Generator Gambar Amazon Titan G1 adalah model teks-ke-gambar mutakhir, tersedia melalui Batuan Dasar Amazon, yang mampu memahami petunjuk yang mendeskripsikan banyak objek dalam berbagai konteks dan menangkap detail relevan ini dalam gambar yang dihasilkannya. Ini tersedia di Wilayah AWS US East (N. Virginia) dan US West (Oregon) dan dapat melakukan tugas pengeditan gambar tingkat lanjut seperti smart cropping, in-painting, dan perubahan latar belakang. Namun, pengguna ingin menyesuaikan model dengan karakteristik unik dalam kumpulan data khusus yang belum pernah dilatih pada model tersebut. Kumpulan data khusus dapat mencakup data kepemilikan tinggi yang konsisten dengan pedoman merek Anda atau gaya tertentu seperti kampanye sebelumnya. Untuk mengatasi kasus penggunaan ini dan menghasilkan gambar yang sepenuhnya dipersonalisasi, Anda dapat menyempurnakan Amazon Titan Image Generator dengan menggunakan data Anda sendiri model khusus untuk Amazon Bedrock.
Dari menghasilkan gambar hingga mengeditnya, model teks-ke-gambar memiliki penerapan luas di berbagai industri. Mereka dapat meningkatkan kreativitas karyawan dan memberikan kemampuan untuk membayangkan kemungkinan-kemungkinan baru hanya dengan deskripsi tekstual. Misalnya, dapat membantu perencanaan desain dan lantai bagi para arsitek dan memungkinkan inovasi lebih cepat dengan memberikan kemampuan untuk memvisualisasikan berbagai desain tanpa proses pembuatannya secara manual. Demikian pula, hal ini dapat membantu dalam desain di berbagai industri seperti manufaktur, desain fesyen di ritel, dan desain game dengan menyederhanakan pembuatan grafis dan ilustrasi. Model teks-ke-gambar juga meningkatkan pengalaman pelanggan Anda dengan memungkinkan iklan yang dipersonalisasi serta chatbot visual yang interaktif dan imersif dalam kasus penggunaan media dan hiburan.
Dalam postingan ini, kami memandu Anda melalui proses menyempurnakan model Amazon Titan Image Generator untuk mempelajari dua kategori baru: Ron si anjing dan Smila si kucing, hewan peliharaan favorit kami. Kami membahas cara menyiapkan data Anda untuk tugas penyesuaian model dan cara membuat tugas penyesuaian model di Amazon Bedrock. Terakhir, kami menunjukkan kepada Anda cara menguji dan menerapkan model yang telah Anda sesuaikan Throughput yang Disediakan.
 |
 |
| Ron si anjing | Tersenyumlah si kucing |
Mengevaluasi kemampuan model sebelum menyempurnakan pekerjaan
Model dasar dilatih pada data dalam jumlah besar, sehingga ada kemungkinan model Anda akan bekerja dengan cukup baik. Oleh karena itu, merupakan praktik yang baik untuk memeriksa apakah Anda benar-benar perlu menyempurnakan model untuk kasus penggunaan Anda atau apakah rekayasa cepat sudah cukup. Mari kita coba menghasilkan beberapa gambar Ron si anjing dan Smila si kucing dengan model dasar Amazon Titan Image Generator, seperti yang ditunjukkan pada tangkapan layar berikut.
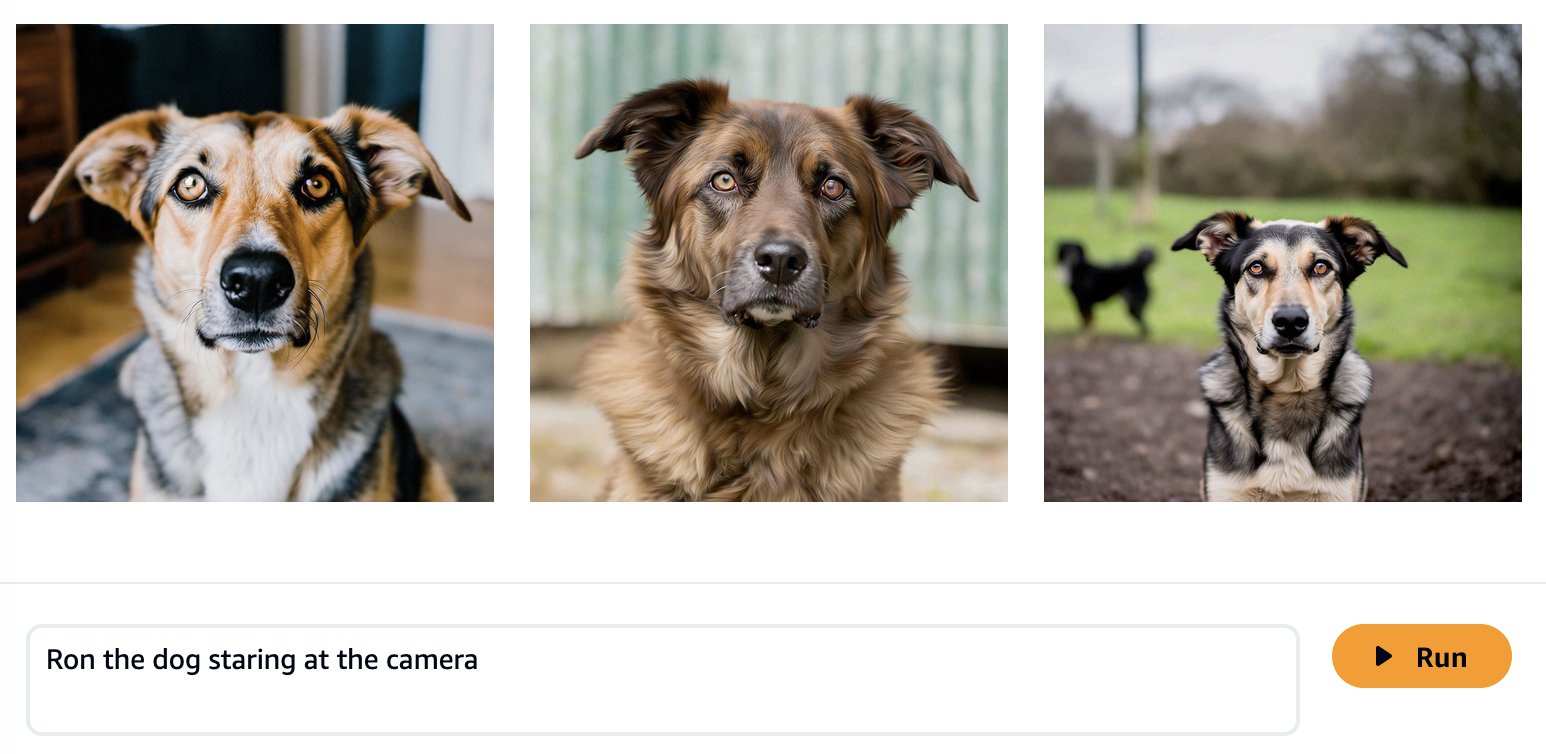

Seperti yang diharapkan, model out-of-the-box belum mengenal Ron dan Smila, dan keluaran yang dihasilkan menunjukkan anjing dan kucing yang berbeda. Dengan beberapa rekayasa yang cepat, kami dapat memberikan lebih banyak detail untuk lebih mendekati tampilan hewan peliharaan favorit kami.


Meskipun gambar yang dihasilkan lebih mirip dengan Ron dan Smila, kami melihat bahwa model tersebut tidak mampu mereproduksi kemiripan sepenuhnya. Sekarang mari kita mulai menyempurnakan foto dari Ron dan Smila untuk mendapatkan hasil yang konsisten dan dipersonalisasi.
Menyempurnakan Generator Gambar Amazon Titan
Amazon Bedrock memberi Anda pengalaman tanpa server untuk menyempurnakan model Amazon Titan Image Generator Anda. Anda hanya perlu menyiapkan data dan memilih hyperparameter, dan AWS akan menangani tugas berat tersebut untuk Anda.
Saat Anda menggunakan model Amazon Titan Image Generator untuk menyempurnakan, salinan model ini dibuat di akun pengembangan model AWS, dimiliki dan dikelola oleh AWS, dan tugas penyesuaian model dibuat. Pekerjaan ini kemudian mengakses data penyesuaian dari VPC dan bobot model amazon Titan diperbarui. Model baru kemudian disimpan ke Layanan Penyimpanan Sederhana Amazon (Amazon S3) terletak di akun pengembangan model yang sama dengan model terlatih. Sekarang dapat digunakan untuk inferensi hanya oleh akun Anda dan tidak dibagikan dengan akun AWS lainnya. Saat menjalankan inferensi, Anda mengakses model ini melalui a komputasi kapasitas yang disediakan atau secara langsung, menggunakan inferensi batch untuk Amazon Bedrock. Terlepas dari modalitas inferensi yang dipilih, data Anda tetap ada di akun Anda dan tidak disalin ke akun milik AWS mana pun atau digunakan untuk meningkatkan model Amazon Titan Image Generator.
Diagram berikut menggambarkan alur kerja ini.
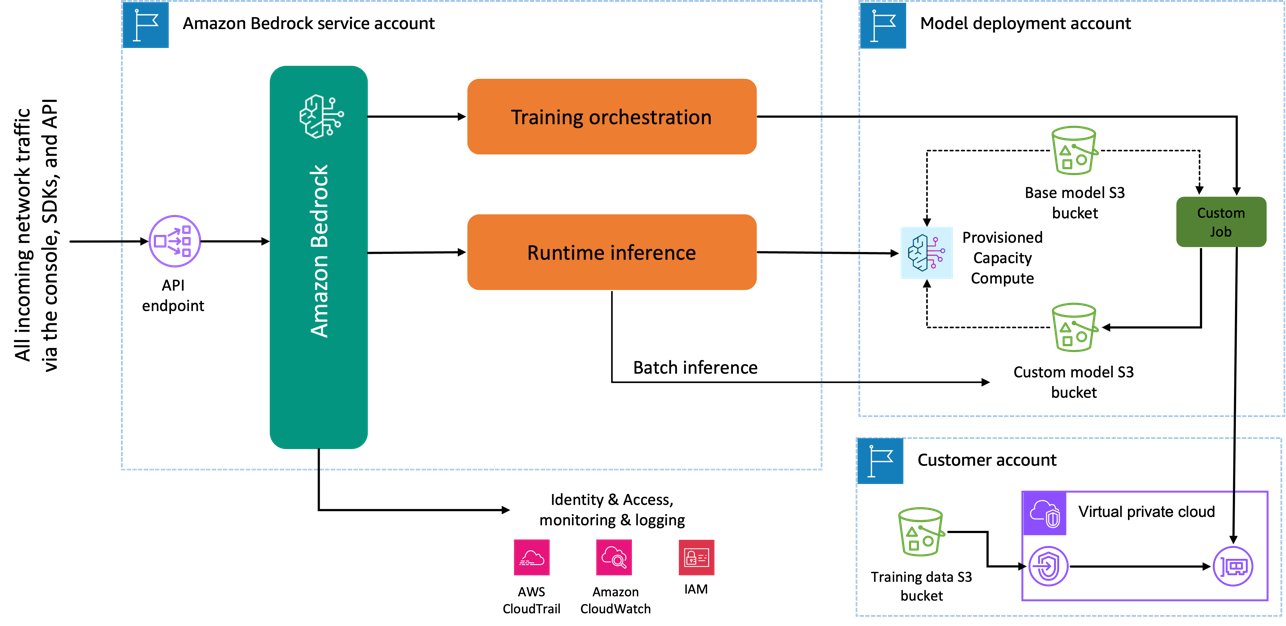
Privasi data dan keamanan jaringan
Data Anda yang digunakan untuk penyesuaian termasuk perintah, serta model kustom, tetap bersifat pribadi di akun AWS Anda. Mereka tidak dibagikan atau digunakan untuk pelatihan model atau peningkatan layanan, dan tidak dibagikan dengan penyedia model pihak ketiga. Semua data yang digunakan untuk penyesuaian dienkripsi saat transit dan saat disimpan. Data tetap berada di Wilayah yang sama tempat panggilan API diproses. Anda juga bisa menggunakan Tautan Pribadi AWS untuk membuat koneksi pribadi antara akun AWS tempat data Anda berada dan VPC.
Persiapan data
Sebelum Anda dapat membuat pekerjaan penyesuaian model, Anda perlu melakukannya siapkan dataset pelatihan Anda. Format set data pelatihan Anda bergantung pada jenis pekerjaan penyesuaian yang Anda buat (penyempurnaan atau pra-pelatihan lanjutan) dan modalitas data Anda (teks-ke-teks, teks-ke-gambar, atau gambar-ke- penyematan). Untuk model Amazon Titan Image Generator, Anda perlu menyediakan gambar yang ingin Anda gunakan untuk penyesuaian dan keterangan untuk setiap gambar. Amazon Bedrock mengharapkan gambar Anda disimpan di Amazon S3 dan pasangan gambar serta keterangan disediakan dalam format JSONL dengan beberapa baris JSON.
Setiap baris JSON adalah sampel yang berisi referensi gambar, URI S3 untuk gambar, dan keterangan yang menyertakan perintah tekstual untuk gambar tersebut. Gambar Anda harus dalam format JPEG atau PNG. Kode berikut menunjukkan contoh formatnya:
{"image-ref": "s3://bucket/path/to/image001.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image002.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image003.png", "caption": ""}
Karena “Ron” dan “Smila” adalah nama yang juga dapat digunakan dalam konteks lain, seperti nama seseorang, kami menambahkan pengidentifikasi “Ron si anjing” dan “Smila si kucing” saat membuat perintah untuk menyempurnakan model kami . Meskipun bukan merupakan persyaratan untuk penyempurnaan alur kerja, informasi tambahan ini memberikan kejelasan yang lebih kontekstual untuk model saat model tersebut disesuaikan untuk kelas baru dan akan menghindari kebingungan antara '"Ron si anjing" dengan seseorang bernama Ron dan " Smila si kucing” dengan kota Smila di Ukraina. Dengan menggunakan logika ini, gambar berikut menunjukkan contoh kumpulan data pelatihan kami.
 |
 |
 |
| Ron si anjing berbaring di tempat tidur anjing putih | Ron si anjing duduk di lantai ubin | Ron si anjing berbaring di kursi mobil |
 |
 |
 |
| Smila si kucing tergeletak di sofa | Smila si kucing menatap kamera sambil berbaring di sofa | Smila si kucing yang sedang berbaring di dalam kandang hewan peliharaan |
Saat mengubah data kami ke format yang diharapkan oleh pekerjaan penyesuaian, kami mendapatkan struktur sampel berikut:
{"ref-gambar": "/ron_01.jpg", "caption": "Ron si anjing berbaring di tempat tidur anjing berwarna putih"} {"image-ref": "/ron_02.jpg", "caption": "Ron si anjing duduk di lantai keramik"} {"image-ref": "/ron_03.jpg", "caption": "Ron si anjing berbaring di kursi mobil"} {"image-ref": "/smila_01.jpg", "caption": "Smila si kucing berbaring di sofa"} {"image-ref": "/smila_02.jpg", "caption": "Smila si kucing duduk di sebelah jendela di sebelah patung kucing"} {"image-ref": "/smila_03.jpg", "caption": "Smila si kucing tergeletak di atas kandang hewan peliharaan"}
Setelah kita membuat file JSONL, kita perlu menyimpannya di bucket S3 untuk memulai pekerjaan penyesuaian. Pekerjaan penyesuaian Amazon Titan Image Generator G1 akan berfungsi dengan 5–10,000 gambar. Untuk contoh yang dibahas dalam postingan ini, kami menggunakan 60 gambar: 30 gambar Ron si anjing dan 30 gambar Smila si kucing. Secara umum, menyediakan lebih banyak variasi gaya atau kelas yang Anda coba pelajari akan meningkatkan akurasi model yang Anda sesuaikan. Namun, semakin banyak gambar yang Anda gunakan untuk penyempurnaan, semakin banyak waktu yang dibutuhkan untuk menyelesaikan pekerjaan penyempurnaan. Jumlah gambar yang digunakan juga memengaruhi harga pekerjaan Anda yang telah disesuaikan. Mengacu pada Harga Batuan Dasar Amazon for more information.
Menyempurnakan Generator Gambar Amazon Titan
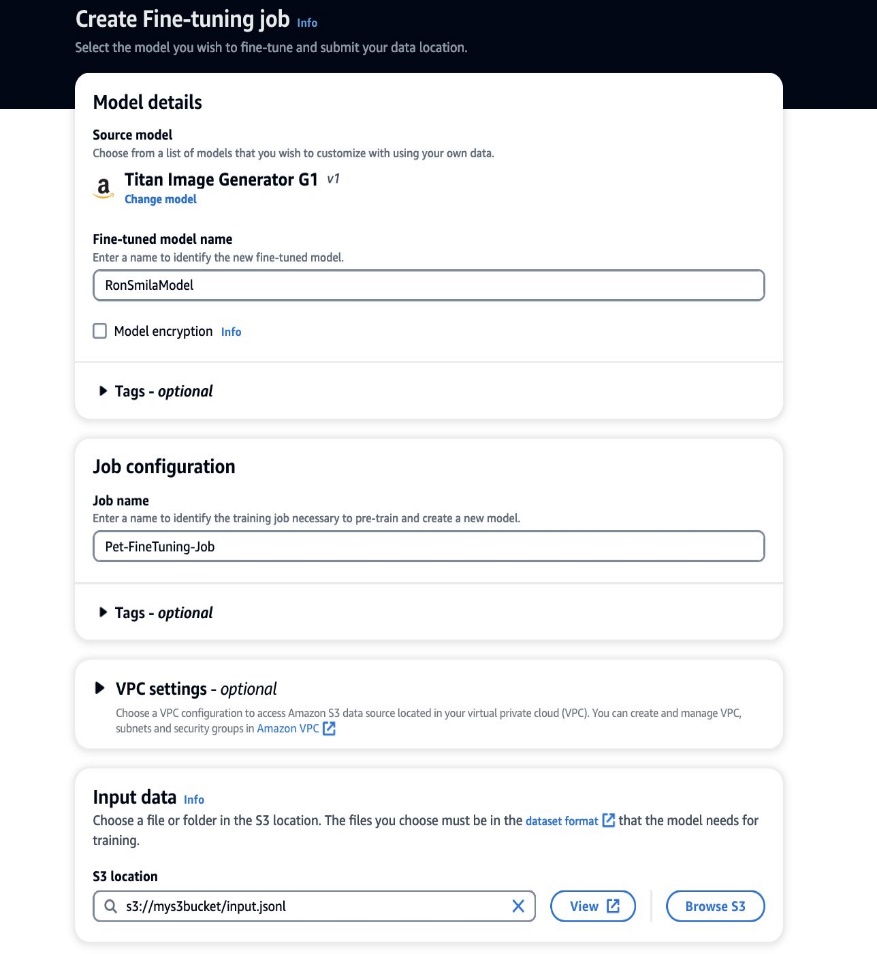
Sekarang setelah data pelatihan kami siap, kami dapat memulai pekerjaan penyesuaian baru. Proses ini dapat dilakukan melalui konsol Amazon Bedrock atau API. Untuk menggunakan konsol Amazon Bedrock, selesaikan langkah-langkah berikut:
- Di konsol Amazon Bedrock, pilih Model khusus di panel navigasi.
- pada Sesuaikan modelnya menu, pilih Ciptakan pekerjaan penyesuaian.
- Untuk Nama model yang disesuaikan, masukkan nama untuk model baru Anda.
- Untuk Konfigurasi pekerjaan, masukkan nama untuk pekerjaan pelatihan.
- Untuk Memasukan data, masukkan jalur S3 dari data input.
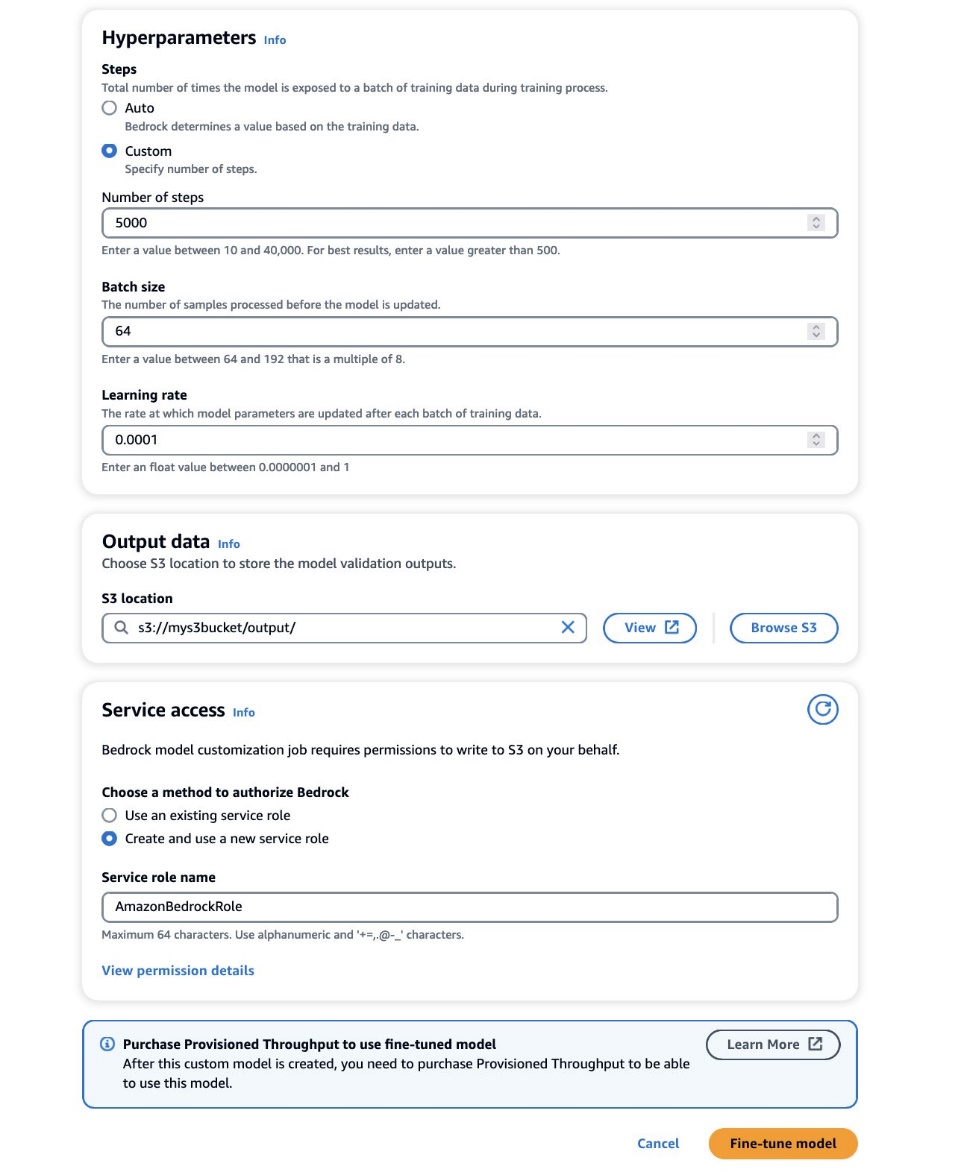
- Dalam majalah Hyperparameter bagian, berikan nilai untuk hal berikut:
- Jumlah langkah – Berapa kali model diekspos ke setiap batch.
- Ukuran batch – Jumlah sampel yang diproses sebelum memperbarui parameter model.
- Tingkat belajar – Kecepatan pembaruan parameter model setelah setiap batch. Pilihan parameter ini bergantung pada kumpulan data tertentu. Sebagai pedoman umum, kami menyarankan Anda memulai dengan menetapkan ukuran batch menjadi 8, kecepatan pemelajaran menjadi 1e-5, dan mengatur jumlah langkah sesuai dengan jumlah gambar yang digunakan, sebagaimana dirinci dalam tabel berikut.
| Jumlah gambar yang disediakan | 8 | 32 | 64 | 1,000 | 10,000 |
| Jumlah langkah yang direkomendasikan | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
Jika hasil pekerjaan penyempurnaan Anda tidak memuaskan, pertimbangkan untuk menambah jumlah langkah jika Anda tidak melihat tanda-tanda gaya apa pun pada gambar yang dihasilkan, dan kurangi jumlah langkah jika Anda mengamati gaya pada gambar yang dihasilkan tetapi dengan artefak atau keburaman. Jika model yang disempurnakan gagal mempelajari gaya unik dalam kumpulan data Anda bahkan setelah 40,000 langkah, pertimbangkan untuk meningkatkan ukuran batch atau kecepatan pembelajaran.
- Dalam majalah Data keluaran bagian, masukkan jalur output S3 tempat output validasi, termasuk metrik kehilangan dan akurasi validasi yang dicatat secara berkala, disimpan.
- Dalam majalah Akses layanan bagian, buat yang baru Identitas AWS dan Manajemen Akses (IAM) role atau pilih IAM role yang ada dengan izin yang diperlukan untuk mengakses bucket S3 Anda.
Otorisasi ini memungkinkan Amazon Bedrock untuk mengambil set data input dan validasi dari bucket yang Anda tunjuk dan menyimpan output validasi dengan lancar di bucket S3 Anda.
- Pilih Sempurnakan modelnya.
Dengan konfigurasi yang benar, Amazon Bedrock kini akan melatih model kustom Anda.
Terapkan Amazon Titan Image Generator yang telah disempurnakan dengan Throughput yang Disediakan
Setelah Anda membuat model kustom, Throughput yang Disediakan memungkinkan Anda mengalokasikan kapasitas pemrosesan tingkat tetap yang telah ditentukan ke model kustom. Alokasi ini memberikan tingkat performa dan kapasitas penanganan beban kerja yang konsisten, sehingga menghasilkan performa beban kerja produksi yang lebih baik. Keuntungan kedua dari Throughput yang Disediakan adalah pengendalian biaya, karena penetapan harga berbasis token standar dengan mode inferensi sesuai permintaan mungkin sulit diprediksi dalam skala besar.
Ketika penyempurnaan model Anda selesai, model ini akan muncul di Model khusus' halaman di konsol Amazon Bedrock.
Untuk membeli Throughput yang Disediakan, pilih model kustom yang baru saja Anda sesuaikan dan pilih Beli Throughput yang Disediakan.
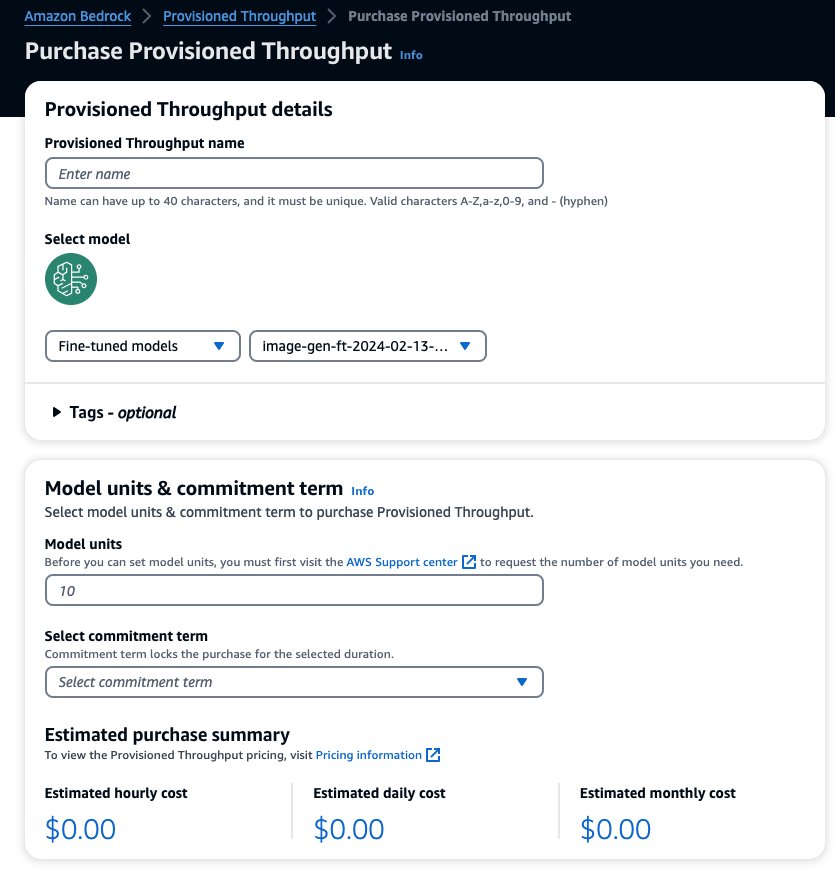
Ini akan mengisi model terpilih yang ingin Anda beli Throughput yang Disediakan. Untuk menguji model yang telah Anda sesuaikan sebelum penerapan, tetapkan unit model ke nilai 1 dan tetapkan jangka waktu komitmen Tidak ada komitmen. Ini dengan cepat memungkinkan Anda mulai menguji model Anda dengan perintah khusus dan memeriksa apakah pelatihannya memadai. Selain itu, ketika model baru yang telah disempurnakan dan versi baru tersedia, Anda dapat memperbarui Throughput yang Disediakan selama Anda memperbaruinya dengan versi lain dari model yang sama.
Hasil penyempurnaan
Untuk tugas kami menyesuaikan model pada Ron si anjing dan Smila si kucing, eksperimen menunjukkan bahwa hyperparameter terbaik adalah 5,000 langkah dengan ukuran batch 8 dan kecepatan pembelajaran 1e-5.
Berikut adalah beberapa contoh gambar yang dihasilkan oleh model yang disesuaikan.
 |
 |
 |
| Ron si anjing mengenakan jubah pahlawan super | Ron si anjing di bulan | Ron si anjing di kolam renang dengan kacamata hitam |
 |
 |
 |
| Tersenyumlah kucing di atas salju | Smila si kucing hitam putih menatap ke arah kamera | Smila si kucing memakai topi Natal |
Kesimpulan
Dalam postingan ini, kami membahas kapan harus menggunakan penyesuaian daripada merekayasa perintah Anda untuk menghasilkan gambar dengan kualitas lebih baik. Kami menunjukkan cara menyempurnakan model Amazon Titan Image Generator dan menerapkan model kustom di Amazon Bedrock. Kami juga memberikan panduan umum tentang cara menyiapkan data Anda untuk penyesuaian dan menetapkan hyperparameter optimal untuk penyesuaian model yang lebih akurat.
Sebagai langkah selanjutnya, Anda dapat menyesuaikan yang berikut ini contoh ke kasus penggunaan Anda untuk menghasilkan gambar yang sangat dipersonalisasi menggunakan Amazon Titan Image Generator.
Tentang Penulis
 Maira Ladeira Tanke adalah Ilmuwan Data AI Generatif Senior di AWS. Dengan latar belakang pembelajaran mesin, dia memiliki pengalaman lebih dari 10 tahun dalam merancang dan membangun aplikasi AI dengan pelanggan di berbagai industri. Sebagai pemimpin teknis, dia membantu pelanggan mempercepat pencapaian nilai bisnis mereka melalui solusi AI generatif di Amazon Bedrock. Di waktu luangnya, Maira senang jalan-jalan, bermain dengan kucingnya Smila, dan menghabiskan waktu bersama keluarganya di tempat yang hangat.
Maira Ladeira Tanke adalah Ilmuwan Data AI Generatif Senior di AWS. Dengan latar belakang pembelajaran mesin, dia memiliki pengalaman lebih dari 10 tahun dalam merancang dan membangun aplikasi AI dengan pelanggan di berbagai industri. Sebagai pemimpin teknis, dia membantu pelanggan mempercepat pencapaian nilai bisnis mereka melalui solusi AI generatif di Amazon Bedrock. Di waktu luangnya, Maira senang jalan-jalan, bermain dengan kucingnya Smila, dan menghabiskan waktu bersama keluarganya di tempat yang hangat.
 Dani Mitchell adalah Arsitek Solusi Spesialis AI/ML di Amazon Web Services. Dia fokus pada kasus penggunaan visi komputer dan membantu pelanggan di seluruh EMEA mempercepat perjalanan ML mereka.
Dani Mitchell adalah Arsitek Solusi Spesialis AI/ML di Amazon Web Services. Dia fokus pada kasus penggunaan visi komputer dan membantu pelanggan di seluruh EMEA mempercepat perjalanan ML mereka.
 Bharathi Srinivasan adalah Ilmuwan Data di AWS Professional Services, tempat dia senang membuat hal-hal keren di Amazon Bedrock. Dia bersemangat mendorong nilai bisnis dari aplikasi pembelajaran mesin, dengan fokus pada AI yang bertanggung jawab. Selain membangun pengalaman AI baru bagi pelanggan, Bharathi suka menulis fiksi ilmiah dan menantang dirinya sendiri dengan olahraga ketahanan.
Bharathi Srinivasan adalah Ilmuwan Data di AWS Professional Services, tempat dia senang membuat hal-hal keren di Amazon Bedrock. Dia bersemangat mendorong nilai bisnis dari aplikasi pembelajaran mesin, dengan fokus pada AI yang bertanggung jawab. Selain membangun pengalaman AI baru bagi pelanggan, Bharathi suka menulis fiksi ilmiah dan menantang dirinya sendiri dengan olahraga ketahanan.
 Achin Jain adalah Ilmuwan Terapan di tim Amazon Artificial General Intelligence (AGI). Dia memiliki keahlian dalam model teks-ke-gambar dan fokus membangun Amazon Titan Image Generator.
Achin Jain adalah Ilmuwan Terapan di tim Amazon Artificial General Intelligence (AGI). Dia memiliki keahlian dalam model teks-ke-gambar dan fokus membangun Amazon Titan Image Generator.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

