Artikel ini diterbitkan sebagai bagian dari Blogathon Ilmu Data.
Inilah rahasianya, metode kontrol sintetik dapat mengatasi masalah ini dengan sangat mudah dan tanpa kehilangan pendapatan atau pelanggan. Jika ini adalah eksperimen, hipotesisnya adalah – menghapus kartu sebagai metode pembayaran tidak akan memengaruhi pendapatan dan penjualan. Basis pengujian akan terdiri dari pelanggan yang tidak memiliki kartu sebagai opsi pembayaran, dan basis kontrol akan memiliki kartu sebagai opsi pembayaran.
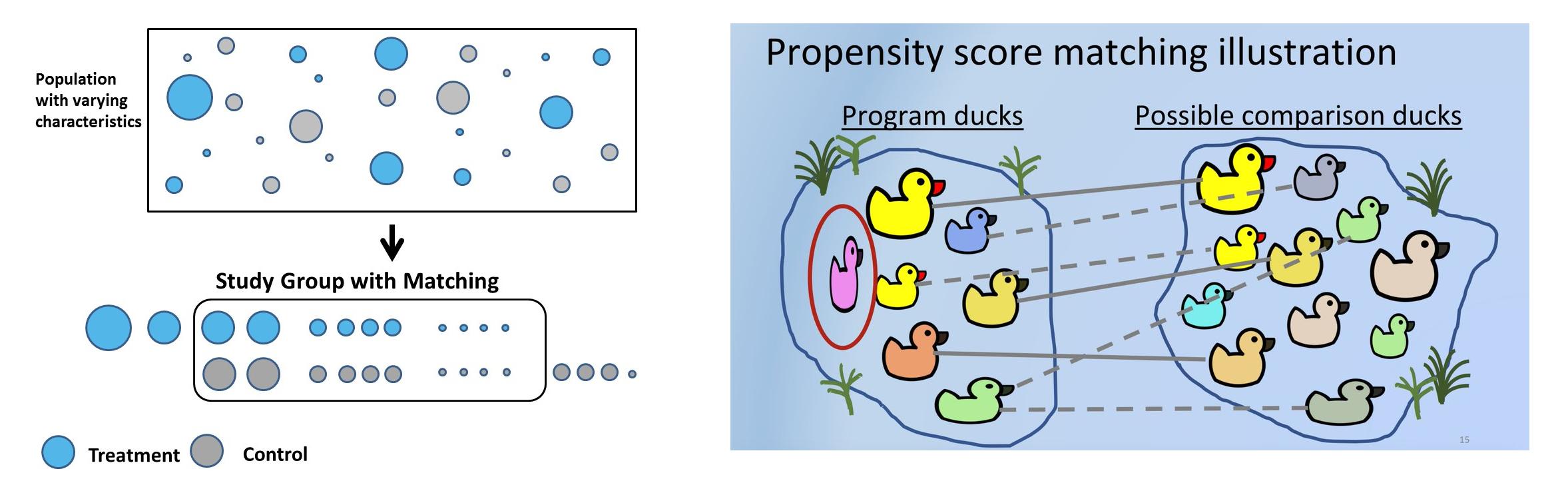
Metode Kontrol Sintetis: Studi Kasus
Metode kontrol sintetik (SCM), dengan kata sederhana, akan memilih untuk setiap pelanggan uji pelanggan kontrol serupa menggunakan serangkaian fitur atau kovariat yang telah ditentukan sebelumnya yang karakteristik pra-perawatannya serupa tetapi belum menjalani perawatan. Dalam SCM, pelanggan disebut unit, intervensi disebut perawatan, dan fitur disebut kovariat. Perusahaan menggunakan SCM untuk banyak kasus penggunaan praktis. Uber, misalnya menggunakan SCM untuk menguji apakah memberikan detail kontak pengemudi sebelum perjalanan meningkatkan kepuasan pelanggan.
Terkadang hipotesis tidak dapat diuji dalam pengaturan eksperimental karena alasan hukum, bisnis, atau platform. Misalnya: di Bangalore, biryani Meghana adalah salah satu yang terbaik, dan platform pengiriman online (Swiggy atau Zomato) memperhatikan bahwa ada kemungkinan besar pelanggan dengan pengeluaran tinggi juga memesan dari Meghana. Hipotesisnya adalah bahwa rata-rata pelanggan Meghana, membelanjakan lebih tinggi daripada yang lain. Tetapi Swiggy atau Zomato tidak dapat menghapus Meghana dari platform untuk 50% pelanggan hanya demi percobaan. Akan ada pelanggan, serta reaksi restoran. Dengan menggunakan SCM, kontrol sintetik dapat dibuat di mana pelanggan uji dan kontrol memiliki kovariat pra-perawatan yang serupa, dan hipotesis dapat divalidasi.
Memecahkan bias seleksi dan menggunakan heuristik bisnis yang tepat sambil memilih kontrol yang tepat menjadi sangat penting dan bahkan dapat membalikkan hasil eksperimen. Misalnya, pengujiannya adalah sekumpulan pelanggan yang memesan Meghana's. Untuk kontrol, pelanggan vegetarian dapat dipilih. Namun secara intrinsik, tes dan kontrol berbeda karena kontrol tidak pernah mencoba masakan non-vegetarian. Cara lain untuk mengontrol adalah pelanggan yang tidak pernah memesan biryani, tetapi ini bukan kontrol yang tepat, karena Meghana's adalah restoran yang menyajikan biryani. Cara lain untuk mengontrol menggunakan geografi. Karena Meghana tidak hadir di Delhi, pelanggan Delhi dapat digunakan sebagai kontrol. Namun kebiasaan makan pengguna Delhi berbeda dengan pengguna India selatan dan hal ini akan menimbulkan bias jika eksperimen dipecah menjadi berbagai dimensi seperti kelompok umur, jenis kelamin, dan masakan. Heuristik bisnis yang tepat dengan demikian menjadi bagian klasik saat menyelesaikan kontrol sintetik.
Daftar Isi
Kontrol sintetis dapat dibuat menggunakan pencocokan. Pencocokan skor kecenderungan adalah metode yang paling umum digunakan untuk membuat SC karena mudah, lebih sedikit memakan waktu, menghemat banyak uang, dan dapat diskalakan ke basis pengguna yang besar. Proses dapat diulang N kali hingga pengujian yang paling mirip, dan kontrol kohor dicocokkan.
Langkah-langkah yang terlibat dalam pencocokan skor kecenderungan:
- Pilih sekelompok besar pelanggan – usia, jenis kelamin, penjualan, unit, dll. Ini adalah kovariat yang dapat menyebabkan bias.
- Tujuan utamanya adalah mencocokkan kovariat sebelum intervensi. Untuk setiap pelanggan yang membayar menggunakan kartu kredit – pelanggan uji, dalam kontrol, perlu ada pelanggan yang kovariat pra-perawatannya mirip dengan tes tetapi tidak membayar menggunakan kartu tetapi menggunakan UPI atau internet banking.
- Sesuaikan model klasifikasi untuk mendapatkan skor kecenderungan. Akurasi tidak penting karena probabilitas yang diprediksi digunakan untuk mencocokkan pengguna yang berbeda. Regresi berbasis pohon atau logistik dapat digunakan. Keunggulan tree-based adalah asumsi regresi logistik dapat diabaikan.
- Dengan menggunakan skor probabilitas, katakanlah 0.6 dan 0.61 dapat dicocokkan dengan menggunakan k tetangga terdekat. Pencocokan bisa 1:1 atau 1:banyak, yang menggunakan duplikat.
- Sekarang selidiki bagaimana pengobatan telah mempengaruhi hasil. Perawatannya adalah biner, 1 atau 0. Dipesan Meghana atau tidak, kartu bekas atau tidak. Tapi hasilnya bisa terus menerus – pendapatan masa depan atau biner – bergejolak atau tidak, dll.
Pernyataan Masalah
Dataset yang digunakan di sini didasarkan pada riwayat pembayaran pelanggan. Mari kita uraikan dengan mengambil petunjuk dari pernyataan masalah kartu debit.
Hipotesis: H0: Pelanggan yang membayar dengan kartu memiliki pendapatan pos yang lebih tinggi. Hipotesis alternatif: H1: Pelanggan yang membayar dengan kartu tidak memiliki pendapatan pos yang lebih tinggi (oleh karena itu percobaan untuk menghapus pembayaran kartu sama sekali dari platform). Jika P<0.05, kita dapat menolak hipotesis nol dan secara meyakinkan mengatakan bahwa pelanggan yang membayar dengan kartu tidak memiliki pos pendapatan yang lebih tinggi.
Ada tiga periode waktu di sini: Pra-periode, yang menjadi dasar fitur/kovariat. Masa pengobatan, dimana pelanggan membayar menggunakan kartu. Periode pasca di mana hasilnya, dalam hal ini, pasca pendapatan, diukur. Memilih periode ini dengan hati-hati penting untuk menghindari bias acara, memastikan tidak ada acara promosi yang direncanakan dan dilaksanakan selama waktu ini. Misalnya, selama Oktober, November karena hari raya dan cashback dari mitra perbankan, pengguna lebih memilih kartu kredit karena menawarkan diskon 500 hingga 5000. Mempertimbangkan periode analisis ini jelas akan membiaskan hasilnya.
Demi analisis ini, mari kita asumsikan periode pra-Jan'21 hingga Juni'21, dan kovariat yang digunakan untuk melatih model diturunkan dari periode ini. Perlakuan menggunakan kartu debit/kredit selama masa pengobatan, dan merupakan variabel dependen model. Misalkan masa pengobatan adalah minggu pertama bulan Juli, dan hasil pasca haid adalah 30 hari berikutnya.
Analisis Data Eksplorasi dari kumpulan data ini telah diperbarui di sini.
Pra-Pemrosesan Data
- Baca kumpulan data dan hapus fitur yang tidak relevan. kartu_pembayaran adalah variabel dependen:
df_fintec = pd.read_csv("https://raw.githubusercontent.com/chrisdmell/Project_DataScience/working_branch/07_cred/Analytics%20Assignment/data_for_churn_analysis.csv") cols_basic_model = ['number_of_cards', 'payments_initiated', 'payments_failed', ' payments_completed', 'payments_completed_amount_first_7days', 'reward_purchase_count_first_7days', 'coins_redeemed_first_7days', 'is_referral', 'visits_feature_1', 'visits_feature_2', 'given_permission_1', 'given_permission_2'] df_fintec_LR = df_fintec[cols_basic_model] df_fintec_LR["is_referral"] = df_fintec_LR[ "is_referral"].astype(int) df_fintec_LR.fillna(0, inplace = True) oh_cols = ["is_referral","given_permission_1","given_permission_2"] df_fintec_LR.drop(columns = oh_cols, inplace = True)
Tekan Jalankan untuk melihat hasilnya
- Persiapkan fitur split test dan scale train (catboost juga berfungsi tanpa standarisasi fitur):
df_fintec = df_fintec.rename(columns={'is_churned': 'card_payment'}) X_train, X_test, y_train, y_test = train_test_split(df_fintec_LR, df_fintec[["card_payment"]],random_state = 70, test_size=0.30) scaler = StandardScaler () scaler.fit(X_train) X_train_Scaled = scaler.transform(X_train) X_test_Scaled = scaler.transform(X_test) X, y =X_train_Scaled ,y_train
Pemodelan
- Gunakan model sederhana, karena kami lebih tertarik pada skor kecenderungan:
clf = CatBoostClassifier( iterations=5, learning_rate=0.1, #loss_function='CrossEntropy' ) clf.fit(X_train, y_train, verbose=False) y_pred = clf.predict(X_test, predict_type='Probability') y_pred y_pred_df = pd. DataFrame(y_pred,columns = ["zero","one"]) y_pred_df.head() df_test = pd.concat([X_test.reset_index(drop=True), y_test.reset_index(drop=True)], sumbu=1 ) df_test = pd.concat([df_test.reset_index(drop=True), y_pred_df[["one"]].reset_index(drop=True)], axis=1) df_test['pendapatan'] = np.random.randint (0,50000, size=len(df_test)) display(df_test.head()) sns.histplot(data=df_test, x='one', hue='card_payment') # multiple="dodge" for
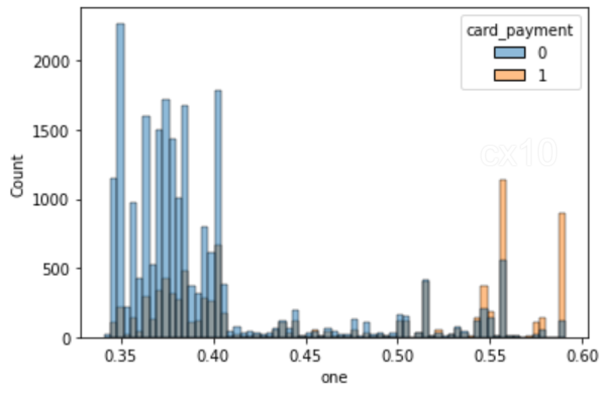
Seperti yang diamati pada histogram, terdapat area tumpang tindih yang jelas, sehingga unit serupa dapat diperoleh dengan menggunakan PSM. Jika tidak ada keseluruhan di antara mereka, tidak mungkin menemukan kecocokan.
Pencocokan menggunakan NearestNeighbors
- Pencocokan menggunakan NearestNeighbors.
dari sklearn.neighbors import NearestNeighbors caliper = np.std(df_test.one) * 0.25 print(f'caliper (radius) is: {caliper:.4f}') n_neighbors = 10 # setup knn knn = NearestNeighbors(n_neighbors=n_neighbors, radius=caliper) ps = df_test[['one']] # tanda kurung ganda sebagai kerangka data knn.fit(ps)
# jarak dan indeks distances, neighbor_indexes = knn.kneighbors(ps) print(neighbor_indexes.shape) # 10 titik terdekat ke titik pertama print(distances[0]) print(neighbor_indexes[0])
# untuk setiap titik dalam perlakuan, kami menemukan titik pencocokan dalam kontrol tanpa penggantian # catat 10 tetangga dapat menyertakan kedua titik dalam perlakuan dan kontrol matched_control = [] # lacak pengamatan yang cocok dalam kontrol untuk indeks_terkini, baris dalam df_test.iterrows (): # ulangi kerangka data jika baris.kartu_pembayaran == 0: # baris saat ini ada di grup kontrol df_test.loc[current_index, 'matched'] = np.nan # set cocok dengan nan else: untuk idx di indeks_tetangga [current_index, :]: # untuk setiap baris dalam perawatan, temukan k tetangga # pastikan baris saat ini bukan idx - jangan cocok dengan dirinya sendiri # dan tetangga berada dalam kontrol if (current_index != idx) dan (df_test.loc[idx].card_payment == 0): jika idx tidak ada di matched_control: # kontrol ini belum dicocokkan df_test.loc[current_index, 'matched'] = idx # catat matched_control.append(idx) yang cocok # tambahkan yang cocok ke daftar istirahat
# coba tambah jumlah tetangga dan/atau kaliper untuk mendapatkan lebih banyak kecocokan print('total observasi dalam pengobatan:', len(df_test[df_test.card_payment==1])) print('total observasi yang cocok dalam kontrol:', len(cocok_kontrol))
total pengamatan dalam pengobatan: 8988
total pengamatan yang cocok dalam kendali: 1296
# kontrol tidak cocok treatment_matched = df_test.dropna(subset=['matched']) # drop tidak cocok # indeks pengamatan kontrol cocok control_matched_idx = treatment_matched.matched control_matched_idx = control_matched_idx.astype(int) # ubah ke int control_matched = df_test.loc [control_matched_idx, :] # pilih observasi kontrol yang cocok # gabungkan perawatan yang cocok dan kontrol df_matched = pd.concat([treatment_matched, control_matched]) df_matched.card_payment.value_counts()
1 1296
0 1296
Nama: card_payment, dtype: int64
sns.histplot(data=df_matched, x='number_of_cards', hue='card_payment') sns.histplot(data=df_matched, x='payments_completed_amount_first_7days', hue='card_payment')
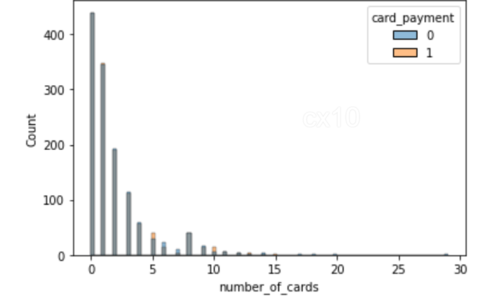
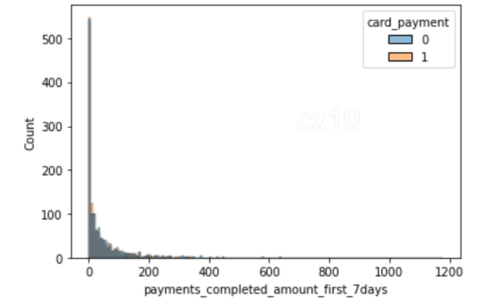
Dari 2 histogram, jelas bahwa pasca pencocokan kecenderungan, distribusi kovariat hampir sama untuk 2 fitur – jumlah kartu dan jumlah pembayaran yang diselesaikan tujuh hari pertama. Hal yang sama dapat diplot untuk fitur lain juga.
Sebelum dan Sesudah
Distribusi kovariat sebelum dan sesudah harus menunjukkan perbedaan SD yang signifikan; baru setelah itu dapat disimpulkan bahwa pencocokan telah efektif.
from numpy import mean from numpy import var from math import sqrt # fungsi untuk menghitung d Cohen untuk sampel independen def cohen_d(d1, d2): # hitung ukuran sampel n1, n2 = len(d1), len(d2) # hitung varian sampel s1, s2 = var(d1, ddof=1), var(d2, ddof=1) # hitung simpangan baku gabungan s = sqrt(((n1 - 1) * s1 + (n2 - 1) * s2) / (n1 + n2 - 2)) # hitung rata-rata sampel u1, u2 = rata-rata(d1), rata-rata(d2) # hitung pengembalian ukuran efek (u1 - u2) / s
effect_sizes = [] cols = list(X_train.columns) # kontrol dan perawatan terpisah untuk uji-t df_control = df_fintec[df_fintec.card_payment==0] df_treatment = df_fintec[df_fintec.card_payment==1] untuk cl dalam kolom: _, p_sebelum = ttest_ind(df_control[cl], df_treatment[cl]) _, p_after = ttest_ind(df_matched_control[cl], df_matched_treatment[cl]) cohen_d_before = cohen_d(df_treatment[cl], df_control[cl]) cohen_d_after = cohen_d(df_matched_treatment[ cl], df_matched_control[cl]) effect_sizes.append([cl,'sebelum', cohen_d_sebelum, p_sebelum]) effect_sizes.append([cl,'setelah', cohen_d_setelah, p_setelah])
df_effect_sizes = pd.DataFrame(ukuran_efek, kolom=['fitur', 'cocok', 'ukuran_efek', 'nilai-p']) fig, ax = plt.subplots(figsize=(15, 5)) sns.barplot( data=df_effect_sizes, x='effect_size', y='feature', hue='matching', orient='h')
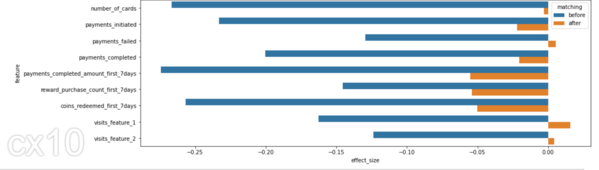
D Cohen, atau perbedaan rata-rata standar, adalah salah satu cara paling umum untuk mengukur ukuran efek. Sebelum pencocokan, perbedaan SD lebih tinggi antara tes dan kontrol (bilah biru). Setelah dilakukan pencocokan perbedaan SD yang lebih rendah, tes dan kontrol memiliki distribusi yang sama sebelum masa perlakuan.
Uji Statistik untuk Mengukur Dampak Pengobatan
Tes-T siswa untuk membandingkan rata-rata dua kelompok. Jika itu adalah retensi atau churn pasca-periode, Uji Chi-Squared dapat digunakan.
# uji-t siswa untuk pendapatan (variabel dependen) setelah pencocokan # nilai p tidak signifikan sekarang dari scipy.stats import ttest_ind print(df_matched_control.revenue.mean(), df_matched_treatment.revenue.mean()) # bandingkan sampel _, p = ttest_ind(df_matched_control.revenue, df_matched_treatment.revenue) print(f'p={p:.3f}') # interpret alpha = 0.05 # tingkat signifikansi if p > alpha: print('same distributions/same group mean (gagal untuk tolak H0 - kami tidak memiliki cukup bukti untuk menolak H0)') else: print('distribusi berbeda/rata-rata grup berbeda (tolak H0)')
25105.91898148148 24040.162037037036
p = 0.062
distribusi yang sama/rata-rata kelompok yang sama (gagal menolak H0 – kita tidak memiliki cukup bukti untuk menolak H0)
Karena P-value > 0.05, kami gagal menolak hipotesis nol, sehingga pelanggan yang membayar dengan kartu memiliki pos pendapatan yang lebih tinggi. Dengan demikian menghemat waktu dan sumber daya yang akan digunakan untuk membangun fitur baru ini.
Cara Lain Mencocokkan Menggunakan Nearest Neighbors
Selain PSM, ada juga metode pencocokan lainnya. Cuplikan kode untuk hal yang sama.
dari sklearn.preprocessing impor StandardScaler dari sklearn.neighbors import NearestNeighbors def get_matching_pairs(treated_df, non_treated_df, scaler=True): treat_x = treated_df.values non_treated_x = non_treated_df.nilai jika scaler == True: scaler = StandardScaler() jika scaler: scaler. fit(treated_x) treat_x = scaler.transform(treated_x) non_treated_x = scaler.transform(non_treated_x) nbrs = NearestNeighbors(n_neighbors=1, algoritma='ball_tree').fit(non_treated_x) jarak, indeks = nbrs.kneighbors(treated_x) indeks = indeks.reshape(indices.shape[0]) cocok = non_treated_df.iloc[indeks] kembali cocok
impor panda sebagai pd impor numpy sebagai np impor matplotlib.pyplot sebagai plt treated_df = pd.DataFrame() np.random.seed(1) size_1 = 200 size_2 = 1000 treated_df['x'] = np.random.normal(0,1, 1,ukuran=ukuran_50,20) diperlakukan_df['y'] = np.random.normal(1,ukuran=ukuran_0,100) diperlakukan_df['z'] = np.random.normal(1,ukuran=ukuran_0,3) tidak_diperlakukan_df = pd. DataFrame() # dua populasi berbeda non_treated_df['x'] = list(np.random.normal(2,size=size_1,2)) + list(np.random.normal(-2,size=2*size_50,30 )) non_treated_df['y'] = daftar(np.random.normal(2,size=size_100,2)) + daftar(np.random.normal(-2,size=2*size_0,200)) non_treated_df[' z'] = daftar(np.random.normal(2,ukuran=ukuran_13,200)) + daftar(np.random.normal(2,ukuran=2*ukuran_6,6)) matched_df = get_matching_pairs(treated_df, non_treated_df) gbr, ax = plt .subplots(figsize=(0.3)) plt.scatter(non_treated_df['x'], non_treated_df['y'], alpha=1,2, label='All non-treated') plt.scatter(treated_df['x '], dirawat_df['y'], label='Dirawat') plt.scatter(matched_df['x'], matched_df['y'], marker='x' , label='cocok') plt.legend() plt.xlim(-XNUMX)
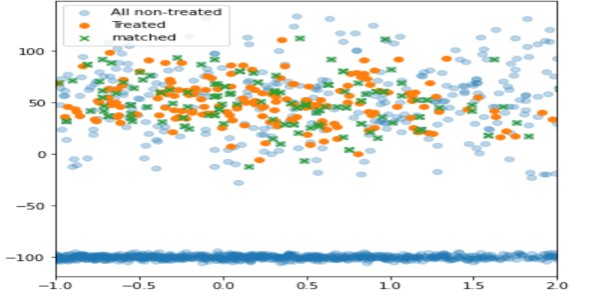
Dengan menggunakan teknik ini, hanya unit yang tidak dirawat yang dekat dengan yang dirawat yang dicocokkan (berwarna hijau), sedangkan unit lainnya tidak disertakan (biru muda).
psmpy – Perpustakaan Pencocokan Skor Kecenderungan Python
PSMPY menyederhanakan PSM, secara efektif menguranginya menjadi hanya 10 baris kode. Pembuatan model, pencocokan, dan penskalaan diurus oleh kerangka kerja. Satu kelemahannya adalah skalanya buruk untuk lebih dari 50 ribu unit.
dari psmpy import PsmPy from psmpy.plotting import * df_fintec.fillna(0, inplace = True) psm = PsmPy(df_fintec, treatment='card_payment', indx='user_id', include = ['is_referral', 'age', ' city', 'device']) # sama seperti kode saya menggunakan balance=False psm.logistic_ps(balance=False) psm.predicted_data psm.knn_matched(matcher='propensity_logit', replacement=False, caliper=None) psm.plot_match( Title='Matching Result', Ylabel='# of obs', Xlabel= 'propensity logit', names = ['treatment', 'control']) display(psm.effect_size) psm.effect_size_plot()
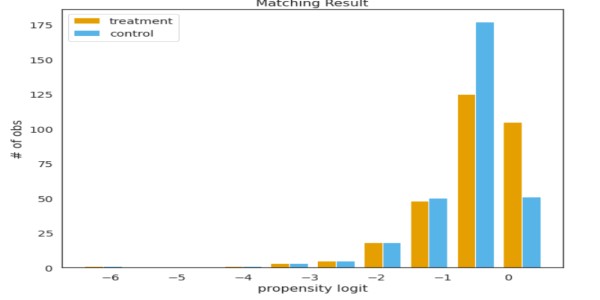
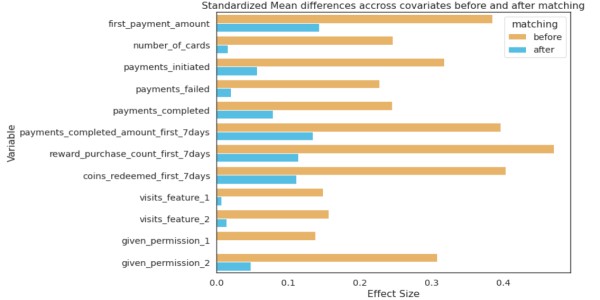
Kekurangan dari
Nilai kovariat mereka tidak akan identik untuk dua individu dengan skor kecenderungan yang identik. PSM secara efektif menyeimbangkan nilai rata-rata kovariat di seluruh kelompok. Pada dasarnya, jika rata-rata jumlah kartu pada pengujian dan kontrol adalah sama, tetapi jika dua pengguna dipilih dengan nilai kecenderungan yang sama, kovariatnya akan berbeda.
Seiring bertambahnya jumlah kovariat, kutukan dimensi memengaruhi pencocokan, mengurangi peluang hingga hampir nol.
Kesimpulan
- Mengontrol bias yang melekat dapat menghasilkan hasil yang baik.
- Pilih kovariat pra-periode yang sesuai berdasarkan masalah yang dihadapi.
- Hipotesis perlu didukung oleh ketajaman bisnis dan data.
Beri tahu saya kasus penggunaan PSM lainnya di bagian komentar di bawah.
Semoga berhasil! Ini milikku Linkedin profil jika Anda ingin terhubung dengan saya atau ingin membantu meningkatkan artikel. Lihat artikel saya yang lain tentang ilmu data dan analitik di sini.
Media yang ditampilkan dalam artikel ini bukan milik Analytics Vidhya dan digunakan atas kebijaksanaan Penulis.
terkait
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://www.analyticsvidhya.com/blog/2022/12/introduction-to-synthetic-control-using-propensity-score-matching/

