परिचय
कंप्यूटर विज़न में, लाइव ऑब्जेक्ट का पता लगाने के लिए विभिन्न तकनीकें मौजूद हैं, जिनमें फास्टर भी शामिल है आर-सीएनएन, एसएसडी, तथा Yolo. प्रत्येक तकनीक की अपनी सीमाएँ और फायदे हैं। हालांकि तेज़ आर-सीएनएन सटीकता में उत्कृष्ट हो सकता है, लेकिन यह वास्तविक समय के परिदृश्यों में उतना अच्छा प्रदर्शन नहीं कर सकता है, जिससे इसकी ओर बदलाव हो सकता है। योलो एल्गोरिदम.
वस्तु का पता लगाना कंप्यूटर विज़न में मौलिक है, जो मशीनों को एक फ्रेम या स्क्रीन के भीतर वस्तुओं की पहचान करने और उनका पता लगाने में सक्षम बनाता है। पिछले कुछ वर्षों में, विभिन्न ऑब्जेक्ट डिटेक्शन एल्गोरिदम विकसित किए गए हैं, जिनमें से YOLO सबसे सफल में से एक के रूप में उभरा है। हाल ही में, YOLOv8 को पेश किया गया है, जो एल्गोरिदम की क्षमताओं को और बढ़ाता है।
इस व्यापक गाइड में, हम तीन प्रमुख ऑब्जेक्ट डिटेक्शन एल्गोरिदम का पता लगाते हैं: तेज़ आर-सीएनएन, एसएसडी (सिंगल शॉट मल्टीबॉक्स डिटेक्टर), और YOLOv8। हम इन एल्गोरिदम को लागू करने के व्यावहारिक पहलुओं पर चर्चा करते हैं, जिसमें एक आभासी वातावरण स्थापित करना और एक स्ट्रीमलिट एप्लिकेशन विकसित करना शामिल है।
सीखने का उद्देश्य
- तेज़ R-CNN, SSD और YOLO को समझें और उनके बीच के अंतरों का विश्लेषण करें।
- OpenCV, पर्यवेक्षण और YOLOv8 का उपयोग करके लाइव ऑब्जेक्ट डिटेक्शन सिस्टम को लागू करने में व्यावहारिक अनुभव प्राप्त करें।
- रोबोफ़्लो एनोटेशन का उपयोग करके छवि विभाजन मॉडल को समझना।
- आसान यूजर इंटरफेस के लिए स्ट्रीमलिट एप्लिकेशन बनाएं।
आइए जानें कि YOLOv8 के साथ छवि विभाजन कैसे करें!
विषय - सूची
इस लेख के एक भाग के रूप में प्रकाशित किया गया था डेटा साइंस ब्लॉगथॉन।
तेज़ आर-सीएनएन
फास्टर आर-सीएनएन (फास्टर रीजन-आधारित कन्वोल्यूशनल न्यूरल नेटवर्क) एक गहन शिक्षण-आधारित ऑब्जेक्ट डिटेक्शन एल्गोरिदम है। इसका मूल्यांकन आर-सीएनएन और फास्ट आर-सीएनएन ढांचे का उपयोग करके किया जाता है और इसे फास्ट आर-सीएनएन का विस्तार माना जा सकता है।
यह एल्गोरिदम आर-सीएनएन में उपयोग की जाने वाली चयनात्मक खोज की जगह, क्षेत्र प्रस्ताव उत्पन्न करने के लिए क्षेत्र प्रस्ताव नेटवर्क (आरपीएन) पेश करता है। आरपीएन डिटेक्शन नेटवर्क के साथ कन्वेन्शनल परतें साझा करता है, जिससे कुशल एंड-टू-एंड प्रशिक्षण की अनुमति मिलती है।
उत्पन्न क्षेत्र प्रस्तावों को बाउंडिंग बॉक्स शोधन और ऑब्जेक्ट वर्गीकरण के लिए फास्ट आर-सीएनएन नेटवर्क में फीड किया जाता है।
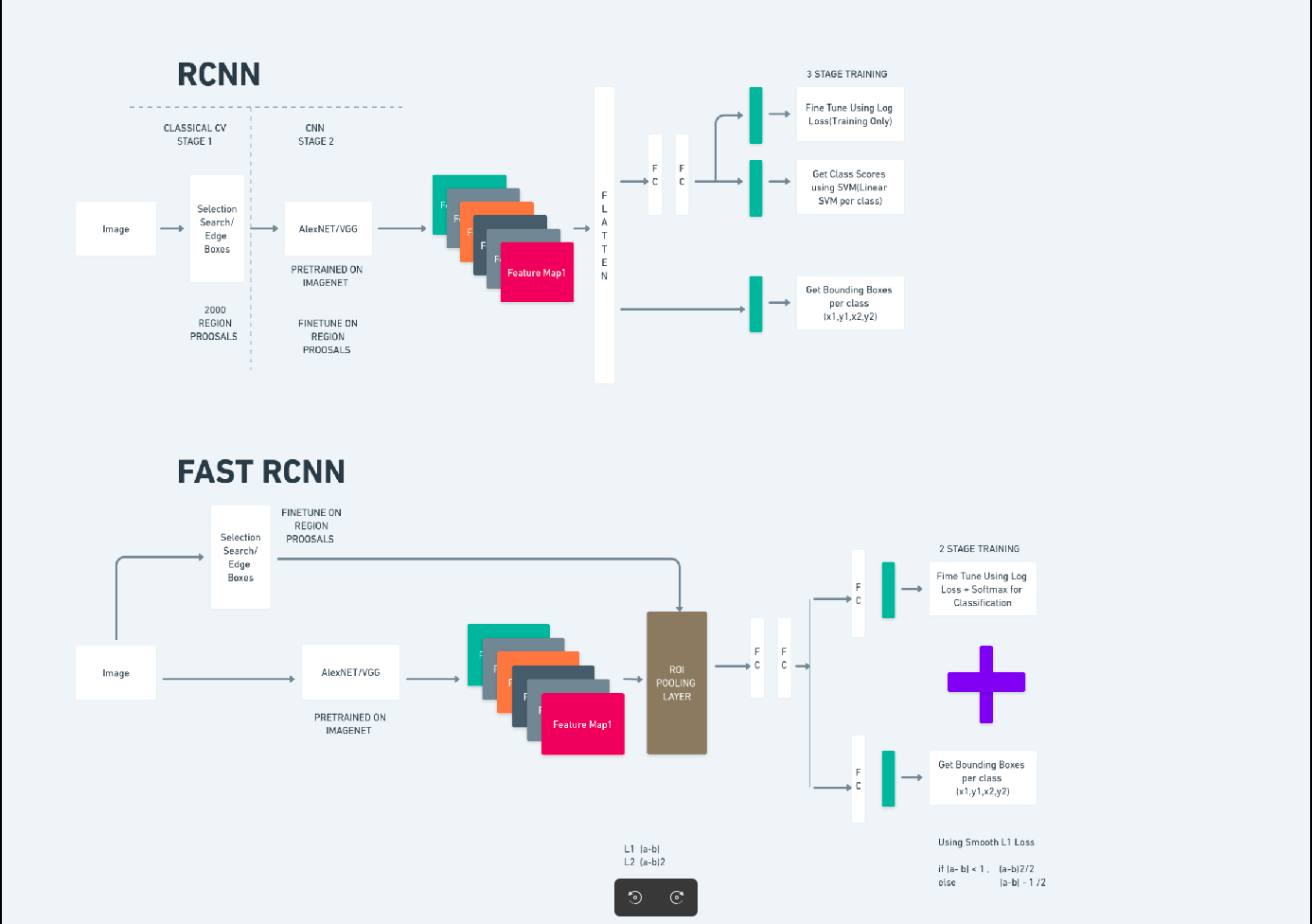
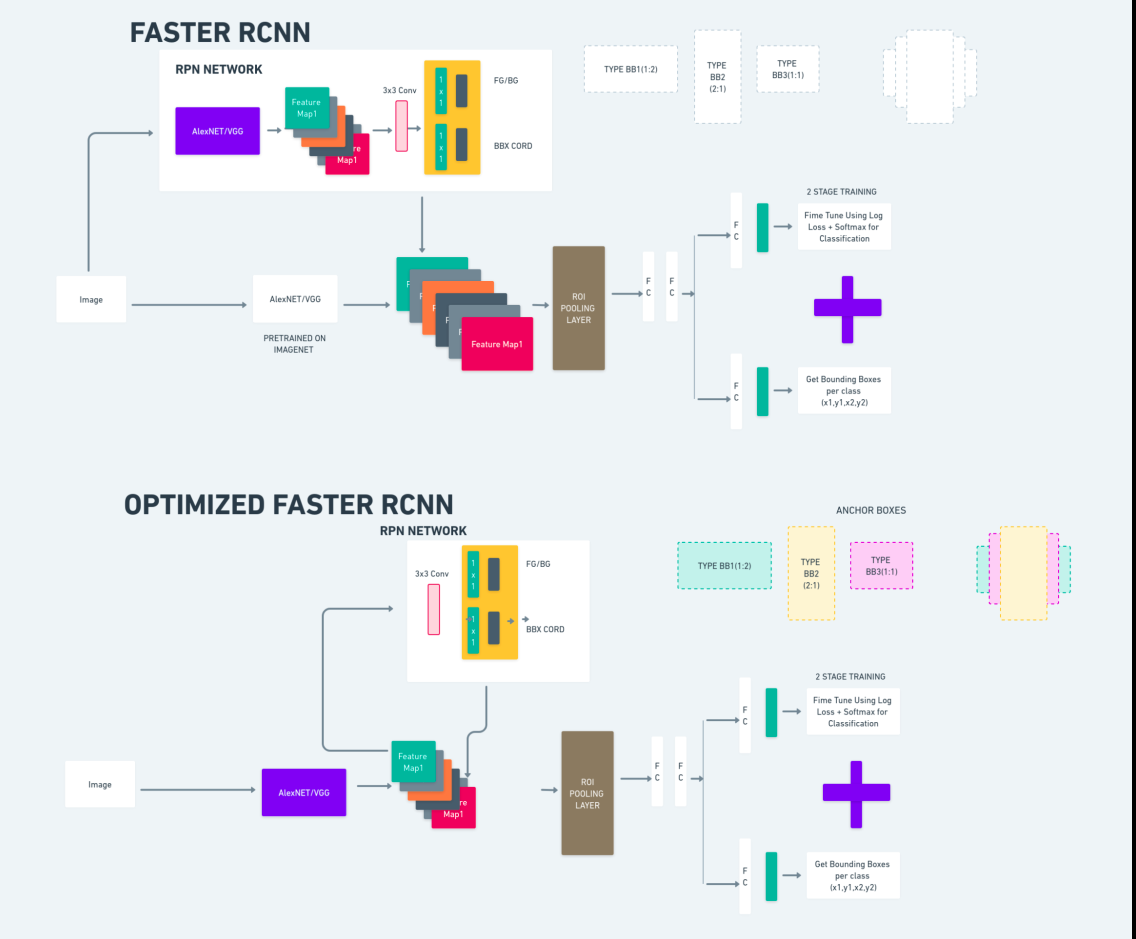
ऊपर दिया गया चित्र फास्टर आर-सीएनएन परिवार को व्यापक रूप से दिखाता है और प्रत्येक एल्गोरिदम के मूल्यांकन के लिए इसे समझना आसान है।
सिंगल शॉट मल्टीबॉक्स डिटेक्टर (एसएसडी)
RSI सिंगल शॉट मल्टीबॉक्स डिटेक्टर (एसएसडी)) ऑब्जेक्ट डिटेक्शन में लोकप्रिय है और मुख्य रूप से कंप्यूटर विज़न कार्यों में उपयोग किया जाता है। पिछली विधि, तेज़ आर-सीएनएन में, हमने दो चरणों का पालन किया: पहले चरण में पता लगाने वाला भाग और दूसरे में प्रतिगमन शामिल था। हालाँकि, SSD के साथ, हम केवल एक ही पहचान चरण निष्पादित करते हैं। SSD को तेज़ और सटीक ऑब्जेक्ट डिटेक्शन मॉडल की आवश्यकता को पूरा करने के लिए 2016 में पेश किया गया था।

फास्टर आर-सीएनएन जैसी पिछली ऑब्जेक्ट डिटेक्शन विधियों की तुलना में एसएसडी के कई फायदे हैं:
- दक्षता: एसएसडी एक एकल-चरण डिटेक्टर है, जिसका अर्थ है कि यह एक अलग प्रस्ताव पीढ़ी चरण की आवश्यकता के बिना सीधे बाउंडिंग बॉक्स और क्लास स्कोर की भविष्यवाणी करता है। यह फास्टर आर-सीएनएन जैसे दो-चरण डिटेक्टरों की तुलना में इसे तेज़ बनाता है।
- एंड-टू-एंड प्रशिक्षण: एसएसडी को बेस नेटवर्क और डिटेक्शन हेड दोनों को संयुक्त रूप से अनुकूलित करके एंड-टू-एंड प्रशिक्षित किया जा सकता है, जो प्रशिक्षण प्रक्रिया को सरल बनाता है।
- मल्टी-स्केल फ़ीचर फ़्यूज़न: SSD कई पैमानों पर फ़ीचर मैप पर काम करता है, जिससे यह अलग-अलग आकार की वस्तुओं का अधिक प्रभावी ढंग से पता लगा सकता है।
एसएसडी गति और सटीकता के बीच एक अच्छा संतुलन बनाता है, जिससे यह वास्तविक समय के अनुप्रयोगों के लिए उपयुक्त हो जाता है जहां प्रदर्शन और दक्षता दोनों महत्वपूर्ण हैं।
आप केवल एक बार देखें(YOLOv8)
2015 में, यू ओनली लुक वन्स (YOLO) को जोसेफ रेडमन, संतोष दिव्वाला, रॉस गिर्शिक और अली फरहादी द्वारा एक शोध पत्र में ऑब्जेक्ट-डिटेक्शन एल्गोरिदम के रूप में पेश किया गया था। YOLO एक एकल-शॉट एल्गोरिदम है जो इनपुट के रूप में एक पूर्ण छवि का उपयोग करके केवल एक तंत्रिका नेटवर्क द्वारा बाउंडिंग बॉक्स और क्लास संभावनाओं की भविष्यवाणी करके एक ही पास में किसी ऑब्जेक्ट को सीधे वर्गीकृत करता है।
अब, आइए YOLOv8 को बेहतर सटीकता और गति के साथ वास्तविक समय में वस्तु का पता लगाने में अत्याधुनिक प्रगति के रूप में समझें। YOLOv8 आपको पूर्व-प्रशिक्षित मॉडल का लाभ उठाने की अनुमति देता है, जो पहले से ही COCO (संदर्भ में सामान्य वस्तुएं) जैसे विशाल डेटासेट पर प्रशिक्षित हैं। छवि विभाजन प्रत्येक वस्तु के बारे में पिक्सेल-स्तरीय जानकारी प्रदान करता है, जिससे छवि सामग्री का अधिक विस्तृत विश्लेषण और समझ संभव हो पाती है।
जबकि छवि विभाजन कम्प्यूटेशनल रूप से महंगा हो सकता है, YOLOv8 इस विधि को अपने तंत्रिका-नेटवर्क आर्किटेक्चर में एकीकृत करता है, जिससे कुशल और सटीक ऑब्जेक्ट विभाजन की अनुमति मिलती है।
YOLOv8 का कार्य सिद्धांत
योलोव8 पहले इनपुट छवि को ग्रिड कोशिकाओं में विभाजित करके काम करता है। इन ग्रिड कोशिकाओं का उपयोग करके, YOLOv8 वर्ग की संभावनाओं के साथ बाउंडिंग बॉक्स (बीबॉक्स) की भविष्यवाणी करता है।
बाद में, YOLOv8 ओवरलैपिंग को कम करने के लिए NMS एल्गोरिदम का उपयोग करता है। उदाहरण के लिए, यदि छवि में कई कारें मौजूद हैं, जिसके परिणामस्वरूप बाउंडिंग बॉक्स ओवरलैप हो रहे हैं, तो एनएमएस एल्गोरिदम इस ओवरलैप को कम करने में मदद करता है।
योलो V8 के वेरिएंट के बीच अंतर: YOLOv8 तीन वेरिएंट में उपलब्ध है: YOLOv8, YOLOv8-L, और YOLOv8-X। वेरिएंट के बीच मुख्य अंतर बैकबोन नेटवर्क का आकार है। YOLOv8 में सबसे छोटा बैकबोन नेटवर्क है, जबकि YOLOv8-X में सबसे बड़ा बैकबोन नेटवर्क है।
अंतर तेज़ R-CNN, SSD और YOLO के बीच
| पहलू | तेज़ आर-सीएनएन | एसएसडी | Yolo |
|---|---|---|---|
| आर्किटेक्चर | आरपीएन और फास्ट आर-सीएनएन के साथ दो-चरण डिटेक्टर | सिंगल-स्टेज डिटेक्टर | सिंगल-स्टेज डिटेक्टर |
| क्षेत्र प्रस्ताव | हाँ | नहीं | नहीं |
| पता लगाने की गति | SSD और YOLO की तुलना में धीमा | तेज़ आर-सीएनएन की तुलना में तेज़, योलो की तुलना में धीमा | बहुत तेज़ |
| शुद्धता | आम तौर पर उच्च सटीकता | संतुलित सटीकता और गति | विशेष रूप से वास्तविक समय के अनुप्रयोगों के लिए, अच्छी सटीकता |
| लचीलापन | लचीला, विभिन्न ऑब्जेक्ट आकार और पहलू अनुपात को संभाल सकता है | वस्तुओं के अनेक स्तरों को संभाल सकता है | छोटी वस्तुओं के सटीक स्थानीयकरण के साथ संघर्ष कर सकते हैं |
| एकीकृत जांच | नहीं | नहीं | हाँ |
| गति बनाम सटीकता ट्रेडऑफ़ | आम तौर पर सटीकता के लिए गति का त्याग किया जाता है | गति और सटीकता को संतुलित करता है | अच्छी सटीकता बनाए रखते हुए गति को प्राथमिकता देता है |
सेगमेंटेशन क्या है?
जैसा कि हम जानते हैं कि विभाजन का अर्थ है कि हम कुछ विशेषताओं के आधार पर बड़ी छवि को छोटे समूहों में विभाजित कर रहे हैं। आइए छवि विभाजन को समझें जो एक कंप्यूटर विज़न तकनीक है जिसका उपयोग किसी छवि को विभिन्न एकाधिक खंडों या क्षेत्रों में विभाजित करने के लिए किया जाता है। चूँकि छवियाँ पिक्सेल से बनी होती हैं और छवि विभाजन में, पिक्सेल को रंग, तीव्रता, बनावट या अन्य दृश्य गुणों में समानता के अनुसार एक साथ समूहीकृत किया जाता है।
उदाहरण के लिए, यदि किसी छवि में पेड़, कारें या लोग हैं तो छवि विभाजन छवि को विभिन्न वर्गों में विभाजित करेगा जो सार्थक वस्तुओं या छवि के हिस्सों का प्रतिनिधित्व करते हैं। छवि विभाजन का व्यापक रूप से चिकित्सा इमेजिंग, उपग्रह छवि विश्लेषण, कंप्यूटर दृष्टि में वस्तु पहचान आदि जैसे विभिन्न क्षेत्रों में उपयोग किया जाता है।

विभाजन भाग में, हम प्रारंभ में रोबफ़्लो का उपयोग करके पहला YOLOv8 विभाजन मॉडल बनाते हैं। फिर, हम विभाजन कार्य करने के लिए विभाजन मॉडल आयात करते हैं। सवाल उठता है: हम विभाजन मॉडल क्यों बनाते हैं जब कार्य अकेले डिटेक्शन एल्गोरिदम के साथ पूरा किया जा सकता है?
विभाजन हमें एक वर्ग की संपूर्ण बॉडी छवि प्राप्त करने की अनुमति देता है। जबकि डिटेक्शन एल्गोरिदम वस्तुओं की उपस्थिति का पता लगाने पर ध्यान केंद्रित करते हैं, विभाजन वस्तुओं की सटीक सीमाओं को चित्रित करके अधिक सटीक समझ प्रदान करता है। इससे छवि में मौजूद वस्तुओं का अधिक सटीक स्थानीयकरण और समझ हो जाती है।
हालाँकि, विभाजन में आमतौर पर डिटेक्शन एल्गोरिदम की तुलना में उच्च समय जटिलता शामिल होती है क्योंकि इसमें एनोटेशन को अलग करने और मॉडल बनाने जैसे अतिरिक्त चरणों की आवश्यकता होती है। इस कमी के बावजूद, विभाजन द्वारा प्रदान की गई बढ़ी हुई सटीकता उन कार्यों में कम्प्यूटेशनल लागत से अधिक हो सकती है जहां सटीक वस्तु चित्रण महत्वपूर्ण है।
YOLOv8 के साथ चरण-दर-चरण लाइव डिटेक्शन और छवि विभाजन
इस अवधारणा में हम कोंडा का उपयोग करके एक आभासी वातावरण बनाने, वेनव को सक्रिय करने और पाइप का उपयोग करके आवश्यकता पैकेज स्थापित करने के चरणों की खोज कर रहे हैं। पहले सामान्य पायथन स्क्रिप्ट बनाते हैं फिर हम स्ट्रीमलिट एप्लिकेशन बनाते हैं।
चरण 1: Conda का उपयोग करके एक आभासी वातावरण बनाएं
conda create -p ./venv python=3.8 -yचरण 2: आभासी वातावरण सक्रिय करें
conda activate ./venv
चरण 3: आवश्यकताएँ.txt बनाएँ
टर्मिनल खोलें और नीचे दी गई स्क्रिप्ट चिपकाएँ:
touch requirements.txtचरण4: नैनो कमांड का उपयोग करें और require.txt को संपादित करें
रिक्वायरमेंट्स.txt बनाने के बाद रिक्वायरमेंट्स.txt को संपादित करने के लिए निम्नलिखित कमांड टाइप करें
nano requirements.txtउपरोक्त स्क्रिप्ट को चलाने के बाद आप इस यूआई को देख सकते हैं।
उसके आवश्यक पैकेज लिखें.
ultralytics==8.0.32
supervision==0.2.1
streamlitतब दबाएं “ctrl+o”(यह कमांड एडिटिंग पार्ट को सेव कर रहा है) फिर दबाएं "दर्ज"
दबाने के बाद "Ctrl+x” आप फ़ाइल से बाहर निकल सकते हैं. और मुख्य पथ पर जा रहे हैं.
चरण5: आवश्यकताओं.txt को स्थापित करना
pip install -r requirements.txtचरण 6: पायथन स्क्रिप्ट बनाएं
टर्मिनल में निम्नलिखित स्क्रिप्ट लिखें या हम कमांड कह सकते हैं।
touch main.pyMain.py बनाने के बाद vs कोड खोलें, आप कमांड राइट इन टर्मिनल का उपयोग करें,
code चरण 7: पायथन स्क्रिप्ट लिखना
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
इस कमांड को चलाने के बाद आप देख सकते हैं कि आपका कैमरा खुला है और आपके कुछ हिस्से का पता लगा रहा है। लिंग और पृष्ठभूमि भागों की तरह।
चरण 7: स्ट्रीमलाइट ऐप बनाएं
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
इस स्क्रिप्ट में, हम स्ट्रीमलिट एप्लिकेशन बना रहे हैं और बटन बना रहे हैं ताकि बटन दबाने के बाद आपका डिवाइस कैमरा खुला रहे और फ्रेम में भाग का पता लगा सके।
इस कमांड का उपयोग करके इस स्क्रिप्ट को चलाएँ।
streamlit run app.py
# first create the app.py then paste the above code and run this script.उपरोक्त कमांड चलाने के बाद मान लीजिए कि आपको रीच-आउट त्रुटि मिली, जैसे,
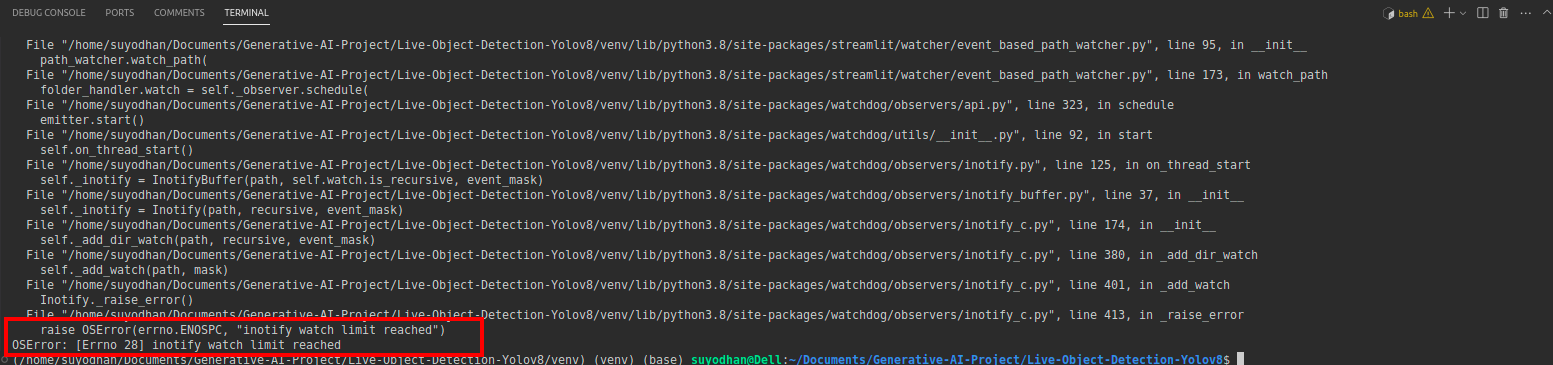
फिर इस कमांड को दबाएं,
sudo sysctl fs.inotify.max_user_watches=524288कमांड को हिट करने के बाद आप अपना पासवर्ड लिखना चाहते हैं क्योंकि हम सूडो कमांड का उपयोग कर रहे हैं सूडो इज गॉड:)
स्क्रिप्ट फिर से चलाएँ. और आप स्ट्रीमलिट एप्लिकेशन देख सकते हैं।
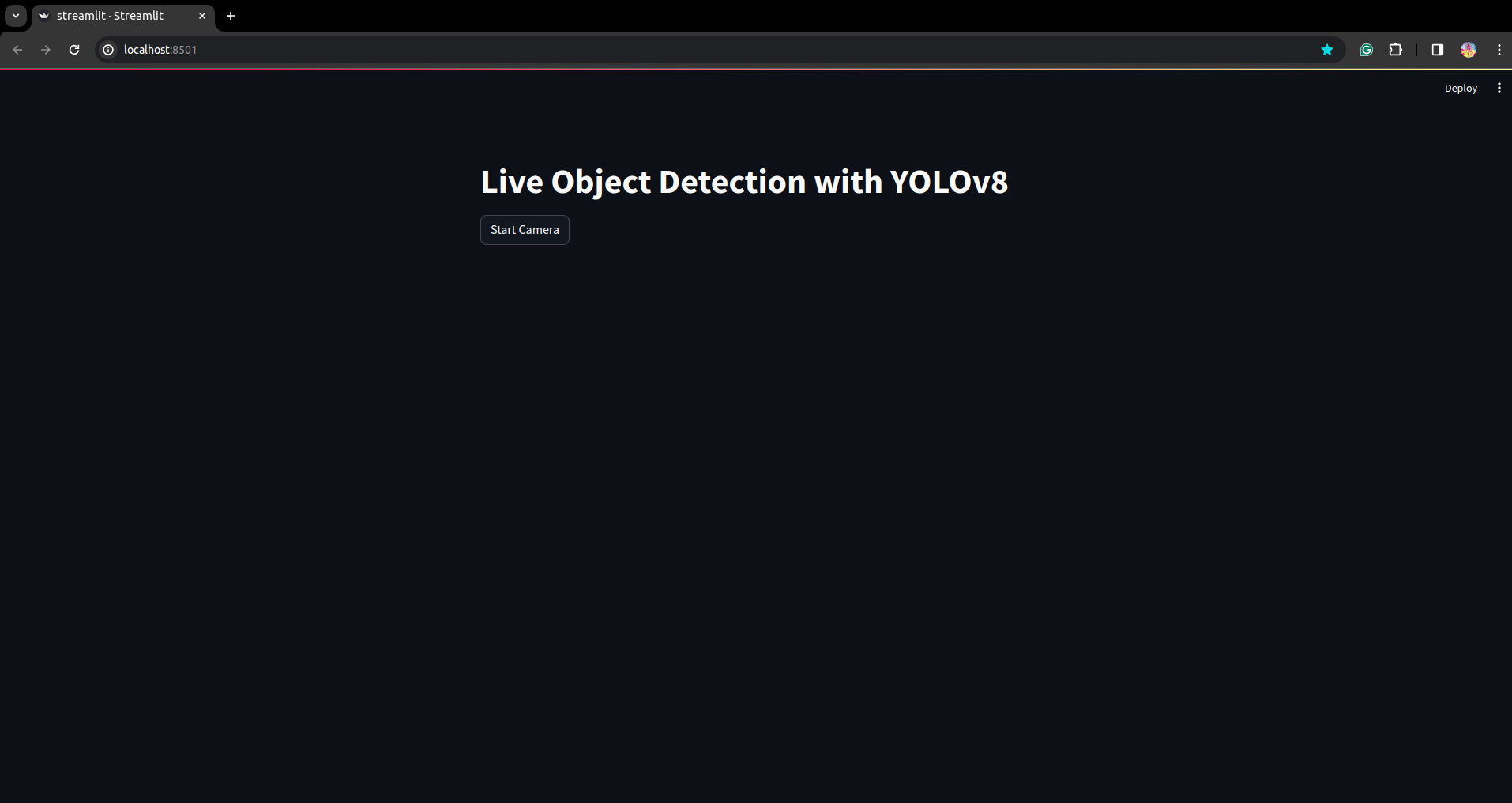
यहां हम एक सफल लाइव डिटेक्शन एप्लिकेशन बना सकते हैं, अगले भाग में हम विभाजन भाग देखेंगे।
एनोटेशन के लिए चरण
चरण 1: रोबोफ्लो सेटअप
साइन इन करने के बाद "प्रोजेक्ट बनाएं” यहां आप प्रोजेक्ट और एनोटेशन ग्रुप बना सकते हैं।

चरण 2: डेटासेट डाउनलोड करना
यहां हम सरल उदाहरण पर विचार करते हैं लेकिन आप इसे अपने समस्या विवरण पर उपयोग करना चाहते हैं इसलिए मैं यहां डक डेटासेट का उपयोग कर रहा हूं।
यह जाओ संपर्क और डक डेटासेट डाउनलोड करें।

फ़ोल्डर निकालें वहां आप तीन फ़ोल्डर देख सकते हैं: ट्रेन, परीक्षण और वैल।
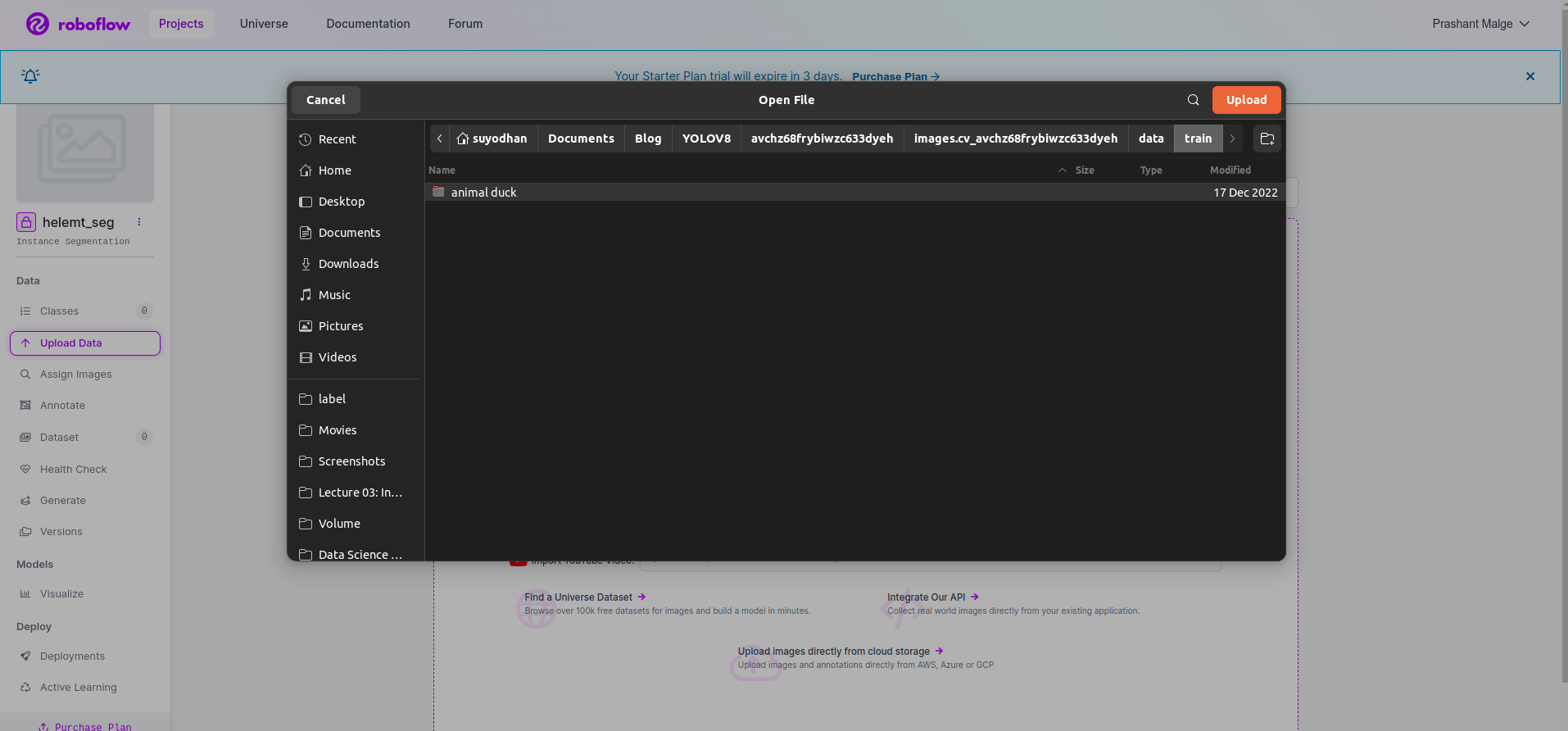
चरण 3: डेटासेट को रोबोफ़्लो पर अपलोड करना
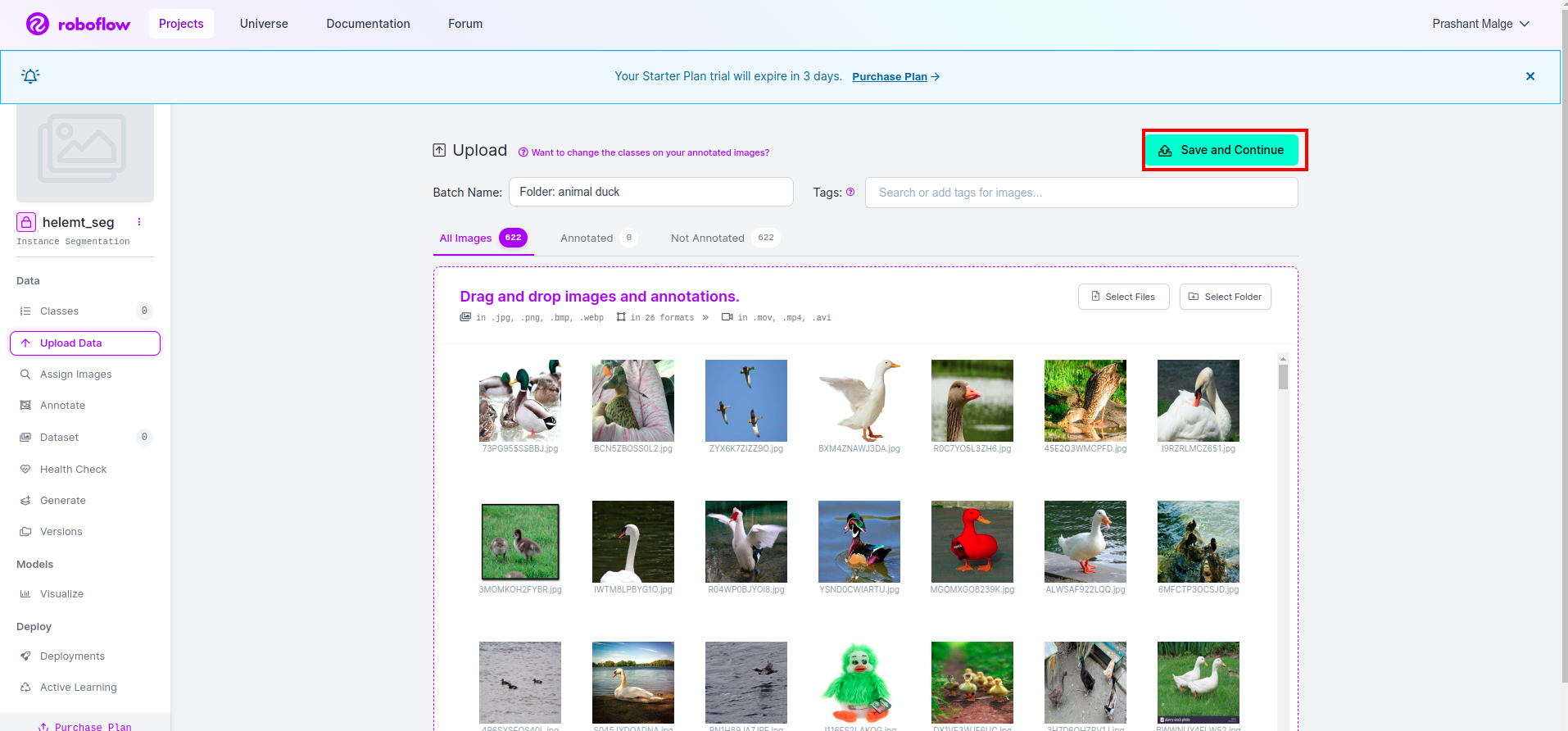
रोबोफ़्लो में प्रोजेक्ट बनाने के बाद आप इस यूआई को यहां देख सकते हैं, आप अपना डेटासेट अपलोड कर सकते हैं, इसलिए केवल ट्रेन भाग की छवियां अपलोड कर रहे हैं, "चुनें"फोल्डर का चयन करें" विकल्प.
फिर “क्लिक करें”सहेजें और जारी रखें" विकल्प जैसा कि मैंने लाल आयताकार बॉक्स में चिह्नित किया है
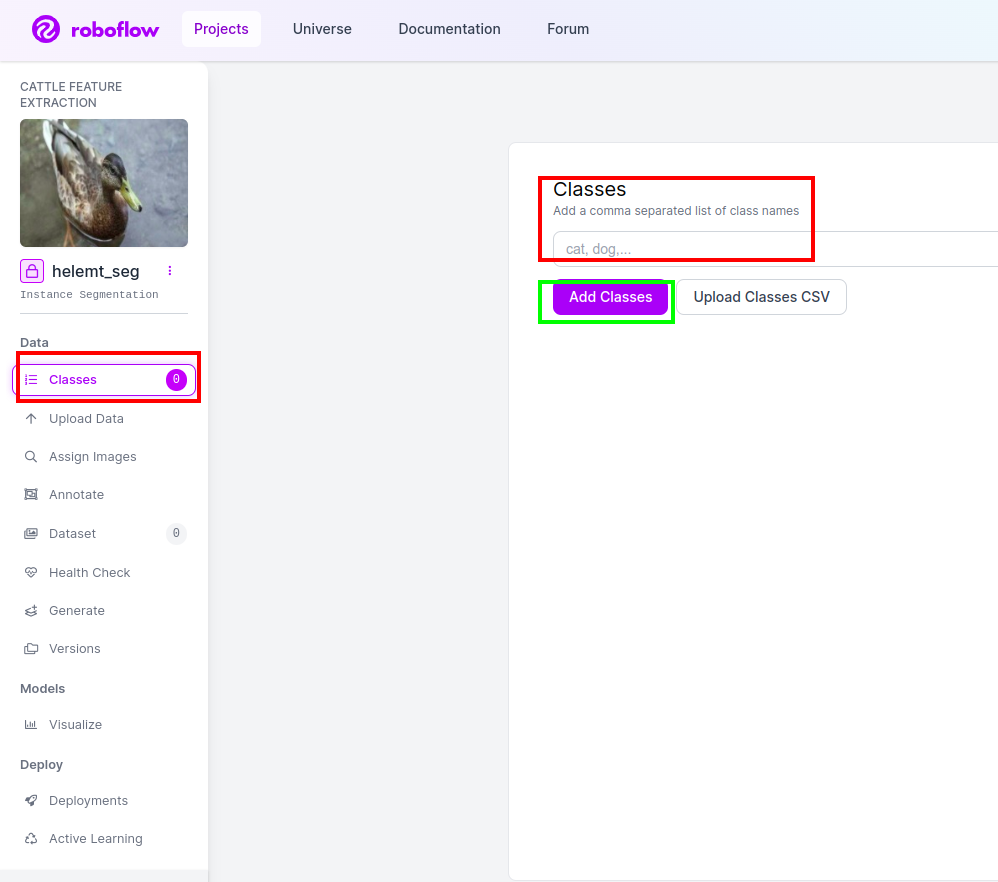
चरण 4: कक्षा का नाम जोड़ें
फिर जाओ कक्षा भाग बाईं ओर लाल बॉक्स को चेक करें। और कक्षा का नाम इस प्रकार लिखें बत्तख, हरे बॉक्स पर क्लिक करने के बाद.
अब हमारा सेटअप पूरा हो गया है और अगला भाग जैसे एनोटेशन भाग भी सरल है।
चरण5: प्रारंभ करें एनोटेशन भाग
इस पर जाएँ एनोटेशन विकल्प मैंने लाल बॉक्स में चिह्नित किया है और फिर एनोटेशन भाग प्रारंभ करें पर क्लिक किया है जैसा कि मैंने हरे बॉक्स में चिह्नित किया है।
पहली छवि पर क्लिक करें जिसमें आप यह यूआई देख सकते हैं। इसे देखने के बाद मैन्युअल एनोटेशन विकल्प पर क्लिक करें।
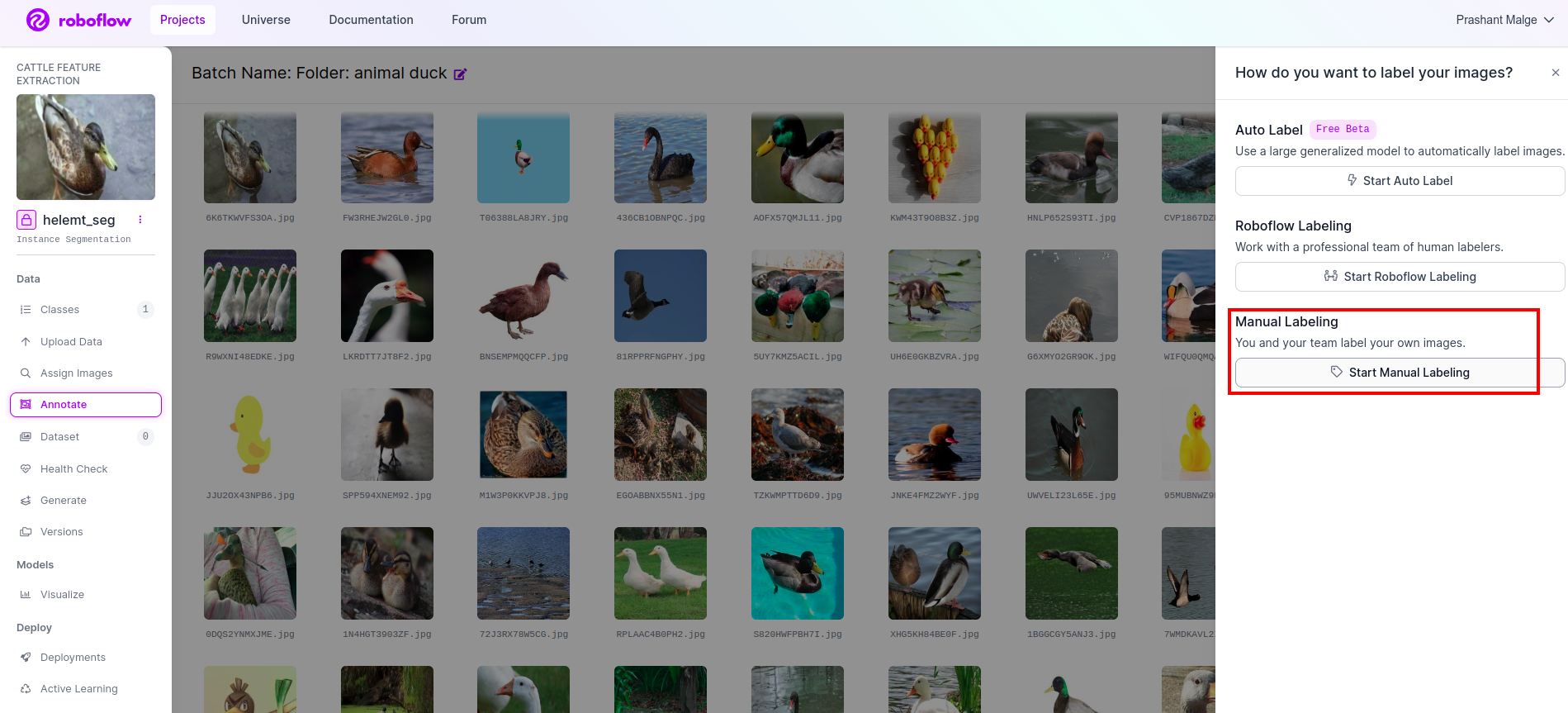
फिर अपनी ईमेल आईडी या अपने टीम के साथी का नाम जोड़ें ताकि आप कार्य सौंप सकें।
पहली छवि पर क्लिक करें जिसमें आप यह यूआई देख सकते हैं। यहां लाल बॉक्स पर क्लिक करें ताकि आप बहु-बहुपद मॉडल का चयन कर सकें।
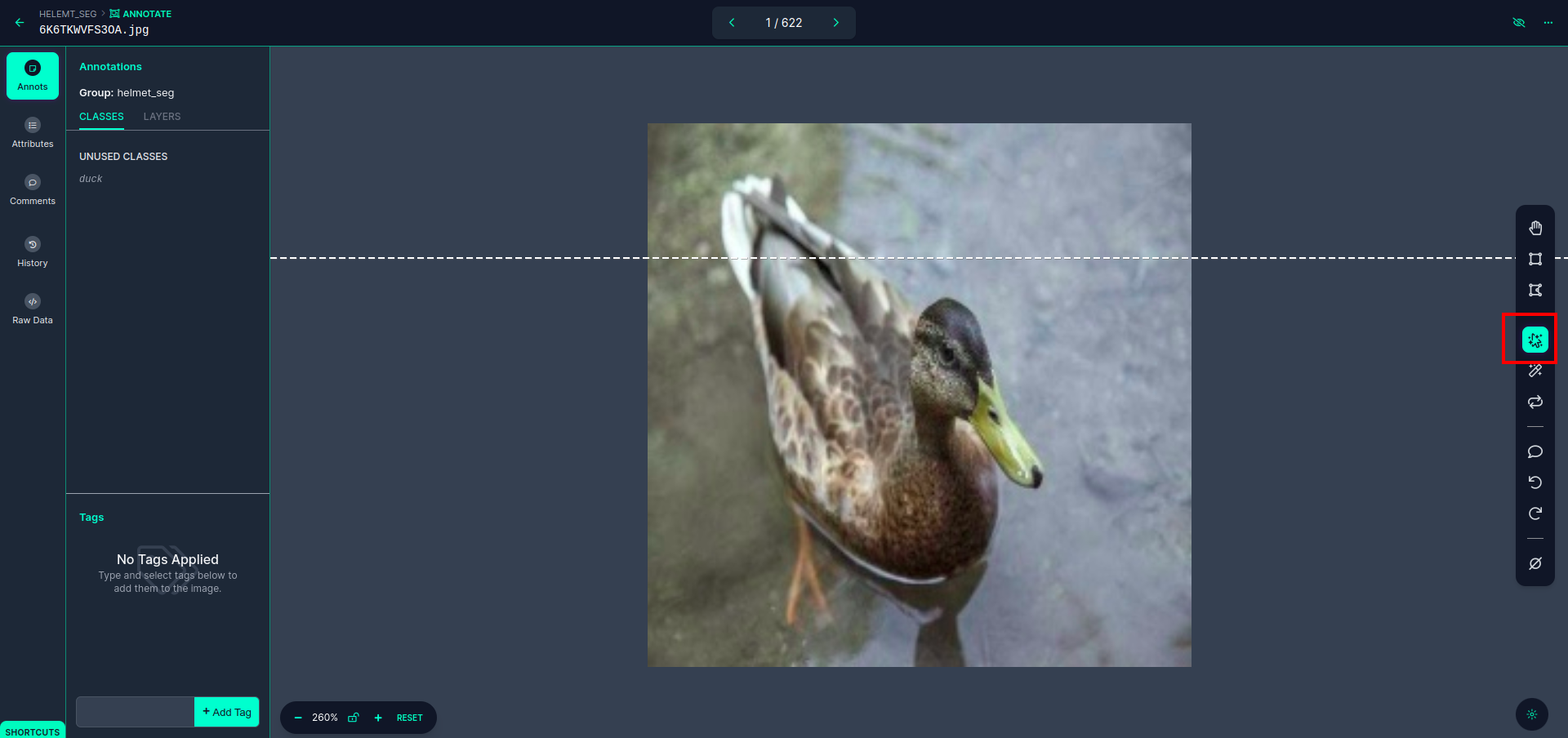
लाल बॉक्स पर क्लिक करने के बाद, डिफ़ॉल्ट मॉडल का चयन करें और डक ऑब्जेक्ट पर क्लिक करें। यह स्वचालित रूप से छवि को खंडित कर देगा. इसके बाद अगले भाग पर क्लिक करें और इसे सेव करें। फिर आपको बाईं ओर एक लाल बॉक्स में चिह्नित दिखाई देगा, जहां आप कक्षा का नाम देख सकते हैं।
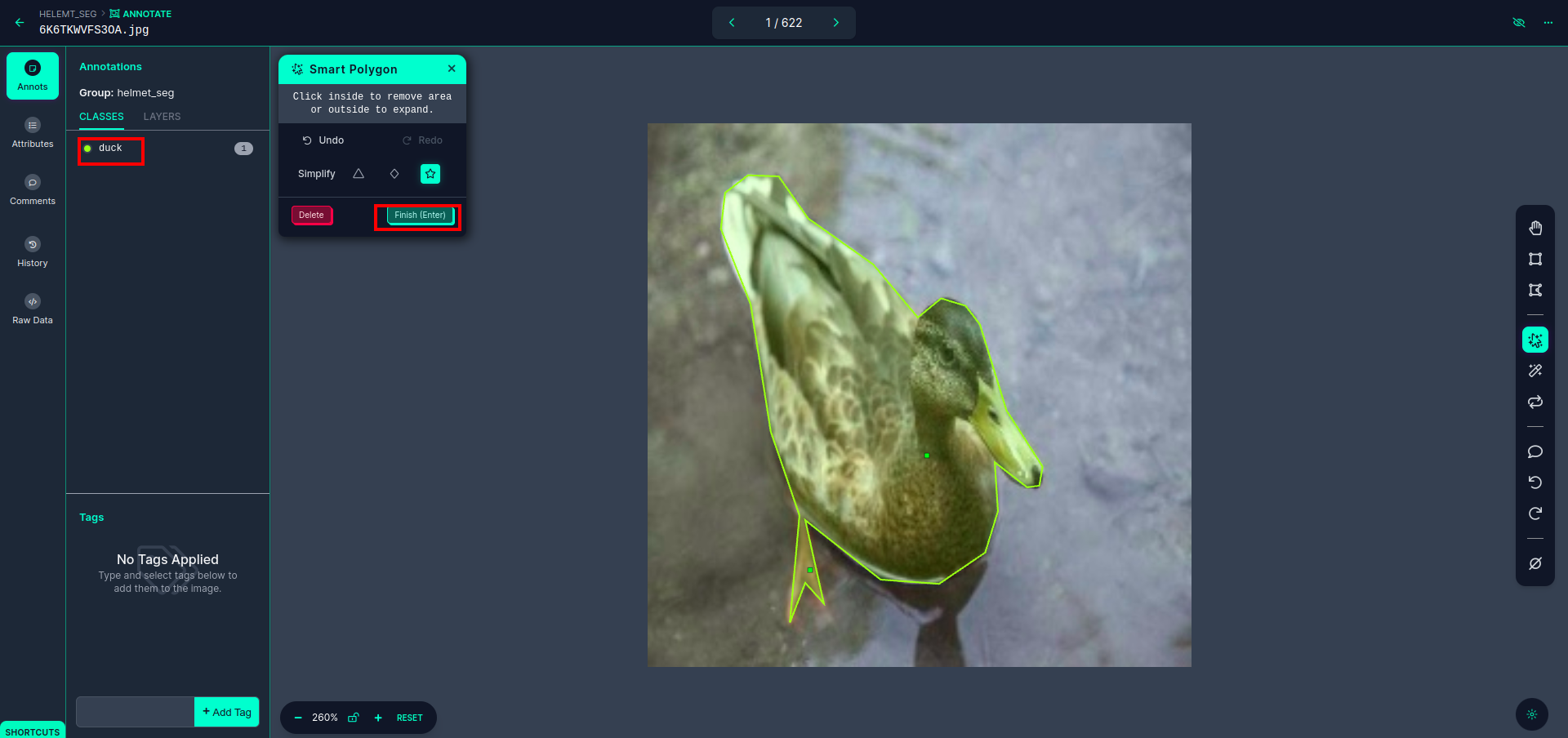
दबाएं सहेजें और दर्ज करें विकल्प। सभी छवियों पर टिप्पणी करें।
YOLOv8 प्रारूप के लिए छवियां जोड़ें। दाईं ओर आपको एनोटेशन सेक्शन में इमेज जोड़ने का विकल्प दिखाई देगा। यहां, दो भाग बनाए गए हैं: एक एनोटेटेड छवियों के लिए और एक अनएनोटेटेड छवियों के लिए।
- सबसे पहले, बाईं ओर क्लिक करें "टिप्पणी" विकल्प तो जोड़ना छवि डेटासेट के लिए.
- फिर अगले पर क्लिक करें"छवियां जोड़ें".
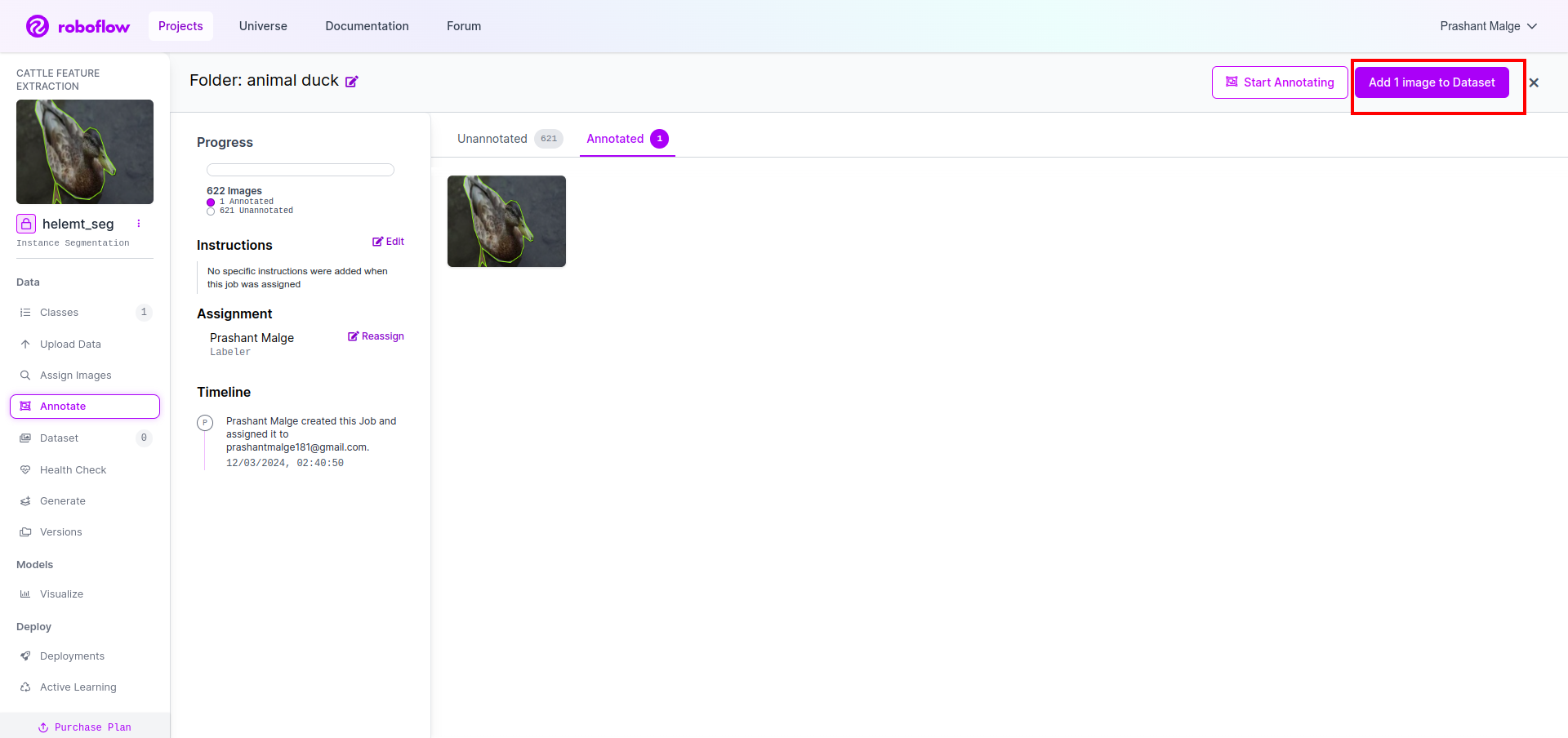
अब अंत में, हम डेटासेट बनाते हैं इसलिए बाईं ओर "जेनरेट" विकल्प पर क्लिक करें, फिर विकल्प की जांच करें और कॉनिट्यून विकल्प दबाएं।
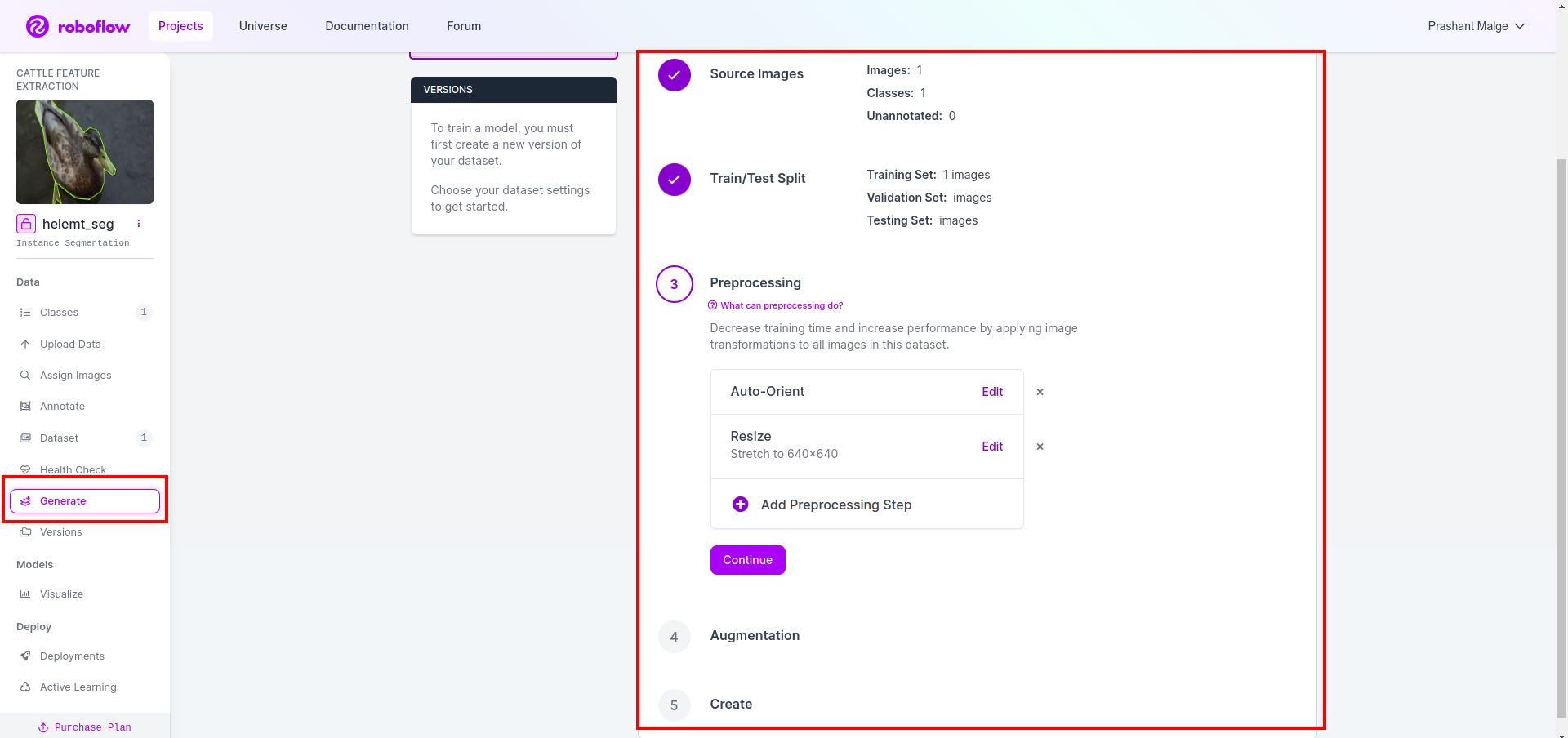
फिर आपको डेटासेट स्प्लिट विकल्प का यूआई मिलता है, यहां आप ट्रेन, टेस्ट और वैल फ़ोल्डर्स की जांच कर सकते हैं, उनकी छवियां स्वचालित रूप से विभाजित हो जाती हैं। और ऊपर दिए गए लाल बॉक्स पर क्लिक करें निर्यात डेटासेट विकल्प और ज़िप फ़ाइल डाउनलोड करें. ज़िप फ़ाइल फ़ोल्डर संरचना इस प्रकार है...
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
चरण 6: छवि विभाजन मॉडल के प्रशिक्षण के लिए स्क्रिप्ट लिखें
इस भाग में सबसे पहले, आप ड्राइव का उपयोग करके Google Collab फ़ाइल बनाएं और फिर अपना डेटासेट अपलोड करें। और Google Collab का उपयोग करके Google ड्राइव को म्यूट करें।
1. के लिए इस कमांड का उपयोग करें गूगल ड्राइव माउंट करें
from google.colab import drive
drive.mount('/content/gdrive')2. डेटा निर्देशिका को परिभाषित करें लगातार चर का प्रयोग करें.
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. आवश्यक पैकेज स्थापित करना, अल्ट्रालिटिक्स स्थापित करें
!pip install ultralytics4. पुस्तकालयों का आयात करना
import os
from ultralytics import YOLO5. भार पूर्व-प्रशिक्षित YOLOv8 मॉडल (यहां हमारे पास अलग-अलग मॉडल हैं, आधिकारिक दस्तावेज भी जांचें, वहां आप अलग-अलग मॉडल देख सकते हैं)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. मॉडल को प्रशिक्षित करें
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together अपनी ड्राइव की जांच न करें मॉडल नाम फ़ोल्डर बनाया गया है और वहां मॉडल उस भविष्यवाणी के लिए सहेजा गया है जिसे हम यह मॉडल चाहते हैं।
7. मॉडल की भविष्यवाणी करें
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)यहां आप देख सकते हैं कि विभाजन छवि सहेजी गई है।

अब अंततः हम लाइव डिटेक्शन और इमेज सेगमेंटेशन मॉडल दोनों बना सकते हैं।
निष्कर्ष
इस ब्लॉग में, हम YOLOv8 के साथ लाइव ऑब्जेक्ट डिटेक्शन और इमेज सेगमेंटेशन का पता लगाते हैं। लाइव डिटेक्शन के लिए, हम एक पूर्व-प्रशिक्षित YOLOv8 मॉडल आयात करते हैं और कैमरा खोलने और वस्तुओं का पता लगाने के लिए कंप्यूटर विज़न लाइब्रेरी, ओपनसीवी का उपयोग करते हैं। इसके अतिरिक्त, हम एक आकर्षक यूजर इंटरफेस के लिए एक स्ट्रीमलिट एप्लिकेशन बनाते हैं।
इसके बाद, हम YOLOv8 के साथ छवि विभाजन में गहराई से उतरेंगे। हम एक पूर्व-प्रशिक्षित मॉडल आयात करते हैं और एक कस्टम डेटासेट पर ट्रांसफर लर्निंग करते हैं। इससे पहले, हमने डेटासेट एनोटेशन के लिए रोबोफ़्लो की खोज की, जैसे टूल का उपयोग में आसान विकल्प प्रदान किया लेबलImg.
अंत में, हम एक बत्तख वाली छवि की भविष्यवाणी करते हैं। हालाँकि छवि में वस्तु एक पक्षी प्रतीत होती है, हम वर्ग का नाम "" के रूप में निर्दिष्ट करते हैंबतखप्रदर्शन प्रयोजनों के लिए।
चाबी छीन लेना
- फास्टर आर-सीएनएन, एसएसडी और नवीनतम YOLOv8 जैसे ऑब्जेक्ट डिटेक्शन मॉडल के बारे में सीखना।
- एनोटेशन टूल रोबोफ़्लो को समझना और YOLOv8 सेगमेंटेशन मॉडल के लिए डेटासेट बनाने में इसकी भूमिका।
- OpenCV (cv2) और पर्यवेक्षण का उपयोग करके लाइव ऑब्जेक्ट डिटेक्शन की खोज करना, व्यावहारिक कौशल को बढ़ाना।
- YOLOv8 का उपयोग करके एक विभाजन मॉडल का प्रशिक्षण और तैनाती, व्यावहारिक अनुभव प्राप्त करना।
आम सवाल-जवाब
A. ऑब्जेक्ट डिटेक्शन में एक छवि के भीतर कई ऑब्जेक्ट्स की पहचान करना और उनका पता लगाना शामिल है, आमतौर पर उनके चारों ओर बाउंडिंग बॉक्स बनाकर। दूसरी ओर, छवि विभाजन, पिक्सेल समानता के आधार पर एक छवि को खंडों या क्षेत्रों में विभाजित करता है, जिससे वस्तु सीमाओं की अधिक विस्तृत समझ मिलती है।
A. YOLOv8 नेटवर्क आर्किटेक्चर, प्रशिक्षण तकनीकों और अनुकूलन में प्रगति को शामिल करके पिछले संस्करणों में सुधार करता है। यह YOLOv3 की तुलना में बेहतर सटीकता, गति और दक्षता प्रदान कर सकता है।
A. YOLOv8 का उपयोग हार्डवेयर क्षमताओं और मॉडल अनुकूलन के आधार पर एम्बेडेड डिवाइस पर वास्तविक समय ऑब्जेक्ट का पता लगाने के लिए किया जा सकता है। हालाँकि, संसाधन-बाधित उपकरणों पर वास्तविक समय के प्रदर्शन को प्राप्त करने के लिए मॉडल प्रूनिंग या क्वांटिज़ेशन जैसे अनुकूलन की आवश्यकता हो सकती है।
ए. रोबोफ़्लो सहज ज्ञान युक्त एनोटेशन उपकरण, डेटासेट प्रबंधन सुविधाएँ और विभिन्न एनोटेशन प्रारूपों के लिए समर्थन प्रदान करता है। यह एनोटेशन प्रक्रिया को सुव्यवस्थित करता है, सहयोग को सक्षम बनाता है, और संस्करण नियंत्रण प्रदान करता है, जिससे कंप्यूटर विज़न परियोजनाओं के लिए डेटासेट बनाना और प्रबंधित करना आसान हो जाता है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2024/03/live-object-detection-and-image-segmentation-with-yolov8/

