambda esegue internamente il polling dei nuovi messaggi dall'origine dell'evento e quindi richiama in modo sincrono la funzione Lambda di destinazione. Lambda legge i messaggi in batch e li fornisce alla tua funzione come payload dell'evento.
Creiamo innanzitutto una tabella in DynamoDB. Fare riferimento a Autorizzazioni API DynamoDB: riferimento ad azioni, risorse e condizioni per verificare che il computer client disponga delle autorizzazioni necessarie.
- Crea un nuovo file chiamato
createTable.py. - Copia il seguente codice nel file, aggiornando il file
regioninformazioni:
- Corri il
createTable.pyscript per creare una tabella chiamatadevice_statusin DynamoDB:
Ora configuriamo la funzione Lambda.
- Sulla console Lambda, selezionare funzioni nel pannello di navigazione.
- Scegli Crea funzione.
- Seleziona Autore da zero.
- Nel Nome della funzioneinserire un nome (ad esempio,
my-notification-kafka). - Nel Runtimescegli Python 3.11.
- Nel Permessi, selezionare Usa un ruolo esistente e scegli un ruolo con autorizzazioni per leggere dal tuo cluster.
- Crea la funzione.
Nella pagina di configurazione della funzione Lambda ora puoi configurare origini, destinazioni e il codice dell'applicazione.
- Scegli Aggiungi trigger.
- Nel Configurazione trigger, accedere
MSKper configurare Amazon MSK come trigger per la funzione di origine Lambda. - Nel Cluster MSK, accedere
myCluster. - Deseleziona Attiva il grilletto, perché non hai ancora configurato la funzione Lambda.
- Nel Dimensione del lotto, accedere
100. - Nel Posizione di partenzascegli Ultime.
- Nel Nome argomentoinserire un nome (ad esempio,
mytopic). - Scegli Aggiungi.
- Nella pagina dei dettagli della funzione Lambda, nel file Code scheda, inserisci il seguente codice:
- Distribuisci la funzione Lambda.
- Sulla Configurazione scheda, scegliere Modifica per modificare il trigger.
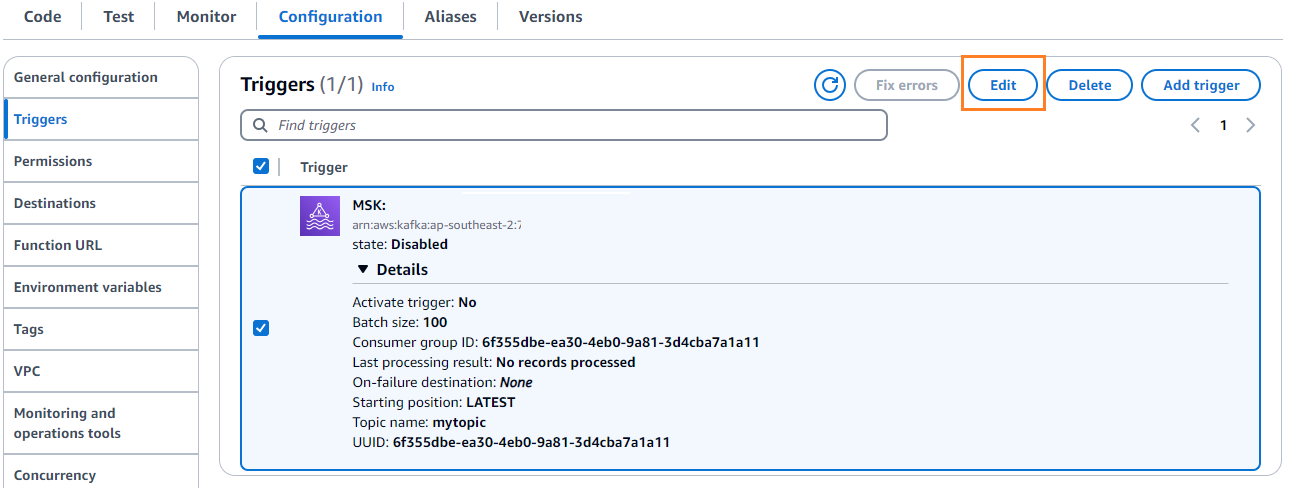
- Seleziona il trigger, quindi scegli Risparmi.
- Sulla console DynamoDB, scegli Esplora gli elementi nel pannello di navigazione.
- Seleziona la tabella
device_status.
Vedrai che Lambda sta scrivendo gli eventi generati nell'argomento Kafka su DynamoDB.

Sommario
Le pipeline di dati in streaming sono fondamentali per la creazione di applicazioni in tempo reale. Tuttavia, la creazione e la gestione dell’infrastruttura possono essere scoraggianti. In questo post, abbiamo illustrato come creare una pipeline di streaming serverless su AWS utilizzando Amazon MSK, Lambda, DynamoDB, Amazon Data Firehose e altri servizi. I vantaggi principali sono l'assenza di server da gestire, la scalabilità automatica dell'infrastruttura e un modello pay-as-you-go che utilizza servizi completamente gestiti.
Pronto a costruire la tua pipeline in tempo reale? Inizia oggi con un account AWS gratuito. Con la potenza del serverless, puoi concentrarti sulla logica della tua applicazione mentre AWS gestisce il lavoro pesante indifferenziato. Costruiamo qualcosa di fantastico su AWS!
Informazioni sugli autori
 Masudur Rahaman Sayem è uno Streaming Data Architect presso AWS. Lavora con i clienti AWS a livello globale per progettare e costruire architetture di streaming di dati per risolvere problemi aziendali reali. È specializzato nell'ottimizzazione di soluzioni che utilizzano servizi di dati in streaming e NoSQL. Sayem è molto appassionato di calcolo distribuito.
Masudur Rahaman Sayem è uno Streaming Data Architect presso AWS. Lavora con i clienti AWS a livello globale per progettare e costruire architetture di streaming di dati per risolvere problemi aziendali reali. È specializzato nell'ottimizzazione di soluzioni che utilizzano servizi di dati in streaming e NoSQL. Sayem è molto appassionato di calcolo distribuito.
 Michael Oguike è un Product Manager per Amazon MSK. La sua passione è l'utilizzo dei dati per scoprire informazioni che guidano l'azione. Gli piace aiutare i clienti di un'ampia gamma di settori a migliorare le loro attività utilizzando lo streaming di dati. Michael ama anche conoscere la scienza comportamentale e la psicologia da libri e podcast.
Michael Oguike è un Product Manager per Amazon MSK. La sua passione è l'utilizzo dei dati per scoprire informazioni che guidano l'azione. Gli piace aiutare i clienti di un'ampia gamma di settori a migliorare le loro attività utilizzando lo streaming di dati. Michael ama anche conoscere la scienza comportamentale e la psicologia da libri e podcast.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-serverless-streaming-pipeline-with-apache-kafka-on-amazon-msk-using-python/

