यह पोस्ट MongoDB के बाबू श्रीनिवासन और रॉबर्ट वाल्टर्स के साथ मिलकर लिखी गई थी।
Apache Kafka के लिए Amazon प्रबंधित स्ट्रीमिंग (अमेज़ॅन एमएसके) एक पूरी तरह से प्रबंधित, अत्यधिक उपलब्ध अपाचे काफ्का सेवा है। अमेज़ॅन एमएसके वास्तविक समय में स्ट्रीमिंग डेटा को निगलना और संसाधित करना आसान बनाता है और एडब्ल्यूएस पारिस्थितिकी तंत्र के भीतर उस डेटा का आसानी से उपयोग करता है। साथ अमेज़ॅन एमएसके सर्वर रहित, आप अपने अनुप्रयोगों के लिए ऑन-डिमांड स्ट्रीमिंग क्षमता और भंडारण प्रदान करने के लिए आवश्यक संसाधनों का स्वचालित रूप से प्रावधान और प्रबंधन कर सकते हैं।
Amazon MSK MongoDB एटलस जैसे डेटा स्रोतों के एकीकरण का भी समर्थन करता है अमेज़न एमएसके कनेक्ट. MSK कनेक्ट का उपयोग करके Amazon MSK के साथ MongoDB डेटा के सर्वर रहित एकीकरण की अनुमति देता है मोंगोडीबी कनेक्टर अपाचे काफ्का के लिए.
MongoDB एटलस सर्वर रहित डेटाबेस सेवाएँ प्रदान करता है जो डेटा आकार और थ्रूपुट के साथ गतिशील रूप से ऊपर और नीचे स्केल करता है - और तदनुसार लागत स्केल करता है। न्यूनतम कॉन्फ़िगरेशन के साथ प्रबंधित की जाने वाली परिवर्तनीय मांगों वाले अनुप्रयोगों के लिए यह सबसे उपयुक्त है। यह MongoDB एटलस इंफ्रास्ट्रक्चर के साथ निर्मित स्वचालित अपग्रेड, एन्क्रिप्शन, सुरक्षा, मेट्रिक्स और बैकअप सुविधाओं के साथ उच्च प्रदर्शन और विश्वसनीयता प्रदान करता है।
MSK सर्वरलेस Amazon MSK के लिए एक प्रकार का क्लस्टर है। MongoDB एटलस सर्वरलेस की तरह, MSK सर्वरलेस स्वचालित रूप से गणना और भंडारण संसाधनों का प्रावधान और माप करता है। अब आप एंड-टू-एंड सर्वर रहित वर्कफ़्लो बना सकते हैं। आप MSK सर्वर रहित और MongoDB एटलस का उपयोग करके सर्वर रहित स्टोरेज का उपयोग करके सर्वर रहित अंतर्ग्रहण के साथ सर्वर रहित स्ट्रीमिंग पाइपलाइन बना सकते हैं। इसके अलावा, MSK कनेक्ट अब समर्थन करता है निजी DNS होस्टनाम. यह सर्वर रहित MSK इंस्टेंसेस को सर्वर रहित MongoDB क्लस्टर से कनेक्ट करने की अनुमति देता है एडब्ल्यूएस प्राइवेटलिंक, आपको प्लेटफ़ॉर्म के बीच सुरक्षित कनेक्टिविटी प्रदान करता है।
यदि आप गैर-सर्वर रहित क्लस्टर का उपयोग करने में रुचि रखते हैं, तो देखें Apache Kafka (MSK) के लिए Amazon प्रबंधित स्ट्रीमिंग के साथ MongoDB को एकीकृत करना.
यह पोस्ट दर्शाती है कि MSK सर्वरलेस, MSK कनेक्ट और MongoDB एटलस के साथ सर्वर रहित स्ट्रीमिंग पाइपलाइन को कैसे कार्यान्वित किया जाए।
समाधान अवलोकन
निम्नलिखित चित्र हमारे समाधान वास्तुकला को दर्शाता है।
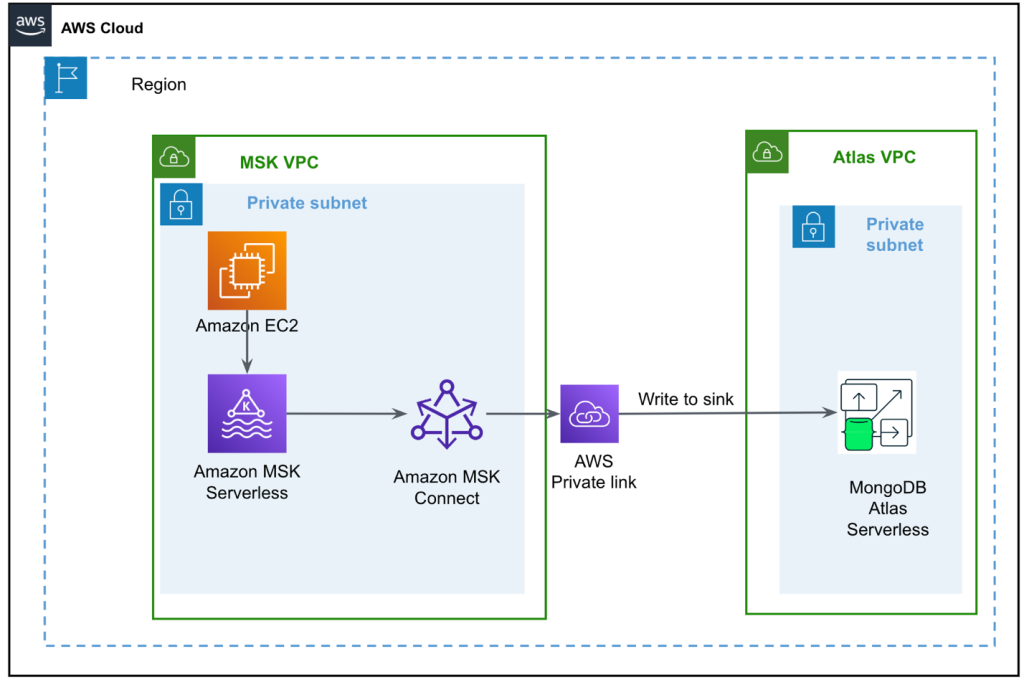
डेटा प्रवाह एक से शुरू होता है अमेज़ॅन इलास्टिक कम्प्यूट क्लाउड (अमेज़ॅन EC2) क्लाइंट इंस्टेंस जो MSK विषय पर रिकॉर्ड लिखता है। जैसे ही डेटा आता है, Apache Kafka के लिए MongoDB कनेक्टर का एक उदाहरण डेटा को MongoDB एटलस सर्वरलेस क्लस्टर में एक संग्रह में लिखता है। दो प्लेटफार्मों के बीच सुरक्षित कनेक्टिविटी के लिए, MongoDB एटलस क्लस्टर और MSK इंस्टेंस वाले VPC के बीच एक AWS PrivateLink कनेक्शन बनाया जाता है।
यह पोस्ट आपको निम्न चरणों के माध्यम से चलता है:
- सर्वर रहित MSK क्लस्टर बनाएँ।
- MongoDB एटलस सर्वर रहित क्लस्टर बनाएं।
- MSK प्लगइन कॉन्फ़िगर करें.
- EC2 क्लाइंट बनाएं.
- MSK विषय कॉन्फ़िगर करें.
- Apache Kafka के लिए MongoDB कनेक्टर को सिंक के रूप में कॉन्फ़िगर करें।
सर्वर रहित MSK क्लस्टर कॉन्फ़िगर करें
सर्वर रहित MSK क्लस्टर बनाने के लिए, निम्नलिखित चरणों को पूरा करें:
- Amazon MSK कंसोल पर, चुनें क्लस्टर नेविगेशन फलक में
- चुनें क्लस्टर बनाएं.
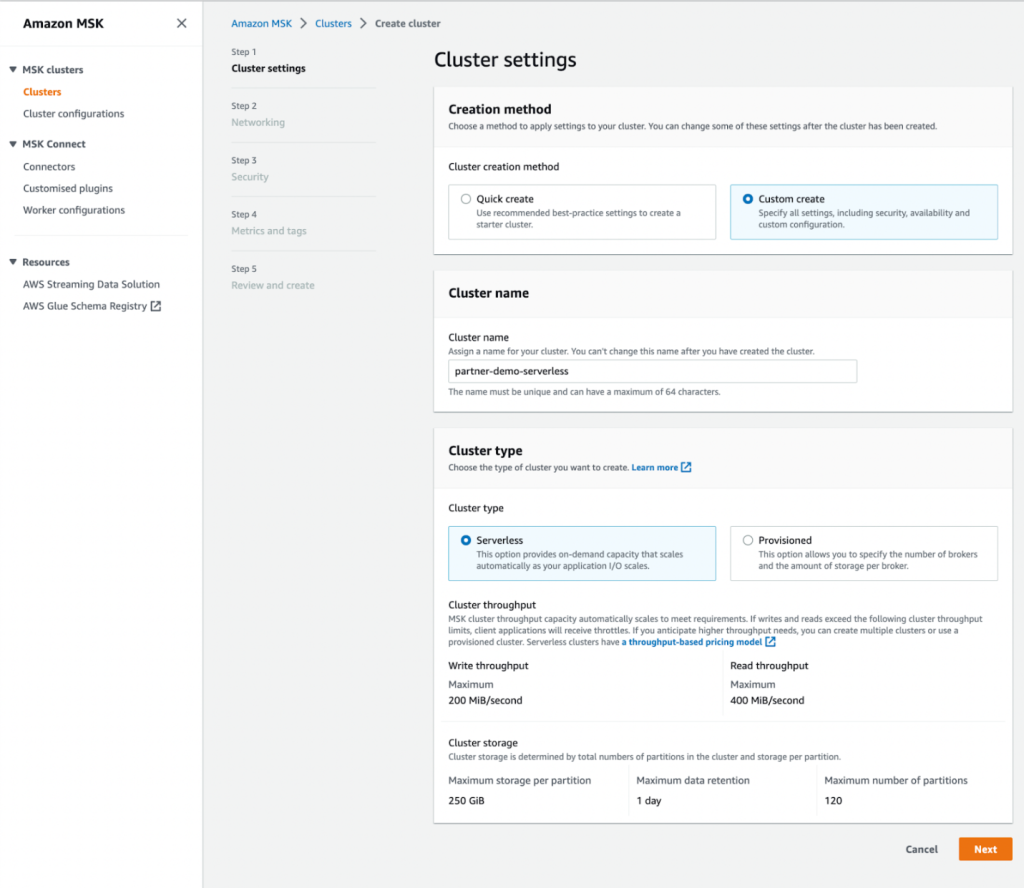
- के लिए निर्माण विधि, चुनते हैं कस्टम निर्माण.
- के लिए क्लस्टर का नाम, दर्ज
MongoDBMSKCluster. - के लिए क्लस्टर प्रकारचुनते हैं serverless.
- चुनें अगला.
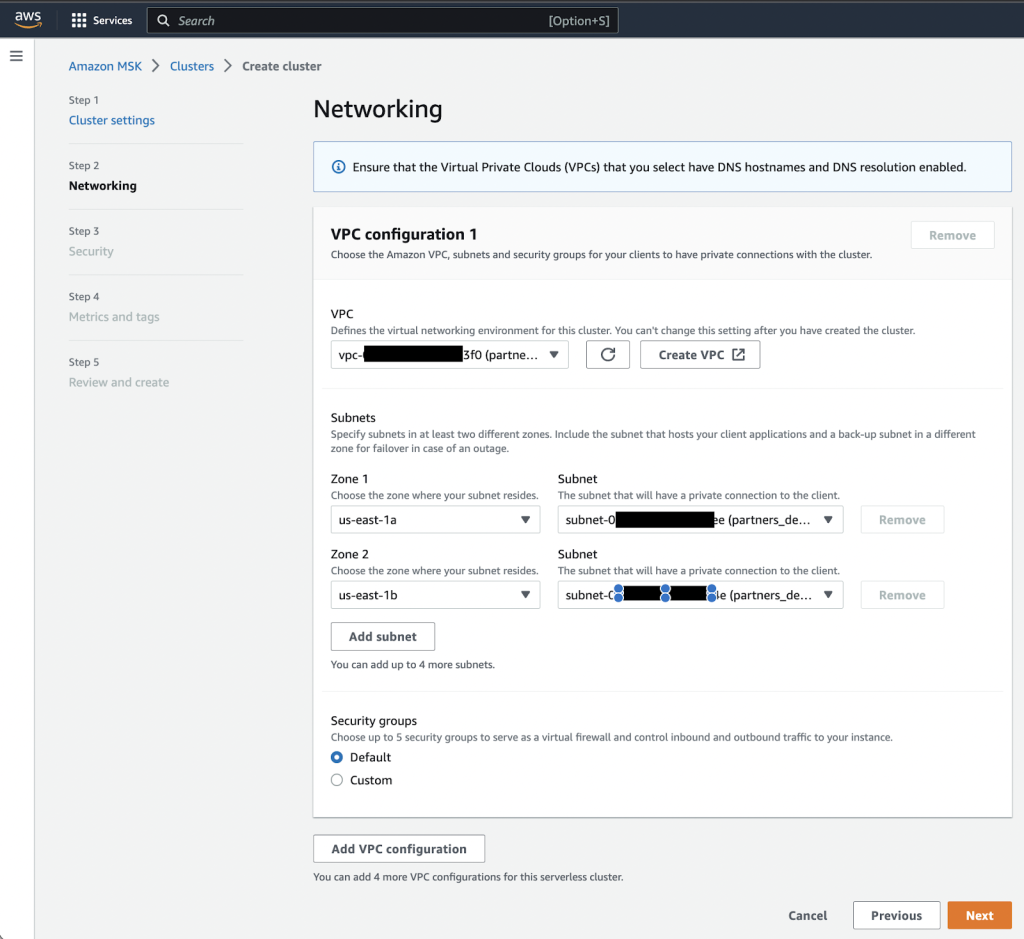
- पर शुद्ध कार्यशील पेज, अपना वीपीसी, उपलब्धता क्षेत्र और संबंधित सबनेट निर्दिष्ट करें।
- बाद में उपयोग करने के लिए उपलब्धता क्षेत्र और सबनेट पर ध्यान दें।
- चुनें अगला.
- चुनें क्लस्टर बनाएं.
जब क्लस्टर उपलब्ध होता है, तो उसकी स्थिति बन जाती है Active.

MongoDB एटलस सर्वर रहित क्लस्टर बनाएं
MongoDB एटलस क्लस्टर बनाने के लिए, इसका अनुसरण करें एटलस के साथ शुरुआत करना ट्यूटोरियल. ध्यान दें कि इस पोस्ट के प्रयोजनों के लिए, आपको एक सर्वर रहित इंस्टेंस बनाना होगा।

क्लस्टर बनने के बाद, निम्नलिखित चरणों के साथ AWS निजी एंडपॉइंट को कॉन्फ़िगर करें:
- पर सुरक्षा मेनू, चुनें नेटवर्क का उपयोग.

- पर निजी समापन बिंदु टैब चुनें सर्वर रहित उदाहरण.

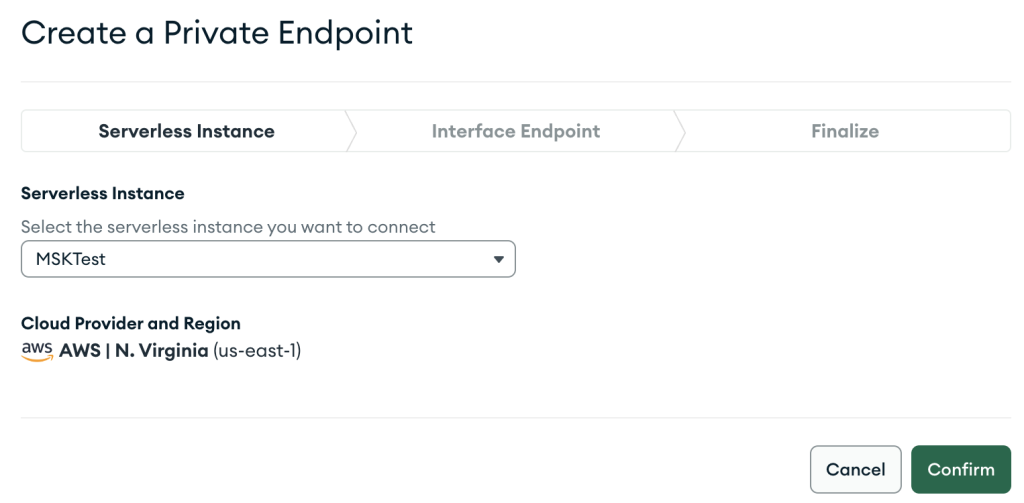
- चुनें नया समापन बिंदु बनाएं.
- के लिए सर्वर रहित उदाहरण, वह उदाहरण चुनें जिसे आपने अभी बनाया है।
- चुनें पुष्टि करें.
- अपना वीपीसी एंडपॉइंट कॉन्फ़िगरेशन प्रदान करें और चुनें अगला.
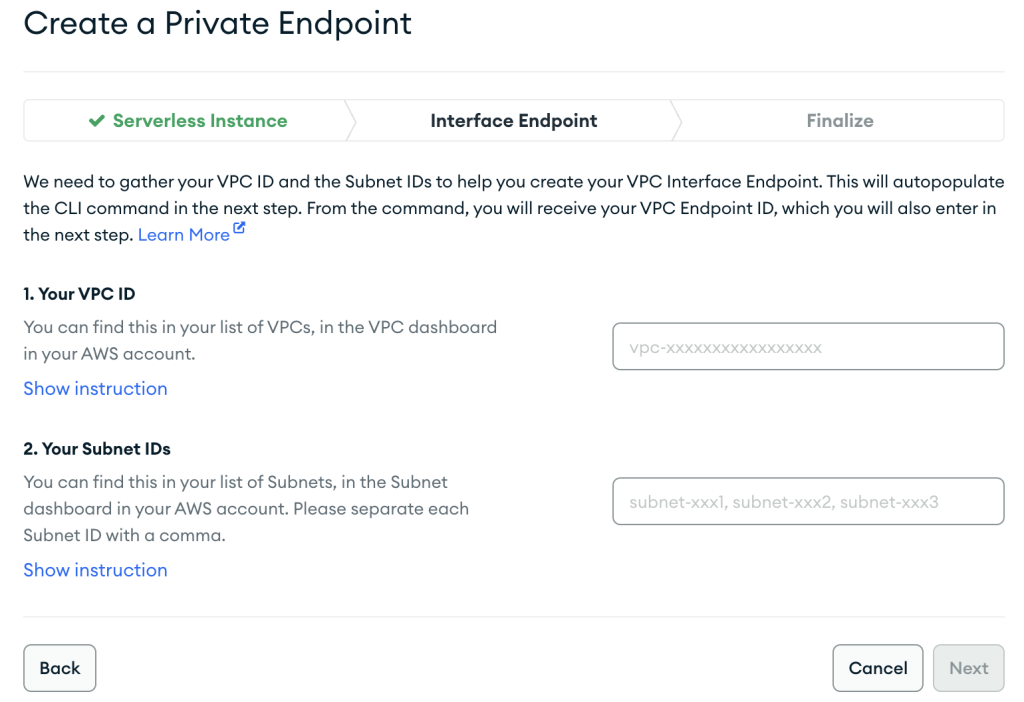
- AWS PrivateLink संसाधन बनाते समय, सुनिश्चित करें कि आप ठीक उसी VPC और सबनेट को निर्दिष्ट करते हैं जो आपने पहले सर्वर रहित MSK उदाहरण के लिए नेटवर्किंग कॉन्फ़िगरेशन बनाते समय उपयोग किया था।
- चुनें अगला.
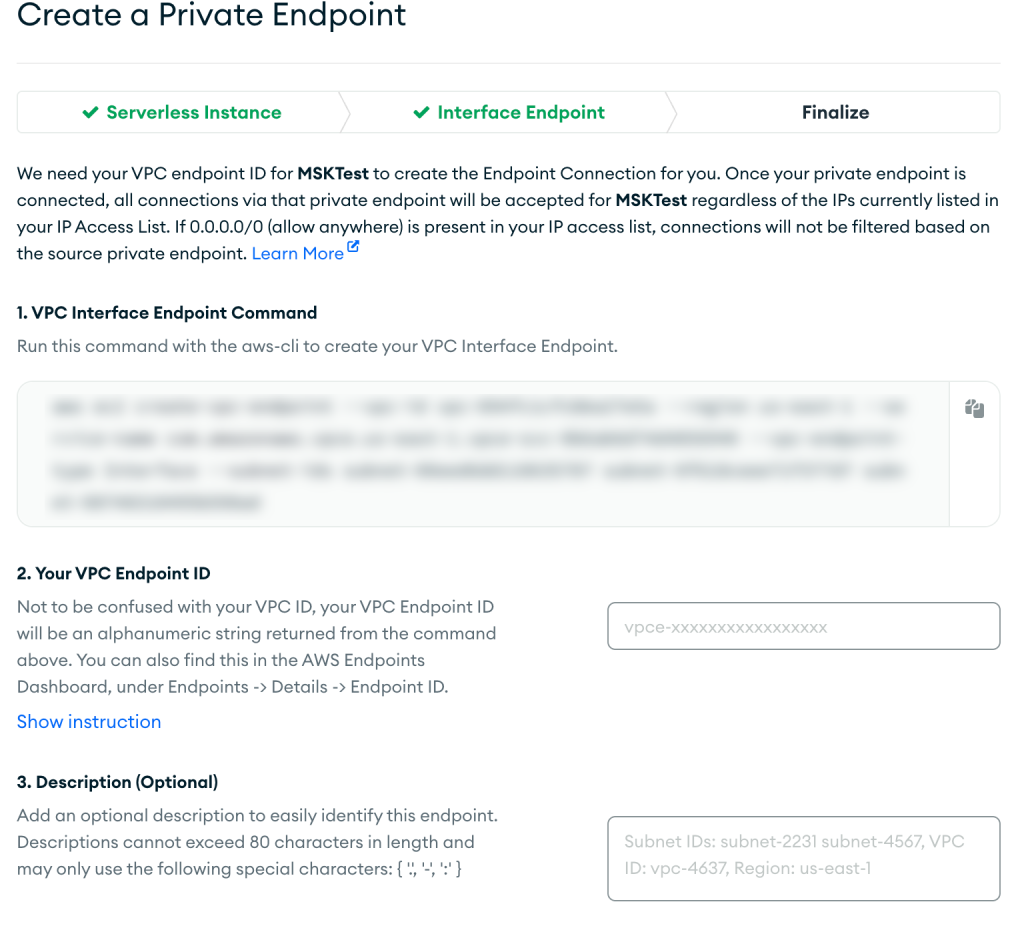
- पर निर्देशों का पालन करें अंतिम रूप पेज, फिर चुनें पुष्टि करें आपका वीपीसी एंडपॉइंट बनने के बाद।
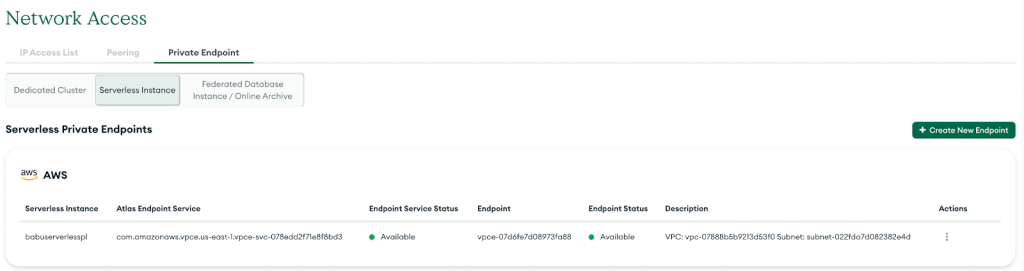
सफल होने पर, नया निजी समापन बिंदु सूची में दिखाई देगा, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
MSK प्लगइन कॉन्फ़िगर करें
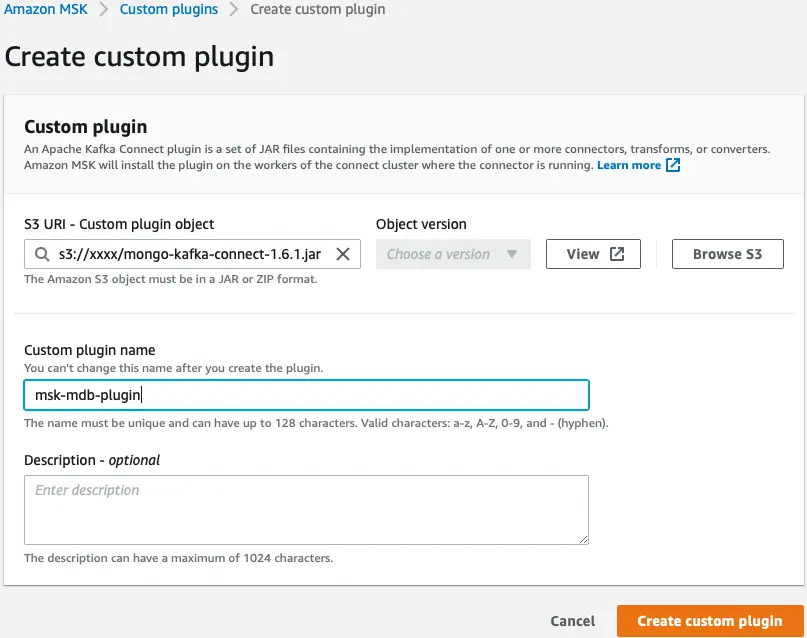
इसके बाद, हम Apache Kafka के लिए MongoDB कनेक्टर का उपयोग करके Amazon MSK में एक कस्टम प्लगइन बनाते हैं। कनेक्टर को किसी पर अपलोड करना होगा अमेज़न सरल भंडारण सेवा (अमेज़ॅन S3) प्लगइन बनाने से पहले बकेट। Apache Kafka के लिए MongoDB कनेक्टर डाउनलोड करने के लिए, देखें एक कनेक्टर JAR फ़ाइल डाउनलोड करें.
- Amazon MSK कंसोल पर, चुनें अनुकूलित प्लगइन्स नेविगेशन फलक में
- चुनें कस्टम प्लगइन बनाएं.
- के लिए एस३ यूआरआई, डाउनलोड किए गए कनेक्टर का S3 स्थान दर्ज करें।
- चुनें कस्टम प्लगइन बनाएं.
EC2 क्लाइंट कॉन्फ़िगर करें
इसके बाद, आइए एक EC2 इंस्टेंस कॉन्फ़िगर करें। हम इस उदाहरण का उपयोग विषय बनाने और विषय में डेटा डालने के लिए करते हैं। निर्देशों के लिए, अनुभाग देखें EC2 क्लाइंट कॉन्फ़िगर करें पोस्ट में Apache Kafka (MSK) के लिए Amazon प्रबंधित स्ट्रीमिंग के साथ MongoDB को एकीकृत करना.
MSK क्लस्टर पर एक विषय बनाएँ
काफ्का विषय बनाने के लिए, हमें पहले काफ्का सीएलआई स्थापित करना होगा।
- क्लाइंट EC2 इंस्टेंस पर, पहले Java इंस्टॉल करें:
sudo yum install java-1.8.0
- इसके बाद, अपाचे काफ्का डाउनलोड करने के लिए निम्नलिखित कमांड चलाएँ:
wget https://archive.apache.org/dist/kafka/2.6.2/kafka_2.12-2.6.2.tgz
- निम्नलिखित कमांड का उपयोग करके टार फ़ाइल को अनपैक करें:
tar -xzf kafka_2.12-2.6.2.tgz
काफ्का के वितरण में उपकरणों के साथ एक बिन फ़ोल्डर शामिल है जिसका उपयोग विषयों को प्रबंधित करने के लिए किया जा सकता है।
- इस पर जाएँ
kafka_2.12-2.6.2निर्देशिका और सर्वर रहित MSK क्लस्टर पर काफ्का विषय बनाने के लिए निम्नलिखित आदेश जारी करें:
bin/kafka-topics.sh --create --topic sandbox_sync2 --bootstrap-server <BOOTSTRAP SERVER> --command-config=bin/client.properties --partitions 2
आप बूटस्ट्रैप सर्वर एंडपॉइंट को कॉपी कर सकते हैं ग्राहक जानकारी देखें आपके सर्वर रहित MSK क्लस्टर के लिए पृष्ठ।
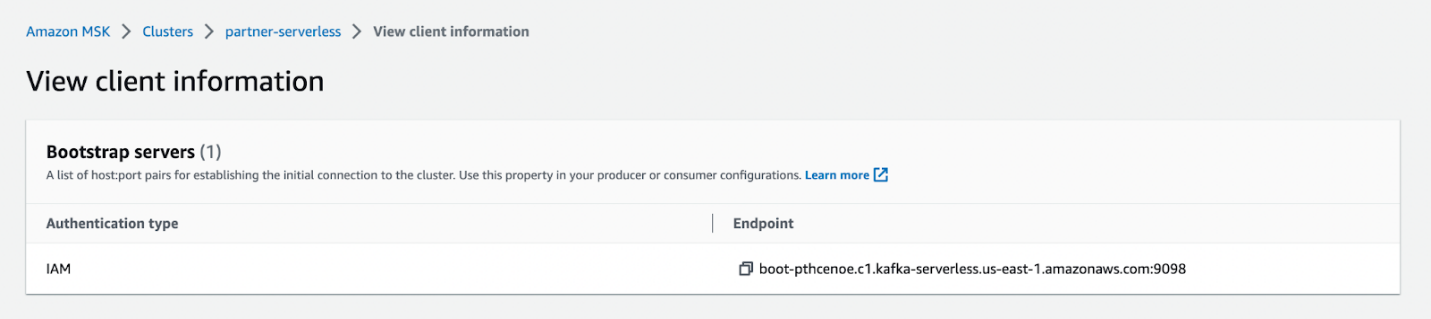
आप इनका पालन करके IAM प्रमाणीकरण को कॉन्फ़िगर कर सकते हैं निर्देश.
सिंक कनेक्टर को कॉन्फ़िगर करें
अब, MongoDB एटलस सर्वरलेस इंस्टेंस पर डेटा भेजने के लिए एक सिंक कनेक्टर को कॉन्फ़िगर करें।
- Amazon MSK कंसोल पर, चुनें कनेक्टर्स नेविगेशन फलक में
- चुनें कनेक्टर बनाएँ.
- आपके द्वारा पहले बनाया गया प्लगइन चुनें।
- चुनें अगला.
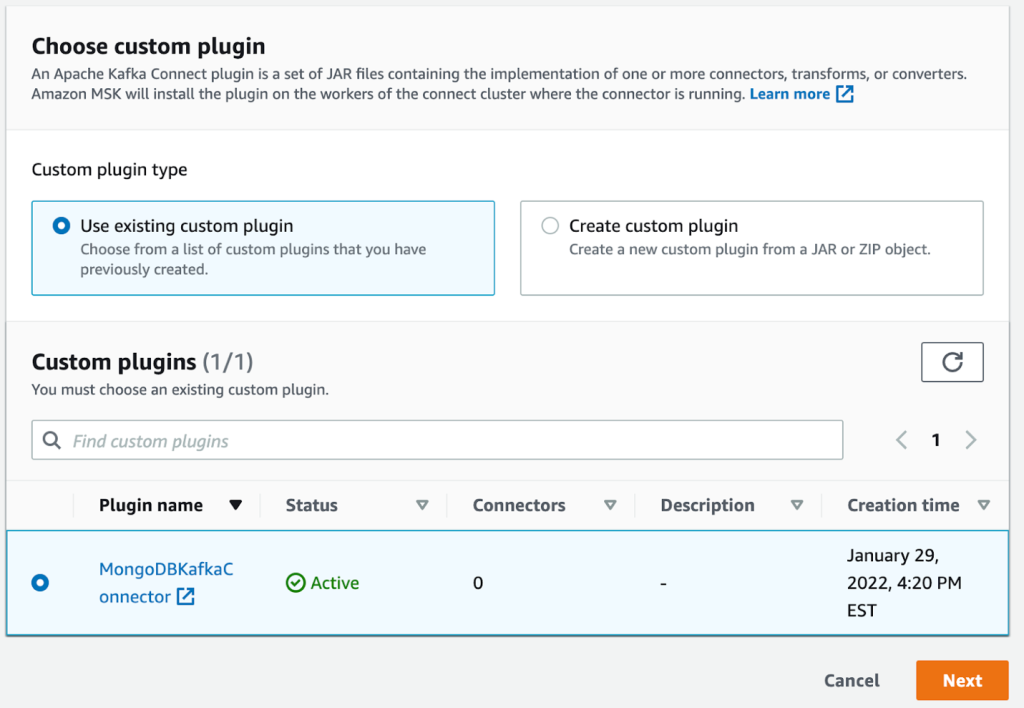
- सर्वर रहित MSK इंस्टेंस का चयन करें जिसे आपने पहले बनाया था।
- अपना कनेक्शन कॉन्फ़िगरेशन निम्नलिखित कोड के रूप में दर्ज करें:
सुनिश्चित करें कि MongoDB एटलस सर्वरलेस इंस्टेंस से कनेक्शन AWS PrivateLink के माध्यम से है। अधिक जानकारी के लिए देखें AWS PrivateLink के साथ अनुप्रयोगों को MongoDB एटलस डेटा प्लेन से सुरक्षित रूप से कनेक्ट करना.
- में पहुँच अनुमतियाँ अनुभाग, एक बनाएं AWS पहचान और अभिगम प्रबंधन (IAM) के साथ भूमिका आवश्यक विश्वास नीति.
- चुनें अगला.
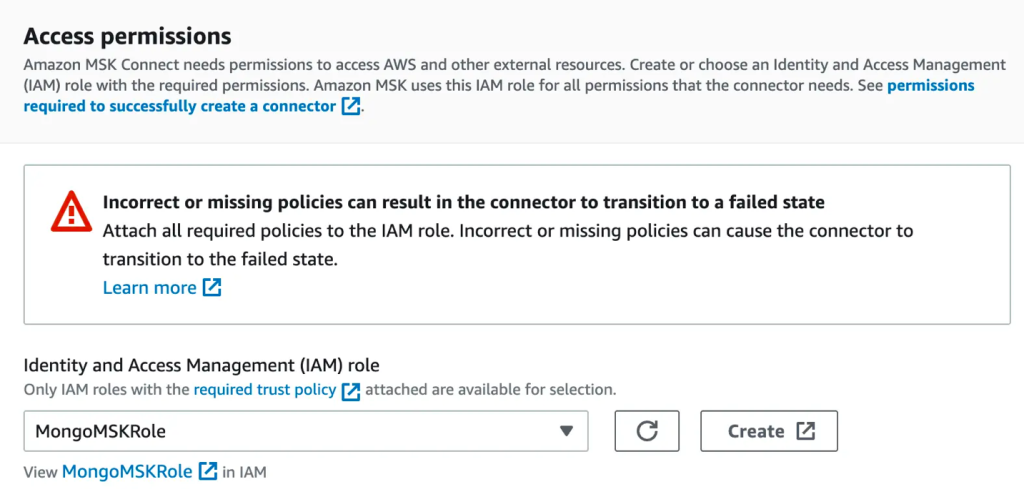
- निर्दिष्ट करें अमेज़न CloudWatch लॉग आपके लॉग डिलीवरी विकल्प के रूप में।
- अपना कनेक्टर पूरा करें.
जब कनेक्टर स्थिति सक्रिय में बदल जाती है, तो पाइपलाइन तैयार है।

MSK विषय में डेटा डालें
अपने EC2 क्लाइंट पर, का उपयोग करके MSK विषय में डेटा डालें kafka-console-producer के रूप में इस प्रकार है:
यह सत्यापित करने के लिए कि डेटा काफ्का विषय से सर्वर रहित MongoDB क्लस्टर में सफलतापूर्वक प्रवाहित होता है, हम MongoDB एटलस UI का उपयोग करते हैं।
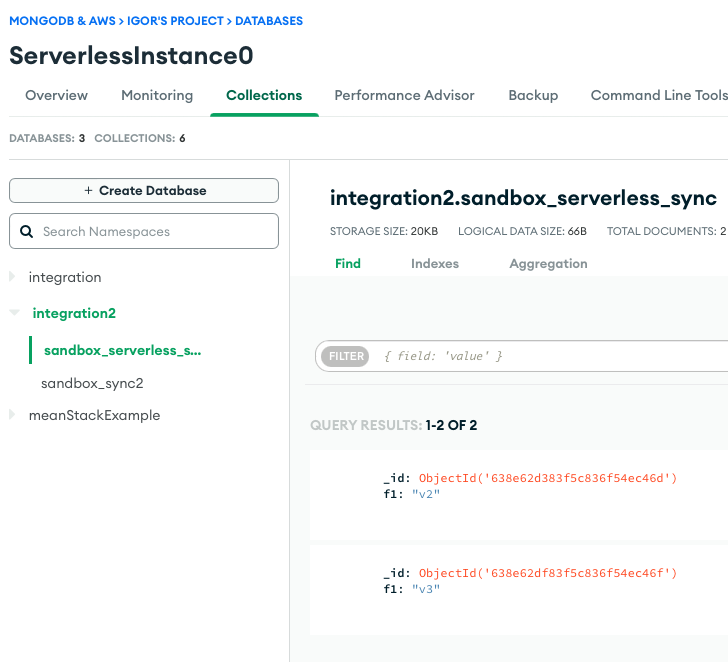
यदि आपको कोई समस्या आती है, तो लॉग फ़ाइलों की जाँच करना सुनिश्चित करें। इस उदाहरण में, हमने अमेज़ॅन एमएसके और अपाचे काफ्का के लिए मोंगोडीबी कनेक्टर से उत्पन्न घटनाओं को पढ़ने के लिए क्लाउडवॉच का उपयोग किया।
क्लीन अप
भविष्य के शुल्कों से बचने के लिए, अपने द्वारा बनाए गए संसाधनों को साफ़ करें। सबसे पहले, MSK क्लस्टर, कनेक्टर और EC2 इंस्टेंस हटाएं:
- Amazon MSK कंसोल पर, चुनें क्लस्टर नेविगेशन फलक में
- अपना क्लस्टर चुनें और पर क्रियाएँ मेनू, चुनें मिटाना.
- चुनें कनेक्टर्स नेविगेशन फलक में
- अपना कनेक्टर चुनें और चुनें मिटाना.
- चुनें अनुकूलित प्लगइन्स नेविगेशन फलक में
- अपना प्लगइन चुनें और चुनें मिटाना.
- Amazon EC2 कंसोल पर, चुनें उदाहरण नेविगेशन फलक में
- आपके द्वारा बनाया गया उदाहरण चुनें.
- चुनें उदाहरण स्थिति, उसके बाद चुनो उदाहरण समाप्त करें.
- पर अमेज़ॅन वीपीसी सांत्वना, चुनें endpoints नेविगेशन फलक में
- आपके द्वारा बनाए गए एंडपॉइंट का चयन करें और पर क्रियाएँ मेनू, चुनें वीपीसी एंडपॉइंट हटाएं.
अब आप एटलस क्लस्टर और AWS PrivateLink को हटा सकते हैं:
- एटलस क्लस्टर कंसोल में लॉग इन करें।
- हटाए जाने वाले सर्वर रहित क्लस्टर पर नेविगेट करें।
- विकल्प ड्रॉप-डाउन मेनू पर, चुनें बर्खास्त.

- पर नेविगेट करें नेटवर्क का उपयोग अनुभाग।
- निजी समापन बिंदु चुनें.
- सर्वर रहित उदाहरण का चयन करें.
- विकल्प ड्रॉप-डाउन मेनू पर, चुनें बर्खास्त.

सारांश
इस पोस्ट में, हमने आपको दिखाया कि MSK सर्वरलेस और MongoDB एटलस सर्वरलेस का उपयोग करके सर्वर रहित स्ट्रीमिंग अंतर्ग्रहण पाइपलाइन कैसे बनाई जाए। MSK सर्वरलेस के साथ, आप आवश्यकतानुसार आवश्यक संसाधनों का स्वचालित रूप से प्रावधान और प्रबंधन कर सकते हैं। हमने दो सेवाओं को सहजता से एकीकृत करने के लिए MSK कनेक्ट पर तैनात MongoDB कनेक्टर का उपयोग किया, और MSK विषय पर नमूना डेटा भेजने के लिए EC2 क्लाइंट का उपयोग किया। MSK कनेक्ट अब समर्थन करता है निजी DNS होस्टनाम, आपको सेवाओं के बीच निजी डोमेन नामों का उपयोग करने में सक्षम बनाता है। इस पोस्ट में, कनेक्टर ने उपलब्धता क्षेत्र-विशिष्ट निजी DNS नाम को हल करने के लिए VPC के डिफ़ॉल्ट DNS सर्वर का उपयोग किया। इस AWS प्राइवेटलिंक कॉन्फ़िगरेशन ने MSK सर्वरलेस इंस्टेंस और MongoDB एटलस सर्वरलेस इंस्टेंस के बीच सुरक्षित और निजी कनेक्टिविटी की अनुमति दी।
अपना सीखना जारी रखने के लिए, निम्नलिखित संसाधन देखें:
लेखक के बारे में

इगोर अलेक्सेव डेटा और एनालिटिक्स डोमेन में AWS में सीनियर पार्टनर सॉल्यूशन आर्किटेक्ट हैं। अपनी भूमिका में इगोर रणनीतिक साझेदारों के साथ काम कर रहे हैं, जिससे उन्हें जटिल, एडब्ल्यूएस-अनुकूलित आर्किटेक्चर बनाने में मदद मिल रही है। AWS में शामिल होने से पहले, एक डेटा/समाधान वास्तुकार के रूप में उन्होंने Hadoop पारिस्थितिकी तंत्र में कई डेटा झीलों सहित बिग डेटा डोमेन में कई परियोजनाओं को लागू किया। डेटा इंजीनियर के रूप में वह धोखाधड़ी का पता लगाने और कार्यालय स्वचालन के लिए एआई/एमएल लगाने में शामिल थे।
 किरण मैटी Amazon Web Services (AWS) के साथ एक प्रधान उत्पाद प्रबंधक है और Palo Alto, California में स्थित Apache Kafka (Amazon MSK) टीम के लिए Amazon प्रबंधित स्ट्रीमिंग के साथ काम करता है। वह प्रदर्शनकारी स्ट्रीमिंग और विश्लेषणात्मक सेवाओं के निर्माण के बारे में भावुक हैं जो उद्यमों को उनके महत्वपूर्ण उपयोग के मामलों को महसूस करने में मदद करती हैं।
किरण मैटी Amazon Web Services (AWS) के साथ एक प्रधान उत्पाद प्रबंधक है और Palo Alto, California में स्थित Apache Kafka (Amazon MSK) टीम के लिए Amazon प्रबंधित स्ट्रीमिंग के साथ काम करता है। वह प्रदर्शनकारी स्ट्रीमिंग और विश्लेषणात्मक सेवाओं के निर्माण के बारे में भावुक हैं जो उद्यमों को उनके महत्वपूर्ण उपयोग के मामलों को महसूस करने में मदद करती हैं।
 बाबू श्रीनिवासन MongoDB में सीनियर पार्टनर सॉल्यूशंस आर्किटेक्ट हैं। अपनी वर्तमान भूमिका में, वह AWS और MongoDB समाधानों के लिए तकनीकी एकीकरण और संदर्भ आर्किटेक्चर बनाने के लिए AWS के साथ काम कर रहा है। उनके पास डेटाबेस और क्लाउड प्रौद्योगिकियों में दो दशकों से अधिक का अनुभव है। उन्हें कई भौगोलिक क्षेत्रों में मल्टीपल ग्लोबल सिस्टम इंटीग्रेटर्स (जीएसआई) के साथ काम करने वाले ग्राहकों को तकनीकी समाधान प्रदान करने का शौक है।
बाबू श्रीनिवासन MongoDB में सीनियर पार्टनर सॉल्यूशंस आर्किटेक्ट हैं। अपनी वर्तमान भूमिका में, वह AWS और MongoDB समाधानों के लिए तकनीकी एकीकरण और संदर्भ आर्किटेक्चर बनाने के लिए AWS के साथ काम कर रहा है। उनके पास डेटाबेस और क्लाउड प्रौद्योगिकियों में दो दशकों से अधिक का अनुभव है। उन्हें कई भौगोलिक क्षेत्रों में मल्टीपल ग्लोबल सिस्टम इंटीग्रेटर्स (जीएसआई) के साथ काम करने वाले ग्राहकों को तकनीकी समाधान प्रदान करने का शौक है।
 रॉबर्ट वाल्टर्स वर्तमान में MongoDB में वरिष्ठ उत्पाद प्रबंधक हैं। MongoDB से पहले, रोब ने Microsoft में SQL सर्वर टीम पर प्रोग्राम प्रबंधन, परामर्श और तकनीकी पूर्व-बिक्री सहित विभिन्न भूमिकाओं में काम करते हुए 17 साल बिताए। रोब ने SQL सर्वर के भीतर उपयोग की जाने वाली प्रौद्योगिकियों के लिए तीन पेटेंट का सह-लेखन किया है और SQL सर्वर पर कई तकनीकी पुस्तकों के प्रमुख लेखक थे। रोब वर्तमान में MongoDB ब्लॉग्स पर एक सक्रिय ब्लॉगर है।
रॉबर्ट वाल्टर्स वर्तमान में MongoDB में वरिष्ठ उत्पाद प्रबंधक हैं। MongoDB से पहले, रोब ने Microsoft में SQL सर्वर टीम पर प्रोग्राम प्रबंधन, परामर्श और तकनीकी पूर्व-बिक्री सहित विभिन्न भूमिकाओं में काम करते हुए 17 साल बिताए। रोब ने SQL सर्वर के भीतर उपयोग की जाने वाली प्रौद्योगिकियों के लिए तीन पेटेंट का सह-लेखन किया है और SQL सर्वर पर कई तकनीकी पुस्तकों के प्रमुख लेखक थे। रोब वर्तमान में MongoDB ब्लॉग्स पर एक सक्रिय ब्लॉगर है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/build-a-serverless-streaming-pipeline-with-amazon-msk-serverless-amazon-msk-connect-and-mongodb-atlas/

