Introduzione
Intelligenza Artificiale ha molti casi d'uso e alcuni dei migliori si trovano nel settore sanitario. Può davvero aiutare le persone a mantenere una vita più sana. Con il crescente boom in IA generativa, oggigiorno alcune applicazioni vengono realizzate con meno complessità. Un'applicazione molto utile che può essere creata è l'app Calorie Advisor. In questo articolo ci occuperemo solo di questo, ispirati dalla cura della nostra salute. Costruiremo una semplice app Calorie Advisor in cui possiamo inserire le immagini del cibo e l'app ci aiuterà a calcolare le calorie di ciascun elemento presente nel cibo. Questo progetto fa parte di NutriGen, focalizzato sulla salute attraverso l’intelligenza artificiale.

Obiettivo di apprendimento
- L'app che creeremo in questo articolo si baserà sulle tecniche di base di Prompt Engineering e di elaborazione delle immagini.
- Utilizzeremo l'API Google Gemini Pro Vision per il nostro caso d'uso.
- Quindi, creeremo la struttura del codice, dove eseguiremo l'elaborazione delle immagini e il prompt engineering. Infine, lavoreremo sull'interfaccia utente utilizzando Streamlit.
- Successivamente, distribuiremo la nostra app nel file Abbracciare il viso Piattaforma gratuita.
- Vedremo anche alcuni dei problemi che dovremo affrontare nell'output in cui Gemini non riesce a rappresentare un alimento e fornisce il conteggio calorico errato per quel cibo. Discuteremo anche diverse soluzioni per questo problema.
Pre-requisiti
Iniziamo con l'implementazione del nostro progetto, ma prima assicurati di avere una conoscenza di base dell'intelligenza artificiale generativa e dei LLM. Non va bene se sai molto poco perché, in questo articolo, implementeremo le cose da zero.
Per Essential Python Prompt Engineering, è richiesta una conoscenza di base dell'intelligenza artificiale generativa e familiarità con Google Gemini. Inoltre, conoscenza di base di Snello, Githube Abbracciare il viso le biblioteche sono necessarie. È utile anche la familiarità con librerie come PIL per scopi di preelaborazione delle immagini.
Questo articolo è stato pubblicato come parte di Blogathon sulla scienza dei dati.
Sommario
Pipeline di progetto
In questo articolo lavoreremo alla creazione di un assistente AI che assista nutrizionisti e individui nel prendere decisioni informate sulle loro scelte alimentari e nel mantenere uno stile di vita sano.
Il flusso sarà questo: immagine di input -> elaborazione dell'immagine -> ingegneria rapida -> chiamata della funzione finale per ottenere l'output dell'immagine di input del cibo. Questa è una breve panoramica di come affronteremo questa affermazione del problema.
Panoramica di Gemini Pro Vision
Gemelli Pro è un multimodale LLM costruito da Google. È stato addestrato per essere multimodale da zero. Può eseguire bene varie attività, tra cui didascalie di immagini, classificazione, riepilogo, risposta alle domande, ecc. Uno dei fatti affascinanti è che utilizza la nostra famosa architettura Transformer Decoder. È stato addestrato su più tipi di dati, riducendo la complessità della risoluzione di input multimodali e fornendo risultati di qualità.
Passaggio 1: creazione dell'ambiente virtuale
Creare un ambiente virtuale è una buona pratica per isolare il nostro progetto e le sue dipendenze in modo tale che non coincidano con gli altri e possiamo sempre avere versioni diverse delle librerie di cui abbiamo bisogno in diversi ambienti virtuali. Quindi, creeremo ora un ambiente virtuale per il progetto. Per fare ciò, seguire i passaggi indicati di seguito:
- Crea una cartella vuota sul desktop per il progetto.
- Apri questa cartella in VS Code.
- Apri il terminale
Scrivi il seguente comando:
pip install virtualenv
python -m venv genai_projectPuoi utilizzare il seguente comando se ricevi un errore di policy di esecuzione sa et:
Set-ExecutionPolicy RemoteSigned -Scope ProcessOra dobbiamo attivare il nostro ambiente virtuale, per questo utilizziamo il seguente comando:
.genai_projectScriptsactivateAbbiamo creato con successo il nostro ambiente virtuale.
Passaggio Crea un ambiente virtuale in Google Colab
Possiamo anche creare il nostro ambiente virtuale in Google Colab; ecco la procedura passo passo per farlo:
- Crea un nuovo taccuino Colab
- Utilizza i comandi seguenti passo dopo passo
!which python
!python --version
#to check if python is installed or not%env PYTHONPATH=
# setting python path environment variable in empty value ensuring that python
# won't search for modules and packages in additional directory. It helps
# in avoiding conflicts or unintended module loading.!pip install virtualenv # create virtual environment
!virtualenv genai_project!wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
#This will help download the miniconda installer script which is used to create
# and manage virtual environments in python!chmod +x Miniconda3-latest-Linux-x86_64.sh
# this command is making our mini conda installer script executable within
# the colab environment. !./Miniconda3-latest-Linux-x86_64.sh -b -f -p /usr/local
# this is used to run miniconda installer script and
# specify the path where miniconda should be installed!conda install -q -y --prefix /usr/local python=3.8 ujson
#this will help install ujson and python 3.8 installation in our venv.import sys
sys.path.append('/usr/local/lib/python3.8/site-packages/')
#it will allow python to locate and import modules from a venv directoryimport os
os.environ['CONDA_PREFIX'] = '/usr/local/envs/myenv'
# used to activate miniconda enviornment
!python --version
#checks the version of python within the activated miniconda environmentPertanto, abbiamo anche creato il nostro ambiente virtuale in Google Colab. Ora controlliamo e vediamo come possiamo creare un file .py di base lì.
!source myenv/bin/activate
#activating the virtual environment!echo "print('Hello, world!')" >> my_script.py
# writing code using echo and saving this code in my_script.py file!python my_script.py
#running my_script.py fileQuesto stamperà Hello World per noi nell'output. Quindi è tutto. Si trattava di lavorare con gli ambienti virtuali in Google Colab. Ora continuiamo con il progetto.
Passaggio 2: importazione delle librerie necessarie
import streamlit as st
import google.generativeaias genai
import os
from dotenv import load_dotenv
load_dotenv()
from PIL import ImageSe riscontri problemi nell'importazione di una delle librerie di cui sopra, puoi sempre utilizzare il comando "pip install nome_libreria" per installarla.
Utilizziamo la libreria Streamlit per creare l'interfaccia utente di base. L'utente potrà caricare un'immagine e ottenere gli output basati su quell'immagine.
Utilizziamo Google Generative per ottenere il LLM e analizzare l'immagine per ottenere il conteggio delle calorie per articolo nel nostro cibo.
L'immagine viene utilizzata per eseguire alcune operazioni preliminari di base dell'immagine.
Passaggio 3: impostazione della chiave API
Crea un nuovo file .env nella stessa directory e memorizza la chiave API. Puoi ottenere Google API Gemelli chiave da GoogleMakerSuite.
Passaggio 4: funzione del generatore di risposta
Qui creeremo una funzione di generatore di risposte. Analizziamolo passo dopo passo:
Innanzitutto abbiamo utilizzato i geni. Configura per configurare l'API che abbiamo creato dal sito Web di Google MakerSuite. Quindi, abbiamo creato la funzione get_gemini_response, che accetta 2 parametri di input: il prompt di input e l'immagine. Questa è la funzione principale che restituirà l'output in formato testo.
genai.configure(api_key=os.getenv("GOOGLE_API_KEY"))
def get_gemini_response(input_prompt, image):
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content([input_prompt, image[0]])
return responseQui utilizziamo il modello “Gemini-pro-vision” perché è multimodale. Dopo aver chiamato il nostro modello dalla dipendenza genie.GenerativeModel, stiamo semplicemente passando il nostro prompt e i dati dell'immagine al modello. Infine, in base alle istruzioni fornite nel prompt e ai dati dell'immagine forniti, il modello restituirà l'output sotto forma di testo che rappresenta il conteggio delle calorie dei diversi alimenti presenti nell'immagine.
Passaggio 5: preelaborazione delle immagini
Questa funzione controlla se il parametro uploaded_file è None, il che significa che l'utente ha caricato un file. Se un file è stato caricato, il codice procede alla lettura del contenuto del file in byte utilizzando il metodo getvalue() dell'oggetto uploaded_file. Ciò restituirà i byte grezzi del file caricato.
I dati in byte ottenuti dal file caricato vengono archiviati in un formato dizionario nella coppia chiave-valore "mime_type" e "data". La chiave "mime_type" memorizza il tipo MIME del file caricato, che indica il tipo di contenuto (ad esempio, immagine/jpeg, immagine/png). La chiave "data" memorizza i byte grezzi del file caricato.
I dati dell'immagine vengono quindi archiviati in un elenco denominato image_parts, che contiene un dizionario con il tipo MIME e i dati del file caricato.
def input_image_setup(uploaded_file):
if uploaded_file isnotNone:
#Read the file into bytes
bytes_data = uploaded_file.getvalue()
image_parts = [
{
"mime_type":uploaded_file.type,
"data":bytes_data
}
]
return image_parts
else:
raise FileNotFoundError("No file uploaded")
Passaggio 6: creazione dell'interfaccia utente
Quindi, finalmente, è il momento di creare l'interfaccia utente per il nostro progetto. Come accennato in precedenza, utilizzeremo la libreria Streamlit per scrivere il codice per il front-end.
## initialising the streamlit app
st.set_page_config(page_title="Calories Advisor App")
st.header("Calories Advisor App")
uploaded_file = st.file_uploader("Choose an image...", type=["jpg", "jpeg", "png"])
image = ""
if uploaded_file isnotNone:
image = Image.open(uploaded_file)
st.image(image, caption="Uploaded Image", use_column_width=True)
submit = st.button("Tell me about the total calories")Inizialmente, abbiamo impostato la configurazione della pagina utilizzando set_page_config e abbiamo assegnato un titolo all'app. Quindi, abbiamo creato un'intestazione e aggiunto una casella di caricamento file in cui gli utenti possono caricare immagini. St. Image mostra l'immagine che l'utente ha caricato nell'interfaccia utente. Infine, c'è un pulsante di invio, dopo il quale otterremo gli output dal nostro modello linguistico di grandi dimensioni, Gemini Pro Vision.
Passaggio 7: scrittura del prompt di sistema
Ora è il momento di essere creativi. Qui creeremo il nostro prompt di input, chiedendo al modello di agire come un nutrizionista esperto. Non è necessario utilizzare il prompt riportato di seguito; puoi anche fornire il tuo prompt personalizzato. Chiediamo al nostro modello di agire in un certo modo per ora. Sulla base dell'immagine in input del cibo fornito, chiediamo al nostro modello di leggere i dati dell'immagine e generare l'output, che ci fornirà il conteggio delle calorie degli alimenti presenti nell'immagine e fornirà un giudizio sulla salubrità del cibo o malsano. Se il cibo è dannoso, gli chiediamo di fornire alternative più nutrienti agli alimenti a nostra immagine. Puoi personalizzarlo maggiormente in base alle tue esigenze e ottenere un ottimo modo per tenere traccia della tua salute.
A volte potrebbe non essere in grado di leggere correttamente i dati dell'immagine, discuteremo le soluzioni al riguardo anche alla fine di questo articolo.
input_prompt = """
You are an expert nutritionist where you need to see the food items from the
image and calculate the total calories, also give the details of all
the food items with their respective calorie count in the below fomat.
1. Item 1 - no of calories
2. Item 2 - no of calories
----
----
Finally you can also mention whether the food is healthy or not and also mention
the percentage split ratio of carbohydrates, fats, fibers, sugar, protein and
other important things required in our diet. If you find that food is not healthy
then you must provide some alternative healthy food items that user can have
in diet.
"""
if submit:
image_data = input_image_setup(uploaded_file)
response = get_gemini_response(input_prompt, image_data)
st.header("The Response is: ")
st.write(response)Infine, stiamo verificando che se l'utente fa clic sul pulsante Invia, otterremo i dati dell'immagine dal file
input_image_setup che abbiamo creato in precedenza. Quindi, passiamo il nostro prompt di input e questi dati di immagine alla funzione get_gemini_response che abbiamo creato in precedenza. Chiamiamo tutte le funzioni che abbiamo creato in precedenza per ottenere l'output finale memorizzato in risposta.
Passaggio 8: distribuzione dell'app su Hugging Face
Adesso è il momento dello schieramento. Cominciamo.
Spiegherà il modo più semplice per distribuire questa app che abbiamo creato. Esistono due opzioni che possiamo esaminare se vogliamo distribuire la nostra app: una è Streamlit Share e l'altra è Hugging Face. Qui utilizzeremo Hugging Face per l'implementazione; puoi provare a esplorare la distribuzione su Streamlit Share iFaceu, se lo desideri. Ecco il collegamento di riferimento: Distribuzione su Streamlit Share
Innanzitutto, creiamo rapidamente il file require.txt necessario per la distribuzione.
Apri il terminale ed esegui il comando seguente per creare un file require.txt.
pip freeze > requirements.txt1plainTextCiò creerà un nuovo file di testo denominato requisiti. Tutte le dipendenze del progetto saranno disponibili lì. Se questo causa un errore, va bene. Puoi sempre creare un nuovo file di testo nella tua directory di lavoro e copiare e incollare il file require.txt dal collegamento GitHub che fornirò successivamente.
Ora assicurati di avere questi file a portata di mano (perché è ciò di cui abbiamo bisogno per la distribuzione):
- app.py
- .env (per le credenziali API)
- requirements.txt
Se non ne hai uno, prendi tutti questi file e crea un account su Hugging Face. Quindi, crea un nuovo spazio e carica lì i file. È tutto. La tua app verrà distribuita automaticamente in questo modo. Potrai anche vedere come sta avvenendo la distribuzione in tempo reale. Se si verifica qualche errore, puoi sempre capirlo grazie alla semplice interfaccia e, ovviamente, alla community di Hugging Face, che offre molti contenuti sulla risoluzione di alcuni bug comuni durante la distribuzione.
Dopo un po' di tempo potrai vedere l'app funzionare. Woo-hoo! Abbiamo finalmente creato e distribuito la nostra app per la previsione delle calorie. Congratulazioni!! Puoi condividere il collegamento funzionante dell'app con gli amici e la famiglia che hai appena creato.
Ecco il collegamento funzionante all'app che abbiamo appena creato: The Alorcalorieisor App
Testiamo la nostra app fornendole un'immagine di input:
Prima:
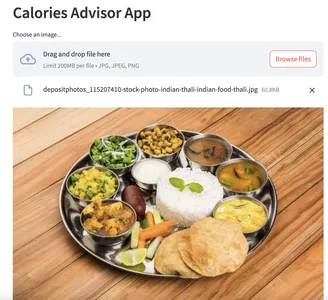
Dopo:

Collegamento GitHub del progetto completo
Ecco il completo collegamento al repository github che include il codice sorgente e altre informazioni utili relative al progetto.
Puoi clonare il repository e personalizzarlo in base alle tue esigenze. Cerca di essere più creativo e chiaro nei tuoi suggerimenti, poiché ciò darà al tuo modello più potere per generare output corretti e adeguati.
Ambito di miglioramento
Problemi che possono verificarsi negli output generati dal modello e relative soluzioni:
A volte potrebbero verificarsi situazioni in cui non si otterrà l'output corretto dal modello. Ciò può accadere perché il modello non è stato in grado di prevedere correttamente l'immagine. Ad esempio, se fornisci immagini del tuo cibo e il tuo prodotto alimentare contiene sottaceti, il nostro modello potrebbe considerarlo qualcos'altro. Questa è la preoccupazione principale qui.
- Un modo per affrontare questo problema è attraverso efficaci tecniche di prompt engineering, come il prompt engineering a pochi scatti, in cui è possibile alimentare il modello con esempi e quindi genererà gli output in base agli insegnamenti di tali esempi e al prompt fornito.
- Un'altra soluzione che può essere presa in considerazione in questo caso è la creazione dei nostri dati personalizzati e la loro messa a punto. Possiamo creare dati contenenti un'immagine dell'alimento in una colonna e una descrizione degli alimenti presenti nell'altra colonna. Ciò aiuterà il nostro modello ad apprendere i modelli sottostanti e a prevedere correttamente gli elementi nell'immagine fornita. Pertanto, è essenziale ottenere risultati più corretti del conteggio delle calorie per le immagini del cibo.
- Possiamo spingerci oltre chiedendo all'utente quali siano i suoi obiettivi nutrizionali e chiedendo al modello di generare risultati basati su questi. (In questo modo, saremo in grado di personalizzare gli output generati dal modello e fornire output più specifici per l'utente.)
Conclusione
Abbiamo approfondito l'applicazione pratica dell'intelligenza artificiale generativa in ambito sanitario, concentrandoci sulla creazione dell'app Calorie Advisor. Questo progetto mostra il potenziale dell’intelligenza artificiale nell’aiutare le persone a prendere decisioni informate sulle loro scelte alimentari e a mantenere uno stile di vita sano. Dalla configurazione del nostro ambiente all'implementazione dell'elaborazione delle immagini e delle tecniche di ingegneria rapida, abbiamo coperto i passaggi essenziali. L'implementazione dell'app su Hugging Face dimostra la sua accessibilità a un pubblico più ampio. Sfide come le imprecisioni nel riconoscimento delle immagini sono state affrontate con soluzioni come un'efficace ingegneria tempestiva. In conclusione, l’app Calorie Advisor testimonia il potere di trasformazione dell’intelligenza artificiale generativa nel promuovere il benessere.
Punti chiave
- Abbiamo discusso molto finora, a partire dalla pipeline del progetto e poi un'introduzione di base al grande modello linguistico Gemini Pro Vision.
- Quindi, abbiamo iniziato con l'implementazione pratica. Abbiamo creato il nostro ambiente virtuale e la chiave API da Google MakerSuite.
- Quindi, abbiamo eseguito tutta la nostra codifica nell'ambiente virtuale creato. Inoltre, abbiamo discusso come distribuire l'app su più piattaforme, come Hugging Face e Streamlit Share.
- Oltre a ciò, abbiamo considerato i possibili problemi che possono verificarsi e abbiamo discusso le soluzioni a tali problemi.
- Quindi è stato divertente lavorare a questo progetto. Grazie per essere rimasto fino alla fine di questo articolo; Spero che tu abbia avuto modo di imparare qualcosa di nuovo.
Domande frequenti
Google ha sviluppato Gemini Pro Vision, un rinomato LLM noto per le sue capacità multimodali. Esegue attività come didascalie, generazione e riepilogo delle immagini. Gli utenti possono creare una chiave API sul sito Web MakerSuite per accedere a Gemini Pro Vision.
R. L’intelligenza artificiale generativa ha un grande potenziale per risolvere i problemi del mondo reale. Alcuni dei modi in cui può essere applicato al settore della salute/nutrizione sono che può aiutare i medici a prescrivere farmaci in base ai sintomi e agire come consulente nutrizionale, dove gli utenti possono ottenere consigli salutari per la loro dieta.
R. La tempestività ingegneristica è una competenza essenziale da padroneggiare al giorno d'oggi. Il posto migliore per imparare l'ingegneria trompt dal livello base all'avanzato è qui: https://www.promptingguide.ai/
R. Per aumentare la capacità del modello di generare output più corretti, possiamo utilizzare le seguenti tattiche: suggerimento efficace, messa a punto e generazione aumentata di recupero (RAG).
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e vengono utilizzati a discrezione dell'autore.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.analyticsvidhya.com/blog/2024/04/how-to-build-a-calorie-advisor-app-using-genai/

