Dalam lanskap manufaktur yang terus berkembang, kekuatan transformatif AI dan pembelajaran mesin (ML) terlihat jelas, mendorong revolusi digital yang menyederhanakan operasional dan meningkatkan produktivitas. Namun, kemajuan ini menimbulkan tantangan unik bagi perusahaan yang menggunakan solusi berbasis data. Fasilitas industri bergulat dengan data tidak terstruktur dalam jumlah besar, yang bersumber dari sensor, sistem telemetri, dan peralatan yang tersebar di seluruh lini produksi. Data real-time sangat penting untuk aplikasi seperti pemeliharaan prediktif dan deteksi anomali, namun mengembangkan model ML khusus untuk setiap kasus penggunaan industri dengan data deret waktu memerlukan banyak waktu dan sumber daya dari data scientist, sehingga menghambat penerapannya secara luas.
AI generatif menggunakan model pondasi terlatih (FM) besar seperti Claude dapat dengan cepat menghasilkan berbagai konten dari teks percakapan hingga kode komputer berdasarkan perintah teks sederhana, yang dikenal sebagai dorongan zero-shot. Hal ini menghilangkan kebutuhan ilmuwan data untuk secara manual mengembangkan model ML spesifik untuk setiap kasus penggunaan, dan oleh karena itu mendemokratisasi akses AI, sehingga menguntungkan produsen kecil sekalipun. Pekerja memperoleh produktivitas melalui wawasan yang dihasilkan AI, para insinyur dapat secara proaktif mendeteksi anomali, manajer rantai pasokan mengoptimalkan inventaris, dan pimpinan pabrik membuat keputusan berdasarkan informasi dan data.
Namun demikian, FM yang berdiri sendiri menghadapi keterbatasan dalam menangani data industri yang kompleks dengan batasan ukuran konteks (biasanya kurang dari 200,000 token), yang menimbulkan tantangan. Untuk mengatasi hal ini, Anda dapat menggunakan kemampuan FM untuk menghasilkan kode sebagai respons terhadap kueri bahasa alami (NLQ). Agen seperti PandaAI ikut bermain, menjalankan kode ini pada data deret waktu resolusi tinggi dan menangani kesalahan menggunakan FM. PandasAI adalah pustaka Python yang menambahkan kemampuan AI generatif ke panda, alat analisis dan manipulasi data yang populer.
Namun, NLQ yang kompleks, seperti pemrosesan data deret waktu, agregasi multi-level, dan operasi pivot atau tabel gabungan, dapat menghasilkan akurasi skrip Python yang tidak konsisten dengan prompt zero-shot.
Untuk meningkatkan akurasi pembuatan kode, kami mengusulkan pembangunan secara dinamis perintah multi-shot untuk NLQ. Perintah multi-shot memberikan konteks tambahan pada FM dengan menunjukkan beberapa contoh keluaran yang diinginkan untuk perintah serupa, sehingga meningkatkan akurasi dan konsistensi. Dalam postingan ini, perintah multi-shot diambil dari penyematan yang berisi kode Python yang berhasil dijalankan pada tipe data serupa (misalnya, data deret waktu resolusi tinggi dari perangkat Internet of Things). Perintah multi-shot yang dibuat secara dinamis memberikan konteks paling relevan dengan FM, dan meningkatkan kemampuan FM dalam penghitungan matematika tingkat lanjut, pemrosesan data deret waktu, dan pemahaman akronim data. Respons yang lebih baik ini memfasilitasi pekerja perusahaan dan tim operasional dalam berinteraksi dengan data, memperoleh wawasan tanpa memerlukan keterampilan ilmu data yang luas.
Selain analisis data deret waktu, FM terbukti bermanfaat dalam berbagai aplikasi industri. Tim pemeliharaan menilai kesehatan aset, mengambil gambar Rekognisi Amazonringkasan fungsionalitas berbasis, dan analisis akar penyebab anomali menggunakan pencarian cerdas dengan Pengambilan Augmented Generation (LAP). Untuk menyederhanakan alur kerja ini, AWS telah memperkenalkan Batuan Dasar Amazon, memungkinkan Anda membangun dan menskalakan aplikasi AI generatif dengan FM terlatih yang canggih seperti Claude v2. Dengan Basis Pengetahuan untuk Batuan Dasar Amazon, Anda dapat menyederhanakan proses pengembangan RAG untuk memberikan analisis akar penyebab anomali yang lebih akurat bagi pekerja pabrik. Postingan kami menampilkan asisten cerdas untuk kasus penggunaan industri yang didukung oleh Amazon Bedrock, mengatasi tantangan NLQ, menghasilkan ringkasan bagian dari gambar, dan meningkatkan respons FM untuk diagnosis peralatan melalui pendekatan RAG.
Ikhtisar solusi
Diagram berikut menggambarkan arsitektur solusi.

Alur kerjanya mencakup tiga kasus penggunaan yang berbeda:
Kasus penggunaan 1: NLQ dengan data deret waktu
Alur kerja untuk NLQ dengan data deret waktu terdiri dari langkah-langkah berikut:
- Kami menggunakan sistem pemantauan kondisi dengan kemampuan ML untuk mendeteksi anomali, seperti Amazon Monitor, untuk memantau kesehatan peralatan industri. Amazon Monitron mampu mendeteksi potensi kegagalan peralatan dari pengukuran getaran dan suhu peralatan.
- Kami mengumpulkan data deret waktu dengan memproses Amazon Monitor data melalui Aliran Data Amazon Kinesis dan Amazon Data Firehose, mengubahnya menjadi format CSV tabel dan menyimpannya dalam Layanan Penyimpanan Sederhana Amazon (Amazon S3).
- Pengguna akhir dapat mulai mengobrol dengan data deret waktu mereka di Amazon S3 dengan mengirimkan kueri bahasa alami ke aplikasi Streamlit.
- Aplikasi Streamlit meneruskan pertanyaan pengguna ke Model penyematan teks Amazon Bedrock Titan untuk menyematkan kueri ini, dan melakukan pencarian kesamaan dalam sebuah Layanan Pencarian Terbuka Amazon indeks, yang berisi NLQ sebelumnya dan kode contoh.
- Setelah pencarian kesamaan, contoh serupa teratas, termasuk pertanyaan NLQ, skema data, dan kode Python, dimasukkan ke dalam prompt kustom.
- PandasAI mengirimkan permintaan khusus ini ke model Amazon Bedrock Claude v2.
- Aplikasi ini menggunakan agen PandasAI untuk berinteraksi dengan model Amazon Bedrock Claude v2, menghasilkan kode Python untuk analisis data Amazon Monitron dan respons NLQ.
- Setelah model Amazon Bedrock Claude v2 mengembalikan kode Python, PandasAI menjalankan kueri Python pada data Amazon Monitron yang diunggah dari aplikasi, mengumpulkan output kode dan menangani setiap percobaan ulang yang diperlukan untuk proses yang gagal.
- Aplikasi Streamlit mengumpulkan respons melalui PandasAI, dan memberikan hasilnya kepada pengguna. Jika hasilnya memuaskan, pengguna dapat menandainya sebagai bermanfaat, menyimpan kode Python yang dihasilkan NLQ dan Claude di OpenSearch Service.
Kasus penggunaan 2: Pembuatan ringkasan komponen yang tidak berfungsi
Kasus penggunaan pembuatan ringkasan kami terdiri dari langkah-langkah berikut:
- Setelah pengguna mengetahui aset industri mana yang menunjukkan perilaku anomali, mereka dapat mengunggah gambar bagian yang tidak berfungsi untuk mengidentifikasi apakah ada yang salah secara fisik dengan bagian tersebut sesuai dengan spesifikasi teknis dan kondisi pengoperasiannya.
- Pengguna dapat menggunakan API DetectText Pengenalan Amazon untuk mengekstrak data teks dari gambar-gambar ini.
- Data teks yang diekstraksi disertakan dalam perintah untuk model Amazon Bedrock Claude v2, memungkinkan model menghasilkan ringkasan 200 kata dari bagian yang tidak berfungsi. Pengguna dapat menggunakan informasi ini untuk melakukan pemeriksaan lebih lanjut terhadap bagian tersebut.
Kasus penggunaan 3: Diagnosis akar penyebab
Kasus penggunaan diagnosis akar masalah kami terdiri dari langkah-langkah berikut:
- Pengguna memperoleh data perusahaan dalam berbagai format dokumen (PDF, TXT, dan sebagainya) terkait dengan aset yang tidak berfungsi, dan mengunggahnya ke bucket S3.
- Basis pengetahuan file-file ini dihasilkan di Amazon Bedrock dengan model penyematan teks Titan dan penyimpanan vektor OpenSearch Service default.
- Pengguna mengajukan pertanyaan terkait diagnosis akar penyebab peralatan tidak berfungsi. Jawaban dihasilkan melalui basis pengetahuan Amazon Bedrock dengan pendekatan RAG.
Prasyarat
Untuk mengikuti posting ini, Anda harus memenuhi prasyarat berikut:
Menyebarkan infrastruktur solusi
Untuk menyiapkan sumber daya solusi Anda, selesaikan langkah-langkah berikut:
- Terapkan Formasi AWS Cloud Template opensearchsagemaker.yml, yang membuat koleksi dan indeks Layanan OpenSearch, Amazon SageMaker contoh notebook, dan bucket S3. Anda dapat memberi nama tumpukan AWS CloudFormation ini sebagai:
genai-sagemaker. - Buka instans notebook SageMaker di JupyterLab. Anda akan menemukan yang berikut ini GitHub repo sudah diunduh pada contoh ini: membuka-potensi-generatif-ai-dalam-operasi-industri.
- Jalankan notebook dari direktori berikut di repositori ini: membuka-potensi-generatif-ai-dalam-operasi-industri/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. Notebook ini akan memuat indeks OpenSearch Service menggunakan notebook SageMaker untuk menyimpan pasangan nilai kunci dari ada 23 contoh NLQ.
- Unggah dokumen dari folder data asetpartdoc di repositori GitHub ke bucket S3 yang tercantum dalam output tumpukan CloudFormation.

Selanjutnya, Anda membuat basis pengetahuan untuk dokumen di Amazon S3.
- Di konsol Amazon Bedrock, pilih Dasar pengetahuan di panel navigasi.
- Pilih Buat basis pengetahuan.
- Untuk Nama basis pengetahuan, masukkan nama.
- Untuk Peran waktu proses, pilih Buat dan gunakan peran layanan baru.
- Untuk Nama sumber data, masukkan nama sumber data Anda.
- Untuk URI S3, masukkan jalur S3 pada bucket tempat Anda mengunggah dokumen penyebab utama.
- Pilih Selanjutnya.
 Model penyematan Titan dipilih secara otomatis.
Model penyematan Titan dipilih secara otomatis. - Pilih Buat toko vektor baru dengan cepat.
- Tinjau pengaturan Anda dan buat basis pengetahuan dengan memilih Buat basis pengetahuan.
- Setelah basis pengetahuan berhasil dibuat, pilih Sync untuk menyinkronkan bucket S3 dengan basis pengetahuan.

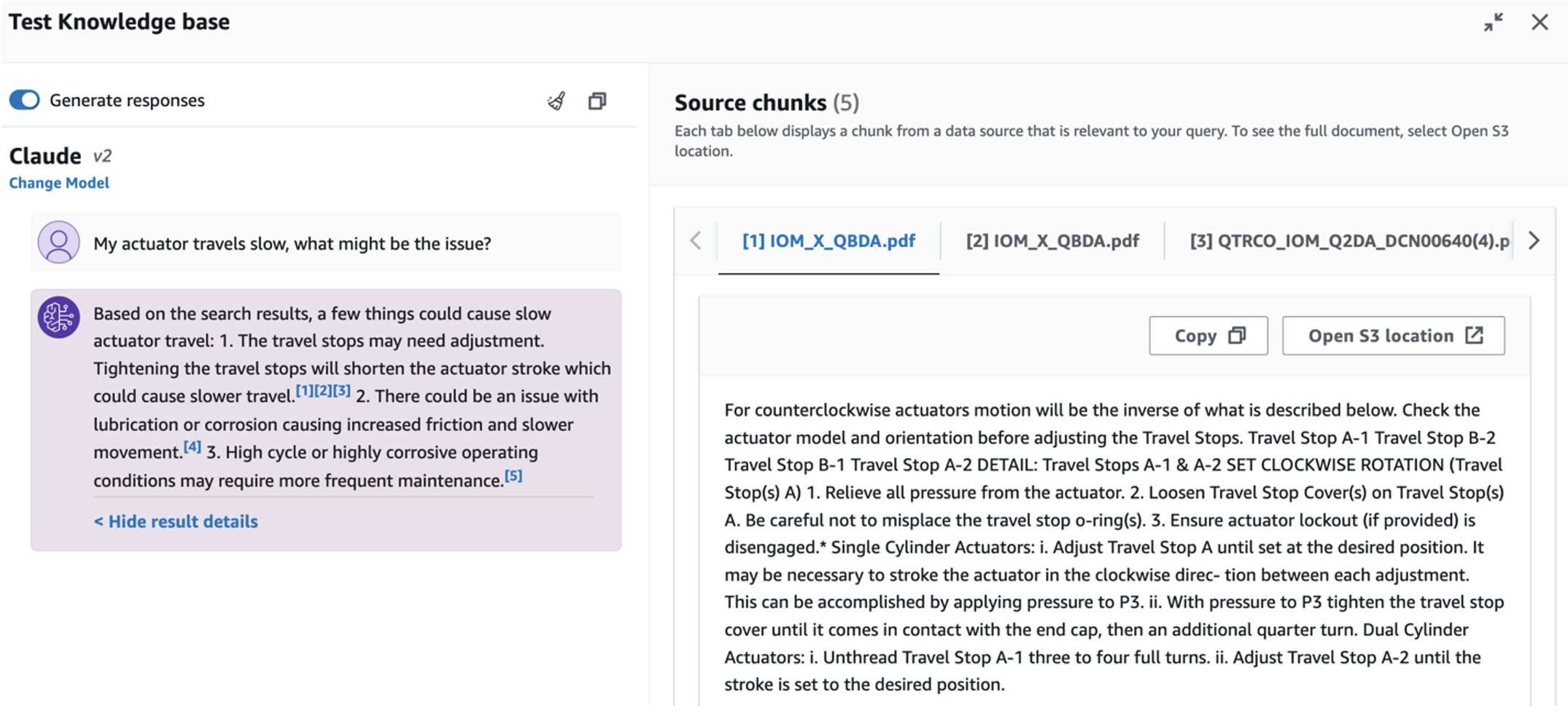
- Setelah Anda menyiapkan basis pengetahuan, Anda dapat menguji pendekatan RAG untuk diagnosis akar masalah dengan mengajukan pertanyaan seperti “Aktuator saya berjalan lambat, apa masalahnya?”
Langkah berikutnya adalah menyebarkan aplikasi dengan paket perpustakaan yang diperlukan pada PC Anda atau instans EC2 (Ubuntu Server 22.04 LTS).
- Siapkan kredensial AWS Anda dengan AWS CLI di PC lokal Anda. Untuk mempermudah, Anda dapat menggunakan peran admin yang sama dengan yang Anda gunakan untuk menyebarkan tumpukan CloudFormation. Jika Anda menggunakan Amazon EC2, lampirkan IAM role yang sesuai ke instance.
- Klon GitHub repo:
- Ubah direktori menjadi
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcdan jalankansetup.shskrip di folder ini untuk menginstal paket yang diperlukan, termasuk LangChain dan PandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Jalankan aplikasi Streamlit dengan perintah berikut:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Berikan ARN koleksi OpenSearch Service yang Anda buat di Amazon Bedrock dari langkah sebelumnya.
Ngobrol dengan asisten kesehatan aset Anda
Setelah Anda menyelesaikan penerapan end-to-end, Anda dapat mengakses aplikasi melalui localhost pada port 8501, yang membuka jendela browser dengan antarmuka web. Jika Anda menerapkan aplikasi pada instans EC2, izinkan akses port 8501 melalui aturan masuk grup keamanan. Anda dapat menavigasi ke tab berbeda untuk berbagai kasus penggunaan.
Jelajahi kasus penggunaan 1
Untuk menjelajahi kasus penggunaan pertama, pilih Wawasan Data dan Bagan. Mulailah dengan mengunggah data deret waktu Anda. Jika Anda tidak memiliki file data deret waktu untuk digunakan, Anda dapat mengunggah yang berikut ini contoh file CSV dengan data proyek Amazon Monitron anonim. Jika Anda sudah memiliki proyek Amazon Monitron, lihat Hasilkan wawasan yang dapat ditindaklanjuti untuk manajemen pemeliharaan prediktif dengan Amazon Monitron dan Amazon Kinesis untuk melakukan streaming data Amazon Monitron Anda ke Amazon S3 dan menggunakan data Anda dengan aplikasi ini.
Saat pengunggahan selesai, masukkan kueri untuk memulai percakapan dengan data Anda. Sidebar kiri menawarkan serangkaian contoh pertanyaan untuk kenyamanan Anda. Tangkapan layar berikut mengilustrasikan respons dan kode Python yang dihasilkan oleh FM saat memasukkan pertanyaan seperti “Beri tahu saya jumlah unik sensor untuk setiap situs yang masing-masing ditampilkan sebagai Peringatan atau Alarm?” (pertanyaan tingkat sulit) atau “Untuk sensor yang menunjukkan sinyal suhu TIDAK Sehat, dapatkah Anda menghitung durasi waktu dalam hari untuk setiap sensor yang menunjukkan sinyal getaran tidak normal?” (pertanyaan tingkat tantangan). Aplikasi ini akan menjawab pertanyaan Anda, dan juga akan menampilkan skrip Python dari analisis data yang dilakukan untuk menghasilkan hasil tersebut.


Jika Anda puas dengan jawabannya, Anda dapat menandainya sebagai Bermanfaat, menyimpan kode Python yang dihasilkan NLQ dan Claude ke indeks OpenSearch Service.

Jelajahi kasus penggunaan 2
Untuk menjelajahi kasus penggunaan kedua, pilih Ringkasan Gambar yang Diambil tab di aplikasi Streamlit. Anda dapat mengunggah gambar aset industri Anda, dan aplikasi akan menghasilkan ringkasan 200 kata tentang spesifikasi teknis dan kondisi pengoperasian berdasarkan informasi gambar. Tangkapan layar berikut menunjukkan ringkasan yang dihasilkan dari gambar penggerak motor sabuk. Untuk menguji fitur ini, jika Anda kekurangan gambar yang cocok, Anda dapat menggunakan yang berikut ini contoh gambar.
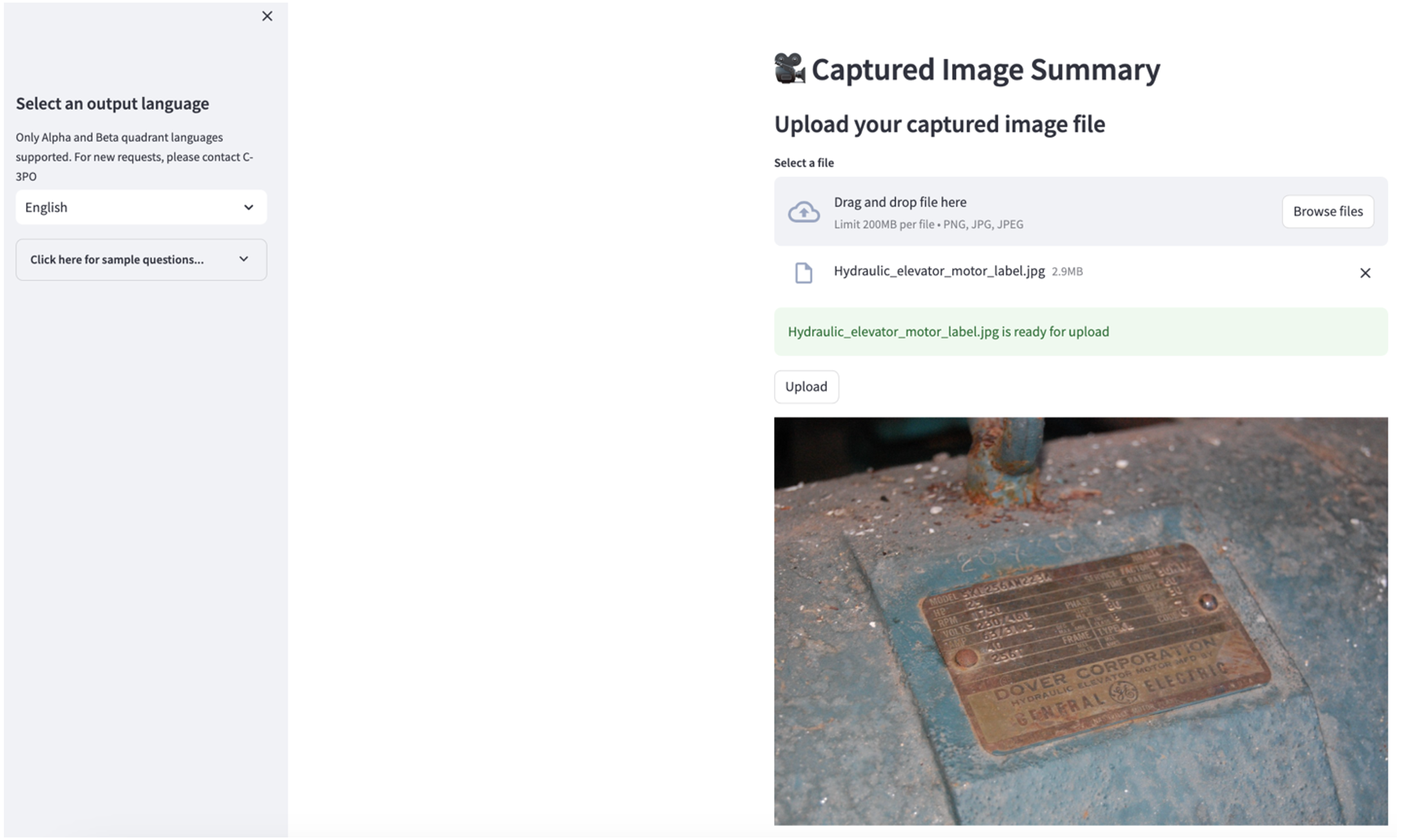
Label motor lift hidrolik” oleh Clarence Risher dilisensikan di bawah CC BY-SA 2.0.

Jelajahi kasus penggunaan 3
Untuk menjelajahi kasus penggunaan ketiga, pilih Diagnosis akar penyebab tab. Masukkan pertanyaan terkait dengan aset industri Anda yang rusak, seperti, “Aktuator saya berjalan lambat, apa masalahnya?” Seperti yang digambarkan dalam tangkapan layar berikut, aplikasi mengirimkan respons dengan kutipan dokumen sumber yang digunakan untuk menghasilkan jawabannya.
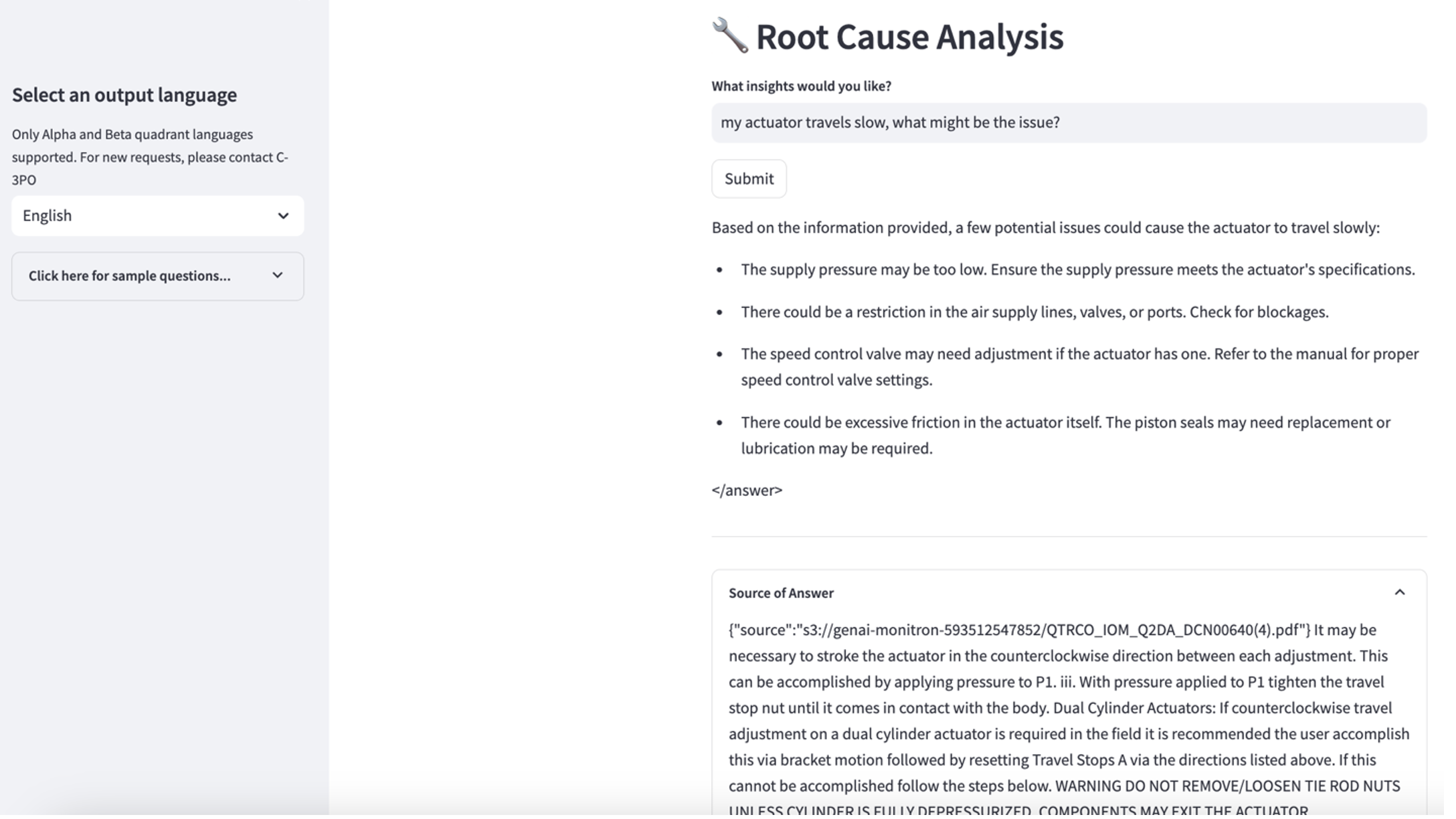
Kasus penggunaan 1: Detail desain
Pada bagian ini, kita membahas detail desain alur kerja aplikasi untuk use case pertama.
Bangunan cepat khusus
Kueri bahasa alami pengguna hadir dengan tingkat kesulitan yang berbeda: mudah, sulit, dan tantangan.
Pertanyaan langsung dapat mencakup permintaan berikut:
- Pilih nilai unik
- Hitung jumlah totalnya
- Urutkan nilai
Untuk pertanyaan-pertanyaan ini, PandasAI dapat langsung berinteraksi dengan FM untuk menghasilkan skrip Python untuk diproses.
Pertanyaan sulit memerlukan operasi agregasi dasar atau analisis deret waktu, seperti berikut:
- Pilih nilai terlebih dahulu dan kelompokkan hasil secara hierarki
- Lakukan statistik setelah pemilihan rekaman awal
- Jumlah stempel waktu (misalnya, min dan maks)
Untuk pertanyaan sulit, templat cepat dengan petunjuk langkah demi langkah yang terperinci membantu FM dalam memberikan tanggapan yang akurat.
Pertanyaan tingkat tantangan memerlukan penghitungan matematika tingkat lanjut dan pemrosesan deret waktu, seperti berikut:
- Hitung durasi anomali untuk setiap sensor
- Hitung sensor anomali untuk situs setiap bulan
- Bandingkan pembacaan sensor dalam pengoperasian normal dan kondisi abnormal
Untuk pertanyaan ini, Anda dapat menggunakan multi-shot dalam perintah khusus untuk meningkatkan akurasi respons. Multi-shot tersebut menunjukkan contoh pemrosesan deret waktu tingkat lanjut dan perhitungan matematika, dan akan memberikan konteks bagi FM untuk melakukan inferensi yang relevan pada analisis serupa. Memasukkan contoh paling relevan dari bank soal NLQ ke dalam prompt secara dinamis dapat menjadi sebuah tantangan. Salah satu solusinya adalah dengan membuat penyematan dari sampel pertanyaan NLQ yang ada dan menyimpan penyematan ini di penyimpanan vektor seperti OpenSearch Service. Saat pertanyaan dikirim ke aplikasi Streamlit, pertanyaan tersebut akan divektorkan Penanaman Batuan Dasar. N penyematan paling relevan teratas dengan pertanyaan itu diambil menggunakan opensearch_vector_search.similarity_search dan dimasukkan ke dalam template prompt sebagai prompt multi-shot.
Diagram berikut menggambarkan alur kerja ini.
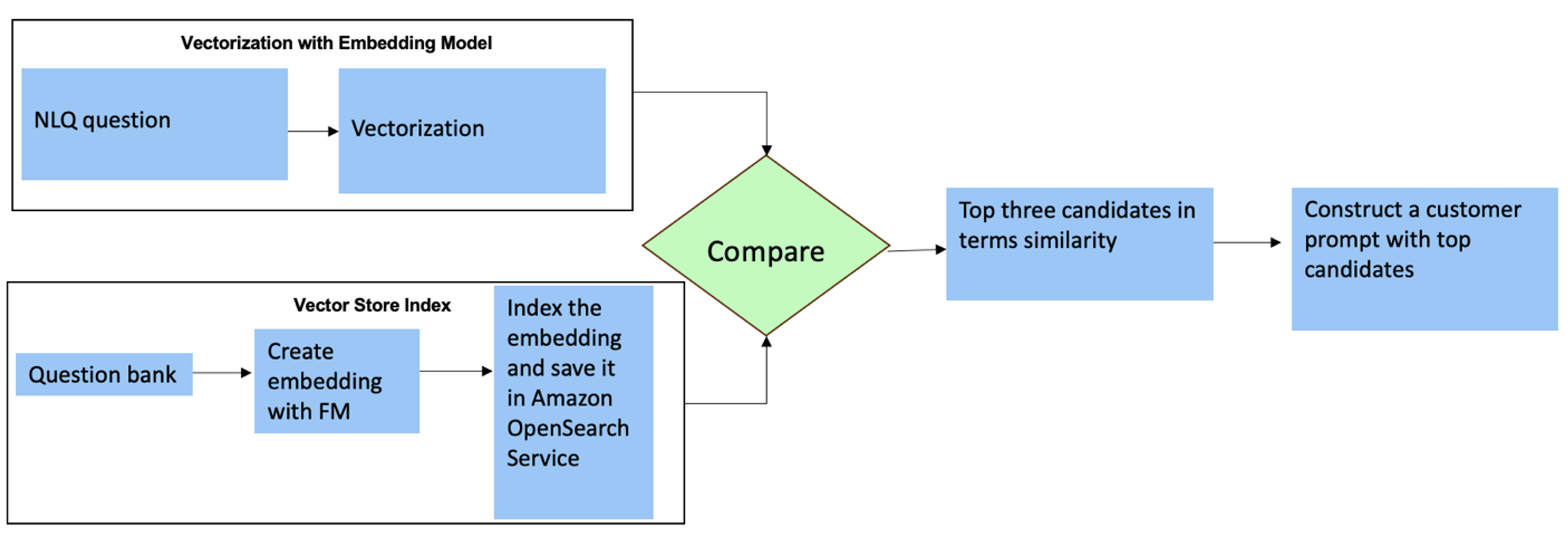
Lapisan penyematan dibuat menggunakan tiga alat utama:
- Model penyematan – Kami menggunakan Amazon Titan Embeddings yang tersedia melalui Amazon Bedrock (amazon.titan-sematkan-teks-v1) untuk menghasilkan representasi numerik dari dokumen tekstual.
- Toko vektor – Untuk penyimpanan vektor kami, kami menggunakan Layanan OpenSearch melalui kerangka LangChain, menyederhanakan penyimpanan embeddings yang dihasilkan dari contoh NLQ di notebook ini.
- Indeks – Indeks OpenSearch Service memainkan peran penting dalam membandingkan penyematan masukan dengan penyematan dokumen dan memfasilitasi pengambilan dokumen yang relevan. Karena kode contoh Python disimpan sebagai file JSON, kode tersebut diindeks di OpenSearch Service sebagai vektor melalui OpenSearchVevtorSearch.dariteks Panggilan API.
Pengumpulan berkelanjutan dari contoh yang diaudit manusia melalui Streamlit
Pada awal pengembangan aplikasi, kami memulai dengan hanya 23 contoh tersimpan di indeks OpenSearch Service sebagai penyematan. Saat aplikasi ditayangkan di lapangan, pengguna mulai memasukkan NLQ mereka melalui aplikasi. Namun, karena terbatasnya contoh yang tersedia di templat, beberapa NLQ mungkin tidak menemukan petunjuk serupa. Untuk terus memperkaya penyematan ini dan menawarkan perintah pengguna yang lebih relevan, Anda dapat menggunakan aplikasi Streamlit untuk mengumpulkan contoh yang telah diaudit oleh manusia.
Di dalam aplikasi, fungsi berikut melayani tujuan ini. Ketika pengguna akhir merasa hasilnya bermanfaat dan pilih Bermanfaat, aplikasi mengikuti langkah-langkah berikut:
- Gunakan metode panggilan balik dari PandasAI untuk mengumpulkan skrip Python.
- Format ulang skrip Python, masukkan pertanyaan, dan metadata CSV ke dalam string.
- Periksa apakah contoh NLQ ini sudah ada di indeks Layanan OpenSearch saat ini menggunakan opensearch_vector_search.similarity_search_with_score.
- Jika tidak ada contoh serupa, NLQ ini ditambahkan ke indeks OpenSearch Service menggunakan opensearch_vector_search.add_texts.
Jika pengguna memilih Tidak membantu, tidak ada tindakan yang diambil. Proses berulang ini memastikan bahwa sistem terus meningkat dengan memasukkan contoh-contoh kontribusi pengguna.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
Dengan menggabungkan audit manusia, jumlah contoh di Layanan OpenSearch yang tersedia untuk penyematan cepat bertambah seiring dengan semakin banyaknya penggunaan aplikasi. Kumpulan data penyematan yang diperluas ini menghasilkan peningkatan akurasi penelusuran dari waktu ke waktu. Khususnya, untuk NLQ yang menantang, akurasi respons FM mencapai sekitar 90% ketika secara dinamis memasukkan contoh serupa untuk membuat perintah khusus untuk setiap pertanyaan NLQ. Ini mewakili peningkatan yang signifikan sebesar 28% dibandingkan dengan skenario tanpa perintah multi-shot.
Kasus penggunaan 2: Detail desain
Di aplikasi Streamlit Ringkasan Gambar yang Diambil tab, Anda dapat langsung mengunggah file gambar. Ini memulai Amazon Rekognition API (deteksi_teks API), mengekstraksi teks dari label gambar yang merinci spesifikasi mesin. Selanjutnya, data teks yang diekstrak dikirim ke model Amazon Bedrock Claude sebagai konteks prompt, menghasilkan ringkasan 200 kata.
Dari perspektif pengalaman pengguna, mengaktifkan fungsi streaming untuk tugas peringkasan teks adalah hal yang terpenting, memungkinkan pengguna membaca ringkasan yang dihasilkan FM dalam potongan yang lebih kecil daripada menunggu keseluruhan keluaran. Amazon Bedrock memfasilitasi streaming melalui API-nya (bedrock_runtime.invoke_model_with_response_stream).
Kasus penggunaan 3: Detail desain
Dalam skenario ini, kami telah mengembangkan aplikasi chatbot yang berfokus pada analisis akar permasalahan, menggunakan pendekatan RAG. Chatbot ini diambil dari beberapa dokumen terkait peralatan bearing untuk memfasilitasi analisis akar masalah. Chatbot analisis akar masalah berbasis RAG ini menggunakan basis pengetahuan untuk menghasilkan representasi teks vektor, atau penyematan. Basis Pengetahuan untuk Amazon Bedrock adalah kemampuan terkelola sepenuhnya yang membantu Anda mengimplementasikan seluruh alur kerja RAG, mulai dari penyerapan hingga pengambilan dan augmentasi cepat, tanpa harus membangun integrasi khusus ke sumber data atau mengelola aliran data dan detail implementasi RAG.
Jika Anda puas dengan respons basis pengetahuan dari Amazon Bedrock, Anda dapat mengintegrasikan respons akar permasalahan dari basis pengetahuan ke aplikasi Streamlit.
Membersihkan
Untuk menghemat biaya, hapus sumber daya yang Anda buat di postingan ini:
- Hapus basis pengetahuan dari Amazon Bedrock.
- Hapus indeks Layanan OpenSearch.
- Hapus tumpukan CloudFormation genai-sagemaker.
- Hentikan instans EC2 jika Anda menggunakan instans EC2 untuk menjalankan aplikasi Streamlit.
Kesimpulan
Penerapan AI generatif telah mengubah berbagai proses bisnis, meningkatkan produktivitas dan keahlian pekerja. Namun, keterbatasan FM dalam menangani analisis data deret waktu telah menghambat pemanfaatan penuhnya oleh klien industri. Kendala ini menghambat penerapan AI generatif pada tipe data dominan yang diproses setiap hari.
Dalam postingan ini, kami memperkenalkan solusi Aplikasi AI generatif yang dirancang untuk mengatasi tantangan ini bagi pengguna industri. Aplikasi ini menggunakan agen open source, PandasAI, untuk memperkuat kemampuan analisis deret waktu FM. Daripada mengirimkan data deret waktu langsung ke FM, aplikasi ini menggunakan PandasAI untuk menghasilkan kode Python untuk analisis data deret waktu tidak terstruktur. Untuk meningkatkan akurasi pembuatan kode Python, alur kerja pembuatan cepat kustom dengan audit manusia telah diterapkan.
Diberdayakan dengan wawasan mengenai kesehatan aset mereka, pekerja industri dapat sepenuhnya memanfaatkan potensi AI generatif di berbagai kasus penggunaan, termasuk diagnosis akar masalah dan perencanaan penggantian komponen. Dengan Basis Pengetahuan untuk Amazon Bedrock, solusi RAG mudah dibangun dan dikelola oleh pengembang.
Perkembangan manajemen dan operasional data perusahaan jelas sedang bergerak menuju integrasi yang lebih mendalam dengan AI generatif untuk mendapatkan wawasan komprehensif mengenai kesehatan operasional. Pergeseran ini, yang dipelopori oleh Amazon Bedrock, diperkuat secara signifikan oleh semakin kuatnya dan potensi LLM sejenisnya Batuan Dasar Amazon Claude 3 untuk lebih meningkatkan solusi. Untuk mempelajari lebih lanjut, kunjungi berkonsultasi dengan Dokumentasi Amazon Batuan Dasar, dan langsung mempelajarinya Lokakarya Batuan Dasar Amazon.
Tentang penulis
 Julia Hu adalah Sr. Arsitek Solusi AI/ML di Amazon Web Services. Dia berspesialisasi dalam AI Generatif, Ilmu Data Terapan, dan arsitektur IoT. Saat ini dia adalah bagian dari tim Amazon Q, dan anggota/mentor aktif di Komunitas Bidang Teknis Machine Learning. Dia bekerja dengan pelanggan, mulai dari perusahaan rintisan hingga perusahaan, untuk mengembangkan solusi AI generatif yang luar biasa. Dia sangat tertarik memanfaatkan Model Bahasa Besar untuk analisis data tingkat lanjut dan mengeksplorasi aplikasi praktis yang mengatasi tantangan dunia nyata.
Julia Hu adalah Sr. Arsitek Solusi AI/ML di Amazon Web Services. Dia berspesialisasi dalam AI Generatif, Ilmu Data Terapan, dan arsitektur IoT. Saat ini dia adalah bagian dari tim Amazon Q, dan anggota/mentor aktif di Komunitas Bidang Teknis Machine Learning. Dia bekerja dengan pelanggan, mulai dari perusahaan rintisan hingga perusahaan, untuk mengembangkan solusi AI generatif yang luar biasa. Dia sangat tertarik memanfaatkan Model Bahasa Besar untuk analisis data tingkat lanjut dan mengeksplorasi aplikasi praktis yang mengatasi tantangan dunia nyata.
 Sudeesh Sasidharan adalah Arsitek Solusi Senior di AWS, dalam tim Energi. Sudeesh suka bereksperimen dengan teknologi baru dan membangun solusi inovatif yang memecahkan tantangan bisnis yang kompleks. Saat dia tidak sedang merancang solusi atau mengutak-atik teknologi terkini, Anda dapat menemukannya di lapangan tenis sedang mengerjakan pukulan backhandnya.
Sudeesh Sasidharan adalah Arsitek Solusi Senior di AWS, dalam tim Energi. Sudeesh suka bereksperimen dengan teknologi baru dan membangun solusi inovatif yang memecahkan tantangan bisnis yang kompleks. Saat dia tidak sedang merancang solusi atau mengutak-atik teknologi terkini, Anda dapat menemukannya di lapangan tenis sedang mengerjakan pukulan backhandnya.
 Neil Desai adalah seorang eksekutif teknologi dengan pengalaman lebih dari 20 tahun di bidang kecerdasan buatan (AI), ilmu data, rekayasa perangkat lunak, dan arsitektur perusahaan. Di AWS, dia memimpin tim arsitek solusi spesialis layanan AI di seluruh dunia yang membantu pelanggan membangun solusi inovatif yang didukung AI Generatif, berbagi praktik terbaik dengan pelanggan, dan mendorong peta jalan produk. Dalam jabatan sebelumnya di Vestas, Honeywell, dan Quest Diagnostics, Neil pernah memegang peran kepemimpinan dalam mengembangkan dan meluncurkan produk dan layanan inovatif yang telah membantu perusahaan meningkatkan operasi mereka, mengurangi biaya, dan meningkatkan pendapatan. Ia bersemangat menggunakan teknologi untuk memecahkan permasalahan dunia nyata dan merupakan seorang pemikir strategis dengan rekam jejak kesuksesan yang terbukti.
Neil Desai adalah seorang eksekutif teknologi dengan pengalaman lebih dari 20 tahun di bidang kecerdasan buatan (AI), ilmu data, rekayasa perangkat lunak, dan arsitektur perusahaan. Di AWS, dia memimpin tim arsitek solusi spesialis layanan AI di seluruh dunia yang membantu pelanggan membangun solusi inovatif yang didukung AI Generatif, berbagi praktik terbaik dengan pelanggan, dan mendorong peta jalan produk. Dalam jabatan sebelumnya di Vestas, Honeywell, dan Quest Diagnostics, Neil pernah memegang peran kepemimpinan dalam mengembangkan dan meluncurkan produk dan layanan inovatif yang telah membantu perusahaan meningkatkan operasi mereka, mengurangi biaya, dan meningkatkan pendapatan. Ia bersemangat menggunakan teknologi untuk memecahkan permasalahan dunia nyata dan merupakan seorang pemikir strategis dengan rekam jejak kesuksesan yang terbukti.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

