लेखक द्वारा छवि
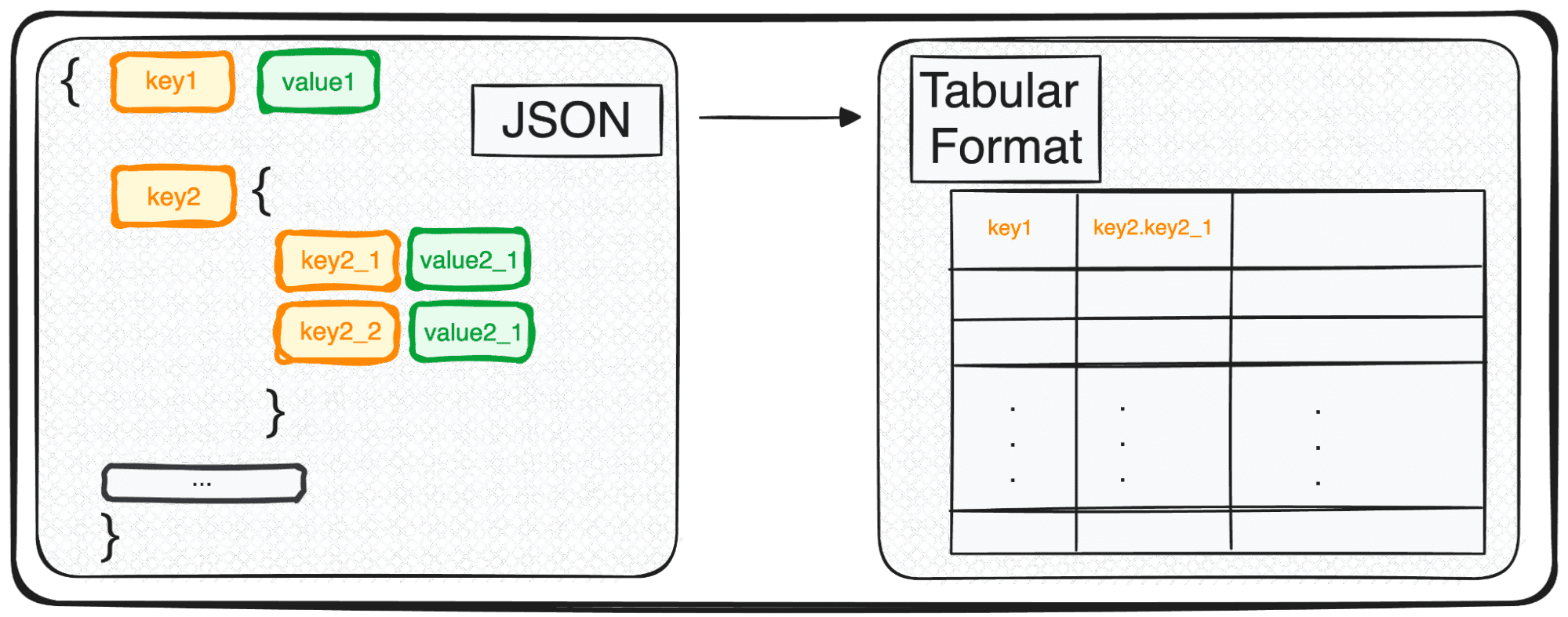
डेटा विज्ञान और मशीन लर्निंग की दुनिया में प्रवेश करते हुए, आपके सामने आने वाले मूलभूत कौशलों में से एक डेटा पढ़ने की कला है। यदि आपके पास पहले से ही इसका कुछ अनुभव है, तो आप शायद JSON (जावास्क्रिप्ट ऑब्जेक्ट नोटेशन) से परिचित हैं - डेटा भंडारण और विनिमय दोनों के लिए एक लोकप्रिय प्रारूप।
इस बारे में सोचें कि कैसे MongoDB जैसे NoSQL डेटाबेस JSON में डेटा संग्रहीत करना पसंद करते हैं, या कैसे REST API अक्सर उसी प्रारूप में प्रतिक्रिया करते हैं।
हालाँकि, JSON, भंडारण और विनिमय के लिए एकदम सही है, लेकिन अपने कच्चे रूप में गहन विश्लेषण के लिए बिल्कुल तैयार नहीं है। यहीं पर हम इसे और अधिक विश्लेषणात्मक रूप से अनुकूल - एक सारणीबद्ध प्रारूप में बदल देते हैं।
तो, चाहे आप एक JSON ऑब्जेक्ट या उनमें से एक रमणीय सरणी के साथ काम कर रहे हों, पायथन के शब्दों में, आप अनिवार्य रूप से एक निर्देश या निर्देशों की एक सूची को संभाल रहे हैं।
आइए मिलकर पता लगाएं कि यह परिवर्तन कैसे घटित होता है, जिससे हमारा डेटा विश्लेषण के लिए तैयार हो जाता है ????
आज मैं एक जादुई कमांड समझाऊंगा जो हमें किसी भी JSON को सेकंडों में सारणीबद्ध प्रारूप में आसानी से पार्स करने की अनुमति देता है।
और यह है... पीडी.json_सामान्यीकरण()
तो आइए देखें कि यह विभिन्न प्रकार के JSONs के साथ कैसे काम करता है।
JSON का पहला प्रकार जिसके साथ हम काम कर सकते हैं वह कुछ कुंजियों और मानों के साथ एकल-स्तरीय JSON है। हम अपने पहले सरल JSON को इस प्रकार परिभाषित करते हैं:
लेखक द्वारा कोड
तो आइए इन JSON के साथ काम करने की आवश्यकता का अनुकरण करें। हम सभी जानते हैं कि उनके JSON प्रारूप में करने के लिए बहुत कुछ नहीं है। हमें इन JSONs को कुछ पठनीय और परिवर्तनीय प्रारूप में बदलने की आवश्यकता है... जिसका अर्थ है पांडा डेटाफ़्रेम!
1.1 सरल JSON संरचनाओं से निपटना
सबसे पहले, हमें पांडा लाइब्रेरी को आयात करने की आवश्यकता है और फिर हम निम्नानुसार pd.json_normalize() कमांड का उपयोग कर सकते हैं:
import pandas as pd
pd.json_normalize(json_string)
इस कमांड को एकल रिकॉर्ड वाले JSON पर लागू करने से, हमें सबसे बुनियादी तालिका प्राप्त होती है। हालाँकि, जब हमारा डेटा थोड़ा अधिक जटिल होता है और JSONs की एक सूची प्रस्तुत करता है, तब भी हम बिना किसी जटिलता के उसी कमांड का उपयोग कर सकते हैं और आउटपुट कई रिकॉर्ड वाली तालिका के अनुरूप होगा।

लेखक द्वारा छवि
आसान...सही है?
अगला स्वाभाविक प्रश्न यह है कि क्या होता है जब कुछ मूल्य गायब होते हैं।
1.2 शून्य मानों से निपटना
कल्पना कीजिए कि कुछ मूल्यों की जानकारी नहीं दी गई है, उदाहरण के लिए, डेविड का आय रिकॉर्ड गायब है। हमारे JSON को एक साधारण पांडा डेटाफ़्रेम में परिवर्तित करते समय, संबंधित मान NaN के रूप में दिखाई देगा।

लेखक द्वारा छवि
और यदि मैं केवल कुछ फ़ील्ड ही प्राप्त करना चाहूँ तो क्या होगा?
1.3 केवल रुचि के उन्हीं कॉलमों का चयन करना
यदि हम कुछ विशिष्ट फ़ील्ड्स को सारणीबद्ध पांडा डेटाफ़्रेम में बदलना चाहते हैं, तो json_normalize() कमांड हमें यह चुनने की अनुमति नहीं देता है कि किन फ़ील्ड्स को बदलना है।
इसलिए, JSON की एक छोटी प्रीप्रोसेसिंग की जानी चाहिए जहां हम रुचि के केवल उन कॉलमों को फ़िल्टर करते हैं।
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
तो, चलिए कुछ और उन्नत JSON संरचना की ओर बढ़ते हैं।
बहु-स्तरीय JSONs के साथ काम करते समय हम खुद को विभिन्न स्तरों के भीतर नेस्टेड JSONs के साथ पाते हैं। प्रक्रिया पहले जैसी ही है, लेकिन इस मामले में, हम चुन सकते हैं कि हम कितने स्तरों को बदलना चाहते हैं। डिफ़ॉल्ट रूप से, कमांड हमेशा सभी स्तरों का विस्तार करेगा और सभी नेस्टेड स्तरों के संक्षिप्त नाम वाले नए कॉलम उत्पन्न करेगा।
इसलिए यदि हम निम्नलिखित JSONs को सामान्यीकृत करते हैं।
लेखक द्वारा कोड
हमें फ़ील्ड कौशल के अंतर्गत 3 कॉलम वाली निम्नलिखित तालिका मिलेगी:
- कौशल.पायथन
- कौशल.एसक्यूएल
- कौशल.जी.सी.पी
और फ़ील्ड भूमिकाओं के अंतर्गत 4 कॉलम
- भूमिकाएँ.परियोजना प्रबंधक
- भूमिकाएँ.डेटा इंजीनियर
- भूमिकाएँ.डेटा वैज्ञानिक
- भूमिकाएँ.डेटा विश्लेषक

लेखक द्वारा छवि
हालाँकि, कल्पना कीजिए कि हम सिर्फ अपने शीर्ष स्तर को बदलना चाहते हैं। हम पैरामीटर max_level को विशेष रूप से 0 पर परिभाषित करके ऐसा कर सकते हैं (max_level जिसे हम विस्तारित करना चाहते हैं)।
pd.json_normalize(mutliple_level_json_list, max_level = 0)
लंबित मान हमारे पांडा डेटाफ़्रेम के भीतर JSONs के भीतर बनाए रखे जाएंगे।

लेखक द्वारा छवि
आखिरी मामला जो हम पा सकते हैं वह JSON फ़ील्ड के भीतर एक नेस्टेड सूची है। इसलिए हम उपयोग करने के लिए सबसे पहले अपने JSONs को परिभाषित करते हैं।
लेखक द्वारा कोड
हम पायथन में पांडा का उपयोग करके इस डेटा को प्रभावी ढंग से प्रबंधित कर सकते हैं। इस संदर्भ में pd.json_normalize() फ़ंक्शन विशेष रूप से उपयोगी है। यह नेस्टेड सूची सहित JSON डेटा को विश्लेषण के लिए उपयुक्त संरचित प्रारूप में समतल कर सकता है। जब यह फ़ंक्शन हमारे JSON डेटा पर लागू होता है, तो यह एक सामान्यीकृत तालिका तैयार करता है जो नेस्टेड सूची को उसके फ़ील्ड के हिस्से के रूप में शामिल करता है।
इसके अलावा, पांडा इस प्रक्रिया को और परिष्कृत करने की क्षमता प्रदान करते हैं। pd.json_normalize() में रिकॉर्ड_पथ पैरामीटर का उपयोग करके, हम फ़ंक्शन को नेस्टेड सूची को विशेष रूप से सामान्य करने के लिए निर्देशित कर सकते हैं।
इस क्रिया के परिणामस्वरूप सूची की सामग्री के लिए विशेष रूप से एक समर्पित तालिका बनती है। डिफ़ॉल्ट रूप से, यह प्रक्रिया केवल सूची के भीतर तत्वों को प्रकट करेगी। हालाँकि, इस तालिका को अतिरिक्त संदर्भ के साथ समृद्ध करने के लिए, जैसे कि प्रत्येक रिकॉर्ड के लिए एक संबद्ध आईडी बनाए रखना, हम मेटा पैरामीटर का उपयोग कर सकते हैं।

लेखक द्वारा छवि
संक्षेप में, पायथन की पांडा लाइब्रेरी का उपयोग करके JSON डेटा को CSV फ़ाइलों में बदलना आसान और प्रभावी है।
JSON अभी भी आधुनिक डेटा भंडारण और विनिमय में सबसे आम प्रारूप है, विशेष रूप से NoSQL डेटाबेस और REST API में। हालाँकि, अपने कच्चे प्रारूप में डेटा से निपटने के दौरान यह कुछ महत्वपूर्ण विश्लेषणात्मक चुनौतियाँ प्रस्तुत करता है।
पांडा की pd.json_normalize() की महत्वपूर्ण भूमिका ऐसे प्रारूपों को संभालने और हमारे डेटा को पांडा डेटाफ़्रेम में परिवर्तित करने का एक शानदार तरीका बनकर उभरती है।
मुझे आशा है कि यह मार्गदर्शिका उपयोगी थी, और अगली बार जब आप JSON के साथ काम कर रहे हों, तो आप इसे अधिक प्रभावी तरीके से कर सकेंगे।
आप संबंधित ज्यूपिटर नोटबुक की जांच कर सकते हैं GitHub रेपो का अनुसरण कर रहा हूँ।
जोसेप फेरर बार्सिलोना से एक एनालिटिक्स इंजीनियर है। उन्होंने भौतिकी इंजीनियरिंग में स्नातक किया है और वर्तमान में मानव गतिशीलता पर लागू डेटा साइंस क्षेत्र में काम कर रहे हैं। वह डेटा विज्ञान और प्रौद्योगिकी पर केंद्रित अंशकालिक सामग्री निर्माता हैं। आप उससे संपर्क कर सकते हैं लिंक्डइन, ट्विटर or मध्यम.
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way

