Koronák a sörfőzdéket, italpalackozókat és élelmiszergyártókat a világ minden táján egyedi gépekkel és komplett gyártósorokkal látja el. Naponta több millió üvegpalack, konzervdoboz és PET-konténer fut át a Krones vonalon. A gyártósorok összetett rendszerek, sok lehetséges hibával, amelyek leállíthatják a sort és csökkenthetik a termelési hozamot. A Krones a lehető legkorábban (néha még azelőtt) szeretné észlelni a hibát, és értesíteni szeretné a gyártósorok üzemeltetőit a megbízhatóság és a teljesítmény növelése érdekében. Tehát hogyan lehet észlelni a hibát? A Krones az adatgyűjtéshez érzékelőkkel látja el a vonalait, amelyek azután kiértékelhetők a szabályok szerint. A Krones-nak, mint sorgyártónak, valamint a vonal üzemeltetőjének lehetősége van a gépekre vonatkozó felügyeleti szabályok létrehozására. Ezért az italpalackozók és más üzemeltetők saját hibahatárukat határozhatják meg a vonalhoz. Korábban a Krones egy idősoros adatbázison alapuló rendszert használt. A fő kihívás az volt, hogy ezt a rendszert nehéz volt hibakeresni, és a lekérdezések a gépek aktuális állapotát reprezentálták, de az állapotátmeneteket nem.
Ez a bejegyzés bemutatja, hogy a Krones hogyan épített streaming megoldást a vonalaik figyelésére Amazon kinezis és a Amazon által felügyelt szolgáltatás az Apache Flink számára. Ezek a teljesen felügyelt szolgáltatások csökkentik a streaming alkalmazások Apache Flink segítségével történő felépítésének bonyolultságát. A Managed Service for Apache Flink kezeli a mögöttes Apache Flink összetevőket, amelyek tartós alkalmazásállapotot, mérőszámokat, naplókat és egyebeket biztosítanak, a Kinesis pedig lehetővé teszi a streaming adatok költséghatékony feldolgozását bármilyen léptékben. Ha el szeretné kezdeni saját Apache Flink alkalmazását, nézze meg a GitHub tárház a Flink Java, Python vagy SQL API-ját használó mintákhoz.
A megoldás áttekintése
A Krones vonalfigyelése része a Krones üzlethelyiség útmutató rendszer. Támogatást nyújt a vállalat összes tevékenységének megszervezésében, rangsorolásában, irányításában és dokumentálásában. Lehetővé teszi számukra, hogy értesítsék a kezelőt, ha a gép leáll, vagy anyagokra van szükség, függetlenül attól, hogy a kezelő hol van a sorban. A jól bevált állapotfelügyeleti szabályok már be vannak építve, de a felhasználói felületen keresztül is meghatározhatók. Például, ha egy bizonyos megfigyelt adatpont megsért egy küszöbértéket, akkor szöveges üzenet vagy karbantartási rendelést kiváltó esemény jelenhet meg a sorban.
Az állapotfigyelő és szabályértékelő rendszer AWS-re épül, AWS elemző szolgáltatásokat használva. Az alábbi ábra szemlélteti az architektúrát.
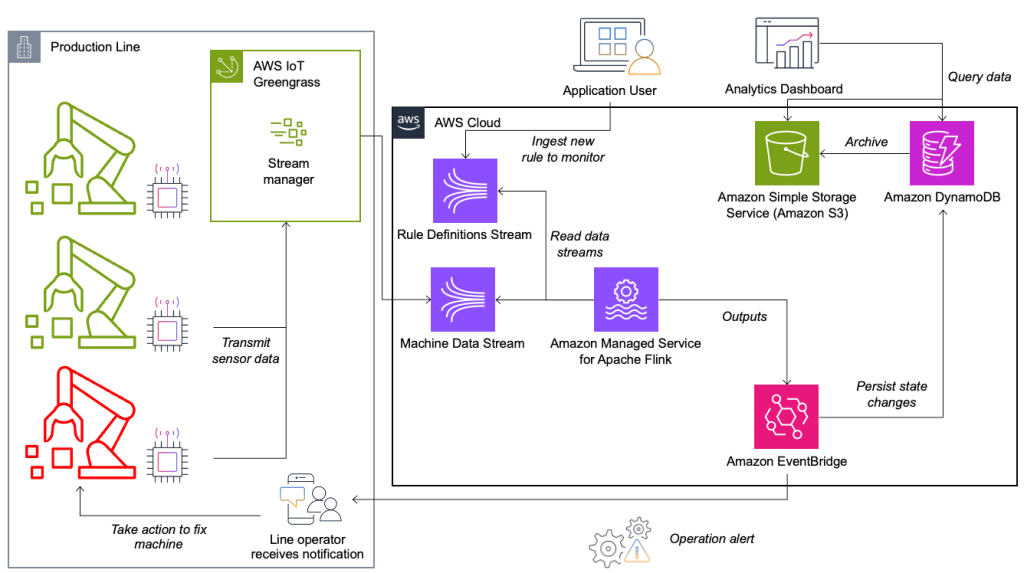
Szinte minden adatfolyam-alkalmazás öt rétegből áll: adatforrásból, adatfolyam-feldolgozásból, adatfolyam-tárolásból, adatfolyam-feldolgozásból és egy vagy több célból. A következő részekben mélyebben belemerülünk az egyes rétegekbe, és részletesen bemutatjuk, hogyan működik a Krones által épített vonalfigyelő megoldás.
Adatforrás
Az adatokat egy szélső eszközön futó szolgáltatás gyűjti össze, amely több protokollt olvas, mint például a Siemens S7 vagy az OPC/UA. A nyers adatok előfeldolgozása egységes JSON-struktúra létrehozása érdekében történik, amely megkönnyíti a későbbi feldolgozást a szabálymotorban. A JSON-ba konvertált hasznos adatminta a következőképpen nézhet ki:
{
"version": 1,
"timestamp": 1234,
"equipmentId": "84068f2f-3f39-4b9c-a995-d2a84d878689",
"tag": "water_temperature",
"value": 13.45,
"quality": "Ok",
"meta": {
"sequenceNumber": 123,
"flags": ["Fst", "Lst", "Wmk", "Syn", "Ats"],
"createdAt": 12345690,
"sourceId": "filling_machine"
}
}Az adatfolyam feldolgozása
AWS IoT Greengrass egy nyílt forráskódú Internet of Things (IoT) szélső futásidejű és felhőszolgáltatás. Ez lehetővé teszi az adatok helyi kezelését, valamint az eszközadatok összesítését és szűrését. Az AWS IoT Greengrass előre beépített összetevőket kínál, amelyek a széleken is telepíthetők. A gyártósoros megoldás a folyamkezelő komponenst használja, amely képes feldolgozni az adatokat és átvinni azokat az AWS-célhelyekre, mint pl AWS IoT Analytics, Amazon egyszerű tárolási szolgáltatás (Amazon S3), és Kinesis. A folyamkezelő puffereli és összesíti a rekordokat, majd elküldi egy Kinesis adatfolyamnak.
Streamtárhely
A folyamtároló feladata az üzenetek hibatűrő pufferelése és egy vagy több fogyasztói alkalmazás számára elérhetővé tétele. Ennek eléréséhez AWS-en a leggyakoribb technológiák a Kinesis és Amazon által kezelt adatfolyam az Apache Kafka számára (Amazon MSK). A gyártósorokról származó szenzoradatok tárolására a Krones a Kinesist választja. A Kinesis egy szerver nélküli streaming adatszolgáltatás, amely bármilyen léptékben, alacsony késleltetéssel működik. A Kinesis adatfolyamon belüli szilánkok az adatrekordok egyedileg azonosított sorozata, ahol egy adatfolyam egy vagy több szilánkból áll. Minden szilánk 2 MB/s olvasási és 1 MB/s írási kapacitással rendelkezik (max. 1,000 rekord/s). E határok átlépésének elkerülése érdekében az adatokat a lehető legegyenletesebben kell elosztani a szilánkok között. Minden Kinesisnek küldött rekordhoz tartozik egy partíciókulcs, amely az adatok szilánkba csoportosítására szolgál. Ezért nagyszámú partíciókulcsot szeretne használni a terhelés egyenletes elosztásához. Az AWS IoT Greengrass rendszeren futó adatfolyam-kezelő támogatja a véletlenszerű partíciókulcs-hozzárendeléseket, ami azt jelenti, hogy minden rekord véletlenszerű szilánkba kerül, és a terhelés egyenletesen oszlik el. A véletlenszerű partíciókulcs-hozzárendelések hátránya, hogy a rekordokat a Kinesis nem sorrendben tárolja. Ennek megoldását a következő részben elmagyarázzuk, ahol a vízjelekről lesz szó.
vízjelek
A vízjel egy olyan mechanizmus, amellyel nyomon követhető és mérhető az eseményidő előrehaladása egy adatfolyamban. Az esemény időpontja az az időbélyeg, amikor az esemény létrejött a forrásnál. A vízjel az adatfolyam-feldolgozó alkalmazás időbeni előrehaladását jelzi, így minden korábbi vagy azonos időbélyeggel rendelkező esemény feldolgozottnak minősül. Ezek az információk elengedhetetlenek a Flink számára az eseményidő előrehaladásához és a releváns számítások, például az ablakkiértékelések elindításához. Az eseményidő és a vízjel közötti megengedett késleltetés beállítható annak meghatározására, hogy mennyi ideig kell várni a késői adatokra, mielőtt befejezettnek tekintené az ablakot, és továbblépne a vízjelen.
A Krone-nak világszerte vannak rendszerei, és a kapcsolatvesztés vagy más hálózati korlátok miatti késői érkezések kezelésére is szükség van. Kezdetben figyelték a későn érkezőket, és az alapértelmezett Flink késői kezelést az ebben a mutatóban látott maximális értékre állították. Problémákat tapasztaltak a szélső eszközökről történő időszinkronizálás során, ami a vízjelezés kifinomultabb módjához vezette őket. Összeállítottak egy globális vízjelet az összes küldő számára, és a legalacsonyabb értéket használták vízjelként. Az időbélyegeket a HashMap tárolja az összes bejövő eseményhez. Amikor a vízjeleket rendszeres időközönként adják ki, a HashMap legkisebb értéke kerül felhasználásra. Annak érdekében, hogy elkerüljék a vízjelek elakadását az adatok hiánya miatt, beállítottak egy idleTimeOut paraméter, amely figyelmen kívül hagyja a bizonyos küszöbértéknél régebbi időbélyegeket. Ez növeli a várakozási időt, de erős adatkonzisztenciát biztosít.
public class BucketWatermarkGenerator implements WatermarkGenerator<DataPointEvent> {
private HashMap <String, WatermarkAndTimestamp> lastTimestamps;
private Long idleTimeOut;
private long maxOutOfOrderness;
}
Stream feldolgozás
Az érzékelőktől származó adatok begyűjtése és a Kinesisbe való bekerülése után azokat egy szabálymotornak kell kiértékelnie. Ebben a rendszerben egy szabály egyetlen metrika (például hőmérséklet) vagy mérőszámok gyűjteményének állapotát jelöli. Egy metrika értelmezéséhez egynél több adatpontot használnak, ami állapotalapú számítás. Ebben a részben mélyebben belemerülünk az Apache Flink kulcsolt állapotába és sugárzási állapotába, valamint abba, hogy hogyan használják őket a Krones szabálymotor felépítéséhez.
Vezérelje az adatfolyamot és a broadcast állapotmintát
Az Apache Flinkben voltak a rendszer azon képességére utal, hogy folyamatosan tárolja és kezeli az információkat az idő és a műveletek során, lehetővé téve a streaming adatok feldolgozását az állapotalapú számítások támogatásával.
A broadcast állapotminta lehetővé teszi egy állapot elosztását egy operátor összes párhuzamos példányára. Ezért minden operátornak ugyanaz az állapota, és az adatok ugyanabban az állapotban dolgozhatók fel. Ezeket az írásvédett adatokat egy vezérlőfolyam segítségével lehet feldolgozni. A vezérlőfolyam normál adatfolyam, de általában sokkal alacsonyabb adatsebességgel. Ez a minta lehetővé teszi az összes operátor állapotának dinamikus frissítését, lehetővé téve a felhasználó számára, hogy újratelepítés nélkül módosítsa az alkalmazás állapotát és viselkedését. Pontosabban, az állapot elosztása egy vezérlőfolyam használatával történik. Ha új rekordot ad hozzá a vezérlőfolyamhoz, minden operátor megkapja ezt a frissítést, és az új állapotot használja az új üzenetek feldolgozásához.
Ez lehetővé teszi a Krones alkalmazás felhasználóinak, hogy új szabályokat töltsenek be a Flink alkalmazásba anélkül, hogy újraindítanák. Ezzel elkerülhető az állásidő, és nagyszerű felhasználói élményt nyújt, mivel a változások valós időben történnek. A szabály egy forgatókönyvet fed le a folyamateltérés észlelése érdekében. Néha a gépadatokat nem olyan könnyű értelmezni, mint amilyennek első pillantásra tűnhet. Ha egy hőmérséklet-érzékelő magas értékeket küld, ez hibát jelezhet, de egy folyamatban lévő karbantartási eljárás következménye is. Fontos, hogy a mutatókat kontextusba helyezzük, és szűrjünk néhány értéket. Ezt az ún csoportosítás.
A mérőszámok csoportosítása
Az adatok és metrikák csoportosítása lehetővé teszi a bejövő adatok relevanciájának meghatározását és pontos eredmények előállítását. Nézzük végig a példát a következő ábrán.
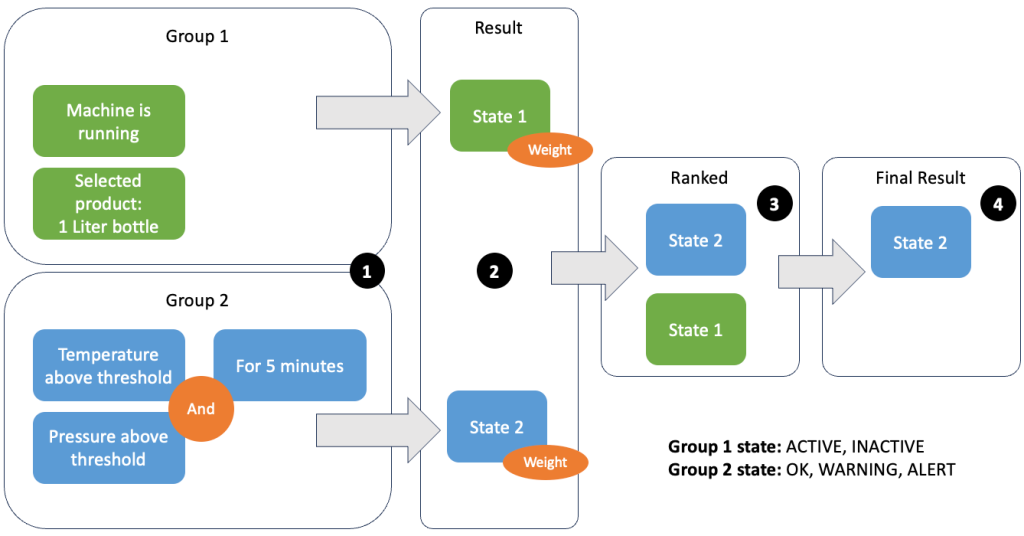
Az 1. lépésben két feltételcsoportot határozunk meg. Az 1. csoport összegyűjti a gép állapotát és azt, hogy melyik termék megy át a vonalon. A 2. csoport a hőmérséklet- és nyomásérzékelők értékét használja. Egy feltételcsoportnak különböző állapotai lehetnek a kapott értékektől függően. Ebben a példában az 1. csoport adatokat kap arról, hogy a gép működik, és az egyliteres palack van kiválasztva termékként; ez adja ennek a csoportnak az állapotot ACTIVE. A 2. csoport hőmérséklet- és nyomásmérőkkel rendelkezik; mindkét mérőszám több mint 5 percig a küszöbérték felett van. Ez azt eredményezi, hogy a 2. csoport a WARNING állapot. Ez azt jelenti, hogy az 1. csoport azt jelenti, hogy minden rendben van, a 2. csoport pedig nem. A 2. lépésben súlyokat adunk a csoportokhoz. Erre bizonyos helyzetekben szükség van, mert a csoportok egymásnak ellentmondó információkat jelenthetnek. Ebben a forgatókönyvben az 1. csoport jelenti ACTIVE és a 2. csoport jelentései WARNING, így nem világos a rendszer számára, hogy mi a vonal állapota. A súlyok hozzáadása után az állapotok rangsorolhatók a 3. lépésben látható módon. Végül a legmagasabban rangsorolt állapot kerül kiválasztásra nyerőként, a 4. lépésben látható módon.
A szabályok kiértékelése és a gép végső állapotának meghatározása után az eredmények további feldolgozása megtörténik. A végrehajtott művelet a szabály konfigurációjától függ; ez lehet egy értesítés a vonal üzemeltetőjének, hogy töltse fel az anyagokat, végezzen karbantartást, vagy csak egy vizuális frissítés a műszerfalon. A rendszernek ezt a részét, amely a mérőszámokat és szabályokat értékeli, és az eredmények alapján intézkedéseket tesz, a szabály motor.
A szabálymotor skálázása
Ha lehetővé teszi a felhasználók számára, hogy saját szabályaikat építsék fel, a szabálymotornak sok szabálya lehet, amelyet ki kell értékelnie, és egyes szabályok ugyanazokat az érzékelőadatokat használhatják, mint más szabályok. A Flink egy elosztott rendszer, amely nagyon jól skálázható vízszintesen. Egy adatfolyam több feladathoz való szétosztásához használhatja a keyBy() módszer. Ez lehetővé teszi egy adatfolyam logikai particionálását, és az adatok egy részének elküldését különböző feladatkezelőknek. Ez gyakran tetszőleges kulcs kiválasztásával történik, így egyenletes terhelést kap. Ebben az esetben Krones hozzátette a ruleId az adatponthoz, és kulcsként használta. Ellenkező esetben a szükséges adatpontokat egy másik feladat dolgozza fel. A kulcsos adatfolyam minden szabályban használható, akárcsak egy normál változó.
úticél
Amikor egy szabály megváltoztatja állapotát, az információ egy Kinesis adatfolyamba kerül, majd ezen keresztül Amazon EventBridge a fogyasztóknak. Az egyik fogyasztó értesítést hoz létre az eseményről, amelyet továbbít a gyártósorra, és riasztja a személyzetet a cselekvésre. A szabályállapot-változások elemzéséhez egy másik szolgáltatás írja az adatokat egy Amazon DynamoDB táblázat a gyors hozzáférés érdekében, és egy TTL is rendelkezésre áll, amely a hosszú távú előzményeket az Amazon S3-ra tölti le további jelentésekhez.
Következtetés
Ebben a bejegyzésben megmutattuk, hogyan épített a Krones valós idejű gyártósor-figyelő rendszert az AWS-re. Az Apache Flink menedzselt szolgáltatása lehetővé tette a Krones csapata számára, hogy gyorsan hozzáláthasson az alkalmazásfejlesztésre az infrastruktúra helyett. A Flink valós idejű képességei lehetővé tették a Krones számára, hogy 10%-kal csökkentse a gép állásidejét, és akár 5%-kal növelje a hatékonyságot.
Ha saját streaming alkalmazásokat szeretne készíteni, nézze meg a rendelkezésre álló mintákat a webhelyen GitHub tárház. Ha egyéni csatlakozókkal kívánja bővíteni Flink alkalmazását, lásd Csatlakozók összeépítésének megkönnyítése az Apache Flink segítségével: Az Async Sink bemutatása. Az Async Sink az Apache Flink 1.15.1-es és újabb verzióiban érhető el.
A szerzőkről
 Flórián Mair az AWS vezető megoldástervezője és adatfolyam-szakértője. Technológus, aki az üzleti kihívások AWS felhőszolgáltatások segítségével történő megoldásával segíti az európai ügyfelek sikerét és innovációját. Amellett, hogy Solutions Architect-ként dolgozik, Florian szenvedélyes hegymászó, és megmászta Európa legmagasabb hegyeit.
Flórián Mair az AWS vezető megoldástervezője és adatfolyam-szakértője. Technológus, aki az üzleti kihívások AWS felhőszolgáltatások segítségével történő megoldásával segíti az európai ügyfelek sikerét és innovációját. Amellett, hogy Solutions Architect-ként dolgozik, Florian szenvedélyes hegymászó, és megmászta Európa legmagasabb hegyeit.
 Dietl Emil a Krones vezető műszaki vezetője, adatmérnökségre szakosodott, kulcsterülete az Apache Flink és a mikroszolgáltatások. Munkája gyakran kritikus fontosságú szoftverek fejlesztését és karbantartását foglalja magában. Szakmai életén kívül nagyra értékeli, hogy minőségi időt tölthet családjával.
Dietl Emil a Krones vezető műszaki vezetője, adatmérnökségre szakosodott, kulcsterülete az Apache Flink és a mikroszolgáltatások. Munkája gyakran kritikus fontosságú szoftverek fejlesztését és karbantartását foglalja magában. Szakmai életén kívül nagyra értékeli, hogy minőségi időt tölthet családjával.
 Simon Peyer az AWS megoldások építésze, svájci székhelyű. Gyakorlatias, és szenvedélyesen köti össze a technológiát és az AWS Cloud szolgáltatásait használó embereket. Különös hangsúlyt fektet számára az adatfolyamokra és az automatizálásra. A munka mellett Simon szereti a családját, a szabadban való tartózkodást és a hegyekben való túrázást.
Simon Peyer az AWS megoldások építésze, svájci székhelyű. Gyakorlatias, és szenvedélyesen köti össze a technológiát és az AWS Cloud szolgáltatásait használó embereket. Különös hangsúlyt fektet számára az adatfolyamokra és az automatizálásra. A munka mellett Simon szereti a családját, a szabadban való tartózkodást és a hegyekben való túrázást.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/big-data/krones-real-time-production-line-monitoring-with-amazon-managed-service-for-apache-flink/

