Dalam postingan ini, kami mendemonstrasikan cara menyempurnakan model bahasa protein (pLM) yang canggih secara efisien untuk memprediksi lokalisasi subseluler protein menggunakan Amazon SageMaker.
Protein adalah mesin molekuler tubuh, yang bertanggung jawab atas segala hal mulai dari menggerakkan otot hingga merespons infeksi. Meskipun beragam, semua protein terbuat dari rantai molekul berulang yang disebut asam amino. Genom manusia mengkodekan 20 asam amino standar, masing-masing dengan struktur kimia yang sedikit berbeda. Ini dapat direpresentasikan dengan huruf alfabet, yang kemudian memungkinkan kita menganalisis dan mengeksplorasi protein sebagai string teks. Jumlah urutan dan struktur protein yang sangat besar inilah yang membuat protein memiliki beragam kegunaan.
Protein juga memainkan peran penting dalam pengembangan obat, sebagai target potensial tetapi juga sebagai terapi. Seperti yang ditunjukkan pada tabel berikut, banyak obat terlaris pada tahun 2022 berupa protein (terutama antibodi) atau molekul lain seperti mRNA yang diterjemahkan menjadi protein dalam tubuh. Oleh karena itu, banyak peneliti ilmu hayati perlu menjawab pertanyaan tentang protein dengan lebih cepat, lebih murah, dan lebih akurat.
| Nama | Pabrikan | Penjualan Global 2022 ($ miliar USD) | Indikasi |
| Komirnati | Pfizer / BioNTech | $40.8 | Covid-19 |
| Spikevax.dll | Modern | $21.8 | Covid-19 |
| Humira | AbbVie | $21.6 | Artritis, penyakit Crohn, dan lain-lain |
| keytruda | Merck | $21.0 | Berbagai kanker |
Sumber data: Urquhart, L. Perusahaan dan obat-obatan teratas berdasarkan penjualan pada tahun 2022. Tinjauan Alam Penemuan Obat 22, 260–260 (2023).
Karena kita dapat merepresentasikan protein sebagai rangkaian karakter, kita dapat menganalisisnya menggunakan teknik yang awalnya dikembangkan untuk bahasa tertulis. Hal ini mencakup model bahasa besar (LLM) yang dilatih sebelumnya pada kumpulan data besar, yang kemudian dapat diadaptasi untuk tugas tertentu, seperti peringkasan teks atau chatbots. Demikian pula, pLM telah dilatih sebelumnya pada database urutan protein besar menggunakan pembelajaran tanpa label dan diawasi sendiri. Kita dapat mengadaptasinya untuk memprediksi hal-hal seperti struktur 3D suatu protein atau bagaimana protein tersebut berinteraksi dengan molekul lain. Para peneliti bahkan telah menggunakan pLM untuk merancang protein baru dari awal. Alat-alat ini tidak menggantikan keahlian ilmiah manusia, namun memiliki potensi untuk mempercepat pengembangan pra-klinis dan desain uji coba.
Salah satu tantangan pada model ini adalah ukurannya. Baik LLM maupun pLM telah berkembang pesat dalam beberapa tahun terakhir, seperti yang diilustrasikan pada gambar berikut. Artinya, diperlukan waktu lama untuk melatihnya hingga mencapai akurasi yang memadai. Ini juga berarti Anda perlu menggunakan perangkat keras, terutama GPU, dengan memori dalam jumlah besar untuk menyimpan parameter model.
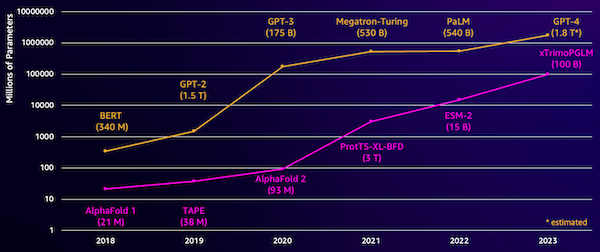
Waktu pelatihan yang lama, ditambah contoh yang besar, sama dengan biaya tinggi, sehingga pekerjaan ini tidak terjangkau oleh banyak peneliti. Misalnya pada tahun 2023, a tim peneliti menjelaskan pelatihan pLM 100 miliar parameter pada 768 GPU A100 selama 164 hari! Untungnya, dalam banyak kasus kita dapat menghemat waktu dan sumber daya dengan mengadaptasi pLM yang ada untuk tugas spesifik kita. Teknik ini disebut mencari setelan, dan juga memungkinkan kita meminjam alat canggih dari jenis pemodelan bahasa lainnya.
Ikhtisar solusi
Masalah khusus yang kami bahas dalam posting ini adalah lokalisasi subseluler: Dengan adanya rangkaian protein, dapatkah kita membuat model yang dapat memprediksi apakah ia hidup di luar (membran sel) atau di dalam sel? Ini adalah informasi penting yang dapat membantu kita memahami fungsinya dan apakah obat tersebut dapat menjadi sasaran obat yang baik.
Kami mulai dengan mengunduh kumpulan data publik menggunakan Studio Amazon SageMaker. Kemudian kami menggunakan SageMaker untuk menyempurnakan model bahasa protein ESM-2 menggunakan metode pelatihan yang efisien. Terakhir, kami menerapkan model tersebut sebagai titik akhir inferensi real-time dan menggunakannya untuk menguji beberapa protein yang diketahui. Diagram berikut menggambarkan alur kerja ini.

Di bagian berikut, kita akan melalui langkah-langkah untuk menyiapkan data pelatihan Anda, membuat skrip pelatihan, dan menjalankan tugas pelatihan SageMaker. Semua kode yang ditampilkan dalam posting ini tersedia di GitHub.
Siapkan data pelatihan
Kami menggunakan bagian dari Kumpulan data DeepLoc-2, yang berisi beberapa ribu protein SwissProt dengan lokasi yang ditentukan secara eksperimental. Kami memfilter urutan berkualitas tinggi antara 100–512 asam amino:
df = pd.read_csv(
"https://services.healthtech.dtu.dk/services/DeepLoc-2.0/data/Swissprot_Train_Validation_dataset.csv"
).drop(["Unnamed: 0", "Partition"], axis=1)
df["Membrane"] = df["Membrane"].astype("int32")
# filter for sequences between 100 and 512 amino acides
df = df[df["Sequence"].apply(lambda x: len(x)).between(100, 512)]
# Remove unnecessary features
df = df[["Sequence", "Kingdom", "Membrane"]]
Selanjutnya, kami memberi token pada urutannya dan membaginya menjadi set pelatihan dan evaluasi:
dataset = Dataset.from_pandas(df).train_test_split(test_size=0.2, shuffle=True)
tokenizer = AutoTokenizer.from_pretrained("facebook/esm2_t33_650M_UR50D")
def preprocess_data(examples, max_length=512):
text = examples["Sequence"]
encoding = tokenizer(text, truncation=True, max_length=max_length)
encoding["labels"] = examples["Membrane"]
return encoding
encoded_dataset = dataset.map(
preprocess_data,
batched=True,
num_proc=os.cpu_count(),
remove_columns=dataset["train"].column_names,
)
encoded_dataset.set_format("torch")
Terakhir, kami mengunggah data pelatihan dan evaluasi yang telah diproses ke Layanan Penyimpanan Sederhana Amazon (Amazon S3):
train_s3_uri = S3_PATH + "/data/train"
test_s3_uri = S3_PATH + "/data/test"
encoded_dataset["train"].save_to_disk(train_s3_uri)
encoded_dataset["test"].save_to_disk(test_s3_uri)Buat skrip pelatihan
Mode skrip SageMaker memungkinkan Anda menjalankan kode pelatihan khusus dalam wadah kerangka pembelajaran mesin (ML) yang dioptimalkan yang dikelola oleh AWS. Untuk contoh ini, kami mengadaptasi sebuah skrip yang ada untuk klasifikasi teks dari Memeluk Wajah. Hal ini memungkinkan kami untuk mencoba beberapa metode untuk meningkatkan efisiensi pekerjaan pelatihan kami.
Metode 1: Kelas pelatihan berbobot
Seperti banyak kumpulan data biologis, data DeepLoc tidak terdistribusi secara merata, yang berarti jumlah protein membran dan non-membran tidak sama. Kita dapat mengambil sampel ulang data kita dan membuang catatan dari kelas mayoritas. Namun, hal ini akan mengurangi total data pelatihan dan berpotensi merusak akurasi kami. Sebagai gantinya, kami menghitung bobot kelas selama tugas pelatihan dan menggunakannya untuk menyesuaikan kerugiannya.
Dalam skrip pelatihan kami, kami membuat subkelas Trainer kelas dari transformers dengan WeightedTrainer kelas yang memperhitungkan bobot kelas saat menghitung kerugian lintas entropi. Hal ini membantu mencegah bias dalam model kami:
class WeightedTrainer(Trainer):
def __init__(self, class_weights, *args, **kwargs):
self.class_weights = class_weights
super().__init__(*args, **kwargs)
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
outputs = model(**inputs)
logits = outputs.get("logits")
loss_fct = torch.nn.CrossEntropyLoss(
weight=torch.tensor(self.class_weights, device=model.device)
)
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else lossMetode 2: Akumulasi gradien
Akumulasi gradien adalah teknik pelatihan yang memungkinkan model mensimulasikan pelatihan pada ukuran batch yang lebih besar. Biasanya, ukuran batch (jumlah sampel yang digunakan untuk menghitung gradien dalam satu langkah pelatihan) dibatasi oleh kapasitas memori GPU. Dengan akumulasi gradien, model menghitung gradien pada kelompok yang lebih kecil terlebih dahulu. Kemudian, alih-alih memperbarui bobot model secara langsung, gradiennya terakumulasi dalam beberapa kelompok kecil. Ketika akumulasi gradien sama dengan ukuran kumpulan target yang lebih besar, langkah pengoptimalan dilakukan untuk memperbarui model. Hal ini memungkinkan model berlatih dengan batch yang lebih besar secara efektif tanpa melebihi batas memori GPU.
Namun, perhitungan ekstra diperlukan untuk gerakan maju dan mundur dalam jumlah yang lebih kecil. Peningkatan ukuran batch melalui akumulasi gradien dapat memperlambat pelatihan, terutama jika terlalu banyak langkah akumulasi yang digunakan. Tujuannya adalah untuk memaksimalkan penggunaan GPU namun menghindari perlambatan berlebihan akibat terlalu banyak langkah komputasi gradien tambahan.
Metode 3: Pos pemeriksaan gradien
Pos pemeriksaan gradien adalah teknik yang mengurangi memori yang dibutuhkan selama pelatihan sekaligus menjaga waktu komputasi tetap masuk akal. Jaringan neural yang besar memakan banyak memori karena harus menyimpan semua nilai antara dari forward pass untuk menghitung gradien selama backward pass. Hal ini dapat menyebabkan masalah memori. Salah satu solusinya adalah dengan tidak menyimpan nilai-nilai perantara ini, namun kemudian nilai-nilai tersebut harus dihitung ulang selama proses backward pass, yang memerlukan banyak waktu.
Pos pemeriksaan gradien memberikan pendekatan yang seimbang. Ini hanya menyimpan beberapa nilai perantara, yang disebut pos pemeriksaan, dan menghitung ulang yang lain sesuai kebutuhan. Oleh karena itu, ia menggunakan lebih sedikit memori dibandingkan menyimpan semuanya, namun juga lebih sedikit komputasi dibandingkan menghitung ulang semuanya. Dengan memilih secara strategis aktivasi mana yang akan diposkan, pos pemeriksaan gradien memungkinkan jaringan neural besar dilatih dengan penggunaan memori dan waktu komputasi yang dapat dikelola. Teknik penting ini memungkinkan untuk melatih model yang sangat besar yang mungkin mengalami keterbatasan memori.
Dalam skrip pelatihan kami, kami mengaktifkan aktivasi gradien dan pos pemeriksaan dengan menambahkan parameter yang diperlukan ke TrainingArguments obyek:
from transformers import TrainingArguments
training_args = TrainingArguments(
gradient_accumulation_steps=4,
gradient_checkpointing=True
)Metode 4: Adaptasi LLM Tingkat Rendah
Model bahasa besar seperti ESM-2 dapat berisi miliaran parameter yang mahal untuk dilatih dan dijalankan. Peneliti mengembangkan metode pelatihan yang disebut Adaptasi Tingkat Rendah (LoRA) untuk menyempurnakan model besar ini menjadi lebih efisien.
Ide utama di balik LoRA adalah ketika menyempurnakan model untuk tugas tertentu, Anda tidak perlu memperbarui semua parameter asli. Sebaliknya, LoRA menambahkan matriks baru yang lebih kecil ke model yang mengubah masukan dan keluaran. Hanya matriks yang lebih kecil ini yang diperbarui selama penyesuaian, yang jauh lebih cepat dan menggunakan lebih sedikit memori. Parameter model asli tetap dibekukan.
Setelah menyempurnakan LoRA, Anda dapat menggabungkan matriks kecil yang diadaptasi kembali ke model aslinya. Atau Anda dapat memisahkannya jika Anda ingin menyempurnakan model untuk tugas lain dengan cepat tanpa melupakan tugas sebelumnya. Secara keseluruhan, LoRA memungkinkan LLM beradaptasi secara efisien terhadap tugas-tugas baru dengan biaya yang lebih murah.
Dalam skrip pelatihan kami, kami mengonfigurasi LoRA menggunakan PEFT perpustakaan dari Hugging Face:
from peft import get_peft_model, LoraConfig, TaskType
import torch
from transformers import EsmForSequenceClassification
model = EsmForSequenceClassification.from_pretrained(
“facebook/esm2_t33_650M_UR50D”,
Torch_dtype=torch.bfloat16,
Num_labels=2,
)
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
bias="none",
r=8,
lora_alpha=16,
lora_dropout=0.05,
target_modules=[
"query",
"key",
"value",
"EsmSelfOutput.dense",
"EsmIntermediate.dense",
"EsmOutput.dense",
"EsmContactPredictionHead.regression",
"EsmClassificationHead.dense",
"EsmClassificationHead.out_proj",
]
)
model = get_peft_model(model, peft_config)Kirimkan pekerjaan pelatihan SageMaker
Setelah Anda menentukan skrip pelatihan, Anda dapat mengonfigurasi dan mengirimkan tugas pelatihan SageMaker. Pertama, tentukan hyperparameternya:
hyperparameters = {
"model_id": "facebook/esm2_t33_650M_UR50D",
"epochs": 1,
"per_device_train_batch_size": 8,
"gradient_accumulation_steps": 4,
"use_gradient_checkpointing": True,
"lora": True,
}Selanjutnya, tentukan metrik apa yang akan diambil dari log pelatihan:
metric_definitions = [
{"Name": "epoch", "Regex": "'epoch': ([0-9.]*)"},
{
"Name": "max_gpu_mem",
"Regex": "Max GPU memory use during training: ([0-9.e-]*) MB",
},
{"Name": "train_loss", "Regex": "'loss': ([0-9.e-]*)"},
{
"Name": "train_samples_per_second",
"Regex": "'train_samples_per_second': ([0-9.e-]*)",
},
{"Name": "eval_loss", "Regex": "'eval_loss': ([0-9.e-]*)"},
{"Name": "eval_accuracy", "Regex": "'eval_accuracy': ([0-9.e-]*)"},
]Terakhir, tentukan estimator Hugging Face dan kirimkan untuk pelatihan pada jenis instans ml.g5.2xlarge. Ini adalah jenis instans hemat biaya yang tersedia secara luas di banyak Wilayah AWS:
from sagemaker.experiments.run import Run
from sagemaker.huggingface import HuggingFace
from sagemaker.inputs import TrainingInput
hf_estimator = HuggingFace(
base_job_name="esm-2-membrane-ft",
entry_point="lora-train.py",
source_dir="scripts",
instance_type="ml.g5.2xlarge",
instance_count=1,
transformers_version="4.28",
pytorch_version="2.0",
py_version="py310",
output_path=f"{S3_PATH}/output",
role=sagemaker_execution_role,
hyperparameters=hyperparameters,
metric_definitions=metric_definitions,
checkpoint_local_path="/opt/ml/checkpoints",
sagemaker_session=sagemaker_session,
keep_alive_period_in_seconds=3600,
tags=[{"Key": "project", "Value": "esm-fine-tuning"}],
)
with Run(
experiment_name=EXPERIMENT_NAME,
sagemaker_session=sagemaker_session,
) as run:
hf_estimator.fit(
{
"train": TrainingInput(s3_data=train_s3_uri),
"test": TrainingInput(s3_data=test_s3_uri),
}
)Tabel berikut membandingkan berbagai metode pelatihan yang telah kita diskusikan dan pengaruhnya terhadap waktu proses, akurasi, dan kebutuhan memori GPU dalam pekerjaan kita.
| konfigurasi | Waktu yang Dapat Ditagih (menit) | Akurasi Evaluasi | Penggunaan Memori GPU Maks (GB) |
| Model dasar | 28 | 0.91 | 22.6 |
| Basis + GA | 21 | 0.90 | 17.8 |
| Basis + GC | 29 | 0.91 | 10.2 |
| Basis + LoRA | 23 | 0.90 | 18.6 |
Semua metode tersebut menghasilkan model dengan akurasi evaluasi yang tinggi. Penggunaan LoRA dan aktivasi gradien menurunkan waktu proses (dan biaya) masing-masing sebesar 18% dan 25%. Menggunakan pos pemeriksaan gradien mengurangi penggunaan memori GPU maksimum sebesar 55%. Tergantung pada kendala Anda (biaya, waktu, perangkat keras), salah satu pendekatan ini mungkin lebih masuk akal dibandingkan pendekatan lainnya.
Masing-masing metode ini bekerja dengan baik jika dilakukan sendiri-sendiri, tetapi apa yang terjadi jika kita menggunakannya secara kombinasi? Tabel berikut merangkum hasilnya.
| konfigurasi | Waktu yang Dapat Ditagih (menit) | Akurasi Evaluasi | Penggunaan Memori GPU Maks (GB) |
| Semua metode | 12 | 0.80 | 3.3 |
Dalam kasus ini, kami melihat penurunan akurasi sebesar 12%. Namun, kami telah mengurangi waktu proses sebesar 57% dan penggunaan memori GPU sebesar 85%! Ini adalah penurunan besar-besaran yang memungkinkan kami melatih berbagai jenis instans yang hemat biaya.
Membersihkan
Jika Anda mengikuti akun AWS Anda sendiri, hapus semua titik akhir inferensi real-time dan data yang Anda buat untuk menghindari biaya lebih lanjut.
predictor.delete_endpoint()
bucket = boto_session.resource("s3").Bucket(S3_BUCKET)
bucket.objects.filter(Prefix=S3_PREFIX).delete()Kesimpulan
Dalam postingan ini, kami mendemonstrasikan cara menyempurnakan model bahasa protein seperti ESM-2 secara efisien untuk tugas yang relevan secara ilmiah. Untuk informasi selengkapnya tentang penggunaan pustaka Transformers dan PEFT untuk melatih pLMS, lihat postingannya Pembelajaran Mendalam Dengan Protein dan ESMBind (ESMB): Adaptasi ESM-2 Peringkat Rendah untuk Prediksi Situs Pengikatan Protein di blog Memeluk Wajah. Anda juga dapat menemukan lebih banyak contoh penggunaan pembelajaran mesin untuk memprediksi sifat protein di Analisis Protein Luar Biasa di AWS Repositori GitHub.
tentang Penulis
 Brian Setia adalah Arsitek Solusi AI/ML Senior di tim Kesehatan Global dan Ilmu Hayati di Amazon Web Services. Dia memiliki pengalaman lebih dari 17 tahun dalam bioteknologi dan pembelajaran mesin, dan bersemangat membantu pelanggan memecahkan tantangan genomik dan proteomik. Di waktu luangnya, ia menikmati memasak dan makan bersama teman dan keluarganya.
Brian Setia adalah Arsitek Solusi AI/ML Senior di tim Kesehatan Global dan Ilmu Hayati di Amazon Web Services. Dia memiliki pengalaman lebih dari 17 tahun dalam bioteknologi dan pembelajaran mesin, dan bersemangat membantu pelanggan memecahkan tantangan genomik dan proteomik. Di waktu luangnya, ia menikmati memasak dan makan bersama teman dan keluarganya.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/efficiently-fine-tune-the-esm-2-protein-language-model-with-amazon-sagemaker/

