Model dasar (FM) adalah model pembelajaran mesin (ML) besar yang dilatih pada spektrum luas kumpulan data yang tidak berlabel dan digeneralisasi. FM, seperti namanya, memberikan landasan untuk membangun aplikasi hilir yang lebih terspesialisasi, dan memiliki kemampuan beradaptasi yang unik. Mereka dapat melakukan berbagai tugas berbeda, seperti pemrosesan bahasa alami, mengklasifikasikan gambar, memperkirakan tren, menganalisis sentimen, dan menjawab pertanyaan. Skala dan kemampuan beradaptasi untuk tujuan umum inilah yang membuat FM berbeda dari model ML tradisional. FM bersifat multimoda; mereka bekerja dengan tipe data yang berbeda seperti teks, video, audio, dan gambar. Model bahasa besar (LLM) adalah jenis FM dan telah dilatih sebelumnya tentang data teks dalam jumlah besar dan biasanya memiliki kegunaan aplikasi seperti pembuatan teks, chatbot cerdas, atau ringkasan.
Data streaming memfasilitasi aliran informasi yang beragam dan terkini secara konstan, sehingga meningkatkan kemampuan model untuk beradaptasi dan menghasilkan keluaran yang lebih akurat dan relevan secara kontekstual. Integrasi dinamis data streaming ini memungkinkan AI generatif aplikasi untuk merespons dengan cepat terhadap perubahan kondisi, meningkatkan kemampuan beradaptasi dan kinerja keseluruhan dalam berbagai tugas.
Untuk lebih memahami hal ini, bayangkan sebuah chatbot yang membantu wisatawan memesan perjalanan mereka. Dalam skenario ini, chatbot memerlukan akses real-time ke inventaris maskapai penerbangan, status penerbangan, inventaris hotel, perubahan harga terkini, dan banyak lagi. Data ini biasanya berasal dari pihak ketiga, dan pengembang perlu menemukan cara untuk menyerap data ini dan memproses perubahan data yang terjadi.
Pemrosesan batch bukanlah pilihan terbaik dalam skenario ini. Ketika data berubah dengan cepat, memprosesnya dalam batch dapat mengakibatkan data basi digunakan oleh chatbot, sehingga memberikan informasi yang tidak akurat kepada pelanggan, sehingga berdampak pada pengalaman pelanggan secara keseluruhan. Namun, pemrosesan aliran dapat memungkinkan chatbot mengakses data secara real-time dan beradaptasi terhadap perubahan ketersediaan dan harga, memberikan panduan terbaik kepada pelanggan dan meningkatkan pengalaman pelanggan.
Contoh lainnya adalah solusi observabilitas dan pemantauan berbasis AI di mana FM memantau metrik internal suatu sistem secara real-time dan menghasilkan peringatan. Ketika model menemukan nilai metrik yang anomali atau tidak normal, model harus segera mengeluarkan peringatan dan memberi tahu operator. Namun, nilai data penting tersebut berkurang secara signifikan seiring berjalannya waktu. Idealnya, pemberitahuan ini diterima dalam hitungan detik atau bahkan saat sedang terjadi. Jika operator menerima pemberitahuan ini beberapa menit atau jam setelah pemberitahuan tersebut terjadi, informasi tersebut tidak dapat ditindaklanjuti dan berpotensi kehilangan nilainya. Anda dapat menemukan kasus penggunaan serupa di industri lain seperti ritel, manufaktur mobil, energi, dan industri keuangan.
Dalam postingan kali ini, kami membahas mengapa streaming data merupakan komponen penting dari aplikasi AI generatif karena sifatnya yang real-time. Kami membahas nilai layanan streaming data AWS seperti Amazon Managed Streaming untuk Apache Kafka (AmazonMSK), Aliran Data Amazon Kinesis, Layanan Terkelola Amazon untuk Apache Flink, dan Firehose Data Amazon Kinesis dalam membangun aplikasi AI generatif.
Pembelajaran dalam konteks
LLM dilatih dengan data point-in-time dan tidak memiliki kemampuan bawaan untuk mengakses data baru pada waktu inferensi. Saat data baru muncul, Anda harus terus menyempurnakan atau melatih model lebih lanjut. Hal ini bukan saja merupakan operasi yang mahal, namun juga sangat terbatas dalam praktiknya karena kecepatan pembuatan data baru jauh melebihi kecepatan penyesuaian. Selain itu, LLM kurang memiliki pemahaman kontekstual dan hanya mengandalkan data pelatihan mereka, sehingga rentan terhadap halusinasi. Ini berarti mereka dapat menghasilkan respons yang lancar, koheren, dan masuk akal secara sintaksis, tetapi responsnya salah secara faktual. Mereka juga tidak memiliki relevansi, personalisasi, dan konteks.
Namun, LLM memiliki kapasitas untuk belajar dari data yang mereka terima dari konteks agar dapat memberikan respons yang lebih akurat tanpa mengubah bobot model. Ini disebut pembelajaran dalam konteks, dan dapat digunakan untuk menghasilkan jawaban yang dipersonalisasi atau memberikan respons yang akurat dalam konteks kebijakan organisasi.
Misalnya, dalam chatbot, peristiwa data dapat berkaitan dengan inventaris penerbangan dan hotel atau perubahan harga yang terus-menerus dimasukkan ke mesin penyimpanan streaming. Selain itu, peristiwa data disaring, diperkaya, dan diubah ke format yang dapat dikonsumsi menggunakan pemroses aliran. Hasilnya tersedia untuk aplikasi dengan menanyakan snapshot terbaru. Snapshot terus diperbarui melalui pemrosesan aliran; oleh karena itu, data terkini disediakan dalam konteks permintaan pengguna ke model. Hal ini memungkinkan model untuk beradaptasi dengan perubahan harga dan ketersediaan terkini. Diagram berikut mengilustrasikan alur kerja pembelajaran dasar dalam konteks.
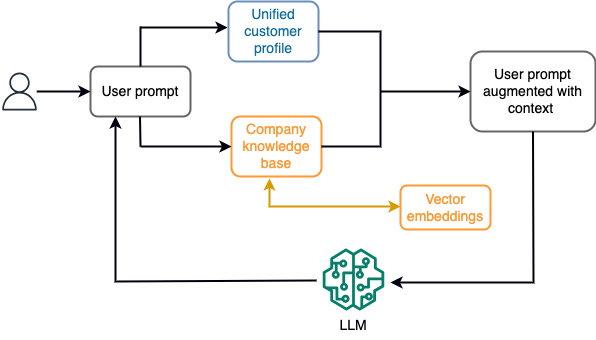
Pendekatan pembelajaran dalam konteks yang umum digunakan adalah dengan menggunakan teknik yang disebut Retrieval Augmented Generation (RAG). Di RAG, Anda memberikan informasi yang relevan seperti kebijakan paling relevan dan catatan pelanggan beserta pertanyaan pengguna ke prompt. Dengan cara ini, LLM menghasilkan jawaban atas pertanyaan pengguna menggunakan informasi tambahan yang disediakan sebagai konteks. Untuk mempelajari lebih lanjut tentang RAG, lihat Penjawaban pertanyaan menggunakan Retrieval Augmented Generation dengan model dasar di Amazon SageMaker JumpStart.
Aplikasi AI generatif berbasis RAG hanya dapat menghasilkan respons umum berdasarkan data pelatihan dan dokumen relevan di basis pengetahuan. Solusi ini gagal ketika aplikasi diharapkan memberikan respons yang dipersonalisasi hampir secara real-time. Misalnya, chatbot perjalanan diharapkan mempertimbangkan pemesanan pengguna saat ini, inventaris hotel dan penerbangan yang tersedia, dan banyak lagi. Selain itu, data pribadi pelanggan yang relevan (umumnya dikenal sebagai profil pelanggan terpadu) biasanya dapat berubah. Jika proses batch digunakan untuk memperbarui database profil pengguna AI generatif, pelanggan mungkin menerima tanggapan yang tidak memuaskan berdasarkan data lama.
Dalam postingan ini, kami membahas penerapan pemrosesan aliran untuk meningkatkan solusi RAG yang digunakan untuk membangun agen penjawab pertanyaan dengan konteks dari akses real-time hingga profil pelanggan terpadu dan basis pengetahuan organisasi.
Pembaruan profil pelanggan hampir secara real-time
Catatan pelanggan biasanya didistribusikan ke seluruh penyimpanan data dalam suatu organisasi. Agar aplikasi AI generatif Anda dapat memberikan profil pelanggan yang relevan, akurat, dan terkini, penting untuk membangun saluran data streaming yang dapat melakukan resolusi identitas dan agregasi profil di seluruh penyimpanan data yang terdistribusi. Pekerjaan streaming terus-menerus menyerap data baru untuk disinkronkan di seluruh sistem dan dapat melakukan pengayaan, transformasi, penggabungan, dan agregasi di seluruh rentang waktu dengan lebih efisien. Peristiwa pengambilan data perubahan (CDC) berisi informasi tentang rekaman sumber, pembaruan, dan metadata seperti waktu, sumber, klasifikasi (masukkan, perbarui, atau hapus), dan pemrakarsa perubahan.
Diagram berikut mengilustrasikan contoh alur kerja untuk penyerapan dan pemrosesan streaming CDC untuk profil pelanggan terpadu.

Pada bagian ini, kami membahas komponen utama pola streaming CDC yang diperlukan untuk mendukung aplikasi AI generatif berbasis RAG.
penyerapan streaming CDC
Replikator CDC adalah proses yang mengumpulkan perubahan data dari sistem sumber (biasanya dengan membaca log transaksi atau binlog) dan menulis peristiwa CDC dengan urutan yang sama persis dengan yang terjadi di aliran data atau topik streaming. Ini melibatkan penangkapan berbasis log dengan alat seperti Layanan Migrasi Database AWS (AWS DMS) atau konektor sumber terbuka seperti Debezium untuk koneksi Apache Kafka. Apache Kafka Connect adalah bagian dari lingkungan Apache Kafka, yang memungkinkan data diserap dari berbagai sumber dan dikirimkan ke berbagai tujuan. Anda dapat menjalankan konektor Apache Kafka Anda Amazon MSK Terhubung dalam hitungan menit tanpa mengkhawatirkan konfigurasi, penyiapan, dan pengoperasian cluster Apache Kafka. Anda hanya perlu mengunggah kode kompilasi konektor Anda ke Layanan Penyimpanan Sederhana Amazon (Amazon S3) dan atur konektor Anda dengan konfigurasi spesifik beban kerja Anda.
Ada juga metode lain untuk menangkap perubahan data. Misalnya, Amazon DynamoDB menyediakan fitur untuk streaming data CDC Aliran Amazon DynamoDB atau Aliran Data Kinesis. Amazon S3 menyediakan pemicu untuk memanggil AWS Lambda berfungsi ketika dokumen baru disimpan.
Penyimpanan streaming
Penyimpanan streaming berfungsi sebagai buffer perantara untuk menyimpan peristiwa CDC sebelum diproses. Penyimpanan streaming menyediakan penyimpanan yang andal untuk data streaming. Secara desain, ini sangat tersedia dan tahan terhadap kegagalan perangkat keras atau node dan menjaga urutan kejadian seperti yang tertulis. Penyimpanan streaming dapat menyimpan peristiwa data baik secara permanen atau untuk jangka waktu tertentu. Hal ini memungkinkan pemroses aliran membaca dari bagian aliran jika terjadi kegagalan atau perlunya pemrosesan ulang. Kinesis Data Streams adalah layanan data streaming tanpa server yang memudahkan pengambilan, pemrosesan, dan penyimpanan aliran data dalam skala besar. Amazon MSK adalah layanan yang terkelola sepenuhnya, sangat tersedia, dan aman yang disediakan oleh AWS untuk menjalankan Apache Kafka.
Pemrosesan arus
Sistem pemrosesan aliran harus dirancang paralelisme untuk menangani throughput data yang tinggi. Mereka harus mempartisi aliran input antara beberapa tugas yang berjalan pada beberapa node komputasi. Tugas harus dapat mengirimkan hasil dari satu operasi ke operasi berikutnya melalui jaringan, sehingga memungkinkan pemrosesan data secara paralel saat melakukan operasi seperti penggabungan, pemfilteran, pengayaan, dan agregasi. Aplikasi pemrosesan aliran harus dapat memproses peristiwa sehubungan dengan waktu peristiwa untuk kasus penggunaan di mana peristiwa dapat datang terlambat atau perhitungan yang benar bergantung pada waktu terjadinya peristiwa, bukan waktu sistem. Untuk informasi lebih lanjut, lihat Pengertian Waktu: Waktu Peristiwa dan Waktu Pemrosesan.
Proses aliran terus menerus menghasilkan hasil dalam bentuk peristiwa data yang perlu dikeluarkan ke sistem target. Sistem target dapat berupa sistem apa pun yang dapat berintegrasi langsung dengan proses atau melalui penyimpanan streaming sebagai perantara. Bergantung pada kerangka kerja yang Anda pilih untuk pemrosesan aliran, Anda akan memiliki opsi berbeda untuk sistem target bergantung pada konektor sink yang tersedia. Jika Anda memutuskan untuk menulis hasilnya ke penyimpanan streaming perantara, Anda dapat membangun proses terpisah yang membaca peristiwa dan menerapkan perubahan pada sistem target, seperti menjalankan konektor sink Apache Kafka. Apa pun opsi yang Anda pilih, data CDC memerlukan penanganan ekstra karena sifatnya. Karena peristiwa CDC membawa informasi tentang pembaruan atau penghapusan, peristiwa tersebut harus digabungkan dalam sistem target dengan urutan yang benar. Jika perubahan diterapkan dalam urutan yang salah, sistem target akan tidak sinkron dengan sumbernya.
Flash Apache adalah kerangka pemrosesan aliran kuat yang dikenal dengan latensi rendah dan kemampuan throughput tinggi. Ini mendukung pemrosesan waktu peristiwa, semantik pemrosesan tepat satu kali, dan toleransi kesalahan yang tinggi. Selain itu, ia memberikan dukungan asli untuk data CDC melalui struktur khusus yang disebut tabel dinamis. Tabel dinamis meniru tabel database sumber dan memberikan representasi kolom dari data streaming. Data dalam tabel dinamis berubah seiring dengan setiap peristiwa yang diproses. Catatan baru dapat ditambahkan, diperbarui, atau dihapus kapan saja. Tabel dinamis mengabstraksikan logika tambahan yang perlu Anda terapkan untuk setiap operasi rekaman (memasukkan, memperbarui, menghapus) secara terpisah. Untuk informasi lebih lanjut, lihat Tabel Dinamis.
Dengan Layanan Terkelola Amazon untuk Apache Flink, Anda dapat menjalankan pekerjaan Apache Flink dan berintegrasi dengan layanan AWS lainnya. Tidak ada server dan cluster yang harus dikelola, dan tidak ada infrastruktur komputasi dan penyimpanan yang harus disiapkan.
Lem AWS adalah layanan ekstrak, transformasi, dan muat (ETL) yang terkelola sepenuhnya, yang berarti AWS menangani penyediaan, penskalaan, dan pemeliharaan infrastruktur untuk Anda. Meskipun dikenal karena kemampuan ETL-nya, AWS Glue juga dapat digunakan untuk aplikasi streaming Spark. AWS Glue dapat berinteraksi dengan layanan data streaming seperti Kinesis Data Streams dan Amazon MSK untuk memproses dan mentransformasikan data CDC. AWS Glue juga dapat berintegrasi secara lancar dengan layanan AWS lainnya seperti Lambda, Fungsi Langkah AWS, dan DynamoDB, memberi Anda ekosistem komprehensif untuk membangun dan mengelola jalur pemrosesan data.
Profil pelanggan terpadu
Mengatasi penyatuan profil pelanggan di berbagai sistem sumber memerlukan pengembangan jalur data yang kuat. Anda memerlukan saluran data yang dapat membawa dan menyinkronkan semua catatan ke dalam satu penyimpanan data. Penyimpanan data ini memberi organisasi Anda tampilan catatan pelanggan holistik yang diperlukan untuk efisiensi operasional aplikasi AI generatif berbasis RAG. Untuk membangun penyimpanan data seperti itu, penyimpanan data yang tidak terstruktur adalah pilihan terbaik.
Grafik identitas adalah struktur yang berguna untuk membuat profil pelanggan terpadu karena mengkonsolidasikan dan mengintegrasikan data pelanggan dari berbagai sumber, memastikan keakuratan dan deduplikasi data, menawarkan pembaruan waktu nyata, menghubungkan wawasan lintas sistem, memungkinkan personalisasi, meningkatkan pengalaman pelanggan, dan mendukung kepatuhan terhadap peraturan. Profil pelanggan terpadu ini memberdayakan aplikasi AI generatif untuk memahami dan berinteraksi dengan pelanggan secara efektif, dan mematuhi peraturan privasi data, yang pada akhirnya meningkatkan pengalaman pelanggan dan mendorong pertumbuhan bisnis. Anda dapat membuat solusi grafik identitas menggunakan Amazon Neptunus, layanan database grafik yang cepat, andal, dan terkelola sepenuhnya.
AWS menyediakan beberapa penawaran layanan penyimpanan NoSQL terkelola dan tanpa server lainnya untuk objek nilai kunci yang tidak terstruktur. Dokumen Amazon DB (dengan kompatibilitas MongoDB) adalah perusahaan yang cepat, terukur, memiliki ketersediaan tinggi, dan terkelola sepenuhnya basis data dokumen layanan yang mendukung beban kerja JSON asli. DynamoDB adalah layanan database NoSQL yang dikelola sepenuhnya yang memberikan kinerja cepat dan dapat diprediksi dengan skalabilitas yang lancar.
Pembaruan basis pengetahuan organisasi hampir secara real-time
Mirip dengan catatan pelanggan, repositori pengetahuan internal seperti kebijakan perusahaan dan dokumen organisasi disimpan di seluruh sistem penyimpanan. Ini biasanya merupakan data tidak terstruktur dan diperbarui secara non-inkremental. Penggunaan data tidak terstruktur untuk aplikasi AI efektif menggunakan vector embeddings, yaitu teknik merepresentasikan data berdimensi tinggi seperti file teks, gambar, dan file audio sebagai numerik multidimensi.
AWS menyediakan beberapa layanan mesin vektor, Seperti Amazon OpenSearch Tanpa Server, AmazonKendra, dan Amazon Aurora Edisi yang Kompatibel dengan PostgreSQL dengan ekstensi pgvector untuk menyimpan embeddings vektor. Aplikasi AI generatif dapat meningkatkan pengalaman pengguna dengan mengubah perintah pengguna menjadi vektor dan menggunakannya untuk menanyakan mesin vektor guna mengambil informasi yang relevan secara kontekstual. Baik prompt maupun data vektor yang diambil kemudian diteruskan ke LLM untuk menerima respons yang lebih tepat dan personal.
Diagram berikut mengilustrasikan contoh alur kerja pemrosesan aliran untuk penyematan vektor.
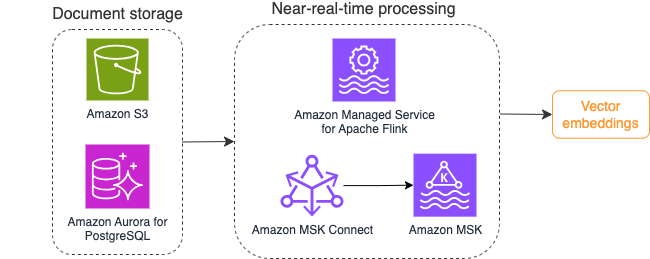
Konten basis pengetahuan perlu dikonversi ke penyematan vektor sebelum ditulis ke penyimpanan data vektor. Batuan Dasar Amazon or Amazon SageMaker dapat membantu Anda mengakses model pilihan Anda dan mengekspos titik akhir privat untuk konversi ini. Selain itu, Anda dapat menggunakan perpustakaan seperti LangChain untuk berintegrasi dengan titik akhir ini. Membangun proses batch dapat membantu Anda mengonversi konten basis pengetahuan Anda menjadi data vektor dan menyimpannya dalam database vektor pada awalnya. Namun, Anda perlu mengandalkan interval untuk memproses ulang dokumen guna menyinkronkan database vektor Anda dengan perubahan pada konten basis pengetahuan Anda. Dengan jumlah dokumen yang banyak, proses ini menjadi tidak efisien. Di antara interval tersebut, pengguna aplikasi AI generatif Anda akan menerima jawaban sesuai dengan konten lama, atau akan menerima jawaban yang tidak akurat karena konten baru belum di-vektorisasi.
Pemrosesan aliran adalah solusi ideal untuk tantangan ini. Ini menghasilkan peristiwa sesuai dokumen yang ada pada awalnya dan selanjutnya memantau sistem sumber dan membuat peristiwa perubahan dokumen segera setelah terjadi. Peristiwa ini dapat disimpan dalam penyimpanan streaming dan menunggu untuk diproses oleh tugas streaming. Pekerjaan streaming membaca peristiwa ini, memuat konten dokumen, dan mengubah konten menjadi serangkaian token kata terkait. Setiap token selanjutnya diubah menjadi data vektor melalui panggilan API ke FM yang disematkan. Hasilnya dikirim untuk disimpan ke penyimpanan vektor melalui operator sink.
Jika Anda menggunakan Amazon S3 untuk menyimpan dokumen, Anda dapat membangun arsitektur sumber peristiwa berdasarkan pemicu perubahan objek S3 untuk Lambda. Fungsi Lambda dapat membuat acara dalam format yang diinginkan dan menuliskannya ke penyimpanan streaming Anda.
Anda juga dapat menggunakan Apache Flink untuk dijalankan sebagai pekerjaan streaming. Apache Flink menyediakan konektor sumber FileSystem asli, yang dapat menemukan file yang ada dan membaca kontennya pada awalnya. Setelah itu, ia dapat terus memantau sistem file Anda untuk mencari file baru dan menangkap kontennya. Konektor mendukung pembacaan sekumpulan file dari sistem file terdistribusi seperti Amazon S3 atau HDFS dengan format teks biasa, Avro, CSV, Parket, dan lainnya, serta menghasilkan rekaman streaming. Sebagai layanan yang terkelola sepenuhnya, Layanan Terkelola untuk Apache Flink menghilangkan overhead operasional dalam penerapan dan pemeliharaan pekerjaan Flink, sehingga Anda dapat fokus dalam membangun dan menskalakan aplikasi streaming Anda. Dengan integrasi yang lancar ke dalam layanan streaming AWS seperti Amazon MSK atau Kinesis Data Streams, layanan ini menyediakan fitur seperti penskalaan otomatis, keamanan, dan ketahanan, menyediakan aplikasi Flink yang andal dan efisien untuk menangani data streaming waktu nyata.
Berdasarkan preferensi DevOps, Anda dapat memilih antara Kinesis Data Streams atau Amazon MSK untuk menyimpan catatan streaming. Kinesis Data Streams menyederhanakan kompleksitas pembuatan dan pengelolaan aplikasi data streaming khusus, memungkinkan Anda fokus untuk memperoleh wawasan dari data Anda, bukan pemeliharaan infrastruktur. Pelanggan yang menggunakan Apache Kafka sering kali memilih Amazon MSK karena keterusterangan, skalabilitas, dan keandalannya dalam mengawasi klaster Apache Kafka dalam lingkungan AWS. Sebagai layanan yang terkelola sepenuhnya, Amazon MSK mengatasi kompleksitas operasional yang terkait dengan penerapan dan pemeliharaan klaster Apache Kafka, memungkinkan Anda berkonsentrasi dalam membangun dan memperluas aplikasi streaming Anda.
Karena integrasi RESTful API sesuai dengan sifat proses ini, Anda memerlukan kerangka kerja yang mendukung pola pengayaan stateful melalui panggilan RESTful API untuk melacak kegagalan dan mencoba lagi permintaan yang gagal. Apache Flink sekali lagi adalah kerangka kerja yang dapat melakukan operasi stateful dengan kecepatan memori. Untuk memahami cara terbaik melakukan panggilan API melalui Apache Flink, lihat Pola pengayaan data streaming yang umum di Amazon Kinesis Data Analytics untuk Apache Flink.
Apache Flink menyediakan konektor sink asli untuk menulis data ke penyimpanan data vektor seperti Amazon Aurora untuk PostgreSQL dengan pgvector atau Layanan Pencarian Terbuka Amazon dengan VectorDB. Alternatifnya, Anda dapat mengatur output pekerjaan Flink (data yang divektorkan) dalam topik MSK atau aliran data Kinesis. Layanan OpenSearch menyediakan dukungan untuk penyerapan asli dari aliran data Kinesis atau topik MSK. Untuk informasi lebih lanjut, lihat Memperkenalkan Amazon MSK sebagai sumber untuk Amazon OpenSearch Ingestion dan Memuat data streaming dari Amazon Kinesis Data Streams.
Analisis umpan balik dan penyesuaian
Penting bagi manajer operasi data dan pengembang AI/ML untuk mendapatkan wawasan tentang kinerja aplikasi AI generatif dan FM yang digunakan. Untuk mencapai hal tersebut, Anda perlu membangun saluran data yang menghitung data indikator kinerja utama (KPI) penting berdasarkan umpan balik pengguna serta berbagai log dan metrik aplikasi. Informasi ini berguna bagi pemangku kepentingan untuk mendapatkan wawasan real-time tentang kinerja FM, aplikasi, dan kepuasan pengguna secara keseluruhan mengenai kualitas dukungan yang mereka terima dari aplikasi Anda. Anda juga perlu mengumpulkan dan menyimpan riwayat percakapan untuk menyempurnakan FM Anda lebih lanjut guna meningkatkan kemampuan mereka dalam melakukan tugas khusus domain.
Kasus penggunaan ini sangat cocok dengan domain analisis streaming. Aplikasi Anda harus menyimpan setiap percakapan dalam penyimpanan streaming. Aplikasi Anda dapat memberi tahu pengguna tentang penilaian mereka atas keakuratan setiap jawaban dan kepuasan mereka secara keseluruhan. Data ini dapat dalam format pilihan biner atau teks bentuk bebas. Data ini dapat disimpan dalam aliran data Kinesis atau topik MSK, dan diproses untuk menghasilkan KPI secara real-time. Anda dapat memanfaatkan FM untuk analisis sentimen pengguna. FM dapat menganalisis setiap jawaban dan menetapkan kategori kepuasan pengguna.
Arsitektur Apache Flink memungkinkan agregasi data yang kompleks dalam jangka waktu tertentu. Ini juga menyediakan dukungan untuk kueri SQL melalui aliran peristiwa data. Oleh karena itu, dengan menggunakan Apache Flink, Anda dapat dengan cepat menganalisis input pengguna mentah dan menghasilkan KPI secara real-time dengan menulis kueri SQL yang sudah dikenal. Untuk informasi lebih lanjut, lihat Tabel API & SQL.
Dengan Layanan Terkelola Amazon untuk Apache Flink Studio, Anda dapat membangun dan menjalankan aplikasi pemrosesan aliran Apache Flink menggunakan SQL standar, Python, dan Scala dalam buku catatan interaktif. Notebook studio didukung oleh Apache Zeppelin dan menggunakan Apache Flink sebagai mesin pemrosesan aliran. Notebook studio dengan mulus menggabungkan teknologi ini untuk membuat analisis tingkat lanjut pada aliran data dapat diakses oleh pengembang dari semua keahlian. Dengan dukungan untuk fungsi yang ditentukan pengguna (UDF), Apache Flink memungkinkan pembuatan operator khusus untuk berintegrasi dengan sumber daya eksternal seperti FM untuk melakukan tugas kompleks seperti analisis sentimen. Anda dapat menggunakan UDF untuk menghitung berbagai metrik atau memperkaya data mentah masukan pengguna dengan wawasan tambahan seperti sentimen pengguna. Untuk mempelajari lebih lanjut tentang pola ini, lihat Secara proaktif mengatasi kekhawatiran pelanggan secara real-time dengan GenAI, Flink, Apache Kafka, dan Kinesis.
Dengan Layanan Terkelola untuk Apache Flink Studio, Anda dapat menyebarkan notebook Studio Anda sebagai pekerjaan streaming dengan satu klik. Anda dapat menggunakan konektor sink asli yang disediakan oleh Apache Flink untuk mengirim output ke penyimpanan pilihan Anda atau menempatkannya dalam aliran data Kinesis atau topik MSK. Pergeseran Merah Amazon dan OpenSearch Service keduanya ideal untuk menyimpan data analitis. Kedua mesin menyediakan dukungan penyerapan asli dari Kinesis Data Streams dan Amazon MSK melalui pipeline streaming terpisah ke data lake atau gudang data untuk analisis.
Amazon Redshift menggunakan SQL untuk menganalisis data terstruktur dan semi-terstruktur di seluruh gudang data dan data lake, menggunakan perangkat keras dan pembelajaran mesin yang dirancang AWS untuk memberikan kinerja harga terbaik dalam skala besar. Layanan OpenSearch menawarkan kemampuan visualisasi yang didukung oleh OpenSearch Dashboards dan Kibana (versi 1.5 hingga 7.10).
Anda dapat menggunakan hasil analisis tersebut dikombinasikan dengan data cepat pengguna untuk menyempurnakan FM bila diperlukan. SageMaker adalah cara paling mudah untuk menyempurnakan FM Anda. Menggunakan Amazon S3 dengan SageMaker memberikan integrasi yang kuat dan lancar untuk menyempurnakan model Anda. Amazon S3 berfungsi sebagai solusi penyimpanan objek yang skalabel dan tahan lama, memungkinkan penyimpanan dan pengambilan set data besar, data pelatihan, dan artefak model secara mudah. SageMaker adalah layanan ML terkelola sepenuhnya yang menyederhanakan seluruh siklus hidup ML. Dengan menggunakan Amazon S3 sebagai backend penyimpanan untuk SageMaker, Anda dapat memperoleh manfaat dari skalabilitas, keandalan, dan efektivitas biaya Amazon S3, sekaligus mengintegrasikannya secara lancar dengan kemampuan pelatihan dan penerapan SageMaker. Kombinasi ini memungkinkan pengelolaan data yang efisien, memfasilitasi pengembangan model kolaboratif, dan memastikan alur kerja ML disederhanakan dan terukur, yang pada akhirnya meningkatkan ketangkasan dan kinerja proses ML secara keseluruhan. Untuk informasi lebih lanjut, lihat Sempurnakan Falcon 7B dan LLM lainnya di Amazon SageMaker dengan dekorator @remote.
Dengan konektor sink sistem file, pekerjaan Apache Flink dapat mengirimkan data ke file Amazon S3 dalam format terbuka (seperti JSON, Avro, Parquet, dan lainnya) sebagai objek data. Jika Anda lebih suka mengelola data lake menggunakan kerangka data lake transaksional (seperti Apache Hudi, Apache Iceberg, atau Delta Lake), semua kerangka kerja ini menyediakan konektor khusus untuk Apache Flink. Untuk lebih jelasnya, lihat Buat pipeline danau sumber-ke-data latensi rendah menggunakan Amazon MSK Connect, Apache Flink, dan Apache Hudi.
Kesimpulan
Untuk aplikasi AI generatif berdasarkan model RAG, Anda perlu mempertimbangkan untuk membangun dua sistem penyimpanan data, dan Anda perlu membangun operasi data yang selalu memperbaruinya dengan semua sistem sumber. Pekerjaan batch tradisional tidak cukup untuk memproses ukuran dan keragaman data yang Anda perlukan untuk diintegrasikan dengan aplikasi AI generatif Anda. Keterlambatan dalam memproses perubahan pada sistem sumber mengakibatkan respons yang tidak akurat dan mengurangi efisiensi aplikasi AI generatif Anda. Streaming data memungkinkan Anda menyerap data dari berbagai database di berbagai sistem. Ini juga memungkinkan Anda mengubah, memperkaya, menggabungkan, dan menggabungkan data di banyak sumber secara efisien hampir secara real-time. Streaming data menyediakan arsitektur data yang disederhanakan untuk mengumpulkan dan mengubah reaksi atau komentar pengguna secara real-time terhadap respons aplikasi, membantu Anda mengirimkan dan menyimpan hasilnya dalam data lake untuk penyempurnaan model. Streaming data juga membantu Anda mengoptimalkan alur data dengan hanya memproses peristiwa perubahan, sehingga memungkinkan Anda merespons perubahan data dengan lebih cepat dan efisien.
Pelajari lebih lanjut tentang Layanan streaming data AWS dan mulai membangun solusi streaming data Anda sendiri.
Tentang Penulis
 Ali Alem adalah Arsitek Solusi Spesialis Streaming di AWS. Ali memberi saran kepada pelanggan AWS dengan praktik terbaik arsitektur dan membantu mereka merancang sistem data analitik real-time yang andal, aman, efisien, dan hemat biaya. Dia bekerja mundur dari kasus penggunaan pelanggan dan merancang solusi data untuk memecahkan masalah bisnis mereka. Sebelum bergabung dengan AWS, Ali mendukung beberapa pelanggan sektor publik dan mitra konsultan AWS dalam perjalanan modernisasi aplikasi dan migrasi mereka ke Cloud.
Ali Alem adalah Arsitek Solusi Spesialis Streaming di AWS. Ali memberi saran kepada pelanggan AWS dengan praktik terbaik arsitektur dan membantu mereka merancang sistem data analitik real-time yang andal, aman, efisien, dan hemat biaya. Dia bekerja mundur dari kasus penggunaan pelanggan dan merancang solusi data untuk memecahkan masalah bisnis mereka. Sebelum bergabung dengan AWS, Ali mendukung beberapa pelanggan sektor publik dan mitra konsultan AWS dalam perjalanan modernisasi aplikasi dan migrasi mereka ke Cloud.
 Imtiz (Taz) Sayed adalah Pemimpin Teknologi Dunia untuk Analisis di AWS. Dia senang terlibat dengan komunitas dalam segala hal tentang data dan analitik. Ia dapat dihubungi melalui LinkedIn.
Imtiz (Taz) Sayed adalah Pemimpin Teknologi Dunia untuk Analisis di AWS. Dia senang terlibat dengan komunitas dalam segala hal tentang data dan analitik. Ia dapat dihubungi melalui LinkedIn.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

