Studio Amazon SageMaker memberikan solusi terkelola sepenuhnya bagi ilmuwan data untuk membangun, melatih, dan menerapkan model pembelajaran mesin (ML) secara interaktif. Dalam proses mengerjakan tugas ML-nya, data scientist biasanya memulai alur kerjanya dengan menemukan sumber data yang relevan dan menghubungkannya. Mereka kemudian menggunakan SQL untuk mengeksplorasi, menganalisis, memvisualisasikan, dan mengintegrasikan data dari berbagai sumber sebelum menggunakannya dalam pelatihan dan inferensi ML mereka. Sebelumnya, data scientist sering kali harus menggunakan berbagai alat untuk mendukung SQL dalam alur kerja mereka, sehingga menghambat produktivitas.
Kami sangat gembira mengumumkan bahwa notebook JupyterLab di SageMaker Studio kini hadir dengan dukungan bawaan untuk SQL. Ilmuwan data sekarang dapat:
- Terhubung ke layanan data populer termasuk Amazon Athena, Pergeseran Merah Amazon, Zona Data Amazon, dan Snowflake langsung di dalam buku catatan
- Telusuri dan cari database, skema, tabel, dan tampilan, serta pratinjau data dalam antarmuka notebook
- Gabungkan kode SQL dan Python dalam buku catatan yang sama untuk eksplorasi dan transformasi data yang efisien untuk digunakan dalam proyek ML
- Gunakan fitur produktivitas pengembang seperti penyelesaian perintah SQL, bantuan pemformatan kode, dan penyorotan sintaksis untuk membantu mempercepat pengembangan kode dan meningkatkan produktivitas pengembang secara keseluruhan
Selain itu, administrator dapat mengelola koneksi ke layanan data ini dengan aman, memungkinkan data scientist mengakses data resmi tanpa perlu mengelola kredensial secara manual.
Dalam postingan ini, kami memandu Anda dalam menyiapkan fitur ini di SageMaker Studio, dan memandu Anda melalui berbagai kemampuan fitur ini. Lalu kami menunjukkan bagaimana Anda dapat meningkatkan pengalaman SQL dalam buku catatan menggunakan kemampuan Text-to-SQL yang disediakan oleh model bahasa besar (LLM) tingkat lanjut untuk menulis kueri SQL kompleks menggunakan teks bahasa alami sebagai masukan. Terakhir, untuk memungkinkan audiens pengguna yang lebih luas menghasilkan kueri SQL dari input bahasa alami di buku catatan mereka, kami menunjukkan kepada Anda cara menerapkan model Text-to-SQL ini menggunakan Amazon SageMaker titik akhir.
Ikhtisar solusi
Dengan integrasi SQL notebook SageMaker Studio JupyterLab, Anda kini dapat terhubung ke sumber data populer seperti Snowflake, Athena, Amazon Redshift, dan Amazon DataZone. Fitur baru ini memungkinkan Anda melakukan berbagai fungsi.
Misalnya, Anda dapat menjelajahi sumber data seperti database, tabel, dan skema secara visual langsung dari ekosistem JupyterLab Anda. Jika lingkungan notebook Anda berjalan pada SageMaker Distribution 1.6 atau lebih tinggi, cari widget baru di sisi kiri antarmuka JupyterLab Anda. Penambahan ini meningkatkan aksesibilitas dan pengelolaan data dalam lingkungan pengembangan Anda.
Jika saat ini Anda tidak menggunakan Distribusi SageMaker yang disarankan (1.5 atau lebih rendah) atau dalam lingkungan kustom, lihat lampiran untuk informasi lebih lanjut.
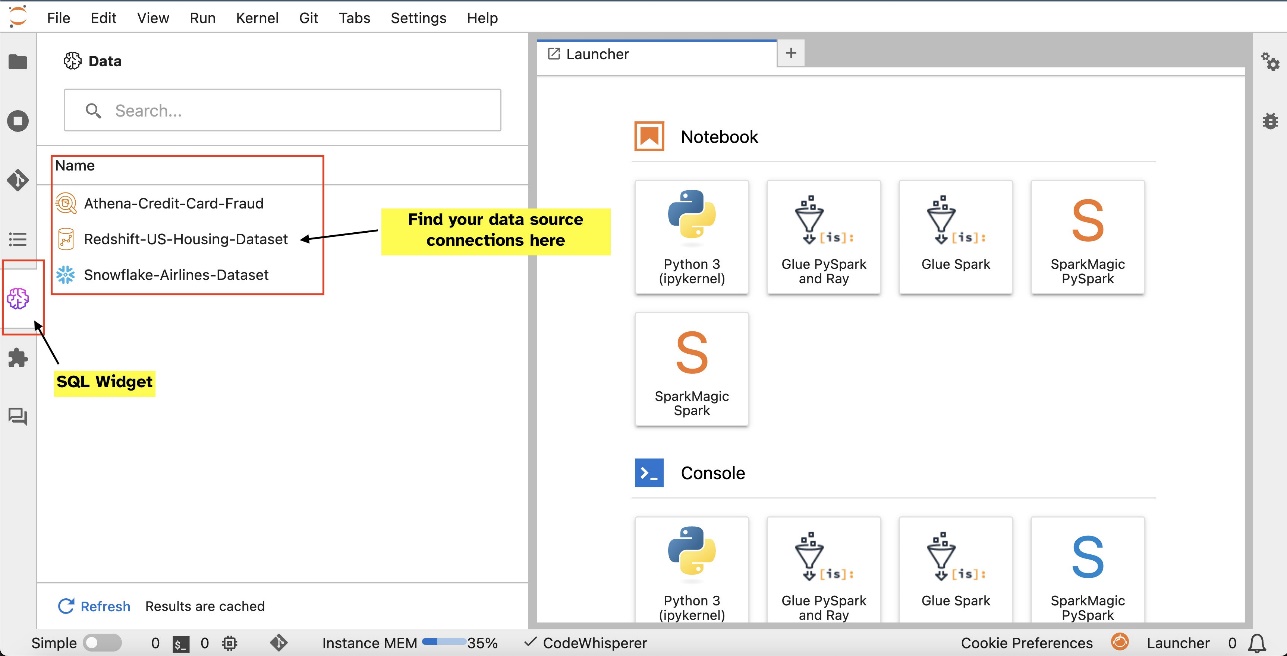
Setelah Anda menyiapkan koneksi (diilustrasikan di bagian berikutnya), Anda bisa membuat daftar koneksi data, menelusuri database dan tabel, dan memeriksa skema.
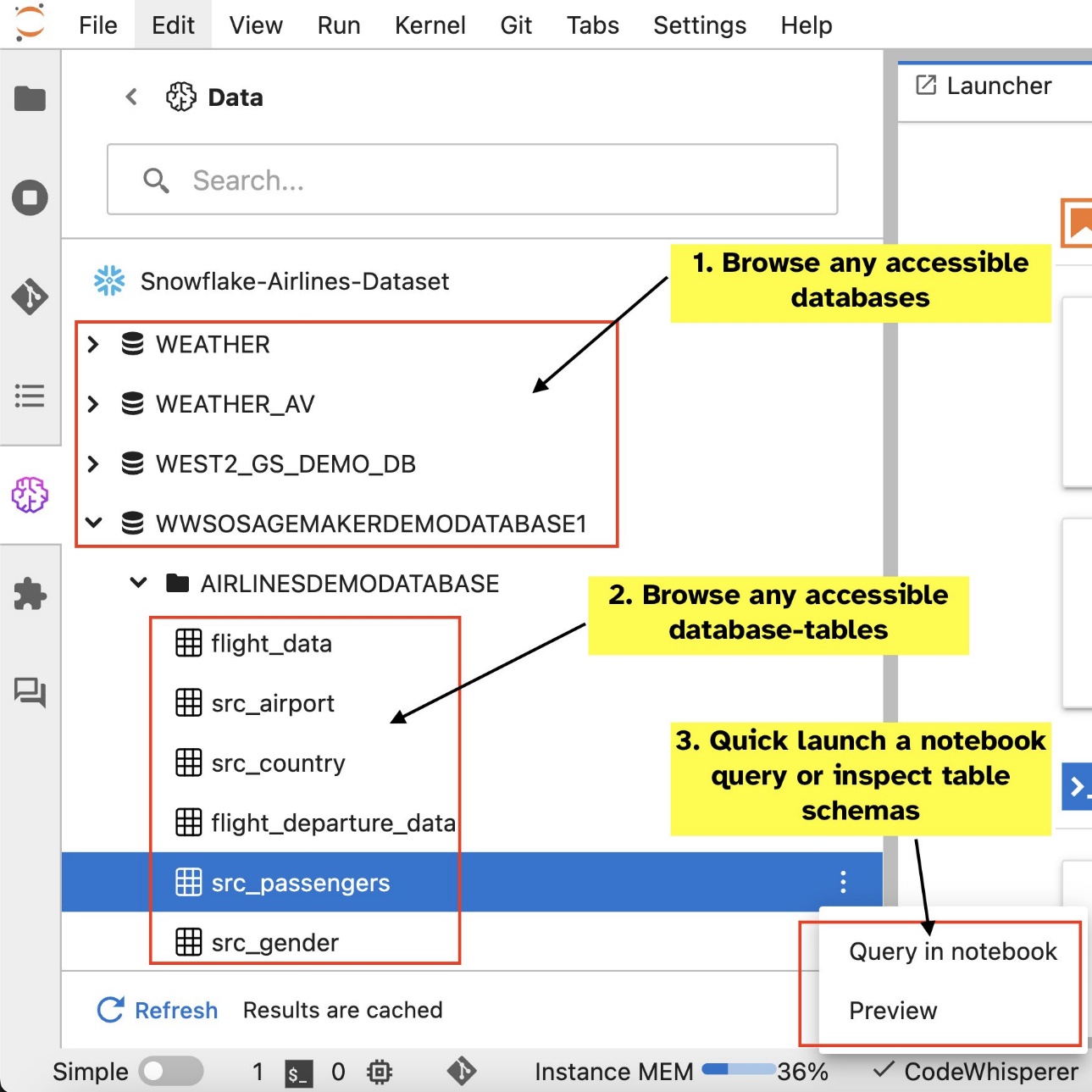
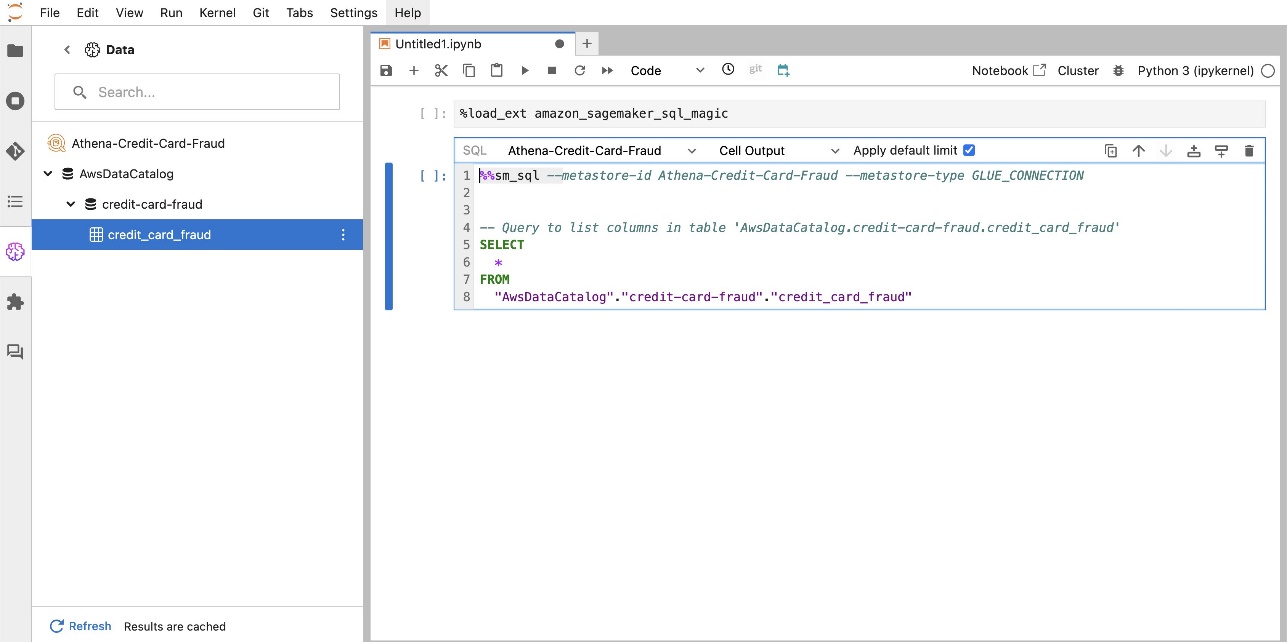
Ekstensi SQL bawaan SageMaker Studio JupyterLab juga memungkinkan Anda menjalankan kueri SQL langsung dari buku catatan. Notebook Jupyter dapat membedakan antara kode SQL dan Python menggunakan %%sm_sql perintah ajaib, yang harus ditempatkan di bagian atas sel mana pun yang berisi kode SQL. Perintah ini memberi sinyal kepada JupyterLab bahwa instruksi berikut adalah perintah SQL, bukan kode Python. Output kueri dapat ditampilkan langsung di dalam buku catatan, memfasilitasi integrasi alur kerja SQL dan Python yang lancar dalam analisis data Anda.
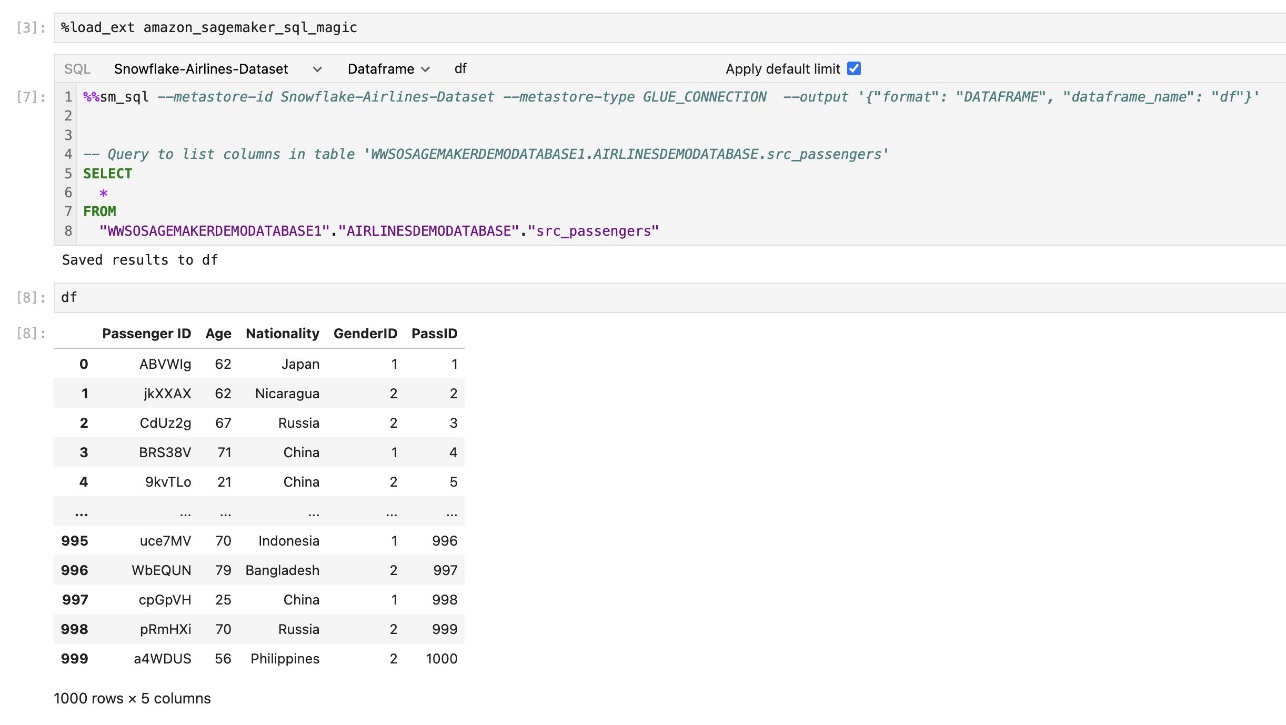
Output kueri dapat ditampilkan secara visual sebagai tabel HTML, seperti yang ditunjukkan pada gambar layar berikut.

Mereka juga dapat ditulis ke a panda DataFrame.
Prasyarat
Pastikan Anda telah memenuhi prasyarat berikut untuk menggunakan pengalaman SQL notebook SageMaker Studio:
- SageMaker Studio V2 – Pastikan Anda menjalankan versi terbaru Domain SageMaker Studio dan profil pengguna. Jika saat ini Anda menggunakan SageMaker Studio Classic, lihat Bermigrasi dari Amazon SageMaker Studio Classic.
- Peran IAM – SageMaker memerlukan Identitas AWS dan Manajemen Akses (IAM) peran yang akan ditetapkan ke domain SageMaker Studio atau profil pengguna untuk mengelola izin secara efektif. Pembaruan peran eksekusi mungkin diperlukan untuk menghadirkan penelusuran data dan fitur eksekusi SQL. Contoh kebijakan berikut memungkinkan pengguna untuk memberikan, mencantumkan, dan menjalankan Lem AWS, Athena, Layanan Penyimpanan Sederhana Amazon (Amazon S3), Manajer Rahasia AWS, dan sumber daya Amazon Redshift:
- Ruang JupyterLab – Anda memerlukan akses ke SageMaker Studio dan JupyterLab Space yang diperbarui Distribusi SageMaker v1.6 atau versi gambar yang lebih baru. Jika Anda menggunakan gambar khusus untuk JupyterLab Spaces atau versi SageMaker Distribution yang lebih lama (v1.5 atau lebih rendah), lihat lampiran untuk petunjuk menginstal paket dan modul yang diperlukan untuk mengaktifkan fitur ini di lingkungan Anda. Untuk mempelajari lebih lanjut tentang SageMaker Studio JupyterLab Spaces, lihat Tingkatkan produktivitas di Amazon SageMaker Studio: Memperkenalkan JupyterLab Spaces dan alat AI generatif.
- Kredensial akses sumber data – Fitur notebook SageMaker Studio ini memerlukan akses nama pengguna dan kata sandi ke sumber data seperti Snowflake dan Amazon Redshift. Buat akses berbasis nama pengguna dan kata sandi ke sumber data ini jika Anda belum memilikinya. Akses berbasis OAuth ke Snowflake bukanlah fitur yang didukung pada tulisan ini.
- Muat keajaiban SQL – Sebelum Anda menjalankan kueri SQL dari sel notebook Jupyter, penting untuk memuat ekstensi sihir SQL. Gunakan perintah
%load_ext amazon_sagemaker_sql_magicuntuk mengaktifkan fitur ini. Selain itu, Anda dapat menjalankan%sm_sql?perintah untuk melihat daftar lengkap opsi yang didukung untuk kueri dari sel SQL. Opsi ini antara lain mencakup pengaturan batas kueri default sebesar 1,000, menjalankan ekstraksi penuh, dan memasukkan parameter kueri. Penyiapan ini memungkinkan manipulasi data SQL yang fleksibel dan efisien langsung dalam lingkungan notebook Anda.
Buat koneksi basis data
Kemampuan penjelajahan dan eksekusi SQL bawaan SageMaker Studio ditingkatkan dengan koneksi AWS Glue. Koneksi AWS Glue adalah objek AWS Glue Data Catalog yang menyimpan data penting seperti kredensial login, string URI, dan informasi virtual private cloud (VPC) untuk penyimpanan data tertentu. Koneksi ini digunakan oleh crawler, pekerjaan, dan titik akhir pengembangan AWS Glue untuk mengakses berbagai jenis penyimpanan data. Anda dapat menggunakan koneksi ini untuk data sumber dan target, dan bahkan menggunakan kembali koneksi yang sama di beberapa crawler atau pekerjaan ekstrak, transformasi, dan muat (ETL).
Untuk menjelajahi sumber data SQL di panel kiri SageMaker Studio, Anda harus terlebih dahulu membuat objek koneksi AWS Glue. Koneksi ini memfasilitasi akses ke berbagai sumber data dan memungkinkan Anda menjelajahi elemen data skematiknya.
Di bagian berikut, kita akan menjalani proses pembuatan konektor AWS Glue khusus SQL. Ini akan memungkinkan Anda mengakses, melihat, dan menjelajahi kumpulan data di berbagai penyimpanan data. Untuk informasi lebih detail tentang koneksi AWS Glue, lihat Menghubungkan ke data.
Buat koneksi Lem AWS
Satu-satunya cara untuk menghadirkan sumber data ke SageMaker Studio adalah dengan koneksi AWS Glue. Anda perlu membuat koneksi AWS Glue dengan tipe koneksi tertentu. Saat tulisan ini dibuat, satu-satunya mekanisme yang didukung untuk membuat koneksi ini adalah menggunakan Antarmuka Baris Perintah AWS (AWS CLI).
File JSON definisi koneksi
Saat menghubungkan ke sumber data yang berbeda di AWS Glue, Anda harus terlebih dahulu membuat file JSON yang mendefinisikan properti koneksi—disebut sebagai file definisi koneksi. File ini sangat penting untuk membuat koneksi AWS Glue dan harus merinci semua konfigurasi yang diperlukan untuk mengakses sumber data. Untuk praktik keamanan terbaik, disarankan untuk menggunakan Secrets Manager untuk menyimpan informasi sensitif seperti kata sandi dengan aman. Sementara itu, properti koneksi lainnya dapat dikelola langsung melalui koneksi AWS Glue. Pendekatan ini memastikan bahwa kredensial sensitif dilindungi sambil tetap membuat konfigurasi koneksi dapat diakses dan dikelola.
Berikut ini adalah contoh definisi koneksi JSON:
Saat menyiapkan koneksi AWS Glue untuk sumber data Anda, ada beberapa panduan penting yang harus diikuti untuk menyediakan fungsionalitas dan keamanan:
- Stringifikasi properti - Dalam
PythonPropertieskuncinya, pastikan semua propertinya pasangan nilai kunci yang dirangkai. Sangat penting untuk menghindari tanda kutip ganda dengan menggunakan karakter garis miring terbalik () jika diperlukan. Ini membantu mempertahankan format yang benar dan menghindari kesalahan sintaksis di JSON Anda. - Menangani informasi sensitif – Meskipun dimungkinkan untuk menyertakan semua properti koneksi di dalamnya
PythonProperties, disarankan untuk tidak menyertakan detail sensitif seperti kata sandi secara langsung di properti ini. Sebaliknya, gunakan Secrets Manager untuk menangani informasi sensitif. Pendekatan ini mengamankan data sensitif Anda dengan menyimpannya di lingkungan yang terkontrol dan terenkripsi, jauh dari file konfigurasi utama.
Buat koneksi AWS Glue menggunakan AWS CLI
Setelah Anda menyertakan semua bidang yang diperlukan dalam file JSON definisi koneksi, Anda siap untuk membuat koneksi AWS Glue untuk sumber data Anda menggunakan AWS CLI dan perintah berikut:
Perintah ini memulai koneksi AWS Glue baru berdasarkan spesifikasi yang dirinci dalam file JSON Anda. Berikut ini adalah rincian singkat dari komponen perintah:
- -wilayah – Ini menentukan Wilayah AWS tempat koneksi AWS Glue Anda akan dibuat. Sangat penting untuk memilih Wilayah tempat sumber data Anda dan layanan lainnya berada untuk meminimalkan latensi dan mematuhi persyaratan residensi data.
- –cli-input-json file:///path/ke/file/connection/definition/file.json – Parameter ini mengarahkan AWS CLI untuk membaca konfigurasi input dari file lokal yang berisi definisi koneksi Anda dalam format JSON.
Anda harus dapat membuat koneksi AWS Glue dengan perintah AWS CLI sebelumnya dari terminal Studio JupyterLab Anda. Di File menu, pilih New dan terminal.

Jika create-connection perintah berjalan dengan sukses, Anda akan melihat sumber data Anda tercantum di panel browser SQL. Jika Anda tidak melihat sumber data Anda tercantum, pilih menyegarkan untuk memperbarui cache.

Buat koneksi Kepingan Salju
Di bagian ini, kami fokus pada pengintegrasian sumber data Snowflake dengan SageMaker Studio. Membuat akun, database, dan gudang Snowflake berada di luar cakupan postingan ini. Untuk memulai dengan Snowflake, lihat Panduan pengguna kepingan salju. Dalam postingan ini, kami berkonsentrasi pada pembuatan file JSON definisi Snowflake dan membuat koneksi sumber data Snowflake menggunakan AWS Glue.
Buat rahasia Manajer Rahasia
Anda dapat terhubung ke akun Snowflake Anda dengan menggunakan ID pengguna dan kata sandi atau menggunakan kunci pribadi. Untuk terhubung dengan ID pengguna dan kata sandi, Anda perlu menyimpan kredensial Anda dengan aman di Secrets Manager. Seperti disebutkan sebelumnya, meskipun informasi ini dapat disematkan di bawah PythonProperties, tidak disarankan untuk menyimpan informasi sensitif dalam format teks biasa. Selalu pastikan bahwa data sensitif ditangani dengan aman untuk menghindari potensi risiko keamanan.
Untuk menyimpan informasi di Secrets Manager, selesaikan langkah-langkah berikut:
- Pada konsol Manajer Rahasia, pilih Simpan rahasia baru.
- Untuk Tipe rahasia, pilih Jenis rahasia lainnya.
- Untuk pasangan nilai kunci, pilih Teks biasa dan masukkan yang berikut ini:
- Masukkan nama untuk rahasia Anda, seperti
sm-sql-snowflake-secret. - Biarkan pengaturan lainnya sebagai default atau sesuaikan jika diperlukan.
- Ciptakan rahasianya.
Buat koneksi AWS Glue untuk Snowflake
Seperti yang dibahas sebelumnya, koneksi AWS Glue sangat penting untuk mengakses koneksi apa pun dari SageMaker Studio. Anda dapat menemukan daftarnya semua properti koneksi yang didukung untuk Snowflake. Berikut ini adalah contoh definisi koneksi JSON untuk Snowflake. Ganti nilai placeholder dengan nilai yang sesuai sebelum menyimpannya ke disk:
Untuk membuat objek koneksi AWS Glue untuk sumber data Snowflake, gunakan perintah berikut:
Perintah ini membuat koneksi sumber data Snowflake baru di panel browser SQL Anda yang dapat dijelajahi, dan Anda bisa menjalankan kueri SQL terhadapnya dari sel buku catatan JupyterLab Anda.
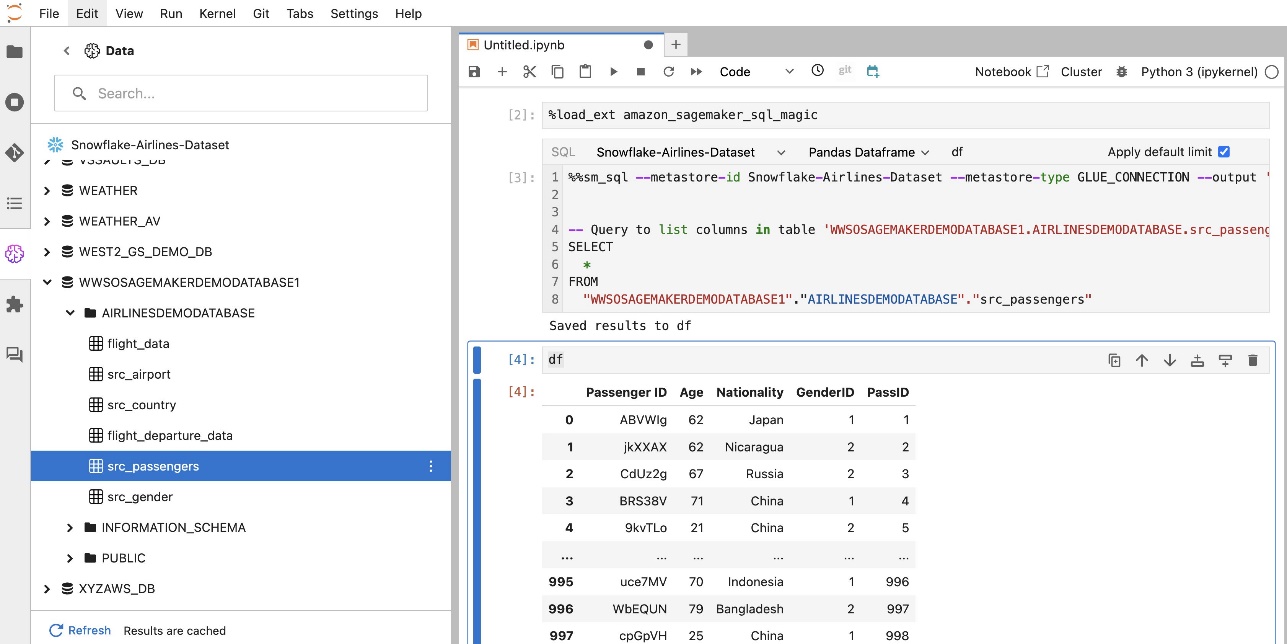
Buat koneksi Amazon Redshift
Amazon Redshift adalah layanan gudang data berskala petabyte yang terkelola sepenuhnya yang menyederhanakan dan mengurangi biaya analisis semua data Anda menggunakan SQL standar. Prosedur untuk membuat koneksi Amazon Redshift sangat mirip dengan prosedur untuk koneksi Snowflake.
Buat rahasia Manajer Rahasia
Mirip dengan pengaturan Snowflake, untuk terhubung ke Amazon Redshift menggunakan ID pengguna dan kata sandi, Anda perlu menyimpan informasi rahasia dengan aman di Secrets Manager. Selesaikan langkah-langkah berikut:
- Pada konsol Manajer Rahasia, pilih Simpan rahasia baru.
- Untuk Tipe rahasia, pilih Kredensial untuk klaster Amazon Redshift.
- Masukkan kredensial yang digunakan untuk masuk untuk mengakses Amazon Redshift sebagai sumber data.
- Pilih klaster Redshift yang terkait dengan rahasia.
- Masukkan nama untuk rahasianya, seperti
sm-sql-redshift-secret. - Biarkan pengaturan lainnya sebagai default atau sesuaikan jika diperlukan.
- Ciptakan rahasianya.
Dengan mengikuti langkah-langkah ini, Anda memastikan kredensial koneksi Anda ditangani dengan aman, menggunakan fitur keamanan yang kuat dari AWS untuk mengelola data sensitif secara efektif.
Buat koneksi AWS Glue untuk Amazon Redshift
Untuk mengatur koneksi dengan Amazon Redshift menggunakan definisi JSON, isi kolom yang diperlukan dan simpan konfigurasi JSON berikut ke disk:
Untuk membuat objek koneksi AWS Glue untuk sumber data Redshift, gunakan perintah AWS CLI berikut:
Perintah ini membuat koneksi di AWS Glue yang ditautkan ke sumber data Redshift Anda. Jika perintah berhasil dijalankan, Anda akan dapat melihat sumber data Redshift Anda dalam notebook SageMaker Studio JupyterLab, siap untuk menjalankan kueri SQL dan melakukan analisis data.

Buat koneksi Athena
Athena adalah layanan kueri SQL yang dikelola sepenuhnya dari AWS yang memungkinkan analisis data yang disimpan di Amazon S3 menggunakan SQL standar. Untuk menyiapkan koneksi Athena sebagai sumber data di browser SQL notebook JupyterLab, Anda perlu membuat JSON definisi koneksi sampel Athena. Struktur JSON berikut mengonfigurasi detail yang diperlukan untuk terhubung ke Athena, menentukan katalog data, direktori pementasan S3, dan Wilayah:
Untuk membuat objek koneksi AWS Glue untuk sumber data Athena, gunakan perintah AWS CLI berikut:
Jika perintah berhasil, Anda akan dapat mengakses katalog dan tabel data Athena langsung dari browser SQL dalam buku catatan SageMaker Studio JupyterLab Anda.
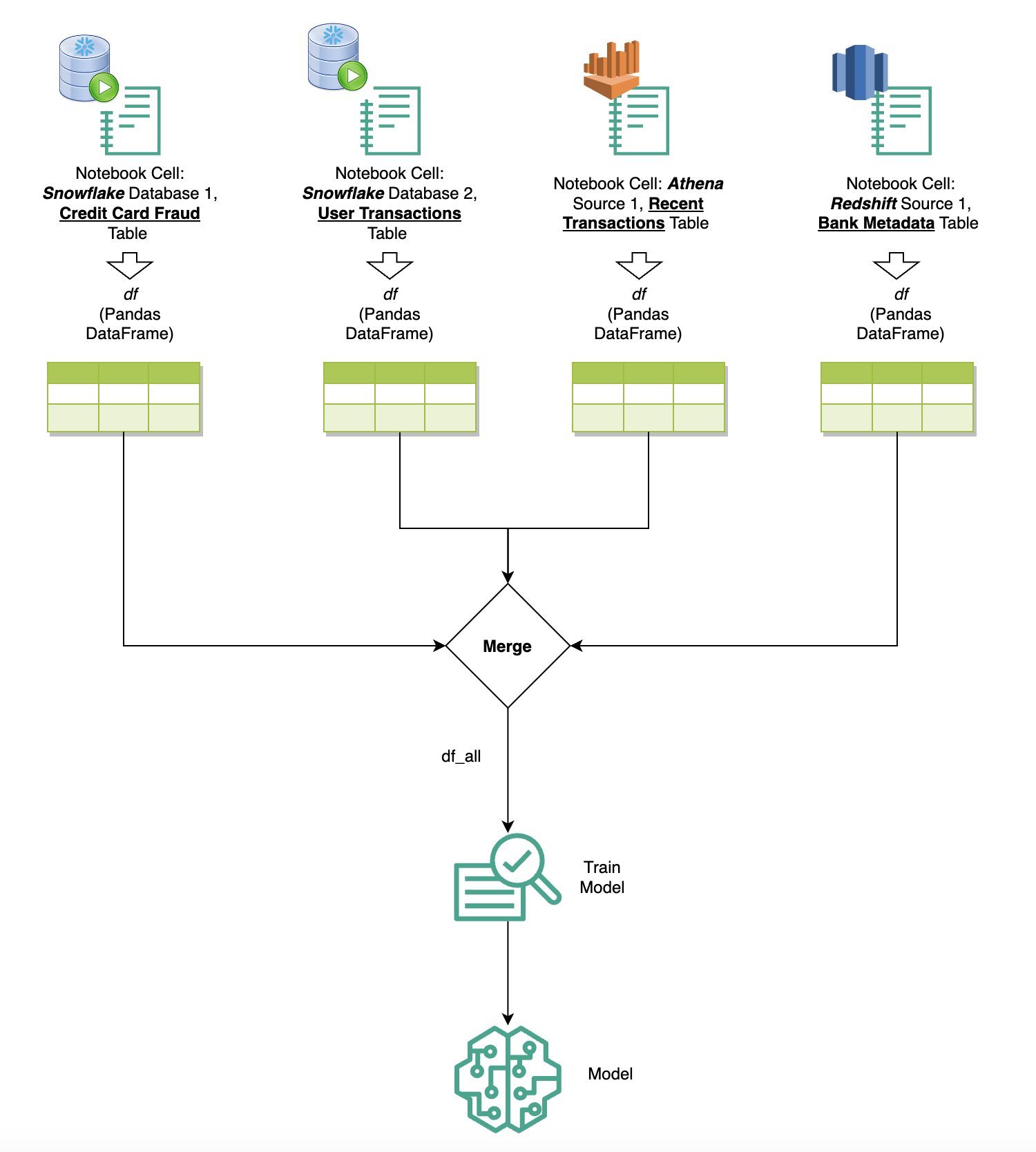
Data kueri dari berbagai sumber
Jika Anda memiliki beberapa sumber data yang terintegrasi ke dalam SageMaker Studio melalui browser SQL bawaan dan fitur SQL notebook, Anda dapat dengan cepat menjalankan kueri dan dengan mudah beralih antar backend sumber data di sel berikutnya dalam notebook. Kemampuan ini memungkinkan transisi yang mulus antara database atau sumber data yang berbeda selama alur kerja analisis Anda.
Anda dapat menjalankan kueri terhadap beragam kumpulan backend sumber data dan membawa hasilnya langsung ke ruang Python untuk analisis atau visualisasi lebih lanjut. Hal ini difasilitasi oleh %%sm_sql perintah ajaib tersedia di notebook SageMaker Studio. Untuk menampilkan hasil kueri SQL Anda ke dalam pandas DataFrame, ada dua opsi:
- Dari toolbar sel buku catatan Anda, pilih jenis output Bingkai Data dan beri nama variabel DataFrame Anda
- Tambahkan parameter berikut ke file Anda
%%sm_sqlperintah:
Diagram berikut mengilustrasikan alur kerja ini dan menunjukkan bagaimana Anda dapat dengan mudah menjalankan kueri di berbagai sumber di sel buku catatan berikutnya, serta melatih model SageMaker menggunakan tugas pelatihan atau langsung di dalam buku catatan menggunakan komputasi lokal. Selain itu, diagram menyoroti bagaimana integrasi SQL bawaan SageMaker Studio menyederhanakan proses ekstraksi dan pembuatan langsung dalam lingkungan akrab sel notebook JupyterLab.
Teks ke SQL: Menggunakan bahasa alami untuk meningkatkan pembuatan kueri
SQL adalah bahasa kompleks yang memerlukan pemahaman tentang database, tabel, sintaksis, dan metadata. Saat ini, kecerdasan buatan (AI) generatif dapat memungkinkan Anda menulis kueri SQL yang kompleks tanpa memerlukan pengalaman SQL yang mendalam. Kemajuan LLM telah berdampak signifikan terhadap pembuatan SQL berbasis pemrosesan bahasa alami (NLP), yang memungkinkan pembuatan kueri SQL yang tepat dari deskripsi bahasa alami—sebuah teknik yang disebut sebagai Text-to-SQL. Namun, penting untuk mengetahui perbedaan inheren antara bahasa manusia dan SQL. Bahasa manusia terkadang ambigu atau tidak tepat, sedangkan SQL terstruktur, eksplisit, dan tidak ambigu. Menjembatani kesenjangan ini dan secara akurat mengubah bahasa alami menjadi kueri SQL dapat menghadirkan tantangan yang berat. Ketika diberikan petunjuk yang tepat, LLM dapat membantu menjembatani kesenjangan ini dengan memahami maksud di balik bahasa manusia dan menghasilkan kueri SQL yang akurat.
Dengan dirilisnya fitur kueri SQL dalam notebook SageMaker Studio, SageMaker Studio mempermudah pemeriksaan database dan skema, serta menulis, menjalankan, dan men-debug kueri SQL tanpa harus meninggalkan IDE notebook Jupyter. Bagian ini mengeksplorasi bagaimana kemampuan Text-to-SQL dari LLM tingkat lanjut dapat memfasilitasi pembuatan kueri SQL menggunakan bahasa alami dalam buku catatan Jupyter. Kami menggunakan model Text-to-SQL yang mutakhir defog/sqlcoder-7b-2 bersama dengan Jupyter AI, asisten AI generatif yang dirancang khusus untuk notebook Jupyter, untuk membuat kueri SQL kompleks dari bahasa alami. Dengan menggunakan model tingkat lanjut ini, kami dapat dengan mudah dan efisien membuat kueri SQL kompleks menggunakan bahasa alami, sehingga meningkatkan pengalaman SQL kami dalam buku catatan.
Pembuatan prototipe buku catatan menggunakan Hugging Face Hub
Untuk memulai pembuatan prototipe, Anda memerlukan hal berikut:
- Kode GitHub – Kode yang disajikan di bagian ini tersedia berikut ini GitHub repo dan dengan merujuk pada contoh notebook.
- Ruang JupyterLab – Akses ke SageMaker Studio JupyterLab Space yang didukung oleh instans berbasis GPU sangatlah penting. Untuk
defog/sqlcoder-7b-2model, model parameter 7B, disarankan menggunakan instance ml.g5.2xlarge. Alternatif sepertidefog/sqlcoder-70b-alpha ataudefog/sqlcoder-34b-alphajuga layak untuk konversi bahasa alami ke SQL, tetapi tipe instans yang lebih besar mungkin diperlukan untuk pembuatan prototipe. Pastikan Anda memiliki kuota untuk meluncurkan instans yang didukung GPU dengan menavigasi ke konsol Service Quotas, mencari SageMaker, dan mencariStudio JupyterLab Apps running on <instance type>.
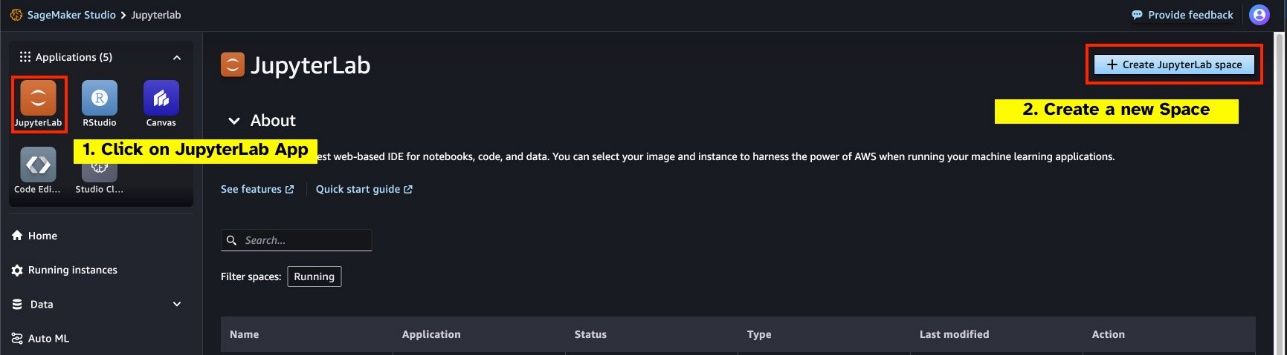
Luncurkan JupyterLab Space baru yang didukung GPU dari SageMaker Studio Anda. Disarankan untuk membuat JupyterLab Space baru dengan kapasitas minimal 75 GB Toko Blok Elastis Amazon Penyimpanan (Amazon EBS) untuk model parameter 7B.

- Memeluk Wajah Hub – Jika domain SageMaker Studio Anda memiliki akses untuk mengunduh model dari Memeluk Wajah Hub, Anda bisa menggunakan
AutoModelForCausalLMkelas dari pelukan/transformator untuk mengunduh model secara otomatis dan menyematkannya ke GPU lokal Anda. Bobot model akan disimpan dalam cache mesin lokal Anda. Lihat kode berikut:
Setelah model diunduh sepenuhnya dan dimuat ke dalam memori, Anda akan melihat peningkatan penggunaan GPU di mesin lokal Anda. Hal ini menunjukkan bahwa model tersebut secara aktif menggunakan sumber daya GPU untuk tugas komputasi. Anda dapat memverifikasi ini di ruang JupyterLab Anda sendiri dengan menjalankan nvidia-smi (untuk tampilan satu kali) atau nvidia-smi —loop=1 (untuk mengulang setiap detik) dari terminal JupyterLab Anda.
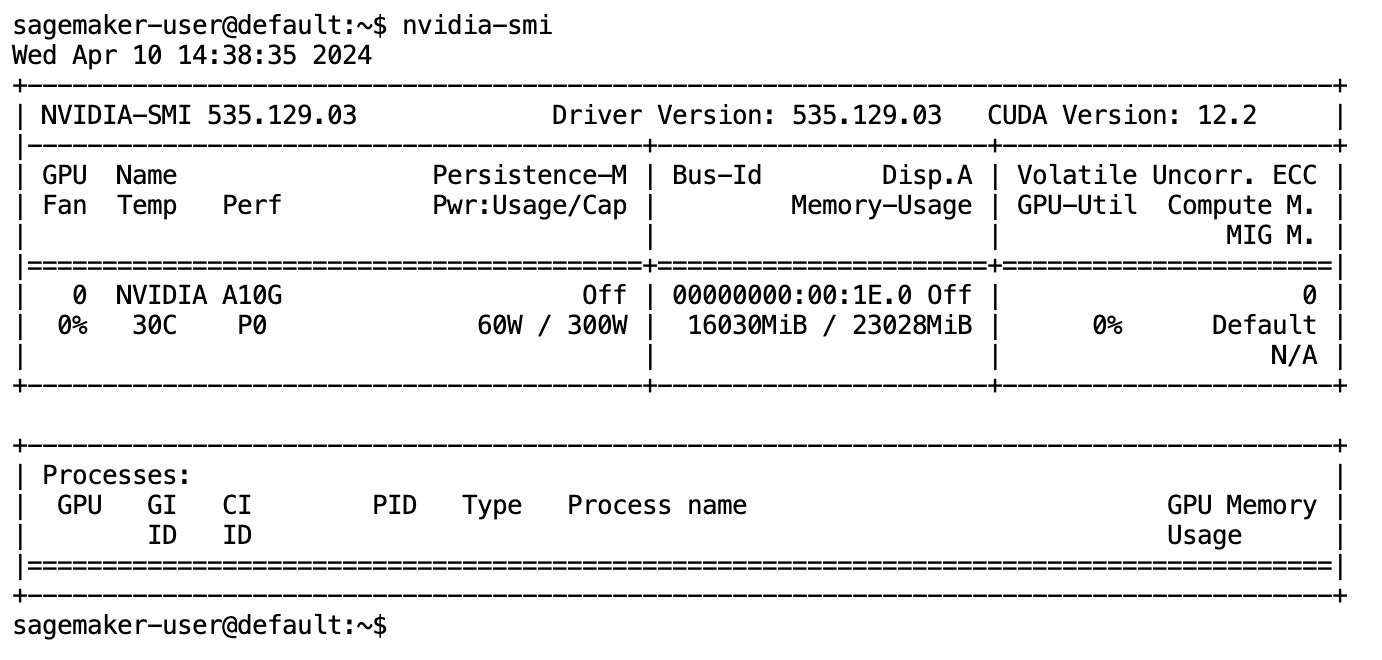
Model Text-to-SQL unggul dalam memahami maksud dan konteks permintaan pengguna, bahkan ketika bahasa yang digunakan bersifat percakapan atau ambigu. Prosesnya melibatkan penerjemahan masukan bahasa alami ke dalam elemen skema database yang benar, seperti nama tabel, nama kolom, dan kondisi. Namun, model Text-to-SQL yang siap pakai tidak akan secara inheren mengetahui struktur gudang data Anda, skema database tertentu, atau dapat secara akurat menafsirkan konten tabel hanya berdasarkan nama kolom. Untuk menggunakan model ini secara efektif dalam menghasilkan kueri SQL yang praktis dan efisien dari bahasa alami, model pembuatan teks SQL perlu disesuaikan dengan skema database gudang spesifik Anda. Adaptasi ini difasilitasi melalui penggunaan LLM meminta. Berikut ini adalah templat prompt yang direkomendasikan untuk model Text-to-SQL defog/sqlcoder-7b-2, dibagi menjadi empat bagian:
- tugas – Bagian ini harus menentukan tugas tingkat tinggi yang harus diselesaikan oleh model. Ini harus mencakup jenis backend database (seperti Amazon RDS, PostgreSQL, atau Amazon Redshift) untuk membuat model menyadari adanya perbedaan sintaksis yang dapat memengaruhi pembuatan kueri SQL akhir.
- petunjuk – Bagian ini harus menentukan batasan tugas dan kesadaran domain untuk model, dan mungkin menyertakan beberapa contoh singkat untuk memandu model dalam menghasilkan kueri SQL yang disesuaikan dengan baik.
- Skema Database – Bagian ini harus merinci skema database gudang Anda, menguraikan hubungan antara tabel dan kolom untuk membantu model dalam memahami struktur database.
- Menjawab – Bagian ini dicadangkan bagi model untuk mengeluarkan respons kueri SQL ke masukan bahasa alami.
Contoh skema database dan prompt yang digunakan di bagian ini tersedia di Repo GitHub.
Rekayasa cepat bukan hanya tentang membentuk pertanyaan atau pernyataan; ini adalah nuansa seni dan sains yang secara signifikan memengaruhi kualitas interaksi dengan model AI. Cara Anda menyusun perintah dapat sangat memengaruhi sifat dan kegunaan respons AI. Keterampilan ini sangat penting dalam memaksimalkan potensi interaksi AI, terutama dalam tugas-tugas kompleks yang memerlukan pemahaman khusus dan respons terperinci.
Penting untuk memiliki opsi untuk dengan cepat membuat dan menguji respons model untuk perintah tertentu dan mengoptimalkan perintah berdasarkan respons tersebut. Notebook JupyterLab memberikan kemampuan untuk menerima umpan balik model instan dari model yang berjalan pada komputasi lokal dan mengoptimalkan perintah serta menyesuaikan respons model lebih lanjut atau mengubah model sepenuhnya. Dalam postingan ini, kami menggunakan notebook SageMaker Studio JupyterLab yang didukung oleh GPU NVIDIA A5.2G 10 GB ml.g24xlarge untuk menjalankan inferensi model Text-to-SQL pada notebook dan secara interaktif membuat prompt model kami hingga respons model cukup disetel untuk menyediakan respons yang dapat dieksekusi langsung di sel SQL JupyterLab. Untuk menjalankan inferensi model dan mengalirkan respons model secara bersamaan, kami menggunakan kombinasi model.generate dan TextIteratorStreamer seperti yang didefinisikan dalam kode berikut:
Keluaran model dapat dihias dengan keajaiban SageMaker SQL %%sm_sql ..., yang memungkinkan notebook JupyterLab mengidentifikasi sel sebagai sel SQL.
Menghosting model Text-to-SQL sebagai titik akhir SageMaker
Di akhir tahap pembuatan prototipe, kami telah memilih Text-to-SQL LLM pilihan kami, format prompt yang efektif, dan jenis instance yang sesuai untuk menghosting model (baik GPU tunggal atau multi-GPU). SageMaker memfasilitasi hosting model kustom yang dapat diskalakan melalui penggunaan titik akhir SageMaker. Titik akhir ini dapat ditentukan berdasarkan kriteria tertentu, sehingga memungkinkan penerapan LLM sebagai titik akhir. Kemampuan ini memungkinkan Anda untuk menskalakan solusi ke audiens yang lebih luas, memungkinkan pengguna menghasilkan kueri SQL dari input bahasa alami menggunakan LLM yang dihosting khusus. Diagram berikut menggambarkan arsitektur ini.

Untuk menghosting LLM Anda sebagai titik akhir SageMaker, Anda membuat beberapa artefak.
Artefak pertama adalah model anak timbangan. Penyajian Perpustakaan Deep Java (DJL) SageMaker container memungkinkan Anda mengatur konfigurasi melalui meta melayani.properti file, yang memungkinkan Anda mengarahkan sumber model—baik langsung dari Hugging Face Hub atau dengan mengunduh artefak model dari Amazon S3. Jika Anda menentukan model_id=defog/sqlcoder-7b-2, DJL Serving akan mencoba mendownload langsung model ini dari Hugging Face Hub. Namun, Anda mungkin dikenakan biaya masuk/keluar jaringan setiap kali titik akhir diterapkan atau diskalakan secara elastis. Untuk menghindari biaya ini dan berpotensi mempercepat pengunduhan artefak model, disarankan untuk tidak menggunakan model_id in serving.properties dan menyimpan bobot model sebagai artefak S3 dan hanya menentukannya dengan s3url=s3://path/to/model/bin.
Menyimpan model (dengan tokenizernya) ke disk dan mengunggahnya ke Amazon S3 dapat dilakukan hanya dengan beberapa baris kode:
Anda juga menggunakan file prompt database. Dalam pengaturan ini, prompt database terdiri dari Task, Instructions, Database Schema, dan Answer sections. Untuk arsitektur saat ini, kami mengalokasikan file prompt terpisah untuk setiap skema database. Namun, ada fleksibilitas untuk memperluas pengaturan ini untuk menyertakan beberapa database per file prompt, sehingga model dapat menjalankan gabungan gabungan di seluruh database pada server yang sama. Selama tahap pembuatan prototipe, kami menyimpan prompt database sebagai file teks bernama <Database-Glue-Connection-Name>.prompt, Di mana Database-Glue-Connection-Name sesuai dengan nama koneksi yang terlihat di lingkungan JupyterLab Anda. Misalnya, postingan ini merujuk pada nama koneksi Snowflake Airlines_Dataset, sehingga file prompt database diberi nama Airlines_Dataset.prompt. File ini kemudian disimpan di Amazon S3 dan selanjutnya dibaca dan di-cache oleh logika penyajian model kami.
Selain itu, arsitektur ini mengizinkan pengguna resmi titik akhir ini untuk mendefinisikan, menyimpan, dan menghasilkan bahasa alami untuk kueri SQL tanpa memerlukan beberapa penerapan ulang model. Kami menggunakan yang berikut ini contoh prompt basis data untuk mendemonstrasikan fungsionalitas Text-to-SQL.
Selanjutnya, Anda membuat logika layanan model kustom. Di bagian ini, Anda menguraikan logika inferensi khusus yang diberi nama model.py. Skrip ini dirancang untuk mengoptimalkan kinerja dan integrasi layanan Text-to-SQL kami:
- Tentukan logika cache file prompt database – Untuk meminimalkan latensi, kami menerapkan logika khusus untuk mengunduh dan menyimpan file prompt database. Mekanisme ini memastikan bahwa perintah sudah tersedia, mengurangi overhead yang terkait dengan seringnya pengunduhan.
- Tentukan logika inferensi model kustom – Untuk meningkatkan kecepatan inferensi, model text-to-SQL kami dimuat dalam format presisi float16 dan kemudian diubah menjadi model DeepSpeed. Langkah ini memungkinkan komputasi yang lebih efisien. Selain itu, dalam logika ini, Anda menentukan parameter mana yang dapat disesuaikan pengguna selama panggilan inferensi untuk menyesuaikan fungsionalitas sesuai kebutuhan mereka.
- Tentukan logika masukan dan keluaran khusus – Menetapkan format input/output yang jelas dan disesuaikan sangat penting untuk kelancaran integrasi dengan aplikasi hilir. Salah satu aplikasi tersebut adalah JupyterAI, yang akan kita bahas di bagian selanjutnya.
Selain itu, kami menyertakan a serving.properties file, yang bertindak sebagai file konfigurasi global untuk model yang dihosting menggunakan layanan DJL. Untuk informasi lebih lanjut, lihat Konfigurasi dan pengaturan.
Terakhir, Anda juga dapat memasukkan a requirements.txt file untuk menentukan modul tambahan yang diperlukan untuk inferensi dan mengemas semuanya ke dalam tarball untuk penerapan.
Lihat kode berikut:
Integrasikan titik akhir Anda dengan asisten AI SageMaker Studio Jupyter
Jupyter AI adalah alat sumber terbuka yang menghadirkan AI generatif ke notebook Jupyter, menawarkan platform yang kuat dan ramah pengguna untuk menjelajahi model AI generatif. Hal ini meningkatkan produktivitas di notebook JupyterLab dan Jupyter dengan menyediakan fitur seperti keajaiban %%ai untuk menciptakan taman bermain AI generatif di dalam notebook, UI obrolan asli di JupyterLab untuk berinteraksi dengan AI sebagai asisten percakapan, dan dukungan untuk beragam LLM dari penyedia seperti Titan Amazon, AI21, Anthropic, Cohere, dan Hugging Face atau layanan terkelola sejenisnya Batuan Dasar Amazon dan titik akhir SageMaker. Untuk postingan ini, kami menggunakan integrasi out-of-the-box Jupyter AI dengan titik akhir SageMaker untuk menghadirkan kemampuan Text-to-SQL ke dalam notebook JupyterLab. Alat Jupyter AI sudah diinstal sebelumnya di semua SageMaker Studio JupyterLab Spaces yang didukung oleh Gambar Distribusi SageMaker; pengguna akhir tidak perlu membuat konfigurasi tambahan apa pun untuk mulai menggunakan ekstensi Jupyter AI untuk berintegrasi dengan titik akhir yang dihosting SageMaker. Di bagian ini, kita membahas dua cara menggunakan alat Jupyter AI terintegrasi.
Jupyter AI di dalam buku catatan menggunakan sihir
Jupyter AI %%ai perintah ajaib memungkinkan Anda mengubah notebook SageMaker Studio JupyterLab menjadi lingkungan AI generatif yang dapat direproduksi. Untuk mulai menggunakan sihir AI, pastikan Anda telah memuat ekstensi jupyter_ai_magics untuk digunakan %%ai sihir, dan juga memuat amazon_sagemaker_sql_magic untuk menggunakan %%sm_sql sihir:
Untuk menjalankan panggilan ke titik akhir SageMaker Anda dari buku catatan Anda menggunakan %%ai perintah ajaib, berikan parameter berikut dan susun perintah sebagai berikut:
- –nama-wilayah – Tentukan Wilayah tempat titik akhir Anda disebarkan. Hal ini memastikan bahwa permintaan diarahkan ke lokasi geografis yang benar.
- –skema permintaan – Sertakan skema data input. Skema ini menguraikan format dan jenis data masukan yang diharapkan yang dibutuhkan model Anda untuk memproses permintaan.
- –jalur respons – Tentukan jalur dalam objek respons tempat keluaran model Anda berada. Jalur ini digunakan untuk mengekstrak data relevan dari respons yang dikembalikan oleh model Anda.
- -f (opsional) - Ini adalah sebuah pemformat keluaran bendera yang menunjukkan jenis keluaran yang dikembalikan oleh model. Dalam konteks buku catatan Jupyter, jika keluarannya berupa kode, tanda ini harus disetel sesuai untuk memformat keluaran sebagai kode yang dapat dieksekusi di bagian atas sel buku catatan Jupyter, diikuti dengan area masukan teks bebas untuk interaksi pengguna.
Misalnya, perintah di sel notebook Jupyter mungkin terlihat seperti kode berikut:
Jendela obrolan Jupyter AI
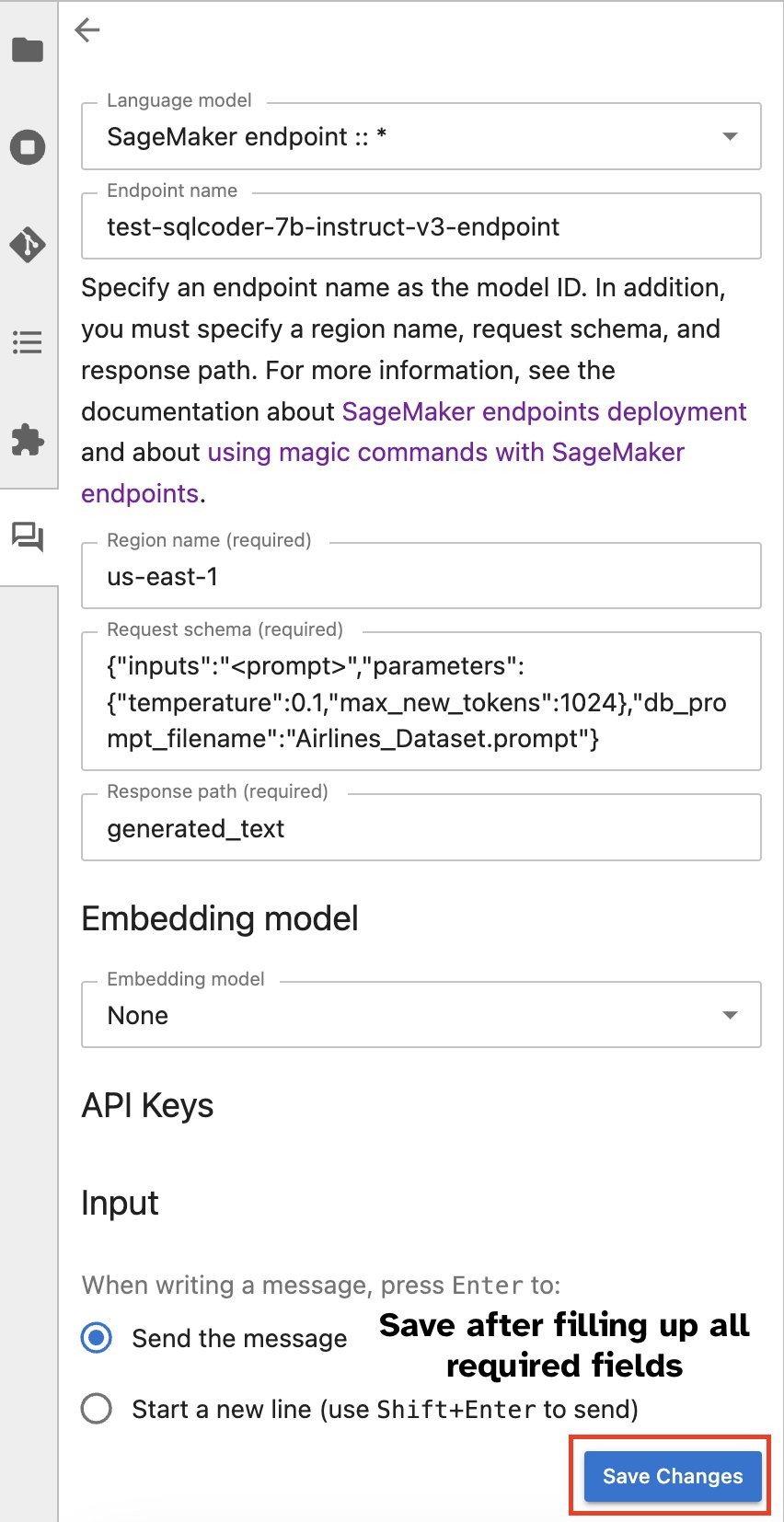
Alternatifnya, Anda dapat berinteraksi dengan titik akhir SageMaker melalui antarmuka pengguna bawaan, menyederhanakan proses pembuatan kueri atau terlibat dalam dialog. Sebelum mulai mengobrol dengan titik akhir SageMaker Anda, konfigurasikan pengaturan yang relevan di Jupyter AI untuk titik akhir SageMaker, seperti yang ditunjukkan pada tangkapan layar berikut.
 |
 |
Kesimpulan
SageMaker Studio kini menyederhanakan dan menyederhanakan alur kerja data scientist dengan mengintegrasikan dukungan SQL ke dalam notebook JupyterLab. Hal ini memungkinkan data scientist untuk fokus pada tugas mereka tanpa perlu mengelola banyak alat. Selain itu, integrasi SQL bawaan yang baru di SageMaker Studio memungkinkan persona data dengan mudah menghasilkan kueri SQL menggunakan teks bahasa alami sebagai masukan, sehingga mempercepat alur kerja mereka.
Kami mendorong Anda untuk menjelajahi fitur-fitur ini di SageMaker Studio. Untuk informasi lebih lanjut, lihat Siapkan data dengan SQL di Studio.
Lampiran
Aktifkan browser SQL dan sel SQL notebook di lingkungan kustom
Jika Anda tidak menggunakan gambar Distribusi SageMaker atau menggunakan gambar Distribusi 1.5 atau lebih rendah, jalankan perintah berikut untuk mengaktifkan fitur penjelajahan SQL di dalam lingkungan JupyterLab Anda:
Pindahkan widget browser SQL
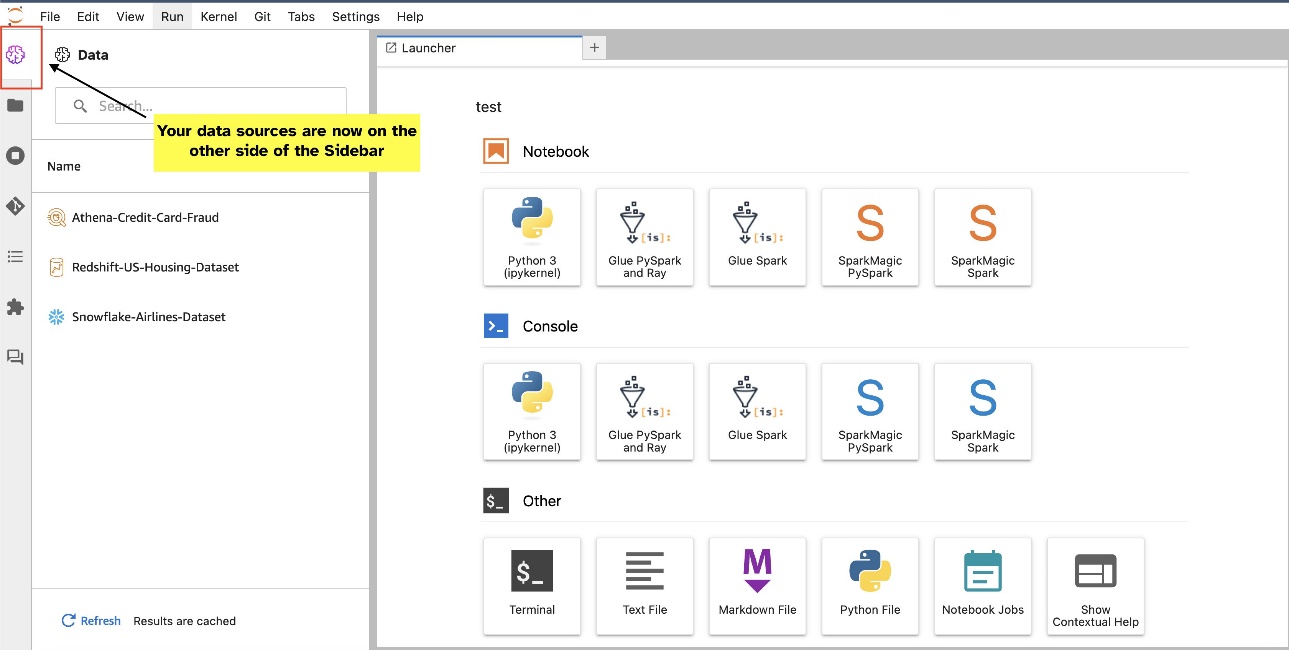
Widget JupyterLab memungkinkan relokasi. Bergantung pada preferensi Anda, Anda dapat memindahkan widget ke kedua sisi panel widget JupyterLab. Jika mau, Anda dapat memindahkan arah widget SQL ke sisi berlawanan (kanan ke kiri) dari sidebar dengan mengklik kanan pada ikon widget dan memilih Beralih Sisi Sidebar.
 |
 |
Tentang penulis
 Pranav Murthy adalah Arsitek Solusi Spesialis AI/ML di AWS. Dia berfokus membantu pelanggan membangun, melatih, menerapkan, dan memigrasikan beban kerja pembelajaran mesin (ML) ke SageMaker. Dia sebelumnya bekerja di industri semikonduktor yang mengembangkan model computer vision (CV) besar dan pemrosesan bahasa alami (NLP) untuk meningkatkan proses semikonduktor menggunakan teknik ML yang canggih. Di waktu luangnya, ia menikmati bermain catur dan jalan-jalan. Anda dapat menemukan Pranav di LinkedIn.
Pranav Murthy adalah Arsitek Solusi Spesialis AI/ML di AWS. Dia berfokus membantu pelanggan membangun, melatih, menerapkan, dan memigrasikan beban kerja pembelajaran mesin (ML) ke SageMaker. Dia sebelumnya bekerja di industri semikonduktor yang mengembangkan model computer vision (CV) besar dan pemrosesan bahasa alami (NLP) untuk meningkatkan proses semikonduktor menggunakan teknik ML yang canggih. Di waktu luangnya, ia menikmati bermain catur dan jalan-jalan. Anda dapat menemukan Pranav di LinkedIn.
 Varun Shah adalah Insinyur Perangkat Lunak yang bekerja di Amazon SageMaker Studio di Amazon Web Services. Dia fokus membangun solusi ML interaktif yang menyederhanakan perjalanan pemrosesan dan persiapan data. Di waktu luangnya, Varun menikmati aktivitas luar ruangan termasuk hiking dan ski, serta selalu siap menjelajahi tempat-tempat baru dan menarik.
Varun Shah adalah Insinyur Perangkat Lunak yang bekerja di Amazon SageMaker Studio di Amazon Web Services. Dia fokus membangun solusi ML interaktif yang menyederhanakan perjalanan pemrosesan dan persiapan data. Di waktu luangnya, Varun menikmati aktivitas luar ruangan termasuk hiking dan ski, serta selalu siap menjelajahi tempat-tempat baru dan menarik.
 Sumedha Swamy adalah Manajer Produk Utama di Amazon Web Services yang memimpin tim SageMaker Studio dalam misinya mengembangkan IDE pilihan untuk ilmu data dan pembelajaran mesin. Dia telah mendedikasikan 15 tahun terakhir untuk membangun produk konsumen dan perusahaan berbasis Machine Learning.
Sumedha Swamy adalah Manajer Produk Utama di Amazon Web Services yang memimpin tim SageMaker Studio dalam misinya mengembangkan IDE pilihan untuk ilmu data dan pembelajaran mesin. Dia telah mendedikasikan 15 tahun terakhir untuk membangun produk konsumen dan perusahaan berbasis Machine Learning.
 Bosco Alburquerque adalah Arsitek Solusi Mitra Senior di AWS dan memiliki lebih dari 20 tahun pengalaman bekerja dengan produk database dan analitik dari vendor database perusahaan dan penyedia cloud. Dia telah membantu perusahaan teknologi merancang dan mengimplementasikan solusi dan produk analitik data.
Bosco Alburquerque adalah Arsitek Solusi Mitra Senior di AWS dan memiliki lebih dari 20 tahun pengalaman bekerja dengan produk database dan analitik dari vendor database perusahaan dan penyedia cloud. Dia telah membantu perusahaan teknologi merancang dan mengimplementasikan solusi dan produk analitik data.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

