Pengantar
Dalam visi komputer, terdapat berbagai teknik untuk mendeteksi objek langsung, termasuk Lebih Cepat R-CNN, SSD, dan YOLO. Setiap teknik memiliki keterbatasan dan kelebihannya. Meskipun Faster R-CNN mungkin unggul dalam hal akurasi, kinerjanya mungkin tidak sebaik dalam skenario real-time, sehingga mendorong peralihan ke arah yang lebih cepat. Algoritma YOLO.
Deteksi objek merupakan hal mendasar dalam visi komputer, memungkinkan mesin mengidentifikasi dan menemukan lokasi objek dalam bingkai atau layar. Selama bertahun-tahun, berbagai algoritma deteksi objek telah dikembangkan, dan YOLO muncul sebagai salah satu yang paling sukses. Baru-baru ini, YOLOv8 telah diperkenalkan, yang semakin meningkatkan kemampuan algoritme.
Dalam panduan komprehensif ini, kami menjelajahi tiga algoritme pendeteksian objek yang menonjol: R-CNN Lebih Cepat, SSD (Single Shot MultiBox Detector), dan YOLOv8. Kami membahas aspek praktis penerapan algoritme ini, termasuk menyiapkan lingkungan virtual dan mengembangkan aplikasi Streamlit.
Tujuan Pembelajaran
- Pahami R-CNN, SSD, dan YOLO yang Lebih Cepat, dan analisis perbedaan di antara keduanya.
- Dapatkan pengalaman praktis dalam mengimplementasikan sistem deteksi objek langsung menggunakan OpenCV, Supervision, dan YOLOv8.
- Memahami model segmentasi gambar menggunakan anotasi Roboflow.
- Buat aplikasi Streamlit untuk antarmuka pengguna yang mudah.
Mari jelajahi cara melakukan segmentasi gambar dengan YOLOv8!
Daftar Isi
Artikel ini diterbitkan sebagai bagian dari Blogathon Ilmu Data.
Lebih cepat R-CNN
R-CNN yang Lebih Cepat (Jaringan Neural Konvolusional Berbasis Wilayah Lebih Cepat) adalah algoritma deteksi objek berbasis pembelajaran mendalam. Ini dievaluasi menggunakan kerangka kerja R-CNN dan Fast R-CNN dan dapat dianggap sebagai perpanjangan dari Fast R-CNN.
Algoritme ini memperkenalkan Jaringan Proposal Wilayah (RPN) untuk menghasilkan proposal wilayah, menggantikan pencarian selektif yang digunakan di R-CNN. RPN berbagi lapisan konvolusional dengan jaringan deteksi, memungkinkan pelatihan end-to-end yang efisien.
Proposal wilayah yang dihasilkan kemudian dimasukkan ke dalam jaringan Fast R-CNN untuk penyempurnaan kotak pembatas dan klasifikasi objek.
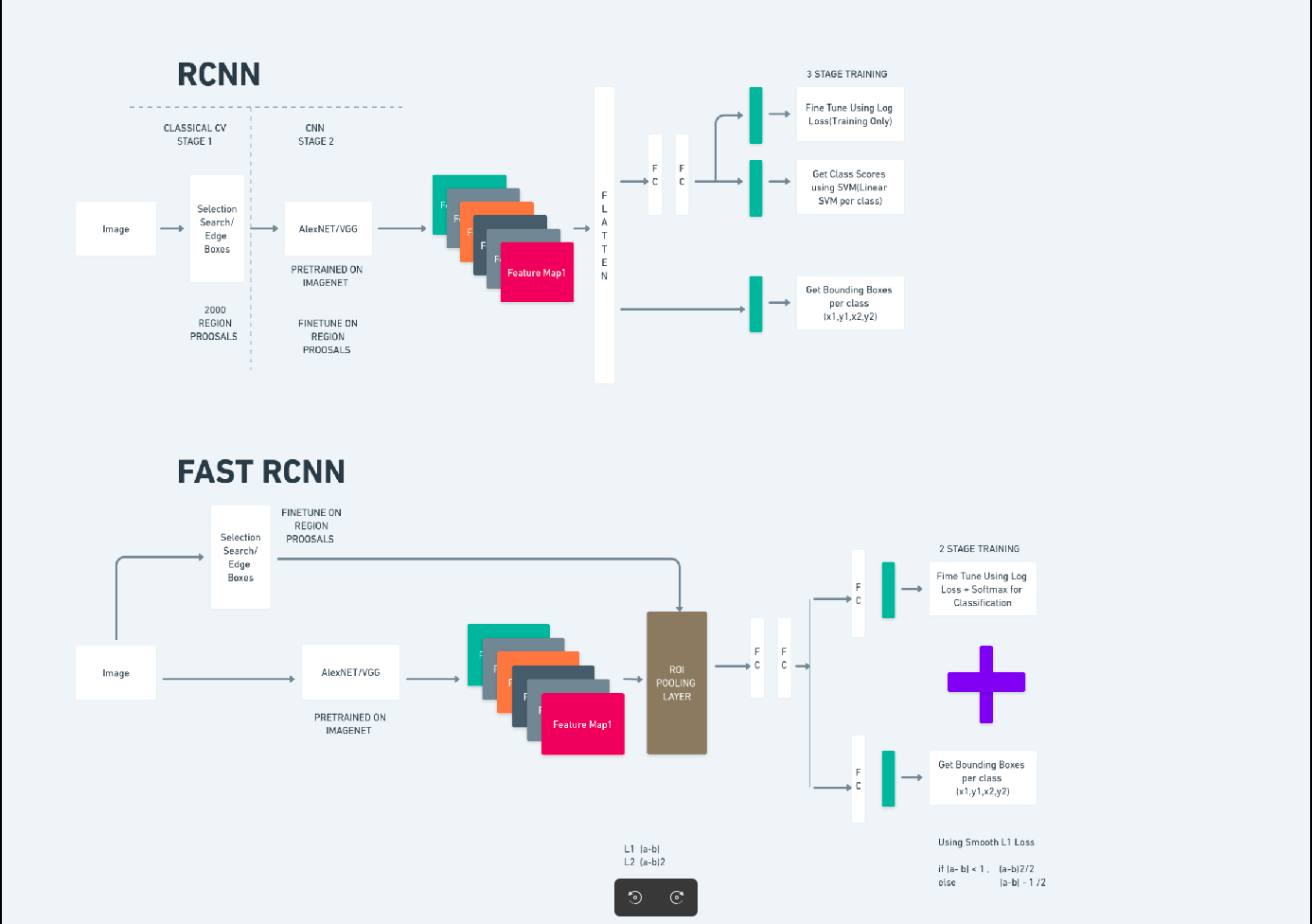
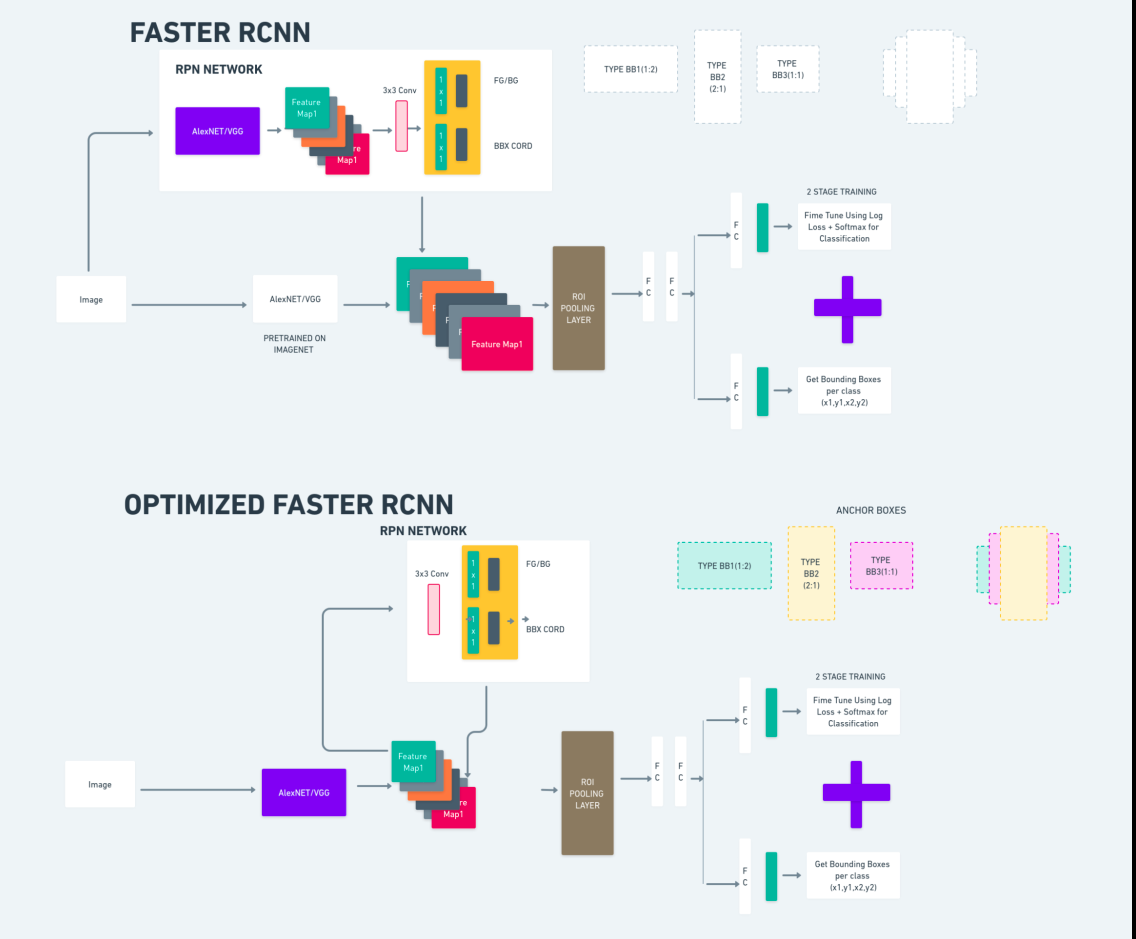
Diagram di atas menggambarkan keluarga Faster R-CNN secara komprehensif dan mudah dipahami untuk mengevaluasi setiap algoritma.
Detektor MultiKotak Tembakan Tunggal (SSD)
Grafik Detektor MultiBox Tembakan Tunggal (SSD) populer dalam deteksi objek dan terutama digunakan dalam tugas visi komputer. Dalam metode sebelumnya, Faster R-CNN, kami mengikuti dua langkah: langkah pertama melibatkan bagian deteksi dan langkah kedua melibatkan regresi. Namun, dengan SSD, kami hanya melakukan satu langkah deteksi. SSD diperkenalkan pada tahun 2016 untuk memenuhi kebutuhan model deteksi objek yang cepat dan akurat.

SSD memiliki beberapa keunggulan dibandingkan metode deteksi objek sebelumnya seperti Faster R-CNN:
- Efisiensi: SSD adalah pendeteksi satu tahap, artinya SSD secara langsung memprediksi kotak pembatas dan skor kelas tanpa memerlukan langkah pembuatan proposal terpisah. Hal ini membuatnya lebih cepat dibandingkan dengan detektor dua tahap seperti Faster R-CNN.
- Pelatihan End-to-End: SSD dapat dilatih secara end-to-end, mengoptimalkan jaringan dasar dan kepala deteksi secara bersamaan, sehingga menyederhanakan proses pelatihan.
- Penggabungan Fitur Multiskala: SSD beroperasi pada peta fitur pada berbagai skala, memungkinkannya mendeteksi objek dengan berbagai ukuran dengan lebih efektif.
SSD memberikan keseimbangan yang baik antara kecepatan dan akurasi, sehingga cocok untuk aplikasi real-time yang mengutamakan kinerja dan efisiensi.
Kamu Hanya Melihat Sekali(YOLOv8)
Pada tahun 2015, You Only Look Once (YOLO) diperkenalkan sebagai algoritma pendeteksian objek dalam makalah penelitian oleh Joseph Redmon, Santosh Divvala, Ross Girshick, dan Ali Farhadi. YOLO adalah algoritma single-shot yang secara langsung mengklasifikasikan suatu objek dalam satu lintasan dengan hanya memiliki satu jaringan saraf yang memprediksi kotak pembatas dan probabilitas kelas menggunakan gambar penuh sebagai masukan.
Sekarang, mari kita pahami YOLOv8 sebagai kemajuan tercanggih dalam deteksi objek real-time dengan peningkatan akurasi dan kecepatan. YOLOv8 memungkinkan Anda memanfaatkan model terlatih, yang sudah dilatih pada kumpulan data besar seperti COCO (Common Objects in Context). Segmentasi gambar memberikan informasi tingkat piksel tentang setiap objek, memungkinkan analisis dan pemahaman konten gambar yang lebih detail.
Meskipun segmentasi gambar membutuhkan biaya komputasi yang mahal, YOLOv8 mengintegrasikan metode ini ke dalam arsitektur jaringan sarafnya, sehingga memungkinkan segmentasi objek menjadi efisien dan akurat.
Prinsip Kerja YOLOv8
YOLOv8 bekerja dengan terlebih dahulu membagi gambar input ke dalam sel grid. Dengan menggunakan sel kisi ini, YOLOv8 memprediksi kotak pembatas (bbox) dengan probabilitas kelas.
Setelah itu, YOLOv8 menggunakan algoritma NMS untuk mengurangi tumpang tindih. Misalnya, jika ada beberapa mobil dalam gambar yang mengakibatkan kotak pembatas tumpang tindih, algoritma NMS membantu mengurangi tumpang tindih ini.
Perbedaan varian Yolo V8: YOLOv8 tersedia dalam tiga varian: YOLOv8, YOLOv8-L, dan YOLOv8-X. Perbedaan utama antar varian adalah ukuran jaringan backbone. YOLOv8 memiliki jaringan backbone terkecil, sedangkan YOLOv8-X memiliki jaringan backbone terbesar.
Perbedaan antara R-CNN, SSD, dan YOLO yang Lebih Cepat
| Aspek | Lebih cepat R-CNN | SSD | YOLO |
|---|---|---|---|
| Arsitektur | Detektor dua tahap dengan RPN dan Fast R-CNN | Detektor satu tahap | Detektor satu tahap |
| Proposal Wilayah | Yes | Tidak | Tidak |
| Kecepatan Deteksi | Lebih lambat dibandingkan dengan SSD dan YOLO | Lebih cepat dibandingkan dengan R-CNN Lebih Cepat, lebih lambat dari YOLO | Sangat cepat |
| Ketepatan | Umumnya akurasi lebih tinggi | Akurasi dan kecepatan seimbang | Akurasi yang lumayan, terutama untuk aplikasi real-time |
| keluwesan | Fleksibel, dapat menangani berbagai ukuran objek dan rasio aspek | Dapat menangani berbagai skala objek | Dapat kesulitan dengan lokalisasi objek kecil yang akurat |
| Deteksi Terpadu | Tidak | Tidak | Yes |
| Pengorbanan Kecepatan vs Akurasi | Umumnya mengorbankan kecepatan demi akurasi | Menyeimbangkan kecepatan dan akurasi | Mengutamakan kecepatan dengan tetap menjaga akurasi yang layak |
Apa itu Segmentasi?
Seperti kita ketahui segmentasi berarti kita membagi gambar besar menjadi kelompok-kelompok kecil berdasarkan ciri-ciri tertentu. Mari kita pahami segmentasi gambar yang merupakan teknik visi komputer yang digunakan untuk mempartisi gambar menjadi beberapa segmen atau wilayah berbeda. Karena gambar terbuat dari piksel dan Dalam segmentasi Gambar, piksel dikelompokkan berdasarkan kesamaan warna, intensitas, tekstur, atau properti visual lainnya.
Misalnya, jika suatu gambar berisi pohon, mobil, atau orang, maka segmentasi gambar akan membagi gambar tersebut ke dalam kelas-kelas berbeda yang mewakili objek atau bagian gambar yang bermakna. Segmentasi gambar banyak digunakan di berbagai bidang seperti pencitraan medis, analisis citra satelit, pengenalan objek dalam visi komputer, dan banyak lagi.

Pada bagian segmentasi, awalnya kami membuat model segmentasi YOLOv8 pertama menggunakan Robflow. Kemudian, kami mengimpor model segmentasi untuk melakukan tugas segmentasi. Timbul pertanyaan: mengapa kita membuat model segmentasi ketika tugas dapat diselesaikan hanya dengan algoritma deteksi?
Segmentasi memungkinkan kita memperoleh gambaran seluruh tubuh suatu kelas. Meskipun algoritma deteksi fokus pada pendeteksian keberadaan objek, segmentasi memberikan pemahaman yang lebih tepat dengan menggambarkan batas objek secara tepat. Hal ini mengarah pada lokalisasi dan pemahaman yang lebih akurat tentang objek yang ada dalam gambar.
Namun, segmentasi biasanya melibatkan kompleksitas waktu yang lebih tinggi dibandingkan dengan algoritme deteksi karena memerlukan langkah tambahan seperti memisahkan anotasi dan membuat model. Terlepas dari kelemahan ini, peningkatan presisi yang ditawarkan oleh segmentasi dapat melebihi biaya komputasi dalam tugas-tugas yang memerlukan penggambaran objek yang tepat.
Deteksi Langsung Langkah demi Langkah dan Segmentasi Gambar Dengan YOLOv8
Dalam konsep ini kita akan mengeksplorasi langkah-langkah untuk membuat lingkungan virtual menggunakan conda, mengaktifkan venv dan menginstal paket persyaratan menggunakan pip. pertama buat script python normal lalu kita buat aplikasi streamlit.
Langkah1: Buat Lingkungan Virtual menggunakan Conda
conda create -p ./venv python=3.8 -yLangkah2: Aktifkan Lingkungan Virtual
conda activate ./venv
Langkah3: Buat persyaratan.txt
Buka terminal dan tempel skrip di bawah ini:
touch requirements.txtLangkah4: Gunakan Perintah Nano dan Edit persyaratan.txt
Setelah membuat persyaratan.txt, masukkan perintah berikut untuk mengedit persyaratan.txt
nano requirements.txtSetelah menjalankan skrip di atas Anda dapat melihat UI ini.
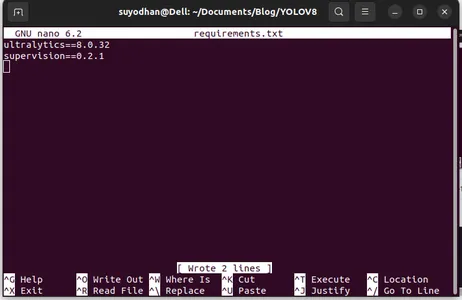
Tulis paket yang diperlukan untuknya.
ultralytics==8.0.32
supervision==0.2.1
streamlitKemudian tekan tombol “ctrl+o”(perintah ini menyimpan bagian pengeditan) lalu Tekan "Memasukkan"
Setelah menekan tombol “Ctrl+x”. Anda dapat keluar dari file. dan pergi ke jalan utama.
Langkah5: Menginstal persyaratan.txt
pip install -r requirements.txtLangkah6: Buat Skrip Python
Di terminal tulis skrip berikut atau kita bisa mengucapkan perintah.
touch main.pySetelah membuat main.py buka kode vs Anda menggunakan perintah tulis di terminal,
code Langkah7: Menulis Skrip Python
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
Setelah menjalankan perintah ini Anda dapat melihat kamera Anda terbuka dan mendeteksi bagian dari diri Anda. seperti gender dan bagian latar belakang.
Langkah7: Buat Aplikasi streamlit
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
Dalam skrip ini, kami membuat aplikasi streamlit dan membuat tombol sehingga setelah menekan tombol, kamera perangkat Anda terbuka dan mendeteksi bagian dalam bingkai.
Jalankan skrip ini menggunakan perintah ini.
streamlit run app.py
# first create the app.py then paste the above code and run this script.Setelah menjalankan perintah di atas, misalkan Anda mendapatkan kesalahan jangkauan seperti,
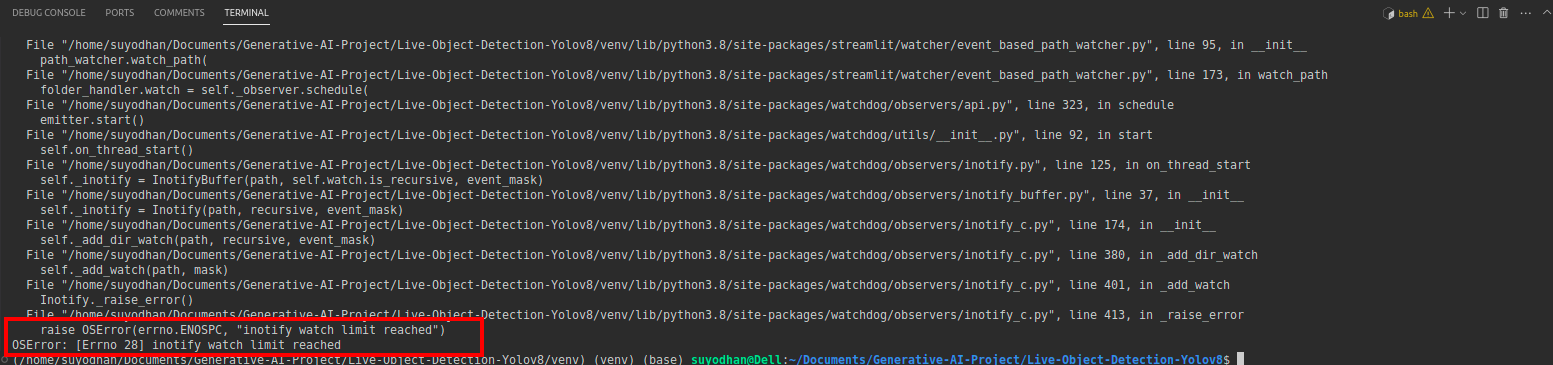
lalu tekan perintah ini,
sudo sysctl fs.inotify.max_user_watches=524288Setelah menekan perintah yang ingin Anda tuliskan kata sandi Anda karena kami menggunakan perintah sudo sudo is god :)
Jalankan skrip lagi. dan Anda dapat melihat aplikasi streamlit.
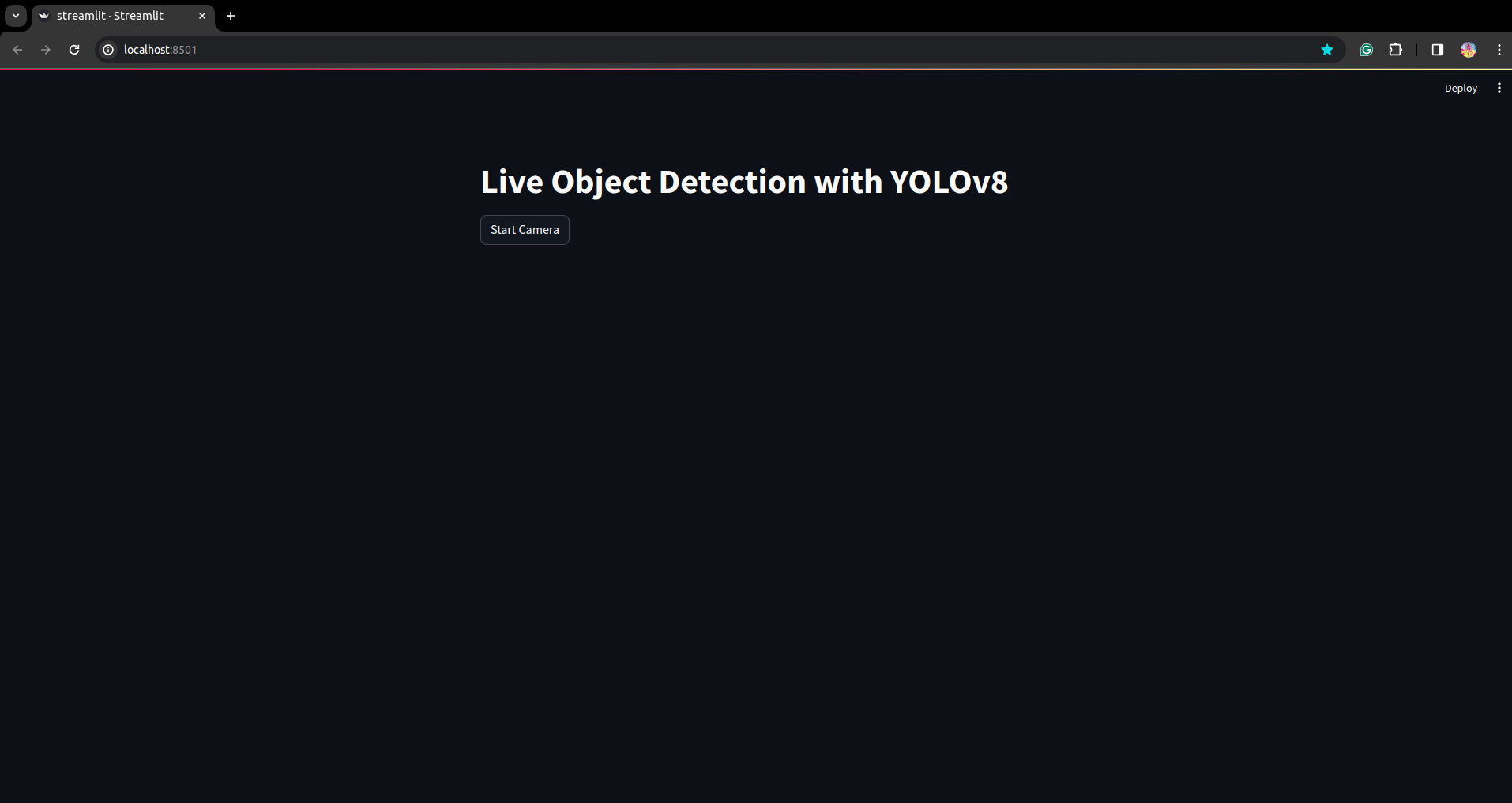
Di sini kita dapat membuat aplikasi deteksi langsung yang sukses. Pada bagian selanjutnya kita akan melihat bagian segmentasi.
Langkah-Langkah Untuk Anotasi
Langkah1: Pengaturan Roboflow
Setelah menandatangani “Buat Proyek”. di sini Anda dapat membuat proyek dan grup anotasi.

Langkah2: Pengunduhan Kumpulan Data
Di sini kita mempertimbangkan contoh sederhana tetapi Anda ingin menggunakannya pada pernyataan masalah Anda, jadi saya menggunakan kumpulan data bebek di sini.
Lakukan ini link dan unduh kumpulan data bebek.

Ekstrak foldernya di sana Anda dapat melihat tiga folder: melatih, menguji dan val.
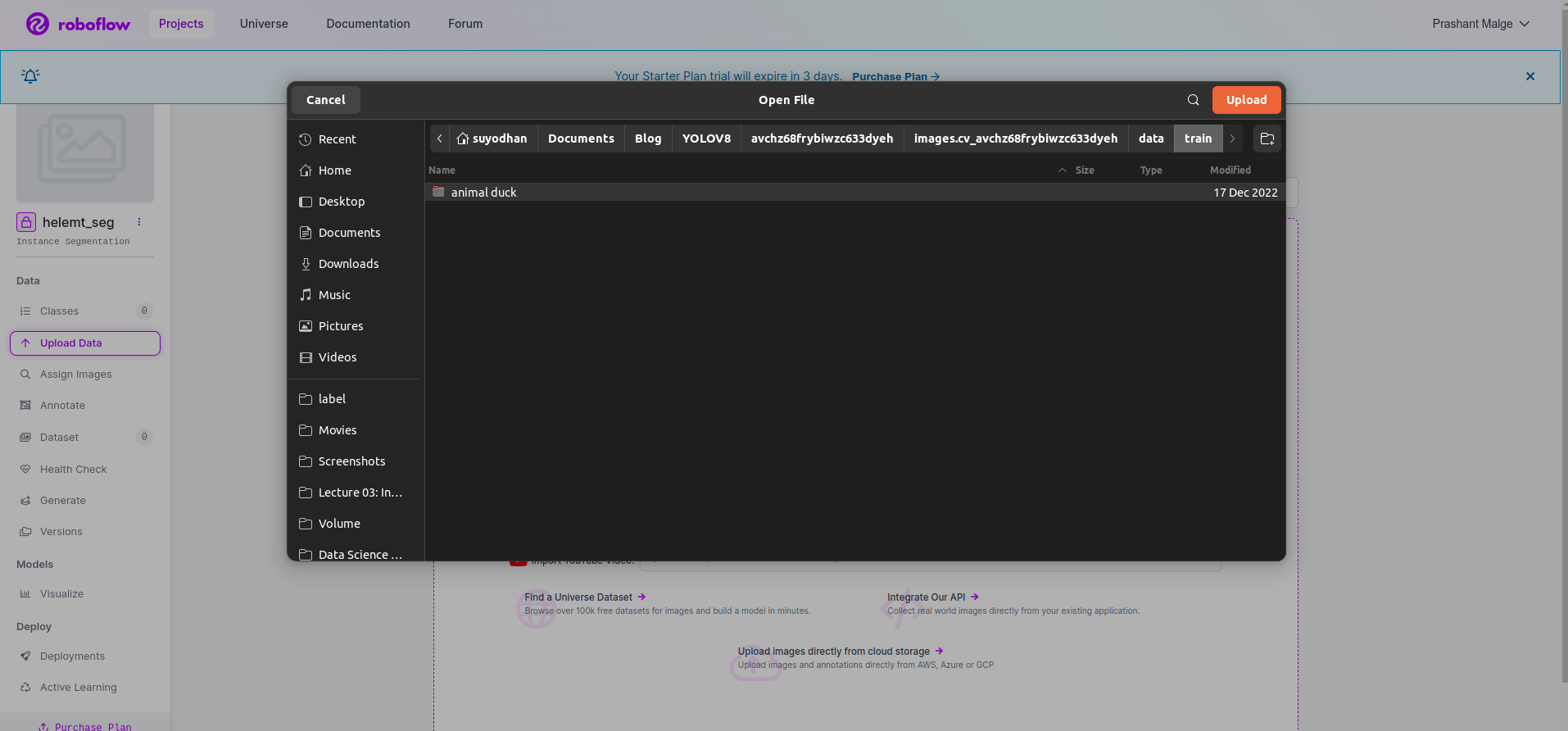
Langkah3: Mengunggah Kumpulan Data di roboflow
Setelah membuat proyek di roboflow Anda dapat melihat UI ini di sini Anda dapat mengunggah kumpulan data Anda sehingga hanya mengunggah gambar bagian kereta pilih "Pilih folder" .
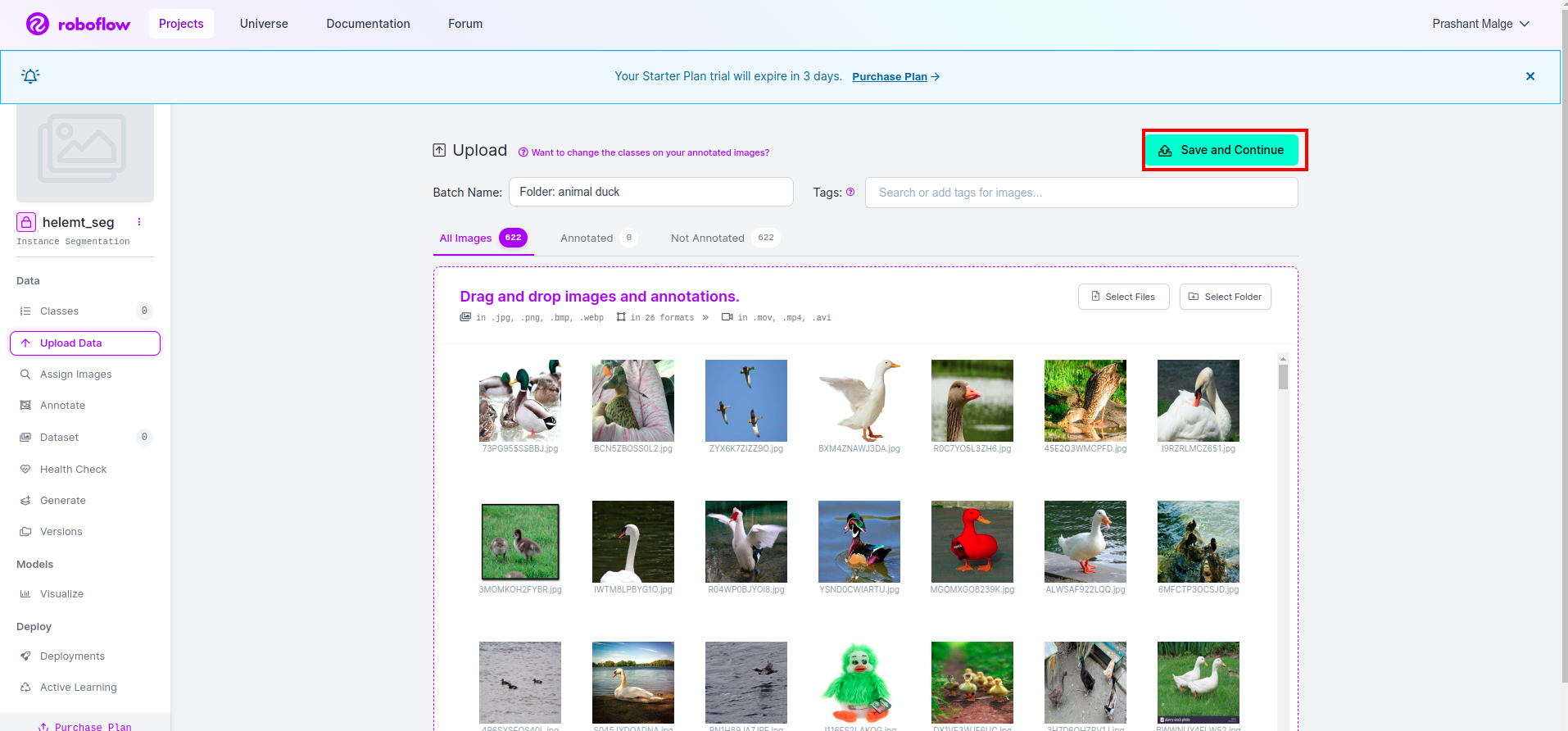
Kemudian klik "Simpan dan Lanjutkan" pilihan seperti yang saya tandai di kotak persegi panjang merah
Langkah4: Tambahkan Nama Kelas
Lalu pergi ke bagian kelas di sisi kiri centang kotak merah. dan tulis nama kelas sebagai bebek, setelah mengklik kotak hijau.
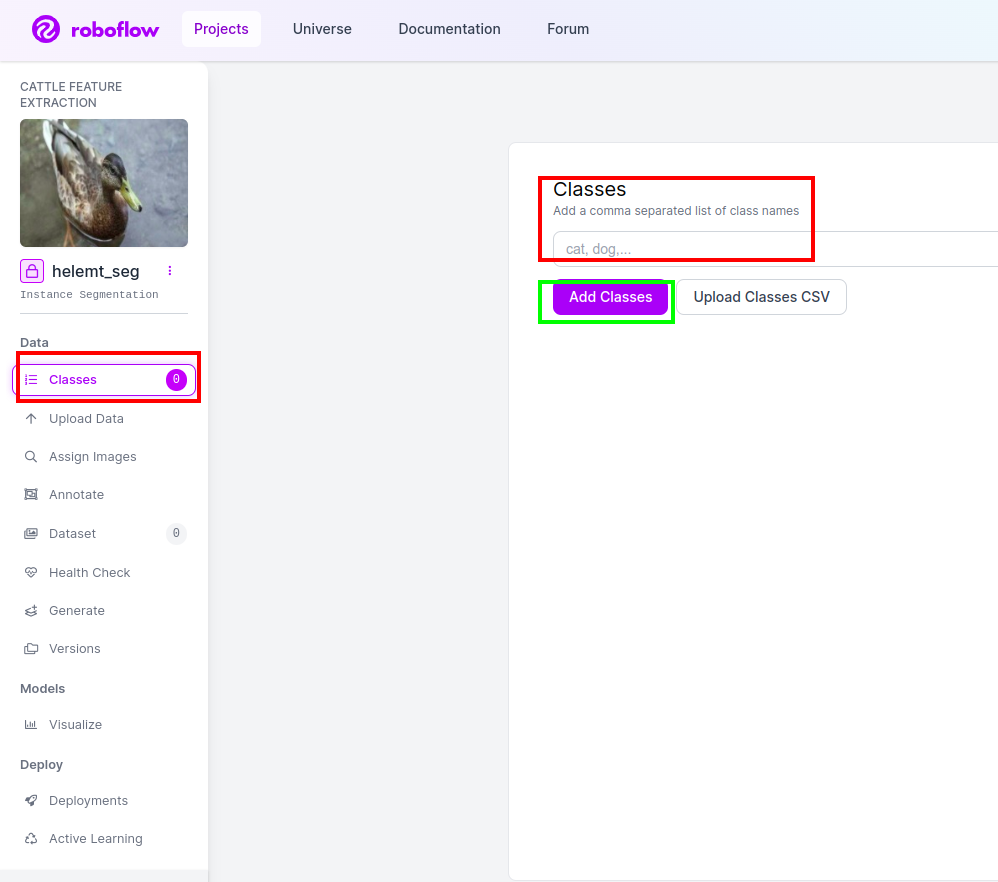
Sekarang pengaturan kita sudah selesai dan bagian selanjutnya seperti bagian anotasi juga sederhana.
Langkah5: Mulai bagian anotasi
Pergi ke opsi anotasi Saya tandai di kotak merah lalu klik mulai bagian annoataion seperti yang saya tandai di kotak hijau.
Klik gambar pertama Anda dapat melihat UI ini. Setelah melihat ini klik opsi anotasi manual.
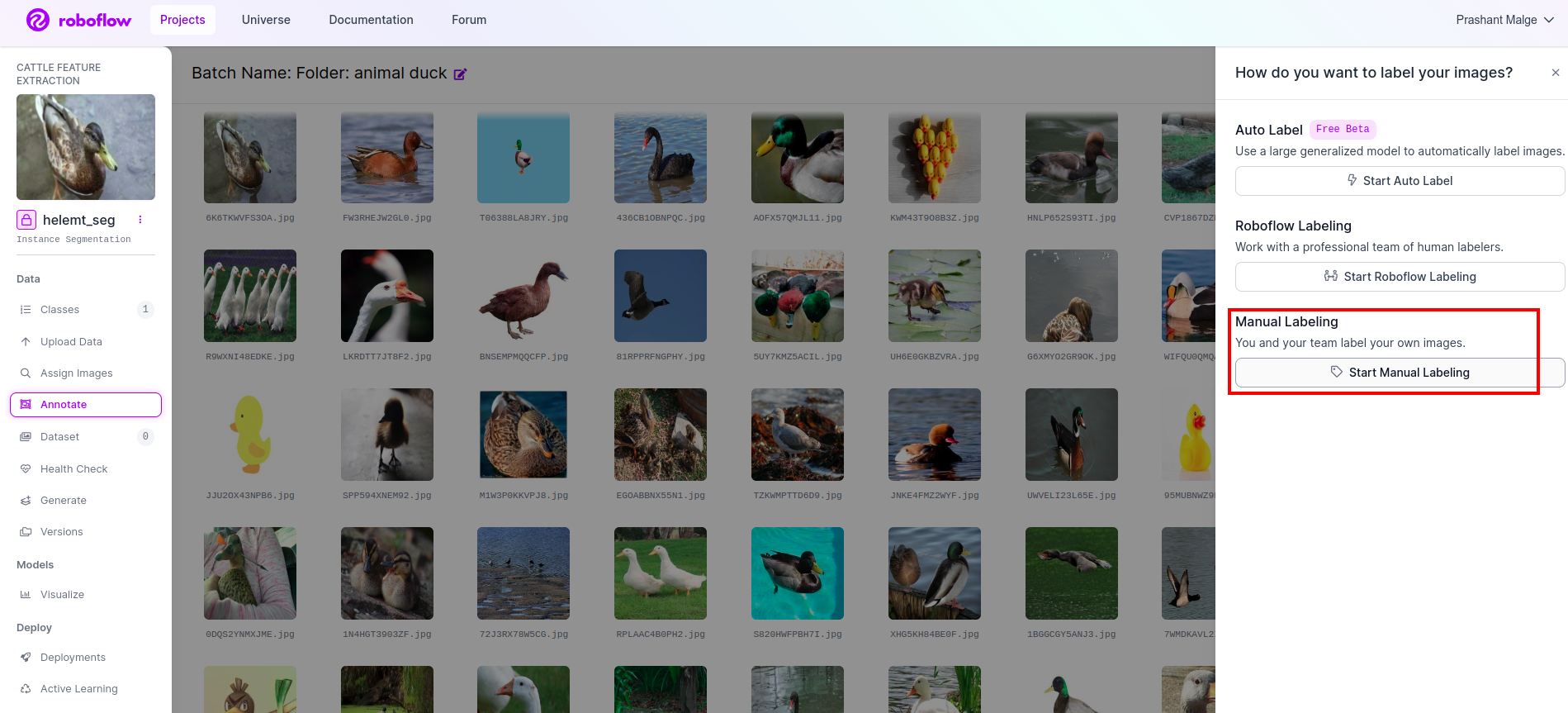
Kemudian tambahkan id email Anda atau nama rekan satu tim Anda sehingga Anda dapat menetapkan tugas.
Klik gambar pertama Anda dapat melihat UI ini. di sini klik kotak merah sehingga Anda dapat memilih model multi-polinomial.
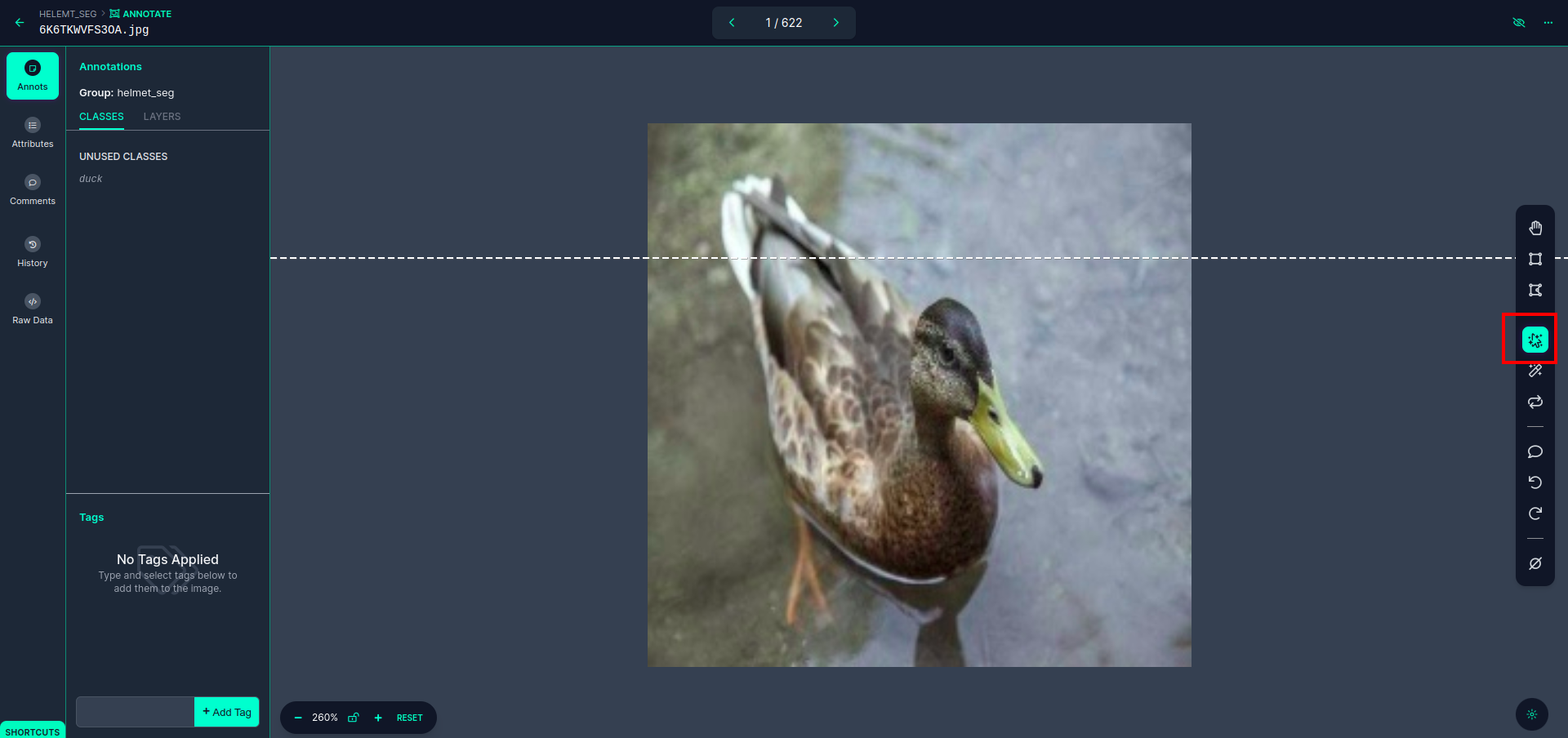
Setelah klik kotak merah, pilih model default dan klik objek bebek. Ini secara otomatis akan mengelompokkan gambar. Kemudian, klik pada bagian selanjutnya dan simpan. Anda kemudian akan melihat sisi kiri ditandai dengan kotak merah, di mana Anda dapat melihat nama kelas.
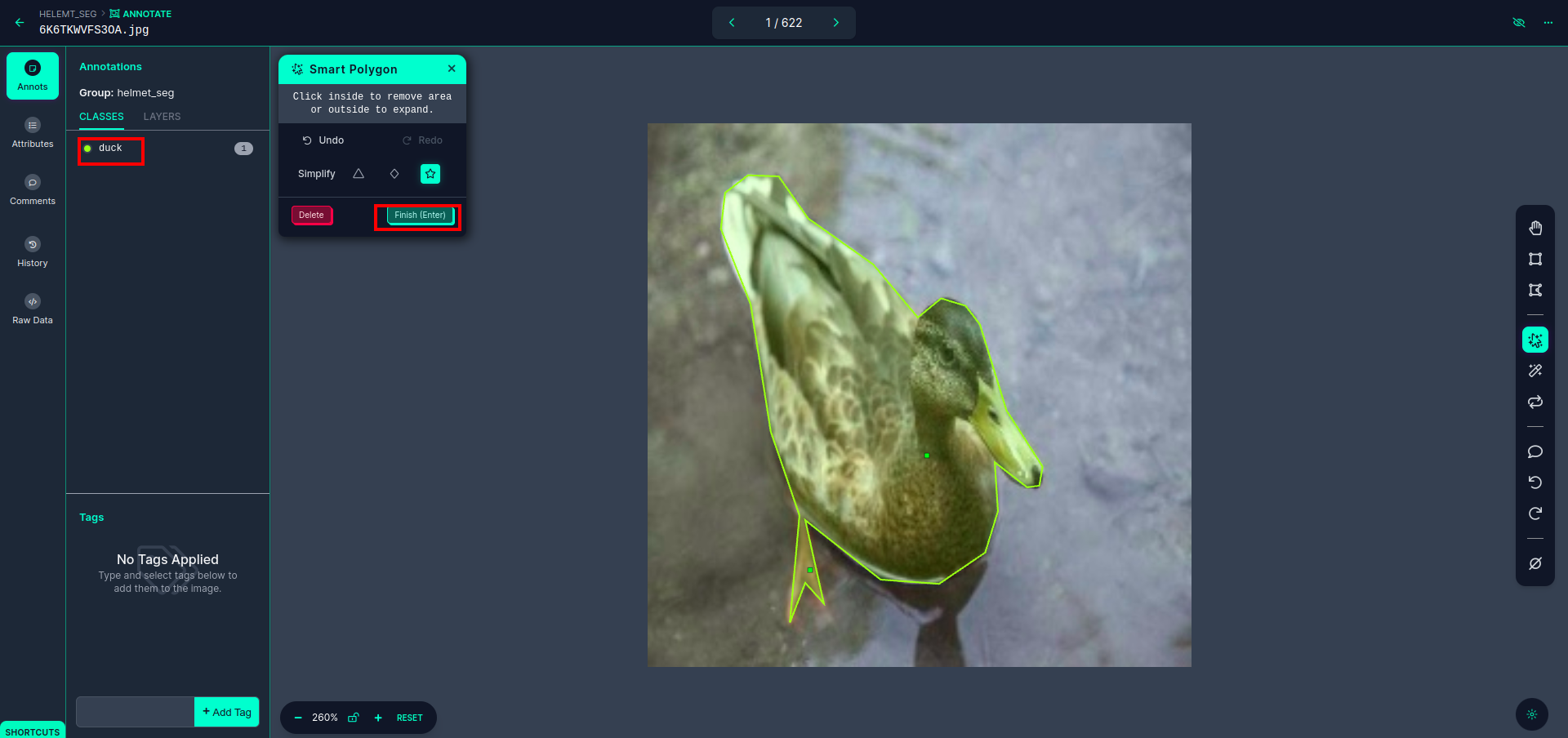
klik simpan & masuk pilihan. beri anotasi pada semua gambar.
Tambahkan gambar untuk format YOLOv8. Di sisi kanan, Anda akan melihat opsi untuk menambahkan gambar di bagian anotasi. Di sini, dua bagian dibuat: satu untuk gambar beranotasi dan satu lagi untuk gambar tanpa anotasi.
- Pertama, klik sisi kiri “membubuhi keterangan" pilihan lalu menambahkan gambar ke kumpulan data.
- Kemudian klik berikutnya “Tambahkan Gambar".
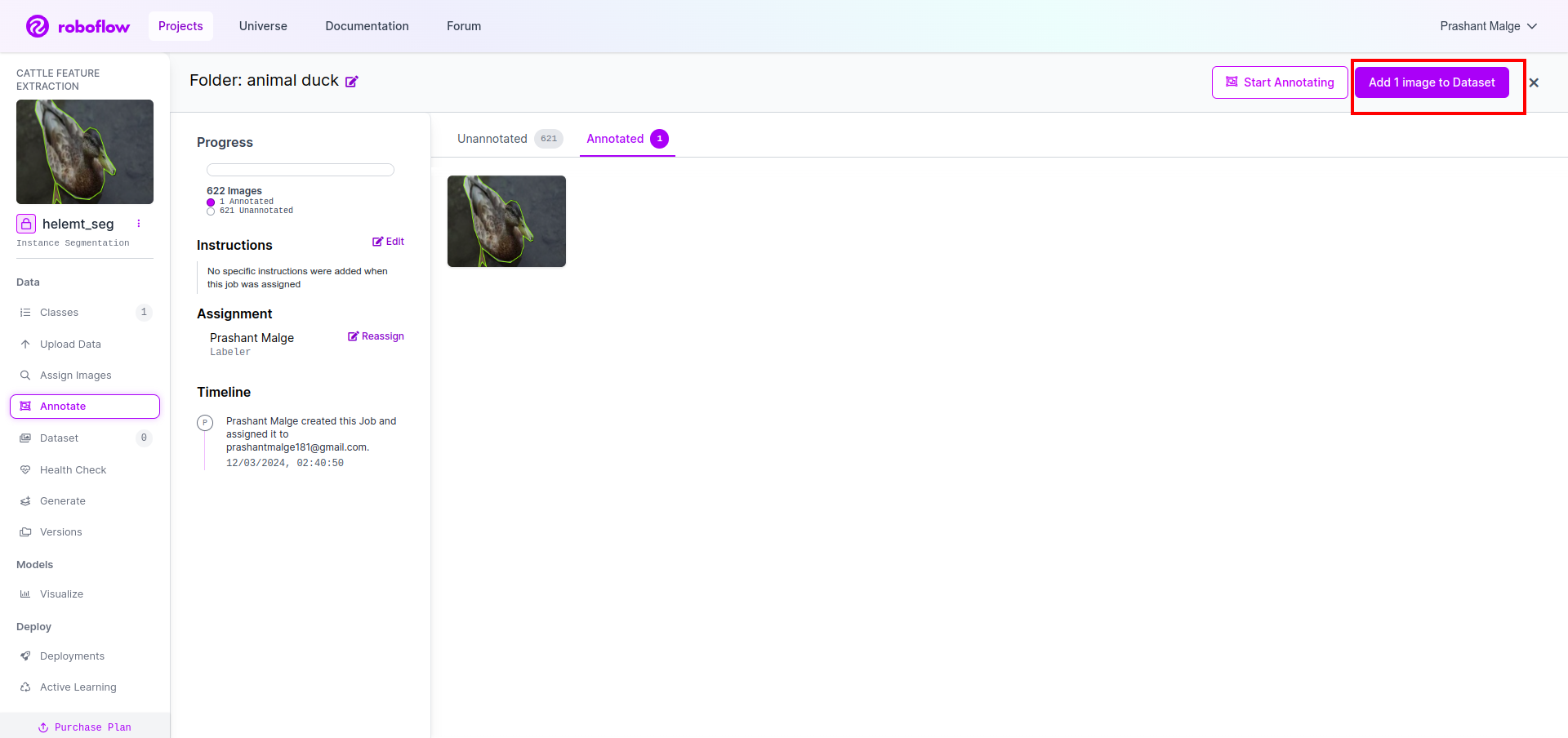
Sekarang terakhir, kita membuat dataset jadi klik opsi “Generate” di sisi kiri lalu centang opsi dan tekan opsi conitune.
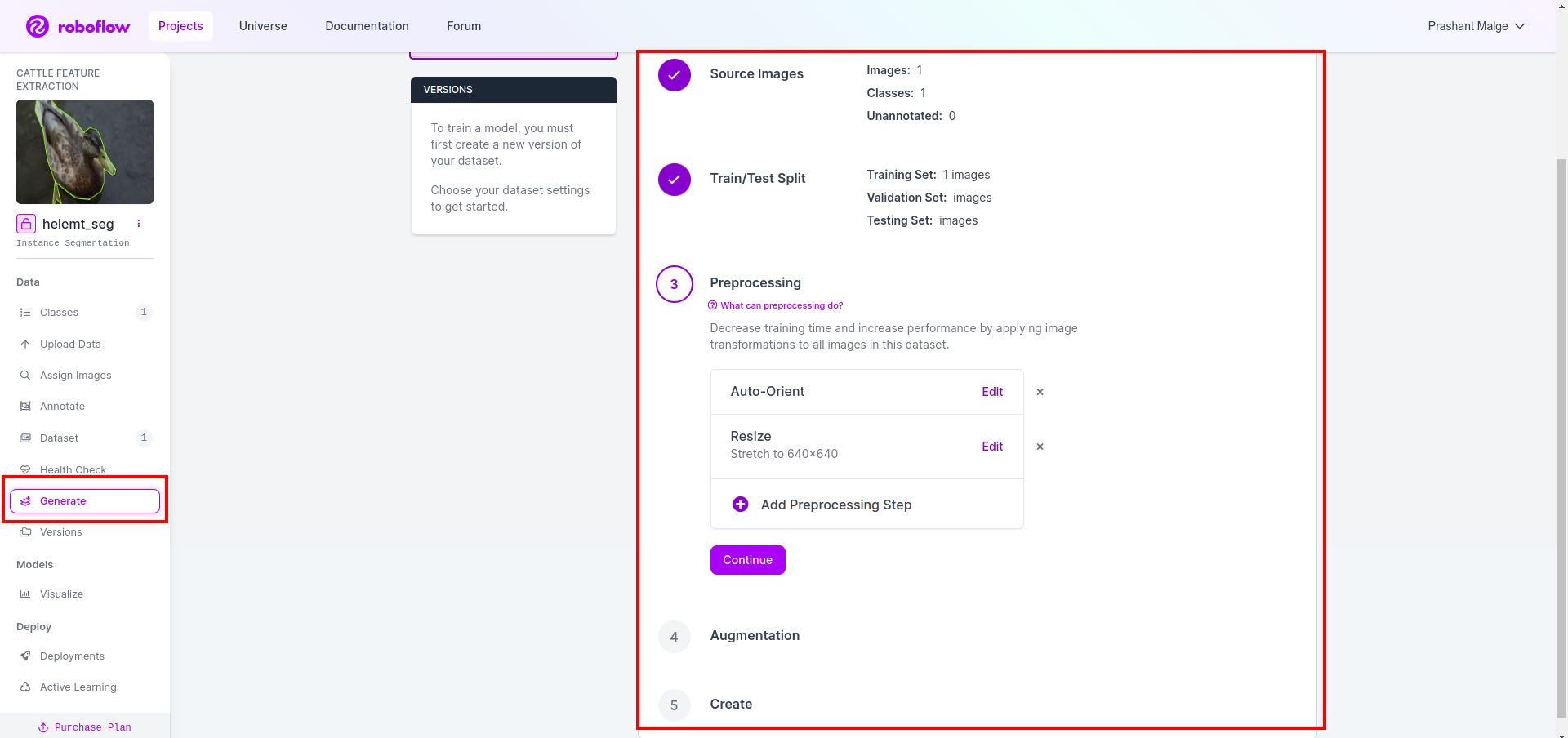
Kemudian Anda mendapatkan UI opsi pemisahan kumpulan data di sini Anda dapat memeriksa folder kereta, pengujian, dan val, gambarnya dipisahkan secara otomatis. dan klik kotak merah di atas Opsi Ekspor Kumpulan Data dan unduh file zipnya. struktur folder file zip seperti…
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
Langkah6: Tulis skrip untuk melatih model segmentasi gambar
Pada bagian ini pertama, Anda membuat file Google Collab menggunakan Drive lalu mengupload dataset Anda. dan arahkan Google Drive menggunakan Google Collab.
1. Gunakan perintah ini untuk Pasang Google Drive
from google.colab import drive
drive.mount('/content/gdrive')2. Tentukan direktori data Gunakan variabel Konstan.
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. Menginstal paket yang diperlukan, Instal ultralitik
!pip install ultralytics4. Mengimpor perpustakaan
import os
from ultralytics import YOLO5. Memuat YOLOv8 yang telah dilatih sebelumnya model (di sini kami memiliki model yang berbeda, periksa juga dokumentasi resmi di sana Anda dapat melihat model yang berbeda)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. Latih Model
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together Tidak periksa drive Anda Folder nama model dibuat dan di sana model disimpan untuk prediksi yang kita inginkan model ini.
7. Prediksi Modelnya
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)Di sini Anda dapat melihat gambar segmentasi disimpan.

Sekarang akhirnya kita dapat membangun model deteksi langsung dan segmentasi gambar.
Kesimpulan
Di blog ini, kami mengeksplorasi deteksi objek langsung dan segmentasi gambar dengan YOLOv8. Untuk deteksi langsung, kami mengimpor model YOLOv8 terlatih dan memanfaatkan perpustakaan visi komputer, OpenCV, untuk membuka kamera dan mendeteksi objek. Selain itu, kami membuat aplikasi Streamlit untuk antarmuka pengguna yang menarik.
Selanjutnya, kita mempelajari segmentasi gambar dengan YOLOv8. Kami mengimpor model terlatih dan melakukan pembelajaran transfer pada kumpulan data khusus. Sebelumnya, kami menjelajahi Roboflow untuk anotasi kumpulan data, memberikan alternatif yang mudah digunakan untuk alat seperti LabelImg.
Terakhir, kami memprediksi gambar yang berisi bebek. Meskipun objek dalam gambar tampak seperti burung, kami menentukan nama kelasnya sebagai “bebek” untuk tujuan demonstrasi.
Pengambilan Kunci
- Mempelajari model deteksi objek seperti Faster R-CNN, SSD, dan YOLOv8 terbaru.
- Memahami alat anotasi Roboflow dan perannya dalam membuat kumpulan data untuk model segmentasi YOLOv8.
- Menjelajahi deteksi objek langsung menggunakan OpenCV (cv2) dan Supervision, meningkatkan keterampilan praktis.
- Melatih dan menerapkan model segmentasi menggunakan YOLOv8, mendapatkan pengalaman langsung.
Tanya Jawab Umum (FAQ)
A. Deteksi objek melibatkan identifikasi dan penempatan beberapa objek dalam suatu gambar, biasanya dengan menggambar kotak pembatas di sekelilingnya. Segmentasi gambar, di sisi lain, membagi gambar menjadi segmen atau wilayah berdasarkan kesamaan piksel, sehingga memberikan pemahaman yang lebih rinci tentang batas objek.
A. YOLOv8 menyempurnakan versi sebelumnya dengan menggabungkan kemajuan dalam arsitektur jaringan, teknik pelatihan, dan pengoptimalan. Ini mungkin menawarkan akurasi, kecepatan, dan efisiensi yang lebih baik dibandingkan dengan YOLOv3.
A. YOLOv8 dapat digunakan untuk deteksi objek real-time pada perangkat yang disematkan, bergantung pada kemampuan perangkat keras dan pengoptimalan model. Namun, hal ini mungkin memerlukan pengoptimalan seperti pemangkasan model atau kuantisasi untuk mencapai kinerja real-time pada perangkat dengan sumber daya terbatas.
A. Roboflow menawarkan alat anotasi intuitif, fitur manajemen kumpulan data, dan dukungan untuk berbagai format anotasi. Ini menyederhanakan proses anotasi, memungkinkan kolaborasi, dan menyediakan kontrol versi, sehingga memudahkan pembuatan dan pengelolaan kumpulan data untuk proyek visi komputer.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://www.analyticsvidhya.com/blog/2024/03/live-object-detection-and-image-segmentation-with-yolov8/

