Terdapat kemajuan luar biasa dalam bidang pembelajaran mendalam terdistribusi untuk model bahasa besar (LLM), terutama setelah ChatGPT dirilis pada bulan Desember 2022. LLM terus bertambah besar dengan miliaran atau bahkan triliunan parameter, dan seringkali tidak cocok dengan satu perangkat akselerator seperti GPU atau bahkan satu node seperti ml.p5.32xlarge karena keterbatasan memori. Pelanggan yang melatih LLM sering kali harus mendistribusikan beban kerja mereka ke ratusan atau bahkan ribuan GPU. Mengaktifkan pelatihan pada skala tersebut masih menjadi tantangan dalam pelatihan terdistribusi, dan pelatihan secara efisien dalam sistem sebesar itu merupakan masalah lain yang sama pentingnya. Selama beberapa tahun terakhir, komunitas pelatihan terdistribusi telah memperkenalkan paralelisme 3D (paralelisme data, paralelisme pipeline, dan paralelisme tensor) dan teknik lainnya (seperti paralelisme urutan dan paralelisme pakar) untuk mengatasi tantangan tersebut.
Pada bulan Desember 2023, Amazon mengumumkan peluncuran Pustaka paralel model SageMaker 2.0 (SMP), yang mencapai efisiensi mutakhir dalam pelatihan model besar, bersama dengan SageMaker mendistribusikan perpustakaan paralelisme data (SMDDP). Rilis ini merupakan pembaruan signifikan dari 1.x: SMP sekarang terintegrasi dengan PyTorch open source Paralel Data Terpecah Sepenuhnya (FSDP) API, yang memungkinkan Anda menggunakan antarmuka yang familier saat melatih model besar, dan kompatibel dengannya Mesin Transformator (TE), membuka teknik paralelisme tensor bersama FSDP untuk pertama kalinya. Untuk mempelajari lebih lanjut tentang rilis ini, lihat Pustaka paralel model Amazon SageMaker kini mempercepat beban kerja PyTorch FSDP hingga 20%.
Dalam postingan ini, kami mengeksplorasi manfaat kinerja Amazon SageMaker (termasuk SMP dan SMDDP), dan bagaimana Anda dapat menggunakan perpustakaan untuk melatih model besar secara efisien di SageMaker. Kami mendemonstrasikan kinerja SageMaker dengan tolok ukur pada klaster ml.p4d.24xlarge hingga 128 instans, dan presisi campuran FSDP dengan bfloat16 untuk model Llama 2. Kami memulai dengan demonstrasi efisiensi penskalaan mendekati linier untuk SageMaker, diikuti dengan menganalisis kontribusi dari setiap fitur untuk throughput yang optimal, dan diakhiri dengan pelatihan yang efisien dengan berbagai panjang urutan hingga 32,768 melalui paralelisme tensor.
Penskalaan hampir linier dengan SageMaker
Untuk mengurangi waktu pelatihan keseluruhan model LLM, mempertahankan throughput yang tinggi saat melakukan penskalaan ke cluster besar (ribuan GPU) sangatlah penting mengingat overhead komunikasi antar-node. Dalam postingan ini, kami mendemonstrasikan efisiensi penskalaan yang kuat dan mendekati linier (dengan memvariasikan jumlah GPU untuk ukuran masalah total yang tetap) pada instans p4d yang menjalankan SMP dan SMDDP.
Pada bagian ini, kami mendemonstrasikan kinerja penskalaan mendekati linier SMP. Di sini kami melatih model Llama 2 dengan berbagai ukuran (parameter 7B, 13B, dan 70B) menggunakan panjang urutan tetap 4,096, backend SMDDP untuk komunikasi kolektif, TE diaktifkan, ukuran batch global 4 juta, dengan 16 hingga 128 node p4d . Tabel berikut merangkum konfigurasi optimal dan performa pelatihan kami (model TFLOP per detik).
| Ukuran model | Jumlah node | TFLOP* | sdp* | tapi* | membongkar* | Efisiensi penskalaan |
| 7B | 16 | 136.76 | 32 | 1 | N | 100.0% |
| 32 | 132.65 | 64 | 1 | N | 97.0% | |
| 64 | 125.31 | 64 | 1 | N | 91.6% | |
| 128 | 115.01 | 64 | 1 | N | 84.1% | |
| 13B | 16 | 141.43 | 32 | 1 | Y | 100.0% |
| 32 | 139.46 | 256 | 1 | N | 98.6% | |
| 64 | 132.17 | 128 | 1 | N | 93.5% | |
| 128 | 120.75 | 128 | 1 | N | 85.4% | |
| 70B | 32 | 154.33 | 256 | 1 | Y | 100.0% |
| 64 | 149.60 | 256 | 1 | N | 96.9% | |
| 128 | 136.52 | 64 | 2 | N | 88.5% |
*Pada ukuran model, panjang urutan, dan jumlah node tertentu, kami menunjukkan throughput dan konfigurasi optimal secara global setelah menjelajahi berbagai kombinasi sdp, tp, dan activation offloading.
Tabel sebelumnya merangkum angka throughput optimal berdasarkan derajat sharding data paralel (sdp) (biasanya menggunakan sharding hibrid FSDP, bukan sharding penuh, dengan detail lebih lanjut di bagian berikutnya), derajat tensor paralel (tp), dan perubahan nilai pembongkaran aktivasi, mendemonstrasikan penskalaan hampir linier untuk SMP dan SMDDP. Misalnya, dengan model Llama 2 berukuran 7B dan panjang urutan 4,096, secara keseluruhan model tersebut mencapai efisiensi penskalaan sebesar 97.0%, 91.6%, dan 84.1% (relatif terhadap 16 node) pada masing-masing 32, 64, dan 128 node. Efisiensi penskalaan stabil di berbagai ukuran model dan sedikit meningkat seiring bertambahnya ukuran model.
SMP dan SMDDP juga menunjukkan efisiensi penskalaan serupa untuk panjang urutan lainnya seperti 2,048 dan 8,192.
Kinerja perpustakaan paralel model SageMaker 2.0: Llama 2 70B
Ukuran model terus berkembang selama beberapa tahun terakhir, seiring dengan seringnya pembaruan kinerja mutakhir di komunitas LLM. Di bagian ini, kami mengilustrasikan performa SageMaker untuk model Llama 2 menggunakan ukuran model tetap 70B, panjang urutan 4,096, dan ukuran batch global 4 juta. Untuk membandingkan konfigurasi dan throughput optimal global pada tabel sebelumnya (dengan backend SMDDP, biasanya FSDP hybrid sharding dan TE), tabel berikut mencakup throughput optimal lainnya (berpotensi dengan paralelisme tensor) dengan spesifikasi tambahan pada backend terdistribusi (NCCL dan SMDDP) , strategi sharding FSDP (sharding penuh dan sharding hybrid), dan mengaktifkan TE atau tidak (default).
| Ukuran model | Jumlah node | TFLOPS | Konfigurasi TFLOP #3 | Peningkatan TFLOP dibandingkan baseline | ||||||||
| . | . | Pecahan penuh NCCL: #0 | Pecahan penuh SMDDP: #1 | Sharding hibrid SMDDP: #2 | Sharding hibrid SMDDP dengan TE: #3 | sdp* | tapi* | membongkar* | #0 → #1 | #1 → #2 | #2 → #3 | #0 → #3 |
| 70B | 32 | 150.82 | 149.90 | 150.05 | 154.33 | 256 | 1 | Y | -0.6% | 0.1% | 2.9% | 2.3% |
| 64 | 144.38 | 144.38 | 145.42 | 149.60 | 256 | 1 | N | 0.0% | 0.7% | 2.9% | 3.6% | |
| 128 | 68.53 | 103.06 | 130.66 | 136.52 | 64 | 2 | N | 50.4% | 26.8% | 4.5% | 99.2% | |
*Pada ukuran model, panjang urutan, dan jumlah node tertentu, kami menunjukkan throughput dan konfigurasi optimal secara global setelah menjelajahi berbagai kombinasi sdp, tp, dan activation offloading.
Rilis terbaru SMP dan SMDDP mendukung banyak fitur termasuk PyTorch FSDP asli, sharding hybrid yang diperluas dan lebih fleksibel, integrasi mesin transformator, paralelisme tensor, dan operasi kolektif pengumpulan semua yang dioptimalkan. Untuk lebih memahami bagaimana SageMaker mencapai pelatihan terdistribusi yang efisien untuk LLM, kami mengeksplorasi kontribusi tambahan dari SMDDP dan SMP berikut fitur inti:
- Peningkatan SMDDP melalui NCCL dengan FSDP full sharding
- Mengganti sharding penuh FSDP dengan sharding hibrid, yang mengurangi biaya komunikasi untuk meningkatkan throughput
- Peningkatan lebih lanjut pada throughput dengan TE, bahkan ketika paralelisme tensor dinonaktifkan
- Pada pengaturan sumber daya yang lebih rendah, pembongkaran aktivasi mungkin dapat mengaktifkan pelatihan yang tidak dapat dilakukan atau sangat lambat karena tekanan memori yang tinggi
Sharding penuh FSDP: Peningkatan SMDDP melalui NCCL
Seperti yang ditunjukkan pada tabel sebelumnya, ketika model di-sharding sepenuhnya dengan FSDP, meskipun throughput NCCL (TFLOPs #0) dan SMDDP (TFLOPs #1) sebanding pada 32 atau 64 node, terdapat peningkatan besar sebesar 50.4% dari NCCL ke SMDDP pada 128 node.
Pada ukuran model yang lebih kecil, kami mengamati peningkatan yang konsisten dan signifikan dengan SMDDP dibandingkan NCCL, dimulai dari ukuran cluster yang lebih kecil, karena SMDDP mampu memitigasi hambatan komunikasi secara efektif.
Sharding hibrid FSDP untuk mengurangi biaya komunikasi
Di SMP 1.0, kami meluncurkan paralelisme data sharded, teknik pelatihan terdistribusi yang didukung oleh Amazon sendiri MiCS teknologi. Di SMP 2.0, kami memperkenalkan SMP hybrid sharding, teknik sharding hybrid yang dapat diperluas dan lebih fleksibel yang memungkinkan model di-sharding di antara subset GPU, bukan di semua GPU pelatihan, seperti halnya sharding penuh FSDP. Ini berguna untuk model berukuran sedang yang tidak perlu di-sharding ke seluruh cluster untuk memenuhi batasan memori per GPU. Hal ini menyebabkan klaster memiliki lebih dari satu replika model dan setiap GPU berkomunikasi dengan lebih sedikit rekan pada waktu proses.
Sharding hibrid SMP memungkinkan sharding model yang efisien pada rentang yang lebih luas, mulai dari tingkat shard terkecil tanpa masalah kehabisan memori hingga ukuran keseluruhan cluster (yang setara dengan sharding penuh).
Gambar berikut mengilustrasikan ketergantungan throughput pada sdp pada tp = 1 untuk kesederhanaan. Meski belum tentu sama dengan nilai tp optimal untuk NCCL atau SMDDP full sharding pada tabel sebelumnya, namun angkanya cukup mendekati. Ini dengan jelas memvalidasi nilai peralihan dari sharding penuh ke sharding hibrid pada ukuran cluster besar sebanyak 128 node, yang berlaku untuk NCCL dan SMDDP. Untuk ukuran model yang lebih kecil, peningkatan signifikan dengan hybrid sharding dimulai dari ukuran cluster yang lebih kecil, dan perbedaannya terus meningkat seiring dengan ukuran cluster.
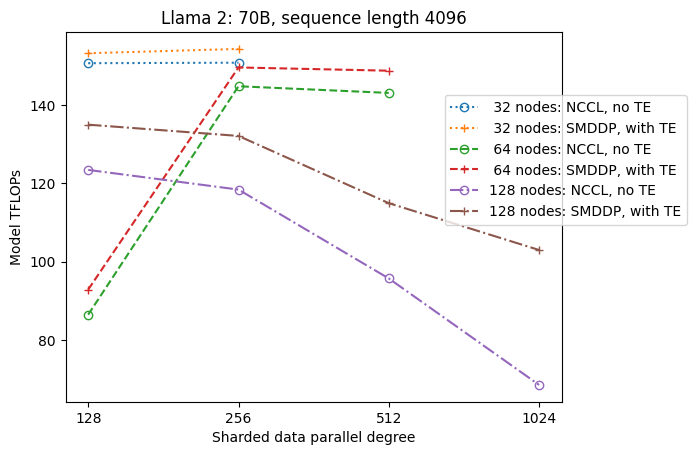
Perbaikan dengan TE
TE dirancang untuk mempercepat pelatihan LLM pada GPU NVIDIA. Meskipun tidak menggunakan FP8 karena tidak didukung pada instance p4d, kami masih melihat peningkatan yang signifikan dengan TE pada p4d.
Selain MiCS yang dilatih dengan backend SMDDP, TE memperkenalkan peningkatan throughput yang konsisten di semua ukuran cluster (satu-satunya pengecualian adalah sharding penuh pada 128 node), bahkan ketika paralelisme tensor dinonaktifkan (derajat paralel tensor adalah 1).
Untuk ukuran model yang lebih kecil atau panjang urutan yang bervariasi, peningkatan TE stabil dan tidak sepele, dalam kisaran sekitar 3–7.6%.
Pembongkaran aktivasi pada pengaturan sumber daya rendah
Pada pengaturan sumber daya yang rendah (mengingat jumlah node yang sedikit), FSDP mungkin mengalami tekanan memori yang tinggi (atau bahkan kehabisan memori dalam kasus terburuk) ketika pos pemeriksaan aktivasi diaktifkan. Untuk skenario yang terhambat oleh memori, mengaktifkan pembongkaran aktivasi berpotensi menjadi pilihan untuk meningkatkan kinerja.
Misalnya, seperti yang kita lihat sebelumnya, meskipun Llama 2 pada ukuran model 13B dan panjang urutan 4,096 mampu berlatih secara optimal dengan setidaknya 32 node dengan titik pemeriksaan aktivasi dan tanpa pembongkaran aktivasi, ia mencapai throughput terbaik dengan pembongkaran aktivasi ketika dibatasi hingga 16 node.
Aktifkan pelatihan dengan urutan panjang: paralelisme tensor SMP
Urutan yang lebih panjang diinginkan untuk percakapan dan konteks yang panjang, dan mendapatkan lebih banyak perhatian di komunitas LLM. Oleh karena itu, kami melaporkan berbagai throughput urutan panjang dalam tabel berikut. Tabel ini menunjukkan throughput optimal untuk pelatihan Llama 2 di SageMaker, dengan berbagai panjang urutan dari 2,048 hingga 32,768. Pada panjang urutan 32,768, pelatihan FSDP asli tidak dapat dilakukan dengan 32 node pada ukuran batch global sebesar 4 juta.
| . | . | . | TFLOPS | ||
| Ukuran model | Panjang urutan | Jumlah node | FSDP dan NCCL asli | SMP dan SMDDP | peningkatan SMP |
| 7B | 2048 | 32 | 129.25 | 138.17 | 6.9% |
| 4096 | 32 | 124.38 | 132.65 | 6.6% | |
| 8192 | 32 | 115.25 | 123.11 | 6.8% | |
| 16384 | 32 | 100.73 | 109.11 | 8.3% | |
| 32768 | 32 | NA | 82.87 | . | |
| 13B | 2048 | 32 | 137.75 | 144.28 | 4.7% |
| 4096 | 32 | 133.30 | 139.46 | 4.6% | |
| 8192 | 32 | 125.04 | 130.08 | 4.0% | |
| 16384 | 32 | 111.58 | 117.01 | 4.9% | |
| 32768 | 32 | NA | 92.38 | . | |
| *: maks | . | . | . | . | 8.3% |
| *: median | . | . | . | . | 5.8% |
Jika ukuran klasternya besar dan memiliki ukuran batch global yang tetap, beberapa pelatihan model mungkin tidak dapat dilakukan dengan FSDP PyTorch asli, karena tidak memiliki dukungan pipeline atau paralelisme tensor bawaan. Pada tabel sebelumnya, dengan ukuran batch global sebesar 4 juta, 32 node, dan panjang urutan 32,768, ukuran batch efektif per GPU adalah 0.5 (misalnya, tp = 2 dengan ukuran batch 1), yang jika tidak maka tidak akan mungkin dilakukan tanpa memperkenalkan paralelisme tensor.
Kesimpulan
Dalam postingan ini, kami mendemonstrasikan pelatihan LLM yang efisien dengan SMP dan SMDDP pada instance p4d, menghubungkan kontribusi ke beberapa fitur utama, seperti peningkatan SMDDP melalui NCCL, sharding hybrid FSDP yang fleksibel daripada sharding penuh, integrasi TE, dan mengaktifkan paralelisme tensor yang mendukung panjang urutan yang panjang. Setelah diuji pada berbagai pengaturan dengan berbagai model, ukuran model, dan panjang urutan, ini menunjukkan efisiensi penskalaan mendekati linier yang kuat, hingga 128 instans p4d di SageMaker. Singkatnya, SageMaker terus menjadi alat yang ampuh bagi para peneliti dan praktisi LLM.
Untuk mempelajari lebih lanjut, lihat Pustaka paralelisme model SageMaker v2, atau hubungi tim SMP di sm-model-parallel-feedback@amazon.com.
Ucapan Terima Kasih
Kami ingin mengucapkan terima kasih kepada Robert Van Dusen, Ben Snyder, Gautam Kumar, dan Luis Quintela atas masukan dan diskusi konstruktif mereka.
Tentang Penulis

Xinle Sheila Liu adalah SDE di Amazon SageMaker. Di waktu luangnya, ia menikmati membaca dan berolahraga di luar ruangan.
 Suhit Kodgule adalah Insinyur Pengembangan Perangkat Lunak di grup AWS Artificial Intelligence yang mengerjakan kerangka kerja pembelajaran mendalam. Di waktu luangnya, dia menikmati hiking, jalan-jalan, dan memasak.
Suhit Kodgule adalah Insinyur Pengembangan Perangkat Lunak di grup AWS Artificial Intelligence yang mengerjakan kerangka kerja pembelajaran mendalam. Di waktu luangnya, dia menikmati hiking, jalan-jalan, dan memasak.
 Victor Zhu adalah Insinyur Perangkat Lunak dalam Pembelajaran Mendalam Terdistribusi di Amazon Web Services. Dia terlihat menikmati hiking dan permainan papan di sekitar SF Bay Area.
Victor Zhu adalah Insinyur Perangkat Lunak dalam Pembelajaran Mendalam Terdistribusi di Amazon Web Services. Dia terlihat menikmati hiking dan permainan papan di sekitar SF Bay Area.
 Derya Kavdar bekerja sebagai insinyur perangkat lunak di AWS. Minatnya mencakup pembelajaran mendalam dan optimalisasi pelatihan terdistribusi.
Derya Kavdar bekerja sebagai insinyur perangkat lunak di AWS. Minatnya mencakup pembelajaran mendalam dan optimalisasi pelatihan terdistribusi.
 Teng Xu adalah Insinyur Pengembangan Perangkat Lunak di grup Pelatihan Terdistribusi di AWS AI. Dia senang membaca.
Teng Xu adalah Insinyur Pengembangan Perangkat Lunak di grup Pelatihan Terdistribusi di AWS AI. Dia senang membaca.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/distributed-training-and-efficient-scaling-with-the-amazon-sagemaker-model-parallel-and-data-parallel-libraries/

