Pengantar
Retrieval Augmented-Generation (RAG) telah menguasai dunia sejak awal. RAG diperlukan untuk Model Bahasa Besar (LLM) untuk memberikan atau menghasilkan jawaban yang akurat dan faktual. Kami memecahkan faktualitas LLM dengan RAG, di mana kami mencoba memberikan LLM konteks yang secara kontekstual mirip dengan permintaan pengguna sehingga LLM akan bekerja dengan konteks ini dan menghasilkan respons yang benar secara faktual. Kami melakukan ini dengan merepresentasikan data dan kueri pengguna kami dalam bentuk penyematan vektor dan melakukan kesamaan kosinus. Namun masalahnya adalah semua pendekatan tradisional mewakili data dalam satu penyematan, yang mungkin tidak ideal untuk selamanya sistem pengambilan. Dalam panduan ini, kita akan melihat ColBERT yang melakukan pengambilan dengan akurasi lebih baik daripada model bi-encoder tradisional.
Tujuan Pembelajaran
- Pahami cara kerja pengambilan di RAG pada tingkat tinggi.
- Pahami batasan penyematan tunggal dalam pengambilan.
- Tingkatkan konteks pengambilan dengan penyematan token ColBERT.
- Pelajari bagaimana interaksi ColBERT yang terlambat meningkatkan pengambilan.
- Ketahui cara bekerja dengan ColBERT untuk pengambilan yang akurat.
Artikel ini diterbitkan sebagai bagian dari Blogathon Ilmu Data.
Daftar Isi
Apa itu RAG?
LLM, meskipun mampu menghasilkan teks yang bermakna dan benar secara tata bahasa, LLM ini mengalami masalah yang disebut halusinasi. Halusinasi di LLM adalah konsep di mana LLM dengan percaya diri menghasilkan jawaban yang salah, yaitu mereka membuat jawaban yang salah dengan cara yang membuat kita yakin bahwa jawaban tersebut benar. Ini telah menjadi masalah besar sejak diperkenalkannya LLM. Halusinasi ini mengarah pada jawaban yang salah dan salah secara faktual. Oleh karena itu Retrieval Augmented Generation diperkenalkan.
Di RAG, kami mengambil daftar dokumen/potongan dokumen dan mengkodekan dokumen tekstual ini ke dalam representasi numerik yang disebut penyematan vektor, di mana satu penyematan vektor mewakili satu potongan dokumen dan menyimpannya dalam database yang disebut toko vektor. Model yang diperlukan untuk mengkodekan potongan-potongan ini ke dalam embeddings disebut model pengkodean atau bi-encoder. Pembuat enkode ini dilatih pada kumpulan data yang besar, sehingga membuatnya cukup kuat untuk menyandikan potongan dokumen dalam satu representasi penyematan vektor.
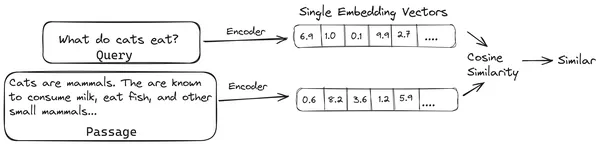
Sekarang ketika pengguna menanyakan kueri ke LLM, maka kami memberikan kueri ini ke pembuat enkode yang sama untuk menghasilkan penyematan vektor tunggal. Penyematan ini kemudian digunakan untuk menghitung skor kemiripan dengan berbagai penyematan vektor lainnya pada potongan dokumen untuk mendapatkan potongan dokumen yang paling relevan. Potongan paling relevan atau daftar potongan paling relevan bersama dengan permintaan pengguna diberikan ke LLM. LLM kemudian menerima informasi kontekstual tambahan ini dan kemudian menghasilkan jawaban yang selaras dengan konteks yang diterima dari permintaan pengguna. Hal ini memastikan bahwa konten yang dihasilkan oleh LLM adalah faktual dan dapat ditelusuri kembali jika diperlukan.
Masalah dengan Bi-Encoder Tradisional
Masalah dengan model Encoder tradisional seperti all-miniLM, OpenAI model penyematan, dan model pembuat enkode lainnya adalah model tersebut memampatkan seluruh teks menjadi representasi penyematan vektor tunggal. Representasi penyematan vektor tunggal ini berguna karena membantu pengambilan dokumen serupa secara efisien dan cepat. Namun, masalahnya terletak pada kontekstualitas antara kueri dan dokumen. Penyematan vektor tunggal mungkin tidak cukup untuk menyimpan informasi kontekstual dari potongan dokumen, sehingga menciptakan hambatan informasi.
Bayangkan 500 kata dikompresi menjadi satu vektor berukuran 782. Ini mungkin tidak cukup untuk mewakili potongan tersebut dengan penyematan vektor tunggal, sehingga memberikan hasil pengambilan di bawah standar di sebagian besar kasus. Representasi vektor tunggal juga mungkin gagal jika ada kueri atau dokumen yang kompleks. Salah satu solusinya adalah dengan merepresentasikan potongan dokumen atau kueri sebagai daftar vektor penyematan, bukan vektor penyematan tunggal, di sinilah ColBERT berperan.
Apa itu ColBERT?
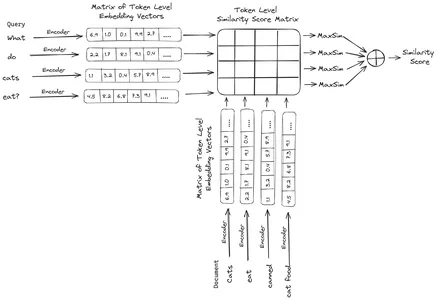
ColBERT (Contextual Late Interactions BERT) adalah bi-encoder yang merepresentasikan teks dalam representasi penyematan multi-vektor. Dibutuhkan Query atau potongan Dokumen/Dokumen kecil dan membuat penyematan vektor di tingkat token. Artinya, setiap token mendapatkan penyematan vektornya sendiri, dan kueri/dokumen dikodekan ke daftar penyematan vektor tingkat token. Penyematan tingkat token dihasilkan dari yang telah dilatih sebelumnya BERTI model maka nama BERT.
Ini kemudian disimpan dalam database vektor. Sekarang, ketika kueri masuk, daftar penyematan tingkat token dibuat untuk kueri tersebut dan kemudian perkalian matriks dilakukan antara kueri pengguna dan setiap dokumen, sehingga menghasilkan matriks yang berisi skor kesamaan. Kesamaan keseluruhan dicapai dengan mengambil jumlah kesamaan maksimum di seluruh token dokumen untuk setiap token kueri. Rumusnya dapat dilihat pada gambar di bawah ini:
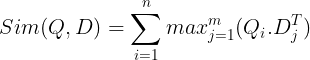
Di sini, dalam persamaan di atas, kita melihat bahwa kita melakukan perkalian titik antara Matriks Token Kueri (berisi N penyematan vektor tingkat token) dan Matriks Transpose Token Dokumen (berisi penyematan vektor tingkat token M), dan kemudian kita mengambil kesamaan maksimum silangkan token dokumen untuk setiap token kueri. Lalu kami menjumlahkan semua kesamaan maksimum ini, yang memberi kami skor kesamaan akhir antara dokumen dan kueri. Alasan mengapa hal ini menghasilkan pengambilan yang efektif dan akurat adalah, karena di sini kita mengalami interaksi tingkat token, yang memberikan ruang untuk pemahaman yang lebih kontekstual antara kueri dan dokumen.
Mengapa Nama ColBERT?
Karena kita menghitung daftar vektor penyematan sebelumnya dan hanya melakukan operasi MaxSim (kesamaan maksimum) ini selama inferensi model, sehingga menyebutnya sebagai langkah interaksi yang terlambat, dan karena kita mendapatkan lebih banyak informasi kontekstual melalui interaksi tingkat token, maka ini disebut kontekstual interaksi terlambat. Demikianlah namanya Interaksi Terlambat Kontekstual BERTI atau ColBERT. Perhitungan ini dapat dilakukan secara paralel sehingga dapat dihitung secara efisien. Terakhir, salah satu kekhawatirannya adalah ruang, yaitu memerlukan banyak ruang untuk menyimpan daftar penyematan vektor tingkat token ini. Masalah ini diselesaikan di ColBERTv2, di mana embeddings dikompresi melalui teknik yang disebut kompresi sisa, sehingga mengoptimalkan ruang yang digunakan.
ColBERT Praktis dengan Contoh
Di bagian ini, kita akan mempelajari langsung ColBERT dan bahkan memeriksa kinerjanya dibandingkan model penyematan biasa.
Langkah 1: Unduh Perpustakaan
Kami akan mulai dengan mengunduh perpustakaan berikut:
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- RAGatouille: Perpustakaan ini memungkinkan kami bekerja dengan metode pengambilan tercanggih (SOTA) seperti ColBERT dengan cara yang mudah digunakan. Ini memberikan opsi untuk membuat indeks pada kumpulan data, menanyakannya, dan bahkan memungkinkan kita untuk melatih model ColBERT pada data kita.
- Rantai Lang: Pustaka ini memungkinkan kita bekerja dengan model penyematan sumber terbuka sehingga kita dapat menguji seberapa baik model penyematan lainnya bekerja jika dibandingkan dengan ColBERT.
- langchain_openai: Menginstal LangChain ketergantungan untuk OpenAI. Kami bahkan akan bekerja dengan model OpenAI Embedding untuk memeriksa kinerjanya terhadap ColBERT.
- ChromaDB: Pustaka ini memungkinkan kita membuat penyimpanan vektor di lingkungan kita sehingga kita dapat menyimpan penyematan yang telah kita buat pada data kita dan kemudian melakukan pencarian semantik antara kueri dan penyematan yang disimpan.
- einops: Pustaka ini diperlukan untuk perkalian matriks tensor yang efisien.
- pengubah kalimat dan tiktoken perpustakaan diperlukan agar model penyematan sumber terbuka dapat berfungsi dengan baik.
Langkah 2: Unduh Model Terlatih sebelumnya
Pada langkah selanjutnya, kita akan mengunduh model ColBERT yang telah dilatih sebelumnya. Untuk ini, kodenya adalah
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- Pertama-tama kita mengimpor kelas RAGPretrainedModel dari perpustakaan RAGatouille.
- Kemudian kita memanggil .from_pretrained() dan memberi nama model yaitu “colbert-ir/colbertv2.0”.
Menjalankan kode di atas akan membuat instance model ColBERT RAG. Sekarang mari kita unduh halaman Wikipedia dan lakukan pengambilan dari halaman tersebut. Untuk ini, kodenya adalah:
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])RAGatouille hadir dengan fungsi praktis yang disebut get_wikipedia_page yang mengambil string dan mendapatkan halaman Wikipedia yang sesuai. Di sini kita mengunduh konten Wikipedia di Elon Musk dan menyimpannya dalam dokumen variabel. Mari kita cetak jumlah kata yang ada dalam dokumen dan beberapa baris pertama dokumen.
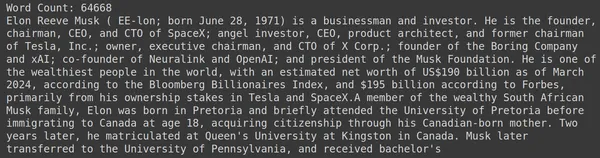
Di sini kita dapat melihat outputnya di gambar. Kita bisa melihat total ada 64,668 kata di halaman Wikipedia Elon Musk.
Langkah 3: Pengindeksan
Sekarang kita akan membuat indeks pada dokumen ini.
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)Di sini kita memanggil .index() dari RAG untuk mengindeks dokumen kita. Untuk ini, kami menyampaikan hal berikut:
- koleksi: Ini adalah daftar dokumen yang ingin kami indeks. Di sini kita hanya memiliki satu dokumen, sehingga merupakan daftar satu dokumen.
- dokumen_id: Setiap dokumen mengharapkan ID dokumen unik. Di sini kami memberikan nama elon_musk karena dokumen tersebut tentang Elon Musk.
- dokumen_metadata: Setiap dokumen memiliki metadatanya sendiri. Sekali lagi ini adalah daftar kamus, di mana setiap kamus berisi metadata pasangan nilai kunci untuk dokumen tertentu.
- nama_indeks: Nama indeks yang kita buat. Sebut saja Elon2.
- ukuran_dokumen_maks: Ini mirip dengan ukuran potongan. Kami menentukan berapa banyak seharusnya setiap potongan dokumen. Di sini kita memberinya nilai 256. Jika kita tidak menentukan nilai apa pun, 256 akan diambil sebagai ukuran potongan default.
- split_dokumen: Ini adalah nilai boolean, di mana True menunjukkan bahwa kita ingin membagi dokumen kita sesuai dengan ukuran potongan yang diberikan, dan False menunjukkan bahwa kita ingin menyimpan seluruh dokumen sebagai satu potongan.
Menjalankan kode di atas akan memotong dokumen kita dalam ukuran 256 per potongan, kemudian menyematkannya melalui model ColBERT, yang akan menghasilkan daftar penyematan vektor tingkat token untuk setiap potongan dan akhirnya menyimpannya dalam indeks. Langkah ini akan memakan sedikit waktu untuk dijalankan dan dapat dipercepat jika memiliki GPU. Terakhir, ini membuat direktori tempat indeks kita disimpan. Di sini direktorinya adalah “.ragatouille/colbert/indexes/Elon2”
Langkah 4: Pertanyaan Umum
Sekarang, kita akan memulai pencarian. Untuk ini, kodenya adalah
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- Di sini, pertama-tama, kita memanggil metode .search() dari objek RAG
- Untuk ini, kami memberikan variabel yang mencakup nama kueri, k (jumlah dokumen yang akan diambil), dan nama indeks yang akan dicari
- Di sini kami memberikan pertanyaan “Perusahaan apa yang ditemukan Elon Musk?”. Hasil yang diperoleh akan berupa daftar format kamus yang berisi kunci-kunci seperti konten, skor, peringkat, id_dokumen, id_bagian, dan metadata_dokumen
- Oleh karena itu kami bekerja dengan kode di bawah ini untuk mencetak dokumen yang diambil dengan cara yang rapi
- Di sini kita melihat daftar kamus dan mencetak isi dokumen
Menjalankan kode akan menghasilkan hasil sebagai berikut:
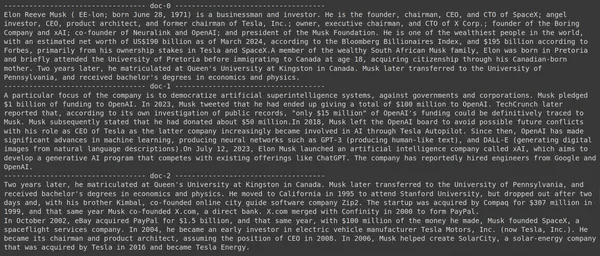
Dalam gambar tersebut, kita dapat melihat bahwa dokumen pertama dan terakhir sepenuhnya mencakup berbagai perusahaan yang didirikan oleh Elon Musk. ColBERT dapat mengambil dengan benar potongan relevan yang diperlukan untuk menjawab pertanyaan.
Langkah 5: Kueri Spesifik
Sekarang mari kita melangkah lebih jauh dan mengajukan pertanyaan spesifik.
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])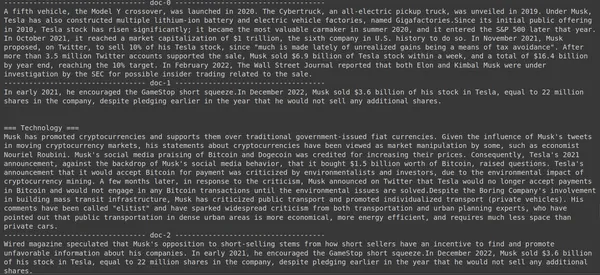
Di sini, pada kode di atas, kami mengajukan pertanyaan yang sangat spesifik tentang berapa banyak saham Tesla Elon yang terjual di bulan Desember 2022. Outputnya bisa kita lihat di sini. Doc-1 berisi jawaban atas pertanyaan tersebut. Elon telah menjual sahamnya di Tesla senilai $3.6 miliar. Sekali lagi, ColBERT berhasil mengambil potongan yang relevan untuk kueri yang diberikan.
Langkah 6: Menguji Model Lain
Sekarang mari kita coba pertanyaan yang sama dengan model penyematan lainnya baik sumber terbuka maupun tertutup di sini:
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- Kita memulai dengan mendownload model terlebih dahulu melalui kelas AutoModel dari perpustakaan Transformers.
- Kemudian kita simpan model_name dan model_kwargs di variabelnya masing-masing.
- Sekarang untuk bekerja dengan model ini di LangChain, kami mengimpor HuggingFaceEmbeddings dari LangChain dan berikan nama model dan model_kwargs.
Menjalankan kode ini akan mengunduh dan memuat model penyematan Jina sehingga kita dapat mengerjakannya
Langkah 7: Buat Embeddings
Sekarang, kita perlu mulai memisahkan dokumen kita dan kemudian membuat embeddings darinya dan menyimpannya di penyimpanan vektor Chroma. Untuk ini, kami bekerja dengan kode berikut:
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- Kita mulai dengan mengimpor Chroma dan RecursiveCharacterTextSplitter dari perpustakaan LangChain
- Kemudian kita membuat instance text_splitter dengan memanggil .from_tiktoken_encoder dari RecursiveCharacterTextSplitter dan meneruskannya ke chunk_size dan chunk_overlap
- Di sini kita akan menggunakan chunk_size yang sama yang telah kita berikan ke ColBERT
- Kemudian kita memanggil metode .split_text() dari text_splitter ini dan memberikannya dokumen yang berisi informasi Wikipedia tentang Elon Musk. Kemudian membagi dokumen berdasarkan ukuran potongan yang diberikan dan akhirnya, daftar Potongan Dokumen disimpan dalam variabel splits
- Terakhir, kita memanggil fungsi .from_texts() kelas Chroma untuk membuat penyimpanan vektor. Untuk fungsi ini, kami memberikan pemisahan, model penyematan, dan nama_koleksi
- Sekarang, kita membuat retriever dengan memanggil fungsi .as_retriever() dari objek penyimpanan vektor. Kami memberi 3 untuk nilai k
Menjalankan kode ini akan mengambil dokumen kita, membaginya menjadi dokumen yang lebih kecil dengan ukuran 256 per potongan, dan kemudian menyematkan potongan yang lebih kecil ini dengan model penyematan Jina dan menyimpan vektor penyematan ini di penyimpanan vektor kroma.
Langkah 8: Membuat Retriever
Terakhir, kami membuat retriever darinya. Sekarang kita akan melakukan pencarian vektor dan memeriksa hasilnya.
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)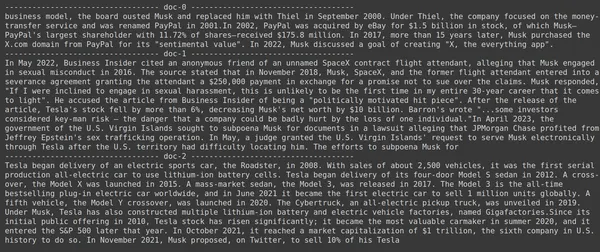
- Kita memanggil fungsi .get_relevent_documents() dari objek retriever dan memberikan kueri yang sama.
- Kemudian kami mencetak dengan rapi 3 dokumen teratas yang diambil.
- Dalam gambar, kita dapat melihat bahwa Jina Embedder meskipun merupakan model penyematan yang populer, pengambilan kueri kita buruk. Itu tidak berhasil mendapatkan potongan dokumen yang benar.
Kita dapat dengan jelas melihat perbedaan antara Jina, model penyematan yang mewakili setiap potongan sebagai penyematan vektor tunggal, dan model ColBERT yang mewakili setiap potongan sebagai daftar vektor penyematan tingkat token. ColBERT jelas berkinerja lebih baik dalam kasus ini.
Langkah 9: Menguji Model Penyematan OpenAI
Sekarang mari kita coba menggunakan model penyematan sumber tertutup seperti model Penyematan OpenAI.
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})Di sini kodenya sangat mirip dengan yang baru saja kita tulis
- Satu-satunya perbedaan adalah, kami meneruskan kunci API OpenAI untuk menyetel variabel lingkungan.
- Kami kemudian membuat instance model OpenAI Embedding dengan mengimpornya dari LangChain.
- Dan saat membuat nama koleksi, kami memberikan nama koleksi yang berbeda, sehingga penyematan dari model OpenAI Embedding disimpan di koleksi yang berbeda.
Menjalankan kode ini akan mengambil kembali dokumen kita, mengelompokkannya menjadi dokumen yang lebih kecil berukuran 256, lalu menyematkannya ke dalam representasi penyematan vektor tunggal dengan model penyematan OpenAI dan terakhir menyimpan penyematan ini di Chroma Vector Store. Sekarang mari kita coba mengambil kembali dokumen yang relevan dengan pertanyaan lainnya.
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)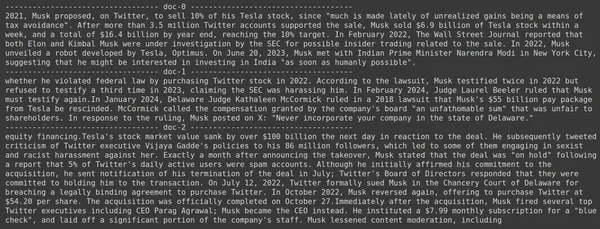
- Kami melihat bahwa jawaban yang kami harapkan tidak ditemukan dalam potongan yang diambil.
- Bagian pertama berisi informasi tentang saham Tesla pada tahun 2022 tetapi tidak berbicara tentang Elon yang menjualnya.
- Hal yang sama dapat dilihat pada dua potongan dokumen lainnya, dimana informasi yang dikandungnya adalah tentang Tesla dan sahamnya tetapi ini bukanlah informasi yang kami harapkan.
- Potongan yang diambil di atas tidak akan memberikan konteks bagi LLM untuk menjawab pertanyaan yang kami berikan.
Bahkan di sini kita dapat melihat perbedaan yang jelas antara representasi penyematan vektor tunggal vs representasi penyematan multi-vektor. Representasi multi-embedding dengan jelas menangkap kueri kompleks sehingga menghasilkan pengambilan yang lebih akurat.
Kesimpulan
Kesimpulannya, ColBERT menunjukkan kemajuan yang signifikan dalam kinerja pengambilan dibandingkan model bi-encoder tradisional dengan merepresentasikan teks sebagai penyematan multi-vektor pada tingkat token. Pendekatan ini memungkinkan pemahaman kontekstual yang lebih bernuansa antara pertanyaan dan dokumen, sehingga menghasilkan hasil pengambilan yang lebih akurat dan mengurangi masalah halusinasi yang biasa diamati di LLM.
Pengambilan Kunci
- RAG mengatasi masalah halusinasi di LLM dengan memberikan informasi kontekstual untuk menghasilkan jawaban faktual.
- Bi-encoder tradisional mengalami hambatan informasi karena mengompresi seluruh teks ke dalam satu penyematan vektor, sehingga menghasilkan akurasi pengambilan di bawah standar.
- ColBERT, dengan representasi penyematan tingkat tokennya, memfasilitasi pemahaman kontekstual yang lebih baik antara kueri dan dokumen, sehingga menghasilkan peningkatan kinerja pengambilan.
- Langkah interaksi akhir di ColBERT, dikombinasikan dengan interaksi tingkat token, meningkatkan akurasi pengambilan dengan mempertimbangkan nuansa kontekstual.
- ColBERTv2 mengoptimalkan ruang penyimpanan melalui kompresi sisa sambil mempertahankan efektivitas pengambilan.
- Eksperimen langsung menunjukkan keunggulan ColBERT dalam kinerja pengambilan dibandingkan dengan model penyematan sumber terbuka dan tradisional seperti Jina dan OpenAI Embedding.
Tanya Jawab Umum (FAQ)
A. Bi-encoder tradisional memampatkan seluruh teks menjadi satu penyematan vektor, sehingga berpotensi kehilangan informasi kontekstual. Hal ini membatasi efektivitasnya dalam tugas pengambilan, terutama dengan kueri atau dokumen yang kompleks.
A. ColBERT (Contextual Late Interactions BERT) adalah model bi-encoder yang merepresentasikan teks menggunakan penyematan vektor tingkat token. Hal ini memungkinkan pemahaman kontekstual yang lebih bernuansa antara kueri dan dokumen, sehingga meningkatkan akurasi pengambilan.
A. ColBERT menghasilkan penyematan tingkat token untuk kueri dan dokumen, melakukan perkalian matriks untuk menghitung skor kesamaan, lalu memilih informasi yang paling relevan berdasarkan kesamaan maksimum di seluruh token. Hal ini memungkinkan pengambilan yang efektif dengan pemahaman kontekstual.
A. ColBERTv2 mengoptimalkan Ruang melalui metode kompresi sisa, mengurangi kebutuhan penyimpanan untuk penyematan tingkat token sambil menjaga akurasi pengambilan.
J. Anda dapat menggunakan perpustakaan seperti RAGatouille untuk bekerja dengan ColBERT dengan mudah. Dengan mengindeks dokumen dan kueri, Anda dapat melakukan tugas pengambilan secara efisien dan menghasilkan jawaban akurat yang selaras dengan konteks.
Media yang ditampilkan dalam artikel ini bukan milik Analytics Vidhya dan digunakan atas kebijaksanaan Penulis.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

