La settimana scorsa abbiamo annunciato il disponibilità generale dell'integrazione tra Amazon DataZone ed Formazione AWS Lake modalità di accesso ibrido. In questo post, condividiamo come questa nuova funzionalità ti aiuta a semplificare il modo in cui utilizzi Amazon DataZone per consentire la condivisione sicura e regolamentata dei tuoi dati nel Colla AWS Catalogo dati. Approfondiremo inoltre il modo in cui i produttori di dati possono condividere le proprie tabelle AWS Glue tramite Amazon DataZone senza doverli prima registrare in Lake Formation.
Panoramica dell'integrazione di Amazon DataZone con la modalità di accesso ibrido di Lake Formation
Amazon DataZone è un servizio di gestione dei dati completamente gestito per catalogare, scoprire, analizzare, condividere e governare i dati tra produttori e consumatori di dati nella tua organizzazione. Con Amazon DataZone, i produttori di dati popolano il catalogo dei dati aziendali con risorse di dati provenienti da origini dati come il catalogo dati di AWS Glue e Amazon RedShift. Arricchiscono inoltre le proprie risorse con il contesto aziendale per renderne semplice la comprensione da parte dei consumatori di dati. Una volta che i dati sono disponibili nel catalogo, i consumatori di dati come analisti e data scientist possono cercare e accedere a questi dati richiedendo abbonamenti. Una volta approvata la richiesta, Amazon DataZone può fornire automaticamente l'accesso ai dati gestendo le autorizzazioni in Lake Formation o Amazon Redshift in modo che il consumatore di dati possa iniziare a eseguire query sui dati utilizzando strumenti come Amazzone Atena o Amazon Redshift.
Per gestire l'accesso ai dati nel catalogo dati di AWS Glue, Amazon DataZone utilizza Lake Formation. In precedenza, se volevi utilizzare Amazon DataZone per gestire l'accesso ai tuoi dati nel catalogo dati di AWS Glue, dovevi prima eseguire l'onboarding dei dati in Lake Formation. Ora, l'integrazione della modalità di accesso ibrido di Amazon DataZone e Lake Formation semplifica il modo in cui puoi iniziare il tuo viaggio in Amazon DataZone eliminando la necessità di caricare prima i tuoi dati in Lake Formation.
Formazione del lago modalità di accesso ibrido ti consente di iniziare a gestire le autorizzazioni sui database e sulle tabelle di AWS Glue tramite Lake Formation, continuando a mantenere quelle esistenti Gestione dell'identità e dell'accesso di AWS (IAM) su queste tabelle e database. La modalità di accesso ibrido di Lake Formation supporta due percorsi di autorizzazione per gli stessi database e tabelle di Data Catalog:
- Nel primo percorso, Lake Formation consente di selezionare entità specifiche (entità con consenso esplicito) e concedere loro le autorizzazioni Lake Formation per accedere a database e tabelle mediante l'adesione
- Il secondo percorso consente a tutte le altre entità (che non vengono aggiunte come entità con consenso esplicito) di accedere a queste risorse tramite le policy principali IAM per Servizio di archiviazione semplice Amazon (Amazon S3) e azioni AWS Glue
Con l'integrazione tra Amazon DataZone e la modalità di accesso ibrido Lake Formation, se disponi di tabelle nel catalogo dati di AWS Glue gestite tramite policy basate su IAM, puoi pubblicare queste tabelle direttamente su Amazon DataZone, senza registrarle in Lake Formation. Amazon DataZone registra la posizione di queste tabelle in Lake Formation utilizzando la modalità di accesso ibrido, che consente di gestire le autorizzazioni sulle tabelle AWS Glue tramite Lake Formation, continuando a mantenere le eventuali autorizzazioni IAM esistenti.
Amazon DataZone ti consente di pubblicare qualsiasi tipo di risorsa nel catalogo dei dati aziendali. Per alcune di queste risorse, Amazon DataZone può gestire automaticamente le concessioni di accesso. Questi beni sono chiamati patrimonio gestitoe includono tabelle Data Catalog gestite da Lake Formation e tabelle e viste Amazon Redshift. Prima di questa integrazione, dovevi completare i seguenti passaggi prima che Amazon DataZone potesse trattare la tabella Data Catalog pubblicata come una risorsa gestita:
- Identifica la posizione Amazon S3 associata alla tabella Data Catalog.
- Registra la posizione Amazon S3 con Lake Formation in modalità di accesso ibrido utilizzando a ruolo con le opportune autorizzazioni.
- Pubblica i metadati della tabella nel catalogo dati aziendali di Amazon DataZone.
Il diagramma seguente illustra questo flusso di lavoro.
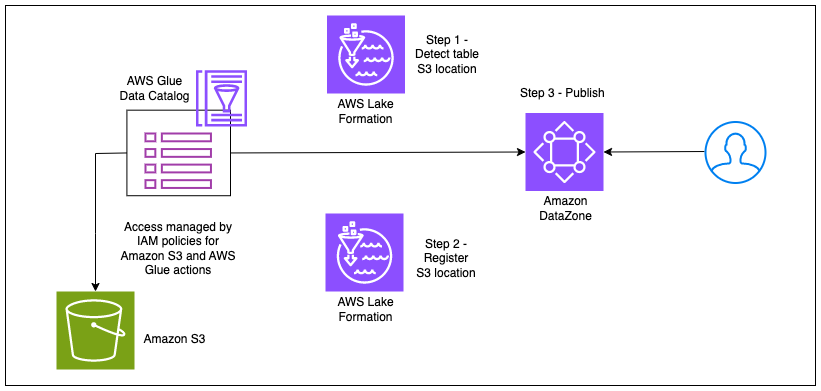
Con l'integrazione di Amazon DataZone con la modalità di accesso ibrido di Lake Formation, puoi pubblicare semplicemente le tue tabelle AWS Glue su Amazon DataZone senza doverti preoccupare di registrare la posizione di Amazon S3 o aggiungere un'entità opt-in in Lake Formation delegando questi passaggi ad Amazon DataZone . L'amministratore di un account AWS può abilitare l'impostazione di registrazione della posizione dei dati in DefaultDataLake progetto sulla console Amazon DataZone. Ora, un proprietario o un editore di dati può pubblicare la propria tabella AWS Glue (gestita tramite autorizzazioni IAM) su Amazon DataZone senza passaggi di configurazione aggiuntivi. Quando un consumatore di dati si iscrive a questa tabella, Amazon DataZone registra le posizioni Amazon S3 della tabella in modalità di accesso ibrido, aggiunge il ruolo IAM del consumatore di dati come entità opt-in e concede l'accesso allo stesso ruolo IAM gestendo le autorizzazioni sul tavola attraverso la formazione del lago. Ciò garantisce che le autorizzazioni IAM sulla tabella possano coesistere con le autorizzazioni Lake Formation appena concesse, senza interrompere i flussi di lavoro esistenti. Il diagramma seguente illustra questo flusso di lavoro.

Panoramica della soluzione
Per dimostrare questa nuova funzionalità, utilizziamo uno scenario di cliente di esempio in cui il team finanziario desidera accedere ai dati di proprietà del team di vendita per l'analisi e il reporting finanziario. Il team di vendita dispone di una pipeline che crea un set di dati contenente informazioni preziose sulla vendita dei biglietti, eventi popolari, luoghi e stagioni. Lo chiamiamo set di dati tickit. Il team di vendita archivia questo set di dati in Amazon S3 e lo registra in un database nel Catalogo dati. L'accesso a questa tabella è attualmente gestito tramite autorizzazioni basate su IAM. Tuttavia, il team di vendita desidera pubblicare questa tabella su Amazon DataZone per facilitare la condivisione sicura e regolamentata dei dati con il team finanziario.
I passaggi per configurare questa soluzione sono i seguenti:
- L'amministratore di Amazon DataZone abilita l'impostazione di registrazione della posizione del data Lake in Amazon DataZone per registrare automaticamente la posizione Amazon S3 delle tabelle AWS Glue in modalità di accesso ibrido Lake Formation.
- Dopo aver abilitato l'integrazione della modalità di accesso ibrido in Amazon DataZone, il team finanziario richiede un abbonamento all'asset di dati di vendita. La risorsa viene visualizzata come risorsa gestita, il che significa che Amazon DataZone può gestire l'accesso a questa risorsa anche se la posizione Amazon S3 di questa risorsa non è registrata in Lake Formation.
- Il team di vendita viene informato di una richiesta di sottoscrizione sollevata dal team finanziario. Esaminano e approvano la richiesta di accesso. Dopo l'approvazione della richiesta, Amazon DataZone soddisfa la richiesta di abbonamento gestendo le autorizzazioni in Lake Formation. Registra la posizione Amazon S3 della tabella sottoscritta in modalità ibrida Lake Formation.
- Il team finanziario ottiene l'accesso al set di dati sulle vendite richiesto per i propri report finanziari. Possono accedere al proprio ambiente DataZone e iniziare a eseguire query utilizzando Athena sul set di dati sottoscritto.
Prerequisiti
Per seguire i passaggi in questo post, è necessario un account AWS. Se non hai un account, puoi crearne uno. Inoltre, devi avere le seguenti risorse configurate nel tuo account:
- Un secchio S3
- Un database e un crawler di AWS Glue
- Ruoli IAM per diversi personaggi e servizi
- Un dominio e un progetto Amazon DataZone
- Un profilo e un ambiente di ambiente Amazon DataZone
- Un'origine dati Amazon DataZone
Se non hai già configurato queste risorse, puoi crearle distribuendo quanto segue AWS CloudFormazione pila:
- Scegli Avvia Stack per distribuire un modello CloudFormation.

- Completa i passaggi per distribuire il modello e lascia tutte le impostazioni predefinite.
- Seleziona Riconosco che AWS CloudFormation potrebbe creare risorse IAM, Quindi scegliere Invio.
Una volta completata la distribuzione di CloudFormation, puoi accedere al portale Amazon DataZone e attivare manualmente un'esecuzione dell'origine dati. Ciò estrae tutti i metadati nuovi o modificati dall'origine e aggiorna le risorse associate nell'inventario. Questa origine dati è stata configurata per pubblicare automaticamente le risorse di dati nel catalogo.
- Nella console Amazon DataZone, scegli Visualizza domini.
Devi aver effettuato l'accesso utilizzando lo stesso ruolo utilizzato per distribuire CloudFormation e verificare di trovarti nella stessa regione AWS.
- Trova il dominio
blog_dz_domain, Quindi scegliere Portale dati aperto. - Scegli Sfoglia tutti i progetti e scegli Progetto produttore di vendita.
- Sulla Dati scheda, scegliere Fonti dei dati nel pannello di navigazione.
- Individua e scegli l'origine dati che desideri eseguire.
Si apre la pagina dei dettagli dell'origine dati.
- Scegli il menu delle opzioni (tre punti verticali) accanto a
tickit_datasourcee scegli Correre.
Lo stato dell'origine dati cambia in In esecuzione mentre Amazon DataZone aggiorna i metadati della risorsa.
Abilita l'integrazione della modalità ibrida in Amazon DataZone
In questa fase, l'amministratore di Amazon DataZone esegue il processo di abilitazione dell'integrazione di Amazon DataZone con la modalità di accesso ibrido di Lake Formation. Completa i seguenti passaggi:
- In una scheda separata del browser, apri la console Amazon DataZone.
Verifica di trovarti nella stessa regione in cui hai distribuito il modello CloudFormation.
- Scegli Visualizza domini.
- Scegli il dominio creato da AWS CloudFormation,
blog_dz_domain. - Scorri verso il basso nella pagina dei dettagli del dominio e scegli Progetti scheda.
A cianografia definisce quali strumenti e servizi AWS possono essere utilizzati con le risorse di dati pubblicate in Amazon DataZone. IL DefaultDataLake il modello è abilitato come parte della distribuzione dello stack CloudFormation. Questo progetto ti consente di creare ed eseguire query su tabelle AWS Glue utilizzando Athena. Per i passaggi per abilitare questa funzionalità nelle proprie distribuzioni, fare riferimento a Abilita i progetti integrati nell'account AWS che possiede il dominio Amazon DataZone.
- Scegliere il
DefaultDataLakeplanimetria.
- Sulla vettovagliamento scheda, scegliere Modifica.
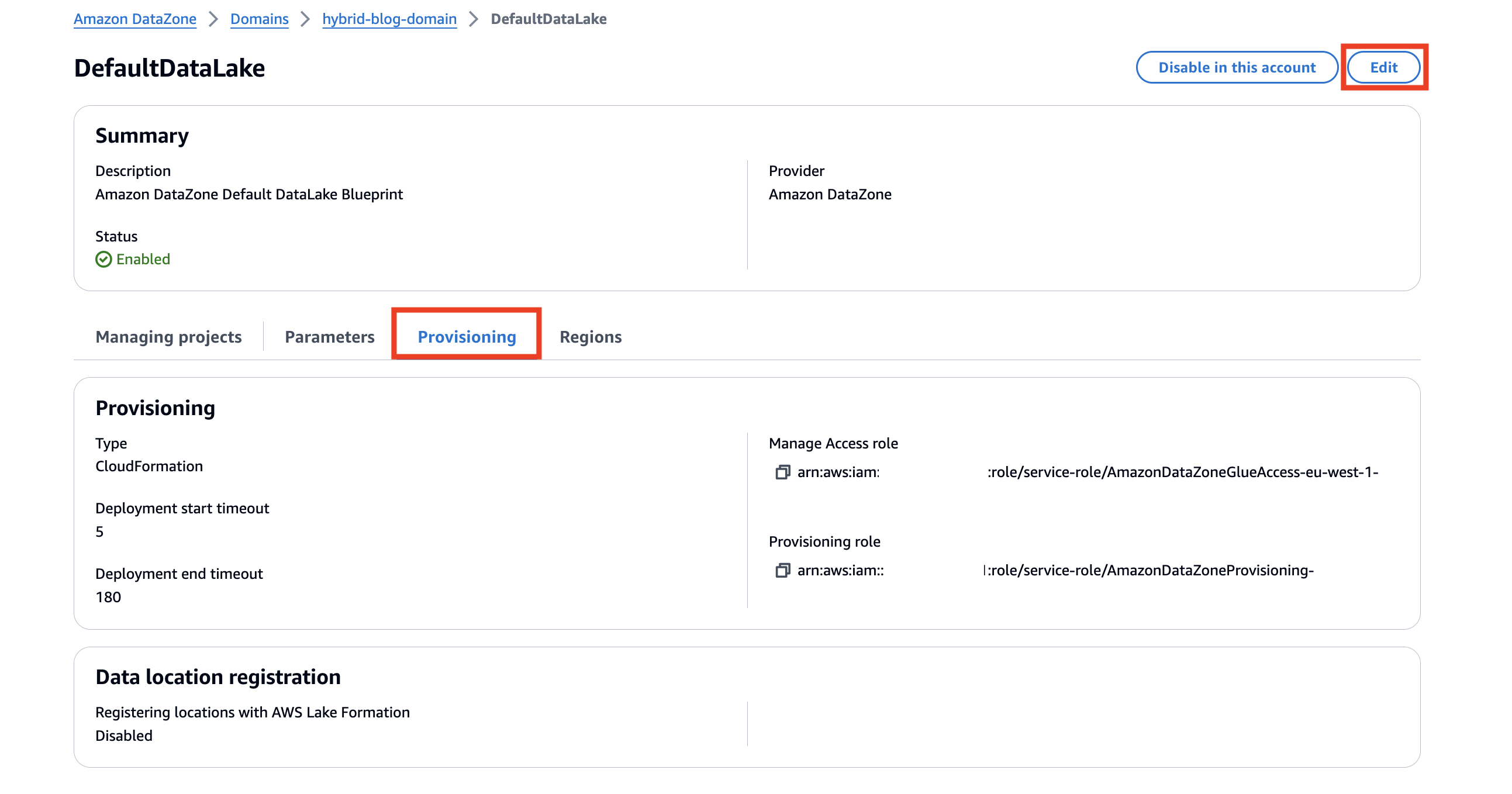
- Seleziona Consenti ad Amazon DataZone di registrare posizioni S3 utilizzando la modalità di accesso ibrido di AWS Lake Formation.
Hai la possibilità di escludere posizioni specifiche di Amazon S3 se non desideri che Amazon DataZone le registri automaticamente nella modalità di accesso ibrido di Lake Formation.
- Scegli Salvare le modifiche.

Richiesta di accesso
In questa fase, accedi ad Amazon DataZone come team finanziario, cerchi l'asset di dati di vendita e ti iscrivi. Completa i seguenti passaggi:
- Torna alla scheda del browser del portale dati Amazon DataZone.
- Passa al progetto finanziario di consumo scegliendo il menu a discesa accanto al nome del progetto e scegliendo Progetto finanziario per i consumatori.
Da questo passaggio in poi, assumerai la personalità di un utente finanziario che desidera abbonarsi a un asset di dati pubblicato nel passaggio precedente.
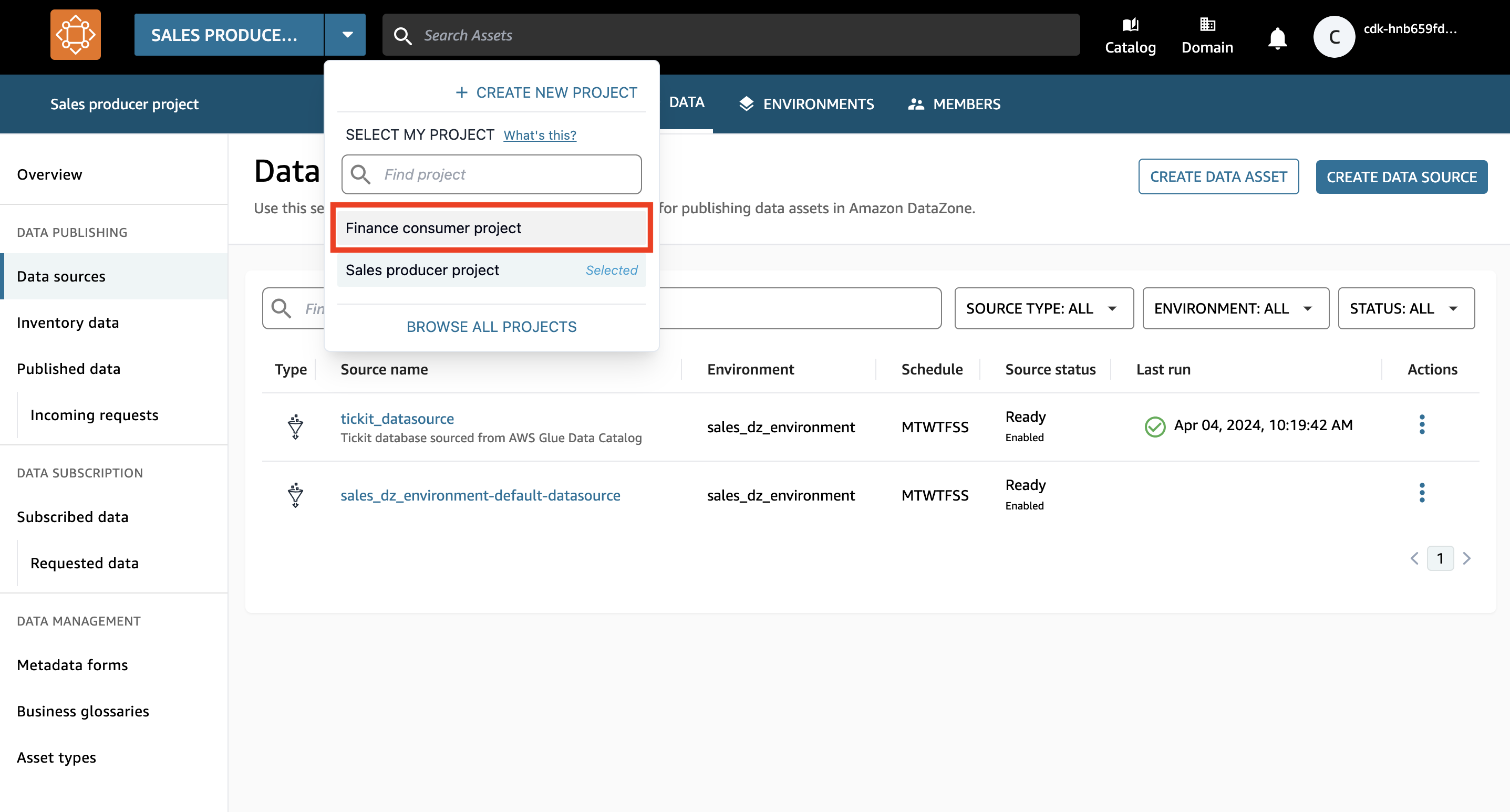
- Nella barra di ricerca, cerca e scegli il
salesrisorsa dati.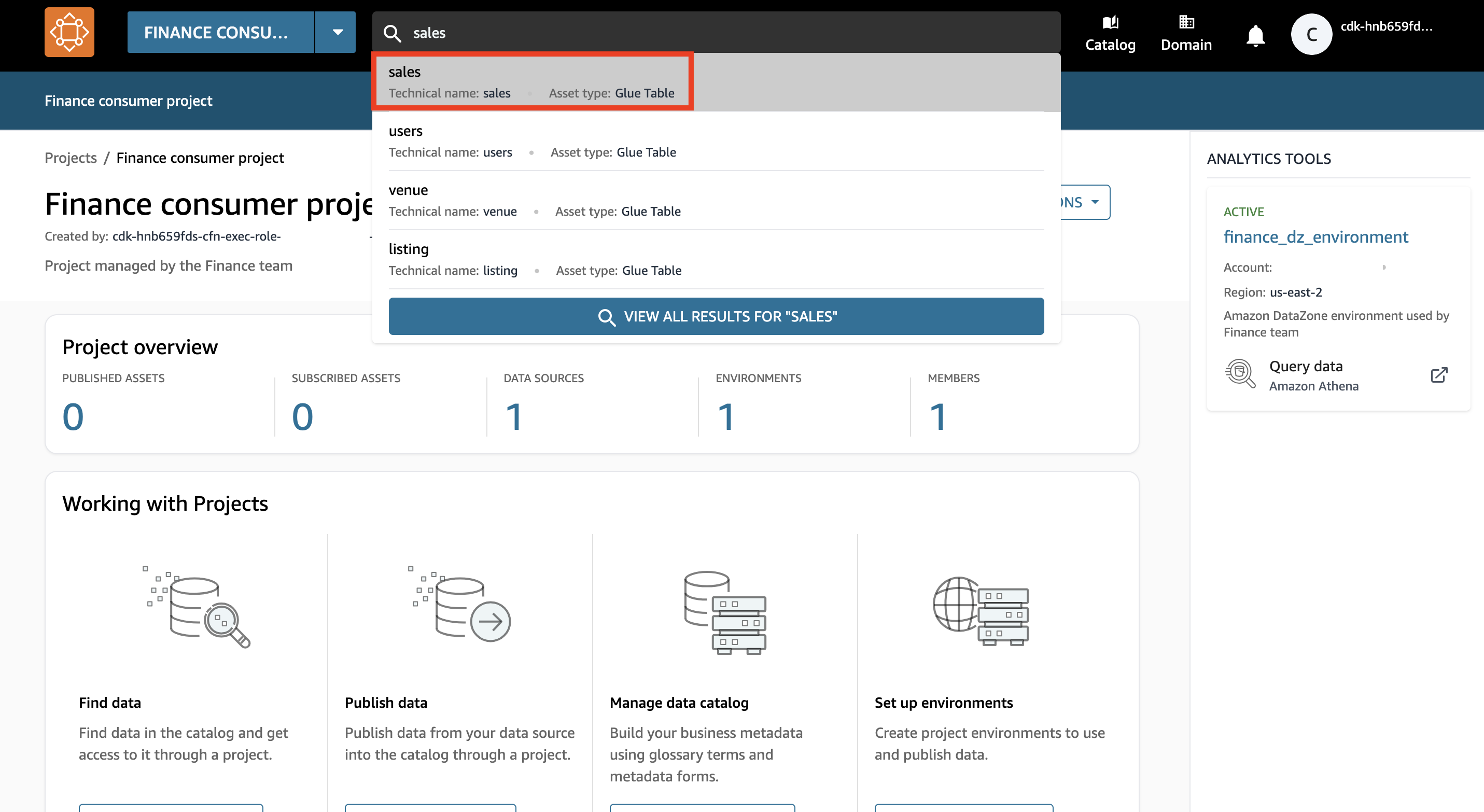
- Scegli Sottoscrivi.
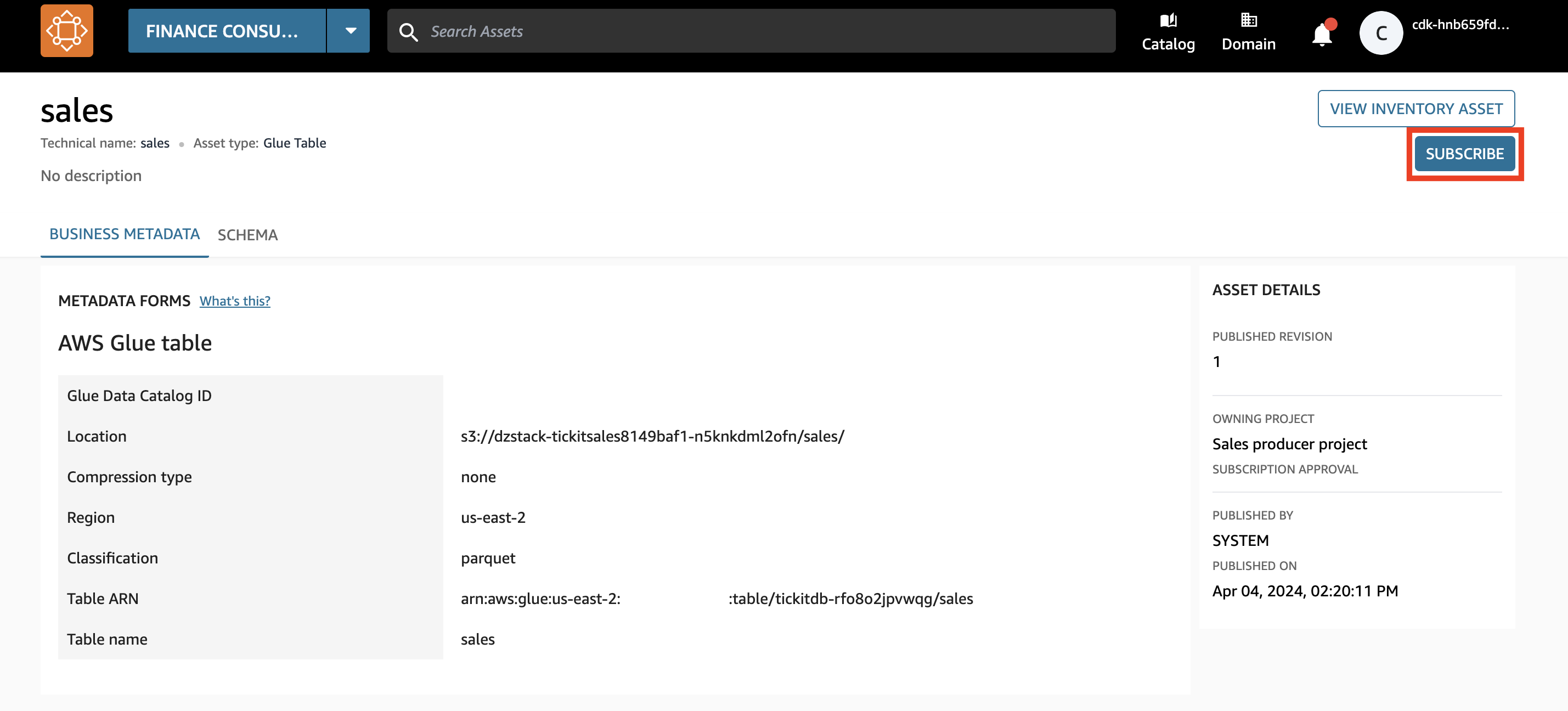
La risorsa viene visualizzata come risorsa gestita. Ciò significa che Amazon DataZone può concedere l'accesso a questa risorsa di dati al progetto del team finanziario gestendo le autorizzazioni in Lake Formation.
- Inserisci un motivo per la richiesta di accesso e scegli Sottoscrivi.
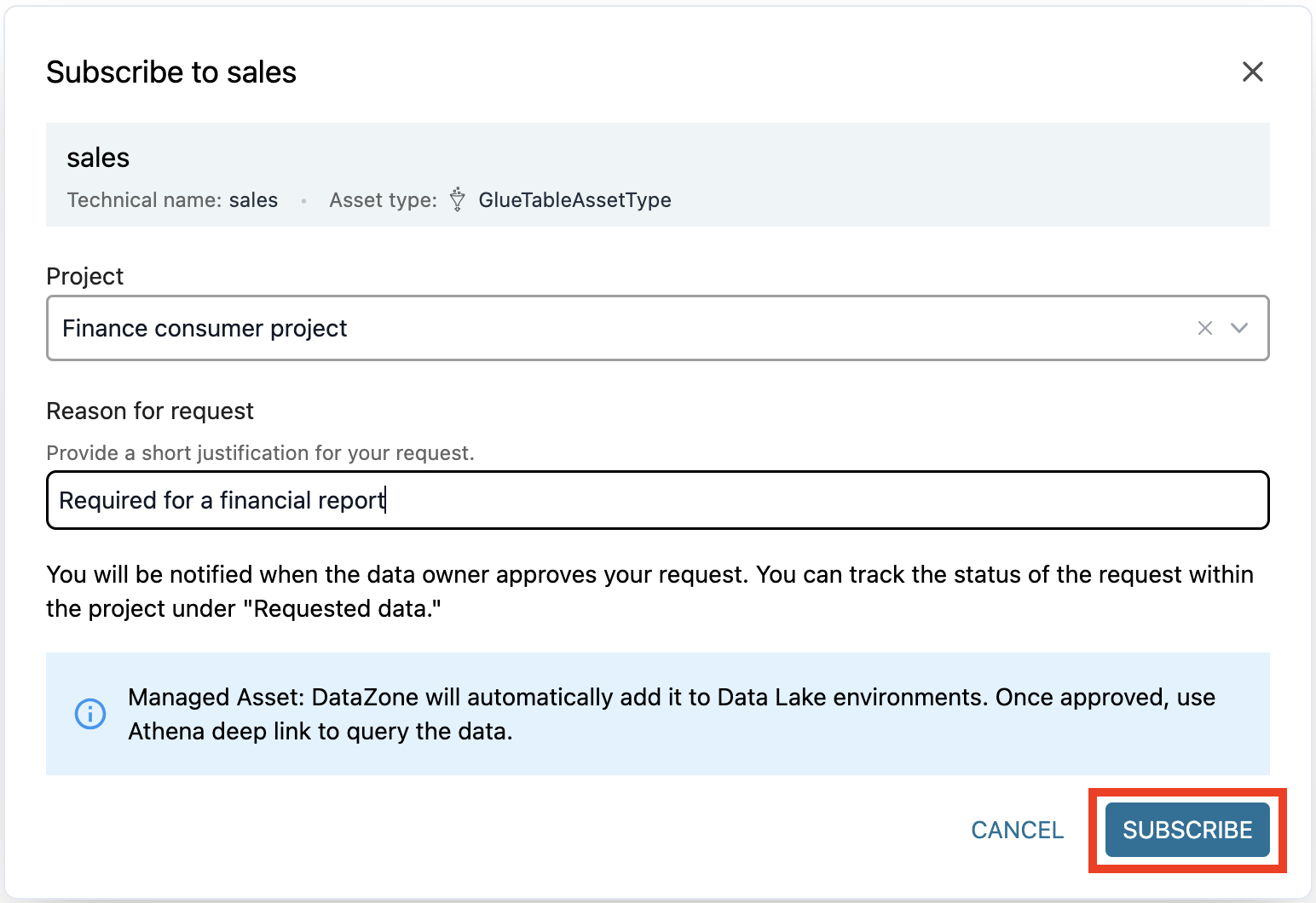
Approva la richiesta di accesso
Il team di vendita riceve una notifica relativa all'invio di una richiesta di accesso da parte del team finanziario. Per approvare la richiesta, completare i seguenti passaggi:
- Scegli il menu a discesa accanto al nome del progetto e scegli Progetto produttore di vendita.
Ora assumi la personalità del team di vendita, che è il proprietario e amministratore delle risorse di dati di vendita.
- Scegli l'icona di notifica nell'angolo in alto a destra del portale DataZone.
- Scegliere il Richiesta di abbonamento creata compito.
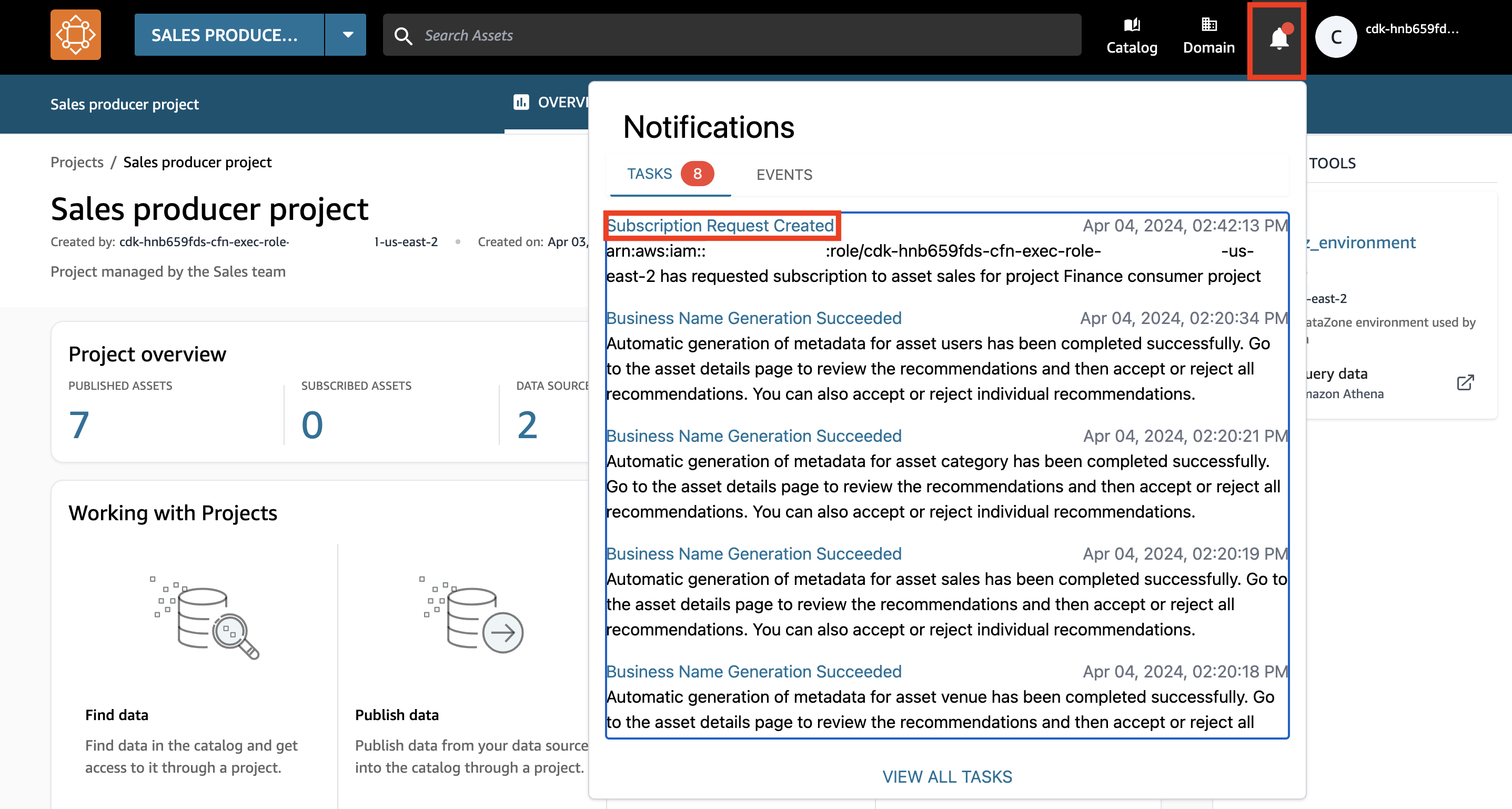
- Concedi l'accesso ai dati di vendita al team finanziario e scegli approvare.

Analizza i dati
Al team finanziario è stato ora concesso l'accesso ai dati di vendita e questo set di dati è stato inserito nel loro ambiente Amazon DataZone. Possono accedere all'ambiente ed eseguire query sul set di dati sulle vendite con Athena, insieme a qualsiasi altro set di dati attualmente in loro possesso. Completa i seguenti passaggi:
- Nel menu a discesa, scegli Progetto finanziario per i consumatori.
Nel riquadro destro della schermata di panoramica del progetto, puoi trovare un elenco di ambienti attivi disponibili per l'uso.
- Scegli l'ambiente Amazon DataZone
finance_dz_environment.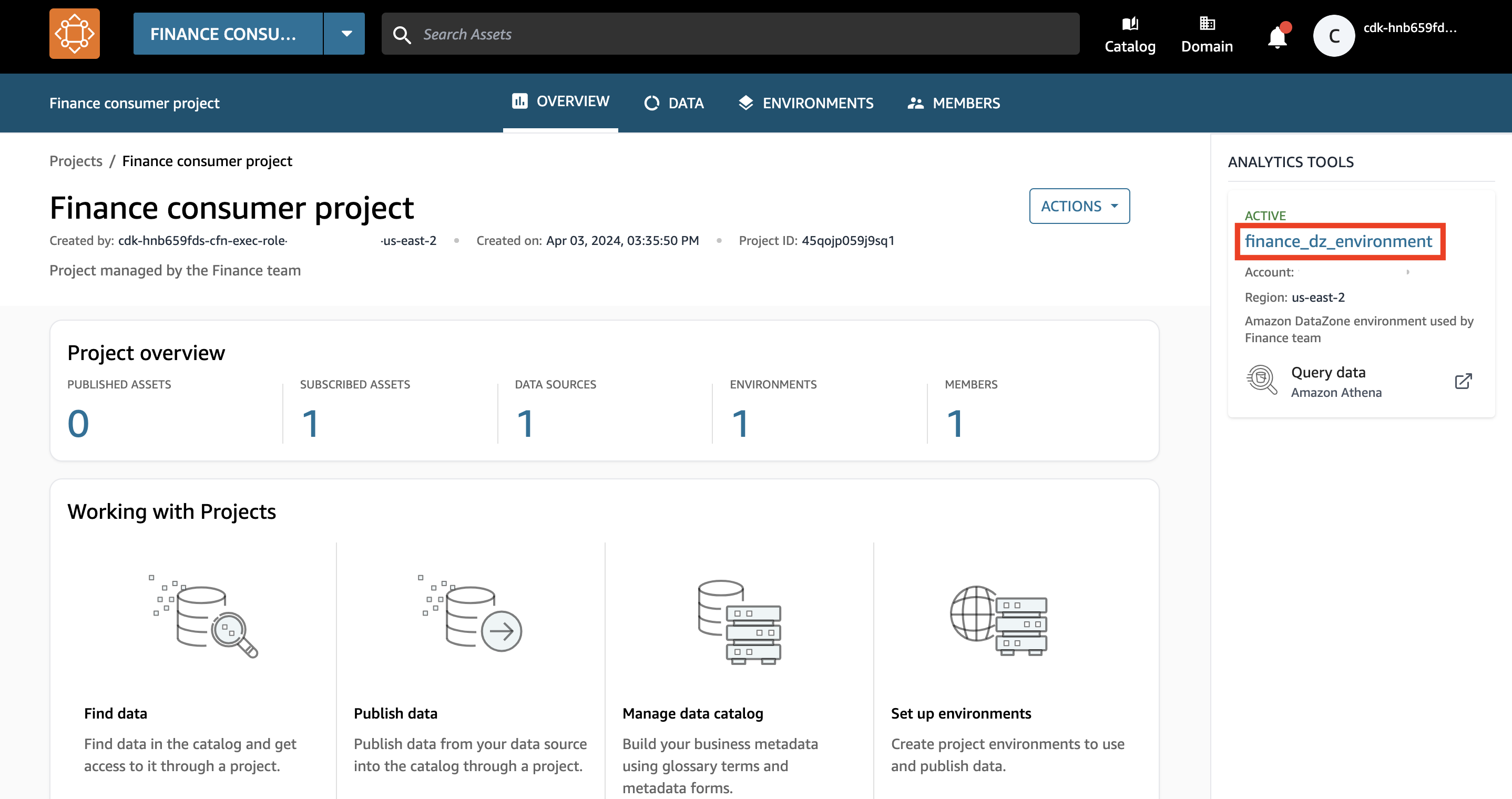
- Nel riquadro di navigazione, sotto Risorse di datiscegli Sottoscritto.
- Verifica che il tuo ambiente ora abbia accesso ai dati di vendita.
Potrebbero essere necessari alcuni minuti affinché l'asset di dati venga aggiunto automaticamente al tuo ambiente.
- Scegli l'icona della nuova scheda per Interroga i dati.
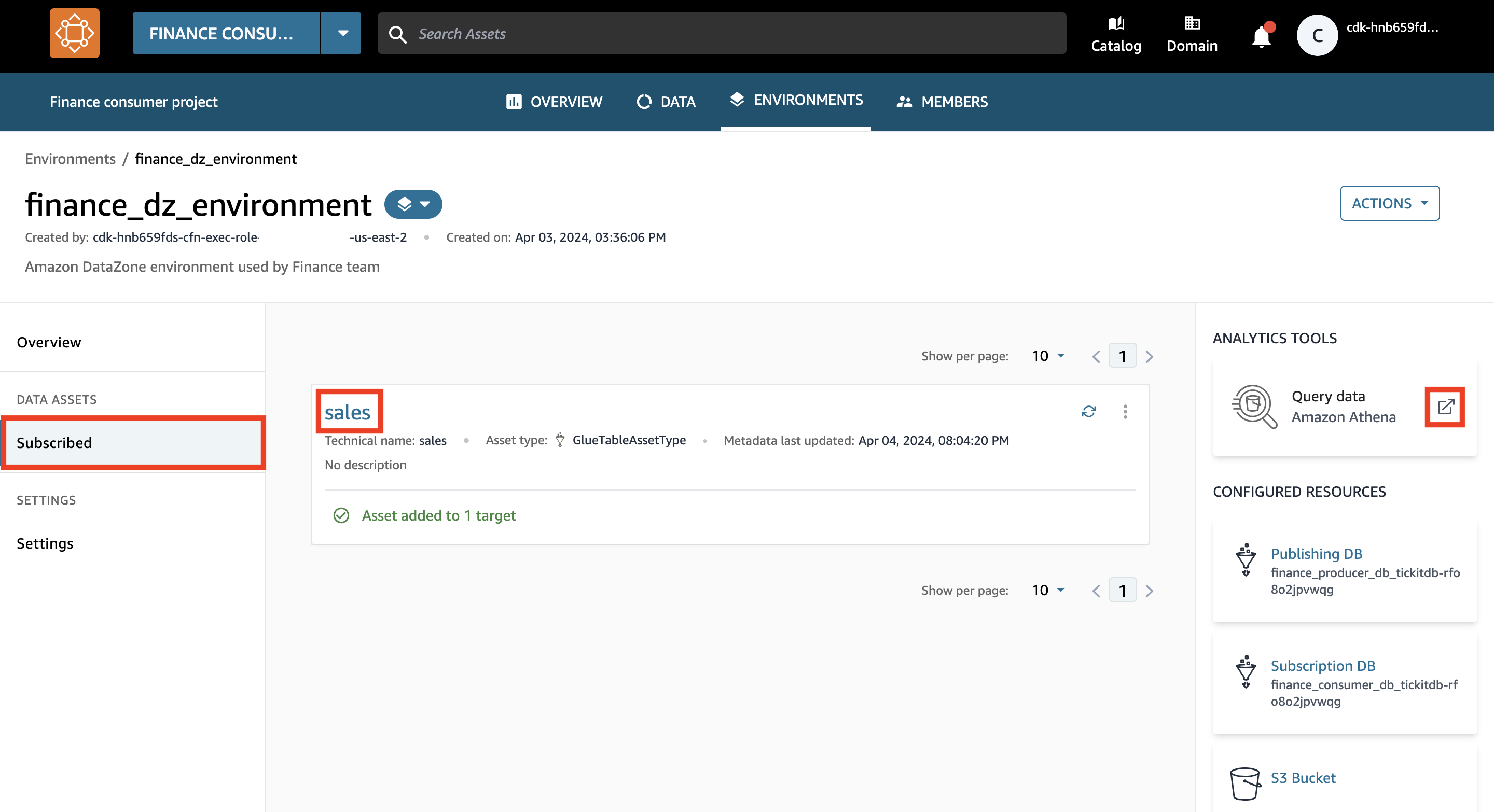
Si apre una nuova scheda con l'editor di query Athena.
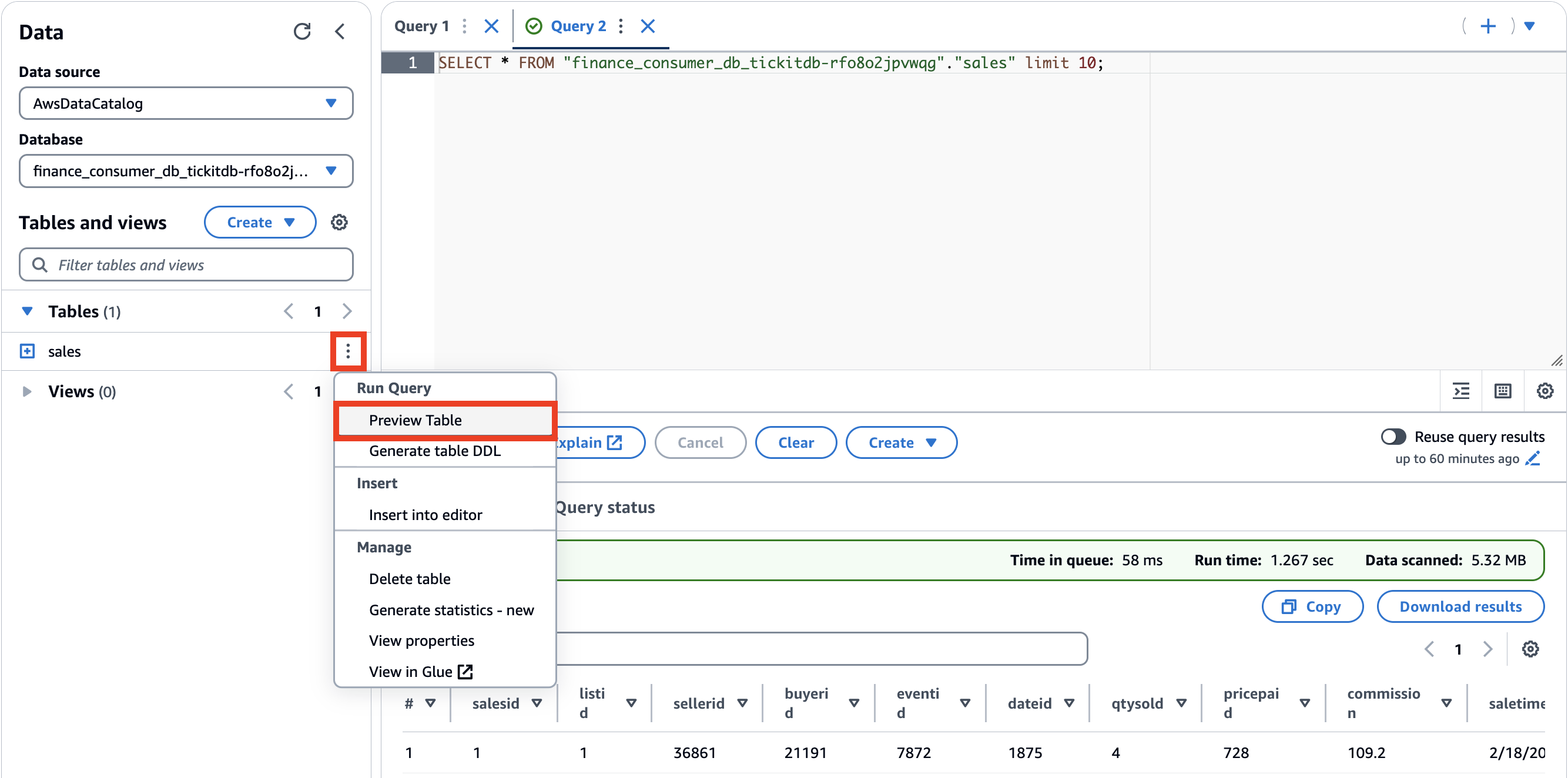
- Nel Banca Datiscegli
finance_consumer_db_tickitdb-<suffix>.
Questo database conterrà le risorse di dati sottoscritte.

- Genera un'anteprima della tabella di vendita scegliendo il menu delle opzioni (tre punti verticali) e scegliendo Anteprima tabella.
ripulire
Per ripulire le tue risorse, completa i seguenti passaggi:
- Torna al ruolo di amministratore utilizzato per distribuire lo stack CloudFormation.
- Sulla console Amazon DataZone, eliminare i progetti utilizzato in questo post. Ciò eliminerà la maggior parte degli oggetti relativi al progetto come risorse di dati e ambienti.
- Nella console AWS CloudFormation, elimina lo stack distribuito all'inizio di questo post.
- Nella console Amazon S3, elimina i bucket S3 contenenti il set di dati tickit.
- Nella console Lake Formation, elimina gli amministratori Lake Formation registrati da Amazon DataZone.
- Nella console Lake Formation, elimina tabelle e database creati da Amazon DataZone.
Conclusione
In questo post, abbiamo discusso di come l'integrazione tra Amazon DataZone e la modalità di accesso ibrido Lake Formation semplifica il processo per iniziare a utilizzare Amazon DataZone per la governance end-to-end dei dati nel catalogo dati di AWS Glue. Questa integrazione ti aiuta a evitare le fasi manuali di onboarding a Lake Formation prima di poter iniziare a utilizzare Amazon DataZone.
Per ulteriori informazioni su come iniziare con Amazon DataZone, fare riferimento al Guida introduttiva. . Check out the Guarda il Playlist di YouTube per alcune delle ultime demo di Amazon DataZone e brevi descrizioni delle funzionalità disponibili. Per ulteriori informazioni su Amazon DataZone, consulta In che modo Amazon DataZone aiuta i clienti a trovare valore in oceani di dati.
Informazioni sugli autori
 Utkarsh Mittal è Senior Technical Product Manager per Amazon DataZone presso AWS. La sua passione è creare prodotti innovativi che semplifichino i percorsi di analisi end-to-end dei clienti. Al di fuori del mondo della tecnologia, Utkarsh ama suonare la musica, e la batteria è la sua ultima fatica.
Utkarsh Mittal è Senior Technical Product Manager per Amazon DataZone presso AWS. La sua passione è creare prodotti innovativi che semplifichino i percorsi di analisi end-to-end dei clienti. Al di fuori del mondo della tecnologia, Utkarsh ama suonare la musica, e la batteria è la sua ultima fatica.
 Praveen Kumar è un Principal Analytics Solution Architect presso AWS con esperienza nella progettazione, realizzazione e implementazione di moderne piattaforme di dati e analisi utilizzando servizi incentrati sul cloud. Le sue aree di interesse sono la tecnologia serverless, i moderni data warehouse nel cloud, lo streaming e le applicazioni di intelligenza artificiale generativa.
Praveen Kumar è un Principal Analytics Solution Architect presso AWS con esperienza nella progettazione, realizzazione e implementazione di moderne piattaforme di dati e analisi utilizzando servizi incentrati sul cloud. Le sue aree di interesse sono la tecnologia serverless, i moderni data warehouse nel cloud, lo streaming e le applicazioni di intelligenza artificiale generativa.
 Paolo Villena è un Senior Analytics Solutions Architect in AWS con esperienza nella creazione di soluzioni moderne di dati e analisi per promuovere valore aziendale. Collabora con i clienti per aiutarli a sfruttare la potenza del cloud. Le sue aree di interesse sono l'infrastruttura come codice, le tecnologie serverless e la codifica in Python
Paolo Villena è un Senior Analytics Solutions Architect in AWS con esperienza nella creazione di soluzioni moderne di dati e analisi per promuovere valore aziendale. Collabora con i clienti per aiutarli a sfruttare la potenza del cloud. Le sue aree di interesse sono l'infrastruttura come codice, le tecnologie serverless e la codifica in Python
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/amazon-datazone-announces-integration-with-aws-lake-formation-hybrid-access-mode-for-the-aws-glue-data-catalog/

