Membuat pipeline machine learning (ML) yang kuat dan dapat digunakan kembali bisa menjadi proses yang rumit dan memakan waktu. Pengembang biasanya menguji skrip pemrosesan dan pelatihan mereka secara lokal, tetapi pipeline itu sendiri biasanya diuji di cloud. Membuat dan menjalankan pipeline penuh selama eksperimen menambahkan overhead dan biaya yang tidak diinginkan ke siklus hidup pengembangan. Dalam posting ini, kami merinci bagaimana Anda dapat menggunakan Mode lokal Amazon SageMaker Pipelines untuk menjalankan pipeline ML secara lokal guna mengurangi pengembangan pipeline dan waktu pengoperasian sekaligus mengurangi biaya. Setelah pipa telah sepenuhnya diuji secara lokal, Anda dapat dengan mudah menjalankannya kembali dengan Amazon SageMaker sumber daya yang dikelola hanya dengan beberapa baris perubahan kode.
Ikhtisar siklus hidup ML
Salah satu pendorong utama inovasi dan aplikasi baru di ML adalah ketersediaan dan jumlah data serta opsi komputasi yang lebih murah. Di beberapa domain, ML telah terbukti mampu memecahkan masalah yang sebelumnya tidak dapat dipecahkan dengan data besar klasik dan teknik analisis, dan permintaan akan ilmu data dan praktisi ML terus meningkat. Dari tingkat yang sangat tinggi, siklus hidup ML terdiri dari banyak bagian yang berbeda, tetapi pembangunan model ML biasanya terdiri dari langkah-langkah umum berikut:
- Pembersihan dan persiapan data (rekayasa fitur)
- Pelatihan dan penyetelan model
- Evaluasi model
- Penerapan model (atau transformasi batch)
Pada langkah persiapan data, data dimuat, dipilah, dan diubah menjadi jenis input, atau fitur, yang diharapkan oleh model ML. Menulis skrip untuk mengubah data biasanya merupakan proses berulang, di mana putaran umpan balik yang cepat penting untuk mempercepat pengembangan. Biasanya tidak perlu menggunakan kumpulan data lengkap saat menguji skrip rekayasa fitur, itulah sebabnya Anda dapat menggunakan fitur mode lokal dari Pemrosesan SageMaker. Ini memungkinkan Anda untuk menjalankan secara lokal dan memperbarui kode secara iteratif, menggunakan kumpulan data yang lebih kecil. Saat kode akhir sudah siap, kode tersebut dikirimkan ke pekerjaan pemrosesan jarak jauh, yang menggunakan set data lengkap dan berjalan pada instans yang dikelola SageMaker.
Proses pengembangan mirip dengan langkah persiapan data untuk pelatihan model dan langkah evaluasi model. Ilmuwan data menggunakan fitur mode lokal Pelatihan SageMaker untuk melakukan iterasi dengan cepat dengan set data yang lebih kecil secara lokal, sebelum menggunakan semua data dalam kluster instans yang dioptimalkan ML yang dikelola SageMaker. Ini mempercepat proses pengembangan dan menghilangkan biaya menjalankan instans ML yang dikelola oleh SageMaker saat bereksperimen.
Saat kematangan ML organisasi meningkat, Anda dapat menggunakan Pipa Amazon SageMaker untuk membuat pipeline ML yang menggabungkan langkah-langkah ini, membuat alur kerja ML yang lebih kompleks yang memproses, melatih, dan mengevaluasi model ML. SageMaker Pipelines adalah layanan terkelola sepenuhnya untuk mengotomatiskan berbagai langkah alur kerja ML, termasuk pemuatan data, transformasi data, pelatihan dan penyetelan model, serta penerapan model. Sampai saat ini, Anda dapat mengembangkan dan menguji skrip Anda secara lokal tetapi harus menguji pipeline ML Anda di cloud. Hal ini membuat iterasi pada aliran dan bentuk pipeline ML menjadi proses yang lambat dan mahal. Sekarang, dengan fitur mode lokal tambahan dari SageMaker Pipelines, Anda dapat mengulangi dan menguji saluran pipa ML Anda dengan cara yang sama seperti Anda menguji dan mengulangi skrip pemrosesan dan pelatihan Anda. Anda dapat menjalankan dan menguji pipeline di mesin lokal, menggunakan sebagian kecil data untuk memvalidasi sintaks dan fungsionalitas pipeline.
Pipa SageMaker
SageMaker Pipelines menyediakan cara yang sepenuhnya otomatis untuk menjalankan alur kerja ML yang sederhana atau kompleks. Dengan SageMaker Pipelines, Anda dapat membuat alur kerja ML dengan Python SDK yang mudah digunakan, lalu memvisualisasikan dan mengelola alur kerja Anda menggunakan Studio Amazon SageMaker. Tim ilmu data Anda dapat menjadi lebih efisien dan menskalakan lebih cepat dengan menyimpan dan menggunakan kembali langkah-langkah alur kerja yang Anda buat di SageMaker Pipelines. Anda juga dapat menggunakan template bawaan yang mengotomatiskan pembuatan infrastruktur dan repositori untuk membangun, menguji, mendaftarkan, dan menerapkan model dalam lingkungan ML Anda. Template ini tersedia secara otomatis untuk organisasi Anda, dan disediakan menggunakan Katalog Layanan AWS produk.
SageMaker Pipelines menghadirkan praktik continuous integration dan continuous deployment (CI/CD) ke ML, seperti menjaga keseimbangan antara lingkungan pengembangan dan produksi, kontrol versi, pengujian sesuai permintaan, dan otomatisasi ujung ke ujung, yang membantu Anda menskalakan ML di seluruh organisasi. Praktisi DevOps tahu bahwa beberapa manfaat utama menggunakan teknik CI/CD mencakup peningkatan produktivitas melalui komponen yang dapat digunakan kembali dan peningkatan kualitas melalui pengujian otomatis, yang menghasilkan ROI yang lebih cepat untuk tujuan bisnis Anda. Manfaat ini sekarang tersedia untuk praktisi MLOps dengan menggunakan SageMaker Pipelines untuk mengotomatiskan pelatihan, pengujian, dan penerapan model ML. Dengan mode lokal, Anda sekarang dapat melakukan iterasi lebih cepat saat mengembangkan skrip untuk digunakan dalam pipeline. Perhatikan bahwa instance pipeline lokal tidak dapat dilihat atau dijalankan dalam Studio IDE; namun, opsi tampilan tambahan untuk pipeline lokal akan segera tersedia.
SDK SageMaker menyediakan tujuan umum konfigurasi mode lokal yang memungkinkan pengembang untuk menjalankan dan menguji prosesor dan estimator yang didukung di lingkungan lokal mereka. Anda dapat menggunakan pelatihan mode lokal dengan beberapa gambar kerangka kerja yang didukung AWS (TensorFlow, MXNet, Chainer, PyTorch, dan Scikit-Learn) serta gambar yang Anda berikan sendiri.
SageMaker Pipelines, yang membuat Directed Acyclic Graph (DAG) dari langkah-langkah alur kerja yang diatur, mendukung banyak aktivitas yang merupakan bagian dari siklus hidup ML. Dalam mode lokal, langkah-langkah berikut didukung:
- Memproses langkah-langkah pekerjaan – Pengalaman yang disederhanakan dan dikelola di SageMaker untuk menjalankan beban kerja pemrosesan data, seperti rekayasa fitur, validasi data, evaluasi model, dan interpretasi model
- Melatih langkah kerja – Proses berulang yang mengajarkan model untuk membuat prediksi dengan menyajikan contoh dari kumpulan data pelatihan
- Pekerjaan penyetelan hyperparameter – Cara otomatis untuk mengevaluasi dan memilih hyperparameter yang menghasilkan model paling akurat
- Langkah-langkah lari bersyarat – Langkah yang menyediakan cabang bersyarat dalam pipa
- Langkah model – Menggunakan argumen CreateModel, langkah ini dapat membuat model untuk digunakan dalam langkah transformasi atau penerapan selanjutnya sebagai titik akhir
- Transformasikan langkah-langkah pekerjaan – Pekerjaan transformasi batch yang menghasilkan prediksi dari kumpulan data besar, dan menjalankan inferensi saat titik akhir persisten tidak diperlukan
- Langkah gagal – Langkah yang menghentikan jalur pipa dan menandai proses sebagai gagal
Ikhtisar solusi
Solusi kami menunjukkan langkah-langkah penting untuk membuat dan menjalankan Pipeline SageMaker dalam mode lokal, yang berarti menggunakan sumber daya CPU, RAM, dan disk lokal untuk memuat dan menjalankan langkah-langkah alur kerja. Lingkungan lokal Anda dapat berjalan di laptop, menggunakan IDE populer seperti VSCode atau PyCharm, atau dapat dihosting oleh SageMaker menggunakan instans notebook klasik.
Mode lokal memungkinkan ilmuwan data untuk menggabungkan langkah-langkah, yang dapat mencakup pekerjaan pemrosesan, pelatihan, dan evaluasi, serta menjalankan seluruh alur kerja secara lokal. Setelah selesai menguji secara lokal, Anda dapat menjalankan kembali pipeline di lingkungan terkelola SageMaker dengan mengganti LocalPipelineSession objek dengan PipelineSession, yang membawa konsistensi ke siklus hidup ML.
Untuk contoh buku catatan ini, kami menggunakan kumpulan data standar yang tersedia untuk umum, the Kumpulan Data Abalon Pembelajaran Mesin UCI. Tujuannya melatih model ML untuk menentukan umur keong abalon dari ukuran fisiknya. Pada intinya, ini adalah masalah regresi.
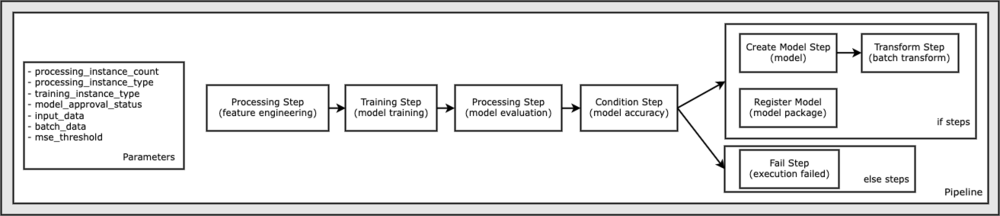
Semua kode yang diperlukan untuk menjalankan contoh notebook ini tersedia di GitHub di amazon-sagemaker-contoh gudang. Dalam contoh buku catatan ini, setiap langkah alur kerja pipeline dibuat secara independen dan kemudian dihubungkan bersama untuk membuat pipeline. Kami membuat langkah-langkah berikut:
- Langkah pemrosesan (rekayasa fitur)
- Langkah pelatihan (pelatihan model)
- Langkah pemrosesan (evaluasi model)
- Langkah kondisi (akurasi model)
- Buat langkah model (model)
- Langkah transformasi (transformasi batch)
- Daftarkan langkah model (paket model)
- Langkah gagal (jalankan gagal)
Diagram berikut mengilustrasikan jalur pipa kami.
Prasyarat
Untuk mengikuti dalam posting ini, Anda memerlukan yang berikut:
Setelah prasyarat ini diterapkan, Anda dapat menjalankan buku catatan contoh seperti yang dijelaskan di bagian berikut ini.
Bangun saluran pipa Anda
Dalam contoh buku catatan ini, kami menggunakan Mode Skrip SageMaker untuk sebagian besar proses ML, yang berarti bahwa kami menyediakan kode (skrip) Python yang sebenarnya untuk melakukan aktivitas dan meneruskan referensi ke kode ini. Mode Skrip memberikan fleksibilitas luar biasa untuk mengontrol perilaku dalam pemrosesan SageMaker dengan memungkinkan Anda menyesuaikan kode sambil tetap memanfaatkan wadah yang dibuat sebelumnya dari SageMaker seperti XGBoost atau Scikit-Learn. Kode khusus ditulis ke file skrip Python menggunakan sel yang dimulai dengan perintah ajaib %%writefile, seperti berikut ini:
%%writefile code/evaluation.py
Pengaktif utama mode lokal adalah LocalPipelineSession objek, yang dipakai dari Python SDK. Segmen kode berikut menunjukkan cara membuat saluran SageMaker dalam mode lokal. Meskipun Anda dapat mengonfigurasi jalur data lokal untuk banyak langkah pipeline lokal, Amazon S3 adalah lokasi default untuk menyimpan output data dengan transformasi. Yang baru LocalPipelineSession objek diteruskan ke Python SDK di banyak panggilan API alur kerja SageMaker yang dijelaskan dalam posting ini. Perhatikan bahwa Anda dapat menggunakan local_pipeline_session variabel untuk mengambil referensi ke bucket default S3 dan nama Region saat ini.
Sebelum kita membuat langkah-langkah pipa individu, kita menetapkan beberapa parameter yang digunakan oleh pipa. Beberapa parameter ini adalah literal string, sedangkan yang lain dibuat sebagai tipe enumerasi khusus yang disediakan oleh SDK. Pengetikan enumerasi memastikan bahwa pengaturan yang valid disediakan untuk pipa, seperti yang ini, yang diteruskan ke ConditionLessThanOrEqualTo melangkah lebih jauh ke bawah:
mse_threshold = ParameterFloat(name="MseThreshold", default_value=7.0)
Untuk membuat langkah pemrosesan data, yang digunakan di sini untuk melakukan rekayasa fitur, kami menggunakan SKLearnProcessor untuk memuat dan mengubah dataset. Kami melewati local_pipeline_session variabel ke konstruktor kelas, yang menginstruksikan langkah alur kerja untuk dijalankan dalam mode lokal:
Selanjutnya, kami membuat langkah pipa aktual pertama kami, a ProcessingStep objek, seperti yang diimpor dari SageMaker SDK. Argumen prosesor dikembalikan dari panggilan ke SKLearnProcessor jalankan() metode. Langkah alur kerja ini digabungkan dengan langkah-langkah lain menjelang akhir notebook untuk menunjukkan urutan operasi dalam alur.
Selanjutnya, kami menyediakan kode untuk menetapkan langkah pelatihan dengan terlebih dahulu membuat instance penaksir standar menggunakan SageMaker SDK. Kami melewati hal yang sama local_pipeline_session variabel ke estimator, bernama xgb_train, sebagai sagemaker_session argumen. Karena kita ingin melatih model XGBoost, kita harus menghasilkan URI gambar yang valid dengan menentukan parameter berikut, termasuk kerangka kerja dan beberapa parameter versi:
Kami secara opsional dapat memanggil metode estimator tambahan, misalnya set_hyperparameters(), untuk menyediakan pengaturan hyperparameter untuk tugas pelatihan. Sekarang setelah estimator dikonfigurasi, kami siap untuk membuat langkah pelatihan yang sebenarnya. Sekali lagi, kami mengimpor TrainingStep kelas dari perpustakaan SageMaker SDK:
Selanjutnya, kami membangun langkah pemrosesan lain untuk melakukan evaluasi model. Hal ini dilakukan dengan membuat ScriptProcessor contoh dan melewati local_pipeline_session objek sebagai parameter:
Untuk mengaktifkan penyebaran model terlatih, baik untuk a Titik akhir waktu nyata SageMaker atau untuk transformasi batch, kita perlu membuat Model objek dengan meneruskan artefak model, URI gambar yang tepat, dan secara opsional kode inferensi khusus kami. Kami kemudian melewati ini Model keberatan dengan ModelStep, yang ditambahkan ke pipa lokal. Lihat kode berikut:
Selanjutnya, kami membuat langkah transformasi batch di mana kami mengirimkan satu set vektor fitur dan melakukan inferensi. Pertama-tama kita perlu membuat Transformer objek dan lulus local_pipeline_session parameter untuk itu. Kemudian kita buat TransformStep, meneruskan argumen yang diperlukan, dan menambahkan ini ke definisi pipeline:
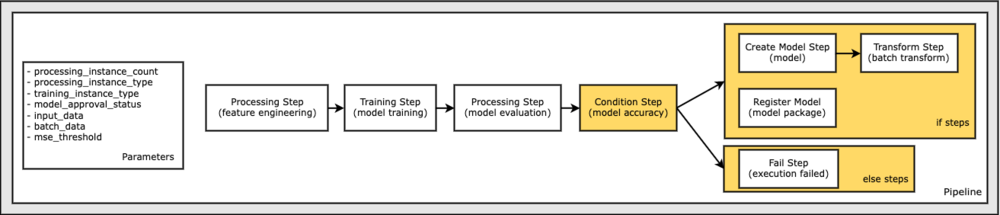
Terakhir, kami ingin menambahkan kondisi cabang ke alur kerja sehingga kami hanya menjalankan transformasi batch jika hasil evaluasi model memenuhi kriteria kami. Kita dapat menunjukkan kondisi ini dengan menambahkan a ConditionStep dengan tipe kondisi tertentu, seperti ConditionLessThanOrEqualTo. Kami kemudian menghitung langkah-langkah untuk dua cabang, pada dasarnya mendefinisikan cabang if/else atau true/false dari pipa. if_steps disediakan di ConditionStep (langkah_buat_model, langkah_transformasi) dijalankan setiap kali kondisi dievaluasi ke True.
Diagram berikut mengilustrasikan cabang bersyarat ini dan langkah-langkah if/else terkait. Hanya satu cabang yang dijalankan, berdasarkan hasil dari langkah evaluasi model dibandingkan dengan langkah kondisi.
Sekarang setelah kita memiliki semua langkah yang ditentukan, dan instance kelas yang mendasarinya dibuat, kita dapat menggabungkannya ke dalam sebuah pipeline. Kami menyediakan beberapa parameter, dan menentukan urutan operasi hanya dengan mendaftar langkah-langkah dalam urutan yang diinginkan. Perhatikan bahwa TransformStep tidak ditampilkan di sini karena ini adalah target dari langkah bersyarat, dan diberikan sebagai argumen langkah untuk ConditionalStep sebelumnya.
Untuk menjalankan pipeline, Anda harus memanggil dua metode: pipeline.upsert(), yang mengupload pipeline ke layanan yang mendasarinya, dan pipeline.start(), yang mulai menjalankan pipa. Anda dapat menggunakan berbagai metode lain untuk menginterogasi status proses, membuat daftar langkah-langkah pipeline, dan banyak lagi. Karena kami menggunakan sesi pipeline mode lokal, semua langkah ini dijalankan secara lokal di prosesor Anda. Output sel di bawah metode mulai menunjukkan output dari pipa:
Anda akan melihat pesan di bagian bawah output sel yang mirip dengan berikut ini:
Pipeline execution d8c3e172-089e-4e7a-ad6d-6d76caf987b7 SUCCEEDED
Kembali ke sumber daya yang dikelola
Setelah kami mengonfirmasi bahwa pipeline berjalan tanpa kesalahan dan kami puas dengan aliran dan bentuk pipeline, kami dapat membuat ulang pipeline tetapi dengan sumber daya yang dikelola SageMaker dan menjalankannya kembali. Satu-satunya perubahan yang diperlukan adalah menggunakan PipelineSession objek bukannya LocalPipelineSession:
dari sagemaker.workflow.pipeline_context impor LocalPipelineSessionfrom sagemaker.workflow.pipeline_context import PipelineSession
local_pipeline_session = LocalPipelineSession()pipeline_session = PipelineSession()
Ini menginformasikan layanan untuk menjalankan setiap langkah yang mereferensikan objek sesi ini pada sumber daya yang dikelola SageMaker. Mengingat perubahan kecil, kami hanya menggambarkan perubahan kode yang diperlukan dalam sel kode berikut, tetapi perubahan yang sama perlu diterapkan pada setiap sel menggunakan local_pipeline_session obyek. Namun, perubahannya identik di semua sel karena kami hanya mengganti local_pipeline_session keberatan dengan pipeline_session obyek.
Setelah objek sesi lokal diganti di mana-mana, kami membuat ulang pipeline dan menjalankannya dengan sumber daya yang dikelola SageMaker:
Membersihkan
Jika Anda ingin menjaga lingkungan Studio tetap rapi, Anda dapat menggunakan metode berikut untuk menghapus pipeline SageMaker dan modelnya. Kode lengkap dapat ditemukan di sampel buku catatan.
Kesimpulan
Sampai saat ini, Anda dapat menggunakan fitur mode lokal Pemrosesan SageMaker dan Pelatihan SageMaker untuk beralih pada skrip pemrosesan dan pelatihan Anda secara lokal, sebelum menjalankannya pada semua data dengan sumber daya yang dikelola SageMaker. Dengan fitur mode lokal baru dari SageMaker Pipelines, praktisi ML sekarang dapat menerapkan metode yang sama saat melakukan iterasi pada pipeline ML mereka, menggabungkan alur kerja ML yang berbeda menjadi satu. Saat pipeline siap untuk produksi, menjalankannya dengan sumber daya terkelola SageMaker hanya memerlukan beberapa baris perubahan kode. Hal ini mengurangi waktu pengoperasian pipeline selama pengembangan, yang mengarah ke pengembangan pipeline yang lebih cepat dengan siklus pengembangan yang lebih cepat, sekaligus mengurangi biaya sumber daya yang dikelola SageMaker.
Untuk mempelajari lebih lanjut, kunjungi Pipa Amazon SageMaker or Gunakan Pipeline SageMaker untuk Menjalankan Pekerjaan Anda Secara Lokal.
Tentang penulis
 Paul Hargis telah memfokuskan upayanya pada pembelajaran mesin di beberapa perusahaan, termasuk AWS, Amazon, dan Hortonworks. Dia senang membangun solusi teknologi dan mengajari orang cara memanfaatkannya sebaik mungkin. Sebelum perannya di AWS, dia adalah arsitek utama untuk Ekspor dan Ekspansi Amazon, membantu amazon.com meningkatkan pengalaman bagi pembeli internasional. Paul suka membantu pelanggan memperluas inisiatif pembelajaran mesin mereka untuk memecahkan masalah dunia nyata.
Paul Hargis telah memfokuskan upayanya pada pembelajaran mesin di beberapa perusahaan, termasuk AWS, Amazon, dan Hortonworks. Dia senang membangun solusi teknologi dan mengajari orang cara memanfaatkannya sebaik mungkin. Sebelum perannya di AWS, dia adalah arsitek utama untuk Ekspor dan Ekspansi Amazon, membantu amazon.com meningkatkan pengalaman bagi pembeli internasional. Paul suka membantu pelanggan memperluas inisiatif pembelajaran mesin mereka untuk memecahkan masalah dunia nyata.
 Niklas Palm adalah Arsitek Solusi di AWS di Stockholm, Swedia, tempat dia membantu pelanggan di seluruh Nordik untuk berhasil di cloud. Dia sangat bersemangat tentang teknologi tanpa server bersama dengan IoT dan pembelajaran mesin. Di luar pekerjaan, Niklas adalah pemain ski dan snowboard lintas alam yang rajin serta ahli memasak telur.
Niklas Palm adalah Arsitek Solusi di AWS di Stockholm, Swedia, tempat dia membantu pelanggan di seluruh Nordik untuk berhasil di cloud. Dia sangat bersemangat tentang teknologi tanpa server bersama dengan IoT dan pembelajaran mesin. Di luar pekerjaan, Niklas adalah pemain ski dan snowboard lintas alam yang rajin serta ahli memasak telur.
 Kirit Tadaka adalah Arsitek Solusi ML yang bekerja di tim SA Layanan SageMaker. Sebelum bergabung dengan AWS, Kirit bekerja di startup AI tahap awal diikuti dengan konsultasi beberapa kali dalam berbagai peran dalam penelitian AI, MLOps, dan kepemimpinan teknis.
Kirit Tadaka adalah Arsitek Solusi ML yang bekerja di tim SA Layanan SageMaker. Sebelum bergabung dengan AWS, Kirit bekerja di startup AI tahap awal diikuti dengan konsultasi beberapa kali dalam berbagai peran dalam penelitian AI, MLOps, dan kepemimpinan teknis.

