Questo post è stato scritto in collaborazione con Amir Souchami e Fabian Szenkier di Unity.
Aura dell'Unità (precedentemente noto come ironSource) è lo standard di mercato per la creazione di esperienze avanzate con i dispositivi che coinvolgono e fideliscono i clienti. Con un potente set di soluzioni, Aura consente una trasformazione digitale completa, consentendo agli operatori di promuovere servizi chiave al di fuori del negozio, direttamente sul dispositivo.
Amazon RedShift è un servizio consigliato per carichi di lavoro OLAP (Online Analytical Processing) come data warehouse su cloud, data mart e altri archivi di dati analitici. Puoi utilizzare SQL semplice per analizzare dati strutturati e semistrutturati, database operativi e data lake per offrire il miglior rapporto prezzo/prestazioni su qualsiasi scala. IL Condivisione dei dati di Amazon Redshift La funzionalità fornisce un accesso istantaneo, granulare e ad alte prestazioni senza copie e spostamenti dei dati tra più data warehouse Redshift nello stesso account AWS o in account AWS diversi e tra regioni AWS. La condivisione dei dati fornisce accesso in tempo reale ai dati in modo da visualizzare sempre le informazioni più aggiornate e coerenti man mano che vengono aggiornate nel data warehouse.
Amazon Redshift senza server semplifica l'esecuzione e la scalabilità delle analisi in pochi secondi senza la necessità di impostare e gestire cluster di data warehouse. Redshift Serverless effettua automaticamente il provisioning e scala in modo intelligente la capacità del data warehouse per offrire prestazioni rapide anche per i carichi di lavoro più impegnativi e imprevedibili, e paghi solo per ciò che utilizzi. Puoi caricare i tuoi dati e iniziare subito a eseguire query nell'editor di query di Amazon Redshift o nel tuo strumento di business intelligence (BI) preferito e continuare a usufruire del miglior rapporto prezzo/prestazioni e delle familiari funzionalità SQL in un ambiente facile da usare e senza amministrazione .
In questo post, descriviamo la rapida e efficace adozione di Redshift Serverless da parte di Aura, che ha consentito loro di ottimizzare il time-to-market delle campagne pubblicitarie con offerte complessive da 24 ore a 2 ore. Esploriamo perché Aura ha scelto questa soluzione e quali sfide tecnologiche ha contribuito a risolvere.
La pipeline di dati iniziale di Aura
Aura è pioniera nell'utilizzo dei cluster Redshift RA3 con condivisione dei dati per carichi di lavoro di estrazione, trasformazione e caricamento (ETL) e BI. Una delle operazioni di Aura sono le campagne pubblicitarie con offerte. Queste campagne sono ottimizzate utilizzando un processo di offerta basato sull'intelligenza artificiale che richiede l'esecuzione di centinaia di query analitiche per campagna. Queste query vengono eseguite sui dati che risiedono in un cluster Redshift fornito da RA3.
La pipeline integrata è composta da vari servizi AWS:
Il diagramma seguente illustra questa architettura.
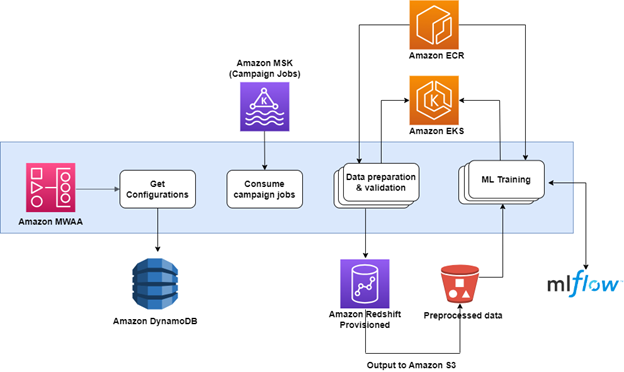
Sfide dell'architettura iniziale
Le query per ciascuna campagna vengono eseguite nel modo seguente:
Innanzitutto, una query di preparazione filtra e aggrega i dati grezzi, preparandoli per l'operazione successiva. Questa è seguita dalla query principale, che esegue la logica in base al set di risultati della query di preparazione.
Con l'aumento del numero di campagne, il team Data di Aura ha dovuto eseguire centinaia di query simultanee per ciascuno di questi passaggi. Il cluster con provisioning esistente di Aura era già ampiamente utilizzato con carichi di lavoro di inserimento dati, ETL e BI, quindi erano alla ricerca di modi economicamente vantaggiosi per isolare questo carico di lavoro con risorse di elaborazione dedicate.
Il team ha valutato una serie di opzioni, tra cui lo scarico dei dati su Amazon S3 e un'architettura multi-cluster che utilizza la condivisione dei dati e Redshift serverless. Il team ha gravitato verso l'architettura multi-cluster con condivisione dei dati, poiché non richiede la riscrittura delle query, consente un'elaborazione dedicata per questo carico di lavoro specifico, evita la necessità di duplicare o spostare i dati dal cluster principale e fornisce elevata concorrenza e scalabilità automatica. Infine, la fatturazione avviene secondo un modello basato sul pagamento in base all'utilizzo e il provisioning è semplice e rapido.
Verifica teorica
Dopo aver valutato le opzioni, il team Data di Aura ha deciso di condurre una prova di concetto utilizzando Redshift Serverless come consumer del cluster principale fornito da Redshift, condividendo solo le tabelle pertinenti per l'esecuzione delle query richieste. Redshift Serverless misura la capacità del data warehouse nelle unità di elaborazione Redshift (RPU). Una singola RPU fornisce 16 GB di memoria e un endpoint serverless può variare da 8 RPU a 512 RPU.
Il team Data di Aura ha avviato la prova di concetto utilizzando un endpoint Serverless Redshift da 256 RPU e ha gradualmente ridotto l'RPU per ridurre i costi assicurandosi al tempo stesso che il tempo di esecuzione delle query fosse inferiore al target richiesto.
Alla fine, il team ha deciso di utilizzare un endpoint Redshift Serverless da 128 RPU (2 TB di RAM) come RPU di base, utilizzando al contempo la funzionalità di ridimensionamento automatico Redshift Serverless, che consente l'esecuzione di centinaia di query simultanee eseguendo automaticamente l'upscaling dell'RPU secondo necessità.
La nuova soluzione di Aura con Redshift Serverless
Dopo una prova di concetto riuscita, la configurazione di produzione includeva l'aggiunta di codice per passare dal cluster Redshift fornito all'endpoint Redshift Serverless. Ciò è stato fatto utilizzando una soglia configurabile in base al numero di query in attesa di essere elaborate in uno specifico argomento MSK consumato all'inizio della pipeline. Le query della campagna su piccola scala verrebbero comunque eseguite sul cluster sottoposto a provisioning e le query su larga scala utilizzerebbero l'endpoint Redshift Serverless. La nuova soluzione utilizza una pipeline Amazon MWAA che recupera informazioni di configurazione da una tabella DynamoDB, utilizza lavori che rappresentano campagne pubblicitarie e quindi esegue centinaia di lavori EKS attivati utilizzando EKSpodOperator. Ogni lavoro esegue le due query seriali (la query di preparazione seguita da una query principale, che restituisce i risultati a Amazon S3). Ciò accade diverse centinaia di volte contemporaneamente utilizzando le risorse di elaborazione Redshift Serverless.
Quindi il processo avvia un altro set di operatori EKSPodOperator per eseguire il codice di addestramento AI in base al risultato dei dati salvato su Amazon S3.
Il diagramma seguente illustra l'architettura della soluzione.
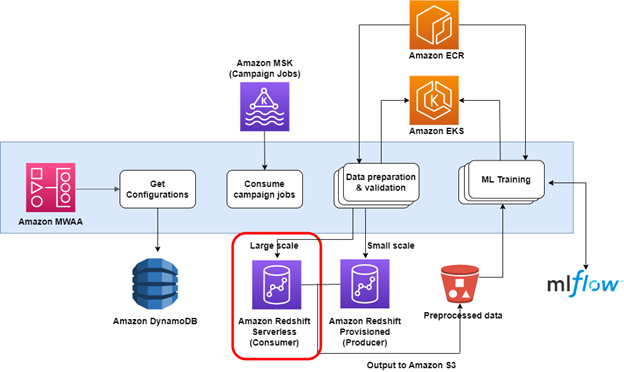
Risultato
L'autonomia complessiva della pipeline è stata ridotta da 24 ore a sole 2 ore, con un miglioramento di 12 volte. Questa integrazione di Redshift Serverless, abbinata alla condivisione dei dati, ha portato a una riduzione del 90% della durata della pipeline, eliminando la necessità di duplicazione dei dati o di riscrittura delle query. Inoltre, l’introduzione di un consumatore dedicato come risorsa di elaborazione esclusiva ha notevolmente alleggerito il carico del cluster produttore, consentendo l’esecuzione di query su piccola scala ancora più velocemente.
"Redshift Serverless e la condivisione dei dati ci hanno permesso di fornire e scalare la nostra capacità di data warehouse per offrire prestazioni rapide, elevata concorrenza e gestire carichi di lavoro ML impegnativi con il minimo sforzo."
– Amir Souchami, Principale Architetto dei Sistemi Tecnici di Aura.
Apprendimenti
Il team Data di Aura è fortemente concentrato nel lavorare in modo economicamente vantaggioso e ha pertanto implementato diversi controlli dei costi nel proprio endpoint Redshift Serverless:
- Limita la spesa complessiva impostando a limite massimo di utilizzo orario RPU (al giorno, alla settimana, al mese) per il gruppo di lavoro. Aura ha configurato tale limite in modo che, quando viene raggiunto, Amazon Redshift invierà un avviso al team di amministratori Amazon Redshift pertinente. Questa funzionalità consente inoltre di scrivere una voce in una tabella di sistema e persino di disattivare le query dell'utente.
- Utilizzare configurazione RPU massima, che definisce il limite superiore delle risorse di calcolo che Redshift Serverless può utilizzare in un dato momento. Quando viene impostato il limite massimo di RPU per il gruppo di lavoro, Redshift Serverless si adatta entro tale limite per continuare a eseguire il carico di lavoro.
- Realizzare regole di monitoraggio delle query che impediscono l'utilizzo dispendioso delle risorse e i costi incontrollati causati da query scritte in modo inadeguato.
Conclusione
Un data warehouse è una parte cruciale di qualsiasi azienda moderna basata sui dati, poiché consente di rispondere a domande aziendali complesse e fornire approfondimenti. L'evoluzione di Amazon Redshift ha consentito ad Aura di adattarsi rapidamente ai requisiti aziendali combinando la condivisione dei dati tra data warehouse forniti e Redshift Serverless. Il viaggio di Aura con Redshift Serverless sottolinea il vasto potenziale dell'integrazione tecnologica strategica nel promuovere l'efficienza e l'eccellenza operativa.
Se il viaggio di Aura ha suscitato il tuo interesse e stai pensando di implementare una soluzione simile nella tua organizzazione, ecco alcuni passaggi strategici da considerare:
- Inizia comprendendo a fondo le esigenze di dati della tua organizzazione e il modo in cui una soluzione di questo tipo può soddisfarle.
- Rivolgiti agli esperti AWS, che possono fornirti indicazioni basate sulle loro esperienze. Prendi in considerazione la possibilità di partecipare a seminari, workshop o forum online che discutono di queste tecnologie. Per iniziare si consigliano le seguenti risorse:
- Una parte importante di questo viaggio sarebbe implementare una prova di concetto. Tale esperienza pratica fornirà preziose informazioni prima di passare alla produzione.
Migliora la tua esperienza con Redshift. Ti stai già godendo la potenza di Amazon Redshift? Migliora il tuo viaggio dei dati con ultime caratteristiche e guida esperta. Rivolgiti al team dedicato del tuo account AWS per ricevere supporto personalizzato, scopri funzionalità all'avanguardia e sblocca un valore ancora maggiore dai tuoi dati con Spostamento rosso Amazon.
Informazioni sugli autori
 Amir Souchami, Chief Architect di Aura presso Unity, focalizzato sulla creazione di sistemi cloud e app mobili resilienti e performanti su larga scala.
Amir Souchami, Chief Architect di Aura presso Unity, focalizzato sulla creazione di sistemi cloud e app mobili resilienti e performanti su larga scala.
 Fabian Szenkier è ML e Big Data Architect presso Aura by Unity, lavora alla creazione di moderne soluzioni AI/ML e pipeline di ingegneria dei dati all'avanguardia su larga scala.
Fabian Szenkier è ML e Big Data Architect presso Aura by Unity, lavora alla creazione di moderne soluzioni AI/ML e pipeline di ingegneria dei dati all'avanguardia su larga scala.
 Liat Tzur è un Senior Technical Account Manager presso Amazon Web Services. Funge da sostenitore del cliente e assiste i suoi clienti nel raggiungimento dell'eccellenza operativa del cloud in linea con i loro obiettivi aziendali.
Liat Tzur è un Senior Technical Account Manager presso Amazon Web Services. Funge da sostenitore del cliente e assiste i suoi clienti nel raggiungimento dell'eccellenza operativa del cloud in linea con i loro obiettivi aziendali.
 Adi Jabkowski è uno specialista Sr. Redshift in EMEA, parte della Worldwide Specialist Organization (WWSO) presso AWS.
Adi Jabkowski è uno specialista Sr. Redshift in EMEA, parte della Worldwide Specialist Organization (WWSO) presso AWS.
 Yonatan Dolan è uno specialista principale di analisi presso Amazon Web Services. Ha sede in Israele e aiuta i clienti a sfruttare i servizi analitici AWS per sfruttare i dati, ottenere informazioni approfondite e ricavare valore.
Yonatan Dolan è uno specialista principale di analisi presso Amazon Web Services. Ha sede in Israele e aiuta i clienti a sfruttare i servizi analitici AWS per sfruttare i dati, ottenere informazioni approfondite e ricavare valore.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/how-aura-from-unity-revolutionized-their-big-data-pipeline-with-amazon-redshift-serverless/

