Introduzione
Al centro di scienza dei dati si trova la statistica, che esiste da secoli ma rimane fondamentalmente essenziale nell'era digitale di oggi. Perché? Perché i concetti statistici di base ne sono la spina dorsale analisi dei dati, permettendoci di dare un senso alle grandi quantità di dati generati quotidianamente. È come conversare con i dati, dove le statistiche ci aiutano a porre le domande giuste e a comprendere le storie che i dati cercano di raccontare.
Dalla previsione delle tendenze future al processo decisionale basato sui dati, fino alla verifica di ipotesi e alla misurazione delle prestazioni, la statistica è lo strumento che alimenta le informazioni alla base delle decisioni basate sui dati. È il ponte tra dati grezzi e informazioni fruibili, il che lo rende una parte indispensabile della scienza dei dati.
In questo articolo ho raccolto i 15 principali concetti statistici fondamentali che ogni principiante della scienza dei dati dovrebbe conoscere!

Sommario
1. Campionamento statistico e raccolta dati
Impareremo alcuni concetti statistici di base, ma capire da dove provengono i nostri dati e come li raccogliamo è essenziale prima di immergerci in profondità nell'oceano dei dati. È qui che entrano in gioco le popolazioni, i campioni e le varie tecniche di campionamento.
Immaginiamo di voler conoscere l'altezza media delle persone in una città. È pratico misurare tutti, quindi prendiamo un gruppo più piccolo (campione) che rappresenta la popolazione più ampia. Il trucco sta nel modo in cui selezioniamo questo campione. Tecniche come il campionamento casuale, stratificato o a grappolo garantiscono che il nostro campione sia ben rappresentato, riducendo al minimo le distorsioni e rendendo i nostri risultati più affidabili.
Comprendendo popolazioni e campioni, possiamo estendere con sicurezza le nostre conoscenze dal campione all’intera popolazione, prendendo decisioni informate senza la necessità di intervistare tutti.
2. Tipologie di dati e scale di misurazione
I dati sono disponibili in vari modi e conoscere il tipo di dati con cui hai a che fare è fondamentale per scegliere le tecniche e gli strumenti statistici giusti.
Dati quantitativi e qualitativi
- Dati quantitativi: Questo tipo di dati riguarda solo i numeri. È misurabile e può essere utilizzato per calcoli matematici. I dati quantitativi ci dicono “quanto” o “quanti”, come il numero di utenti che visitano un sito web o la temperatura in una città. È semplice e obiettivo e fornisce un'immagine chiara attraverso valori numerici.
- Dati qualitativi: Al contrario, i dati qualitativi riguardano caratteristiche e descrizioni. Riguarda "che tipo" o "quale categoria". Pensateli come i dati che descrivono qualità o attributi, come il colore di un'auto o il genere di un libro. Questi dati sono soggettivi, basati su osservazioni piuttosto che su misurazioni.
Quattro scale di misurazione
- Scala nominale: Questa è la forma più semplice di misurazione utilizzata per classificare i dati senza un ordine specifico. Gli esempi includono tipi di cucina, gruppi sanguigni o nazionalità. Si tratta di etichettare senza alcun valore quantitativo.
- Scala ordinale: I dati possono essere ordinati o classificati qui, ma gli intervalli tra i valori non sono definiti. Pensa a un sondaggio sulla soddisfazione con opzioni come soddisfatto, neutrale e insoddisfatto. Ci dice l'ordine ma non la distanza tra le classifiche.
- Scala degli intervalli: L'intervallo scala i dati dell'ordine e quantifica la differenza tra le voci. Tuttavia, non esiste un vero e proprio punto zero. Un buon esempio è la temperatura in gradi Celsius; la differenza tra 10°C e 20°C è la stessa che tra 20°C e 30°C, ma 0°C non significa assenza di temperatura.
- Scala del rapporto: La scala più informativa ha tutte le proprietà di una scala a intervalli più un punto zero significativo, consentendo un confronto accurato delle grandezze. Gli esempi includono peso, altezza e reddito. Qui possiamo dire che qualcosa vale il doppio di un altro.
3. Statistiche descrittive
Immaginare statistiche descrittive come primo appuntamento con i tuoi dati. Si tratta di conoscere le nozioni di base, i tratti generali che descrivono ciò che hai di fronte. La statistica descrittiva ha due tipi principali: tendenza centrale e misure di variabilità.
Misure di Tendenza Centrale: Questi sono come il centro di gravità dei dati. Ci forniscono un singolo valore tipico o rappresentativo del nostro set di dati.
Significare: La media viene calcolata sommando tutti i valori e dividendo per il numero di valori. È come la valutazione complessiva di un ristorante basata su tutte le recensioni. La formula matematica per la media è riportata di seguito:

Mediano: Il valore medio quando i dati vengono ordinati dal più piccolo al più grande. Se il numero di osservazioni è pari, è la media dei due numeri centrali. Viene utilizzato per trovare il punto medio di un ponte.
Se n è pari, la mediana è la media dei due numeri centrali.
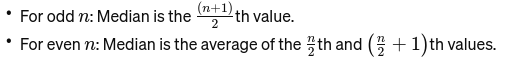
Modalità: È valore che ricorre più frequentemente in un set di dati. Consideralo il piatto più popolare in un ristorante.
Misure di variabilità: Mentre le misure di tendenza centrale ci portano al centro, le misure di variabilità ci parlano dello spread o della dispersione.
Range: La differenza tra i valori più alti e più bassi. Dà un’idea di base dello spread.
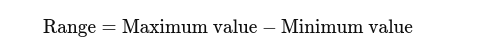
Varianza: Misura la distanza di ciascun numero dell'insieme dalla media e quindi da ogni altro numero dell'insieme. Per un esempio, è calcolato come:
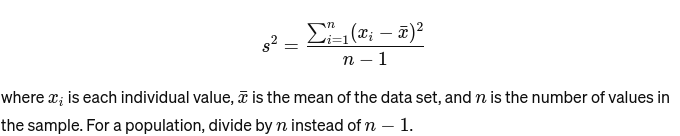
Deviazione standard: La radice quadrata della varianza fornisce una misura della distanza media dalla media. È come valutare la consistenza delle dimensioni della torta di un fornaio. È rappresentato come:
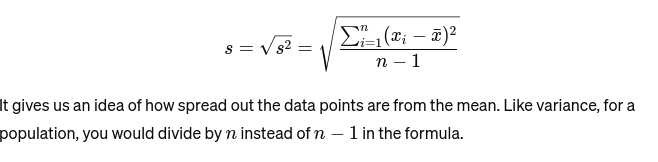
Prima di passare al successivo concetto statistico di base, ecco a Guida per principianti all'analisi statistica per voi!
4. Visualizzazione dei dati
Visualizzazione dati è l'arte e la scienza di raccontare storie con i dati. Trasforma i risultati complessi della nostra analisi in qualcosa di tangibile e comprensibile. È fondamentale per l'analisi esplorativa dei dati, in cui l'obiettivo è scoprire modelli, correlazioni e approfondimenti dai dati senza ancora giungere a conclusioni formali.
- Grafici e grafici: Partendo dalle nozioni di base, i grafici a barre, i grafici a linee e i grafici a torta forniscono informazioni fondamentali sui dati. Sono l’ABC della visualizzazione dei dati, essenziale per qualsiasi narratore di dati.
Di seguito abbiamo un esempio di grafico a barre (a sinistra) e di grafico a linee (a destra).
- Visualizzazioni avanzate: Man mano che ci immergiamo più in profondità, le mappe termiche, i grafici a dispersione e gli istogrammi consentono analisi più sfumate. Questi strumenti aiutano a identificare tendenze, distribuzioni e valori anomali.
Di seguito è riportato un esempio di grafico a dispersione e istogramma

Le visualizzazioni collegano i dati grezzi e la cognizione umana, consentendoci di interpretare e dare un senso rapidamente a set di dati complessi.
5. Nozioni di base sulla probabilità
Probabilità è la grammatica del linguaggio statistico. Riguarda la possibilità o la probabilità che gli eventi accadano. Comprendere i concetti di probabilità è essenziale per interpretare i risultati statistici e fare previsioni.
- Eventi indipendenti e dipendenti:
- Eventi indipendenti: Il risultato di un evento non influenza il risultato di un altro. Come lanciando una moneta, ottenere testa in un lancio non cambia le probabilità per il lancio successivo.
- Eventi dipendenti: L’esito di un evento influenza il risultato di un altro. Ad esempio, se peschi una carta da un mazzo e non la sostituisci, le tue possibilità di pescare un'altra carta specifica cambiano.
La probabilità fornisce le basi per fare inferenze sui dati ed è fondamentale per comprendere la significatività statistica e la verifica delle ipotesi.
6. Distribuzioni comuni di probabilità
Distribuzioni di probabilità sono come specie diverse nell'ecosistema statistico, ciascuna adattata alla propria nicchia di applicazioni.
- Distribuzione normale: Spesso chiamata curva a campana per la sua forma, questa distribuzione è caratterizzata dalla media e dalla deviazione standard. È un presupposto comune in molti test statistici perché molte variabili sono naturalmente distribuite in questo modo nel mondo reale.
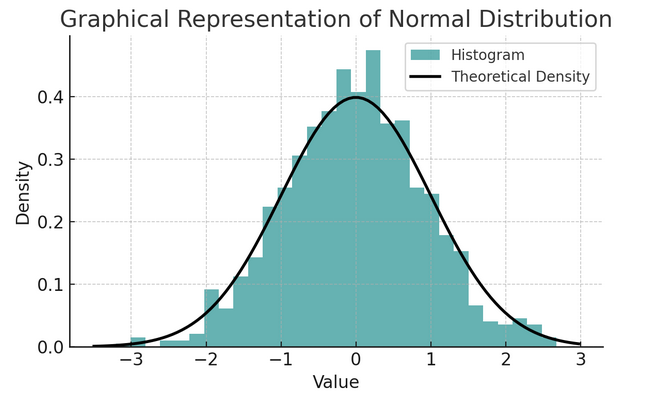
Un insieme di regole note come regola empirica o regola 68-95-99.7 riassume le caratteristiche di una distribuzione normale, che descrive come i dati vengono distribuiti attorno alla media.
Regola 68-95-99.7 (Regola Empirica)
Questa regola si applica a una distribuzione perfettamente normale e delinea quanto segue:
- 68% dei dati rientra in una deviazione standard (σ) della media (μ).
- 95% dei dati rientra entro due deviazioni standard dalla media.
- Circa 99.7% dei dati rientra nelle tre deviazioni standard della media.
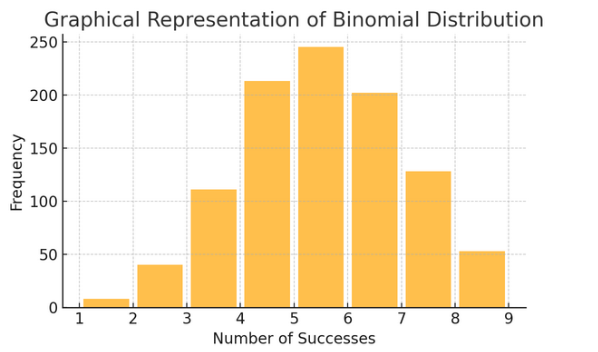
Distribuzione binomiale: Questa distribuzione si applica a situazioni con due esiti (come successo o fallimento) ripetuti più volte. Aiuta a modellare eventi come lanciare una moneta o fare un test vero/falso.
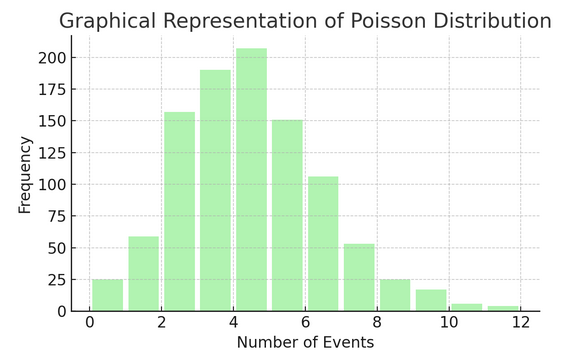
Distribuzione di Poisson conta il numero di volte in cui accade qualcosa in un intervallo o spazio specifico. È ideale per le situazioni in cui gli eventi accadono in modo indipendente e costante, come le e-mail quotidiane che ricevi.
Ogni distribuzione ha il proprio insieme di formule e caratteristiche e la scelta di quella giusta dipende dalla natura dei tuoi dati e da ciò che stai cercando di scoprire. Comprendere queste distribuzioni consente agli statistici e ai data scientist di modellare i fenomeni del mondo reale e prevedere con precisione eventi futuri.
7 . Controllo di un'ipotesi
Considerare verifica di ipotesi come lavoro investigativo in statistica. È un metodo per verificare se una particolare teoria sui nostri dati potrebbe essere vera. Questo processo parte da due ipotesi opposte:
- Ipotesi nulla (H0): Questo è il presupposto predefinito, suggerendo che ci sia un effetto o una differenza. Sta dicendo: "Non" è una novità qui."
- Al “Ipotesi alternativa (H1 o Ha): Ciò sfida lo status quo, proponendo un effetto o una differenza. Afferma: "Sta succedendo qualcosa di interessante".
Esempio: verificare se un nuovo programma dietetico porta alla perdita di peso rispetto al non seguire alcuna dieta.
- Ipotesi nulla (H0): Il nuovo programma dietetico non porta a dimagrimento (nessuna differenza di perdita di peso tra chi segue il nuovo programma dietetico e chi non lo fa).
- Ipotesi alternativa (H1): Il nuovo programma dietetico porta alla perdita di peso (una differenza nella perdita di peso tra chi lo segue e chi non lo segue).
La verifica delle ipotesi implica la scelta tra questi due sulla base delle prove (i nostri dati).
Livelli di errore e significatività di tipo I e II:
- Errore di tipo I: Ciò accade quando rifiutiamo erroneamente l’ipotesi nulla. Condanna una persona innocente.
- Errore di tipo II: Ciò si verifica quando non riusciamo a rifiutare un’ipotesi falsa nulla. Permette a un colpevole di essere libero.
- Livello di significatività (α): Questo è la soglia per decidere quante prove sono sufficienti per rifiutare l’ipotesi nulla. Spesso è impostato al 5% (0.05), indicando un rischio del 5% di un errore di tipo I.
8. Intervalli di confidenza
Intervalli di confidenza fornirci un intervallo di valori all'interno del quale ci aspettiamo che il parametro valido della popolazione (come una media o una proporzione) rientri con un certo livello di confidenza (comunemente 95%). È come prevedere il punteggio finale di una squadra sportiva con un margine di errore; stiamo dicendo: "Siamo sicuri al 95% che il punteggio reale rientrerà in questo intervallo".
Costruire e interpretare gli intervalli di confidenza ci aiuta a comprendere la precisione delle nostre stime. Più ampio è l’intervallo, la nostra stima sarà meno precisa e viceversa.
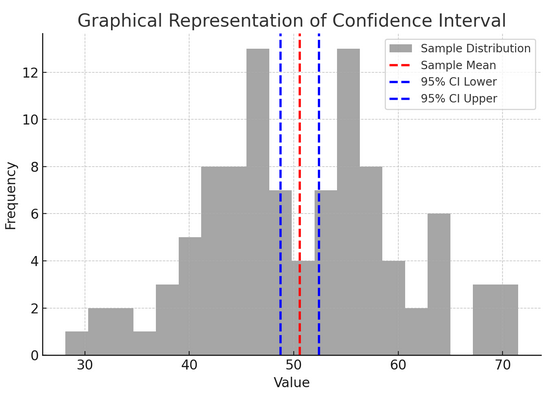
La figura sopra illustra il concetto di intervallo di confidenza (CI) nelle statistiche, utilizzando una distribuzione campionaria e il suo intervallo di confidenza al 95% attorno alla media del campione.
Ecco una ripartizione dei componenti critici nella figura:
- Distribuzione del campione (istogramma grigio): Ciò rappresenta la distribuzione di 100 punti dati generati casualmente da una distribuzione normale con una media di 50 e una deviazione standard di 10. L'istogramma descrive visivamente come i punti dati sono distribuiti attorno alla media.
- Media del campione (linea rossa tratteggiata): Questa linea indica il valore medio (medio) dei dati del campione. Serve come stima puntuale attorno alla quale costruiamo l’intervallo di confidenza. In questo caso, rappresenta la media di tutti i valori del campione.
- Intervallo di confidenza al 95% (linee blu tratteggiate): Queste due linee segnano i limiti inferiore e superiore dell'intervallo di confidenza al 95% attorno alla media campionaria. L'intervallo viene calcolato utilizzando l'errore standard della media (SEM) e un punteggio Z corrispondente al livello di confidenza desiderato (1.96 per confidenza al 95%). L’intervallo di confidenza suggerisce che siamo sicuri al 95% che la media della popolazione rientri in questo intervallo.
9. Correlazione e causalità
Correlazione e causalità spesso si confondono, ma sono diversi:
- Correlazione: Indica una relazione o associazione tra due variabili. Quando uno cambia, anche l’altro tende a cambiare. La correlazione viene misurata da un coefficiente di correlazione compreso tra -1 e 1. Un valore più vicino a 1 o -1 indica una relazione forte, mentre 0 suggerisce l'assenza di legami.
- Causa: Ciò implica che i cambiamenti in una variabile causano direttamente cambiamenti in un’altra. Si tratta di un’affermazione più solida della correlazione e richiede test rigorosi.
Solo perché due variabili sono correlate non significa che una causa l’altra. Questo è un classico caso in cui non si confonde la “correlazione” con la “causalità”.
10. Regressione lineare semplice
Un'espansione regressione lineare è un modo per modellare la relazione tra due variabili adattando un'equazione lineare ai dati osservati. Una variabile è considerata una variabile esplicativa (indipendente) e l'altra è una variabile dipendente.
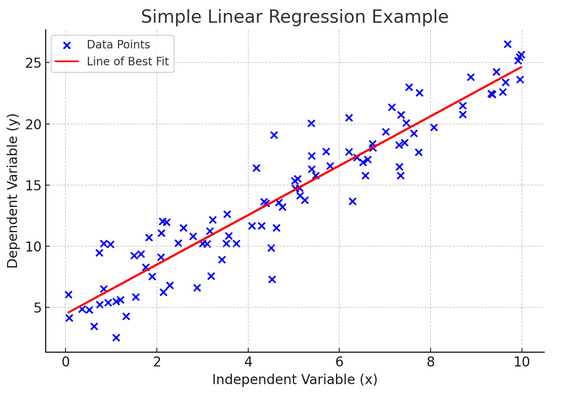
La regressione lineare semplice ci aiuta a capire come i cambiamenti nella variabile indipendente influenzano la variabile dipendente. È un potente strumento di previsione ed è fondamentale per molti altri modelli statistici complessi. Analizzando la relazione tra due variabili, possiamo fare previsioni informate su come interagiranno.
La regressione lineare semplice presuppone una relazione lineare tra la variabile indipendente (variabile esplicativa) e la variabile dipendente. Se la relazione tra queste due variabili non è lineare, i presupposti della regressione lineare semplice potrebbero essere violati, portando potenzialmente a previsioni o interpretazioni imprecise. Pertanto, verificare una relazione lineare tra i dati è essenziale prima di applicare la regressione lineare semplice.
11. Regressione lineare multipla
Pensa alla regressione lineare multipla come a un'estensione della regressione lineare semplice. Tuttavia, invece di provare a prevedere un risultato con un cavaliere dall'armatura scintillante (predittore), hai un'intera squadra. È come passare da una partita di basket uno contro uno a un lavoro di squadra, in cui ogni giocatore (predittore) apporta abilità uniche. L’idea è vedere come diverse variabili insieme influenzano un singolo risultato.
Tuttavia, con un team più numeroso si presenta la sfida della gestione delle relazioni, nota come multicollinearità. Si verifica quando i predittori sono troppo vicini tra loro e condividono informazioni simili. Immagina due giocatori di basket che cercano costantemente di effettuare lo stesso tiro; possono intralciarsi a vicenda. La regressione può rendere difficile vedere il contributo unico di ciascun predittore, distorcendo potenzialmente la nostra comprensione di quali variabili siano significative.
12. Regressione logistica
Mentre la regressione lineare prevede risultati continui (come la temperatura o i prezzi), regressione logistica si usa quando il risultato è definitivo (come sì/no, vinci/perdi). Immagina di provare a prevedere se una squadra vincerà o perderà in base a vari fattori; la regressione logistica è la tua strategia preferita.
Trasforma l'equazione lineare in modo che il suo output sia compreso tra 0 e 1, rappresentando la probabilità di appartenere a una particolare categoria. È come avere una lente magica che converte i punteggi continui in una visione chiara di “questo o quello”, permettendoci di prevedere risultati categorici.
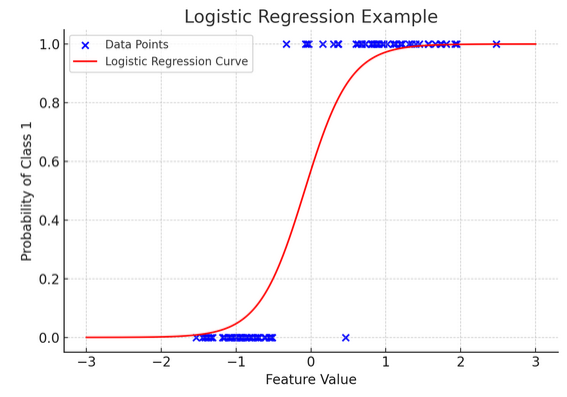
La rappresentazione grafica illustra un esempio di regressione logistica applicata a un set di dati di classificazione binaria sintetica. I punti blu rappresentano i punti dati, con la loro posizione lungo l'asse x che indica il valore della caratteristica e l'asse y che indica la categoria (0 o 1). La curva rossa rappresenta la previsione del modello di regressione logistica della probabilità di appartenere alla classe 1 (ad esempio, “vittoria”) per diversi valori di caratteristiche. Come puoi vedere, la curva passa gradualmente dalla probabilità della classe 0 alla classe 1, dimostrando la capacità del modello di prevedere risultati categorici sulla base di una caratteristica continua sottostante.
La formula per la regressione logistica è data da:

Questa formula utilizza la funzione logistica per trasformare il risultato dell'equazione lineare in una probabilità compresa tra 0 e 1. Questa trasformazione ci permette di interpretare i risultati come probabilità di appartenenza ad una particolare categoria in base al valore della variabile indipendente xx.
13. Test ANOVA e Chi-Quadro
ANOVA (Analisi della varianza) ed Test del chi quadrato sono come gli investigatori nel mondo delle statistiche, che ci aiutano a risolvere diversi misteri. IOt ci consente di confrontare le medie di più gruppi per vedere se almeno uno è statisticamente diverso. Consideralo come una degustazione di campioni di diversi lotti di biscotti per determinare se un lotto ha un sapore significativamente diverso.
D'altra parte, il test del chi quadrato viene utilizzato per i dati categoriali. Ci aiuta a capire se esiste un'associazione significativa tra due variabili categoriali. Ad esempio, esiste una relazione tra il genere musicale preferito di una persona e la sua fascia d'età? Il test del chi quadrato aiuta a rispondere a queste domande.
14. Il teorema del limite centrale e la sua importanza nella scienza dei dati
I Teorema del limite centrale (CLT) è un principio statistico fondamentale che sembra quasi magico. Ci dice che se si prendono abbastanza campioni da una popolazione e si calcolano le loro medie, tali medie formeranno una distribuzione normale (la curva a campana), indipendentemente dalla distribuzione originale della popolazione. Questo è incredibilmente potente perché ci permette di fare inferenze sulle popolazioni anche quando non conosciamo la loro esatta distribuzione.
Nella scienza dei dati, il CLT è alla base di molte tecniche, consentendoci di utilizzare strumenti progettati per dati normalmente distribuiti anche quando i nostri dati inizialmente non soddisfano tali criteri. È come trovare un adattatore universale per i metodi statistici, rendendo molti strumenti potenti applicabili in più situazioni.
15. Compromesso bias-varianza
In modellazione predittiva ed machine learning, le compromesso bias-varianza è un concetto cruciale che evidenzia la tensione tra due principali tipi di errore che possono far fallire i nostri modelli. Il bias si riferisce agli errori derivanti da modelli eccessivamente semplicistici che non catturano bene le tendenze sottostanti. Immagina di provare a far passare una linea retta attraverso una strada curva; mancherai il bersaglio. Al contrario, le varianze derivanti da modelli troppo complessi catturano il rumore nei dati come se fosse un modello reale, come tracciare ogni svolta e svolta su un sentiero accidentato, pensando che sia il percorso da seguire.
L'arte sta nel bilanciare questi due per ridurre al minimo l'errore totale, trovando il punto debole in cui il modello è giusto: abbastanza complesso da catturare modelli accurati ma abbastanza semplice da ignorare il rumore casuale. È come accordare una chitarra; non suonerà bene se è troppo stretto o allentato. Il compromesso bias-varianza si tratta di trovare il perfetto equilibrio tra questi due. Il compromesso bias-varianza è l’essenza della messa a punto dei nostri modelli statistici per ottenere il meglio nel prevedere i risultati in modo accurato.
Conclusione
Dal campionamento statistico al compromesso bias-varianza, questi principi non sono semplici nozioni accademiche ma strumenti essenziali per un’analisi approfondita dei dati. Forniscono agli aspiranti data scientist le competenze per trasformare vasti dati in informazioni fruibili, sottolineando la statistica come la spina dorsale del processo decisionale e dell'innovazione basati sui dati nell'era digitale.
Abbiamo tralasciato qualche concetto statistico di base? Fatecelo sapere nella sezione commenti qui sotto.
Esplora la nostra guida alle statistiche end-to-end per la scienza dei dati per conoscere l'argomento!
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

