Ciao!, tecnici, sono sicuro che questo articolo ti aiuterà a capire come usare il notebook Azure Databricks per eseguire operazioni relative ai dati al suo interno. Andiamo!
Databricks
Databricks Data Science & Engineering (a volte chiamato semplicemente "Area di lavoro") è una piattaforma di analisi basata su Apache Spark. È integrato con azzurro, AWS e GCP per fornire una configurazione con un clic, flussi di lavoro semplificati e uno spazio di lavoro interattivo che consente la collaborazione tra ingegneri dei dati, scienziati dei dati e ingegneri dell'apprendimento automatico.
Azure Databricks è una piattaforma di analisi dei dati ottimizzata per la piattaforma dei servizi cloud di Microsoft Azure. Azure Databricks offre due ambienti per lo sviluppo di applicazioni ad alta intensità di dati: Databricks Scienza e ingegneria dei dati, ed Apprendimento automatico di Databricks. Azure è il fornitore di servizi di prima parte di Databricks (il che significa che tutti i servizi di supporto per i databrick saranno forniti da Azure nel proprio cloud). Puoi vedere l'area di lavoro di databrick di seguito: -
Passaggi per creare il servizio Azure Databricks
Pre-requisito
È necessario disporre almeno di un abbonamento al piano gratuito di Azure.
Passo 1: – Aprire il portale di Azure (portal.azure.com)
Passo 2:- Per creare il servizio Databricks è necessario cliccare sull'icona “Crea una Risorsa”.
Passo 2.1:- Ora cerca il "Databrick di Azure" servizio e quindi fare clic sull'opzione crea pulsante.
Passo 2.2:- Ora inserisci i dettagli necessari per la creazione del servizio nella sezione dei dettagli del progetto.
Seleziona il corretto sottoscrizione dal menu a discesa, per me, sto utilizzando una prova gratuita, quindi sceglierò l'opzione predefinita fornita.
Ora devi creare un gruppo di risorse, basta cliccare su crea nuovo se non hai altrimenti scegline uno dalle opzioni a tendina.
Ora devi riempire il Dettagli istanza le sezioni forniscono di seguito
Nome dell'area di lavoro:- fornisci il nome per il tuo spazio di lavoro
Regione:- seleziona la regione che fa per te. Sceglierò quello predefinito.
Fascia di prezzo:- Sceglierò quello standard.
Passo 2.3:- Ora manterrò le impostazioni predefinite e farò clic su Avanti nelle sezioni Networking, Advance e Tag.
Passo 2.4:- Infine, fai clic su “Rivedi + Crea” pulsante.
passaggio 2.5:- Una volta che il messaggio “Convalida superata” is visualizzati, Fare clic sul "creare" pulsante.
passaggio 2.6:- Ora fai clic su vai al servizio e verrai reindirizzato alla pagina del servizio di Azure Databricks fai clic su "Avvia spazio di lavoro" e verrai reindirizzato al tuo spazio di lavoro.
Ora è stato creato il nostro servizio Azure Databricks. È ora di creare un cluster per eseguire il notebook. Creiamo...
Creazione di cluster in Databricks
Passo 1:- Dalle opzioni del menu Fornisci i databrick, fai clic su "Calcola" per creare un cluster.
Passo 2:- Verrai reindirizzato alla pagina di calcolo, qui otterrai 2 tipi di opzioni di creazione del cluster, uno è “Gruppi per tutti gli usi” e l'altro è "Gruppo di lavoro".
Cluster per tutti gli usi:- Essi vengono utilizzati per l'analisi dei dati utilizzando i notebook ed eseguono lavori di importazione e trasformazione dei dati utilizzando i notebook.
Gruppo di lavoro:- Sono utilizzati per eseguire il lavoro o lo scopo di pianificazione dei taccuini per eseguire le operazioni scritte all'interno dei taccuini.
Qui creeremo cluster per tutti gli usi, ora fai clic sul pulsante Crea cluster.
Passo 3:- Ora verrai spostato nella nuova pagina di creazione del cluster. Qui dovrai impostare i seguenti dettagli:-
Nome del cluster:- Scegli il nome che vuoi dare al tuo cluster. Ho dato "blogdemocls".
Modalità cluster:- Qui avrai tre opzioni "Alta concorrenza", "Standard" ed “Singolo nodo”. Attualmente, sono al livello gratuito, quindi sceglierò “Singolo nodo”. Puoi scegliere altre opzioni in base ai tuoi requisiti di elaborazione.
Versione Databricks Runtime:- In questo, ti verranno fornite diverse versioni runtime di Scala e Spark. In questo, sceglierò l'ultima versione con l'opzione LTS (Long Term Support). Puoi scegliere secondo le tue esigenze.
Opzioni del pilota automatico:- In questo è possibile definire il tempo di inattività. Il cluster viene arrestato se diventa inattivo per il tempo di inattività definito.
Nota:- Se scegli un'altra modalità cluster, otterrai altre due opzioni "Tipo di lavoratore" e "Tipo di driver". Ma attualmente siamo al livello gratuito, quindi queste due opzioni sono disabilitate per noi.
Tipo di nodo:- Qui definirai la configurazione della tua macchina di cui hai bisogno per elaborare i tuoi dati. Come quanta memoria e core di cui avevi bisogno. Avrai molte opzioni, indipendentemente dal fatto che la tua necessità sia per scopi di calcolo, memoria o archiviazione, puoi scegliere tra queste. In questo, sceglieremo a Macchina standard D4a_v4 per uso generico con 16 GB di memoria e 4 core. Puoi trovare questa macchina nella categoria Uso generale e quindi fare clic su altre opzioni.
Ora fai clic sul pulsante Crea cluster e attendi la sua creazione. Ora, quando viene creato, fai clic sul pulsante di avvio e verrà avviato in 3-5 minuti.
Creazione di quaderni
Ora il nostro cluster è in esecuzione e creeremo il nostro primo notebook databricks.
Passo 1:- Vai all'area di lavoro e fai clic su di essa, quindi fai clic sulla freccia a discesa nell'area di lavoro e crea una nuova cartella per mantenere tutti i taccuini al suo interno. Chiameremo questa cartella “inshortsnews”.
Passo 2:- Ora fai clic sulla freccia a discesa della cartella "inshortsnews" e fai clic su crea e quindi fai clic sul taccuino.
Passo 2.1:- Ora fornisci tutti i dettagli per la creazione del taccuino come nome, Assegno il nome "inshorts-news-data-scrapping" al nostro taccuino, lingua di default, sceglieremo "Python". Se vuoi puoi anche scegliere tra R, Scala e SQL come lingua predefinita per il tuo progetto.
Passo 2.2:- Fare clic su Crea e il taccuino verrà creato con la lingua fornita.
Inshorts Notizie Rottamazione
Ora esamineremo i dati delle notizie dall'app Web di notizie Inshorts utilizzando Python, Panda e altre librerie.
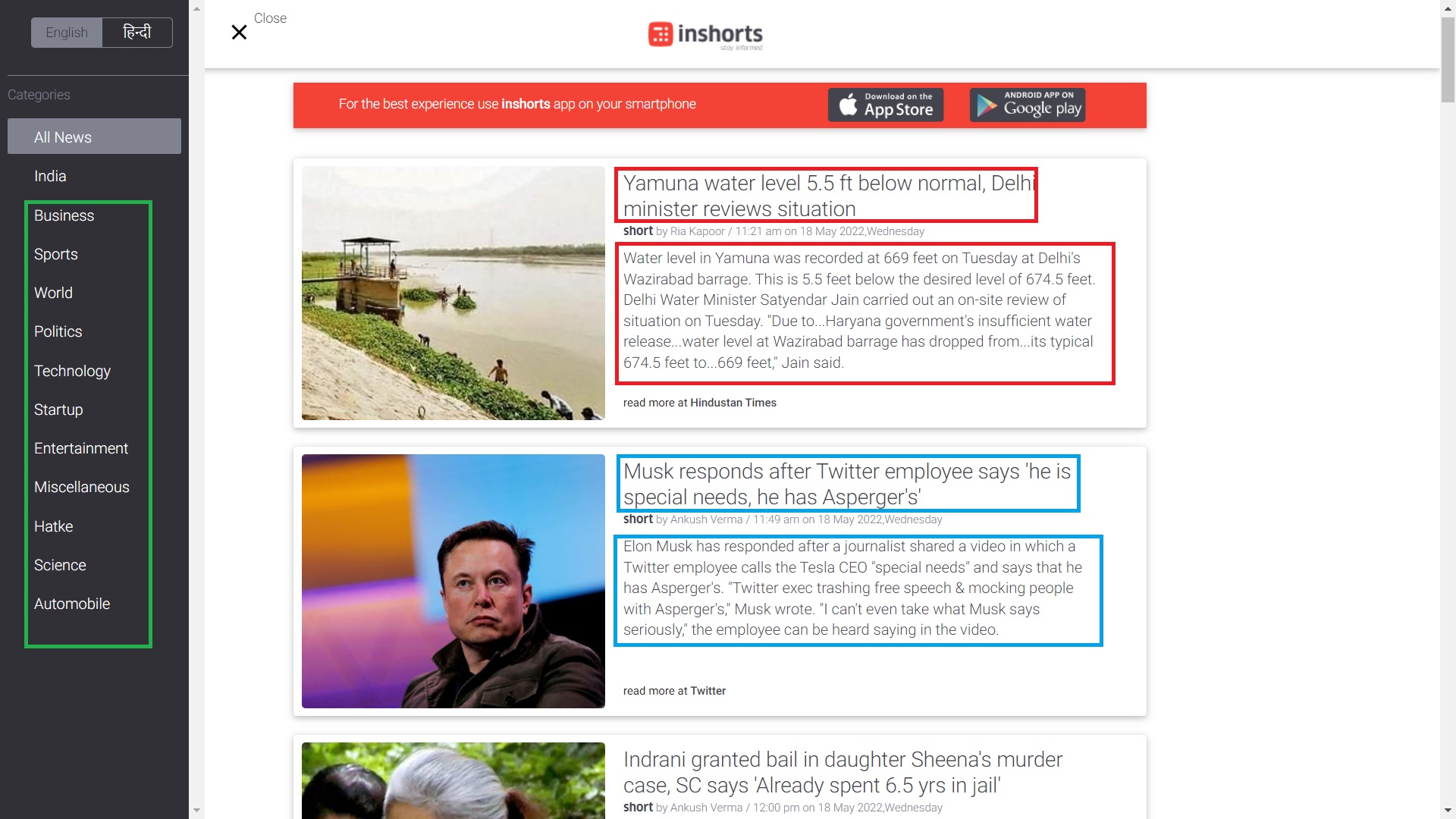
pantaloncini è un'app di aggregazione che riassume gli articoli di notizie in 60 parole e copre un'ampia gamma di argomenti, tra cui tecnologia, affari e altri contenuti come video, infografiche e blog. Nell'immagine sottostante andremo a raschiare i dati che si trovano all'interno delle caselle rettangolari.
In questo, andremo a raschiare l'articolo titoli delle news, contenuti di notizie, e il categoria degli articoli di notizie.
Titolo delle notizie:- È una frase di una riga che contiene una panoramica dell'articolo di notizie.
Articolo di notizie:- È una frase su più righe e contiene tutte le informazioni sulla notizia in 60 parole.
Categoria di notizie:- Racconta la categoria dell'articolo di notizie.
Esempio
news_headline:- La Boring Company di Musk condivide uno scorcio della loop station di Las Vegas.
news_article:- The Boring Company ha condiviso una breve clip su Twitter che mostra una delle stazioni della metropolitana che l'azienda sta costruendo come parte del suo circuito del Las Vegas Convention Center (LVCC). A settembre, il fondatore Elon Musk ha affermato che il primo tunnel operativo sotto Las Vegas era quasi completo. ""I tunnel sotto le città con auto elettriche a guida autonoma sembreranno come un motore a curvatura", aveva aggiunto.
nuova_categoria:- Tecnologia
Gli articoli sono stati classificati in molte categorie, ma esamineremo solo 7 diverse categorie e sono le seguenti: - technology, sports, politics, entertainment, world, automobile ed science.
Iniziamo a codificare
Per raccogliere questi dati ho utilizzato le seguenti librerie requests, BeautifulSoup4e pandas. Quindi per utilizzare queste librerie dobbiamo prima installarle nel nostro notebook. Abbiamo solo bisogno di installare bellazuppa lib e gli altri due sono già forniti con il nostro notebook.
Passo 1:- Per installare le librerie all'interno dei notebook databricks utilizziamo il metodo seguente: -
Passo 2:- Ora importa tutte le librerie richieste
Passo 3:- Ora definiamo gli endpoint per ogni categoria da cui vogliamo raschiare i dati.
Passo 04:- Ora invieremo richieste per ciascuno degli "URL" sopra definiti e quindi abbelliremo i dati di risposta. Quindi abbiamo utilizzato la comprensione dell'elenco per trovare tutti i titoli delle notizie e i nuovi contenuti dai dati di risposta. Abbiamo anche diviso gli URL per ottenere la categoria delle notizie.
Passo 05:- Crea il frame di dati dal dizionario dei dati che abbiamo raschiato dall'app web di notizie di Inshorts.
Step-06:– Ora mostra i dati che abbiamo raschiato.
Saluti!!! al raggiungimento della fine della guida e all'apprendimento di argomenti piuttosto interessanti su Azure Databricks. Da questa guida hai appreso con successo come avviare i servizi di databrick in Azure Cloud. Insieme a ciò, hai anche imparato come creare cluster per notebook in databrick e basi di rottamazione dei dati usando Python e Panda.
Ora nel prossimo articolo esploreremo Azure Data Lake Storage Gen2 (ADLS Gen2), come creare servizi di archiviazione ADLS gen2 e, insieme a ciò, salveremo i nostri dati raschiati in questo account di archiviazione programmando il nostro notebook su base oraria utilizzando il Azure Data Factory (ADF) metodi. In questo modo creiamo il nostro set di dati testuali per le attività della PNL.
Sentiti libero di connetterti con me su LinkedIn ed Github per ulteriori contenuti su Data Engineering e Machine Learning!
Buon apprendimento!!!
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e vengono utilizzati a discrezione dell'autore.














.png)






