Alur Kerja Terkelola Amazon untuk Apache Airflow (Amazon MWAA) adalah layanan orkestrasi terkelola untuk Aliran Udara Apache yang dapat Anda gunakan untuk menyiapkan dan mengoperasikan pipeline data di cloud dalam skala besar. Apache Airflow adalah alat sumber terbuka yang digunakan untuk menulis, menjadwalkan, dan memantau urutan proses dan tugas secara terprogram, yang disebut sebagai Alur kerja. Dengan Amazon MWAA, Anda dapat menggunakan Apache Airflow dan Python untuk membuat alur kerja tanpa harus mengelola infrastruktur dasar untuk skalabilitas, ketersediaan, dan keamanan.
Dengan menggunakan beberapa akun AWS, organisasi dapat secara efektif menskalakan beban kerja mereka dan mengelola kompleksitasnya seiring pertumbuhan mereka. Pendekatan ini memberikan mekanisme yang kuat untuk memitigasi potensi dampak gangguan atau kegagalan, memastikan beban kerja penting tetap beroperasi. Selain itu, hal ini memungkinkan optimalisasi biaya dengan menyelaraskan sumber daya dengan kasus penggunaan tertentu, memastikan bahwa pengeluaran terkendali dengan baik. Dengan mengisolasi beban kerja dengan persyaratan keamanan atau kebutuhan kepatuhan tertentu, organisasi dapat mempertahankan tingkat privasi dan keamanan data tertinggi. Selain itu, kemampuan untuk mengatur beberapa akun AWS secara terstruktur memungkinkan Anda menyelaraskan proses bisnis dan sumber daya sesuai dengan kebutuhan operasional, peraturan, dan anggaran unik Anda. Pendekatan ini mengedepankan efisiensi, fleksibilitas, dan skalabilitas, sehingga memungkinkan perusahaan besar memenuhi kebutuhan mereka yang terus berkembang dan mencapai tujuan mereka.
Postingan ini menunjukkan cara mengatur pipeline ekstrak, transformasi, dan pemuatan (ETL) ujung ke ujung menggunakan Layanan Penyimpanan Sederhana Amazon (Amazon S3), Lem AWS, dan Amazon Redshift Tanpa Server dengan Amazon MWAA.
Ikhtisar solusi
Untuk postingan ini, kami mempertimbangkan kasus penggunaan di mana tim teknik data ingin membangun proses ETL dan memberikan pengalaman terbaik kepada pengguna akhir ketika mereka ingin menanyakan data terbaru setelah file mentah baru ditambahkan ke Amazon S3 di pusat. akun (Akun A dalam diagram arsitektur berikut). Tim teknik data ingin memisahkan data mentah ke dalam akun AWS miliknya sendiri (Akun B dalam diagram) untuk meningkatkan keamanan dan kontrol. Mereka juga ingin melakukan pemrosesan data dan pekerjaan transformasi di akun mereka sendiri (Akun B) untuk mengelompokkan tugas dan mencegah perubahan yang tidak diinginkan pada sumber data mentah yang ada di akun pusat (Akun A). Pendekatan ini memungkinkan tim untuk memproses data mentah yang diambil dari Akun A ke Akun B, yang didedikasikan untuk tugas penanganan data. Hal ini memastikan data mentah dan data yang diproses dapat dipisahkan dengan aman di beberapa akun, jika diperlukan, untuk meningkatkan tata kelola dan keamanan data.
Solusi kami menggunakan pipeline ETL end-to-end yang diatur oleh Amazon MWAA yang mencari file tambahan baru di lokasi Amazon S3 di Akun A, tempat data mentah berada. Hal ini dilakukan dengan memanggil tugas ETL AWS Glue dan menulis ke objek data di klaster Redshift Serverless di Akun B. Pipeline kemudian mulai berjalan prosedur yang tersimpan dan perintah SQL di Redshift Tanpa Server. Saat kueri selesai berjalan, an MEMBONGKAR operasi dipanggil dari gudang data Redshift ke bucket S3 di Akun A.
Karena keamanan itu penting, postingan ini juga membahas cara mengkonfigurasi koneksi Airflow menggunakan Manajer Rahasia AWS untuk menghindari penyimpanan kredensial database dalam koneksi dan variabel Airflow.
Diagram berikut mengilustrasikan gambaran arsitektur komponen yang terlibat dalam orkestrasi alur kerja.
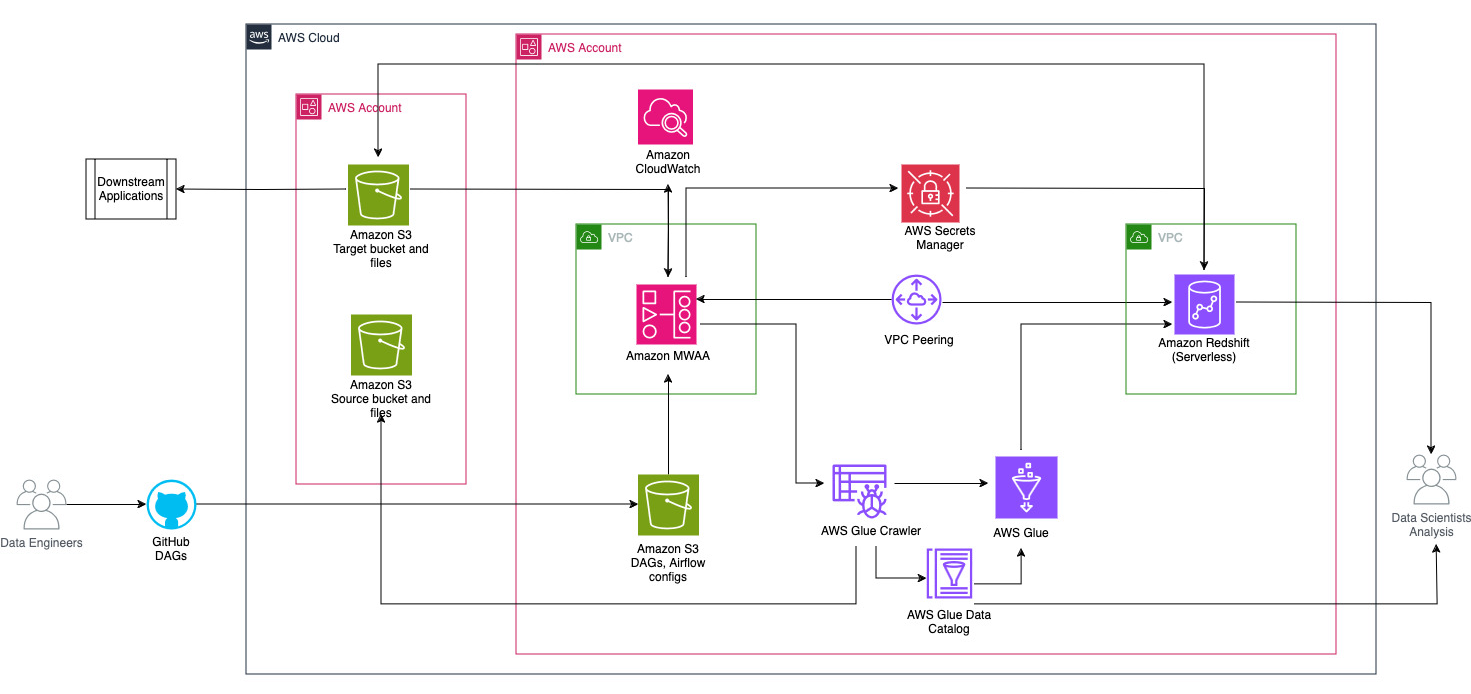
Alur kerja terdiri dari komponen-komponen berikut:
- Bucket S3 sumber dan target berada di akun pusat (Akun A), sedangkan Amazon MWAA, AWS Glue, dan Amazon Redshift berada di akun yang berbeda (Akun B). Akses lintas akun telah diatur antara bucket S3 di Akun A dengan sumber daya di Akun B untuk dapat memuat dan membongkar data.
- Di akun kedua, Amazon MWAA dihosting di satu VPC dan Redshift Serverless di VPC berbeda, yang terhubung melalui peering VPC. Grup kerja Redshift Tanpa Server diamankan di dalam subnet privat di tiga Availability Zone.
- Rahasia seperti nama pengguna, kata sandi, port DB, dan Wilayah AWS untuk Redshift Serverless disimpan di Secrets Manager.
- Titik akhir VPC dibuat untuk Amazon S3 dan Secrets Manager untuk berinteraksi dengan sumber daya lain.
- Biasanya, teknisi data membuat Grafik Asiklik Terarah Aliran Udara (DAG) dan menerapkan perubahannya ke GitHub. Dengan tindakan GitHub, tindakan tersebut diterapkan ke bucket S3 di Akun B (untuk postingan ini, kami mengunggah file ke bucket S3 secara langsung). Bucket S3 menyimpan file terkait Aliran Udara seperti file DAG,
requirements.txtfile, dan plugin. Skrip dan aset ETL AWS Glue disimpan di bucket S3 lain. Pemisahan ini membantu menjaga organisasi dan menghindari kebingungan. - Airflow DAG menggunakan berbagai operator, sensor, koneksi, tugas, dan aturan untuk menjalankan pipeline data sesuai kebutuhan.
- Log Aliran Udara telah masuk amazoncloudwatch, dan peringatan dapat dikonfigurasi untuk tugas pemantauan. Untuk informasi lebih lanjut, lihat Memantau dasbor dan alarm di Amazon MWAA.
Prasyarat
Karena solusi ini berpusat pada penggunaan Amazon MWAA untuk mengatur pipeline ETL, Anda perlu menyiapkan sumber daya dasar tertentu di seluruh akun terlebih dahulu. Secara khusus, Anda perlu membuat bucket dan folder S3, sumber daya AWS Glue, dan sumber daya Redshift Serverless di akunnya masing-masing sebelum menerapkan integrasi alur kerja penuh menggunakan Amazon MWAA.
Terapkan sumber daya di Akun A menggunakan AWS CloudFormation
Di Akun A, luncurkan yang disediakan Formasi AWS Cloud tumpukan untuk membuat sumber daya berikut:
- Bucket dan folder S3 sumber dan target. Sebagai praktik terbaik, struktur keranjang masukan dan keluaran diformat dengan partisi gaya sarang sebagai
s3://<bucket>/products/YYYY/MM/DD/. - Contoh kumpulan data disebut
products.csv, yang kami gunakan dalam posting ini.
![]()
Unggah tugas AWS Glue ke Amazon S3 di Akun B
Di Akun B, buat lokasi Amazon S3 bernama aws-glue-assets-<account-id>-<region>/scripts (jika tidak ada). Ganti parameter ID akun dan Wilayah di sample_glue_job.py skrip dan unggah file tugas AWS Glue ke lokasi Amazon S3.
Terapkan sumber daya di Akun B menggunakan AWS CloudFormation
Di Akun B, luncurkan templat tumpukan CloudFormation yang disediakan untuk membuat sumber daya berikut:
- Bucket S3
airflow-<username>-bucketuntuk menyimpan file terkait Airflow dengan struktur berikut:- hari – Folder untuk file DAG.
- plugin – File untuk plugin Airflow khusus atau komunitas apa pun.
- Persyaratan - The
requirements.txtfile untuk paket Python apa pun. - script – Skrip SQL apa pun yang digunakan di DAG.
- data – Kumpulan data apa pun yang digunakan di DAG.
- Lingkungan Tanpa Server Redshift. Nama grup kerja dan namespace diawali dengan
sample. - Lingkungan AWS Glue, yang berisi hal berikut:
- Lem AWS crawler, yang merayapi data dari bucket sumber S3
sample-inp-bucket-etl-<username>di Akun A. - Sebuah database disebut
products_dbdi Katalog Data Lem AWS. - Sebuah ELT pekerjaan bernama
sample_glue_job. Pekerjaan ini dapat membaca file dariproductstabel di Katalog Data dan memuat data ke tabel Redshiftproducts.
- Lem AWS crawler, yang merayapi data dari bucket sumber S3
- Titik akhir gateway VPC ke Amazon S3.
- Lingkungan Amazon MWAA. Untuk langkah-langkah mendetail dalam membuat lingkungan Amazon MWAA menggunakan konsol Amazon MWAA, lihat Memperkenalkan Alur Kerja Terkelola Amazon untuk Apache Airflow (MWAA).
![]()
Buat sumber daya Amazon Redshift
Buat dua tabel dan prosedur tersimpan pada grup kerja Redshift Serverless menggunakan produk.sql file.
Dalam contoh ini, kita membuat dua tabel yang disebut products dan products_f. Nama prosedur tersimpan adalah sp_products.
Konfigurasikan izin Aliran Udara
Setelah lingkungan Amazon MWAA berhasil dibuat, statusnya akan ditampilkan sebagai Tersedia. Memilih Buka UI Aliran Udara untuk melihat UI Aliran Udara. DAG secara otomatis disinkronkan dari bucket S3 dan terlihat di UI. Namun, pada tahap ini, tidak ada DAG di folder S3.
Tambahkan kebijakan yang dikelola pelanggan AmazonMWAAFullConsoleAccess, yang memberikan izin akses kepada pengguna Airflow Identitas AWS dan Manajemen Akses (IAM), dan lampirkan kebijakan ini ke peran Amazon MWAA. Untuk informasi lebih lanjut, lihat Mengakses lingkungan Amazon MWAA.
Kebijakan yang melekat pada peran Amazon MWAA memiliki akses penuh dan hanya boleh digunakan untuk tujuan pengujian di lingkungan pengujian yang aman. Untuk penerapan produksi, ikuti prinsip hak istimewa paling rendah.
Mengatur lingkungan
Bagian ini menguraikan langkah-langkah untuk mengonfigurasi lingkungan. Prosesnya melibatkan langkah-langkah tingkat tinggi berikut:
- Perbarui penyedia yang diperlukan.
- Siapkan akses lintas akun.
- Buat koneksi peering VPC antara VPC Amazon MWAA dan VPC Amazon Redshift.
- Konfigurasikan Secrets Manager untuk berintegrasi dengan Amazon MWAA.
- Tentukan koneksi Aliran Udara.
Perbarui penyedia
Ikuti langkah-langkah di bagian ini jika versi Amazon MWAA Anda kurang dari 2.8.1 (versi terbaru saat postingan ini ditulis).
Penyedia adalah paket yang dikelola oleh komunitas dan mencakup semua operator inti, pengait, dan sensor untuk layanan tertentu. Penyedia Amazon digunakan untuk berinteraksi dengan layanan AWS seperti Amazon S3, Amazon Redshift Serverless, AWS Glue, dan banyak lagi. Ada lebih dari 200 modul dalam penyedia Amazon.
Meskipun versi Airflow yang didukung di Amazon MWAA adalah 2.6.3, yang dibundel dengan paket yang disediakan Amazon versi 8.2.0, dukungan untuk Amazon Redshift Serverless tidak ditambahkan hingga Amazon menyediakan paket versi 8.4.0. Karena versi penyedia paket default lebih lama dibandingkan saat dukungan Redshift Serverless diperkenalkan, versi penyedia harus ditingkatkan agar dapat menggunakan fungsi tersebut.
Langkah pertama adalah memperbarui file batasan dan requirements.txt file dengan versi yang benar. Mengacu pada Menentukan paket penyedia yang lebih baru untuk langkah-langkah memperbarui paket penyedia Amazon.
- Tentukan persyaratannya sebagai berikut:
- Perbarui versi dalam file batasan ke 8.4.0 atau lebih tinggi.
- Tambahkan batasan-3.11-updated.txt file ke
/dagsfolder.
Lihat Versi Apache Airflow di Amazon Managed Workflows untuk Apache Airflow untuk versi file batasan yang benar bergantung pada versi Airflow.
- Navigasi ke lingkungan Amazon MWAA dan pilih Edit.
- Bawah Kode DAG di Amazon S3, Untuk Berkas persyaratan, pilih versi terbaru.
- Pilih Save.
Ini akan memperbarui lingkungan dan penyedia baru akan berlaku.
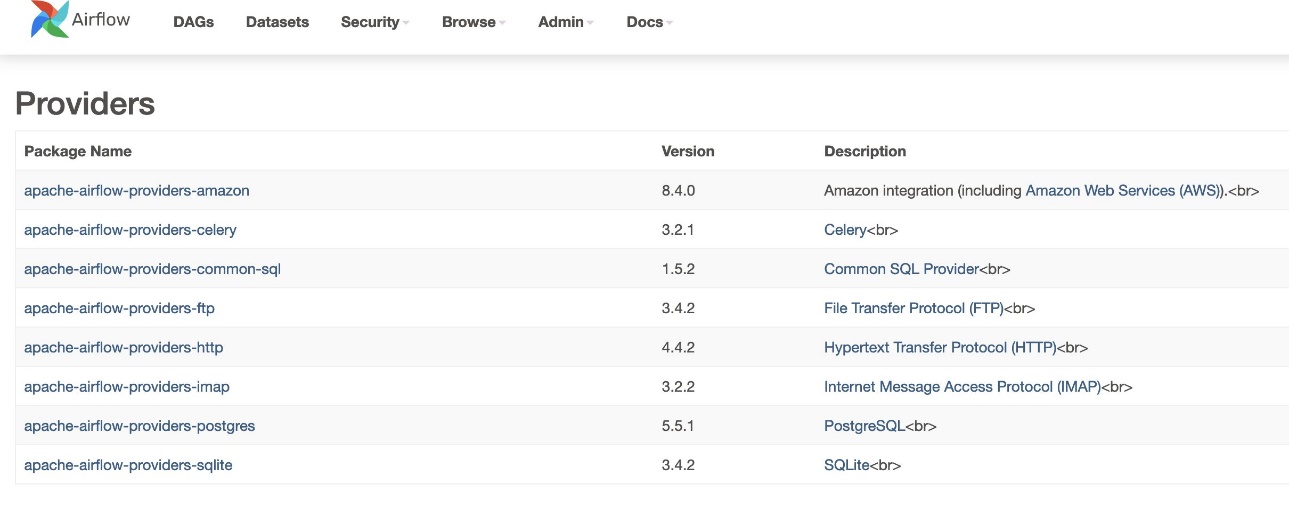
- Untuk memverifikasi versi penyedia, buka Penyedia bawah admin tabel.
Versi paket penyedia Amazon harus 8.4.0, seperti yang ditunjukkan pada tangkapan layar berikut. Jika tidak, ada kesalahan saat memuat requirements.txt. Untuk men-debug kesalahan apa pun, buka konsol CloudWatch dan buka requirements_install_ip masuk Aliran log, di mana kesalahan dicantumkan. Mengacu pada Mengaktifkan log di konsol Amazon MWAA lebih lanjut.
Siapkan akses lintas akun
Anda perlu menyiapkan kebijakan dan peran lintas akun antara Akun A dan Akun B untuk mengakses bucket S3 guna memuat dan mengeluarkan data. Selesaikan langkah-langkah berikut:
- Di Akun A, konfigurasikan kebijakan bucket untuk bucket
sample-inp-bucket-etl-<username>untuk memberikan izin kepada peran AWS Glue dan Amazon MWAA di Akun B untuk objek dalam bucketsample-inp-bucket-etl-<username>: - Demikian pula, konfigurasikan kebijakan bucket untuk bucket
sample-opt-bucket-etl-<username>untuk memberikan izin kepada peran Amazon MWAA di Akun B untuk menempatkan objek di bucket ini: - Di Akun A, buat kebijakan IAM yang disebut
policy_for_roleA, yang memungkinkan tindakan Amazon S3 yang diperlukan pada bucket keluaran: - Buat peran IAM baru yang disebut
RoleAdengan Akun B sebagai peran entitas tepercaya dan tambahkan kebijakan ini ke peran tersebut. Hal ini memungkinkan Akun B mengambil PeranA untuk melakukan tindakan Amazon S3 yang diperlukan pada bucket output. - Di Akun B, buat kebijakan IAM yang disebut
s3-cross-account-accessdengan izin untuk mengakses objek di bucketsample-inp-bucket-etl-<username>, yang ada di Akun A. - Tambahkan kebijakan ini ke peran AWS Glue dan peran Amazon MWAA:
- Di Akun B, buat kebijakan IAM
policy_for_roleBmenentukan Akun A sebagai entitas tepercaya. Berikut ini adalah kebijakan kepercayaan yang harus diambilRoleAdi Akun A: - Buat peran IAM baru yang disebut
RoleBdengan Amazon Redshift sebagai jenis entitas tepercaya dan tambahkan kebijakan ini ke peran tersebut. Hal ini memungkinkanRoleBuntuk mengasumsikanRoleAdi Akun A dan juga dapat diasumsikan oleh Amazon Redshift. - Melampirkan
RoleBke namespace Redshift Serverless, sehingga Amazon Redshift dapat menulis objek ke bucket output S3 di Akun A. - Lampirkan kebijakan
policy_for_roleBke peran Amazon MWAA, yang memungkinkan Amazon MWAA mengakses bucket output di Akun A.
Lihat Bagaimana cara memberikan akses lintas akun ke objek yang ada di bucket Amazon S3? untuk detail selengkapnya tentang menyiapkan akses lintas akun ke objek di Amazon S3 dari AWS Glue dan Amazon MWAA. Mengacu pada Bagaimana cara SALIN atau UNLOAD data dari Amazon Redshift ke bucket Amazon S3 di akun lain? untuk detail selengkapnya tentang menyiapkan peran untuk membongkar data dari Amazon Redshift ke Amazon S3 dari Amazon MWAA.
Siapkan peering VPC antara VPC Amazon MWAA dan Amazon Redshift
Karena Amazon MWAA dan Amazon Redshift berada dalam dua VPC terpisah, Anda perlu menyiapkan peering VPC di antara keduanya. Anda harus menambahkan rute ke tabel rute yang terkait dengan subnet untuk kedua layanan. Mengacu pada Bekerja dengan koneksi peering VPC untuk detail tentang peering VPC.

Pastikan rentang CIDR VPC Amazon MWAA diizinkan di grup keamanan Redshift dan rentang CIDR VPC Amazon Redshift diizinkan di grup keamanan Amazon MWAA, seperti yang ditunjukkan pada tangkapan layar berikut.

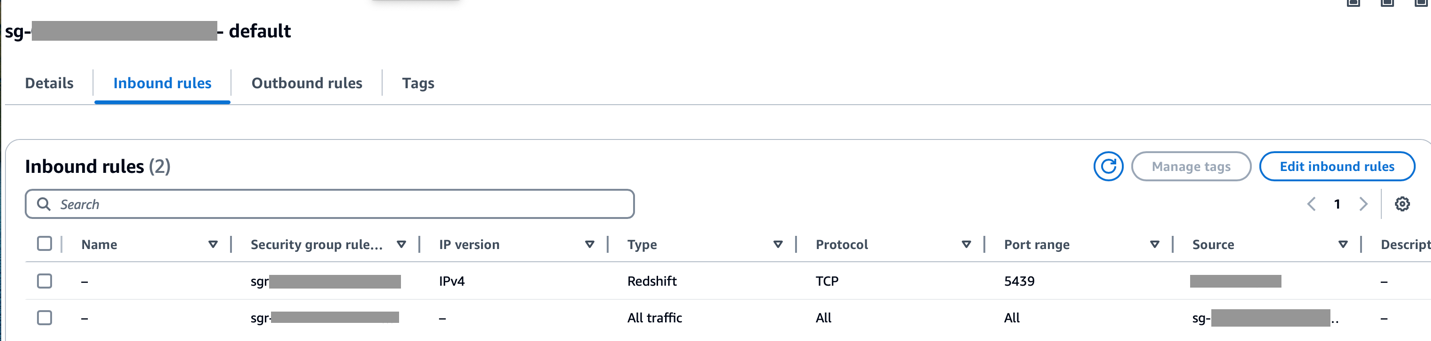
Jika salah satu langkah sebelumnya tidak dikonfigurasi dengan benar, Anda mungkin mengalami kesalahan “Connection Timeout” saat menjalankan DAG.
Konfigurasikan koneksi Amazon MWAA dengan Secrets Manager
Ketika pipa Amazon MWAA dikonfigurasi untuk menggunakan Secrets Manager, pipa tersebut akan mencari koneksi dan variabel terlebih dahulu di backend alternatif (seperti Secrets Manager). Jika backend alternatif berisi nilai yang diperlukan, maka akan dikembalikan. Jika tidak, ia akan memeriksa database metadata untuk mengetahui nilainya dan mengembalikannya. Untuk lebih jelasnya, lihat Mengonfigurasi koneksi Apache Airflow menggunakan rahasia AWS Secrets Manager.
Selesaikan langkah-langkah berikut:
- Konfigurasi a Titik akhir VPC untuk menghubungkan Amazon MWAA dan Secrets Manager (
com.amazonaws.us-east-1.secretsmanager).
Hal ini memungkinkan Amazon MWAA untuk mengakses kredensial yang disimpan di Secrets Manager.

- Untuk memberikan izin kepada Amazon MWAA untuk mengakses kunci rahasia Secrets Manager, tambahkan kebijakan yang disebut
SecretsManagerReadWriteterhadap peran IAM terhadap lingkungan. - Untuk membuat backend Secrets Manager sebagai opsi konfigurasi Apache Airflow, buka opsi konfigurasi Airflow, tambahkan pasangan nilai kunci berikut, dan simpan pengaturan Anda.
Ini mengonfigurasi Airflow untuk mencari string koneksi dan variabel di airflow/connections/* dan airflow/variables/* jalur:

- Untuk menghasilkan string URI koneksi Airflow, buka AWS CloudShell dan masuk ke shell Python.
- Jalankan kode berikut untuk menghasilkan string URI koneksi:
String koneksi harus dibuat sebagai berikut:
- Tambahkan koneksi di Secrets Manager menggunakan perintah berikut di Antarmuka Baris Perintah AWS (AWS CLI).
Ini juga dapat dilakukan dari konsol Secrets Manager. Ini akan ditambahkan di Secrets Manager sebagai teks biasa.
Gunakan koneksi airflow/connections/secrets_redshift_connection di DAG. Saat DAG dijalankan, DAG akan mencari koneksi ini dan mengambil rahasia dari Secrets Manager. Dalam kasus RedshiftDataOperator, melewati secret_arn sebagai parameter, bukan nama koneksi.
Anda juga dapat menambahkan rahasia menggunakan konsol Secrets Manager sebagai pasangan nilai kunci.
- Tambahkan rahasia lain di Manajer Rahasia dan simpan sebagai
airflow/connections/redshift_conn_test.
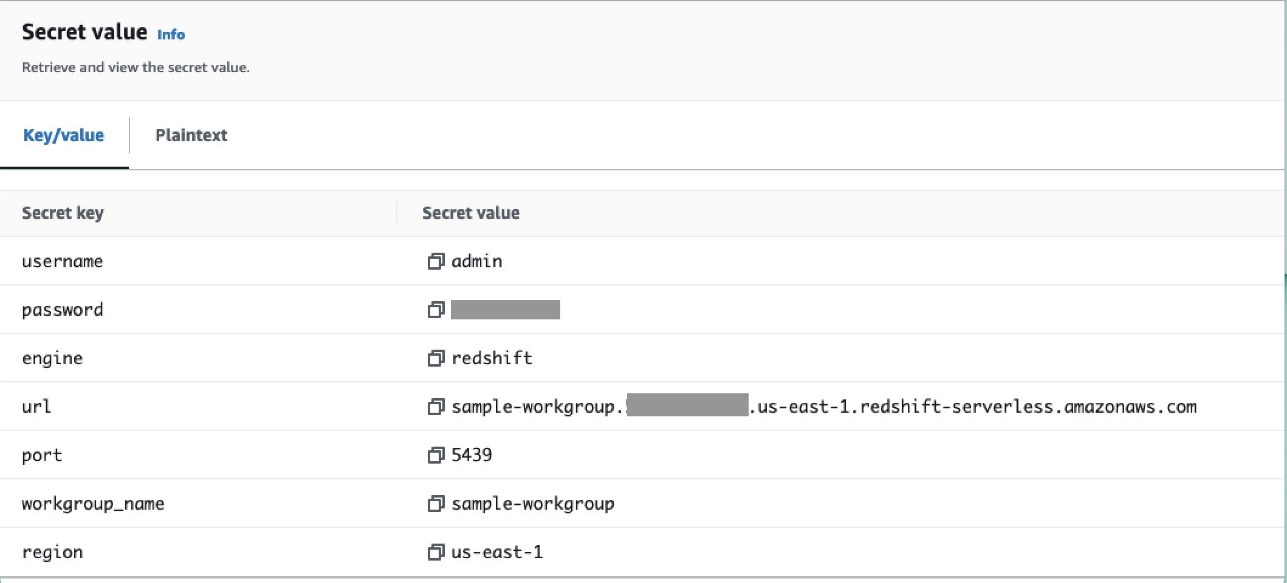
Buat koneksi Airflow melalui database metadata
Anda juga dapat membuat koneksi di UI. Dalam hal ini, detail koneksi akan disimpan dalam database metadata Airflow. Jika lingkungan Amazon MWAA tidak dikonfigurasi untuk menggunakan backend Secrets Manager, lingkungan tersebut akan memeriksa nilai database metadata dan mengembalikannya. Anda dapat membuat koneksi Airflow menggunakan UI, AWS CLI, atau API. Di bagian ini, kami menunjukkan cara membuat koneksi menggunakan Airflow UI.
- Untuk Id Koneksi, masukkan nama untuk koneksi.
- Untuk Jenis Koneksi, pilih Pergeseran Merah Amazon.
- Untuk tuan rumah, masukkan titik akhir Redshift (tanpa port dan database) untuk Redshift Tanpa Server.
- Untuk Basis Data, Masuk
dev. - Untuk Pengguna, masukkan nama pengguna admin Anda.
- Untuk Kata Sandi, masukkan kata sandi Anda.
- Untuk pelabuhan, gunakan porta 5439.
- Untuk ekstra, mengatur
regiondantimeoutparameter. - Uji koneksi, lalu simpan pengaturan Anda.

Buat dan jalankan DAG
Pada bagian ini, kami menjelaskan cara membuat DAG menggunakan berbagai komponen. Setelah Anda membuat dan menjalankan DAG, Anda dapat memverifikasi hasilnya dengan menanyakan tabel Redshift dan memeriksa bucket S3 target.
Buat DAG
Di Airflow, pipeline data didefinisikan dalam kode Python sebagai DAG. Kami membuat DAG yang terdiri dari berbagai operator, sensor, koneksi, tugas, dan aturan:
- DAG dimulai dengan mencari file sumber di bucket S3
sample-inp-bucket-etl-<username>di bawah Akun A untuk penggunaan hari iniS3KeySensor. S3KeySensor digunakan untuk menunggu satu atau beberapa kunci ada di bucket S3.- Misalnya, bucket S3 kita dipartisi sebagai
s3://bucket/products/YYYY/MM/DD/, jadi sensor kita harus memeriksa folder dengan tanggal sekarang. Kami memperoleh tanggal saat ini di DAG dan meneruskannya keS3KeySensor, yang mencari file baru di folder hari ini. - Kami juga mengatur
wildcard_matchasTrue, yang memungkinkan pencarian aktifbucket_keyuntuk ditafsirkan sebagai pola wildcard Unix. Mengaturmodeuntukreschedulesehingga tugas sensor mengosongkan slot pekerja ketika kriteria tidak terpenuhi dan dijadwal ulang di lain waktu. Sebagai praktik terbaik, gunakan mode ini kapan sajapoke_intervallebih dari 1 menit untuk mencegah terlalu banyak beban pada penjadwal.
- Misalnya, bucket S3 kita dipartisi sebagai
- Setelah file tersedia di bucket S3, crawler AWS Glue berjalan menggunakan
GlueCrawlerOperatoruntuk merayapi bucket sumber S3sample-inp-bucket-etl-<username>di bawah Akun A dan memperbarui metadata tabel di bawahproducts_dbdatabase di Katalog Data. Crawler menggunakan peran AWS Glue dan database Data Catalog yang dibuat pada langkah sebelumnya. - DAG menggunakan
GlueCrawlerSensormenunggu hingga crawler selesai. - Ketika pekerjaan perayap selesai,
GlueJobOperatordigunakan untuk menjalankan tugas AWS Glue. Nama skrip AWS Glue (beserta lokasi) dan diteruskan ke operator bersama dengan IAM role AWS Glue. Parameter lain sepertiGlueVersion,NumberofWorkers, danWorkerTypedilewatkan menggunakancreate_job_kwargsparameter. - DAG menggunakan
GlueJobSensoruntuk menunggu pekerjaan AWS Glue selesai. Jika sudah selesai, tabel pementasan Redshiftproductsakan dimuat dengan data dari file S3. - Anda dapat terhubung ke Amazon Redshift dari Airflow menggunakan tiga yang berbeda operator:
PythonOperator.SQLExecuteQueryOperator, yang menggunakan koneksi PostgreSQL danredshift_defaultsebagai koneksi default.RedshiftDataOperator, yang menggunakan Redshift Data API danaws_defaultsebagai koneksi default.
Di DAG kami, kami menggunakan SQLExecuteQueryOperator dan RedshiftDataOperator untuk menunjukkan cara menggunakan operator ini. Prosedur tersimpan Redshift dijalankan RedshiftDataOperator. DAG juga menjalankan perintah SQL di Amazon Redshift untuk menghapus data dari tabel pementasan menggunakan SQLExecuteQueryOperator.
Karena kami mengonfigurasi lingkungan Amazon MWAA untuk mencari koneksi di Secrets Manager, ketika DAG berjalan, DAG mengambil detail koneksi Redshift seperti nama pengguna, kata sandi, host, port, dan Wilayah dari Secrets Manager. Jika koneksi tidak ditemukan di Secrets Manager, nilai diambil dari koneksi default.
In SQLExecuteQueryOperator, kita meneruskan nama koneksi yang kita buat di Secrets Manager. Itu mencari airflow/connections/secrets_redshift_connection dan mengambil rahasia dari Secrets Manager. Jika Secrets Manager tidak diatur, koneksi dibuat secara manual (misalnya, redshift-conn-id) dapat dilewati.
In RedshiftDataOperator, kami melewati secret_arn dari airflow/connections/redshift_conn_test koneksi yang dibuat di Secrets Manager sebagai parameter.
- Sebagai tugas akhir,
RedshiftToS3Operatordigunakan untuk membongkar data dari tabel Redshift ke bucket S3sample-opt-bucket-etldi Akun B.airflow/connections/redshift_conn_testdari Secrets Manager digunakan untuk membongkar data. TriggerRulediatur keALL_DONE, yang memungkinkan langkah selanjutnya dijalankan setelah semua tugas upstream selesai.- Ketergantungan tugas ditentukan menggunakan
chain()fungsi, yang memungkinkan pelaksanaan tugas paralel jika diperlukan. Dalam kasus kami, kami ingin semua tugas dijalankan secara berurutan.
Berikut kode DAG selengkapnya. Itu dag_id harus cocok dengan nama skrip DAG, jika tidak, maka tidak akan disinkronkan ke UI Airflow.
Verifikasi proses DAG
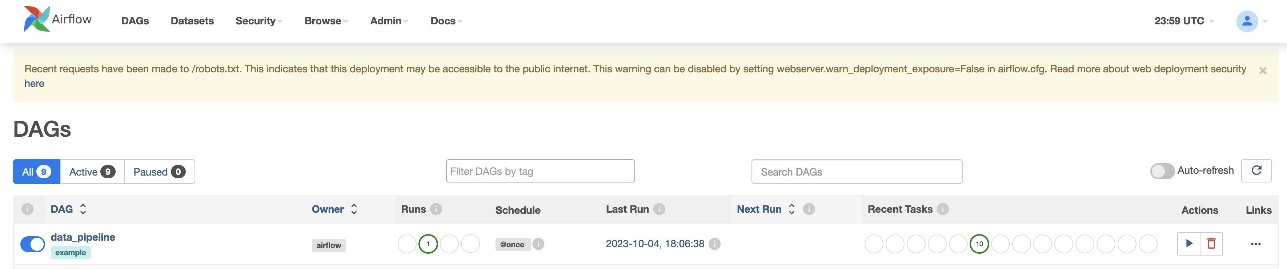
Setelah Anda membuat file DAG (ganti variabel di script DAG) dan upload ke s3://sample-airflow-instance/dags folder, itu akan secara otomatis disinkronkan dengan Airflow UI. Semua DAG muncul di DAG tab. Alihkan ON opsi untuk membuat DAG dapat dijalankan. Karena DAG kita disetel ke schedule="@once", Anda perlu menjalankan pekerjaan secara manual dengan memilih ikon jalankan di bawah tindakan. Ketika DAG selesai, status diperbarui dengan warna hijau, seperti yang ditunjukkan pada gambar layar berikut.
Dalam majalah Link bagian, ada opsi untuk melihat kode, grafik, kisi, log, dan lainnya. Memilih Grafik untuk memvisualisasikan DAG dalam format grafik. Seperti yang diperlihatkan dalam tangkapan layar berikut, setiap warna simpul menunjukkan operator tertentu, dan warna garis simpul menunjukkan status tertentu.

Verifikasi hasilnya
Di konsol Amazon Redshift, navigasikan ke Editor Kueri v2 dan pilih data di products_f meja. Tabel harus dimuat dan memiliki jumlah rekaman yang sama dengan file S3.

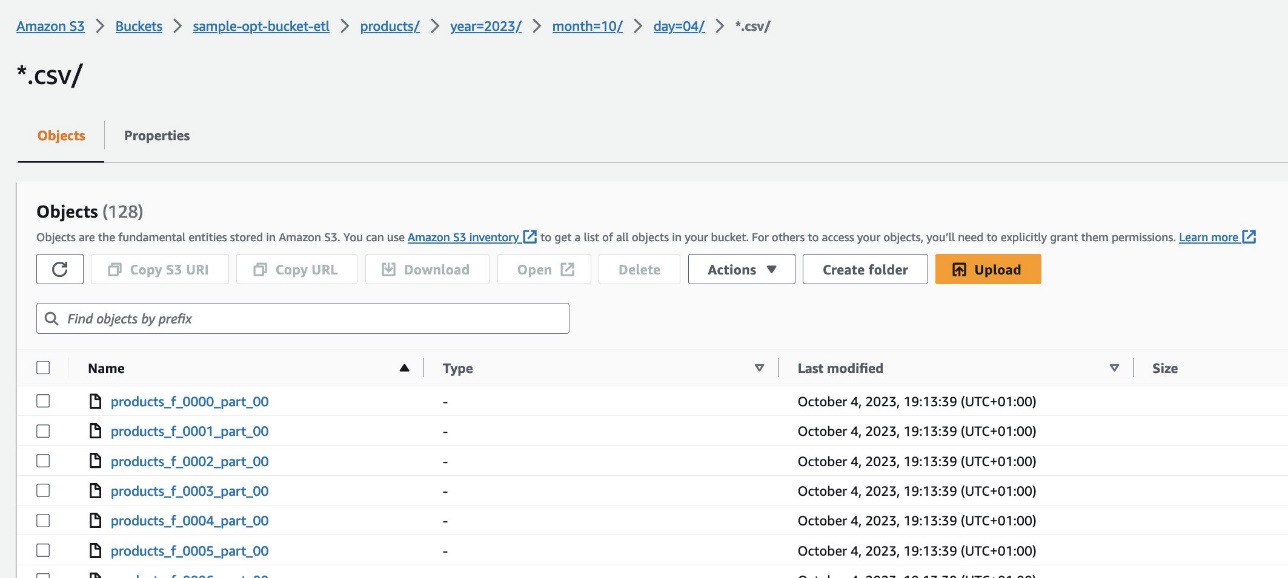
Di konsol Amazon S3, navigasikan ke bucket S3 s3://sample-opt-bucket-etl di Rekening B.The product_f file harus dibuat di bawah struktur folder s3://sample-opt-bucket-etl/products/YYYY/MM/DD/.
Membersihkan
Bersihkan sumber daya yang dibuat sebagai bagian dari postingan ini untuk menghindari timbulnya biaya berkelanjutan:
- Hapus tumpukan CloudFormation dan bucket S3 yang Anda buat sebagai prasyarat.
- Hapus koneksi peering VPC dan VPC, kebijakan dan peran lintas akun, serta rahasia di Secrets Manager.
Kesimpulan
Dengan Amazon MWAA, Anda dapat membangun alur kerja yang kompleks menggunakan Airflow dan Python tanpa mengelola klaster, node, atau overhead operasional lainnya yang biasanya terkait dengan penerapan dan penskalaan Airflow dalam produksi. Dalam postingan ini, kami menunjukkan bagaimana Amazon MWAA menyediakan cara otomatis untuk menyerap, mengubah, menganalisis, dan mendistribusikan data antara berbagai akun dan layanan dalam AWS. Untuk contoh lebih lanjut dari operator AWS lainnya, lihat yang berikut ini Repositori GitHub; kami mendorong Anda untuk mempelajari lebih lanjut dengan mencoba beberapa contoh berikut.
Tentang Penulis

Radhika Jakkula adalah Arsitek Solusi Prototipe Big Data di AWS. Dia membantu pelanggan membangun prototipe menggunakan layanan analitik AWS dan database yang dibuat khusus. Dia ahli dalam menilai berbagai persyaratan dan menerapkan layanan AWS yang relevan, alat big data, dan kerangka kerja untuk menciptakan arsitektur yang kuat.
 Sidhanth Muralidhar adalah Manajer Akun Teknis Utama di AWS. Dia bekerja dengan pelanggan perusahaan besar yang menjalankan beban kerja mereka di AWS. Dia bersemangat bekerja dengan pelanggan dan membantu mereka merancang beban kerja untuk biaya, keandalan, kinerja, dan keunggulan operasional dalam skala besar dalam perjalanan cloud mereka. Dia juga sangat tertarik dengan analisis data.
Sidhanth Muralidhar adalah Manajer Akun Teknis Utama di AWS. Dia bekerja dengan pelanggan perusahaan besar yang menjalankan beban kerja mereka di AWS. Dia bersemangat bekerja dengan pelanggan dan membantu mereka merancang beban kerja untuk biaya, keandalan, kinerja, dan keunggulan operasional dalam skala besar dalam perjalanan cloud mereka. Dia juga sangat tertarik dengan analisis data.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/orchestrate-an-end-to-end-etl-pipeline-using-amazon-s3-aws-glue-and-amazon-redshift-serverless-with-amazon-mwaa/

