
लेखक द्वारा छवि
यदि आप जानते हैं कि मशीन लर्निंग निर्णय वृक्ष कैसे बनाया जाता है, तो बधाई हो, आपके पास यह है कोड विशेषज्ञता का समान स्तर चैटजीपीटी और हजारों अन्य डेटा वैज्ञानिकों के रूप में जो आपकी इच्छित नौकरी के लिए प्रतिस्पर्धा कर रहे हैं।
हाल ही में प्रबंधकों को काम पर रखने के बीच एक आकर्षक प्रवृत्ति यह है कि कच्ची कोडिंग क्षमता अब इसमें कटौती नहीं करती है। काम पर रखने के लिए, आपको भाषाओं, रूपरेखाओं और स्टैक ओवरफ्लो पर खोज करने के तरीके को जानने से एक कदम ऊपर जाना होगा। आपको कहीं अधिक वैचारिक समझ और आज के डेटा विज्ञान परिदृश्य की समझ की आवश्यकता है - जिसमें ऐसी चीजें भी शामिल हैं जिनके बारे में आप सोचते हैं कि केवल कंपनी के सीईओ को चिंतित होना चाहिए, जैसे डेटा प्रशासन और नैतिकता।
इसमें कई तकनीकी और गैर-तकनीकी हैं डेटा विज्ञान कौशल यह आपको पता होना चाहिए, लेकिन यदि आपको काम पर रखने में कठिनाई हो रही है, तो ये कम सामान्य डेटा विज्ञान कौशल आपके लिए रोजगार के द्वार तक पहुंचने का टिकट हो सकते हैं।
पहले, डेटा वैज्ञानिक अकेले अंधेरे भूमिगत तहखानों में मॉडल तैयार करने का काम करते थे। मॉडल भविष्यवाणियाँ या अंतर्दृष्टि पैदा करेंगे; उन्हें सी-सूट अधिकारियों को सौंप दिया जाएगा जो उस मॉडल की समझ के बिना उन पर कार्रवाई करेंगे जिसने इन भविष्यवाणियों का उत्पादन किया था। (मैं थोड़ा अतिशयोक्ति कर रहा हूं, लेकिन उतना नहीं।)
आज, डेटा वैज्ञानिकों के उत्पादों को समझने में नेतृत्व कहीं अधिक सक्रिय भूमिका निभाता है। इसका मतलब है कि एक डेटा वैज्ञानिक के रूप में आपको यह समझाने में सक्षम होना चाहिए कि मॉडल जो करते हैं वह क्यों करते हैं, वे कैसे काम करते हैं, और वे उस विशेष भविष्यवाणी के साथ क्यों आए।
हालाँकि आप अपने बॉस को अपने मॉडल को चलाने वाला वास्तविक कोड दिखा सकते हैं, लेकिन विज़ुअलाइज़ेशन के माध्यम से उन्हें यह दिखाना अधिक उपयोगी (पढ़ें: रोजगार योग्य) है कि आपका मॉडल कैसे काम करता है। उदाहरण के लिए, कल्पना करें कि आपने एक एमएल मॉडल विकसित किया है जो एक दूरसंचार कंपनी के लिए ग्राहक मंथन की भविष्यवाणी करता है। अपने कोड की पंक्तियों के स्क्रीनशॉट के बजाय, आप फ़्लोचार्ट या निर्णय वृक्ष आरेख का उपयोग करके स्पष्ट रूप से समझा सकते हैं कि मॉडल ग्राहकों को कैसे विभाजित करता है और मंथन के जोखिम वाले लोगों की पहचान करता है। यह मॉडल के तर्क को पारदर्शी और समझने में आसान बनाता है।
कोड को चित्रित करने का तरीका जानना एक दुर्लभ कौशल है, लेकिन निश्चित रूप से इसे विकसित करने लायक है। अभी तक कोई पाठ्यक्रम नहीं है, लेकिन मेरा सुझाव है कि आप अपने निर्णय वृक्ष का दस्तावेज़ीकरण करने वाला फ़्लोचार्ट बनाने के लिए मिरो जैसे मुफ़्त टूल आज़माएँ। इससे भी बेहतर, किसी गैर-डेटा वैज्ञानिक मित्र या परिवार के सदस्य को अपना कोड समझाने का प्रयास करें। जितना अधिक लेटोगे, उतना अच्छा होगा।

लेखक द्वारा छवि
कई डेटा वैज्ञानिक इनपुट डेटा की बारीकियों की तुलना में मॉडल एल्गोरिदम पर अधिक ध्यान केंद्रित करते हैं। फ़ीचर इंजीनियरिंग मशीन लर्निंग मॉडल के प्रदर्शन को बेहतर बनाने के लिए सुविधाओं (इनपुट चर) को चुनने, संशोधित करने और बनाने की प्रक्रिया है।
उदाहरण के लिए, यदि आप रियल एस्टेट की कीमतों के लिए पूर्वानुमानित मॉडल पर काम कर रहे हैं, तो आप वर्ग फुटेज, शयनकक्षों की संख्या और स्थान जैसी बुनियादी सुविधाओं से शुरुआत कर सकते हैं। हालाँकि, फीचर इंजीनियरिंग के माध्यम से, आप अधिक सूक्ष्म सुविधाएँ बना सकते हैं। आप निकटतम सार्वजनिक परिवहन स्टेशन की दूरी की गणना कर सकते हैं या एक ऐसी सुविधा बना सकते हैं जो संपत्ति की उम्र का प्रतिनिधित्व करती हो। आप नए फीचर्स बनाने के लिए मौजूदा सुविधाओं को भी जोड़ सकते हैं, जैसे अपराध दर, स्कूल रेटिंग और सुविधाओं की निकटता के आधार पर "स्थान वांछनीयता स्कोर"।
यह एक दुर्लभ कौशल है क्योंकि इसके लिए न केवल तकनीकी जानकारी की आवश्यकता होती है, बल्कि गहन डोमेन ज्ञान और रचनात्मकता की भी आवश्यकता होती है। आपको वास्तव में इसकी आवश्यकता है मिल आपका डेटा और मौजूदा समस्या, और फिर मॉडलिंग के लिए इसे और अधिक उपयोगी बनाने के लिए डेटा को रचनात्मक रूप से रूपांतरित करें।
फ़ीचर इंजीनियरिंग को अक्सर कौरसेरा, ईडीएक्स, या उडासिटी जैसे प्लेटफार्मों पर व्यापक मशीन लर्निंग पाठ्यक्रमों के हिस्से के रूप में कवर किया जाता है। लेकिन मुझे लगता है कि सीखने का सबसे अच्छा तरीका व्यावहारिक अनुभव है। वास्तविक दुनिया के डेटा पर काम करें और विभिन्न फीचर इंजीनियरिंग रणनीतियों के साथ प्रयोग करें।
यहां एक काल्पनिक प्रश्न है: कल्पना कीजिए कि आप एक स्वास्थ्य सेवा कंपनी में डेटा वैज्ञानिक हैं। आपको एक निश्चित बीमारी के जोखिम वाले रोगियों की पहचान करने के लिए एक पूर्वानुमान मॉडल विकसित करने का काम सौंपा गया है। आपकी सबसे बड़ी चुनौती क्या होने की संभावना है?
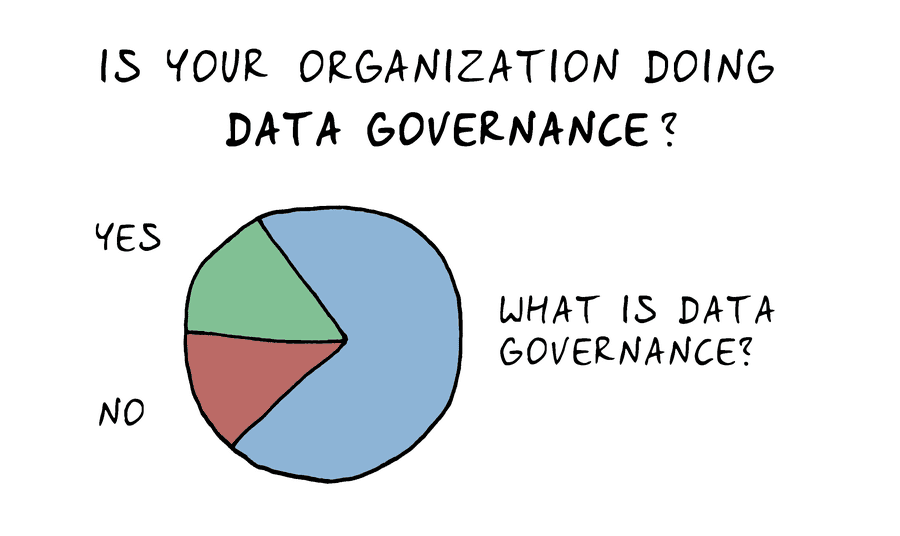
यदि आपने उत्तर दिया है, "ईटीएल पाइपलाइनों से जूझना," तो आप गलत हैं। आपकी सबसे बड़ी चुनौती यह सुनिश्चित करना हो सकती है कि आपका मॉडल न केवल प्रभावी हो बल्कि अनुपालनशील, नैतिक और टिकाऊ भी हो। इसमें यह सुनिश्चित करना शामिल है कि मॉडल के लिए आपके द्वारा एकत्र किया गया कोई भी डेटा आपके स्थान के आधार पर HIPAA और GDPR जैसे नियमों का अनुपालन करता है। आपको यह जानना होगा कि उस डेटा का उपयोग करना कब कानूनी है, आपको इसे कैसे गुमनाम करना है, आपको रोगियों से किस सहमति की आवश्यकता है, और वह सहमति कैसे प्राप्त करें।
और आपको डेटा स्रोतों, परिवर्तनों और मॉडल निर्णयों का दस्तावेजीकरण करने में सक्षम होना चाहिए ताकि एक गैर-विशेषज्ञ मॉडल का ऑडिट करने में सक्षम हो सके। यह पता लगाने की क्षमता न केवल नियामक अनुपालन के लिए बल्कि भविष्य के मॉडल ऑडिट और सुधार के लिए भी महत्वपूर्ण है।
डेटा गवर्नेंस कहाँ से सीखें: यह सघन है, लेकिन एक महान संसाधन है वैश्विक डेटा प्रबंधन समुदाय.
से छवि dataedo
"मुझे पता है कि डेटा विज्ञान मूल रूप से आंकड़े जान सकता है, मॉडल बना सकता है, रुझान ढूंढ सकता है, लेकिन अगर आपने मुझसे पूछा, तो मैं किसी भी वास्तविक नैतिक दुविधा के बारे में नहीं सोच सकता, मुझे लगता है कि डेटा विज्ञान केवल वास्तविक तथ्यों को सामने लाता है।" कहा Reddit उपयोगकर्ता Carlos_tec17, गलत तरीके से।
कानूनी अनुपालन से परे, विचार करने के लिए एक नैतिक पहलू भी है। आपको यह सुनिश्चित करने की आवश्यकता है कि आपके द्वारा बनाया गया कोई भी मॉडल अनजाने में ऐसे पूर्वाग्रहों का परिचय नहीं देता है जो कुछ समूहों के साथ असमान व्यवहार का कारण बन सकते हैं।
मुझे इसका उदाहरण पसंद है अमेज़न का पुराना भर्ती मॉडल यह समझाने के लिए कि नैतिकता क्यों मायने रखती है। यदि आप इससे परिचित नहीं हैं, तो अमेज़ॅन डेटा वैज्ञानिकों ने एक ऐसा मॉडल बनाकर अपने भर्ती वर्कफ़्लो को तेज़ करने का प्रयास किया है जो बायोडाटा के आधार पर संभावित नियुक्तियों को चुन सकता है। समस्या यह थी कि उन्होंने मॉडल को अपने मौजूदा बायोडाटा के आधार पर प्रशिक्षित किया, जो कि बहुत ही पुरुष-प्रधान था। उनका नया मॉडल पुरुष नियुक्तियों के प्रति पक्षपाती था। यह बेहद अनैतिक है.
हम डेटा विज्ञान के "तेजी से आगे बढ़ें और चीजों को तोड़ दें" चरण से बहुत आगे निकल चुके हैं। अब, एक डेटा वैज्ञानिक के रूप में, आपको यह जानना होगा कि आपके निर्णयों का लोगों पर वास्तविक प्रभाव पड़ेगा। अज्ञान अब कोई बहाना नहीं है; आपको अपने मॉडल के सभी संभावित प्रभावों के बारे में पूरी तरह से जागरूक होने की आवश्यकता है, और यह जो निर्णय लेता है वह क्यों करता है।
यूमिचिगन के पास एक मददगार है पाठ्यक्रम "डेटा विज्ञान नैतिकता" पर। मुझे भी अच्छा लगा इस किताब यह समझाने के लिए कि डेटा विज्ञान जैसे "संख्या-आधारित" विज्ञान में भी नैतिकता क्यों और कैसे उभरती है।
एक गुप्त जीवन हैक यह है कि जितना बेहतर आप मार्केटिंग करना जानते हैं, आपके लिए नौकरी पाना उतना ही आसान होगा। और "बाज़ार" से मेरा मतलब है "जानिए कि चीज़ों को सेक्सी कैसे बनाया जाए।" मार्केटिंग करने की क्षमता के साथ, आप अपना कौशल बेचने वाला बायोडाटा बनाने में बेहतर होंगे। आप एक साक्षात्कारकर्ता को आकर्षक बनाने में बेहतर होंगे। और विशेष रूप से डेटा विज्ञान में, आप यह समझाने में बेहतर होंगे कि आपका मॉडल - और आपके मॉडल के परिणाम - क्यों मायने रखते हैं।
याद रखें, इससे कोई फर्क नहीं पड़ता कि आपका मॉडल कितना अच्छा है यदि आप किसी और को यह विश्वास नहीं दिला सकते कि यह आवश्यक है। उदाहरण के लिए, कल्पना करें कि आपने एक मॉडल विकसित किया है जो किसी विनिर्माण संयंत्र में उपकरण विफलताओं की भविष्यवाणी कर सकता है। सिद्धांत रूप में, आपका मॉडल कंपनी को अनियोजित डाउनटाइम में लाखों बचा सकता है। लेकिन यदि आप उस तथ्य को सी-सूट तक नहीं पहुंचा सकते हैं, तो आपका मॉडल आपके कंप्यूटर पर अप्रयुक्त पड़ा रहेगा।
विपणन कौशल के साथ, आप एक सम्मोहक प्रस्तुति के साथ अपने उपयोग और अपने मॉडल की आवश्यकता को साबित कर सकते हैं जो वित्तीय लाभ, बढ़ी हुई उत्पादकता की संभावना और आपके मॉडल को अपनाने के दीर्घकालिक लाभों पर प्रकाश डालता है।
यह डेटा विज्ञान की दुनिया में एक बहुत ही दुर्लभ कौशल है क्योंकि अधिकांश डेटा वैज्ञानिक दिल से संख्यावादी लोग हैं। अधिकांश भावी डेटा वैज्ञानिक वास्तव में मानते हैं कि केवल अपना सर्वश्रेष्ठ प्रदर्शन करना और अपना सिर झुकाए रखना एक विजयी रोजगार रणनीति है। दुर्भाग्य से, कंप्यूटर आपको काम पर रखने वाले नहीं हैं - लोग काम पर रखने वाले हैं। स्वयं, अपने कौशल और अपने उत्पादों का विपणन करने में सक्षम होना आज के नौकरी बाजार में एक वास्तविक लाभ है।
मार्केटिंग कैसे करें यह सीखने के लिए, मैं कुछ शुरुआती, निःशुल्क पाठ्यक्रमों की अनुशंसा करता हूँ पसंद कौरसेरा द्वारा प्रस्तुत "डिजिटल दुनिया में विपणन"। मुझे विशेष रूप से "डिजिटल दुनिया में टिके रहने वाले उत्पाद विचारों की पेशकश" अनुभाग पसंद आया। वहाँ कोई डेटा विज्ञान-विशिष्ट विपणन पाठ्यक्रम नहीं है, लेकिन मुझे पसंद आया इस ब्लॉग पोस्ट यह बताता है कि एक डेटा वैज्ञानिक के रूप में अपनी मार्केटिंग कैसे करें।
यह वहां कठिन है। वहाँ होने के बावजूद अनुमानित वृद्धि डेटा वैज्ञानिक रोजगार के मामले में, श्रम सांख्यिकी ब्यूरो के अनुसार, कई प्रवेश स्तर के डेटा विज्ञान उम्मीदवारों को नौकरी पाने में कठिनाई हो रही है, as इन रेडिट प्रविष्टियाँ समझाना. चैटजीपीटी से प्रतिस्पर्धा है और छंटनी के गिद्ध मंडरा रहे हैं।
नौकरी बाजार में प्रतिस्पर्धा करने और खड़े होने के लिए, आपको केवल तकनीकी विशेषज्ञता से ऊपर जाना होगा। डेटा गवर्नेंस, नैतिकता, मॉडल अर्थात फीचर इंजीनियरिंग और मार्केटिंग कौशल आपको प्रबंधकों को नियुक्त करने के लिए अधिक विचारशील, मजबूत और दिलचस्प उम्मीदवार बनाते हैं।
नैट रोसीडि एक डेटा वैज्ञानिक और उत्पाद रणनीति में है। वह एनालिटिक्स पढ़ाने वाले एक सहायक प्रोफेसर भी हैं, और के संस्थापक हैं स्ट्रैट स्क्रैच, शीर्ष कंपनियों के वास्तविक साक्षात्कार प्रश्नों के साथ डेटा वैज्ञानिकों को उनके साक्षात्कार के लिए तैयार करने में मदद करने वाला एक मंच। उसके साथ जुड़ें ट्विटर: स्ट्रैट स्क्रैच or लिंक्डइन.
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/5-rare-data-science-skills-that-can-help-you-get-employed?utm_source=rss&utm_medium=rss&utm_campaign=5-rare-data-science-skills-that-can-help-you-get-employed

